

このガイドでは以下を学びます:
- アリババスクレイパーとは何か、その仕組み
- Alibabaから自動取得可能なデータの種類
- Pythonを使用したAlibabaスクレイピングスクリプトの構築方法
さっそく始めましょう!
アリババスクレイパーとは?
アリババスクレイパーとは、アリババのページからデータを自動的に抽出するために設計されたウェブスクレイピングボットです。ユーザーの閲覧行動をシミュレートしてアリババのページをナビゲートします。ページネーションなどの操作を処理し、商品詳細、価格、企業データなどの構造化された情報を取得します。
Alibabaからスクレイピング可能なデータ
Alibabaは貴重な情報の宝庫であり、以下のようなデータが取得可能です:
- 製品詳細:名称、説明、画像、価格帯、販売者情報など
- 企業情報:企業名、製造元詳細、連絡先情報、評価
- 顧客フィードバック:評価、製品レビューなど。
- 物流と在庫状況: 在庫状況、最小発注数量、配送オプションなど。
- カテゴリとタグ:商品カテゴリ、関連タグ、またはラベル。
スクレイピング方法を確認しましょう!
PythonでAlibabaをスクレイピングする:ステップバイステップガイド
このセクションでは、ガイド付きチュートリアルでAlibabaスクレイパーの構築方法を学びます。
目的は、Alibabaの「ノートパソコン」ページからデータを自動的に抽出するPythonスクリプトの作成をガイドすることです:
準備はいいですか?以下の手順に従ってください!
ステップ #1: プロジェクト設定
まず、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ダウンロードしてインストールウィザードに従ってください。
次に、以下のコマンドでプロジェクト用ディレクトリを作成します:
mkdir alibaba-スクレイパー
alibaba-scraperフォルダは、Python Alibabaスクレイパーを配置する場所です。
ターミナルで入力し、その中に仮想環境を作成します:
cd alibaba-スクレイパー
python -m venv env
お好みのPython IDE(Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionなど)でプロジェクトフォルダを読み込みます。
プロジェクトディレクトリ内にscraper.py ファイルを作成します。現在のファイル構造は以下の通りです:

scraper.py は現在空の Python スクリプトですが、すぐに必要なスクレイピングロジックが含まれるようになります。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは次のコマンドを実行:
./env/bin/activate
Windowsでは同等の操作として以下を実行します:
env/Scripts/activate
これでAlibabaウェブスクレイピング用のPython環境の準備が整いました!
ステップ #2: スクラッピングライブラリの選択
次の目標は、Alibabaが動的ページか静的ページを使用しているかを判断することです。そのためには、ブラウザのシークレットモードでAlibabaのターゲットページを開きます。次に、背景を右クリックし、「要素を検査」を選択し、「ネットワーク」タブに移動し、「Fetch/XHR」でフィルタリングし、ページを再読み込みします:
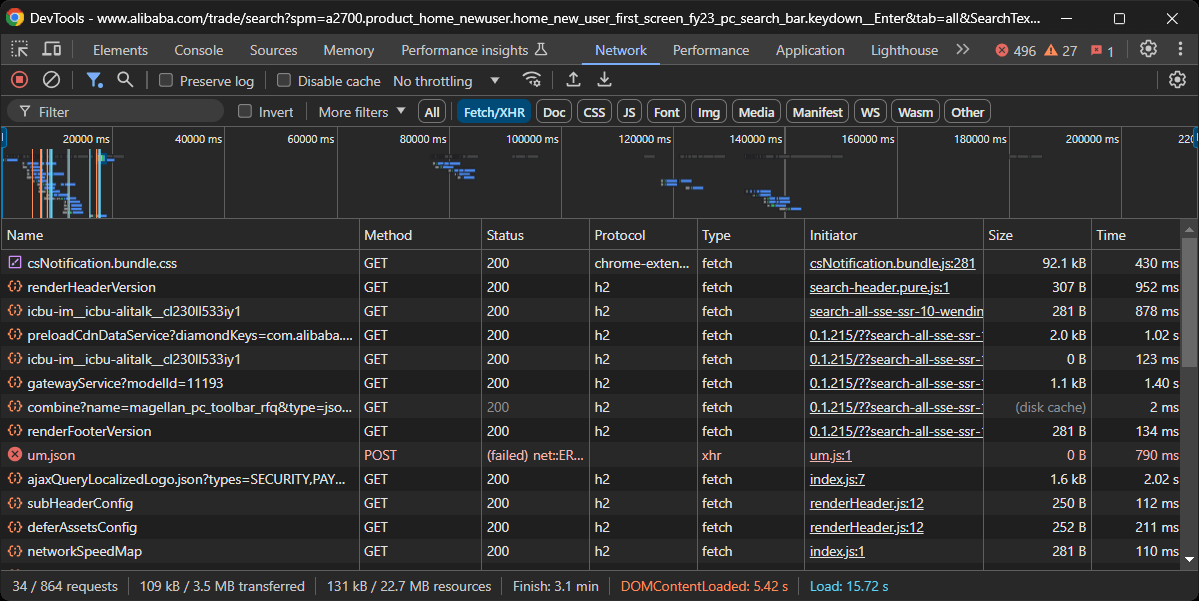
開発者ツールのこのセクションで、ページが重要な動的リクエストを行っているかどうかを確認します。この例では行われているため、ページが動的であることを示しています。さらに分析すると、ページはレンダリングにJavaScriptを使用していることがわかります。
つまり、Alibabaを効果的にスクレイピングするにはSeleniumのようなブラウザ自動化ツールが必要です。詳細はSeleniumウェブスクレイピングチュートリアルでご確認ください。
Seleniumを使用すると、ウェブブラウザをプログラムで制御し、ユーザー操作をシミュレートしてJavaScriptでレンダリングされたコンテンツをスクレイピングできます。さっそくインストールして始めましょう!
ステップ #3: Selenium のインストールと設定
アクティブ化された仮想環境で、以下のコマンドを実行してSeleniumをインストールします:
pip install -U selenium
scraper.pyでSeleniumをインポートし、WebDriverオブジェクトを作成します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスを初期化
driver = webdriver.Chrome(service=Service())
上記のコードはChromeインスタンスを制御するためのWebDriverインスタンスを初期化します。Alibabaはヘッドレスブラウザをブロックする可能性のあるスクレイピング対策を実施している点に注意してください。
したがって、--headlessフラグを設定しないでください。代替案として、Playwright Stealthの検討をお勧めします。
スクレイパーの最終行では、WebDriverを閉じることを忘れないでください:
driver.quit()
素晴らしい!これでAlibabaのスクラッピングを開始する準備が整いました。
ステップ #4: 対象ページへの接続
SeleniumWebDriverオブジェクトが公開するget()メソッドを使用して、目的のページにアクセスします:
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
driver.get(url)
scraper.pyファイルには以下のコードが含まれます:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスを初期化
driver = webdriver.Chrome(service=Service())
# 対象ページのURL
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# 対象ページに接続
driver.get(url)
# スクラッピングロジック...
# ブラウザを閉じる
driver.quit()
最終行にデバッグブレークポイントを設定し、デバッガー付きでスクリプトを実行します。以下のような結果が表示されるはずです:
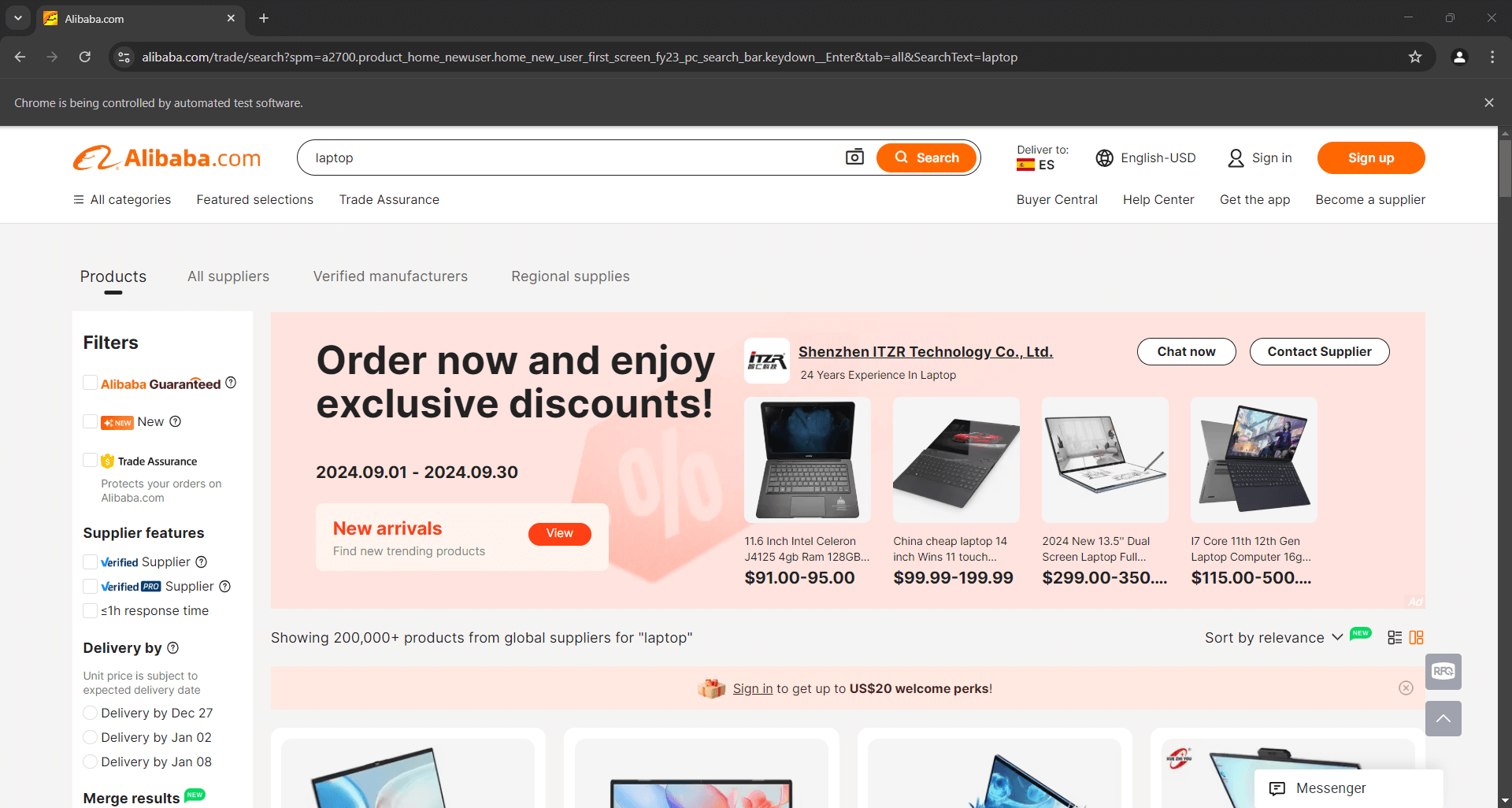
「Chrome は自動テストソフトウェアによって制御されています」というメッセージは、Selenium が想定通り Chrome を制御していることを確認します。よくできました!
ステップ #5: 製品要素の選択
Alibabaの商品ページには複数の商品が含まれるため、スクレイピングしたデータを格納するデータ構造を最初に初期化する必要があります。この目的には配列が最適です:
products = []
次に、ページ上の商品のHTML要素を調査し、以下の点を理解します:
- ・要素の選択方法
- 各要素が含むデータ
- データを抽出する方法
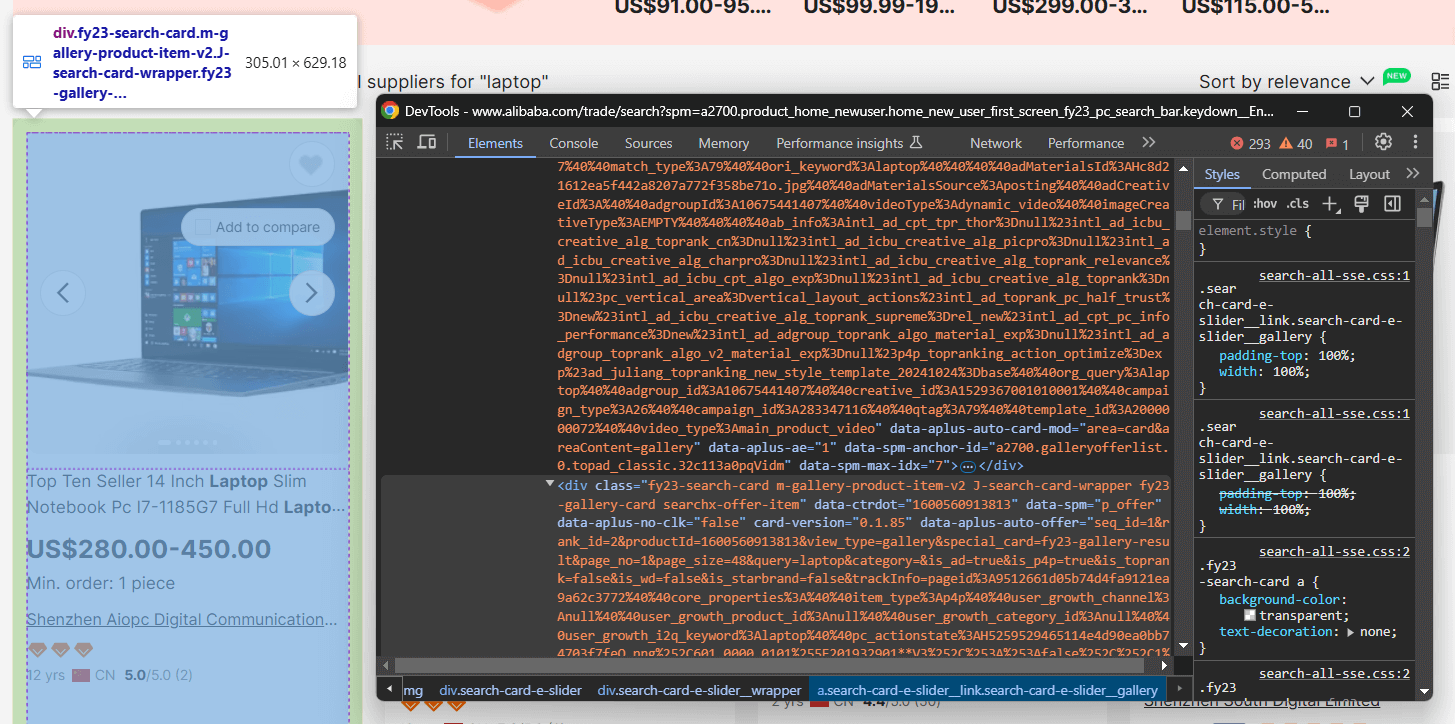
ここでは、各製品要素が.m-gallery-product-item-v2 ノードであることがわかります。
Seleniumを使用してすべての商品要素を選択します:
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
find_elements() は指定されたセレクタ戦略を適用し、ページ上の要素を取得します。上記のケースでは、セレクタ戦略はCSS セレクタです。
Byのインポートを忘れないでください:
from selenium.webdriver.common.by import By
選択された要素を反復処理し、各要素からデータをスクレイピングする準備をします:
for product_element in product_elements:
# 各商品要素からデータをスクレイピング
素晴らしい!Alibabaのスクレイピング成功に一歩近づきました。
ステップ #6: 製品要素のスクレイピング
商品要素を検査してHTML構造を理解する:
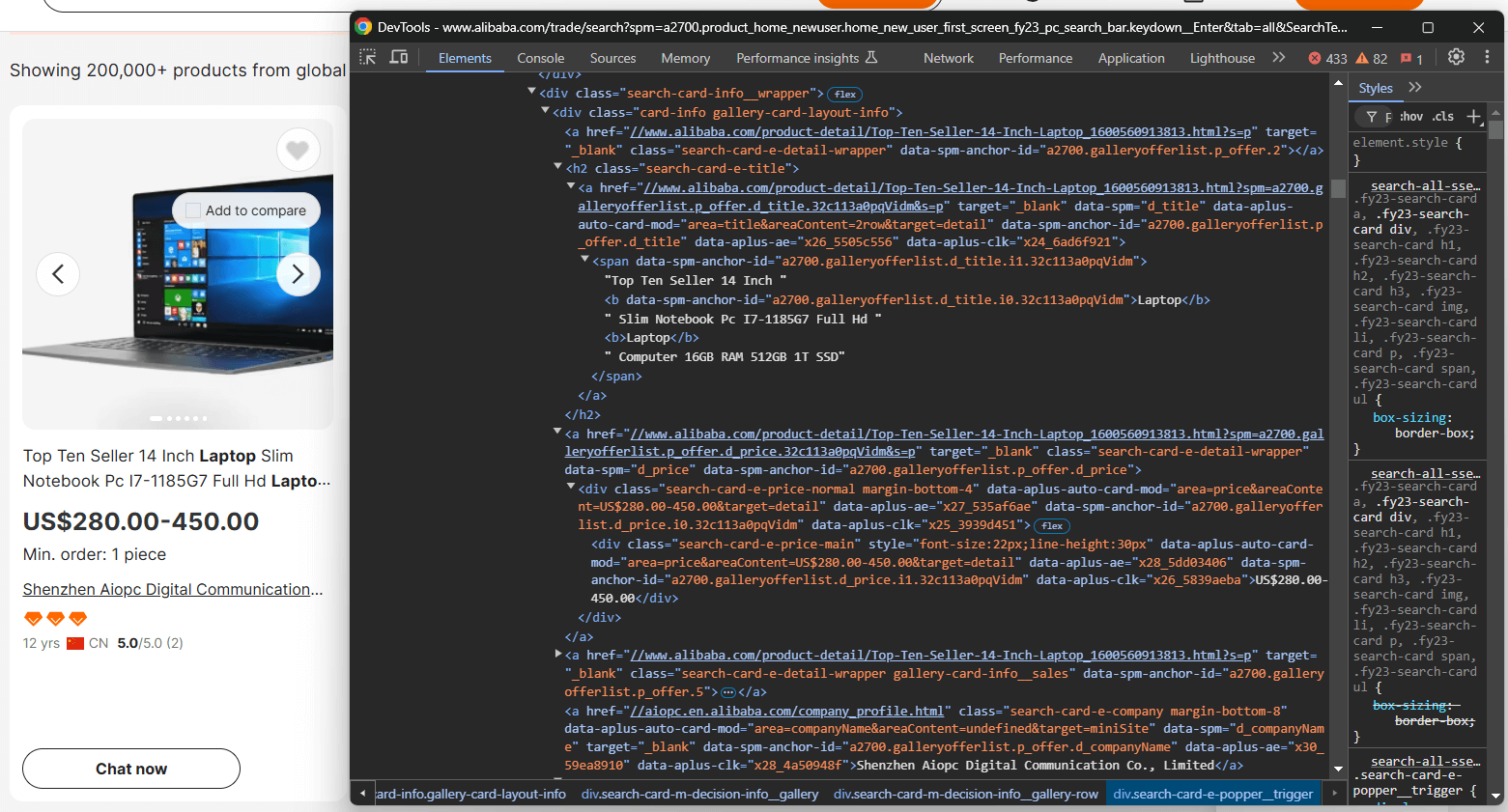
ここでは以下をスクレイピングできることがわかります:
.search-card-e-slider__img内の商品画像.search-card-e-title内の商品説明.search-card-e-price-main内の商品価格帯.search-card-e-companyから会社/製造元
forループ内で、その情報をスクレイピングロジックに変換します:
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
find_element() は指定された CSS セレクタに一致する唯一の要素を取得します。その後、text 属性でそのテキストコンテンツにアクセスできます。ノードの HTML 属性の値を取得するには、get_attribute() メソッドを使用します。
スクレイピングしたデータを使用して製品辞書を作成し、products配列に追加します:
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
products.append(product)
素晴らしい!Alibabaデータ抽出ロジックが完成しました。
ステップ #7: スクレイピングしたデータをCSVにエクスポート
現在、スクレイピングしたデータはproducts 配列に保存されています。他の人とアクセス・共有できるようにするには、CSVファイルのような人間が読める形式にエクスポートする必要があります。
以下のコードを使用して、スクレイピングしたデータでCSVファイルを作成し、データを格納します:
csv_file_name = "products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image", "description", "price", "company"])
# ヘッダー行の書き込み
writer.writeheader()
# 商品データの行書き込み
for product in products:
writer.writerow(product)
Python標準ライブラリのcsvをインポートすることを忘れないでください:
import csv
さあ!あなたのAliabaスクレイパーが完成しました。
ステップ #8: 全てを統合する
以下が最終的なAlibabaスクレイピングスクリプトのコードです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import csv
# Chrome WebDriverインスタンスの初期化
driver = webdriver.Chrome(service=Service())
# 対象ページのURL
url = "https://www.alibaba.com/trade/search?spm=a2700.product_home_newuser.home_new_user_first_screen_fy23_pc_search_bar.keydown__Enter&tab=all&SearchText=laptop"
# 対象ページに接続
driver.get(url)
# スクレイピングしたデータの保存先
products = []
# ページ上の全商品要素を選択
product_elements = driver.find_elements(By.CSS_SELECTOR, ".m-gallery-product-item-v2")
# 商品ノードを反復処理しデータをスクレイピング
for product_element in product_elements:
# 商品詳細を抽出
img_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-slider__img")
img = img_element.get_attribute("src")
description_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-title")
description = description_element.text.strip()
price_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-price-main")
price = price_element.text.strip()
company_element = product_element.find_element(By.CSS_SELECTOR,".search-card-e-company")
company = company_element.text.strip()
# スクレイピングしたデータで製品辞書を作成
product = {
"img": img,
"description": description,
"price": price,
"company": company
}
# 製品データを配列に追加
products.append(product)
# 出力CSVファイル名を定義
csv_file_name = "products.csv"
# 書き込みモードでファイルを開き、CSVライターを作成
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["img", "description", "price", "company"])
# ヘッダー行を書き込む
writer.writeheader()
# 商品データ行を書き込む
for product in products:
writer.writerow(product)
# ブラウザを閉じる
driver.quit()
わずか60行強のコードで、PythonによるAlibabaスクレイパーを構築しました!
以下のコマンドでスクレイパーを起動します:
python3 script.py
Windowsの場合:
python script.py
プロジェクトフォルダ内にproducts.csvファイルが生成されます。開くと以下が表示されます:
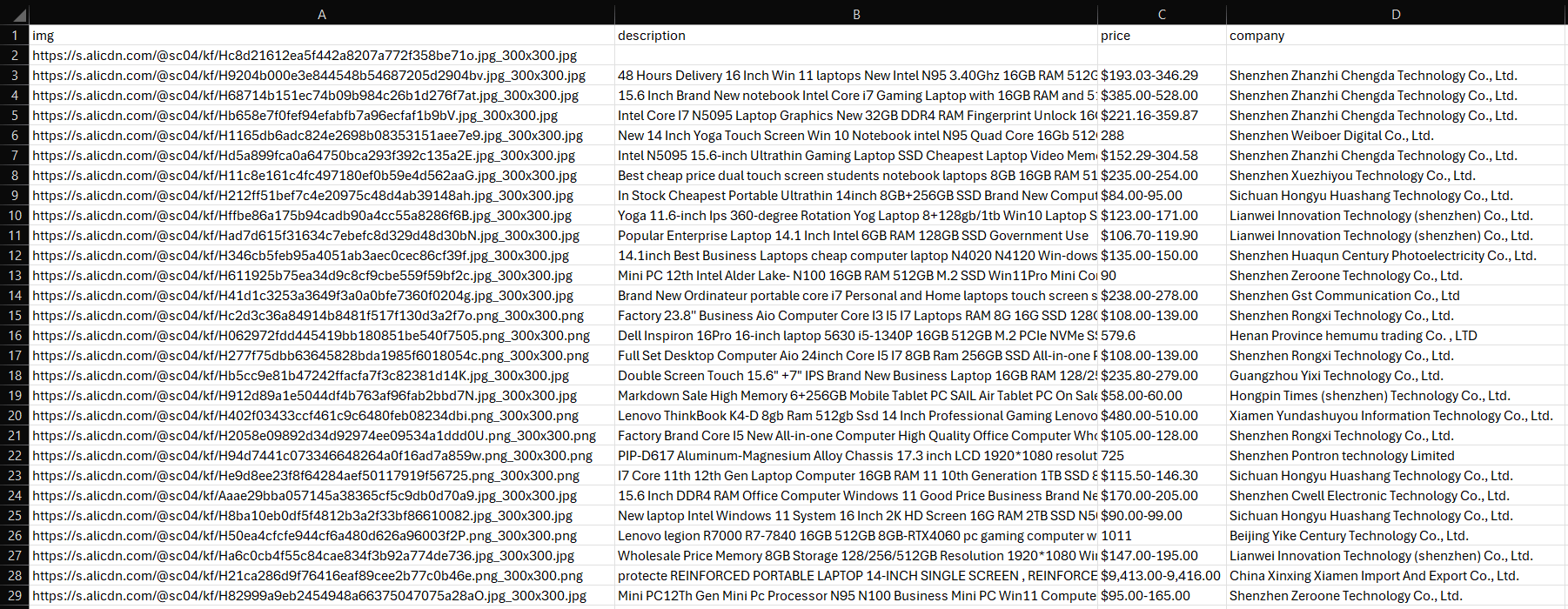
さあ、これで完了です!次のステップは?ページネーションの処理、スクリプトのデプロイ、自動実行の設定、そして最適なパフォーマンスのためのさらなる調整です!
まとめ
このステップバイステップチュートリアルでは、Alibabaスクレイパーの概念と取得可能なデータの種類を学びました。また、100行未満のコードでAlibaba製品をスクレイピングするPythonスクリプトの作成方法も確認しました。
問題は、Alibabaのスクレイピングには課題が伴うことです。プラットフォームは厳格なボット対策を採用し、ページネーションなどの操作によりスクレイピングプロセスを複雑化させています。スケーラブルで効果的なAlibabaスクレイピングソリューションの構築は、非常に困難な場合があります。
当社のAlibabaスクレイパーAPIなら、こうした課題を気にせずご利用いただけます!この専用ソリューションにより、ブロックされるリスクなく、シンプルなAPI呼び出しで対象サイトからデータを取得可能です。
ウェブスクレイピングが好ましくない場合でも、製品データにご興味があれば、すぐに使える当社のAlibabaデータセットをご検討ください!
今すぐBright Dataの無料アカウントを作成し、スクレイパーAPIをお試しいただくか、データセットをご覧ください。






