

このガイドでは以下の内容を確認できます:
- – Crunchbaseスクレイパーの定義と動作原理
- Crunchbaseから自動収集可能なデータの種類
- PythonでCrunchbaseスクレイピングスクリプトを構築する方法
- サイトスクレイピングに高度なソリューションが必要な理由
さっそく見ていきましょう!
Crunchbaseスクレイパーとは?
Crunchbaseスクレイパーとは、Crunchbaseのウェブページからデータを抽出するために設計された自動化ツールです。サイト内をナビゲートし、必要な情報を特定し、ウェブスクレイピングを通じて収集します。
Crunchbaseはデータを保護するため、高度なボット対策およびスクレイピング対策を採用しています。そのため、効果的なCrunchbaseスクレイパーには、JavaScriptレンダリング、CAPTCHAの解決、ブラウザフィンガープリント偽装などの機能が含まれている必要があります。
Crunchbaseからスクレイピングすべきデータ
以下は、ウェブスクレイピングを通じてCrunchbaseから自動的に取得可能なデータのリストです:
- 企業情報:名称、概要、業種、本社所在地、設立日、ステータス(例:活動中、買収済み)など
- 資金調達データ:総調達額、資金調達ラウンド、投資家など
- 主要人物:創業者、経営陣、メンバー、役職・肩書など
- 製品・サービス:製品説明、提供製品・サービスのカテゴリーなど
- 買収・合併:買収対象企業の詳細、買収日・条件など
- 市場・財務データ:売上高予測、従業員数など
- ニュースとイベント:プレスリリース、重要なマイルストーンやイベントなど
- 競合他社:競合企業リストなど
PythonでCrunchbaseスクレイパーを構築する方法
このチュートリアルセクションでは、Pythonを使用してCrunchbaseスクレイパーを作成する方法を学びます。目的は、Bright Data Crunchbaseページから自動的にデータを収集できるスクリプトを開発することです:
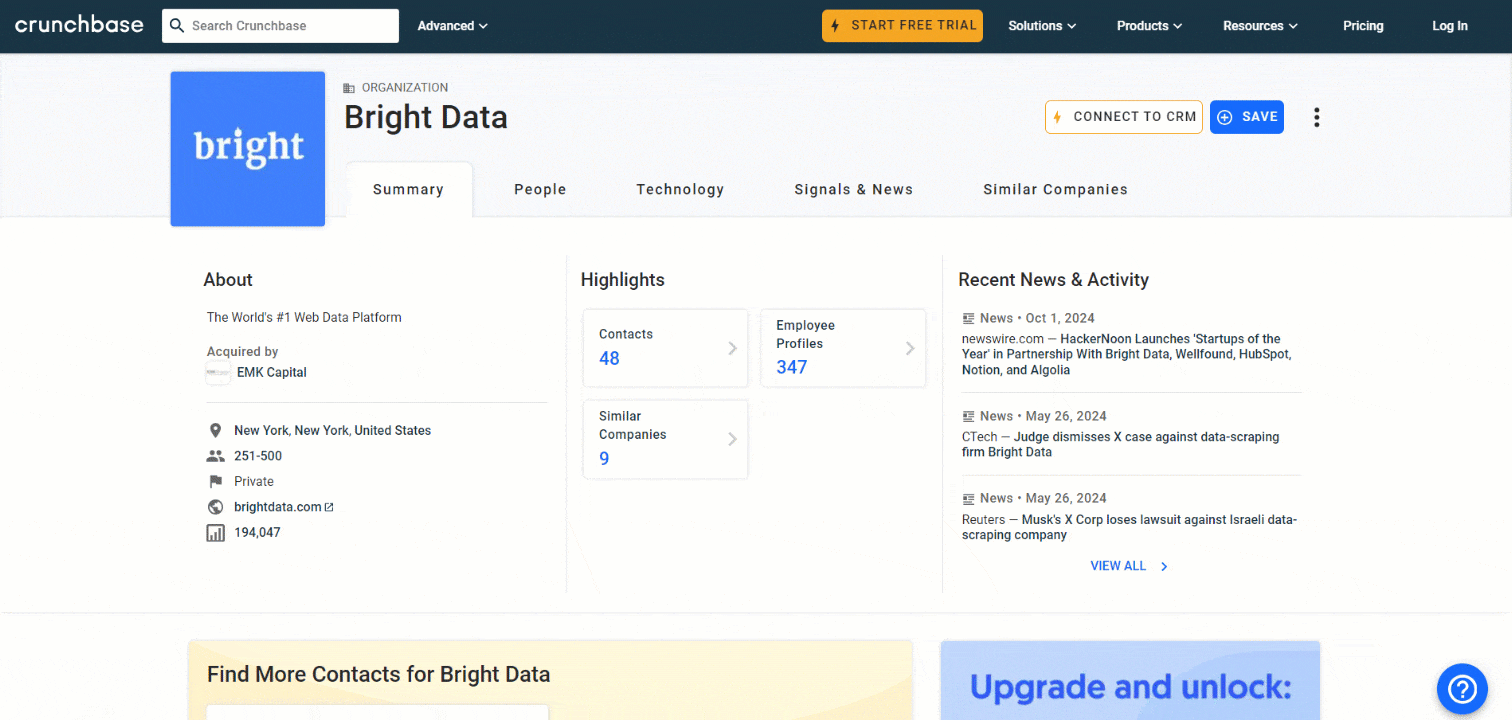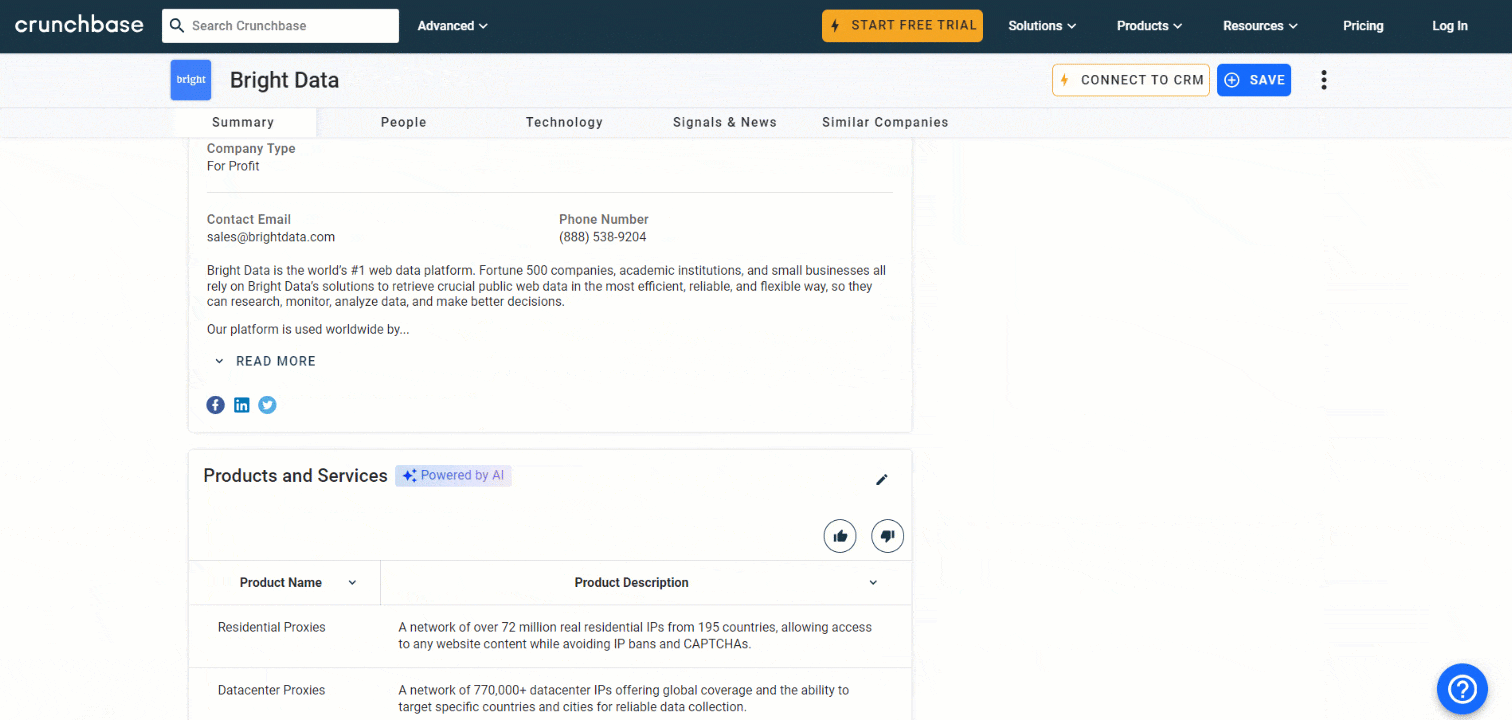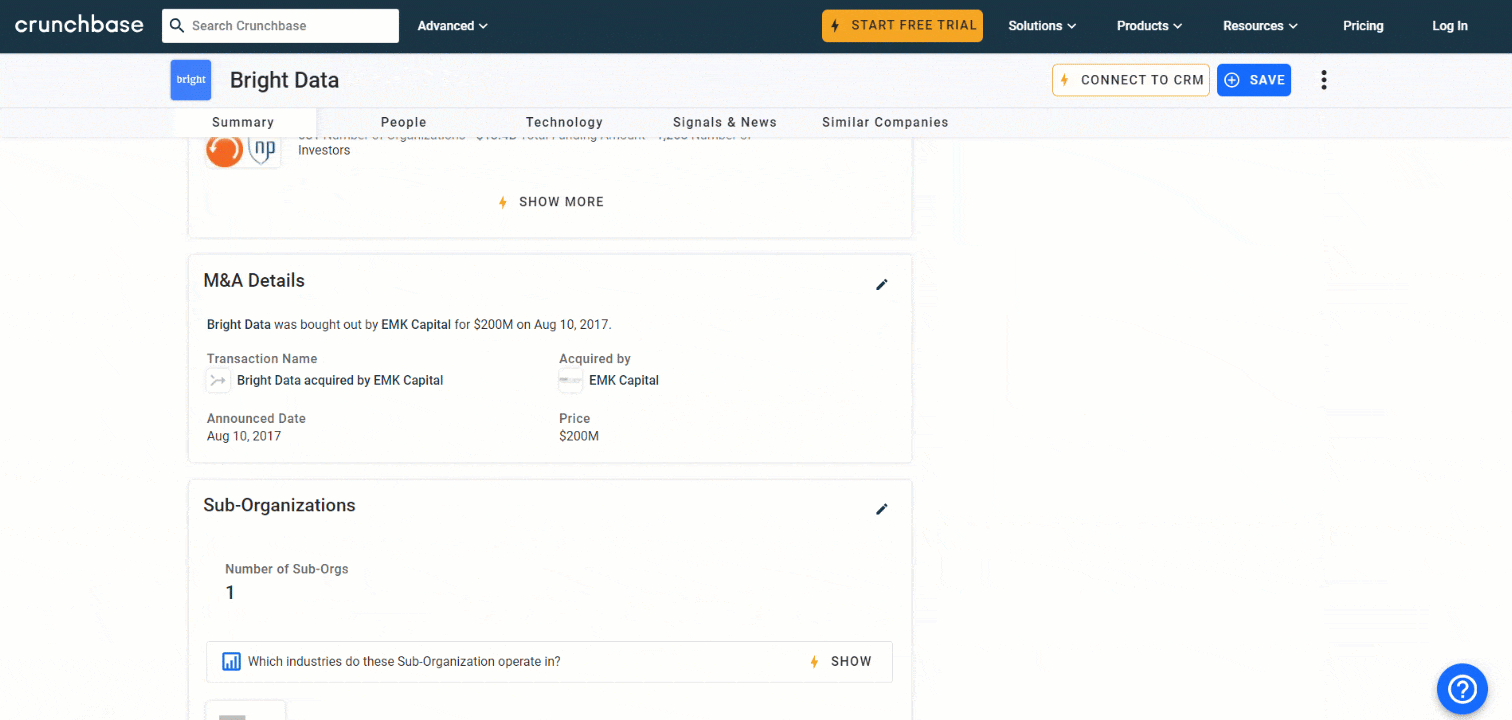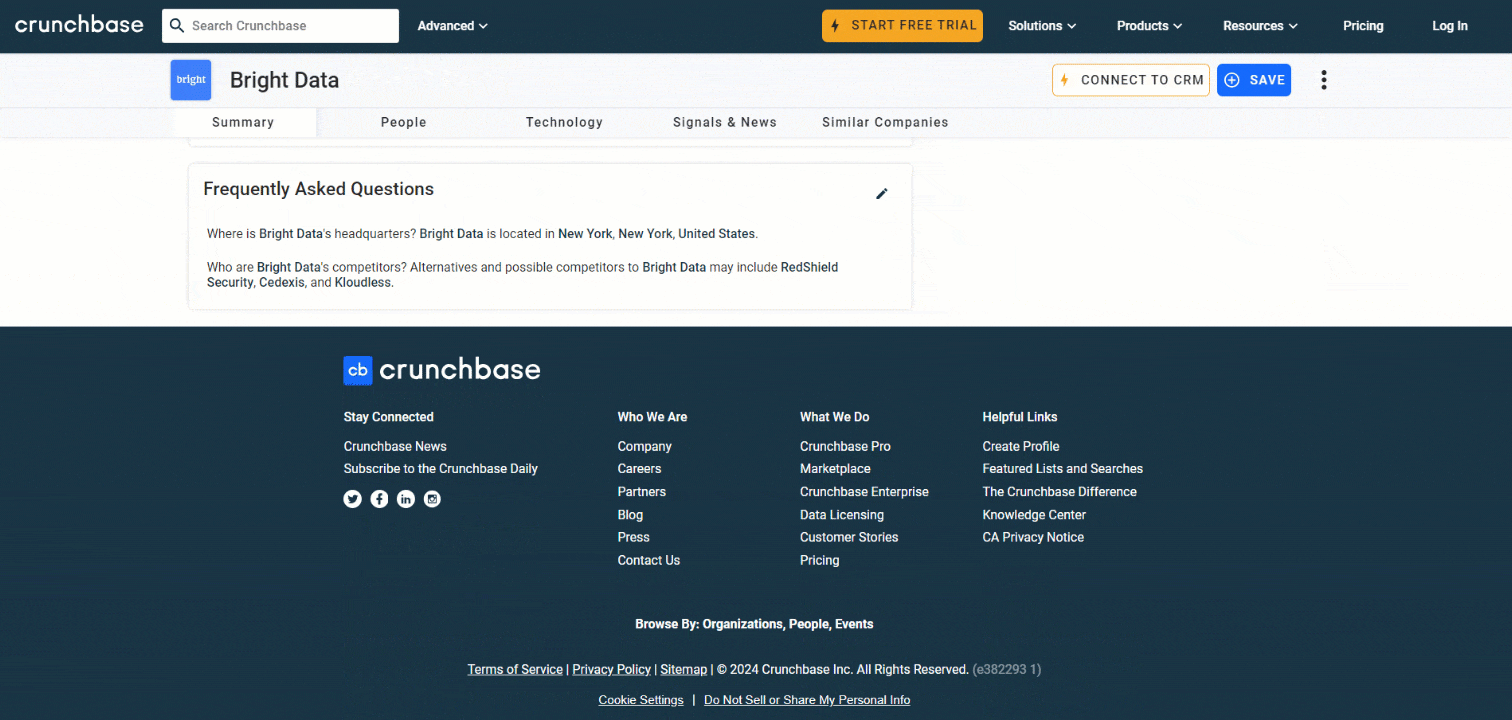
以下の手順に従って、PythonでCrunchbaseをスクレイピングする方法を確認しましょう!
ステップ #1: Pythonプロジェクトの作成
まず、お使いのマシンにPython 3以上がインストールされていることを確認してください。インストールされていない場合は、公式サイトからダウンロードし 、指示に従ってください。
Python Crunchbaseスクレイパー用のディレクトリを作成します:
mkdir crunchbase-スクレイパーcrunchbase-scraperフォルダにはスクレイパーが含まれます。
PyCharm Community EditionやPython拡張機能付きのVisual Studio Codeなど、お好みのPython IDEでプロジェクトフォルダを開きます。
次に、プロジェクトフォルダ内に scraper.py ファイルを作成します。このファイルに Crunchbase のスクレイピングロジックを記述します。
次に、Python仮想環境を初期化します。macOSまたはLinuxユーザーの場合は以下を実行:
python3 -m venv envWindows では同等のコマンドとして以下を実行します:
python -m venv envこれによりプロジェクト内にenvディレクトリが追加されます。
現在のプロジェクト構造は以下のようになります:

仮想環境を以下のコマンドで有効化します:
source env/bin/activateWindowsの場合:
envScriptsactivateこれで、ローカル依存関係をインストールできるPythonプロジェクトが完成しました。
スクリプトは以下で実行できます:
python3 スクレイパー.pyまたは、Windowsの場合:
python スクレイパー.pyステップ #2: スクラッピングライブラリの選定とインストール
次に、Crunchbaseからデータを抽出するのに最適なスクレイピングライブラリを特定する必要があります。まず、デスクトップHTTPクライアントを使用して対象ウェブページにGETHTTPリクエストを送信します。以下のような結果が返されます:
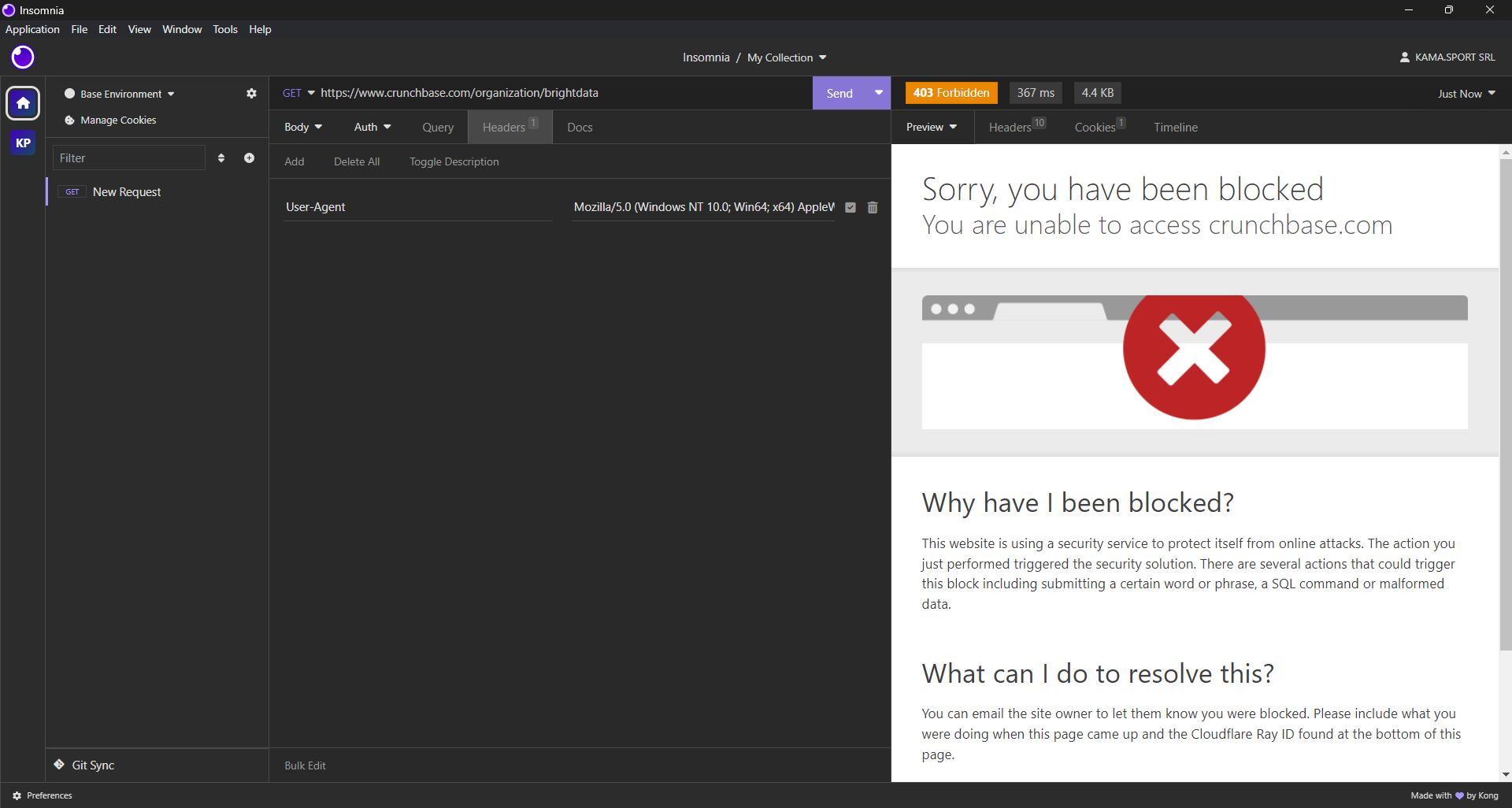
ご覧の通り、Crunchbaseはリクエストをブロックします——現実的なブラウザヘッダーを使用しても同様です。つまり、Crunchbaseを効果的にスクレイピングするにはブラウザ自動化ツールが必要です。最適なヘッドレスブラウザに関する記事で詳細を確認してください。
Pythonでは、Seleniumが最も人気のあるヘッドレスブラウザ自動化ツールの一つです。具体的には、ブラウザに特定の操作を実行させ、動的ページからデータをスクレイピングすることを可能にします。
Seleniumをインストールするには、pipパッケージを使用します。アクティブなPython仮想環境で以下のコマンドを実行してください:
pip install -U selenium次に、スクレイパー.pyファイルで以下の行を使用してSeleniumをインポートします:
from selenium import webdriverこれで、Crunchbase のウェブスクレイピングに必要な環境が整いました。
ステップ #3: 対象ページにアクセスする
Chrome WebDriverインスタンスを初期化し、get()メソッドを使用して制御対象のブラウザに目的のページへのアクセスを指示します:
driver = webdriver.Chrome()
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)その後、WebDriverを閉じ、ブラウザリソースを解放することを忘れないでください:
driver.quit()現在の Crunchbase スクレイパー スクリプトは次のようになります:
from selenium import webdriver
# Chromeインスタンスを制御するドライバーを初期化
# ヘッダーモードで
driver = webdriver.Chrome()
# 目的のCrunchbaseページに移動
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# スクラッピングロジック...
# ドライバーを閉じ、ブラウザリソースを解放
driver.quit()実行すると、スクリプトが終了する直前に一瞬以下のページが表示されます:
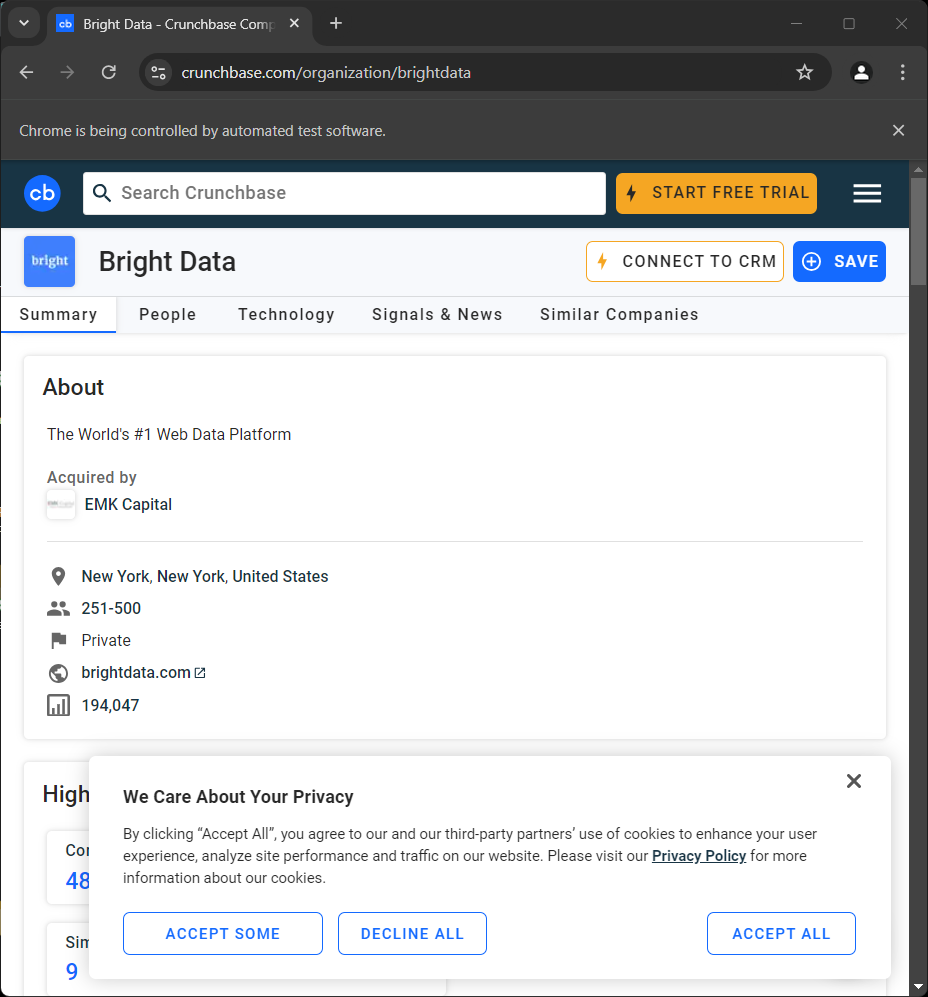
「Chromeはテストソフトウェアによって制御されています」というメッセージは、Seleniumが意図した通りChrome上で動作していることを示しています。
通常、Seleniumのスクラッピングスクリプトではリソース節約のためヘッドレスモードでブラウザを起動します。しかしCrunchbaseは高度なボット検知システムを備えており、ヘッドレスブラウザをブロックします。そのためブラウザをヘッドモードで実行する必要があります。代替手段としてPlaywright Stealthを使用し、これらの検知メカニズムを回避することも可能です。
ステップ #4: クッキーポップアップの処理
欧州のユーザーの場合、数秒後にページに以下のクッキーポップアップが表示されます:
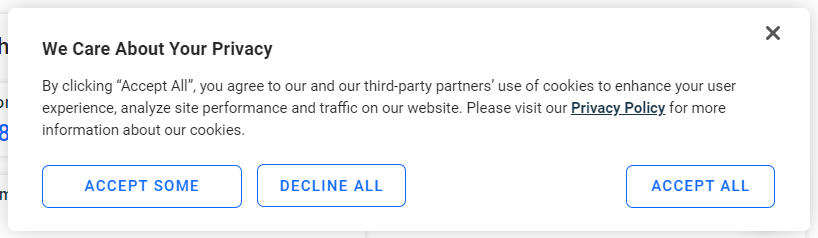
「すべて受け入れる」ボタンをクリックしない限り、ページとのインタラクションは不可能です。ボタンを検査します:
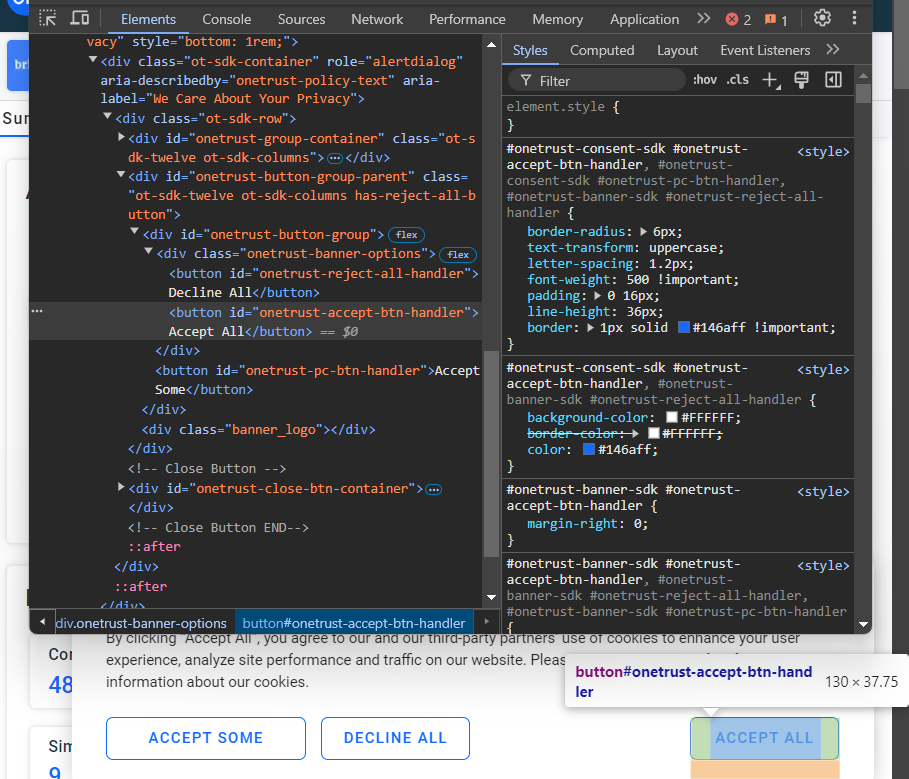
#onetrust-accept-btn-handlerCSSセレクタで選択可能であることが確認できます。
次に、最大60秒間待機して「すべて受け入れる」ボタンがページ上に表示されクリック可能になった時点でクリックする関数を記述します:
def handle_cookie_banner(driver, seconds=60):
try:
# 指定秒数待機し、クッキーバナーの「すべて承諾」ボタンがページに表示されるのを待つ
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# ElementClickInterceptedException エラー回避のため JavaScript 経由でバナーをクリック
driver.execute_script("arguments[0].click();", accept_button)
print("'Accept All' ボタンをクリックしました")
except:
print("{seconds} 秒以内に 'Accept All' ボタンが見つかりませんでした")注意点:
try ... exceptブロックは必須です。クッキーポップアップがページ上に存在しない可能性があるためです。その場合、WebDriverWait はNoSuchElementExceptionを発生させ、exceptで捕捉されます。- 「Accept All」
ボタンはclick()メソッドではなくJavaScript経由でクリックされます。理由は、HTMLボタンがフェードインアニメーションで遅れて表示されるためです。click()でクリックしようとするとElementClickInterceptedExceptionが発生する可能性があります。
上記の関数が動作するには、以下のインポートが必要です:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import Byクッキーポップアップは以下のように呼び出して処理できます:
handle_cookie_banner(driver)素晴らしい!ページのデータスクレイピングを開始する準備が整いました。
ステップ #5: 会社概要情報のスクレイピング
「Summary」カードで最初にスクレイピングする情報は、企業の「About」説明です:
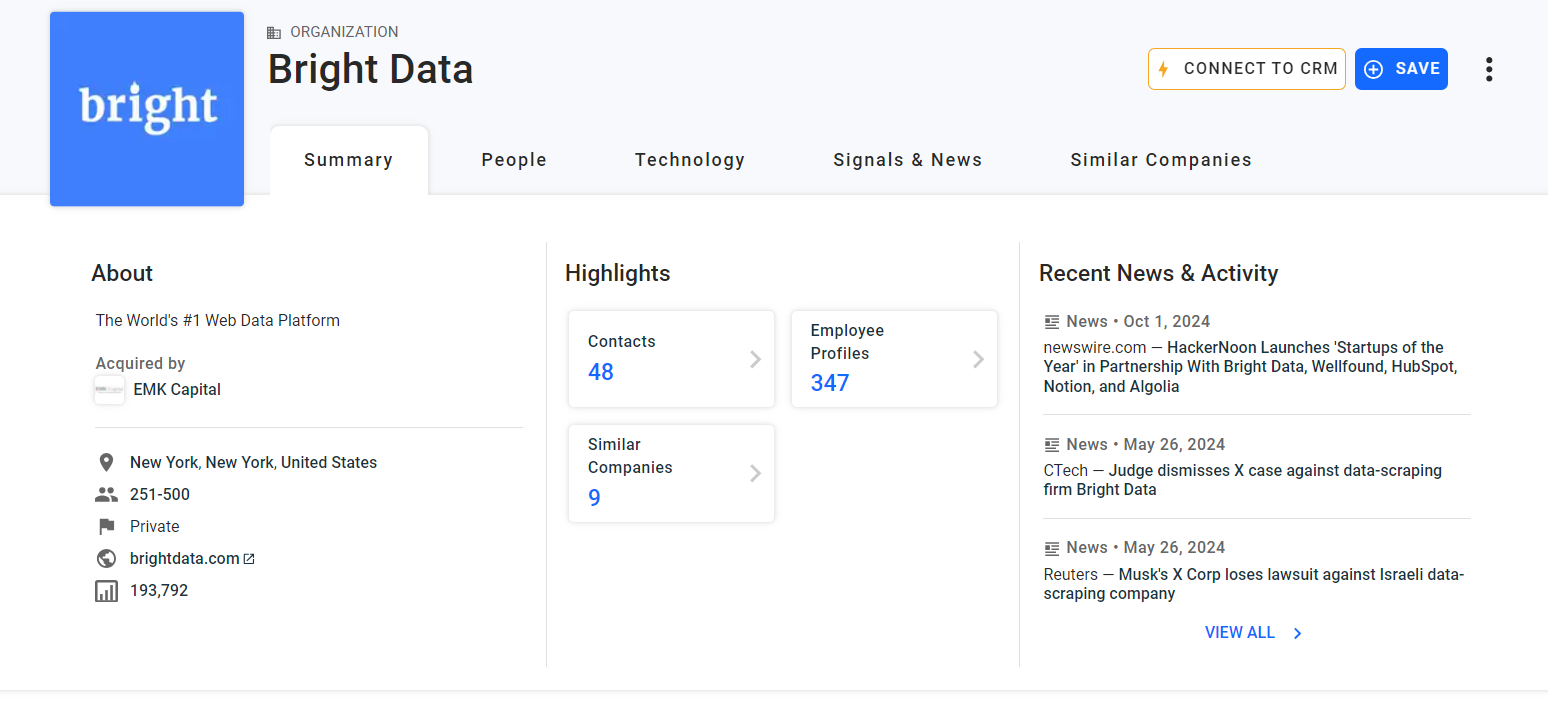
「About」HTML要素を検査します:
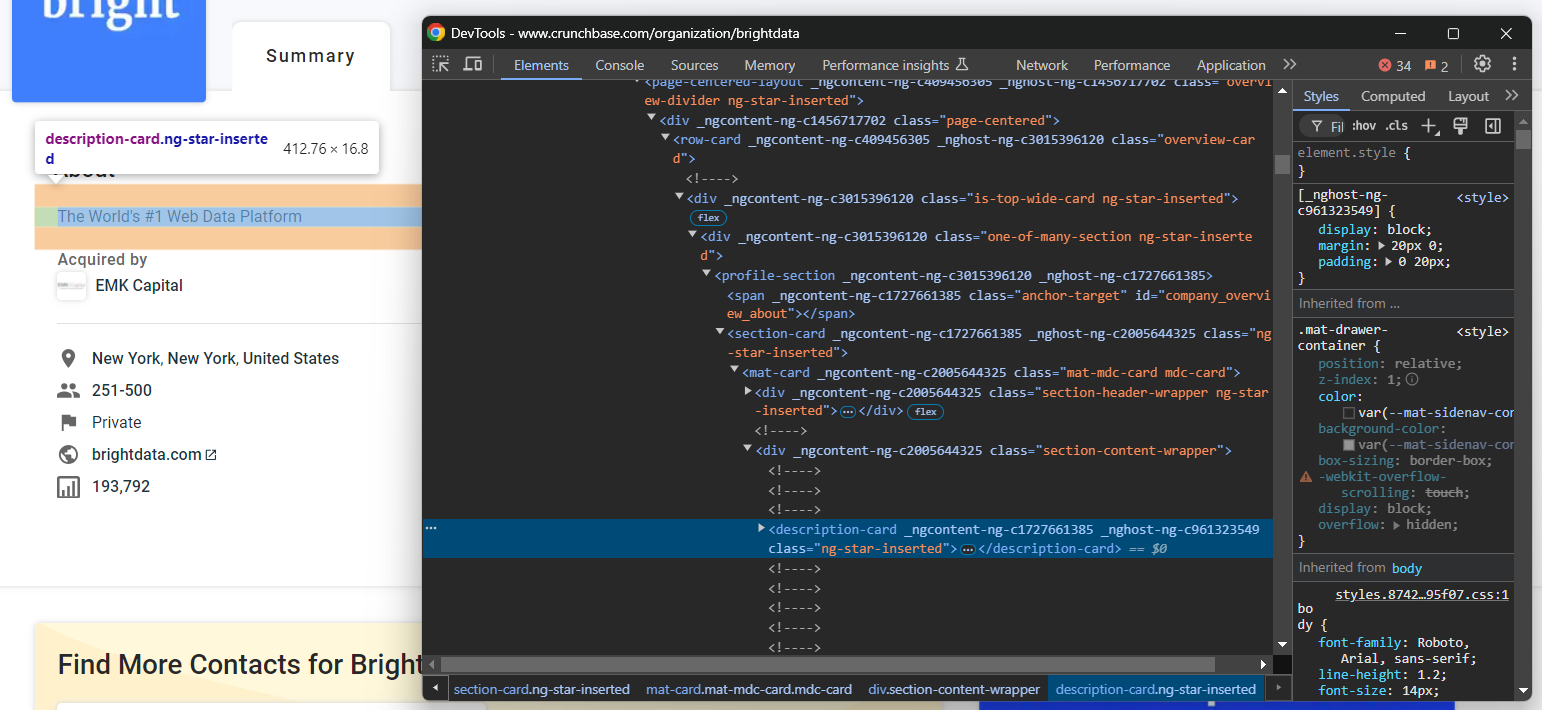
以下のCSSセレクターで選択できることに注意してください:
profile-section description-cardfind_element()メソッドを使用してページ上でCSSセレクタを適用します。その後、text属性でノード内のテキストを抽出します:
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.textabout変数には以下が格納されます:
'The World's #1 Web Data Platform'さあ始めましょう!
ステップ #6: ページ構造の調査
次に、ページ上の「詳細」カードに含まれる情報に注目します:
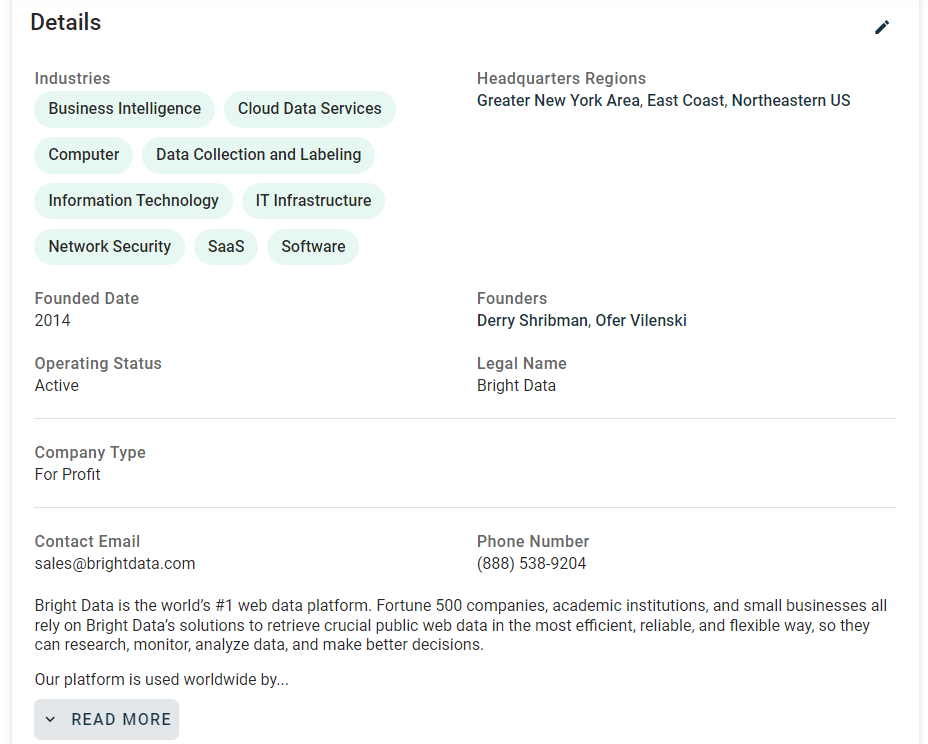
このセクションを調査すると、データをスクレイピングするためのHTML要素を選択する簡単な方法がないことに気づくでしょう:
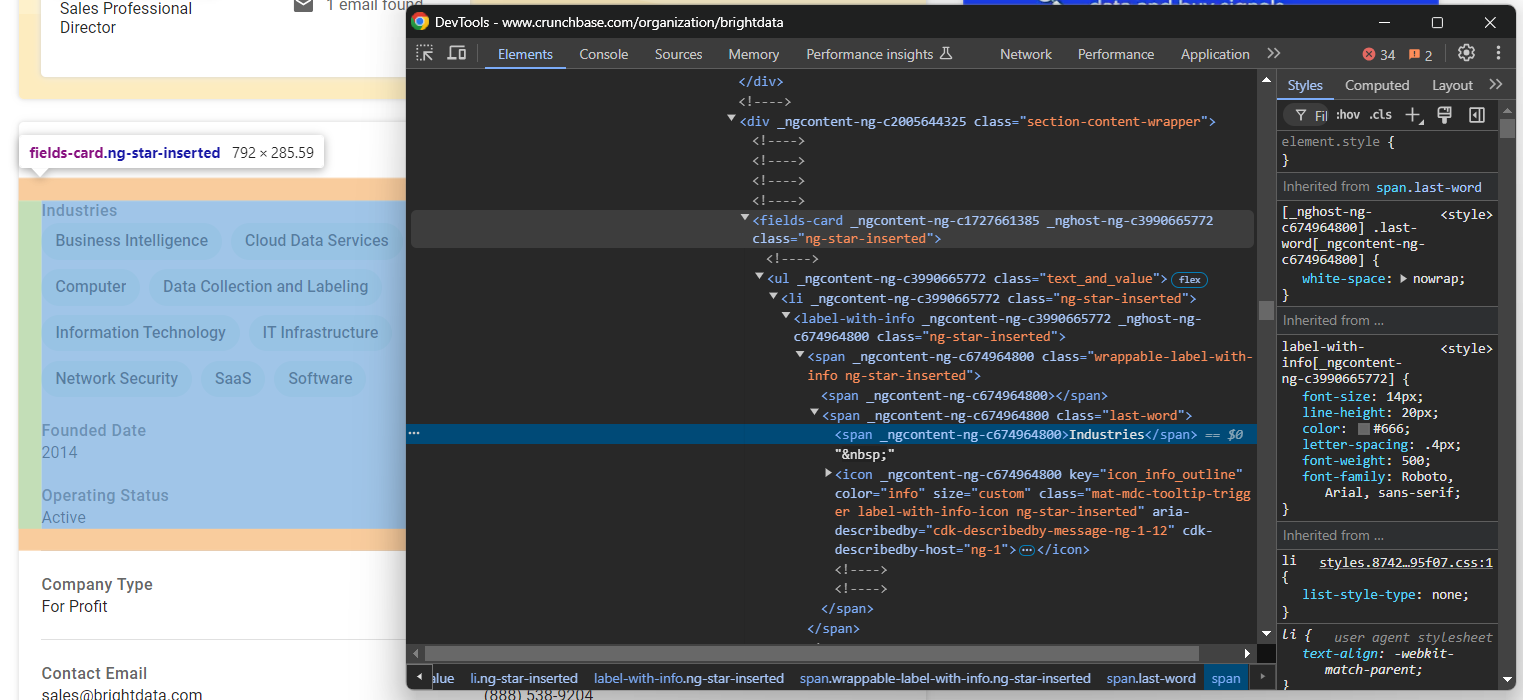
これらのノードのほとんどは、ビルド時に生成されたと思われるランダムなHTML属性を持っています。これらの属性はデプロイのたびに変化するため、ノード選択の根拠として頼れません。さらに、これらの要素の多くは一意のクラスやIDでマークされていません。
対象要素を選択する効果的なアプローチは、そのラベルに注目することです。例えば、業界情報を格納するfields-cardノードは、「Industries」という文字列を含むlabel-with-infoノード を持つfields-cardを特定することで選択できます。
このセクションからのデータスクレイピングにはこの手法を用いるため、ロジックを関数に集約するのが合理的です:
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# すべての親ノードを選択
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# 親ノードを順に調べ、特定の子ノードが目的のテキストを含む親ノードを探す
for parent_node in parent_nodes:
try:
# 現在の親ノード内の特定の子ノードを取得
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# 目的のテキストを含むか確認
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None上記の関数を使用して、「Industries」フィールドカードノードを以下のように選択します:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")素晴らしい!これでCrunchbaseのスクレイピングが格段に楽になります。
ステップ #7: 企業詳細のスクレイピング
「Industries」ノードを検査します:
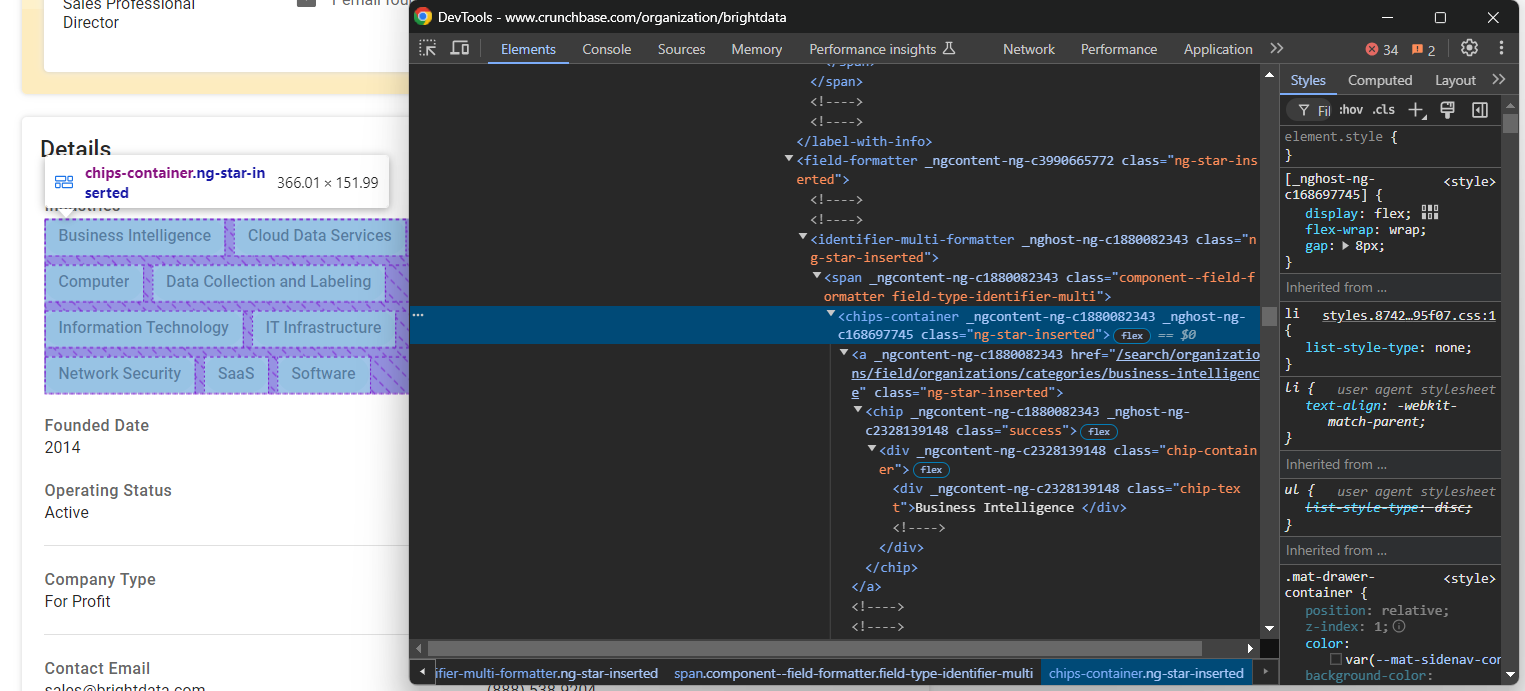
これは企業が事業を展開する業界を格納したノードをchips-containerに保存します。それらをすべて選択し、反復処理してデータを抽出します:
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)次に、「設立日」要素に注目します:
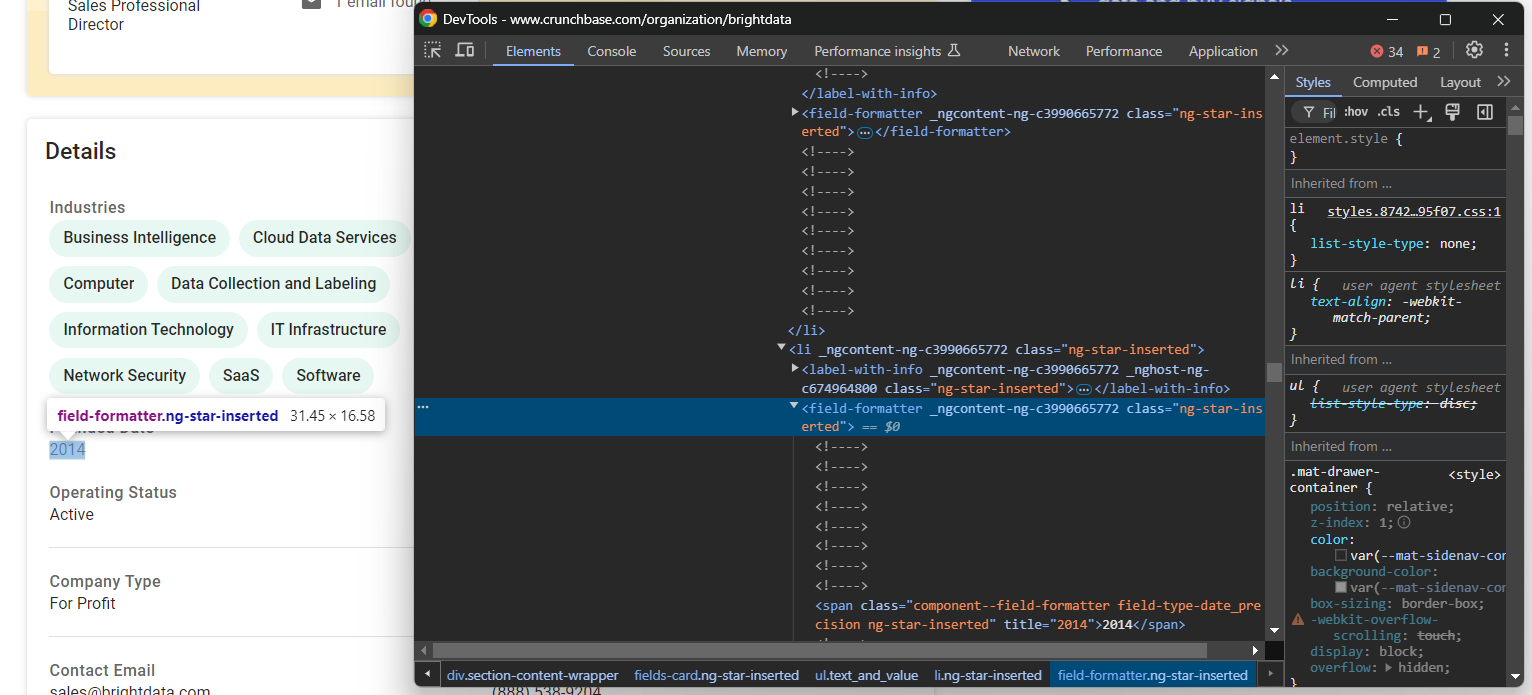
この場合、親要素であるfields-card li内のfield-formatter要素からテキストを抽出するだけなので、スクレイピングロジックはより簡単です:
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founded Date")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text同様のロジックは、他のほとんどの会社詳細要素にも適用できます:
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Headquarters Regions")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Phone Number")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text特別な注意が必要な別のノードは「創設者」要素です:
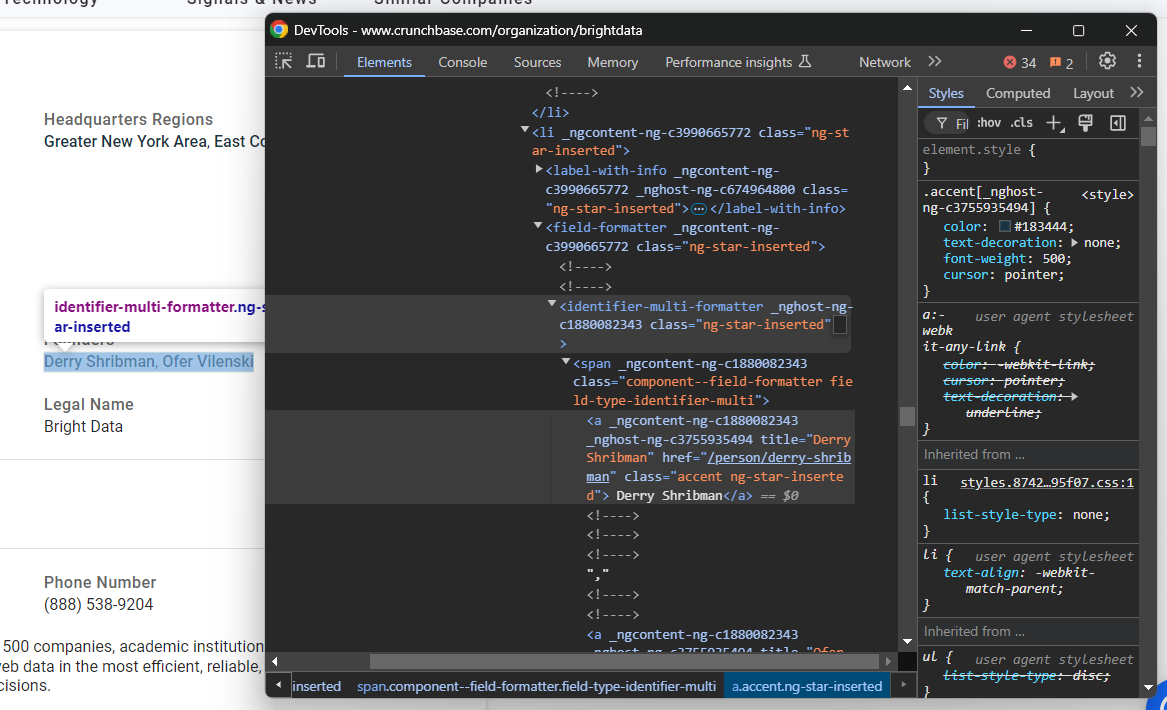
この場合、identifier-multi-formattera ノードを反復処理し、そこからデータを抽出する必要があります:
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Founders")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)最後に、「詳細」セクションの末尾にある説明ノードを確認してください:
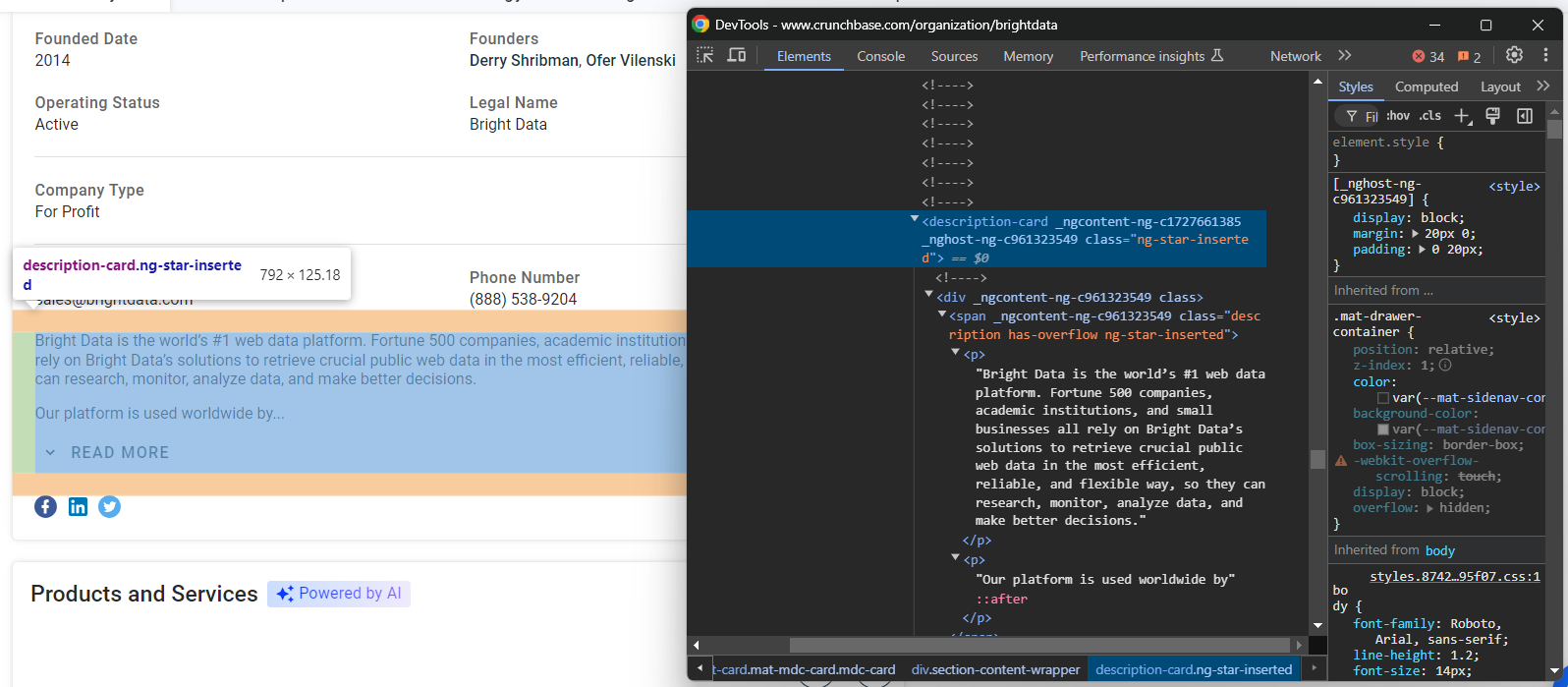
このデータをスクレイピングするには:
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text素晴らしい!Crunchbaseスクレイパーがほぼ完成しました。
ステップ #8: 製品・サービス表のスクレイピング
収集する価値のあるその他の情報として、企業が提供する製品・サービスのリストがあります:
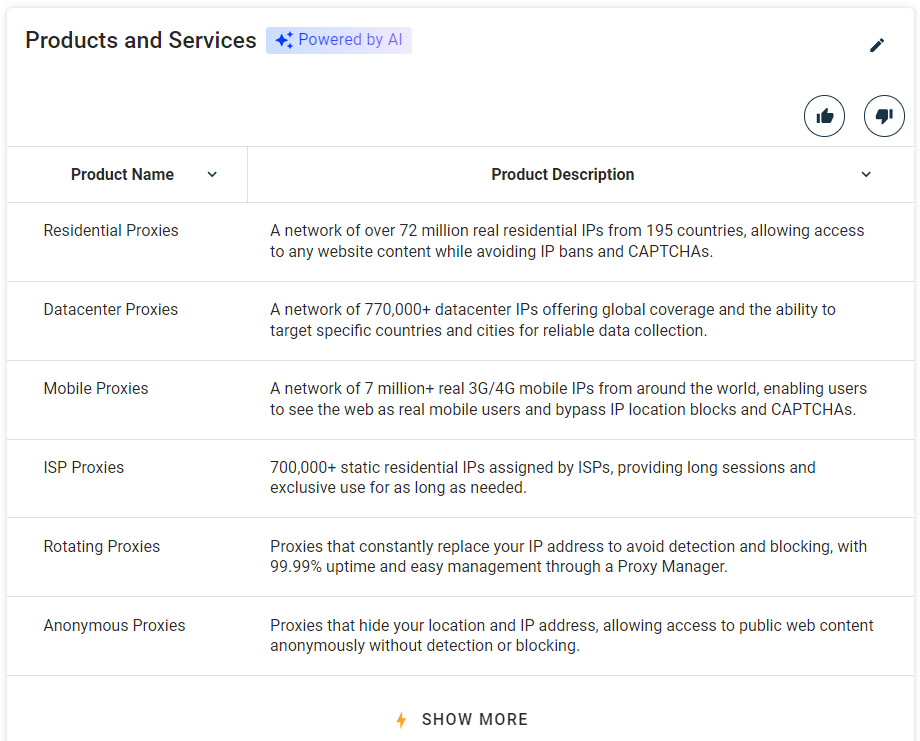
先に定義した関数を使用して「製品とサービス」セクションを選択します:
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Products and Services")次に、以下のコードでテーブルからデータをスクレイピングします:
products = []
for row in products_table_rows:
# 各行の列から名称と説明を抽出
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)素晴らしい!Crunchbaseのスクレイピングロジックが完了しました。
ステップ #9: スクレイピングしたデータのエクスポート
スクレイピングしたデータで企業辞書を作成:
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}次に、company.jsonファイルにエクスポートします:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)まず、open()で出力ファイルcompany.jsonを作成します。次に、json.dump()が company を JSON 形式に変換し、出力ファイルに書き込みます。
Python標準ライブラリのjsonをインポートすることを忘れないでください:
import jsonステップ #10: 全てを統合する
最終的なscraper.pyファイルは以下の通りです:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import json
def find_parent_node_based_on_child_node_text(parent_nodes_selector, child_node_selector, text):
# すべての親ノードを選択
parent_nodes = driver.find_elements(By.CSS_SELECTOR, parent_nodes_selector)
# 親ノードを反復処理し、特定の子ノードが目的のテキストを含むノードを探す
for parent_node in parent_nodes:
try:
# 現在の親ノード内の特定の子ノードを取得
child_node = parent_node.find_element(By.CSS_SELECTOR, child_node_selector)
# 目的のテキストが含まれているか確認
if text.upper() in child_node.text.upper():
return parent_node
except:
continue
return None
def handle_cookie_popup(driver, seconds=60):
try:
# 指定秒数待機し、クッキーポップアップの「すべて受け入れる」ボタンがページに表示されるのを待つ
accept_button = WebDriverWait(driver, seconds).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, "#onetrust-accept-btn-handler"))
)
# ElementClickInterceptedException エラー回避のため JavaScript 経由でポップアップをクリック
driver.execute_script("arguments[0].click();", accept_button)
print("'Accept All' ボタンをクリックしました")
except:
print("'Accept All' ボタンが {seconds} 秒以内に検出されませんでした")
# Chromeインスタンスをヘッダーモードで制御するドライバーを初期化
driver = webdriver.Chrome()
# 対象のCrunchbaseページへ移動
url = "https://www.crunchbase.com/organization/brightdata"
driver.get(url)
# 表示された場合、クッキーポップアップを処理
handle_cookie_popup(driver)
# スクラッピングロジック
about_node = driver.find_element(By.CSS_SELECTOR, "profile-section description-card")
about = about_node.text
industries_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Industries")
industries_nodes = industries_parent_node.find_elements(By.CSS_SELECTOR, "chips-container a")
industries = []
for industry_node in industries_nodes:
industries.append(industry_node.text)
founded_date_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "設立日")
founded_date_node = founded_date_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
founded_date = founded_date_node.text
company_type_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Company Type")
company_type_node = company_type_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
company_type = company_type_node.text
operating_status_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Operating Status")
operating_status_node = operating_status_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
operating_status = operating_status_node.text
headquarters_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Headquarters Regions")
headquarters_node = headquarters_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
headquarters = headquarters_node.text
founders_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "創業者")
founders_nodes = founders_parent_node.find_elements(By.CSS_SELECTOR, "identifier-multi-formatter a")
founders = []
for founders_node in founders_nodes:
founders.append(founders_node.text)
legal_name_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Legal Name")
legal_name_node = legal_name_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
legal_name = legal_name_node.text
contact_email_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Contact Email")
contact_email_node = contact_email_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
contact_email = contact_email_node.text
phone_number_parent_node = find_parent_node_based_on_child_node_text("fields-card li", "label-with-info", "Phone Number")
phone_number_node = phone_number_parent_node.find_element(By.CSS_SELECTOR, "field-formatter")
phone_number = phone_number_node.text
description_node = driver.find_element(By.CSS_SELECTOR, "section-card description-card")
description = description_node.text
products_parent_node = find_parent_node_based_on_child_node_text("profile-section", ".section-title", "Products and Services")
products_table_rows = products_parent_node.find_elements(By.CSS_SELECTOR, "table tbody tr")
# 製品テーブルのスクレイピング
products = []
for row in products_table_rows:
# 各行の列から名前と説明を抽出
name = row.find_element(By.CSS_SELECTOR, "td:nth-child(1)").text
description = row.find_element(By.CSS_SELECTOR, "td:nth-child(2)").text
product = {
"name": name,
"description": description
}
products.append(product)
# スクレイピングしたデータで辞書を埋める
company = {
"about": about,
"industries": industries,
"founded_date": founded_date,
"company_type": company_type,
"operating_status": operating_status,
"headquarters": headquarters,
"founders": founders,
"email": contact_email,
"phone": phone_number,
"description": description,
"products": products
}
# スクレイピングしたデータをJSONファイルにエクスポート
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# ドライバーを終了しブラウザリソースを解放
driver.quit()わずか100行強のコードで、PythonによるCrunchbaseスクレイパーを構築しました!
以下のコマンドでスクリプトを実行します:
python3 script.pyWindowsの場合:
python script.pyプロジェクトフォルダ内にcompany.jsonファイルが生成されます。開くと以下のように表示されます:
{
"about": "世界No.1のWebデータプラットフォーム",
"industries": [
"ビジネスインテリジェンス",
"クラウドデータサービス",
"コンピューター",
"データ収集とラベリング",
"情報技術",
"ITインフラストラクチャ",
"ネットワークセキュリティ",
"SaaS",
"ソフトウェア"
],
"founded_date": "2014",
"company_type": "営利",
"operating_status": "活動中",
"headquarters": "ニューヨーク大都市圏、東海岸、米国北東部",
"founders": [
"Derry Shribman",
"Ofer Vilenski"
],
"email": "[email protected]",
"phone": "(888) 538-9204",
"description": "位置情報やIPアドレスを隠蔽するプロキシサービス。検知やブロックされることなく、匿名で公開ウェブコンテンツにアクセス可能。",
"products": [
{
"name": "レジデンシャルプロキシ",
"description": "195カ国から集めた400M+ monthlyの実際のレジデンシャルIPネットワーク。IP禁止やCAPTCHAを回避しながら、あらゆるウェブサイトコンテンツにアクセス可能。",
},
{
"name": "データセンター・プロキシ",
"description": "77万以上のデータセンターIPからなるネットワーク。グローバルなカバレッジを提供し、特定の国や都市をターゲットにすることで信頼性の高いデータ収集を実現します。",
},
{
"name": "モバイルプロキシ",
"description": "世界中の700万以上の実在する3G/4GモバイルIPネットワーク。ユーザーが実際のモバイルユーザーとしてウェブを閲覧し、IP位置ブロックやCAPTCHAを回避できるようにします。"
},
{
"name": "ISPプロキシ",
"description": "ISPから割り当てられた70万以上のスタティックレジデンシャルIP。長時間のセッションと、必要な限り排他的な利用を提供します。"
},
{
"name": "ローテーションプロキシ",
"description": "検出やブロックを回避するためIPアドレスを絶えず変更するプロキシ。99.99%の稼働率とプロキシマネージャーによる簡単な管理を実現します。"
},
{
"name": "匿名プロキシ",
"description": "位置情報とIPアドレスを隠蔽し、検知やブロックを受けずに匿名で公開ウェブコンテンツにアクセス可能。"
}
]
}これがBright DataのCrunchbase企業ページで入手可能なデータです。
さあ、これでPythonを使ったCrunchbaseのウェブスクレイピング方法が習得できました。
Crunchbaseデータの容易な取得
Crunchbaseは豊富な価値あるデータを提供しますが、スクレイパーや自動ボットから保護するため徹底的な対策を講じています。ヘッドレスブラウザでサイトとやり取りする際や特定の操作を行うと、403 ForbiddenページやCAPTCHAに遭遇する可能性があります。
最初のステップとして、PythonでCAPTCHAを回避する方法に関するガイドを参照できます。ただし、Crunchbaseはさらに高度な反スクレイピング対策を採用しており、それでもブロックされる可能性があります。
適切なツールなしでは、Crunchbaseのスクレイピングはすぐに遅くイライラする作業になりかねません。最適な解決策はBright Dataの専用CrunchbaseスクレイパーAPIです。ブロックされることなくCrunchbaseからデータを取得しましょう!
まとめ
このステップバイステップチュートリアルでは、Crunchbaseスクレイパーの定義と取得可能なデータの種類を学びました。また、約150行のコードのみで企業概要データをスクレイピングするPythonスクリプトの構築方法も確認しました。
問題は、Crunchbaseがボットや自動スクリプトに対して厳格な対策を講じていることです。CAPTCHA、ブラウザフィンガープリント、IP禁止などは、スクレイピングを防ぐために使用される防御策のほんの一部に過ぎません。当社のCrunchbaseスクレイパーAPIを使えば、これらの課題をすべて忘れることができます。
ウェブスクレイピングは不要だがCrunchbaseデータには興味があるという方には、当社のCrunchbaseデータセットをご検討ください!
Bright Dataのソリューションの中から、お客様のニーズに最適なものを見つけるため、専門家にご相談ください。





