

ウェブには、調査やビジネス上の意思決定に非常に役立つ膨大な量のデータがあります。そのため、Playwrightのようなツールの使い方を知っておくことがとても重要になります。
Playwrightはマイクロソフト社が開発した強力なNode.jsライブラリで、ウェブサイトからデータをスクレイピングできます。この記事では、Playwrightを使用してBright Dataのホームページからデータをスクレイピングする、実用的で詳細な例をご紹介します。これらの例をご覧いただいた後で、Playwrightでスクレイピングしたい他のウェブサイトに適用できます。
Playwrightを使う理由
ウェブスクレイピングは新しい概念ではありません。JavaScriptエコシステムでは、Cheerio、Selenium、Puppeteer、Playwrightなどのツールを使用して、ウェブスクレイピングをよりシンプルにできます。
新しいウェブスクレイピングライブラリのPlaywrightは、次の機能により特に魅力的です。
強力なロケーター
Playwrightは、自動待機および再試行ロジックが組み込まれたロケーターを使用して、ウェブページ上の要素を選択します。自動待機ロジックを使用すると、手動でウェブページが読み込まれるのを待つ必要がないため、よりシンプルなウェブスクレイピングコードを使用できます。
また、再試行ロジックにより、Playwrightは最初のページが読み込まれた後に動的にデータが読み込まれる、最新のシングルページアプリケーション (SPA) のスクレイピングにも適したライブラリと言えます。
複数のロケーターメソッド
Playwrightでロケーターを使用する際、CSSセレクター構文、XPath構文、要素テキストコンテンツなど、数種類の構文を使用してウェブページのどの要素を検出するかを指定できます。また、ロケーターにフィルターを適用して、さらに絞り込むこともできます。
Playwrightでのウェブスクレイピング
このセクションでは、Node.jsプロジェクトを作成し、Playwrightをインストールして、Playwrightを使用してウェブページのデータを検出、操作、抽出する方法を解説します。
前提条件
この記事のコードスニペットは、最新の長期サポート (LTS) バージョンのNode.js (執筆時点ではv18.15.0) で動作します。始める前に、Node.jsがインストールされていることを確認してください。
Visual Studio Codeなどの、JavaScript構文のハイライトとオートコンプリートが可能なコードエディターも強くお勧めします。
新規プロジェクトの作成
新しいターミナルウィンドウを開き、Node.jsプロジェクト用の新しいフォルダを作成し、次のコマンドを使用してそのフォルダに移動します。
mkdir playwright-demoncd playwright-demon
その後、次のnpmコマンドを実行してNode.jsプロジェクトを作成します。
npm init -yn
Playwrightのインストール
Node.jsプロジェクトを作成したら、ターミナルウィンドウで次のコマンドを使用してPlaywrightライブラリをインストールします。
npm install playwrightn
Playwrightはインストール時に必要なブラウザをダウンロードするため、ライブラリのインストールには時間がかかる場合があります。
Bright Dataのホームページを開く
Playwrightライブラリをインストールしたら、プロジェクトフォルダにindex.jsという名前の新しいファイルを作成します。作成したらフォルダに次のコードをコピーして貼り付けます。
// Import the Playwright library to use itnconst playwright = require(u0022playwrightu0022);nn(async () =u003e {n // Launch a new instance of a Chromium browsern const browser = await playwright.chromium.launch({n // Set headless to false so you can see how Playwright isn // interacting with the browsern headless: false,n });n // Create a new Playwright contextn const context = await browser.newContext();n // Create a new page/tab in the context.n const page = await context.newPage();nn // Navigate to the Bright Data home page.n await page.goto(u0022https://brightdata.com/u0022);nn // Wait 10 seconds (or 10,000 milliseconds)n await page.waitForTimeout(10000);nn // Close the browsern await browser.close();n})();n
ターミナルで次のコマンドを使用してスニペットを実行します。
node index.jsn
Chromiumブラウザが開き、Bright Dataのホームページが読み込まれます。
要素の検出
Playwrightを使用してBright Dataのホームページに移動したので、ロケーターを使用してウェブページ上の特定の要素を検出できます。Playwrightには複数のロケーターがあるので、次のセクションで各ロケーターの仕組みを説明します。
CSSセレクターによる要素の検出
Playwrightでは、CSSセレクターを使用してウェブページ上の要素を検出できます。CSSセレクターは、CSSでウェブページ上の特定のHTML要素にスタイルを適用するために使用される、簡潔ながら強力な構文です。
たとえば、Bright Dataのロゴはページヘッダーの<svg>要素で、page_header_logo_svgクラスが割り当てられています。

この情報を使用して、CSSセレクターでSVG要素を検出できます。
const logoSvg = page.locator(u0022.page_header_logo_svgu0022);n
ロケーターはlogoSvg変数に格納され、後で要素を操作したり、要素から情報を抽出したりするために使用できます。
XPathクエリによる要素の検出
XPathは、XMLドキュメント内の要素の検出に使用できるもう1つのセレクター構文です。HTMLはXMLなので、この構文を使用してウェブページ上のHTML要素を検出できます。
たとえば、次のXPathクエリで前のセクションで見たものと同じSVGロゴを選択できます。
const logoSvg = page.locator(u0022//*[@class='page_header_logo_svg']u0022);n
クエリはpage_header_logo_svgクラスが割り当てられているすべての要素を検出し、それらの場所をlogoSvg変数に保存します。
ロールによる要素の検出
HTML要素には異なるロールを割り当てることができます。これらのロールはウェブページにセマンティックな意味を与え、スクリーンリーダーやその他のツールがページをサポートしやすくします。ロールの詳細については、こちらをご覧ください。
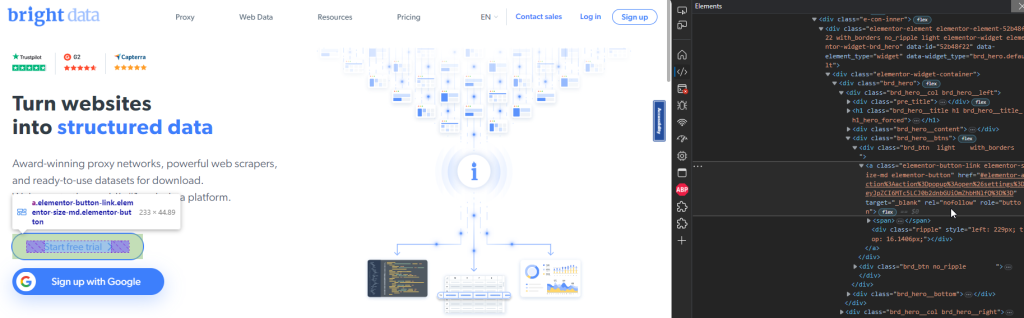
次のコードスニペットは、割り当てられているロールと名前を使用して登録ボタンを見つける方法を示しています。
const signupButton = page.getByRole(u0022buttonu0022, {n name: u0022Start free trialu0022,n});n
このスニペットは、ホームページの[無料トライアルを開始]ボタンを見つけます。
const signupButton = page.getByRole(u0022buttonu0022, {n name: u0022Start free trialu0022,n});
このスニペットは、ホームページの[無料トライアルを開始]ボタンを見つけます。
テキストによる要素の検出
HTML要素にidやclass属性など、有意義な識別子属性がない場合、getByTextメソッドを使用して要素をテキストで選択できます。
たとえば、Bright Dataのホームページのヒーローセクションには、青色で「構造化データ」と書かれたタイトルがあります。
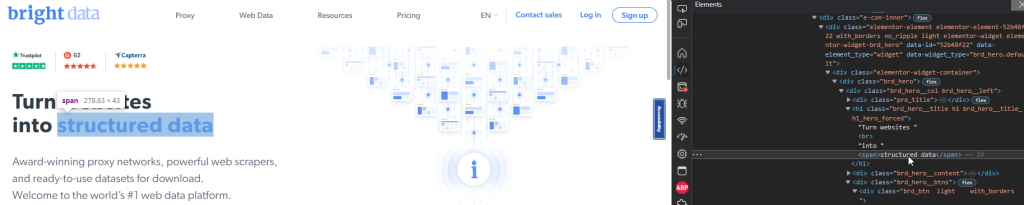
次のPlaywrightスニペットを使用して、これらの単語を含む<span>要素を選択できます。
const structuredData = page.getByText(u0022structured datau0022);n
ラベルによる要素の検出
HTMLフォームでは、入力要素に通常ラベルが付いています。Playwrightは、getByLabelメソッドを使用して、これらのラベルでそのラベルに関連する入力要素を識別できます。
たとえば、Bright Dataのログインページには、「Work email」という言葉を含むラベルが付いた入力要素があります。
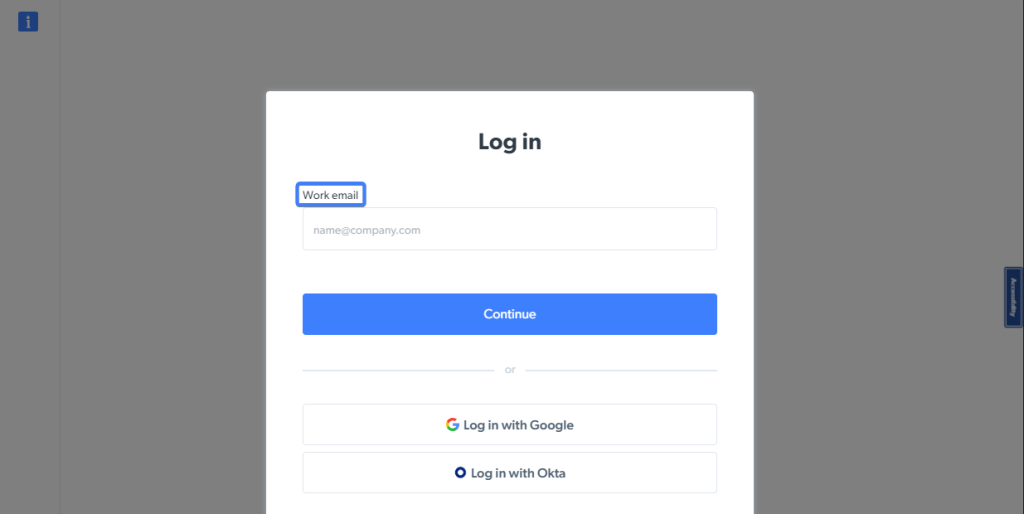
次のコードスニペットを使うと、ページ上でこの入力要素を見つけて変数に保存し、後で使用できます。
// Navigate to the Bright Data login page.nawait page.goto(u0022https://brightdata.com/cp/startu0022);nn// Locate the u003cinputu003e using the labelnconst emailInput = page.getByLabel(u0022Work emailu0022);n
プレースホルダーによる要素の検出
getByPlaceholderメソッドを使用して、表示されたプレースホルダーの値に基づいて入力要素を検出することもできます。
Bright Dataのログインページのメールアドレスフィールドには、入力すべき情報をユーザーに示す、プレースホルダーテキストが表示されます。
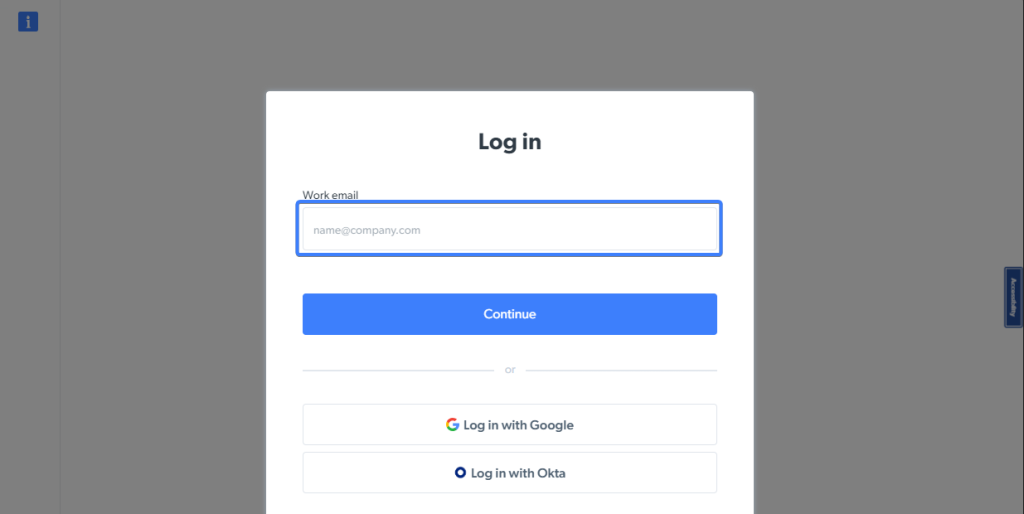
次のスニペットは、入力により表示されるプレースホルダーの値に基づいてこの要素を検出します。
// Navigate to the Bright Data login page.nawait page.goto(u0022https://brightdata.com/cp/startu0022);nn// Locate the u003cinputu003e using the placeholdernconst emailInput = page.getByPlaceholder([email protected]);nn
代替テキストによる要素の検出
HTMLでは、alt属性を使用して画像にテキストの説明を追加できます。この説明は、画像が読み込まれなかった場合に表示され、スクリーンリーダーが画像を説明する際に音声で読み上げられます。PlaywrightのgetByAltTextメソッドでは、alt属性を使用してimg要素を見つけることができます。
たとえば、Bright Dataは自社のデータが使用されている業界をリストアップしています。医療業界用に使用されている画像は、alt値「healthcare use case」を使用して取得できます。
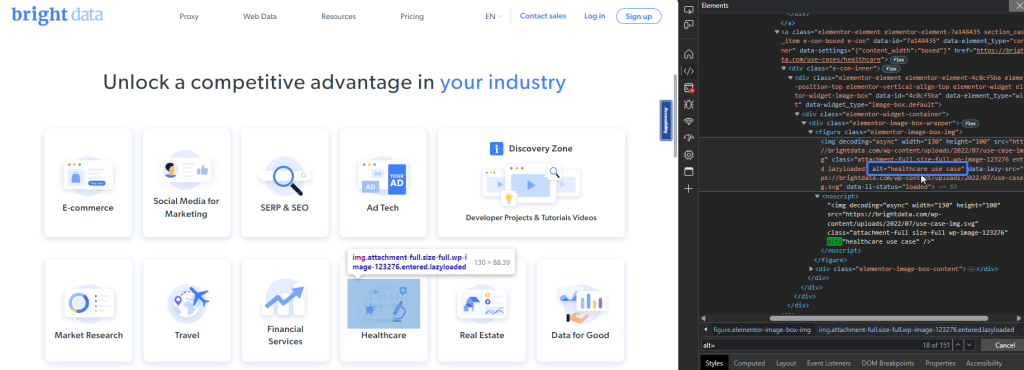
次のコードスニペットは画像要素を検出します。
const healthcareImage = page.getByAltText(u0022healthcare use caseu0022);n
タイトルによる要素の検出
最後にご紹介するスクレイピングに使用できるPlaywrightセレクターは、getByTitleメソッドです。このメソッドは、title属性によってHTML要素を検出します。HTMLコンポーネントにカーソルを合わせると、titleの値が表示されます。
たとえば、Bright Dataヘルプデスクのウェブサイトには、title属性を持つ登録リンクがあります。

次のPlaywrightスニペットを使用して、title属性でリンクを検出できます。
// Navigate to the Bright Data helpdesk webpage.nawait page.goto(u0022https://help.brightdata.com/hc/en-usu0022);nn// Locate the Sign in link using its title attributenconst signInLink = page.getByTitle(u0022Opens a dialogu0022);n
ここまで、Playwrightを使用してウェブページ上の要素を検出する方法をいくつかご紹介してきました。今度は、これらの要素を操作し、データを抽出する方法を解説します。
要素の操作
ウェブページ上の要素を見つけたら、その要素を操作できます。たとえば、保護されているページをスクレイピングするために、ウェブサイトへのログインが必要な場合があります。
このコードスニペットは、ウェブページ上の要素を操作するためのさまざまなPlaywrightメソッドを示しています。次のコードに含まれているそれぞれの関数について説明します。
// Import the Playwright library to use itnconst playwright = require(u0022playwrightu0022);nn(async () =u003e {n // Launch a new instance of a Chromium browsern const browser = await playwright.chromium.launch({n // Set headless to false so you can see how Playwright isn // interacting with the browsern headless: false,n });n // Create a new Playwright contextn const context = await browser.newContext();n // Create a new page/tab in the context.n const page = await context.newPage();nn // Navigate to the Bright Data login page.n await page.goto(u0022https://brightdata.com/u0022);nn // Locate and click on the signup buttonn await pagen .locator(u0022#hero_newu0022)n .getByRole(u0022buttonu0022, {n name: u0022Start free trialu0022,n })n .click();nn // Locate the first name field and FILL in a first namen await page.locator(u0022.hs_firstname inputu0022).fill(u0022Johnu0022);nn // Locate the last name field and FILL in a last namen await page.locator(u0022.hs_lastname inputu0022).fill(u0022Smithu0022);nn // Locate the email field and TYPE in an email addressn await page.locator(u0022.hs_email inputu0022).type([email protected]);nn // Locate the company size field and SELECT an optionn await page.locator(u0022.hs_numemployees selectu0022).selectOption(u00221-9 employeesu0022);nn // Locate the terms and conditions checkbox and CHECK it.n await page.locator(u0022.legal-consent-container inputu0022).check();nn // Wait 10 seconds so you can see the result.n await page.waitForTimeout(10000);nn // Close the browsern await browser.close();n})();n
このスニペットをindex.jsファイルに貼り付け、次のコマンドを使用して再実行します。
node index.jsn
Bright Dataのホームページが少しの間表示された後、登録ダイアログが表示されます。次に、Playwrightがこのスニペットのさまざまなメソッドを使用して、登録フォームにどのように入力するかを説明します。
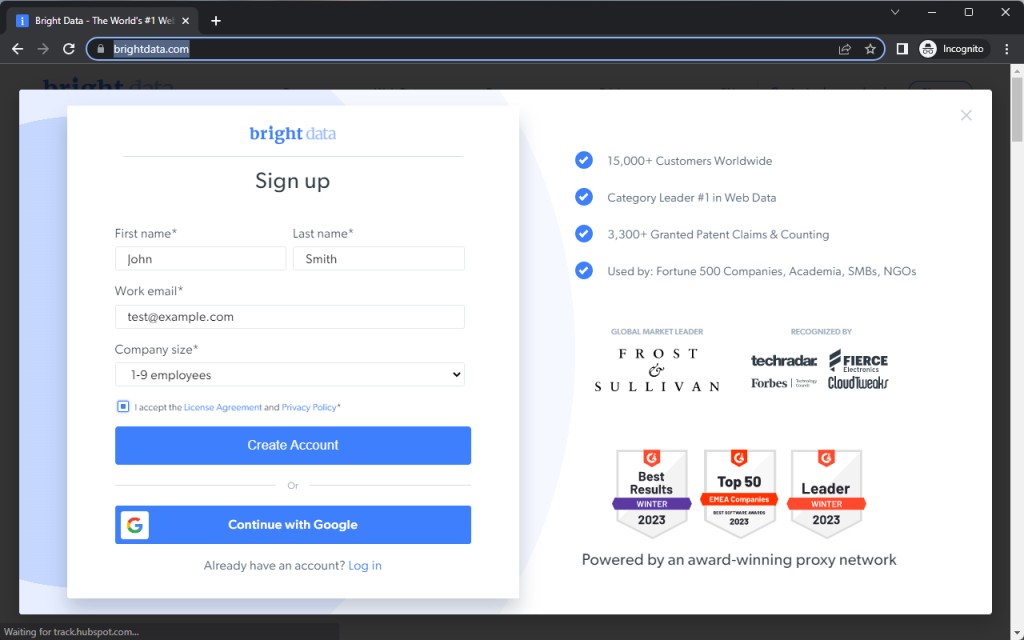
エレメントのクリック
前のスニペットでは、Playwrightが最初に登録ボタンをクリックして、ダイアログが表示されました。
// Locate and click on the signup buttonnawait pagen .getByRole(u0022buttonu0022, {n name: u0022Start free trialu0022,n })n .click();n
Playwrightには、要素をクリックするメソッドが2つあります。
clickメソッドは要素のシングルクリックをシミュレートします。dblclickメソッドは要素のダブルクリックをシミュレートします。
この例では、登録ボタンを一度クリックするだけで済むため、このスニペットではclickメソッドが使用されています。
テキストフィールドへの入力
この例では、スニペットが登録フォームのテキストフィールドに入力するために、2つのメソッドが使用されました。
// Locate the first name field and FILL in a first namenawait page.locator(u0022.hs_firstname inputu0022).fill(u0022Johnu0022);nn// Locate the last name field and FILL in a last namenawait page.locator(u0022.hs_lastname inputu0022).fill(u0022Smithu0022);nn// Locate the email field and TYPE in an email addressnawait page.locator(u0022.hs_email inputu0022).type([email protected]);n
スニペットは、フィールドによってfillとtypeの2つのメソッドを使い分けています。どちらの関数もテキストフィールドに入力しますが、その方法が若干異なります。
fillメソッドは、指定された値をテキストフィールドに挿入します。これはほとんどのフォームで機能しますが、ウェブサイトによっては値全体を挿入できない場合があります。typeメソッドは、指定された値を入力する際に1つ1つのキー入力をシミュレートすることで、そのような問題を解決します。
おそらくほとんどの場合はfillメソッドを使用しますが、必要に応じてtypeメソッドを使用して、値を手動で入力しているようにシミュレートできます。
ドロップダウンオプションの選択
登録フォームには会社の規模を選択するドロップダウンフィールドがあり、Playwrightは「従業員数1~9人」と入力しました。
// Locate the company size field and SELECT an optionnawait page.locator(u0022.hs_numemployees selectu0022).selectOption(u00221-9 employeesu0022);n
Playwrightでは、SelectOptionメソッドを使用してフォームのドロップダウンフィールドのオプションを選択できます。この関数では、値またはラベルに基づいてドロップダウン項目を選択し、複数選択では複数のオプションを選択できます。
ラジオボタンとチェックボックスにチェックを入れる
フォームを送信する前に、利用規約に同意する必要があります。次のスニペットは、適切なチェックボックスにチェックを入れます。
// Locate the terms and conditions checkbox and CHECK it.nawait page.locator(u0022.legal-consent-container inputu0022).check();n
チェックボックスを変更するには、checkとuncheckメソッドを使用できます。
checkメソッドはチェックボックスにチェックを入れます。uncheckメソッドはチェックボックスのチェックを外します。
このセクションでは、Playwrightでページ上のHTML要素を操作する方法を説明しました。次のセクションでは、ページからデータを抽出する方法を解説します。
要素からのデータの抽出
ウェブスクレイピングにはデータの抽出が不可欠です。Playwrightでは、いくつかのメソッドを使用して、検出した要素からさまざまなタイプのデータを取得できます。次のセクションでは、これらのメソッドのいくつかについて説明します。
要素内のテキストの抽出
innerTextメソッドを使用すると、要素内のテキストを抽出できます。たとえば、Bright Dataのホームページの上部にはヒーロー要素があります。
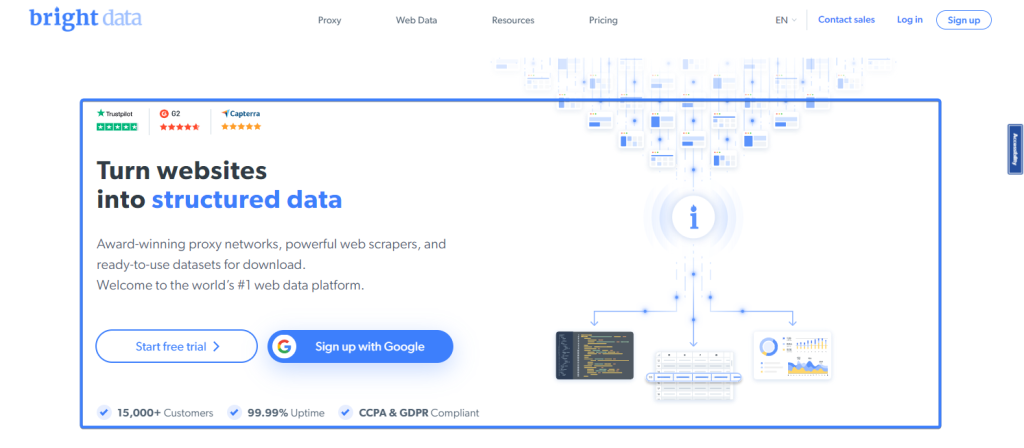
次のスニペットを使用すると、Bright Dataのホームページのヒーローのタイトルを抽出できます。
const headerText = await page.locator(u0022.brd_hero__title.h1u0022).innerText();n// headerText = u0022Turn websites
into structured datau0022n
ロケーターが複数の要素を指している場合、allInnerTextsメソッドを使用して、すべての要素内のテキストを配列の文字列として取得できます。たとえば、Bright Dataのホームページには、自社のデータのユースケースのリストがあります。
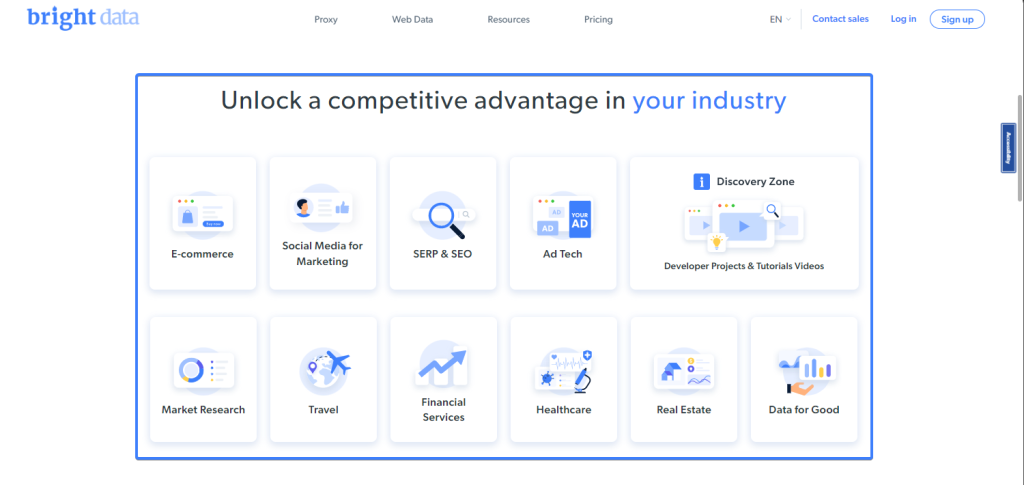
次のスニペットを使用して、Bright Dataのすべてのユースケースのリストを抽出できます。
const useCases = await pagen .locator(u0022.section_cases_row_col .elementor-image-box-titleu0022)n .allInnerTexts();n // useCases = [n // 'E-commerce',n // 'Social Media for Marketing',n // 'SERP u0026 SEO',n // 'Ad Tech',n // 'Market Research',n // 'Travel',n // 'Financial Services',n // 'Healthcare',n // 'Real Estate',n // 'Data for Good'n // ]n
要素内のHTMLの抽出
Playwrightでは、innerHTMLメソッドを使用して要素内のHTMLを抽出することもできます。たとえば、Bright DataのホームページのフッターのHTMLは、次のスニペットを使用して取得できます。
const footerHtml = await page.locator(u0022#footeru0022).innerHTML();n// footerHtml = 'u003cdiv class=u0022containeru0022u003eu003cdiv class=u0022footer__logou0022u003e...'n
属性値の抽出
リンクのhref属性など、HTML要素の属性からのデータ抽出が必要な場合があります。次のPlaywrightスニペットは、ログインリンクのhrefプロパティをスクレイピングする方法を示しています。
const signUpHref = await page.getByText(u0022Log inu0022).getAttribute(u0022hrefu0022);n// signUpHref = '/cp/start'n
ページのスクリーンショットの撮影
データをスクレイピングする際、監査目的でスクリーンショットが必要な場合があります。これにはscreenshotメソッドを使用できます。この関数では、スクリーンショットファイルの保存場所やページ全体のスクリーンショットを撮るかなど、いくつかのオプションを設定できます。
次のスニペットは、Bright Dataのホームページのページ全体のスクリーンショットを撮って保存します。
await page.screenshot({n // Save the screenshot to the u0022homepage.pngu0022 filen path: u0022homepage.pngu0022,n // Take a screenshot of the entire pagen fullPage: true,n});n
自動スクレイピングサービスの使用
ご覧いただいたスニペットでは、ウェブページのデータを検出、操作、抽出する方法が詳細に示されていました。これらのメソッドを使うと、ウェブページからほぼどのようなデータでもスクレイピングできます。しかし、検出する前に適切な要素を特定する必要があるため、手間がかかります。また、1つのウェブサイトで複数のページをスクレイピングする場合、CAPTCHAやレート制限にも注意が必要です。
Bright Dataは、データ抽出に集中できるソリューションをいくつか提供しています。Bright Dataは、人気のウェブサイトからのスクレイピングに役立つ既製のJavaScript関数とテンプレートを備えた、Web Scraper IDEを提供しています。また、Web Unlockerを使用してCAPTCHAを潜り抜け、Bright Dataのプロキシサービスを使用してレート制限やジオロケーションブロックを回避することもできます。これらのサービスはPlaywrightの多くのハードルを取り除き、データをより迅速かつ簡単にスクレイピングできるようにします。
まとめ
この記事では、ウェブサイトからのデータスクレイピングに役立つマイクロソフト社が開発したライブラリ、Playwrightについて解説しました。また、Playwrightを使用してウェブページ上の要素を検出し、操作して、データを抽出する方法も説明しました。最後に、Bright Dataのような自動スクレイピングサービスがウェブスクレイピングのプロセスをどのようにシンプルにできるかもご覧いただきました。





