

この記事では、以下のことを学びます:
- Apache Spark Structured Streamingとは何か、そしてそれが何を提供するのか。
- Bright DataのSERP APIをSpark Structured Streamingパイプラインに統合することが、なぜ有効な戦略となるのか。
- Bright DataのSERP APIを使用して、ライブのウェブ検索データを継続的に取り込むPySparkパイプラインの構築方法。
さっそく始めましょう!
Apache Spark Structured Streamingとは?
Apache Spark Structured Streaming は、Spark SQL エンジンを基盤として構築された、スケーラブルでフォールトトレラントなストリーム処理エンジンです。従来の Spark Streaming ライブラリ(DStreams を使用してデータを個別の RDD ベースのマイクロバッチに分割する)とは異なり、Structured Streaming はライブデータストリームを、継続的にデータが追加される境界のないテーブルとして扱います。 静的なバッチジョブで書くのと同じDataFrameやSQL APIのコードを記述するだけで、新しいデータが到着するたびにSparkがそれを増分的に実行します。
このエンジンは、デフォルトでマイクロバッチ実行モデルで動作します。各トリガー間隔ごとに、Sparkはソースから最新のデータを読み込み、処理を行い、結果をシンクに書き込みます。チェックポイント機能によって進行状況を追跡するため、パイプラインは障害から回復し、中断した箇所から正確に再開することができ、エンドツーエンドの耐障害性を保証します。
Structured Streamingは、Kafkaトピック、Deltaテーブル、Auto Loader経由のクラウドオブジェクトストレージ、レートジェネレーター(テスト用)など、さまざまな組み込みソースをサポートしています。ネイティブにサポートされていないソース(REST APIなど)については、foreachBatch拡張メソッドを使用できます。このメソッドは各マイクロバッチをPython関数に渡し、そこで任意の取り込みロジックを記述できます。ここではこのアプローチを採用します。
Spark Streaming 対 Spark Structured Streaming:違いは何ですか?
従来のSpark Streamingライブラリに馴染みのある方なら、それがStructured Streamingとどのように関連しているのか疑問に思うかもしれません。両者は基盤となるSparkエンジンを共有していますが、重要な点で異なります:
Spark StreamingはDStreamsに基づいています。これは、入力ストリームを時間制限のあるバッチに分割することで生成されるRDDのシーケンスです。すべての変換はRDDに対して行われるため、より低レベルのAPIで作業することになります。イベントタイムセマンティクス(つまり、データが取り込まれた時刻ではなく、生成された時刻順にデータを並べ替えること)へのサポートは限定的であり、現在は開発が継続されていません。
Spark Structured StreamingはDataFrameおよびDataset APIを基盤としており、Spark SQLの最適化機能をフルに活用できます。 ネイティブなイベントタイム・ウィンドウ処理、遅延データの処理のためのウォーターマーク、ステートフル集計、およびチェックポイントによるより洗練されたフォールトトレランスモデルを提供します。バッチDataFrameと同じAPIを使用するため、同じジョブ内でストリーミングデータと静的データを混在させることができます(例:静的ルックアップテーブルを用いたストリーミング結合)。
要するに、Spark Streamingは下位互換性を維持するために残されたレガシープロジェクトであるのに対し、Structured Streamingは、すべての新しいストリーミングワークロード向けに推奨され、現在も活発に開発されているエンジンです。
なぜBright DataのSERP APIをSpark Structured Streamingに統合するのか?
Spark Structured Streamingは、大規模なデータ変換や集計を行うための強力なエンジンを提供しますが、処理の対象となる信頼性の高い構造化されたライブWebデータソースが必要です。そこでBright DataのSERP APIが役立ちます。
SERP APIを使用すると、主要な検索エンジン(Google、Bing、DuckDuckGo、Yandexなど)に対してプログラムからクエリを発行し、ブロックされることなく完全な検索エンジン結果ページ(SERP)を取得できます。 結果は、パース済みJSON、上位のオーガニック検索結果のみを含む軽量なparsed_light形式、生のHTML、またはAI処理に適したクリーンなMarkdownなど、複数の形式で返されます。ボット対策、レート制限、動的レンダリングなどの理由から、検索エンジンを直接スクレイピングすることは極めて困難ですが、Bright Dataのインフラストラクチャを経由してクエリを送信することで、パイプラインからそれらの複雑さをすべて排除できます。
これをSpark Structured Streamingのマイクロバッチエンジンと組み合わせることで、プロキシやCAPTCHA、スクレイピングインフラの管理を必要とせずに、最新のSERPデータを定期的に取得し、大規模な変換や集計を適用し、構造化された結果を任意のシンクに書き込む、継続的に稼働するパイプラインを構築できます。
このアプローチは、特に次のような場合に有用です:
- 特定のターゲットキーワード群が各検索エンジンでどのようにランク付けされているかを定期的に監視し、結果をデルタテーブルに書き込み、経時的な順位変動を算出する。
- 競合他社のブランド名や製品に関するSERPを継続的に取得し、構造化された結果をパースして、ダッシュボード作成のためにデータウェアハウスへストリーミングする。
- 複数のトピックにわたるGoogleニュースの検索結果を並列マイクロバッチでポーリングし、Sparkの状態保持型集計を使用して記事を重複排除し、選別された結果をデータレイクに送信する。
- SERPの結果を継続的に取り込み、ターゲットキーワードに対して有料広告が表示されたタイミングを検知し、広告文とURLをキャプチャして、下流システムにアラートを送信します。
Spark Structured Streamingの分散型でスケーラブルな処理機能と、AIおよびデータパイプライン向けのBright DataのWebアクセスインフラストラクチャを組み合わせることで、独自のスクレイピングインフラを維持することなく、実世界の検索データに継続的に反応するパイプラインを構築できます。
Spark Structured Streaming を使用した継続的な SERP 取り込みパイプラインの構築方法
このガイドセクションでは、以下の機能を持つ PySpark パイプラインを構築します。
- Sparkの組み込みレートソースをクロックとして使用し、スケジュールに従ってトリガーされる。
- 各マイクロバッチの
foreachBatch関数内でBright DataのSERP APIを呼び出し、対象トピックに関する最新のGoogleニュース検索結果を取得します。 - 構造化されたJSONレスポンスをパースし、クリーンなSpark DataFrameに変換します。
- 結果をシンク(ローカルのJSON出力ディレクトリとコンソールの両方)に書き出し、リアルタイムデータを検査できるようにします。
注:この例はニュース監視のユースケースを示していますが、同じパターンは、キーワードの順位追跡、広告監視、Web検索による価格比較など、あらゆる継続的なSERP取り込みシナリオに適用できます。
前提条件
この手順を実行するには、以下の環境が整っていることを確認してください:
- Python 3.8以上がインストールされていること。
- Apache Spark 3.3以上がローカルにインストールされているか、Databricks / AWS EMR / Google Dataprocクラスターにアクセスできること。
- PySparkがインストールされていること:
pip install pyspark。 requestsライブラリがインストールされていること:pip install requests。- 有効な SERP API ゾーンと API キー(管理者権限付き)を持つ Bright Data アカウント。
Bright Dataの公式ドキュメントに従って、SERP APIゾーンを設定し、APIキーを取得してください。APIキーとゾーン名は安全な場所に保管してください。まもなく必要になります。
ステップ 1: プロジェクトの設定
新しいプロジェクトディレクトリを作成し、必要なファイルを設定します:
mkdir spark-serp-pipeline
cd spark-serp-pipeline
touch pipeline.py
touch config.py
mkdir -p output/checkpointconfig.pyを開き、Bright Data の認証情報と検索設定を追加します:
# config.py
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY"
SERP_API_ZONE = "YOUR_SERP_API_ZONE"
# 監視対象の検索クエリ(ユースケースに合わせてカスタマイズしてください)
SEARCH_QUERY = "artificial intelligence news"
# 新しいマイクロバッチをトリガーする間隔(秒単位)
TRIGGER_INTERVAL_SECONDS = 60
# JSON 結果の出力ディレクトリ
OUTPUT_PATH = "output/serp_results"
CHECKPOINT_PATH = "output/checkpoint"セキュリティ上のヒント:本番環境では、ソースファイルに認証情報をハードコーディングしないでください。環境変数、シークレットマネージャー(例:AWS Secrets Manager、Azure Key Vault、HashiCorp Vault)、またはDatabricks Secretsを使用して、実行時にこれらの値を注入してください。
ステップ 2: SparkSession の初期化
pipeline.pyを開き、SparkSession の作成から始めます。これがすべての Spark 機能へのエントリポイントです:
# pipeline.py
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType, StructField, StringType, IntegerType, ArrayType
)
from pyspark.sql import functions as F
import requests
import json
import config
# SparkSessionの初期化
spark = SparkSession.builder
.appName("BrightDataSERPStream")
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
# 出力を簡潔にするためログの詳細レベルを下げる
spark.sparkContext.setLogLevel("WARN")
print("SparkSessionが初期化されました。")spark.sql.shuffle.partitions を 4のような小さな数値に設定するのは、ローカル開発環境では適切です。クラスタ上では、データのサイズやエグゼキュータコアの数に基づいてこれを調整します。
ステップ 3: SERP API フェッチ関数の定義
次に、Bright DataのSERP APIを呼び出し、パース済みの結果を返すPython関数を定義します。この関数は、ドライバー上のSparkのforeachBatchコールバック内部から呼び出されるため、Sparkの分散メカニズムではなく、標準のrequestsライブラリを使用します:
# pipeline.py (続き)
def fetch_serp_results(query: str) -> list[dict]:
"""
Bright DataのSERP APIを呼び出し、パースされたニュース結果のリストを返します。
軽量で構造化された JSON 出力のため、parsed_light データ形式を使用します。
"""
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {config.BRIGHT_DATA_API_KEY}"
}
payload = {
"ゾーン": config.SERP_API_ゾーン,
"url": f"https://www.google.com/search?q={query}&tbm=nws&hl=en&gl=us",
"format": "raw",
"data_format": "parsed_light"
}
try:
response = requests.post(url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
data = response.json()
# parsed_light 形式では、結果オブジェクトの配列 "news" が返されます
results = data.get("news", [])
print(f"[SERP API] クエリ '{query}' に対して {len(results)} 件の結果を取得しました")
return results
except requests.exceptions.RequestException as e:
print(f"[SERP API] リクエストに失敗しました: {e}")
return []主要なリクエストパラメータを詳しく見ていきましょう:
zone: Bright Dataダッシュボードから取得したSERP APIのゾーン名。url: Google検索のURLです。tbm=nwsパラメータは検索結果をGoogleニュースに限定します。hl=enはインターフェース言語を英語に設定し、gl=usは地域ターゲティングの結果として米国を対象とします。format: レスポンス本文を直接取得するには「raw」に設定します。data_format:「parsed_light」に設定すると、広告やナレッジパネルを除いた、タイトル、URL、ソース、日付を含む上位のオーガニック検索結果およびニュース検索結果のクリーンなJSON配列を受け取れます。広告やナレッジパネルを含む完全なSERPデータが必要な場合は「parsed」を使用してください。LLM向けの出力には「markdown」を使用してください。
ステップ 4: レートジェネレーターを使用したストリーミングソースの構築
Spark Structured StreamingにはネイティブなHTTPソースがないため、定評のあるパターンを採用します。組み込みのレートソースをクロックとして機能させ、1秒ごと(または設定されたレートごと)に1行を生成します。レートソースによって生成される各マイクロバッチがforeachBatchコールバックをトリガーし、その内部でSERP APIを呼び出します。
pipeline.pyにレートストリームの定義を追加します:
# pipeline.py (続き)
rate_stream = spark.readStream
.format("rate")
.option("rowsPerSecond", 1)
.load()
print("レートストリームが作成されました。パイプラインはマイクロバッチ間隔ごとにトリガーされます。")レートソースは、このようなテストやクロック駆動型のシナリオ向けに明示的に設計されています。実際のAPIにはレート制限が適用されるため、ステップ5でトリガー間隔を設定し、パイプラインがSERP APIを1秒に1回ではなく、1分間に1回だけ呼び出すようにします。
ステップ5:foreachBatchハンドラの定義
foreachBatchハンドラは、パイプラインの中核となる部分です。Sparkはマイクロバッチごとにこの関数を呼び出し、そのバッチの行を含むDataFrameと一意のバッチIDを渡します。関数内では、SERP APIを呼び出し、結果をSpark DataFrameに変換し、変換を適用して、出力シンクに書き込みます:
# pipeline.py (続き)
# パースされたSERP結果のスキーマを定義
serp_schema = StructType([
StructField("title", StringType(), True),
StructField("link", StringType(), True),
StructField("source", StringType(), True),
StructField("date", StringType(), True),
StructField("global_rank", IntegerType(), True),
])
def process_batch(batch_df, batch_id):
"""
各マイクロバッチのトリガー時にSparkによって呼び出されます。
Bright DataからSERPデータを取得し、結果をDataFrameに変換して、
出力シンクに書き込みます。
"""
print(f"n--- バッチ {batch_id} の処理中 ---")
# Bright DataからライブSERP結果を取得
results = fetch_serp_results(config.SEARCH_QUERY)
if not results:
print(f"バッチ {batch_id}: 結果が返されませんでした。書き込みをスキップします。"
return
# 結果リストをSpark DataFrameに変換
results_df = spark.createDataFrame(results, schema=serp_schema)
# 追跡用のメタデータ列を追加
enriched_df = results_df
.withColumn("query", F.lit(config.SEARCH_QUERY))
.withColumn("batch_id", F.lit(batch_id))
.withColumn("ingested_at", F.current_timestamp())
# 可視化のためにコンソールに出力
enriched_df.show(truncate=False)
# JSON出力への書き込み(追加モード、取り込み日によるパーティション化)
enriched_df
.withColumn("ingestion_date", F.to_date("ingested_at"))
.write
.mode("append")
.partitionBy("ingestion_date")
.json(config.OUTPUT_PATH)
print(f"バッチ {batch_id}: {enriched_df.count()} 件のレコードを {config.OUTPUT_PATH} に書き込みました")この設計に関する注意点:
spark.createDataFrame(results, schema=serp_schema)は、SERP API から返される Python の辞書リストを、型付き Spark DataFrame に変換します。スキーマの推論よりも明示的なスキーマを指定する方が推奨されます。これにより、ジョブの処理が高速化され、結果の予測可能性が高まります。
F.lit(batch_id)は、各行に現在のマイクロバッチ ID を付加します。これは、パイプラインが失敗したバッチを再試行する場合の重複排除に役立ちます(foreachBatchはデフォルトで「少なくとも一度」の配信を保証するため)。
F.current_timestamp() は、各行にドライバー側の取り込み時刻をタイムスタンプとして付与し、各結果がいつパイプラインに入ったかに関する信頼性の高い監査証跡を提供します。
ステップ 6: ストリーミングクエリの開始
次に、foreachBatchハンドラーをレートストリームに接続し、クエリを開始して、すべてを連携させます:
# pipeline.py (続き)
# foreachBatch ハンドラを接続し、トリガー間隔を設定する
query = rate_stream.writeStream
.foreachBatch(process_batch)
.trigger(processingTime=f"{config.TRIGGER_INTERVAL_SECONDS} 秒")
.option("checkpointLocation", config.CHECKPOINT_PATH)
.start()
print(f"ストリーミングクエリが開始されました。{config.TRIGGER_INTERVAL_SECONDS} 秒ごとにトリガーされます。"
print("Ctrl+C を押して停止してください。"
# クエリが終了するのを待機します(中断されるまで無期限に実行されます)
query.awaitTermination().trigger(processingTime="60 seconds")の呼び出しは、レートソースが生成した行数に関係なく、60秒ごと(1分ごとに1回)に新しいマイクロバッチを起動するようSparkに指示します。これがSERP API呼び出しのペースを調整する仕組みであり、レート制限内に収めつつも継続的に実行し続けることを可能にします。
.option("checkpointLocation", ...)は、フォールトトレランス(耐障害性)にとって極めて重要です。Sparkは、クエリの進行状況メタデータ(オフセット、コミット済みのバッチ)をこのディレクトリに書き込みます。プロセスがクラッシュして再起動した場合、Sparkはチェックポイントを読み取り、どのバッチがすでに処理済みかを判断し、正しいポイントからスムーズに再開します。
ステップ 7: 実行と結果の確認
ターミナルからパイプラインを実行します:
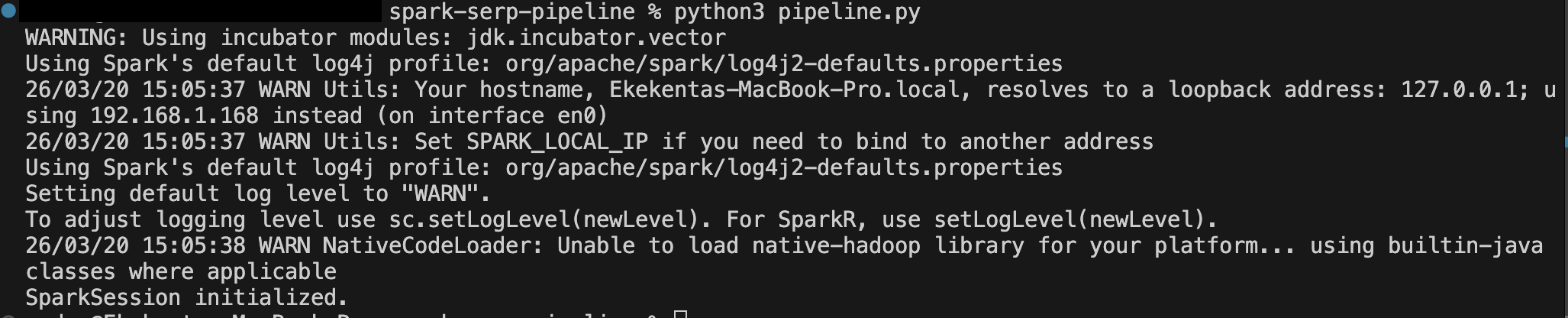
python pipeline.py最初のトリガーが発火した後、次のような出力が表示されるはずです:
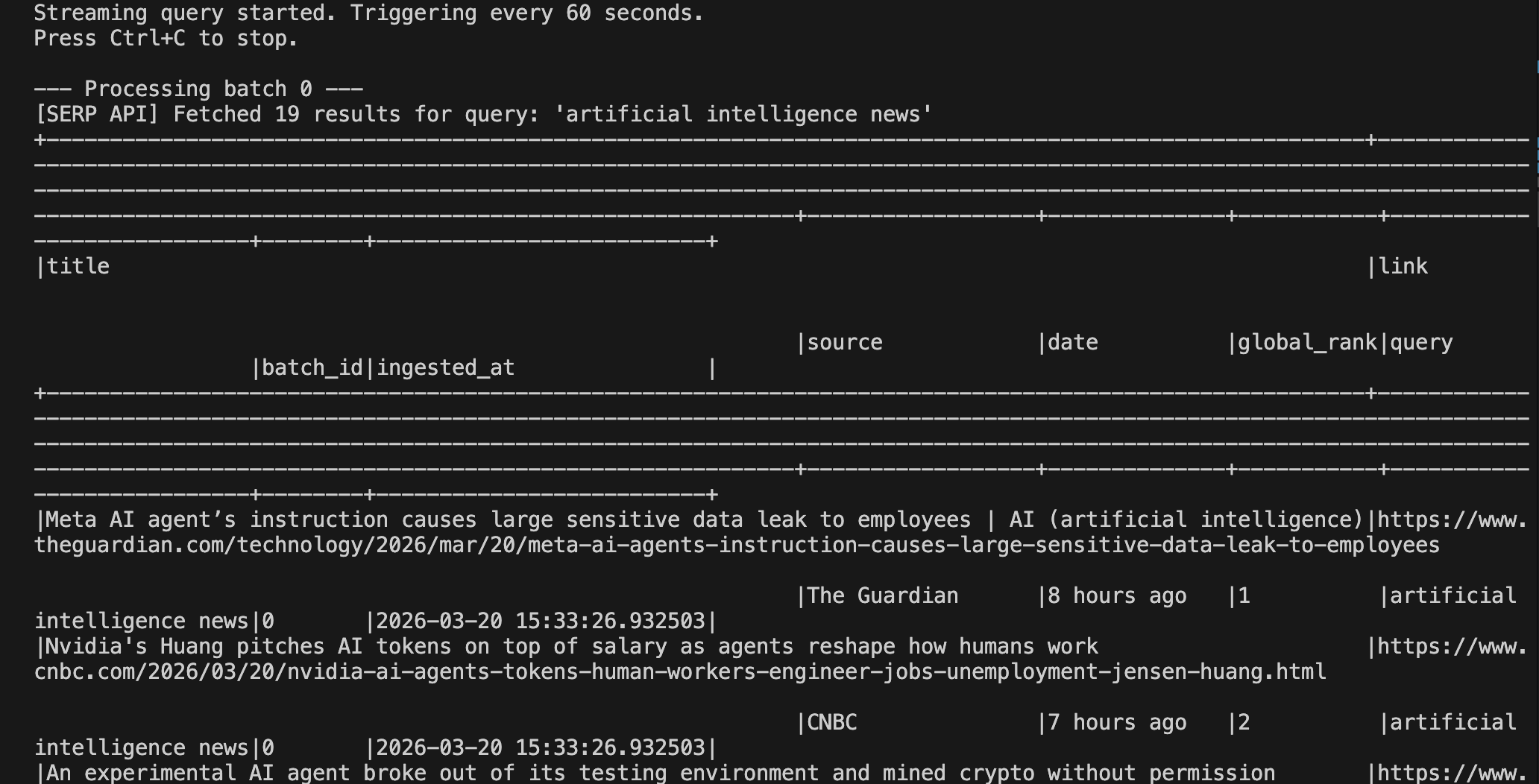
localhost:4040 で Spark 上で実行中の出力を確認できます:
数分間実行した後、出力ディレクトリを確認します:
ls output/serp_results/
ls output/serp_results/ingestion_date=2025-03-19/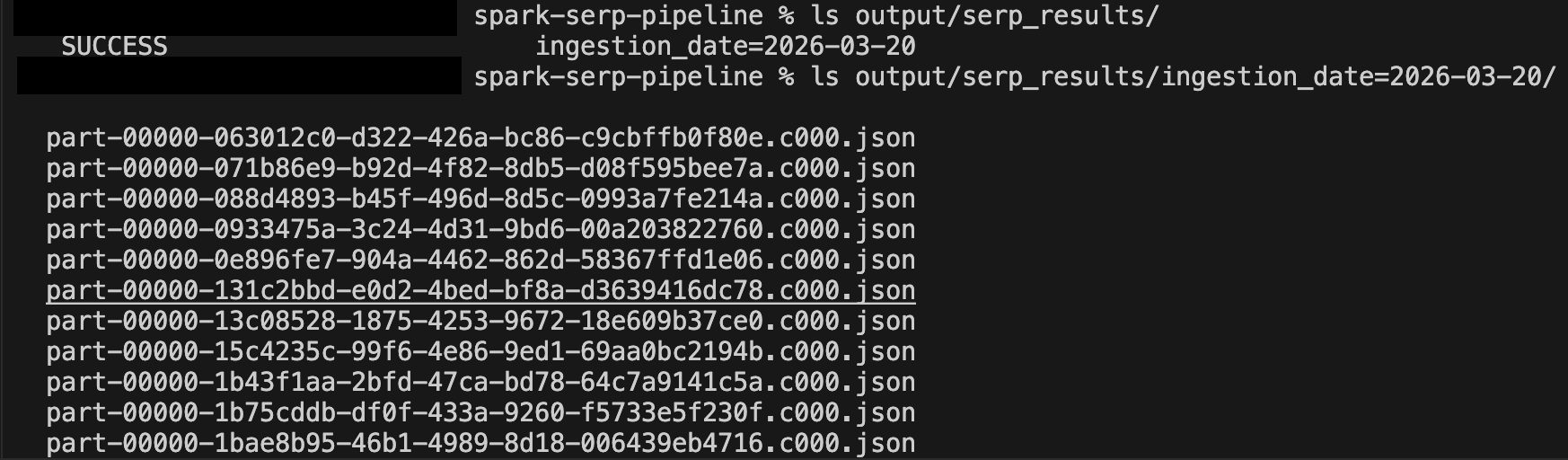
いつでも結果をSparkに読み込んで、アドホックな分析を行うことができます:
# 蓄積された結果を読み込む
df = spark.read.json("output/serp_results/")
df.orderBy("ingested_at", ascending=False).show(20, truncate=False)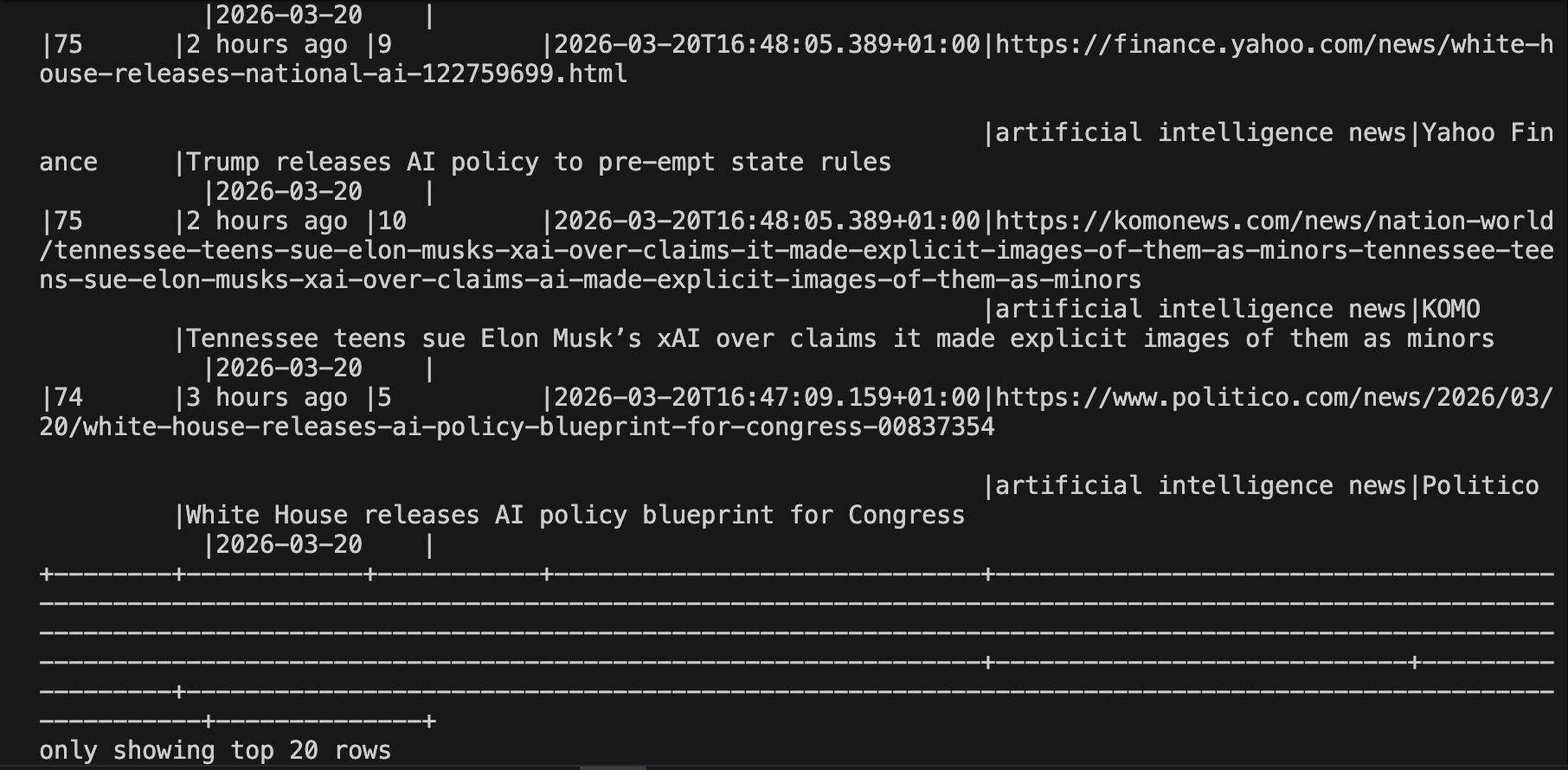
参考用に、パイプラインのコード全体を以下にまとめておきます。
さらなる活用
この例は基本的な取り込みパターンを示していますが、他にも多くの応用が可能です:
- 単一のトピックではなく、キーワードのリストを維持し、各
foreachBatch呼び出し内でSERP API呼び出しを並列化します。Pythonのconcurrent.futures.ThreadPoolExecutorを使用して、同じマイクロバッチ内で複数のクエリに対して同時にAPIを呼び出します。 - JSONシンクをDeltaテーブルに置き換えることで、スキーマの進化をサポートしたACID準拠の増分書き込みが可能になります。これにより、履歴クエリや重複排除が大幅に簡素化されます。
- Bright DataのSERP APIは、Google、DuckDuckGo、Yandexなどに加え、Bing検索エンジンのクエリもサポートしています。同じバッチ内で複数の検索エンジンを並列にポーリングし、結果セットをマージします。
- BrightDataのWeb Unlockerを使用して、SERP APIから返されたURLを追跡し、各記事の完全なHTMLまたはMarkdownコンテンツを取得します。そのコンテンツを、同じSparkパイプライン内の下流のNLPステージにパイプします。
- Databricks、AWS EMR、またはGoogle Dataprocにパイプラインをデプロイすることで、本番環境レベルのスケーラビリティを実現できます。Databricksでは、Delta Live Tablesを使用してパイプラインを宣言的に管理することも可能です。
- エンリッチされたSERP結果をKafkaトピックに書き出し、下流のマイクロサービス、ダッシュボード、またはアラートシステムからリアルタイムで消費します。
まとめ
このチュートリアルでは、Bright DataのSERP APIを使用して、検索エンジンのライブ結果を継続的に取り込み、Apache Spark Structured Streamingで処理する方法について学びました。レートソースをスケジューリングクロックとして、foreachBatchを統合ブリッジとして使用することで、トリガーごとに最新のSERPデータを取得し、型付きSpark DataFrameに変換し、結果をパーティション化されたJSONシンクに書き込む、継続的に稼働するパイプラインを構築しました。これらすべてに、フォールトトレラントなチェックポイント機能が組み込まれています。
このパターンは、キーワードの順位追跡、競合他社のモニタリング、ニュースの集約、広告インテリジェンスなど、リアルタイムのウェブ検索シグナルを大規模に処理する必要があるあらゆるチームに最適です。アドホックなスクリプトベースのポーリングとは異なり、Spark Structured Streamingパイプラインは、データ量に合わせて拡張可能な、分散型で復旧可能な基盤を提供します。
より高度なパイプラインを構築するには、BrightDataのWebデータ製品群をぜひご検討ください。任意のURLにおけるボット対策の回避が可能な「Web Unlocker」、JavaScriptが多用されたサイト向けの「スクレイピングブラウザ」、そして主要プラットフォーム向けの既成データセットなどが含まれています。
今すぐBright Dataの無料アカウントに登録し、信頼性の高いリアルタイムWebデータでデータパイプラインを強化しましょう。





