

なぜザランドから商品詳細データをスクレイピングするのか?
ザランドは欧州で最も人気のあるオンライン衣料品小売プラットフォームの一つです。5,000万人以上のアクティブユーザーを擁し、欧州を代表するファッションECサイトです。確立されたブランドから新進デザイナーまで、靴・衣類・アクセサリーを含む膨大な商品を提供しています。
ザランドから商品詳細データをスクレイピングする主な理由は以下の3点です:
- 市場調査:最新のファッショントレンドに関する貴重な知見を得られます。この情報は、企業が情報に基づいた意思決定を行い、競争力を維持し、顧客の需要に効果的に応えるための商品提供を調整するのに役立ちます。
- 価格監視:価格変動を追跡し、お得な情報を活用するとともに市場を分析します。
- ブランド人気度:ザランドで人気の商品に注目し、顧客の間で現在どのブランドが支持されているかを把握して戦略を分析する。
要するに、ザランドのスクレイピングは可能性の世界を開き、企業とユーザー双方にとって有益です。
ザランドスクレイピング用ライブラリとツール
数あるスクレイピングツールの中からザランドに最適なものを選ぶには、まずブラウザでサイトを開きます。DOMを検査し、生のソースコードと比較してください。DOM構造がサーバーが生成するHTML文書とわずかに異なることに気付くでしょう。これはサイトがレンダリングにJavaScriptに依存していることを意味します。動的コンテンツサイトをスクレイピングするには、SeleniumのようなJavaScriptを実行できるツールが必要です!
次にプログラミング言語の選択です。ウェブスクレイピングにおいて最も人気があるのはPythonです。その簡潔な構文と豊富なライブラリエコシステムは、私たちの目的に最適です。ではPythonを使用しましょう
始める前に、以下の2つのガイドを確認してください:
- Pythonによるウェブスクレイピング – ステップバイステップガイド
- Pythonで動的ウェブサイトをスクレイピング
Seleniumは制御可能なウェブブラウザでサイトをレンダリングし、特定の操作を実行するよう指示できます。PythonでSeleniumを使用すれば、効果的なZalandoスクレイパーを構築可能です。さっそく見ていきましょう!
SeleniumでZalandoの商品データをスクレイピング
このステップバイステップチュートリアルに従い、PythonでZalandoスクレイパーを作成する方法を学びましょう。
ステップ1: Pythonプロジェクトの設定
ウェブスクレイピングを始める前に、以下の前提条件を満たしていることを確認してください:
- Python 3+ がマシンにインストールされていること:インストーラーをダウンロードし、ダブルクリックしてインストールウィザードに従ってください。
- お好みのPython IDE:PyCharm Community Editionまたは Python拡張機能付きのVisual Studio Codeが利用可能です。
これでPythonプロジェクトを設定し、コードを書くために必要な環境が整いました!
ターミナルを起動し、以下のコマンドを実行して:
- zalando-スクレイパーフォルダを作成します。
- そのフォルダに移動します。
- Python仮想環境で初期化します。
mkdir zalando-scraper
cd zalando-scraper
python -m venv envLinuxまたはmacOSでは、以下のコマンドを実行して環境を有効化します:
./env/bin/activateWindowsの場合は以下を実行:envScriptsactivate.ps1
次に、プロジェクトフォルダ内に scraper.py ファイルを作成し、以下の行を追加します:
print("Hello, World!")これは最も簡単なPythonスクリプトです。現時点では「Hello, World!」と表示するだけですが、すぐにザランドのスクレイピングロジックが含まれるようになります。
動作確認のため、以下のコマンドで実行します:
python スクレイパー.pyターミナルに次のメッセージが表示されるはずです:
Hello, World!スクリプトが期待通りに動作することを確認したら、Python IDEでプロジェクトフォルダを開いてください。
素晴らしい!スクレイパーの最初のコードを書く準備ができました。
ステップ2: スクラッピングライブラリのインストール
前述の通り、Zalandoスクレイパー構築にはSeleniumを採用します。アクティブなPython仮想環境で以下のコマンドを実行し、プロジェクトの依存関係に追加してください:
pip install seleniumインストールには時間がかかる場合がありますので、しばらくお待ちください。
本チュートリアルでは自動ドライバー検出機能を備えたSelenium 4.13.xを前提としています。お使いのマシンに古いバージョンのSeleniumがインストールされている場合は、以下で更新してください:
pip install selenium -Uscraper.py の内容をすべて削除し、以下のコマンドで Selenium スクレイパーを初期化します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 制御可能なChromeインスタンスを設定
service = Service()
options = webdriver.ChromeOptions()
# ブラウザオプション...
driver = webdriver.Chrome(
service=service,
options=options
)
# レスポンシブレンダリングを回避するためウィンドウを最大化
driver.maximize_window()
# スクラッピングロジック...
# ブラウザを閉じリソースを解放
driver.quit()上記スクリプトはSeleniumをインポートし、WebDriverオブジェクトをインスタンス化します。これによりChromeブラウザインスタンスをプログラムで制御できます。
デフォルトではブラウザウィンドウが開かれ、ページ上での操作を監視できます。これは開発時に有用です。
GUIなしのヘッドレスモードでChromeを開くには、以下のオプションを設定します:
options.add_argument('--headless=new')
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')追加のuser-agentオプションは必須です。Zalandoはヘッダーなしのヘッドレスブラウザからのリクエストをブロックするためです。この設定は本番環境でより一般的です。
素晴らしい!さあ、Zalando用Pythonウェブスクレイパーを構築しましょう。
ステップ3: 対象ページを開く
このガイドでは、Zalando UKの靴商品から詳細データをスクレイピングする方法を説明します。異なる商品タイプをターゲットにする場合、作成するスクリプトに若干の変更が必要です。理由は、各商品が異なる情報を持つ固有のページ構造を持つ可能性があるためです。
執筆時点での対象ページの外観は以下の通りです:
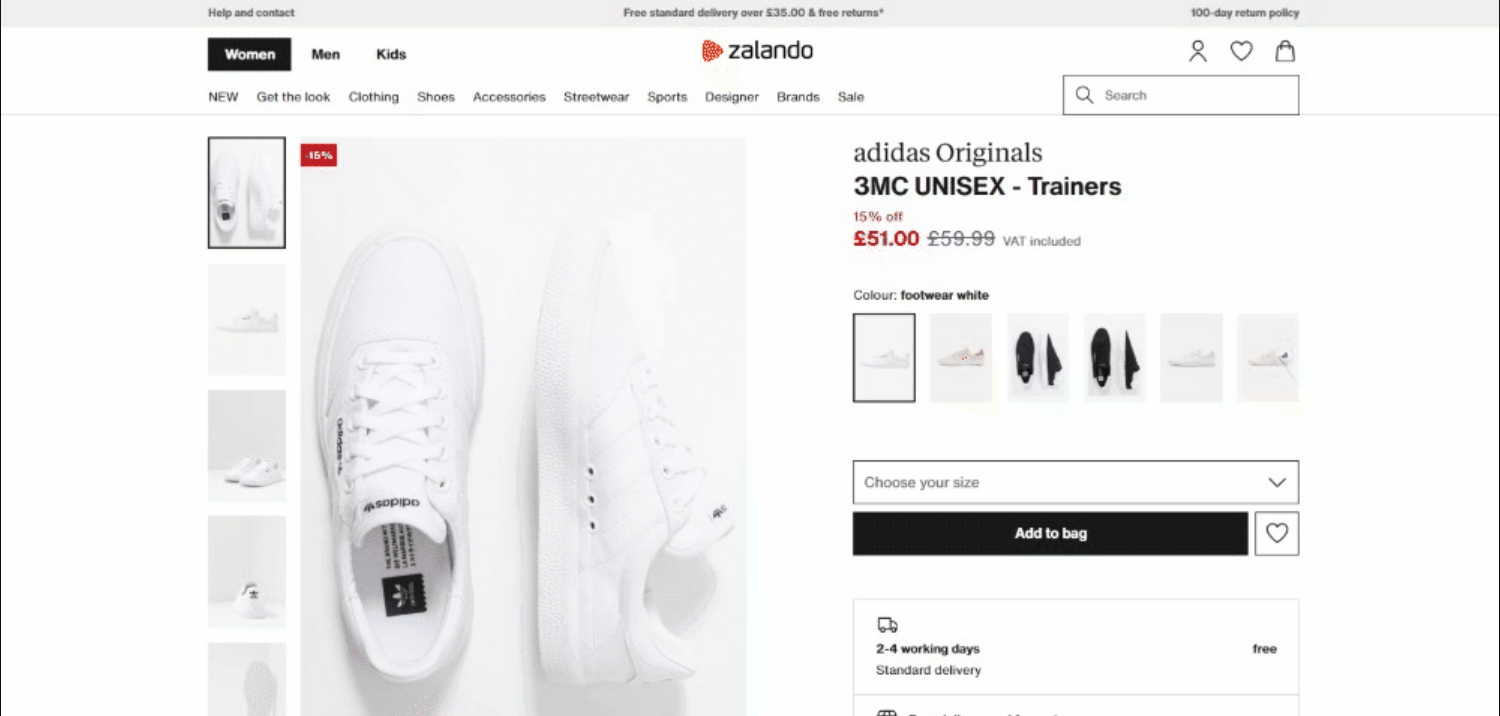
詳細なターゲットページのURLは以下の通りです:
Seleniumで対象ページに接続するには以下を実行:
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')get() は、パラメータとして渡された URL で指定されたページをブラウザに訪問するよう指示します。
これまでに作成したザランドのスクレイピングスクリプトは以下の通りです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service()
# Chromeインスタンスの設定
options = webdriver.ChromeOptions()
# ブラウザオプション...
driver = webdriver.Chrome(
service=service,
options=options
)
# レスポンシブ表示を回避するためウィンドウを最大化
driver.maximize_window()
# 制御下にあるブラウザでターゲットページを訪問
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# スクラッピングロジック...
# ブラウザを閉じてリソースを解放
driver.quit()アプリケーションを実行します。終了する前に1秒未満の間、以下のウィンドウが開きます:
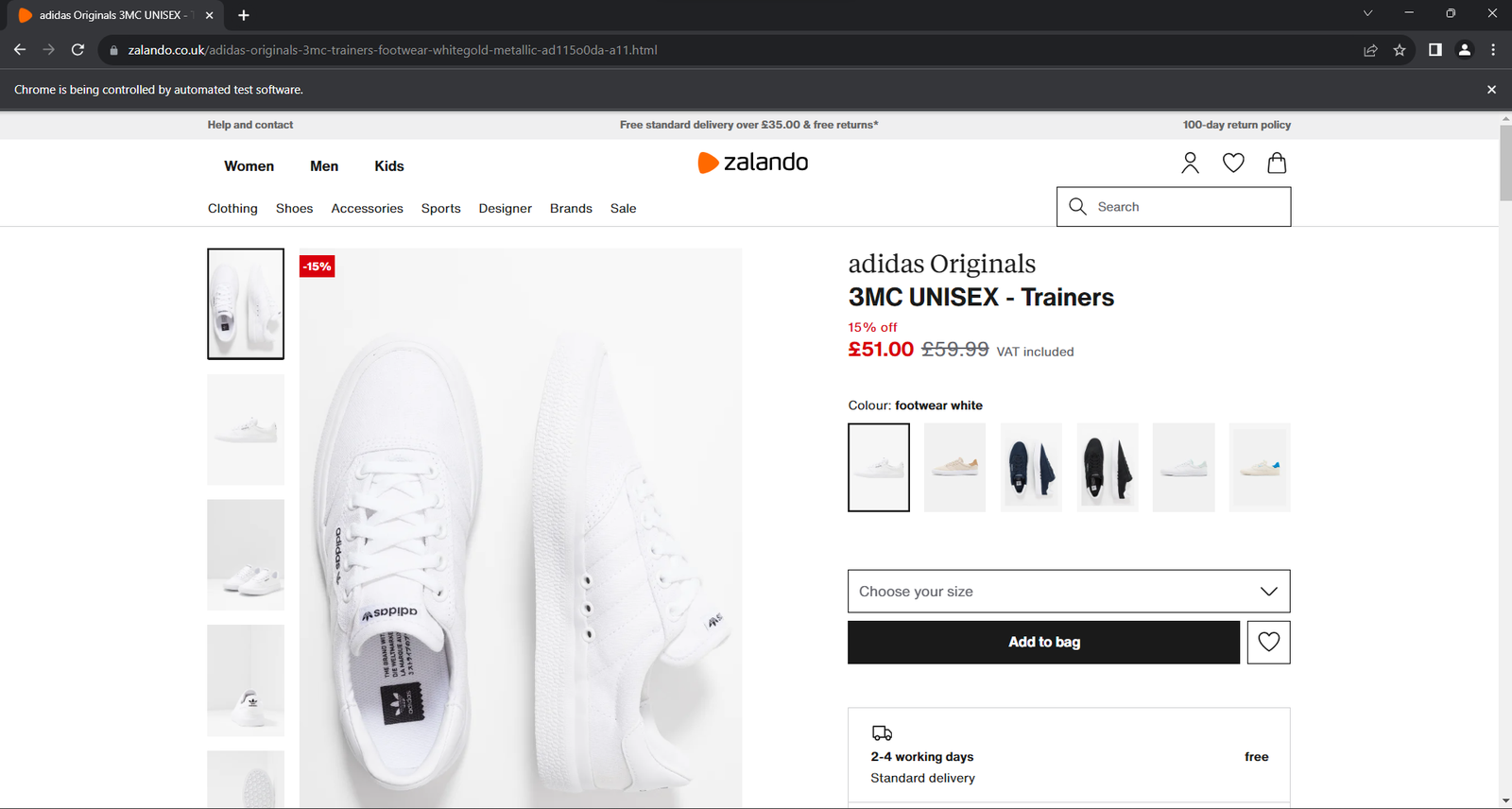
「Chromeは自動化されたソフトウェアによって制御されています」という免責事項は、Seleniumが正常に動作していることを保証します。
ステップ4: ページ構造の理解
効果的なスクレイピングロジックを書くには、対象ページのDOM構造を研究する時間が必要です。これにより、HTML要素の選択方法やデータ抽出方法を理解できます。
ブラウザをシークレットモードで開き、選択した Zalando商品ページにアクセスします。右クリックして「要素を検査」を選択し、ブラウザのDevToolsを開きます:
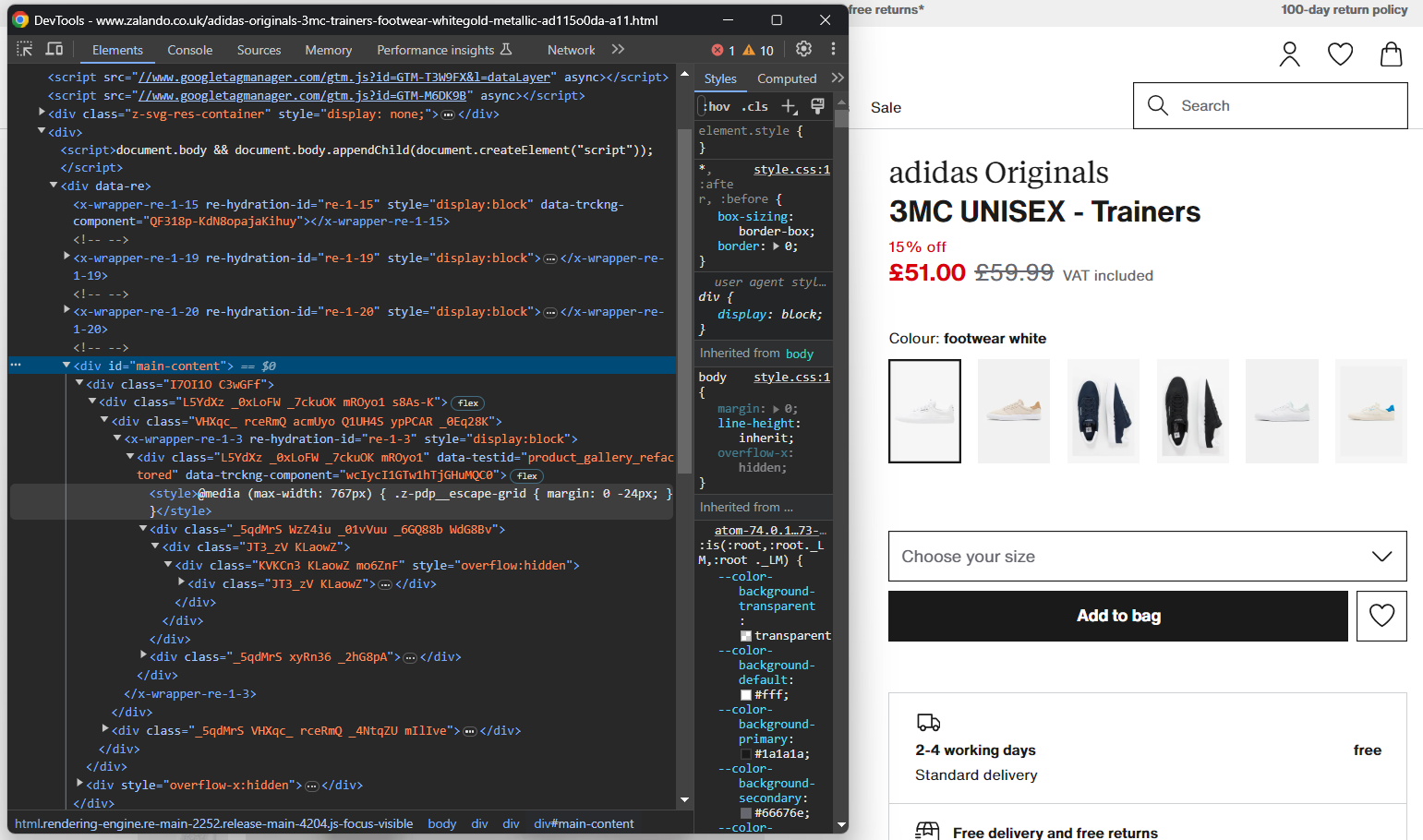
ここで、ほとんどのCSSクラスがビルド時にランダムに生成されていることに気づくでしょう。つまり、デプロイごとに変更されるため、選択戦略の基盤とすべきではありません。一方で、data-testidのような珍しいHTML属性を有する要素も存在します。これは効果的なセレクタ定義に役立ちます。
ページを操作し、アコーディオンなどの特定要素をクリックした後のDOM変化を分析してください。ユーザー操作に基づいてDOMに動的に追加されるデータが存在することに気付くでしょう。
次のステップに進む準備が整うまで、対象ページを継続的に調査し、そのHTML構造に慣れ親しんでください。
ステップ5: 製品データの抽出を開始
まず、スクレイピングしたデータを管理するためのデータ構造を初期化します。Pythonの辞書が最適です:
product = {}ページ上の要素を選択し、そこからデータを抽出しましょう!
靴のブランド名を含むHTML要素を調査します:
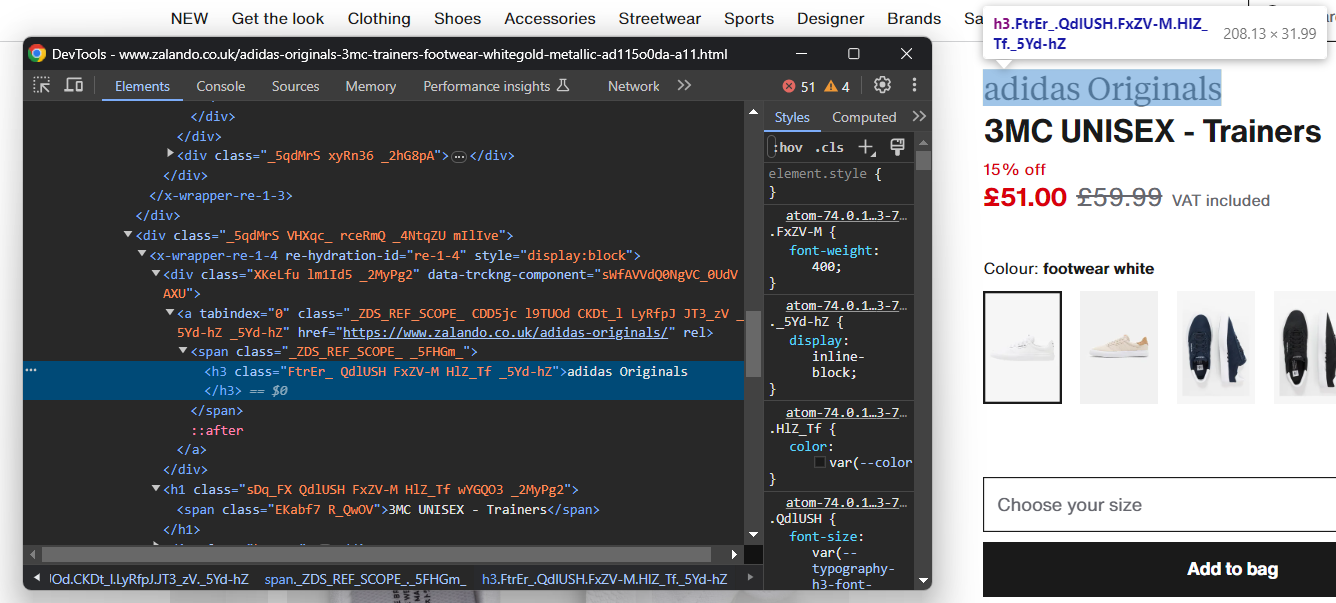
ブランド名は<h3>タグ、製品名は<h1>タグで囲まれていることに注意してください。以下のコードでデータをスクレイピングします:
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.textfind_element()は、パラメータとして渡された選択戦略に一致する最初の要素を返す Selenium のメソッドです。特に By.CSS_SELECTOR は、CSS セレクタ戦略を使用するようドライバーに指示します。Selenium は以下もサポートしています:
- By.TAG_NAME: HTMLタグに基づいて要素を検索します。
- By.XPATH: XPath式による要素検索。
同様に、選択クエリに一致する全ノードのリストを返す find_elements() も存在します。
By のインポートを忘れないでください:
from selenium.webdriver.common.by import ByHTML要素が与えられた場合、text属性でそのテキストコンテンツにアクセスできます。必要に応じてPythonのreplace()メソッドを使用してテキスト文字列をクリーンアップしてください。
価格情報の抽出はやや複雑です。下の画像からわかるように、これらの要素を選択する簡単な方法はありません:
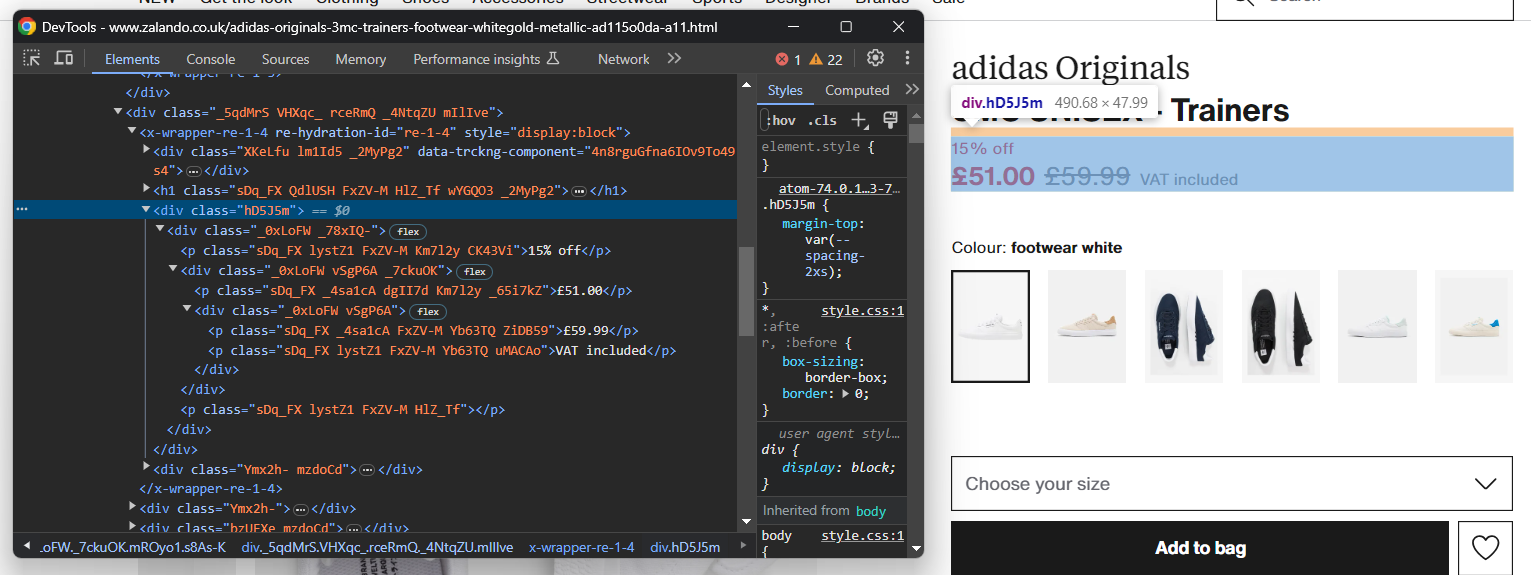
実行可能な方法は次の通りです:
- 価格の<div>要素を、<h1>名要素の最初の兄弟要素としてアクセスします。
- その内部にある全ての<p>ノードを取得する。
以下の方法で実現します:
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")Seleniumはノードの兄弟要素にアクセスするユーティリティメソッドを提供していないことに留意してください。そのため代わりにfollowing-sibling::*XPath式を使用する必要があります。
商品価格データは以下で取得できます:
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
discount = price_elements[0].text.replace(' off', '')
price = price_elements[1].text
original_price = price_elements[2].text次に商品画像ギャラリーに焦点を当てます:
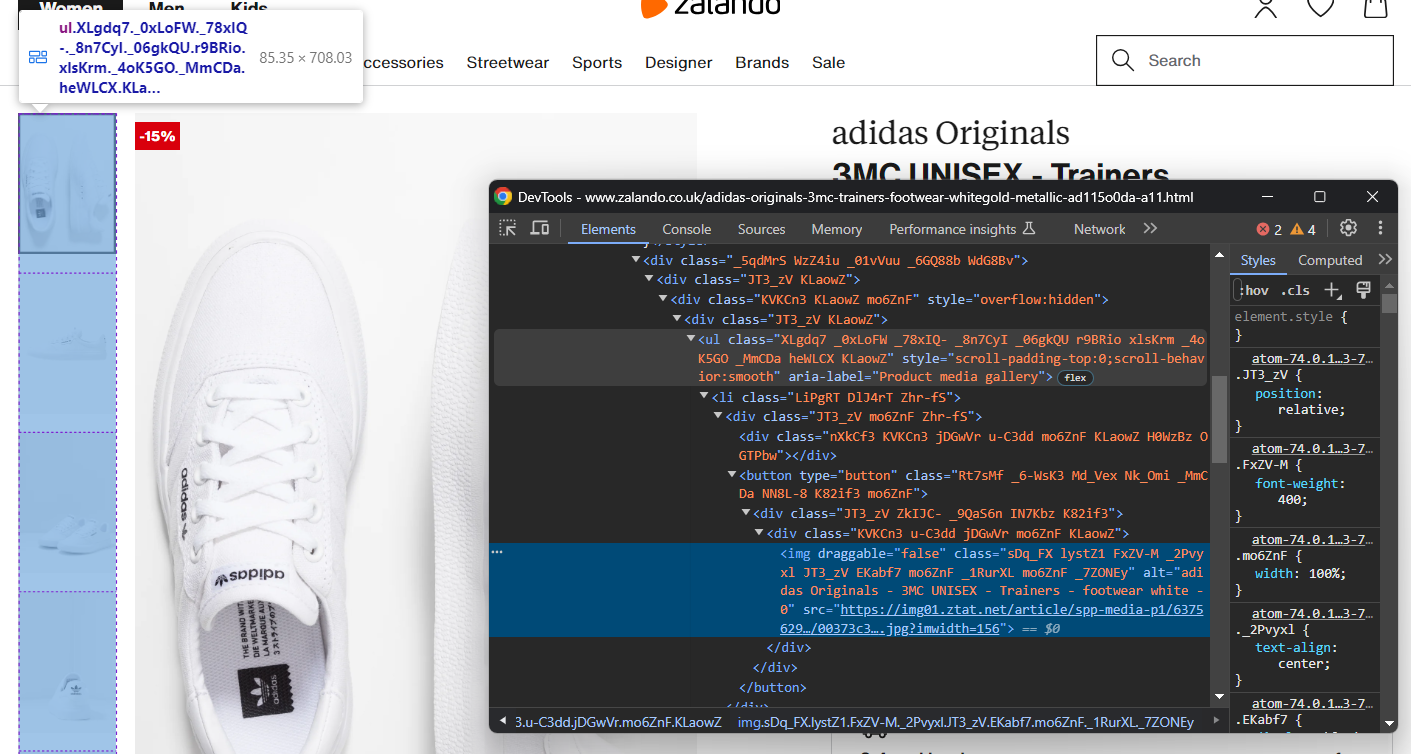
複数の画像が含まれるため、それらを格納する配列を初期化します:
images = []ここでも<img>要素の選択は容易ではありませんが、「Product media gallery」<ul>内の<li>要素をターゲットにすることで実現できます:
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)同様に、靴のカラーオプションを収集できます:
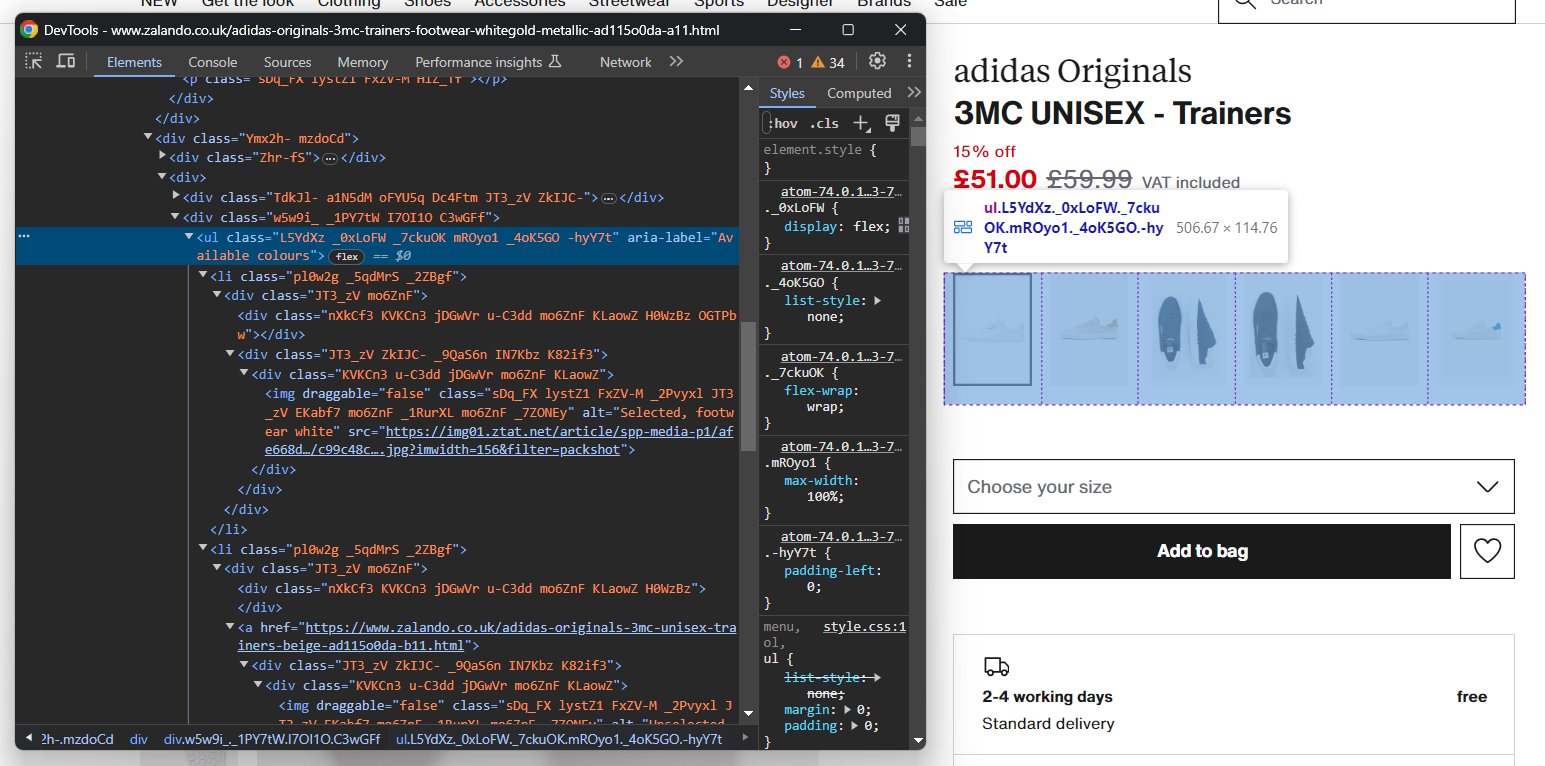
以前と同様に、各カラー要素は<li>です。詳細には、各カラーセクションには以下が含まれます:
- オプションのリンク。
- 画像。
- 画像要素のalt属性に格納された名前。
すべての色を抽出するには:
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
# 新しいカラーオブジェクトを初期化
color = {
'color': None,
'image': None,
'link': None
}
# 色リンクの存在を確認しURLを抽出
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
# 色画像が存在するか確認し、データを取得
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)完璧です!スクレイピングロジックの実装が完了しましたが、取得すべきデータはまだあります。
ステップ6: 商品詳細データをスクレイピング
商品詳細は、カラー選択要素の下に配置されたカード内に保存されています:
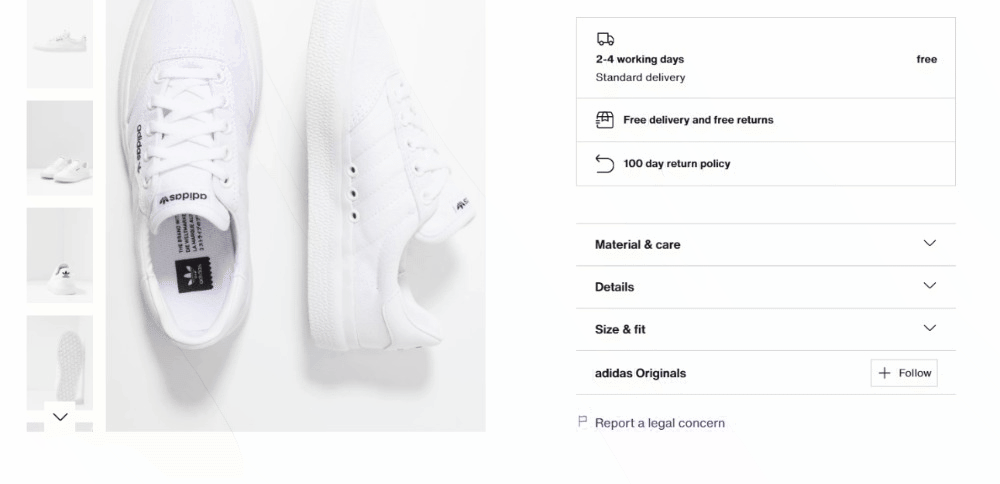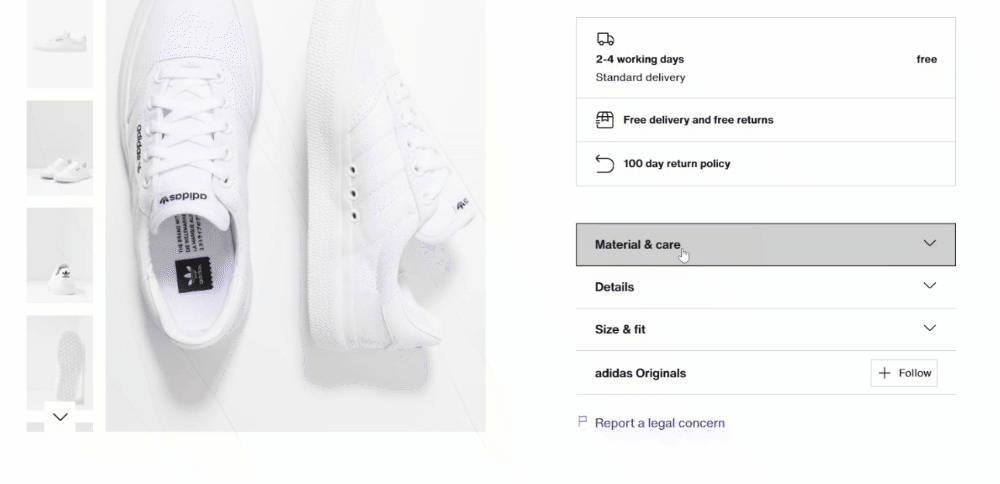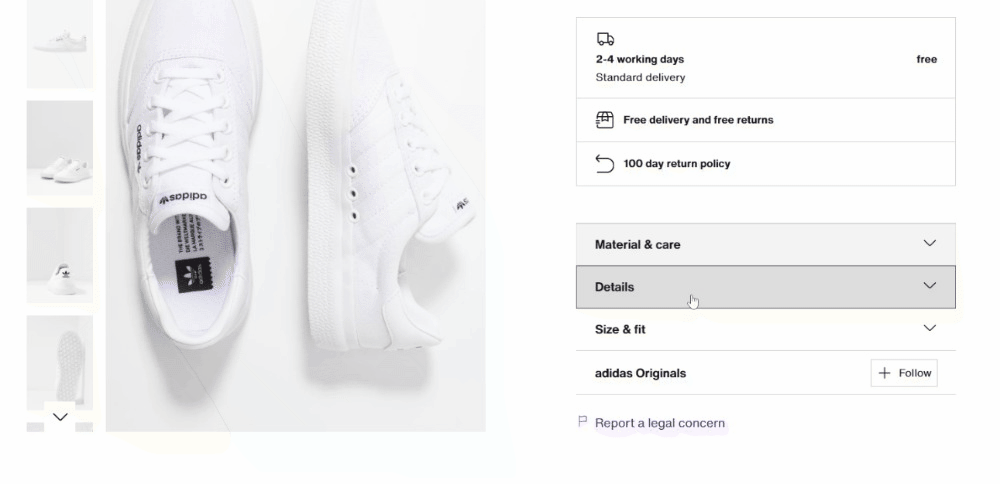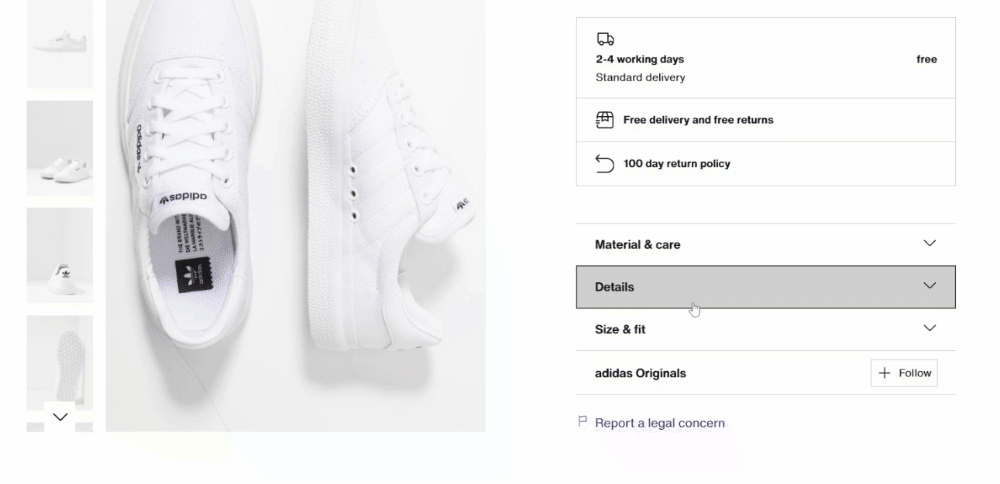
まず配送情報に注目します:
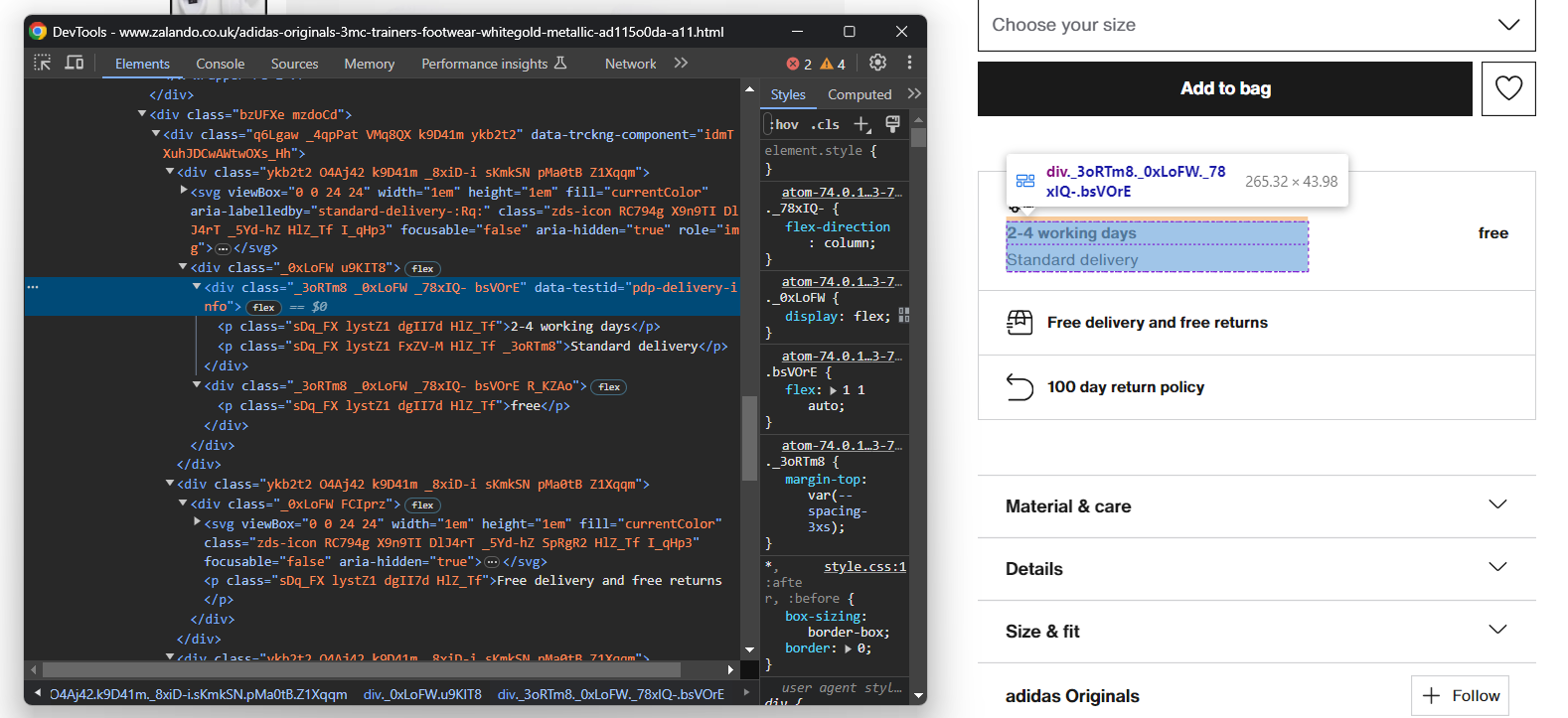
これは3つのデータフィールドで構成されるため、配送辞書を以下のように初期化します:
delivery = {
'time': None,
'type': None,
'cost': None,
}これら3つの要素を選択する簡単なセレクタは存在しません。以下の方法が有効です:
- data-testid属性が”pdp-delivery-info”のノードを選択します。
- その親要素に移動します。
- すべての子孫<p>要素を取得する。
このロジックを実装し、配送データを以下のように抽出します:
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].textSeleniumではノードの親要素にアクセスする方法が提供されていないため、parent::* XPath式を使用する必要があります。
次に、商品詳細アコーディオンに焦点を当てます:
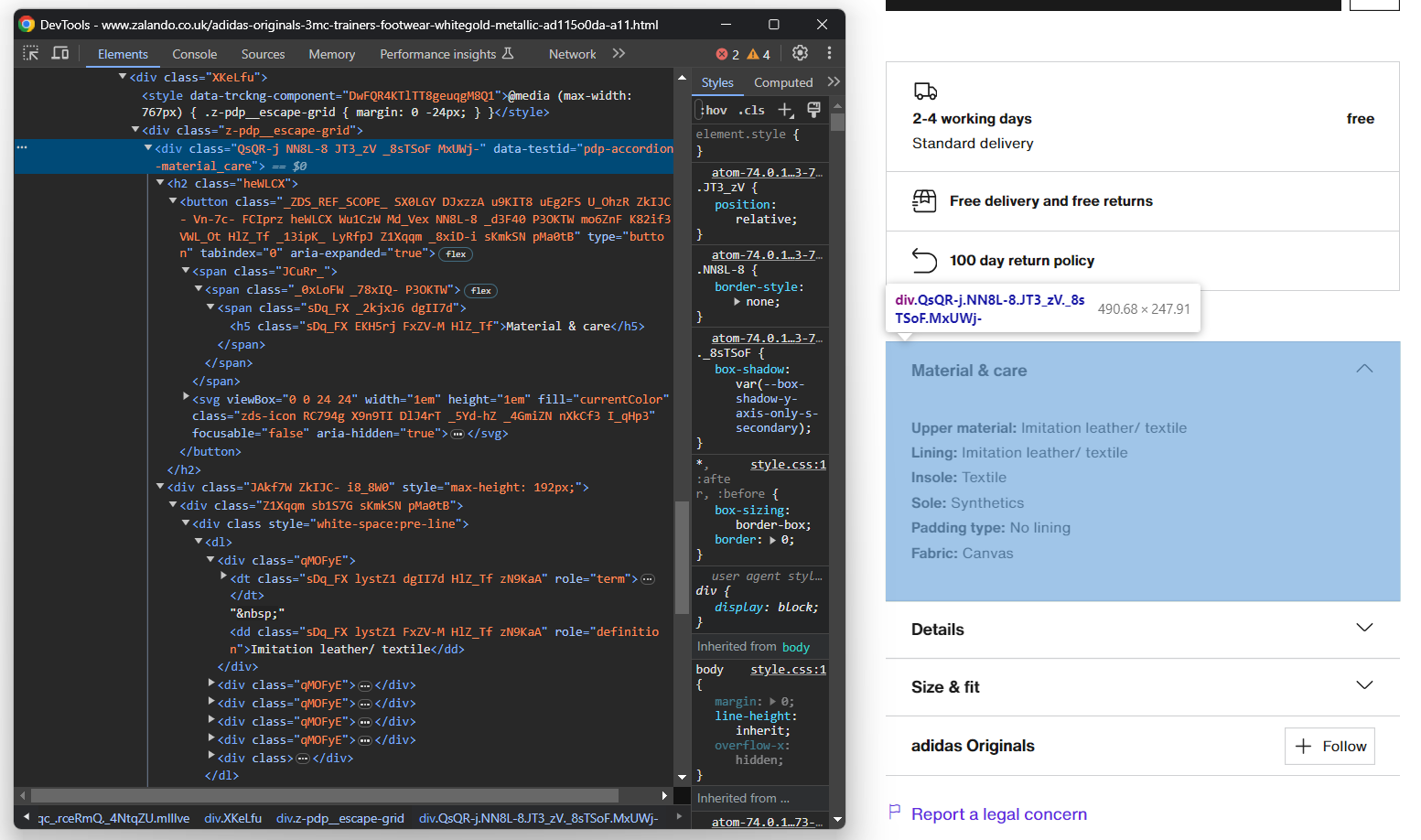
今回は、data-testid属性が「pdp-accordion-」で始まるノードをターゲットにすることで、すべてのアコーディオン要素を取得できます。以下のCSSセレクターを使用します:
[data-testid^="pdp-accordion-"]このセクションには複数のフィールドが含まれるため、追跡用の辞書を作成する必要があります:
info = {}次に、前述のCSSセレクタを適用して商品詳細アコーディオンを選択します:
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]「サイズとフィット」要素には関連データが含まれていないため無視できます。[:2]によりリストを最初の2要素に絞り込みます。
これらのHTML要素は動的に生成され、開かれた際にのみDOMにコンテンツが追加されます。そのため、click()メソッドでクリック操作をシミュレートする必要があります:
for info_element in info_elements:
info_element.click()
// スクラッピングロジック...
次に、プログラムで info オブジェクトを以下のように設定します:
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text上記のロジックは、アコーディオン内の情報を動的に抽出し、名前ごとに整理します。
このコードの動作を理解するには、infoを出力してみてください。以下のように表示されます:
{'素材とケア': {'アッパー素材': '合成皮革/テキスタイル', 'ライニング': '合成皮革/テキスタイル', 'インソール': 'テキスタイル', 'ソール': '合成素材', 'パッドタイプ': '裏地なし', '生地': 'キャンバス'}, 'Details': {'Shoe tip': 'Round', 'Heel type': 'Flat', 'Fastening': 'Laces', 'Shoe fastener': 'Laces', 'Pattern': 'Plain', 'Article number': 'AD115O0DA-A11'}}素晴らしい!ザランドの製品詳細をスクレイピングしました!
ステップ7: 製品オブジェクトへのデータ投入
スクレイピングしたデータで製品辞書に値を代入するだけです:
# スクレイピングしたデータを辞書に代入
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = infoZalandoスクレイパーが期待通りに動作していることを確認するためのログ出力も追加できます:
print(job)
スクリプトを実行:
python スクレイパー.py出力例:
{'brand': 'adidas Originals', 'name': '3MC UNISEX - Trainers', 'price': '£51.00', 'original_price': '£59.99', 'discount': '15%', ... }さあ、これでザランドから商品データをスクレイピングする方法がわかりました。
ステップ8: スクレイピングしたデータをJSONにエクスポート
現在、スクレイピングしたデータはPythonの辞書に格納されています。共有や読み取りを容易にするため、JSON形式でエクスポートします:
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)上記のスニペットはopen()でproduct.json出力ファイルを作成し、json.dump()でJSONデータを出力します。PythonでのJSONデータパース・シリアライズの詳細はガイドを参照してください。
jsonのインポートを忘れずに追加してください:
import jsonこのパッケージはPython標準ライブラリに含まれるため、手動でインストールする必要はありません。
素晴らしい!ウェブページに含まれる生の製品データから始まり、半構造化JSONデータを得ました。これで完全なZalandoスクレイパーを確認する準備が整いました。
ステップ8: 全てを統合する
以下が scraper.py ファイルの完全なコードです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
service = Service()
# Chromeインスタンスの設定
options = webdriver.ChromeOptions()
# ブラウザオプション...
driver = webdriver.Chrome(
service=service,
options=options)
# レスポンシブレンダリングを回避するためウィンドウを最大化
driver.maximize_window()
# 制御下にあるブラウザで対象ページにアクセス
driver.get('https://www.zalando.co.uk/adidas-originals-3mc-trainers-footwear-whitegold-metallic-ad115o0da-a11.html')
# スクレイピングデータを格納するオブジェクトをインスタンス化
product = {}
# スクレイピングロジック
brand_element = driver.find_element(By.CSS_SELECTOR, 'h3')
brand = brand_element.text
name_element = driver.find_element(By.CSS_SELECTOR, 'h1')
name = name_element.text
price_elements = name_element
.find_element(By.XPATH, 'following-sibling::*[1]')
.find_elements(By.TAG_NAME, "p")
discount = None
price = None
original_price = None
if len(price_elements) >= 3:
割引 = 価格要素[0].text.replace(' off', '')
価格 = 価格要素[1].text
元価格 = 価格要素[2].text
画像 = []
image_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Product media gallery"] li')
for image_element in image_elements:
image = image_element.find_element(By.TAG_NAME, 'img').get_attribute('src')
images.append(image)
colors = []
color_elements = driver.find_elements(By.CSS_SELECTOR, '[aria-label="Available colours"] li')
for color_element in color_elements:
color = {
'color': None,
'image': None,
'link': None
}
link_elements = color_element.find_elements(By.TAG_NAME, 'a')
if len(link_elements) > 0:
color['link'] = link_elements[0].get_attribute('href')
image_elements = color_element.find_elements(By.TAG_NAME, 'img')
if len(image_elements) > 0:
color['image'] = image_elements[0].get_attribute('src')
color['color'] = image_elements[0].get_attribute('alt')
.replace('Selected, ', '')
.replace('Unselected, ','')
.strip()
colors.append(color)
delivery = {
'time': None,
'type': None,
'cost': None,
}
delivery_elements = driver
.find_element(By.CSS_SELECTOR, '[data-testid="pdp-delivery-info"]')
.find_element(By.XPATH, 'parent::*[1]')
.find_elements(By.TAG_NAME, 'p')
if len(delivery_elements) == 3:
delivery['time'] = delivery_elements[0].text
delivery['type'] = delivery_elements[1].text
delivery['cost'] = delivery_elements[2].text
info = {}
info_elements = driver.find_elements(By.CSS_SELECTOR, '[data-testid^="pdp-accordion-"]')[:2]
for info_element in info_elements:
info_element.click()
info_section_name = info_element.find_element(By.CSS_SELECTOR, 'h5').text
info[info_section_name] = {}
for dt_element in info_element.find_elements(By.CSS_SELECTOR, 'dt'):
info_section_detail_name = dt_element.text.replace(':', '')
info[info_section_name][info_section_detail_name] = dt_element.find_element(By.XPATH, 'following-sibling::dd').text
# ブラウザを閉じてリソースを解放
driver.quit()
# スクレイピングしたデータを辞書に割り当て
product['brand'] = brand
product['name'] = name
product['price'] = price
product['original_price'] = original_price
product['discount'] = discount
product['images'] = images
product['colors'] = colors
product['delivery'] = delivery
product['info'] = info
print(product)
# スクレイピングしたデータをJSONファイルにエクスポート
with open('product.json', 'w', encoding='utf-8') as file:
json.dump(product, file, indent=4, ensure_ascii=False)わずか100行強のコードで、商品詳細データを取得する完全な機能を備えたザランドのウェブスクレイパーを構築しました。
実行するには:
python スクレイパー.pyスクリプトが完了するまで数秒待ちます。
スクレイピング処理が終了すると、プロジェクトのルートフォルダに product.json ファイルが生成されます。開くと以下のように表示されます:
{
"brand": "adidas Originals",
"name": "3MC UNISEX - Trainers",
"price": "£51.00",
"original_price": "£59.99",
"discount": "15%",
"images": [
"https://img01.ztat.net/article/spp-media-p1/637562911a7e36c28ce77c9db69b4cef/00373c35a7f94b4b84a4e070879289a2.jpg?imwidth=156",
// 簡略化のため省略...
"https://img01.ztat.net/article/spp-media-p1/7d4856f0e4803b759145755d10e8e6b6/521545d1286c478695901d26fcd9ed3a.jpg?imwidth=156"
],
"colors": [
{
"color": "footwear white",
"image": "https://img01.ztat.net/article/spp-media-p1/afe668d0109a3de0a5175a1b966bf0c9/c99c48c977ff429f8748f961446f79f5.jpg?imwidth=156&filter=packshot",
"link": null
},
// 簡略化のため省略...
{
"color": "white",
"image": "https://img01.ztat.net/article/spp-media-p1/87e6a1f18ce44e3cbd14da8f10f52dfd/bb1c3a8c409544a085c977d6b4bef937.jpg?imwidth=156&filter=packshot",
"link": "https://www.zalando.co.uk/adidas-originals-3mc-unisex-trainers-white-ad115o0da-a16.html"
}
],
"delivery": {
"time": "2-4営業日",
"type": "標準配送",
"cost": "無料"
},
"info": {
"素材とケア": {
"アッパー素材": "合成皮革/テキスタイル",
"ライニング": "合成皮革/テキスタイル",
"中敷き": "テキスタイル",
"ソール": "合成素材",
"パッドタイプ": "裏地なし",
"生地": "キャンバス"
},
"詳細": {
"トゥ形状": "ラウンド",
"ヒールタイプ": "フラット",
"留め具": "紐",
"靴の留め具": "紐",
"柄": "無地",
"商品番号": "AD115O0DA-A11"
}
}
}おめでとう!Pythonでザランドのスクレイピング方法を習得しました!
まとめ
このチュートリアルでは、ザランドがスクレイピングに適した優れたECサイトである理由と、そこからデータを抽出する方法を理解しました。ここでは、商品ページから自動的にデータを取得するザランドスクレイパーの構築方法を確認しました。
ここで示したように、ザランドのスクレイピングは少なくとも3つの理由から最も簡単な作業ではありません:
- サイトにはスクリプトをブロックする可能性のある反スクレイピング対策が実装されている。
- ウェブページにはランダムなCSSクラスが含まれています。
- 各商品ページは固有の構造を持ち、異なる情報が含まれる場合があります。
最初の問題を回避し、ブロックされる心配をなくすには、当社の新ソリューションをお試しください!スクレイピングブラウザは制御可能なブラウザであり、CAPTCHA、フィンガープリンティング、自動リトライなどを自動的に処理します。ただし、コードの記述とメンテナンスは引き続き必要です。残りの2つの問題については、すぐに使えるソリューションで解決しましょう。当社のザランドスクレイパーをご覧ください!
注:本ガイドは執筆時点で当社チームにより徹底的にテストされていますが、ウェブサイトはコードや構造を頻繁に更新するため、一部の手順が期待通りに機能しなくなる可能性があります。




