

従来のウェブスクレイピングでは、特定のウェブサイトレイアウトに合わせた複雑で時間のかかるコードを記述する必要があり、サイト変更時に容易に機能しなくなる可能性があります。ScrapeGraphAIは大規模言語モデル(LLM)を活用し、人間のように情報を抽出して解釈するため、レイアウトではなくデータに集中できます。LLMをScrapeGraphAIに統合することで、データ抽出が強化され、コンテンツ集約が自動化され、リアルタイム分析が可能になります。
本記事ではScrapeGraphAIを用いたウェブスクレイピング手法を解説します。その前に、時間とコストを節約できるBright Dataのソリューションをご紹介します。
Bright Dataのウェブスクレイピングソリューション
Bright Dataは、効率的・拡張性・コンプライアンスに最適化された包括的なウェブスクレイピングソリューションを提供します:
- Web Scraper API
- すぐに使えるデータセット
- カスタムデータセット
これらのソリューションにより、小規模なアプリケーションから企業レベルのニーズまで、あらゆる規模のプロジェクトに最適な、高速・正確・スケーラブルなデータ収集を実現します。
ScrapeGraphAIによるLLMウェブスクレイピングの実装
このチュートリアルを始める前に、以下の前提条件が必要です:
- Python 3.x がインストールされていること。
- OpenAIアカウント。このチュートリアルでは、ScrapeGraphAIによるデータスクレイピングにOpenAIのLLMを使用します。Anthropic、Google、またはLlamaや Mistral AIなどのオープンソースモデルなど、他のモデルを使用することも可能ですが、このチュートリアルでは、その人気と設定の容易さからGPT-4を使用します。
Pythonでのウェブスクレイピングに慣れていない場合は、こちらのウェブスクレイピングチュートリアルを参照して始めましょう。
環境設定
まず最初に仮想環境を作成します。ターミナルを開き、プロジェクトディレクトリに移動してください:
python -m venv venv
次に仮想環境をアクティブ化します。macOSとLinuxでは以下のコマンドで実行できます:
source venv/bin/activate
Windowsでは次のコマンドを使用します:
venvScriptsactivate
仮想環境をアクティブ化したら、ScrapeGraphAIとその依存関係をインストールします:
pip install scrapegraphai
playwright install
playwright install コマンドは、Chromium、Firefox、WebKit 用の必要なブラウザを設定します。
環境変数を安全に管理するには、python-dotenvをインストールします:
pip install python-dotenv
APIキーなどの機密情報を保護することが重要です。環境変数はコードファイルとは別に.envファイルに保存することを推奨します。
プロジェクトディレクトリに.env という名前の新規ファイルを作成し、OpenAI キーを指定する以下の行を追加します:
OPENAI_API_KEY="your-openai-api-key"
このファイルはGitなどのバージョン管理システムにコミットしないでください。.gitignoreファイルに.envを追加してこれを防止します。
ScrapeGraphAIでデータをスクレイピング
このチュートリアルでは、ウェブスクレイピング技術を練習するためのデモサイト「Books to Scrape」から製品データをスクレイピングすることから始めます。このサイトはオンライン書店を模倣しており、様々なジャンルの書籍を価格、評価、在庫状況とともに提供しています:
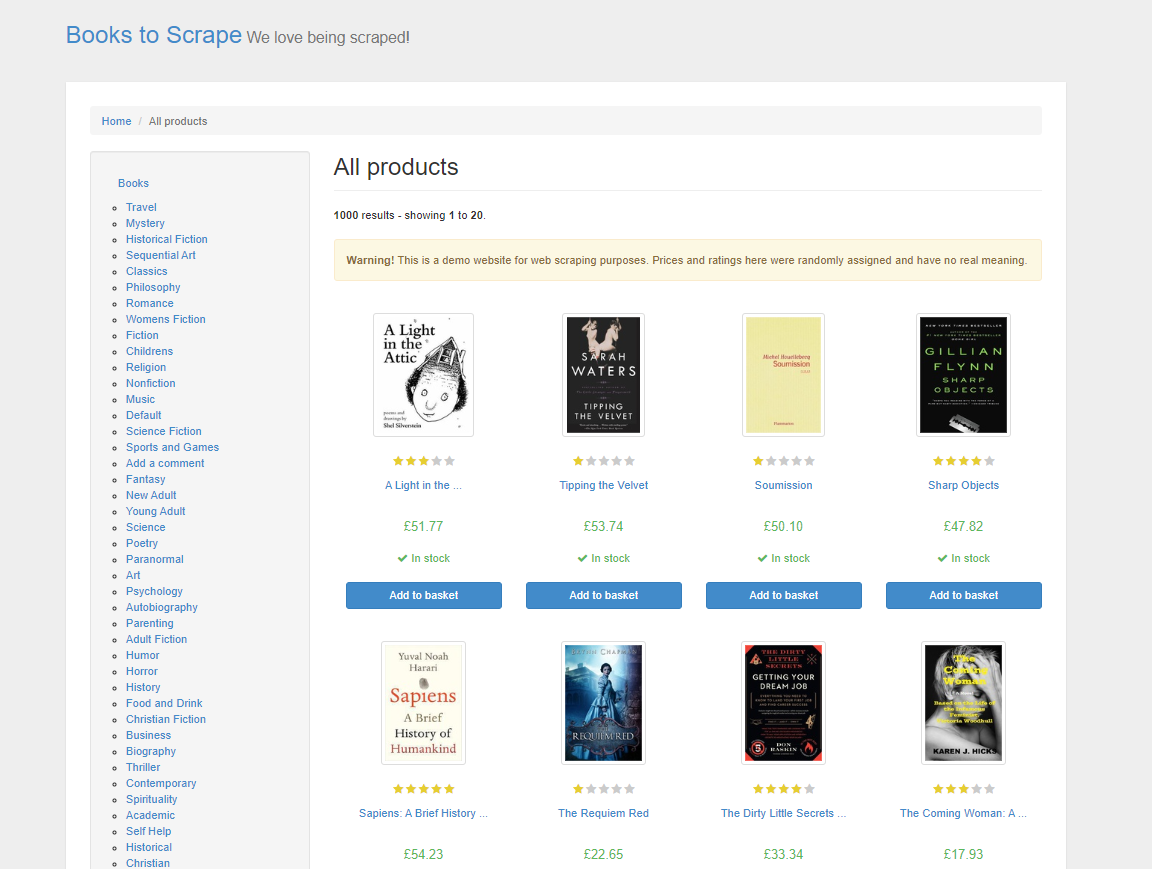
従来のHTMLウェブスクレイピングでは、ページのHTMLを解析し、目的のデータを特定するために要素やタグを手動で確認する必要がありました。このプロセスは時間がかかり、ウェブ構造の深い理解が求められます。ScrapeGraphAIでは、プロンプトを使用して必要なデータを指定するだけで、LLMがインテリジェントにデータを抽出します。
ScrapeGraphAIは、異なるスクレイピングニーズに対応する複数のグラフタイプを提供します。これらのグラフはスクレイピングプロセスの構造と目的を定義します。主なグラフの概要は以下の通りです:
- SmartScraperGraphは単一ページスクレイパーです。プロンプトとURLまたはローカルファイルを指定すると、LLMが指定した情報を抽出します。
- SearchGraphは複数ページ対応のスクレイパーで、プロンプトに基づいて検索エンジンの結果から情報を抽出します。
- SpeechGraphはSmartScraperGraphを拡張し、テキスト読み上げ機能を追加。抽出内容の音声ファイルを生成します。
- ScriptCreatorGraphはプロンプトとURLを受け取り、結果を生成する代わりに、指定されたURLをスクレイピング可能なPythonスクリプトを出力します。
これらのグラフがニーズに完全に合致しない場合、ScrapeGraphAIでは異なるノードを組み合わせ、特定の要件に合わせてスクレイピングプロセスを調整することでカスタムグラフを作成することも可能です。
適切なグラフタイプを選択すると同時に、スクレイパーの設定(特にプロンプトとモデルの選択)も重要です。プロンプトはLLMが抽出すべきデータを正確に理解するための指針となるため、明確かつ明示的に記述してください。さらに、適切なLLMモデルの選択は、スクレイパーがウェブサイトのコンテンツを処理・解釈する精度を決定します。 地理的制限のあるコンテンツのスムーズなスクレイピングを確保するためのプロキシ設定や、処理の効率性と高速性を維持するヘッドレスモードなど、その他のオプションも設定可能です。適切な設定が、最終的にスクレイピングデータの精度と関連性を決定します。
スクレイパーコードの記述
スクレイパーコードを作成するには、app.py という名前の新規ファイルを作成し、以下のコードを追加します:
from dotenv import load_dotenv
import os
from scrapegraphai.graphs import SmartScraperGraph
# .envファイルから環境変数をロード
load_dotenv()
# OpenAI APIキーにアクセス
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# ScrapeGraphAIの設定
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
}
}
# プロンプトとソースを定義
prompt = "Extract the title, price and availability of all books on this page."
source = "http://books.toscrape.com/"
# スクレイパーグラフの作成
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=source,
config=graph_config)
# スクレイパーの実行
result = smart_scraper_graph.run()
# 結果の出力
print(result)
このコードは、環境変数処理のための osやdotenvといった必須モジュール、およびスクレイピングに使用するScrapeGraphAIのSmartScraperGraphクラスをインポートします。その後、APIキーなどの機密データを保護するため、dotenv経由で環境変数をロードします。 次に、使用するモデルとAPIキーを指定したスクレイピング用のLLM設定を作成します。この設定は、サイトURLやスクレイピングプロンプトと共にSmartScraperGraphを定義するために使用され、run()メソッドで実行されることで指定されたデータの収集プロセスが開始されます。
このコードを実行するには、ターミナルを開き `python app.py` を実行します。出力は以下のような形式になります:
{
"books": [
{
"title": "A Light in the Attic",
"price": "£51.77",
"availability": "In stock"
},
{
"title": "Tipping the Velvet",
"price": "£53.74",
"availability": "In stock"
}, ...
]
}
注意: コードの実行中に問題が発生した場合、ScrapeGraphAI の基盤依存関係である
grpcioパッケージを手動でインストールする必要があるかもしれません。以下のコマンドでインストールできます:
pip install grpcio
ScrapeGraphAIはウェブスクレイピングのデータ抽出部分を容易にしますが、CAPTCHAやIPブロックなど、対処方法を知る必要がある一般的な課題が依然として存在します。
ブラウジング動作を模倣するには、コード内に時間遅延を実装できます。検出回避のためローテーションプロキシの利用も有効です。さらに、Bright DataのCAPTCHAソルバーやAnti CaptchaなどのCAPTCHAの解決サービスをスクレイパーに統合すれば、自動解決が可能です。
ご注意:常にウェブサイトの利用規約を遵守してください。個人利用目的のスクラッピングは許容される場合が多いですが、データの再配布は法的リスクを伴う可能性があります。
ScrapeGraphAIでのプロキシ利用
ScrapeGraphAIでは、IPブロック回避や地域制限コンテンツへのアクセスを可能にするプロキシサービスを設定できます。無料プロキシサービスの利用や、独自のカスタムプロキシサーバーの設定が可能です。
無料プロキシサービスを利用するには、graph_configに以下を追加してください:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"プロキシ": {
"server": "broker",
"criteria": {
"anonymous": True,
"secure": True,
"countryset": {"US"},
"timeout": 10.0,
"max_tries": 3
},
},
}
}
この設定により、ScrapeGraphAIは指定した条件に合致する無料プロキシサービスを使用します。
Bright Dataなどのプロバイダーのカスタムプロキシサーバーを使用するには、以下の通りgraph_configを変更し、サーバーURL、ユーザー名、パスワードを挿入してください:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"プロキシ": {
"server": "http://your_プロキシ_サーバー:ポート",
"username": "your_username",
"password": "your_password",
},
}
}
カスタムプロキシサーバーの使用には、特に大規模なウェブスクレイピングにおいていくつかの利点があります。プロキシの場所を制御できるため、地理的制限のあるコンテンツをスクレイピングできます。さらに、カスタムプロキシは無料プロキシと比較して信頼性とセキュリティが高く、IPブロックやレート制限を受ける可能性を低減します。
データのクリーニングと前処理
データをスクレイピングした後、特にAIモデルに投入する予定がある場合は、データのクリーニングと前処理が必要です。クリーンなデータは、モデルが正確で一貫した情報から学習することを保証し、モデルの性能と信頼性に直接影響します。データクリーニングには通常、欠損値の処理、データ型の修正、テキストの正規化、重複データの削除が含まれます。
pandasを使用して先にスクレイピングしたデータをクリーニングする例を以下に示します:
import pandas as pd
# 結果をDataFrameに変換
df = pd.DataFrame(result["books"])
# 通貨記号を除去し価格をfloatに変換
df['price'] = df['price'].str.replace('£', '').astype(float)
# 在庫状況テキストの正規化
df['availability'] = df['availability'].str.strip().str.lower()
# 欠損値の処理(存在する場合)
df.dropna(inplace=True)
# クリーニング済みデータのプレビュー
print(df.head())
このコードは、書籍価格から通貨記号を削除し、在庫状況を小文字に変換して標準化し、欠損値を処理することでデータをクリーニングします。
コードを実行する前に、データ操作用のpandasライブラリをインストールする必要があります:
pip install pandas
コードを実行するには、ターミナルを開き `python app.py` を実行します。出力は次のようになります:
title price availability
0 A Light in the Attic 51.77 in stock
1 Tipping the Velvet 53.74 in stock
2 Soumission 50.10 in stock
3 Sharp Objects 47.82 in stock
4 Sapiens: A Brief History of Humankind 54.23 in stock
これはスクレイピングしたデータをクリーニングする方法の一例に過ぎません。クリーニングプロセスは、データやトレーニング対象のLLMユースケースによって異なります。データをクリーニングすることで、言語モデルが構造化され意味のある入力を受け取れるようになります。AIのためのデータ活用の詳細については、Data for AIをご検討ください。
このチュートリアルの全コードは、こちらのGitHubリポジトリで公開されています。
結論
ScrapeGraphAIはLLMを活用し、ウェブスクレイピングに適応型アプローチを提供します。ウェブサイトの構造変化に対応し、データをインテリジェントに抽出します。ただし、ウェブスクレイピングの拡張には課題が伴います。IPブロック対策、CAPTCHAの解決、法的コンプライアンスの維持などです。
これらの課題を克服するため、Bright DataはAIおよび機械学習プロジェクト向けにカスタマイズされた包括的なウェブスクレイピングソリューションを提供しています。これにはBright Data Web Scraper API、プロキシサービス、Serverless Scrapingが含まれます。さらにBright Dataは、100以上の人気ウェブサイトからのデータで構成されたすぐに使えるデータセットも提供しています。
今すぐ無料トライアルを開始しましょう!





