ローカルスクレイピングの規模を1,000ページから100,000ページに拡大する場合、通常はサーバー、プロキシ、運用作業の増加を意味します。対象サイトのスクレイピング難易度が上昇し、インフラコストが増加します。チームは機能開発よりもスクレイパーの修正に時間を費やすようになります。大規模化に伴い、スクレイピングは単なるスクリプトからインフラストラクチャへと変貌します。
ローカルスクレイピングとクラウドスクレイピングの選択は、コスト、信頼性、配信速度の3点に影響します。
要約
- ローカルスクレイピングは自社マシン上で実行されます。完全な制御権はありますが、手動でのメンテナンスが必要です。
- クラウドスクレイピングは自動スケーリングと組み込みのIPローテーションを備えたリモートインフラ上で実行されます。
- 1,000ページ未満、または規制対象の内部専用データにはローカルスクレイピングを選択。
- 10,000ページ以上、ブロックされたサイト、または24時間365日の監視が必要な場合はクラウドスクレイピングを選択してください。
- IPブロックは最大のボトルネックであり、68%のチームが主な課題として挙げています。
- 大規模運用では、クラウドスクレイピングによりDevOpsのオーバーヘッドを排除し、総コストを最大70%削減可能です。
- Bright Data は 1 億 5000 万以上のレジデンシャルIP、99.9% の稼働率、メンテナンス不要の実行を提供します。
ローカルスクレイピングとは?
ローカルスクレイピングとは、コード、IP、ブラウザだけでなく、障害やダウンタイムも含め、スタック全体を所有することを意味します。スクレイピングスクリプトを自社のインフラ上で実行し、パイプライン全体を自ら管理します。
管理されたインフラストラクチャ層は存在しないため、何かが壊れた場合は、自分で修正する必要があります。
ローカルスクレイピングの仕組み
ローカルスクレイピングはシンプルな実行ループに従います。スクリプトがリクエストを送信し、レスポンスを受信し、HTMLまたはレンダリングされたページからデータを抽出します。
リクエストは自身のIPアドレス、または設定したプロキシから発信されます。サイトがトラフィックをブロックした場合、IPをローテーションし手動でリクエストを再試行する必要があります。
静的ページにはシンプルなHTTPクライアントで十分ですが、JavaScriptを多用するサイトでは、コンテンツを抽出する前にレンダリングするためにローカルでヘッドレスブラウザを実行する必要があります。
これらに加え、ローカルスクレイピングでは通常、CAPTCHAやその他のボット対策を手動で処理する必要があります。
小規模では問題ありませんが、ボリュームが増えると、当初のシンプルなスクリプトは、運用・保守が必要な複雑なインフラシステムへと急速に変化します。
ローカルスクレイピングの利点
ローカルスクレイピングは実行を完全に自身の環境内に留めるため、以下が必要な場合に最適です:
- 完全な実行制御:リクエストのタイミング、ヘッダー、パースロジック、保存方法を管理できます。
- サードパーティへの依存なし:外部インフラやプロバイダーなしでスクレイピングを実行できます。
- 機密データの保護:データは自社ネットワーク内に留まります。
- 高い学習価値:ヘッダー、クッキー、レート制限、失敗処理を直接扱うことで実践的な知見が得られます。
- 小規模タスクの低コスト設定:保護されていないサイトの少量スクレイピングにはスクリプトとノートPCのみで十分。
ローカルスクレイピングの限界
ボリュームと信頼性要件が増すにつれ、ローカルスクレイピングの維持は困難になる:
- スケーラビリティの低さ:ボリューム増加には追加サーバーと帯域幅の購入が必要。
- IPブロック:サイトがトラフィックをブロックするため、プロキシの調達・ローテーションプロキシ・交換が必要。
- CAPTCHAによる中断:手動解決は自動化を妨げ、自動解決ツールはコストと遅延を生む。
- JavaScript多用ブラウザ実行:JavaScript多用サイトでは、CPUとメモリを大量に消費するローカルブラウザが必要となる。
- 継続的なメンテナンス:サイト変更や検出アルゴリズムの更新により、頻繁なコード修正と再デプロイが必要となる。
- 脆弱な信頼性:障害発生時は介入するまでデータ収集が停止する。
例:Pythonによるローカルスクレイピング
小規模なPythonによるローカルスクレイピングの実例:
import requests
from bs4 import BeautifulSoup
def scrape_products(url):
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
return [
{
"name": item.find("h3").text.strip(),
"price": item.find("span", class_="price").text.strip(),
}
for item in soup.select(".product-card")
]
products = scrape_products("https://example.com/products")このスクリプトはローカルで実行され、実際のIPアドレスを使用します。保護されていないサイトでは数百ページを問題なく処理できます。
ただし、欠けている点に注意してください。プロキシローテーション、CAPTCHA処理、再試行ロジック、監視機能がありません。これらの機能を追加すると、スクリプトが肥大化し、実行や保守が困難になる可能性があります。
クラウドスクレイピングとは?
クラウドスクレイピングは、実行をアプリケーションの外に移します。プロバイダーのAPIにリクエストを送信すると、抽出されたデータが返されます。プロバイダーがプロキシネットワークの運用と必要なスクレイピングインフラ全体を管理します。
Bright Dataのようなプラットフォームは、このインフラを本番環境規模で運用しています。
クラウドスクレイピングの仕組み
クラウドスクレイピングはリクエスト→実行→レスポンスのモデルに従います:
- プロバイダーのAPIを通じてスクレイピングリクエストを送信します。
- プロバイダーは、そのリクエストをプロキシネットワーク経由でルーティングします。これは、あなたのマシン上ではなく、リモートのインフラストラクチャ上で行われます。
- サイトがJavaScriptを必要とする場合、リクエストは管理されたブラウザ内で実行されます。レンダリングされたページはデータ抽出前に処理されます。
- 失敗したリクエストは、プロバイダー定義のロジックに基づいて再試行されます。
- CAPTCHAの判定は実行レイヤー内で検出・解決されます。
- 抽出されたデータはレスポンスとして受け取ります。
クラウドスクレイピングの仕組みを簡略化した概要は以下の通りです: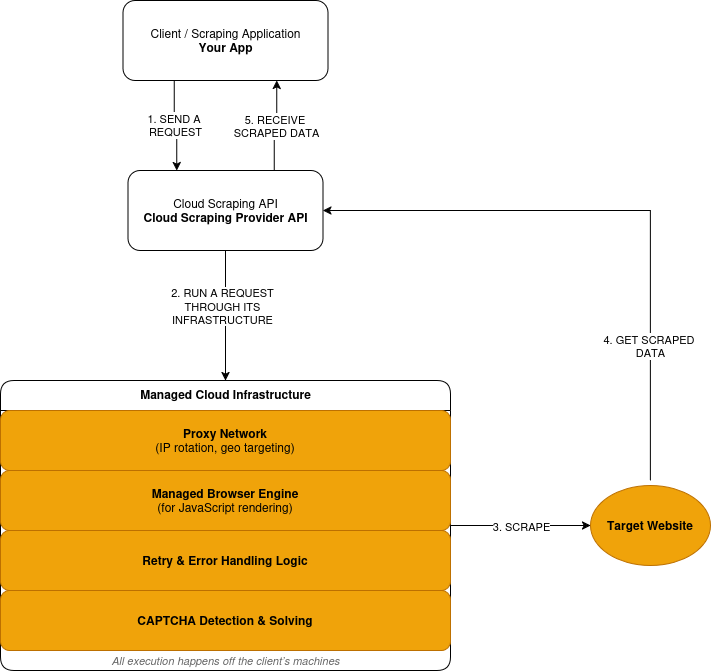
クラウドスクレイピングの利点
クラウドスクレイピングは、拡張性、信頼性、運用負担の軽減に優れています:
- 管理された実行:リクエストはプロバイダーが運用するインフラ上で実行されます。
- 組み込みのスケーラビリティ:サーバーを購入せずにボリュームを増加可能
- 統合型ボット対策:IPローテーションと再試行が自動実行されます。
- ブラウザインフラを含む:スクレイピングプロバイダーがJavaScriptレンダリングを処理。
- メンテナンス範囲の縮小:サイト変更時に再デプロイが不要。
- 使用量ベースの費用:リクエスト量に基づく課金体系。
クラウドスクレイピングのトレードオフ
クラウドスクレイピングは運用責任を軽減する一方で、外部依存性を導入します。一部の制御がアプリケーション境界の外に移行します。
- 低レベル制御の減少:タイミング、IP選択、再試行はプロバイダーのロジックに従います。
- サードパーティ依存性:可用性と実行は自社システム外に存在します。
- 使用量に応じたコスト増加:高ボリュームは支出を増加させる。
- 外部デバッグ:障害発生時にはプロバイダーの可視性とサポートが必要となる。
- コンプライアンス制約:管理環境外へのデータ流出が不可能なケースあり。
例:Bright Data Web Unlockerによる高ボリュームウェブスクレイピング
これはクラウドベースの実行レイヤーを介して実行される同一のスクラッピングタスクです。
import requests
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer API_KEY',
}
payload = {
'ゾーン': 'web_unlocker1',
'url': 'https://example.com/products',
'format': 'json'
}
response = requests.post('https://api.brightdata.com/request', json=payload, headers=headers)
print(response.json())一見すると、これはローカルスクレイピングの例と似ています。依然として単一のHTTPリクエストです。違いはリクエストが実行される場所です。
Bright DataWeb Unlocker APIでは、リクエストは管理されたインフラ上で実行されます。IPローテーション、ブロック検出、再試行はアプリケーションの外側で処理されます。
クラウドスクレイピング vs ローカルスクレイピング:直接比較
プロジェクトに実際に影響を与える要素について、ローカルスクレイピングとクラウドスクレイピングを比較します。
| 要素 | ローカルスクレイピング | クラウドスクレイピング | Bright Dataの優位性 |
|---|---|---|---|
| インフラストラクチャ | DIY設定 | 完全管理型 | 195カ国に広がるグローバルネットワーク |
| 拡張性 | 限定的 | 自動スケーリング(月間数十億リクエスト対応) | 月間数十億リクエスト |
| IPブロック | 高リスク | 自動ローテーション | 1億5000万以上のレジデンシャルIP |
| メンテナンス | 手動 | プロバイダー管理 | 24時間365日監視 |
| コストモデル | 固定+隠れた費用 | 従量課金 | 最大70%のコスト削減 |
| ボット対策 | DIY | 組み込み | 99.9%のCAPTCHA成功率 |
| コンプライアンス | DIY | 異なる | SOC2、GDPR、CCPA |
コスト内訳:ローカル vs クラウドスクレイピング
ローカルスクレイピングは、運用に必要なすべての要素を考慮するまでは安価に見えます。最大のコストはサーバーではなく、機能開発ではなくスクレイピングの維持管理に追われるエンジニアです。
クラウドスクレイピングでは、これらのコストがリクエストごとの課金に移行します。
ローカルスクレイピングのコスト構成要素
ローカルスクレイピングには、時間の経過とともに蓄積する固定費があります。
- サーバー:仮想マシン、帯域幅、ストレージ。
- プロキシ: 住宅用またはモバイルIPのサブスクリプション。
- CAPTCHAの解決:サードパーティの解決サービス。
- 保守:修正や更新のためのエンジニアリング時間。
- ダウンタイム:障害時のデータ損失。
これらのコストはスクレイピングの有無にかかわらず発生します。
クラウドスクレイピングのコスト構成要素
クラウドスクレイピングは使用量に応じた変動料金制を採用。
- リクエスト:リクエスト単位またはページ単位の課金。
- レンダリング:JavaScript実行にはより高いコストがかかります。
- データ転送:帯域幅に基づく課金。
インフラストラクチャ、プロキシ、メンテナンスはすべて含まれます。
コスト比較
| コスト要因 | ローカルスクレイピング | クラウドスクレイピング | Bright Data |
|---|---|---|---|
| サーバー容量 | 固定月額費用 | 含まれる | 含まれる |
| プロキシインフラストラクチャ | 別途サブスクリプション | 含まれる | 1億5000万以上のIPプール |
| CAPTCHAの解決 | 別サービス | 含まれる | 含まれる |
| 保守作業 | 継続的なエンジニアリング時間 | プロバイダー管理 | ゼロメンテナンス |
| ダウンタイムの影響 | 自社チームで吸収 | プロバイダーによる軽減 | 99.9%稼働率SLA |
実世界のコスト例
保護されたサイトから月間50万ページをスクレイピングするワークロードを想定します。
ローカル環境の場合:
- サーバーと帯域幅: 月額300ドル
- レジデンシャルプロキシ: 月額1,250ドル
- CAPTCHAの解決: $150/月
- エンジニアリング保守: $3,000/月
- 合計: $4,700/月
クラウド設定:
- レンダリング付きリクエスト: $1,500/月
- データ転送: $50/月
- 合計: $1,550/月
この規模では、クラウド方式により月額コストが約70%削減されます。
損益分岐点
- 月間5,000ページ未満:ローカル環境が有利な場合が多い
- 5,000~10,000ページ:コストが収束
- 10,000ページ以上:クラウドが一般的に低コスト
この点を超えると、ローカルコストは直線的に増加します。クラウドコストは使用量に応じて予測可能な形で増加します。
ローカルスクレイピングの適切な使用タイミング
以下の条件がすべて当てはまる場合、ローカルスクレイピングが適切な選択となる:
- 1回の実行で1,000ページ未満をスクレイピングする場合
- 対象サイトにボット対策がほとんどない
- データが自社環境外に流出できない場合
- 手動でのメンテナンスを受け入れる場合
- スクレイピングが業務上必須ではない場合
これらの条件外では、コストとリスクが急速に増加します。
クラウドスクレイピングの利用適応条件
以下のいずれかに該当する場合、クラウドスクレイピングが適しています:
- 月間10,000ページを超えるボリューム
- サイトが強力なボット対策を導入している場合
- JavaScriptレンダリングが必要な場合
- データの継続的な更新が必要
- 実行制御よりも信頼性が重要である場合
この時点で、インフラストラクチャの所有は負担となります。
Bright Dataがクラウドスクレイピングを簡素化する方法
Bright Dataはスクレイピングの実行場所と、運用不要となるレイヤーを定義します。スクレイピングの実行・維持コストを押し上げるスクレイピングインフラを管理します:
- ネットワークアクセス: 管理プロキシインフラ経由のリクエストルーティング
- ブラウザ実行: JavaScript多用サイト向けリモートブラウザ
- ボット対策:IPローテーション、ブロック検知、再試行
- 障害処理:実行制御と再試行ロジック
- メンテナンス:サイトや防御策の変化に応じた継続的な更新
- セッションコントロール:リクエスト間でスティッキーセッションを維持
- 地理的精度:国、都市、通信事業者、ASNをターゲットに設定。
- フィンガープリント管理: ブラウザレベルのフィンガープリントによる検知を低減。
- トラフィック制御:負荷を安全にスロットリング、バースト、分散。
実行パスとツール
Bright Data は、お客様のニーズに応じて、このインフラストラクチャを個別のツールを通じて公開しています。
スクレイピングブラウザAPI
サイトが JavaScript レンダリングやユーザーのようなインタラクションを必要とする場合は、スクレイピングブラウザを使用します。既存のSeleniumまたはPlaywrightロジックは、ローカルインスタンスではなく Bright Data がホストするブラウザに対して実行されます。
Bright Dataはローカルブラウザクラスター、ライフサイクル管理、リソース調整を置き換えます。
Web Unlocker API
保護されたサイトでのHTTPベースのウェブスクレイピングにはWeb Unlockerをご利用ください。Bright Dataはリクエストを適応型プロキシインフラストラクチャ経由でルーティングし、組み込みのブロック処理を適用します。
これにより、プロキシの調達、IPのローテーション、コード内での再試行ロジックの記述が不要になります。
WebスクレイパーAPI(事前構築済みデータセット)
Amazon、Google、LinkedInなど標準化されたプラットフォームにはWeb Scraper APIをご利用ください。主要なECサイトやソーシャルメディアプラットフォーム向けに150以上の事前構築済みスクレイパーを提供します。
Bright Dataはブラウザ自動化やカスタムパーサーなしで構造化データを返します。これにより、一般的なデータソース向けのサイト固有スクレイパーのメンテナンスが不要になります。
スタックから消えるもの
Bright Data を利用すると、以下の運用が不要になります:
- プロキシプールやIPローテーションロジック
- ローカルまたは自己管理型ブラウザクラスター
- CAPTCHAの解決サービス
- カスタムリトライおよびブロック検出コード
- サイトや検知方法の変更に対する継続的な修正
これらの運用コストは、ローカル環境やDIYクラウド環境では急速に累積します。
Bright Dataと他のクラウドスクレイピングツールの比較
クラウドスクレイピングプラットフォームは互換性がありません。適切な選択は、スクレイピング量、対象サイトの保護レベル、運用可能なインフラ規模によって異なります。
直接比較
| プロバイダー | 規模 | IPプール | コンプライアンス | 最適用途 |
|---|---|---|---|---|
| Bright Data | エンタープライズ(数十億) | 1億5000万以上 | SOC2、GDPR、CCPA | 大規模生産 |
| ScrapingBee | 中小規模 | 限定的 | 部分的 | 簡易プロジェクト |
| Octoparse | GUIベース | 小規模プール | 限定的 | 非技術ユーザー |
Bright Dataの適応領域
Bright Dataは、スクレイピングが継続的かつ運用上重要なワークロードに適しています。
具体的には以下のケースが含まれます:
- 月間10,000ページを超えるボリューム
- 対象サイトが最新のボット対策を導入している場合
- JavaScriptレンダリングが必要な場合
- データが下流システムや分析に供給される場合
- スクレイピングの失敗がビジネスに影響を与える場合
このような場合、APIの簡便性よりもインフラストラクチャの所有権がコストとリスクを左右します。
他のツールで十分な場合
制約が少ない場合には、軽量なクラウドツールが有効である。
APIベースのサービスが適しているのは:
- 小規模または定期的なスクレイピング作業
- 保護が限定的なサイト
- 時折の失敗が許容されるワークロード
GUIベースのツールが適しているのは:
- 技術的知識のないユーザー
- 単発または手動のデータ収集
- 探索的またはアドホックなタスク
これらのツールは設定の手間を軽減しますが、大規模運用における制限を解消するものではありません。
選択方法
選択基準は前述のコストと使用頻度の閾値を反映します:
- スクレイピングが小規模、頻度が低い、または重要でない場合、よりシンプルなツールで十分であることが多い
- スクレイピングが継続的、保護対象、または業務上重要である場合、管理されたインフラストラクチャが重要となる
結論
学習目的ならローカルスクレイピングから始めましょう。自身のマシンでスクレイパーを実行することで、リクエスト処理・パース・障害対応の仕組みが理解できます。1,000ページ未満の小規模作業では、この手法で十分です。
規模や保護要件がコスト構造を変える段階でクラウドスクレイピングに移行する。月間10,000ページを超える場合、対象サイトが最新のボット対策を導入している場合、またはデータの継続的更新が必要な場合、インフラの所有権が制約要因となる。
ローカルスクレイピングは制御と責任を伴う。クラウドスクレイピングは制御の一部を犠牲にする代わりに、予測可能な実行、低い運用リスク、スケーラブルなコストを実現する。
本番環境ではクラウドスクレイピングはインフラです。大規模なCDNやメールサーバーを自社で運用しないのと同様、スクレイピングインフラも同様の論理に従います。
このプロファイルに該当する場合、Bright Dataのようなプラットフォームを利用すれば、抽出ロジックは自社で保持しつつ、実行と保守を自社スタックから外すことが可能です。
よくある質問:クラウドスクレイピング vs ローカルスクレイピング
ローカルスクレイピングとは?
ローカルスクレイピングは自らが管理するマシン上で実行されます。リクエスト、プロキシ、ブラウザ、再試行、障害対応を自ら管理します。保護が緩いサイトでの小規模・低頻度のジョブに最適です。
クラウドスクレイピングとは?
クラウドスクレイピングは、サードパーティが運営するインフラ上で実行されます。APIにリクエストを送信すると、抽出されたデータが応答として返されます。スクレイピングプロバイダーが、実行、スケーリング、IPローテーション、CAPTCHAの解決、ボット対策の回避など、多くの処理を担当します。
ローカルスクレイピングからクラウドスクレイピングに切り替えるべきタイミングは?
以下のいずれかに該当する場合に切り替えを検討してください:
- ・限定されたリクエスト量後にIPブロックが発生した場合
- CAPTCHAが自動化を妨げる場合
- 月間10,000ページを超えるボリューム
- JavaScriptのレンダリングが必要になった場合
- スクレイピングの失敗が下流システムに影響する場合
その時点で、インフラの所有は負担となります。
クラウドスクレイピングはローカルスクレイピングより高コストか?
ローカル環境ではサーバー、プロキシ、メンテナンス、ダウンタイムのコストが累積します。クラウド料金は使用量に応じてスケーリングされ、固定インフラコストが排除されます。
- 小規模ではローカルスクレイピングの方が安価な場合が多い
- 大規模では、クラウドスクレイピングの方が一般的にコストが低い
JavaScriptを多用するサイトはクラウドスクレイピングで処理できますか?
はい。クラウドプラットフォームは管理されたブラウザを運用し、JavaScriptをリモートで実行します。
ローカルスクレイピングではヘッドレスブラウザを自身で実行する必要があり、これが同時実行数を制限し、メンテナンス負荷を増大させます。
クラウドスクレイピングはどのようにIPブロックを軽減するのか?
クラウドプロバイダーは大規模なプロキシネットワークを運用し、リクエストルーティングを管理します。IPローテーションと再試行ロジックはインフラストラクチャレベルで実行されます。
機密データや規制対象データのスクレイピングにクラウドスクレイピングは適していますか?
必ずしもそうとは限りません。ポリシーや規制により、管理された環境から離れることができないワークロードもあります。ただし、Bright DataはSOC2、GDPR、CCPAに完全に準拠したスクレイピングソリューションを提供しています。
ローカルとクラウドスクレイピングを併用できますか?
可能です。ただし複雑性は増します。
開発チームによっては、スクレイパーの開発・テストをローカル環境で行い、本番ワークロードをクラウドで実行する場合があります。この場合、2つの実行環境を維持し、それらの差異を管理する必要があります。
多くのチームは主要な制約に基づいて1つのアプローチを選択します。
Bright Dataのようなクラウドスクレイピングプラットフォームから最も恩恵を受けるチームは?
スクレイピングを継続的またはビジネスクリティカルなシステムとして運用するチームです。これには、高ボリューム、保護対象サイト、JavaScriptレンダリング、または帯域幅が限られているワークロードが含まれます。