

このチュートリアルでは、以下の内容を解説します:
- クライアント特定のための完全なステップバイステップワークフロー。
- Bright DataのFilter APIを使用して、ニーズに特化したCrunchbaseデータセットを生成する方法。
- Bright Data APIとAIを活用してデータエンリッチメントと分析を行い、クライアント開拓のためにこのデータセットを処理する方法。
さっそく始めましょう!
新規クライアント特定ワークフローの紹介
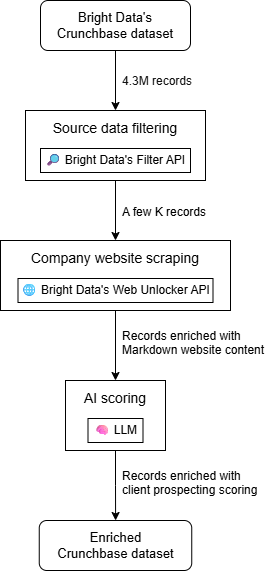
大まかに言えば、AIを活用したクライアント開拓ワークフローは3つの主要なステップで構築できます:
- ソースデータのフィルタリング:Crunchbaseデータセットから始め、独自のニーズに応じてフィルタリングします。
- 企業ウェブサイトのスクレイピング:データセット内の各企業のホームページコンテンツを取得します。
- AIスコアリング:AIを活用してウェブサイトコンテンツ(および企業レコードの他のフィールド)を基に各企業を評価し、自社の製品やサービスに合わせたクライアント開拓スコアを生成します。
出力結果は、各Crunchbase企業レコードにクライアント開拓スコアや追加情報を含む列が付加されたエンリッチされたデータセットです。結果のデータセットをフィルタリングしたり、スコア順に並べ替えたりして、最初にコンタクトすべき企業を特定できます。
各ステップの詳細と実装方法を学びましょう!
1. ソースデータのフィルタリング
このワークフローの理想的なソースは、企業情報を含むデータセットです。Bright Dataは最高の企業データプロバイダーであり、LinkedIn、Crunchbase、Indeedなど多くのプラットフォームをカバーする豊富なデータセットを提供しています。
クライアント開拓においては、Crunchbaseが特に価値があります。CBランク、ヒートスコア、その他の指標など、業界での企業の影響力を素早く評価できる専門的なフィールドを備えているためです。
Bright Dataは430万件以上のレコードを持つCrunchbaseデータセットを提供しています。このような大規模なデータセットを直接扱うのは困難なため、Filter APIを使用して特定の条件を満たす企業に絞り込むことができます。例えば、特定の従業員数範囲内で現在活動中の企業など、関連する条件で絞り込めます。
2. 企業ウェブサイトのスクレイピング
フィルタリングされたCrunchbaseデータセットのデータフィールドは確かに興味深いものです。しかし、それだけでは正確なクライアント特定には一般的に不十分です。企業を真に評価するには、そのウェブサイトを分析することが最良のアプローチの一つです。これにより、企業が何をしているか、そしてあなたのサービスから恩恵を受けられるかどうかを把握できます。
各企業のウェブサイトからコンテンツをプログラム的に取得するのは困難です。なぜなら、各サイトは構造が異なり、IPバン、ジオロケーション制限、CAPTCHAなどのボット対策によって保護されている場合があるからです。また、JavaScriptのレンダリングが必要なサイトもあります。
これらの課題に一貫して対応し、LLM分析に最適化された形式でウェブサイトコンテンツを取得する最良の解決策は、Bright DataのWeb Unlocker APIを利用することです。このエンドポイントを使えば、どれほど保護されたウェブサイトでもスクレイピングが可能です。
3. AIスコアリング
最後に、フィルタリングされたCrunchbaseデータセットに各企業のウェブサイトコンテンツが付加されたら、各レコードをAIに渡します。自社のサービス・製品の説明を提供し、AIに各企業が自社のオファリングに適しているかをスコアリングさせます。
Bright DataのFilter APIを使ってニーズに特化したCrunchbaseデータセットを取得する
まず、AIを活用したクライアント開拓ワークフローのソースデータを取得することから始めましょう。これは、開拓仮説に関連する条件を満たす企業を含む、フィルタリングされたCrunchbaseデータセットです。
この最初のステップにより、重要なデータのみを扱うことができ、より大きなデータセットを処理する場合と比べて時間とコストの両方を節約できます。これからご覧いただくように、Bright Dataが輝くのはまさにここで、高度なフィルタリング機能、特にFilter APIを通じて発揮されます。
以下の手順に従って、カスタマイズされたCrunchbaseデータセットを取得しましょう!
前提条件
このセクションを進めるには、以下が必要です:
- APIキーが設定されたBright Dataアカウント。
requestsがインストールされたローカルPython環境。- Bright Dataのデータセットとスナップショット生成の仕組みについての基本的な理解。
Bright Data APIキーの設定については、公式ガイドをご参照ください。
ステップ#1:Crunchbaseデータセットをフィルタリングする
まずBright Dataアカウントにログインします。コントロールパネルで「Web Datasets」ページに移動し、「Dataset Marketplace」タブを選択します。「Dataset Marketplace」ページで「crunchbase」を検索し、「Crunchbase companies information」データセットを選択します: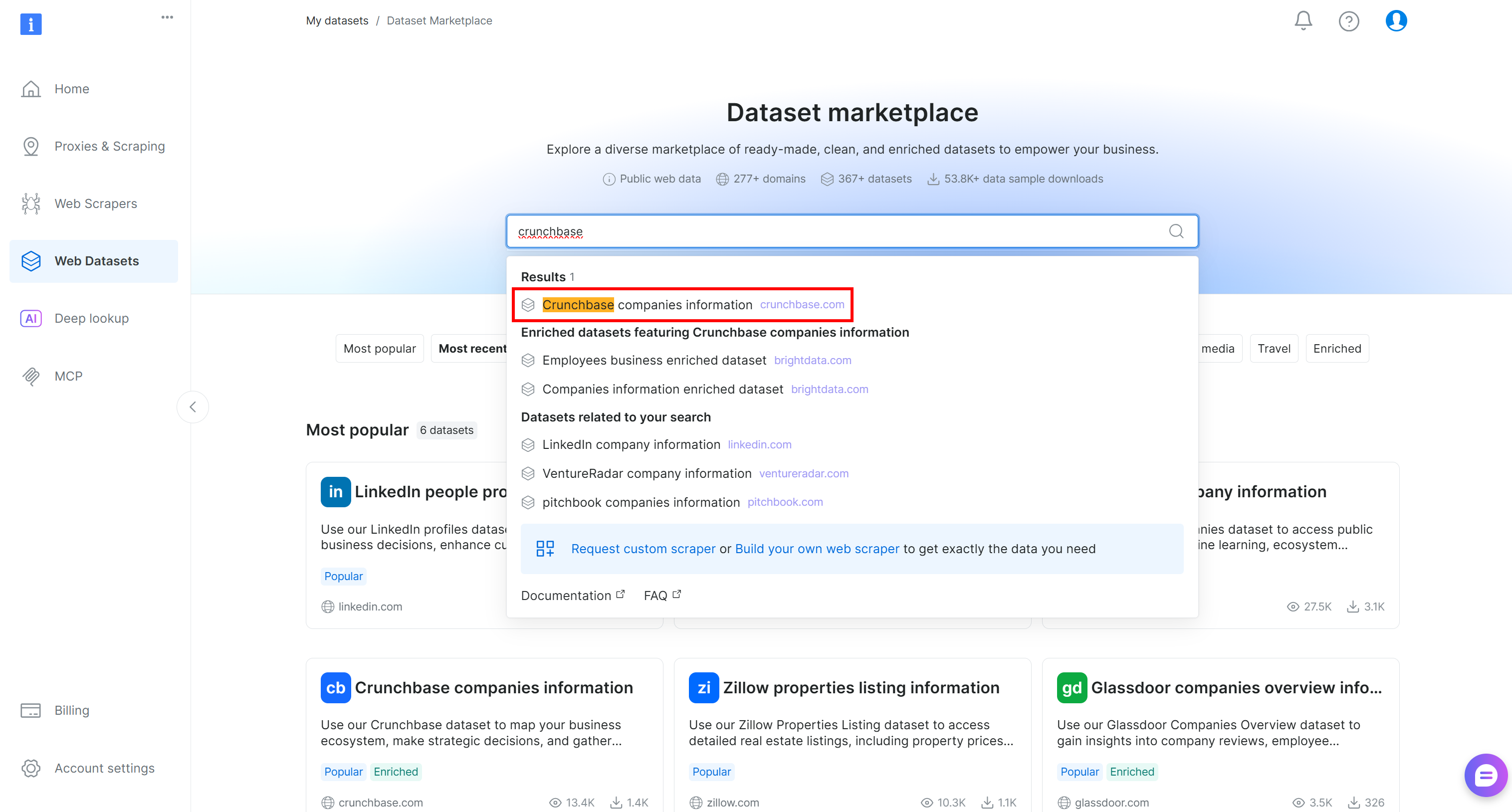
「Crunchbase companies information」データセットページにリダイレクトされます。そこでは、左側の「Filters」ボタンを押すことでコントロールパネルから直接データフィルタリングを適用できます: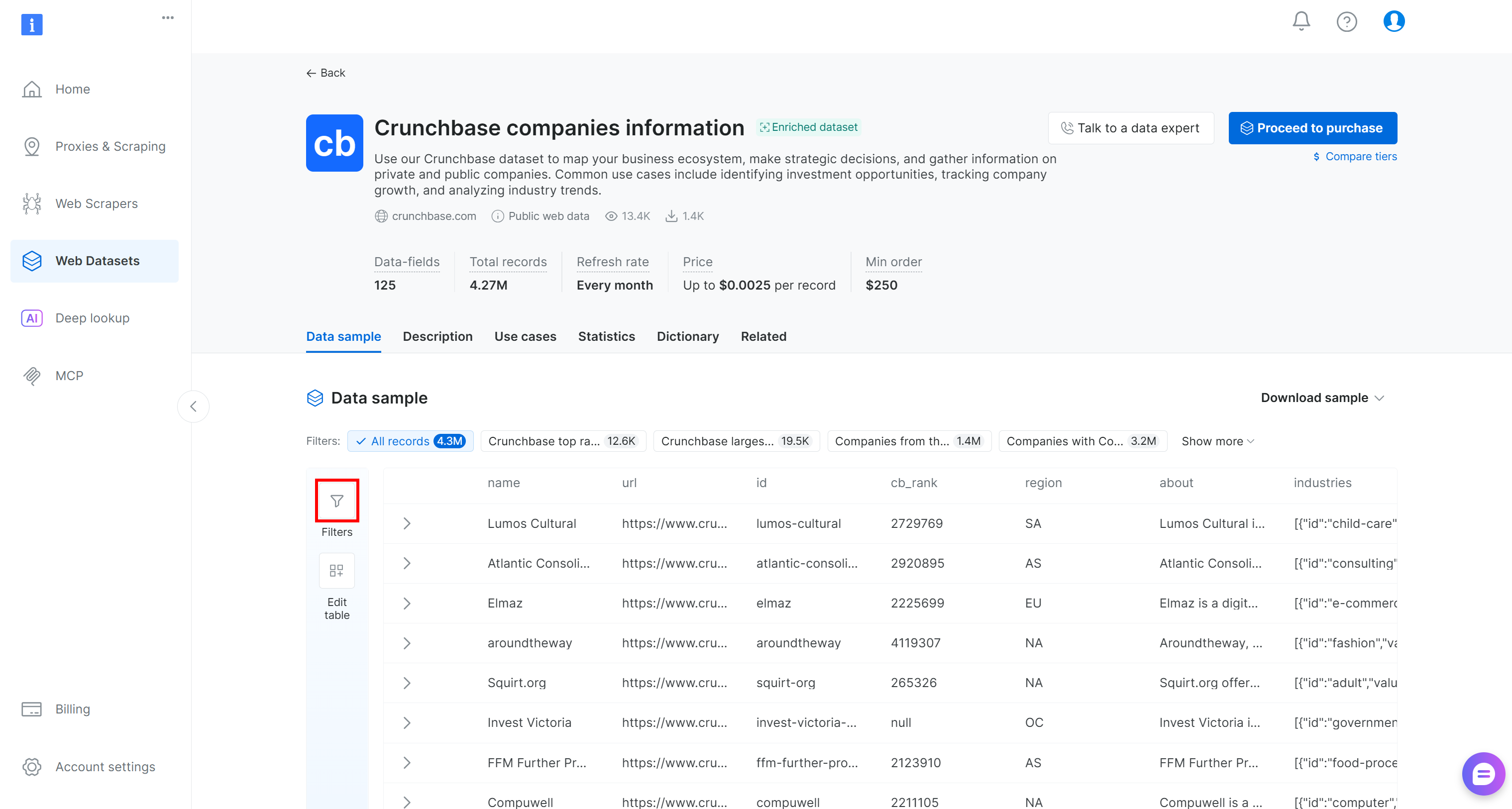
具体的には、125以上のデータフィールドそれぞれに1つ以上のフィルターを追加できます。フィルターを適用して、430万件の企業エントリーの全リストから潜在的に優良なクライアントをより簡単に特定しましょう。
例えば、以下の条件を満たす企業を探したいとします:
- 北米またはヨーロッパに所在する。
- 事業中である。
- AI業界で事業を展開している。
- CBランクが10,000以下である。
- 従業員数が250名未満である。
websiteフィールドが入力されている。- ヒートスコアが60以下である。
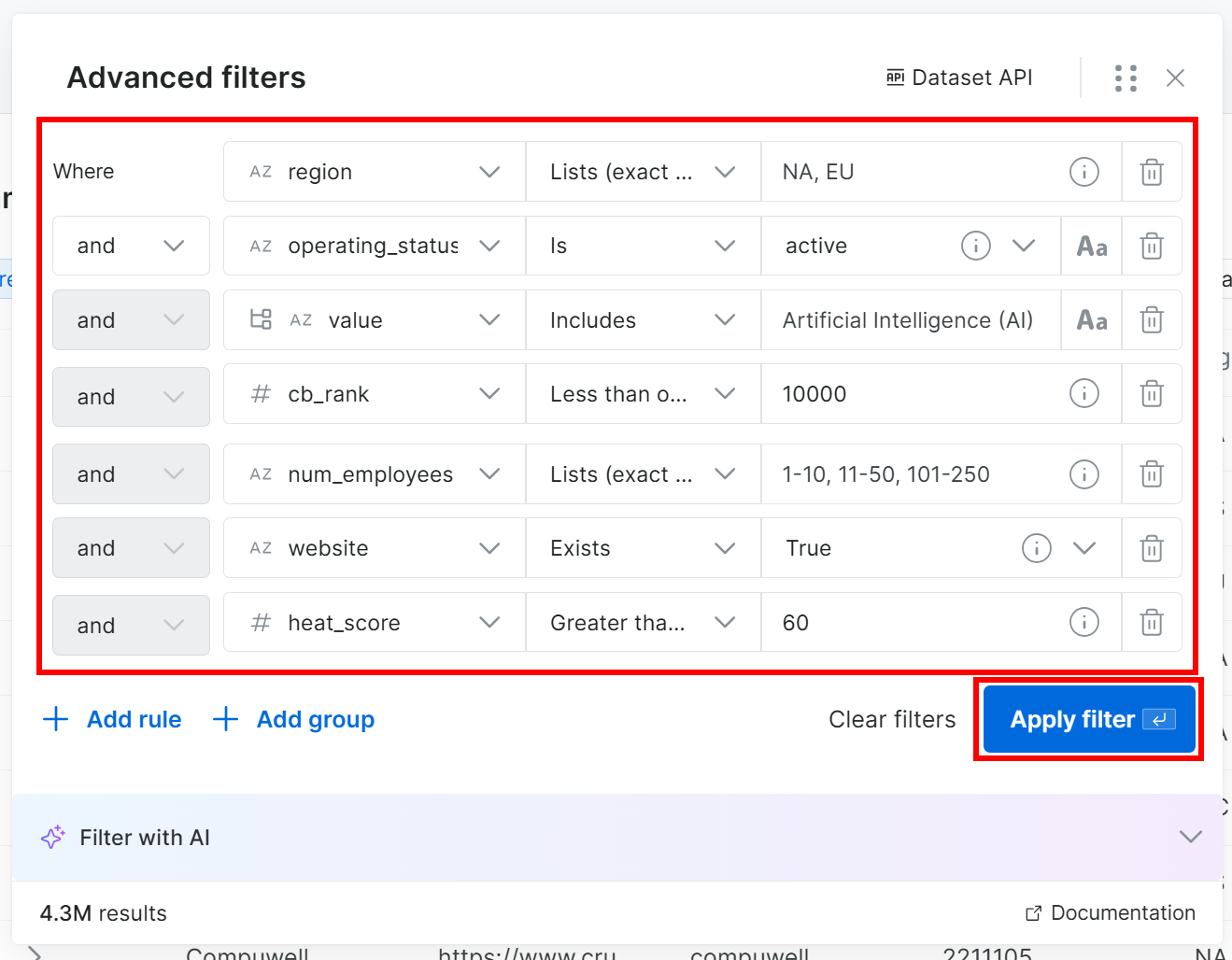
注意:フィルターを手動で追加したくない場合は、「Filter with AI」ボタンをクリックして、必要なデータを平易な英語でプロンプトとして説明できます。
「Apply Filter」ボタンを押して、しばらくお待ちください。フィルタリングには時間がかかる場合があります。Bright Dataは最初の30件のレコードのプレビューを表示し、フィルターが期待通りに機能しているかを確認できます。
フィルタリングされたデータセットのレコード総数も表示されます:
この例では、430万件のレコードから、開拓のための潜在的なクライアント1,300件が得られました。これがBright Dataのフィルタリング機能の力であり、大規模な初期データセットから必要なデータを正確に抽出するのに役立ちます。素晴らしい!
ステップ#2:Filter APIを呼び出す
ここで2つの選択肢があります:「Proceed to purchase」をクリックしてデータセットを直接ダウンロードするか、Filter APIを使用してプログラム的に生成するかです。Filter API(Bright DataのDataset APIの一部)を呼び出すと、再現性と制御性が高まるため、こちらのアプローチを採用します。
フィルターモーダルで「Dataset API」ボタンをクリックします。これにより、選択したフィルターが適用された状態で特定のデータセットに対してFilter APIを呼び出すためのコードが表示されます。「Python」オプションを選択してPythonスニペットを取得します: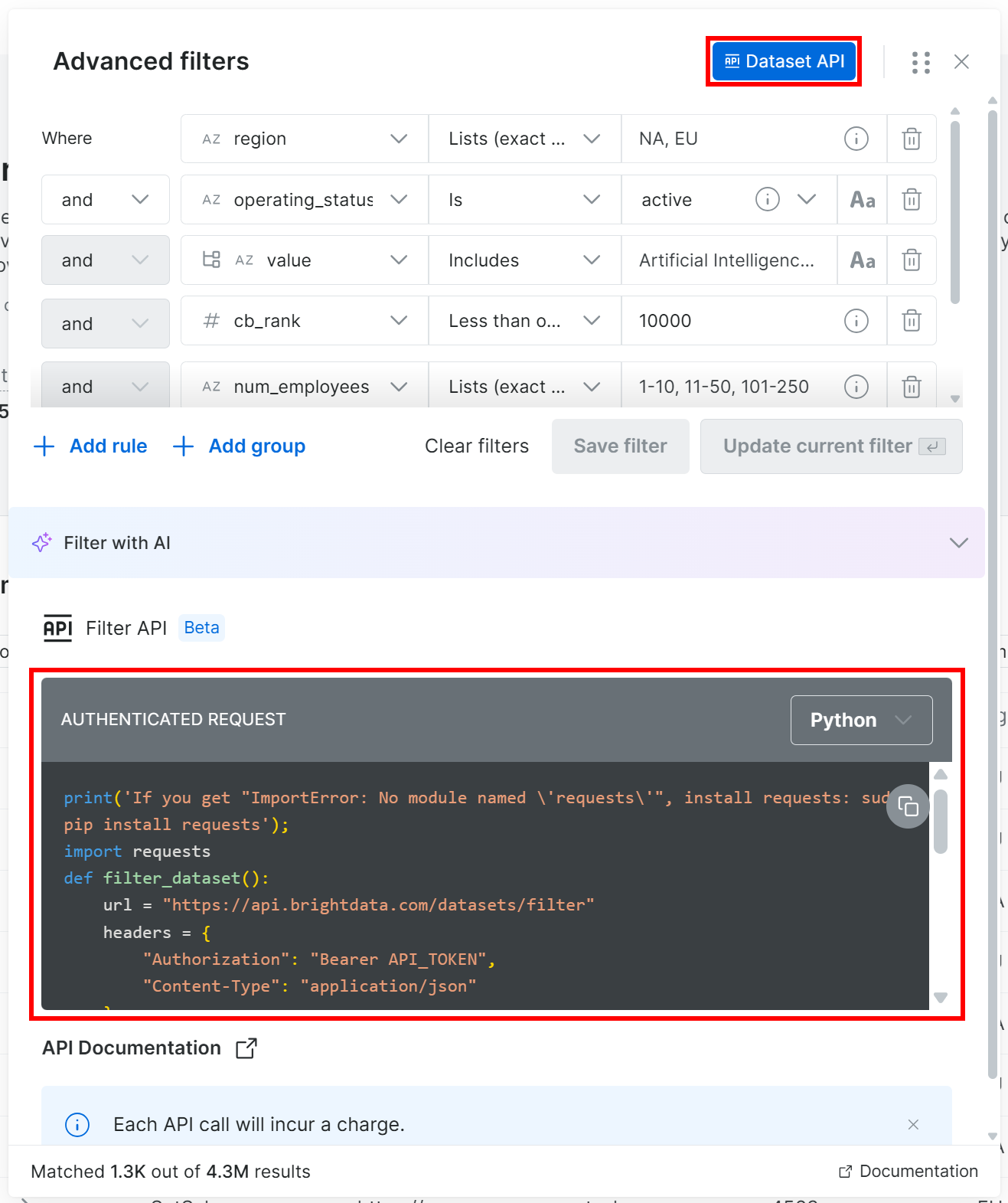
次のようなPythonスニペットが取得できます:
print('If you get "ImportError: No module named 'requests'", install requests: sudo pip install requests');
import requests
def filter_dataset():
url = "https://api.brightdata.com/datasets/filter"
headers = {
"Authorization": "Bearer API_TOKEN",
"Content-Type": "application/json"
}
payload = {
"dataset_id": "gd_l1vijqt9jfj7olije",
"filter": {"operator":"and","filters":[{"name":"region","value":["NA","EU"],"operator":"in"},{"name":"operating_status","value":"active","operator":"="},{"name":"industries:value","value":"Artificial Intelligence (AI)","operator":"includes"},{"name":"cb_rank","value":10000,"operator":"<="},{"name":"num_employees","value":["1-10","11-50","101-250"],"operator":"in"},{"name":"website","operator":"is_not_null"},{"name":"heat_score","value":60,"operator":">="}]}
}
response = requests.post(url, headers=headers, json=payload)
if response.ok:
print("Request succeeded:", response.json())
else:
print("Request failed:", response.text)
filter_dataset()API_TOKENプレースホルダーをBright Data APIキーに置き換え、スクリプトをローカルに保存して、Python環境で実行します。
すべて正常に動作すれば、次のように表示されるはずです:
Request succeeded: {'snapshot_id': 'snap_XXXXXXXXXXXXXXXXXXX'}これは、新しいデータセットスナップショットを生成するタスクが開始されたことを意味します。
この時点で、以下のいずれかを選択できます:
- Dataset APIを通じてステータスを確認してダウンロードする、または
- コントロールパネルから手動でダウンロードする(次のステップで行うこと!)
ステップ#3:フィルタリングされたデータを取得する
スナップショット生成タスクが完了すると、スナップショットの準備ができたことを知らせるメールが届きます: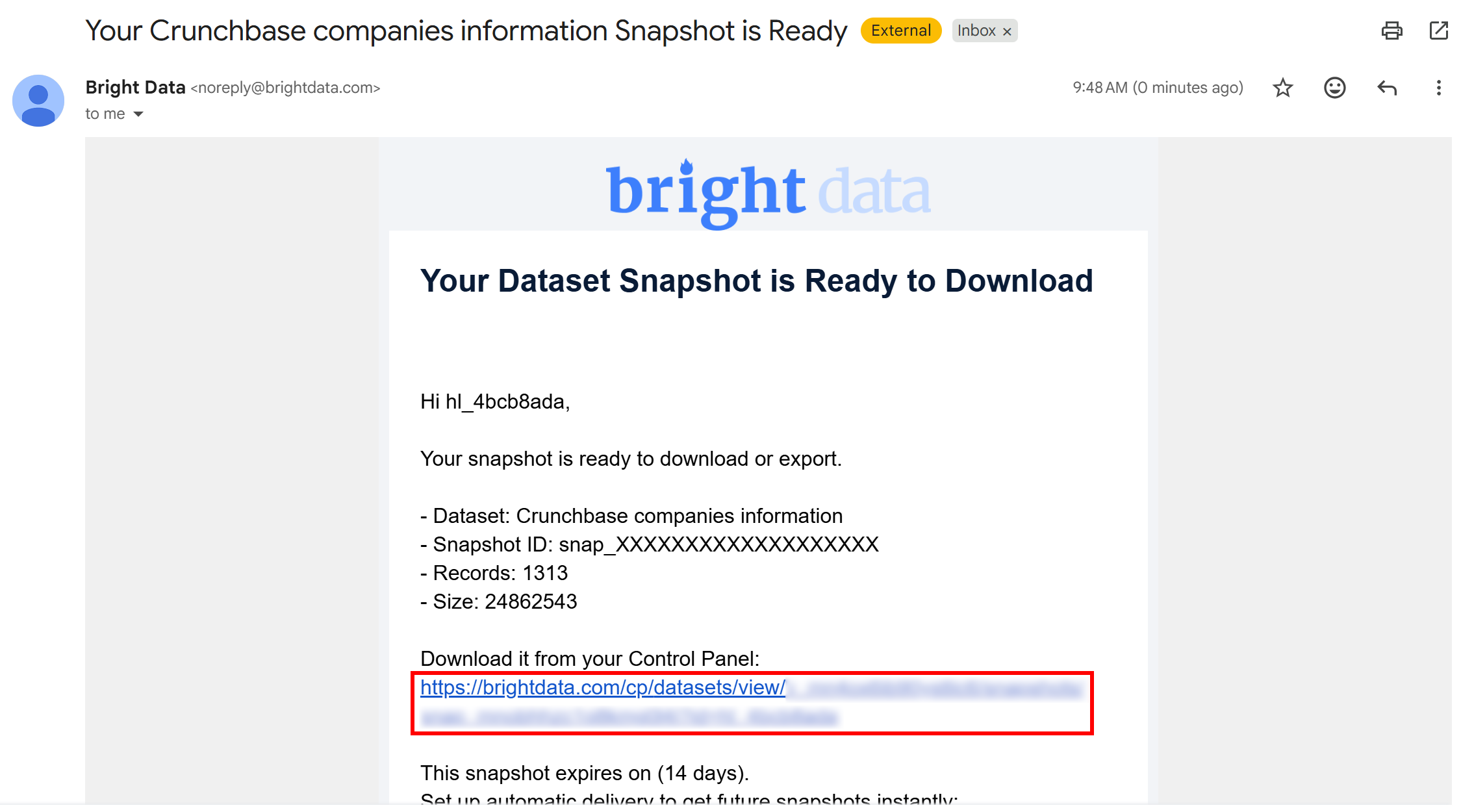
メール内のURLをクリックすると、Bright Dataコントロールパネルのスナップショットページに移動します: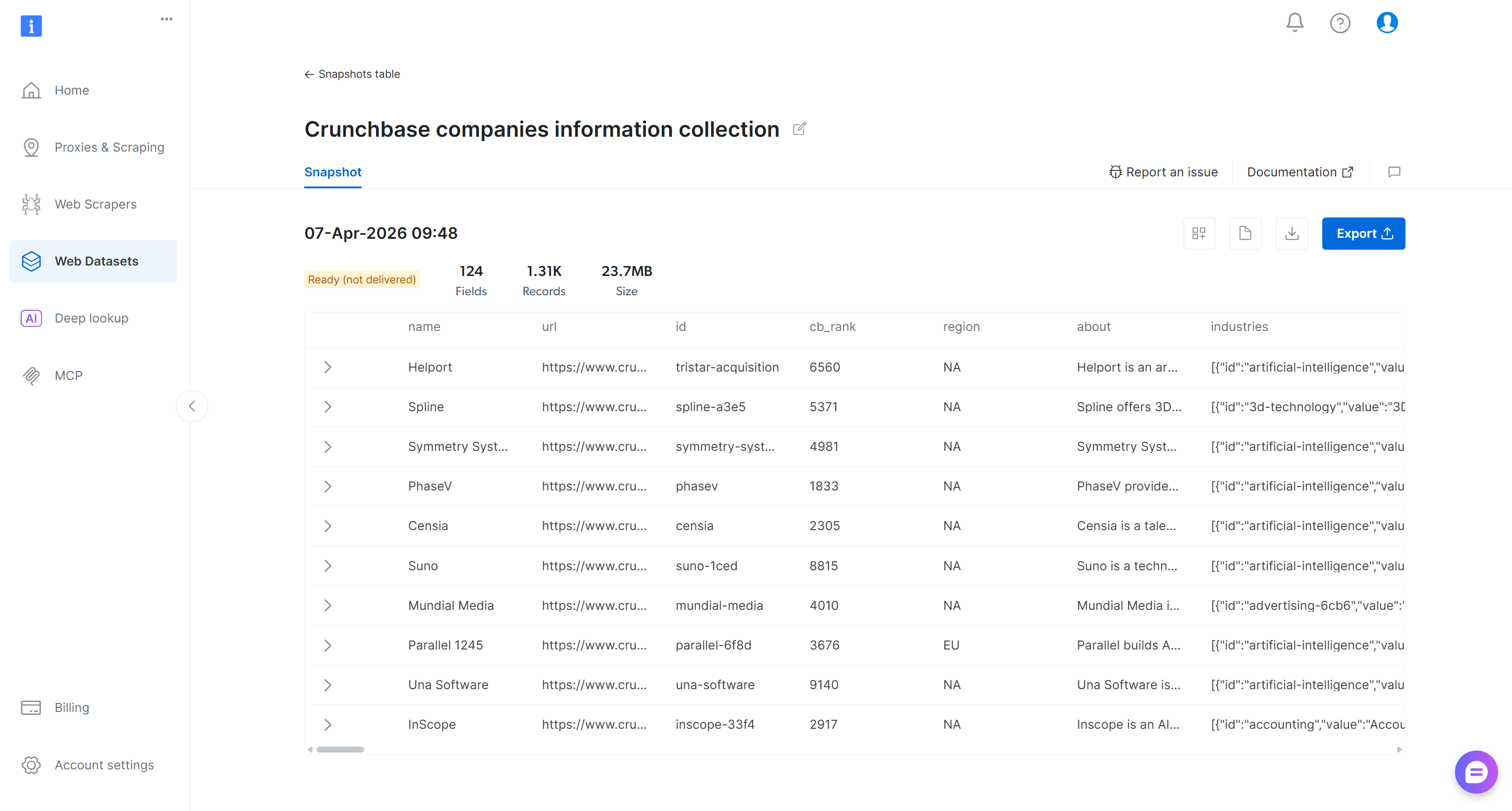
ここでは、フィルタリングされたデータセットの探索、ダウンロード、追加詳細へのアクセスが可能です。例えば、レコード数や総コストなどのインサイトを含むレポートをダウンロードできます。この場合、レポートには$3.29を費やして1,313件のレコードを取得したことが示されています(注意:価格設定は1,000件あたり$2.50です):

スナップショットを取得するには、「Download」アイコンをクリックして「CSV」オプションを選択します: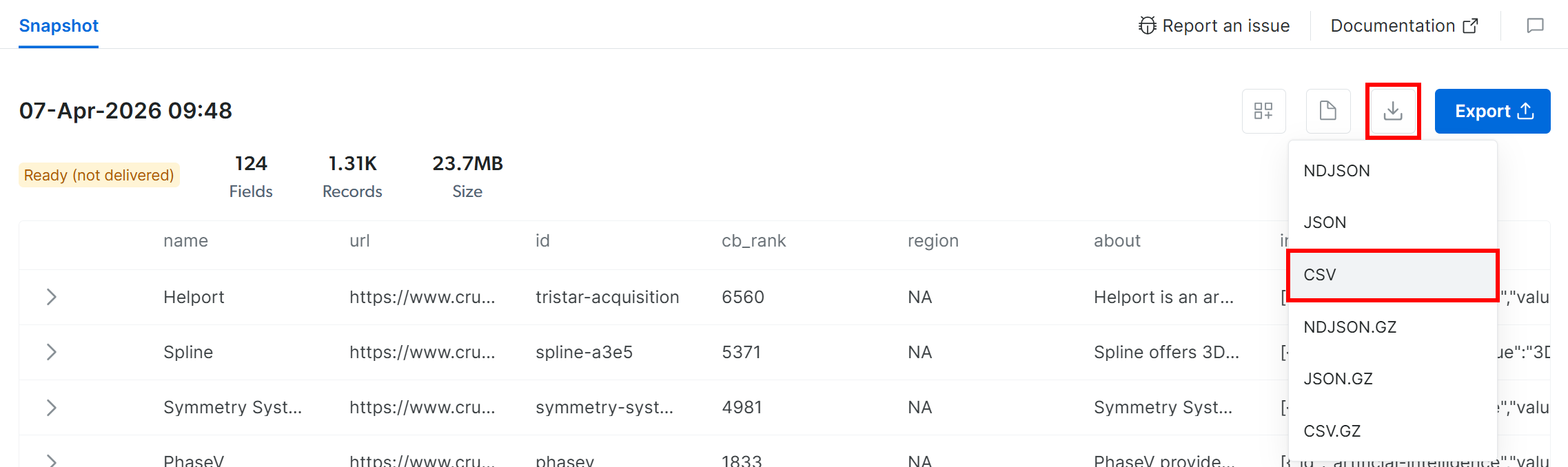
ブラウザが、フィルタリングされたCrunchbaseデータを含むsnap_XXXXXXXXXXXXXXXXXXX.csvというファイルをダウンロードします。完璧!
ステップ#4:フィルタリングされたデータセットを確認する
snap_XXXXXXXXXXXXXXXXXXX.csvファイルを開くと、次のように表示されるはずです:
ダウンロードされたデータセットには、指定したフィルターに一致する1,313件のCrunchbase企業エントリー(各エントリーに133列)が含まれていることに注目してください。
ミッション完了!AIを活用したデータ変換とエンリッチメントによるクライアント開拓を実行するためのソースデータが揃いました。
注意:次に進む前に、データセットを確認し、この記事をサポートする「Crunchbase Data Analysis for Client Prospecting」Kaggleノートブックで示されているように、コンテンツをさらに絞り込むための追加フィルタリングステップの適用を検討してください。
カスタマイズされたCrunchbaseデータセットを起点にAIで新規クライアントを開拓する方法
フィルタリングされたCrunchbaseデータセットは、データ処理とエンリッチメントワークフローのソースとして機能します。各行について、このプロセスは以下を実行します:
- Web Unlocker APIを使用して企業のウェブサイトを訪問し、Markdown形式でコンテンツを取得する。
- 企業のコンテンツをAIモデルに渡し、企業が何をしているかを理解させ、自社ビジネスにとってどれほど良い潜在クライアントかを示すスコアを提供させる。
実装方法を見てみましょう!
前提条件
このセクションを進めるには、前述の前提条件を満たした上で、さらに以下が必要です:
- Bright DataアカウントでWeb Unlocker APIゾーン(例:
web_unlocker)が設定されていること。 - Web Unlocker APIの動作方法とサポートする機能についての知識。
- OpenAI APIキー。
Web Unlockerゾーンの作成については、Bright Dataドキュメントの「Create Your First Unlocker API」ガイドをご参照ください。以下では、Web UnlockerゾーンがWeb Unlocker APIという名前であると仮定します。
シンプルさを保ちこのチュートリアルを簡潔にするため、すでにローカルJupyter Notebook環境が準備済みであることを前提とします。
ステップ#1:ソースフィルタリングデータセットをノートブックにアップロードする
Jupyter Notebookを起動して新しいノートブックを作成します(例:client_prospecting.ipynbという名前にします)。次に、snap_XXXXXXXXXXXXXXXXXXX.csvファイルをアップロードします:
このファイルは、AIを活用したクライアント開拓ワークフローのソースデータとして使用されます。よくできました!
ステップ#2:必要なライブラリをインストールする
データエンリッチメントロジックに入る前に、このワークフローで必要な依存関係をインストールします。セルに以下を追加します:
!pip install pandas requests pydantic openaiこれにより、以下のライブラリがインストールされます:
pandas:CrunchbaseデータのソースCSVをDataFrameとして読み込み、操作するため。requests:企業ホームページをダウンロードするためにBright DataのWeb Unlocker APIに接続するため。pydantic:OpenAIタスクの構造化された出力を定義するため。openai:クライアント開拓のために指定されたホームページをランク付けするためにOpenAIモデルと対話するため。
「▶」ボタンを押してセルを実行し、これらのライブラリをインストールします。これで、フィルタリングされたCrunchbaseデータセットから始まるAIを活用したクライアント開拓に必要なすべての依存関係がノートブックに含まれました。
ステップ#3:初期セルをセットアップする
インポート、シークレット、定数がコード全体に散らばらないよう、ノートブックの最初のセルにすべてまとめます:
import os
import pandas as pd
import requests
import datetime
import concurrent.futures
from typing import Optional
from pydantic import BaseModel, Field
from openai import OpenAI
# Secrets to connect to third-party services (replace them with the actual values)
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
# Define the required constants
SOURCE_CSV_PATH = "snap_XXXXXXXXXXXXXXXXXXX.csv"
ENRICHED_CSV_PATH = "crunchbase_analyzed_companies.csv"
# Initialize the OpenAI client
openai_client = OpenAI(api_key=OPENAI_API_KEY)以下を確認してください:
<YOUR_BRIGHT_DATA_API_KEY>をBright Data APIキーに置き換える。<YOUR_OPENAI_API_KEY>をOpenAI APIキーに置き換える。- 必要に応じてソースファイル名(
SOURCE_CSV_PATH)とエンリッチされたファイルパス(ENRICHED_CSV_PATH)を更新する。
ENRICHED_CSV_PATHは、エンリッチされたデータが保存される出力ファイルパスを定義することに注意してください。
これで、開始するためのすべての構成要素が揃いました。
ステップ#4:データセットを読み込む
新しいセルに、ソースデータセットをDataFrameに読み込み、主要な情報を表示するロジックを追加します:
# Load the CSV file containing the filtered Crunchbase dataset
df = pd.read_csv(SOURCE_CSV_PATH, keep_default_na=False)
# Print the basic info about the dataset
df.info()
# Print the first rows
df.head()注意:keep_default_na=Falseオプションは必須です。そうしないと、"NA"を含むregion列がpandasによってデフォルトでNaNとして解釈されてしまいます。
セルを実行すると、次のような出力が表示されるはずです: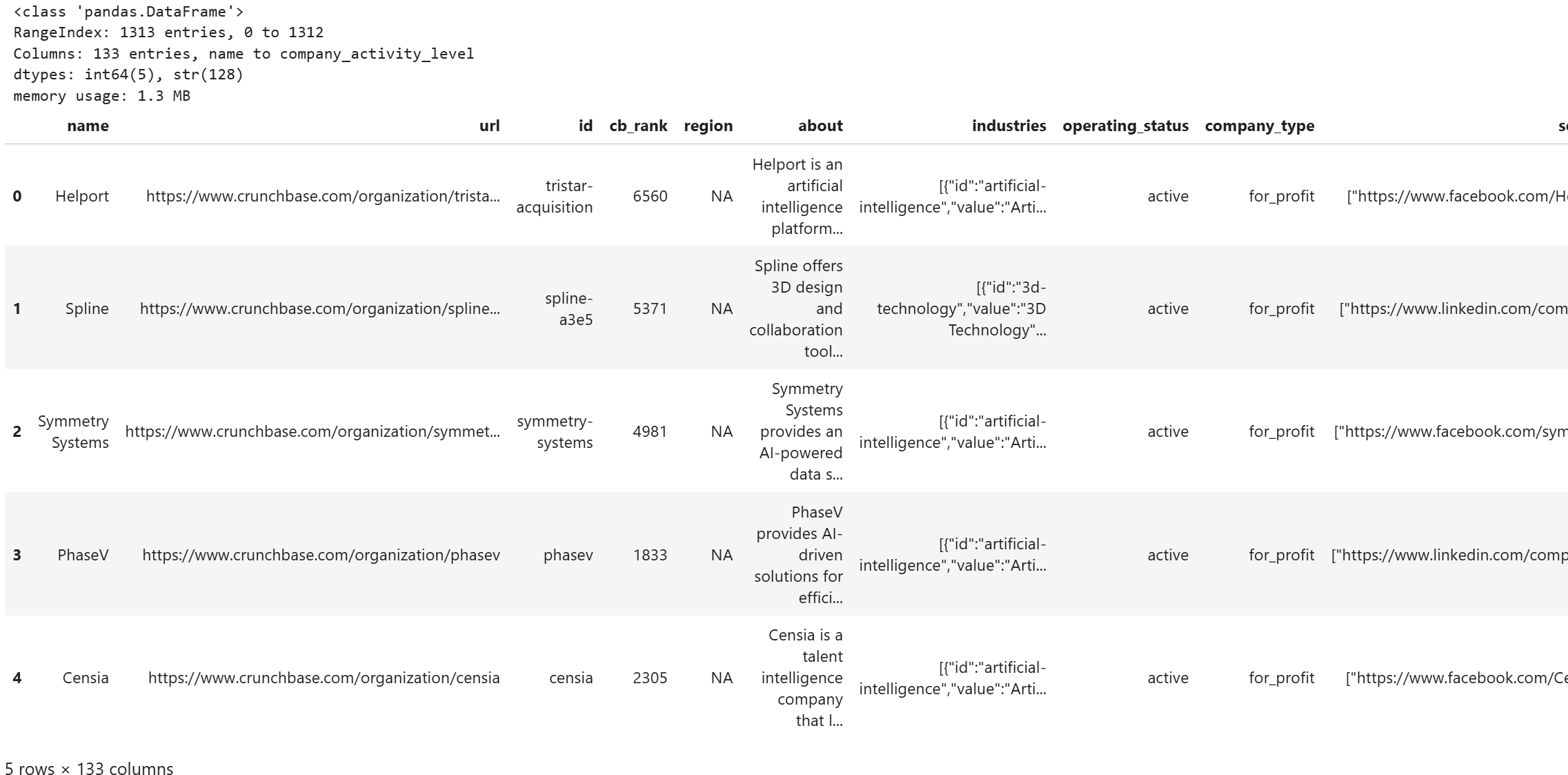
DataFrameにフィルタリングされたCrunchbaseデータセットの1,313件のエントリーが133列で格納されていることに注目してください。素晴らしい!
ステップ#5:ウェブサイトスクレイピング用の関数を定義する
次に、Web Unlocker APIを呼び出して企業のウェブサイトをスクレイピングする関数を定義します:
def fetch_website(url, zone = "web_unlocker"):
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": zone,
"url": url,
"format": "raw", # Get the response directly in the body
"data_format": "markdown" # Get the webpage in Markdown format (ideal for LLM ingestion)
}
api_url = "https://api.brightdata.com/request"
try:
response = requests.post(api_url, json=data, headers=headers)
# Raise an error if the response is 4xx/5xx
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching '{url}' via Web Unlocker API: {e}")
return NoneWeb Unlocker APIの動作方法については、公式ドキュメントをご参照ください。
fetch_website()関数は、指定されたURLに対してBright DataのWeb Unlocker APIゾーン("web_unlocker"を自身のゾーン名に置き換えてください)を呼び出します。data_format: "markdown"パラメーターにより、レスポンスはAI対応のMarkdown形式のウェブサイトになります。このデータ形式はLLM取り込みに最適であり、まさにこれから行うことです。
この関数は各企業エントリーに適用され、ホームページのMarkdown版でエンリッチされます。次のステップでその方法を見てみましょう!
ステップ#6:すべての企業ホームページを並列で取得する
Web Unlocker APIは、Bright Dataの他のAPIベース製品と同様に、4億以上のレジデンシャルIPを持つエンタープライズグレードのインフラに支えられています。これにより、レート制限やスケーリングの問題を心配することなく、無制限の同時実行でAPIを呼び出せます。
データセットには数千の企業が含まれているため、複数のウェブサイトを同時にスクレイピングすることが合理的です。以下のセルがまさにそれを実行します:
batch_size = 5
total = len(df)
defprocess_row_for_scraping(idx):
url = df.at[idx, "website"]
# Skip the row if the "website" field is missing
if pd.isna(url):
return None
# Retrieve the website homepage in Markdown
markdown = fetch_website(url)
timestamp = datetime.datetime.now(datetime.UTC)
return idx, markdown, timestamp
for start in range(0, total, batch_size):
# Get the current batch
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing Crunchbase records {start} to {end-1}")
# Fetching website homepages in parallel for the batch
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row_for_scraping, batch_indices))
# Update the DataFrame with the results
for r in results:
# Skip
if r is None:
continue
idx, markdown, timestamp = r
df.at[idx, "website_markdown"] = markdown
df.at[idx, "website_markdown_fetching_timestamp"] = timestamp
# Save the updated CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")このスニペットは、Crunchbaseデータセットを処理して各企業エントリーをAIを活用した分析に対応したウェブサイトのMarkdown版でエンリッチします。一度に5行のバッチで処理し、ウェブサイトを並列で取得してI/Oバウンド操作を高速化します。
process_row()関数は各企業を処理し、Web Unlocker APIを使用してホームページを取得してタイムスタンプを記録します。URLが欠落している場合はスキップすることで効率が向上し、不要なAPI呼び出しを回避できます。また、タイムスタンプを追跡することは重要で、企業のウェブサイトは頻繁に変更される可能性があるため、最後にスクレイピングした時期を把握しておくことが重要です。
バッチはスレッドプールで処理され、複数のリクエストを並行して実行できます。各バッチ後、DataFrameが更新されてディスクに保存されます。増分保存は基本的に重要であり、プロセスが中断された場合のデータ損失を防ぎ、最初からやり直すことなく再開できます。
プロヒント:最初の実行では、全データセットを処理する前にワークフローが期待通りに動作することを確認するため、行数を5または10に制限してください。
実行後、下の画像のような出力メッセージが表示されます:
ノートブックのディレクトリにcrunchbase_analyzed_companies.csvファイルが表示されます。これには、元のすべてのCrunchbaseデータに加えて、2つの新しい列が含まれます:
website_markdown:各企業のホームページのAI対応Markdown版。website_markdown_fetching_timestamp:各ページが取得された正確な時刻。
素晴らしい!このデータセットは、AIを活用した分析とクライアント開拓の準備ができました。
ステップ#7:AIクライアント開拓用の関数を指定する
次のステップは、AIにクライアント開拓を実行させる関数を追加することです。アイデアは、自社が何をしているかを説明し、AIに各Crunchbase企業エントリーを評価させて以下を生成させることです:
- この企業がどれほど強い潜在クライアントであるかを示すスコア。
- スコアの根拠を説明する短いコメント(数字だけでは全体像が伝わらない場合に役立ちます)。
- ウェブサイトコンテンツに基づく企業のコアビジネスの短い説明(適合性を判断するのに役立ちます)。
注意:以下のプロンプトは企業のウェブサイトのみを入力として使用していますが、より高度で詳細な分析のためにレコード全体を渡すことも可能です。
このセルでプロセスを実装します:
# Define the structured output schema
class AIProspectingResult(BaseModel):
ai_client_prospecting_score: float
ai_client_prospecting_comment: str
ai_core_business: str
def analyze_website(markdown):
# Ask the AI to perform the client prospecting task
system_prompt = (
"You are a business intelligence analyst specialized in identifying potential clients "
"for a cybersecurity firm. We are a specialized cybersecurity firm providing adversarial testing "
"for AI-powered ecosystems. Our mission is to proactively identify vulnerabilities by attempting to 'break' "
"AI models through sophisticated attack simulations. Following our assessment, we deliver a comprehensive "
"Vulnerability & Patch Report, detailing specific weaknesses discovered and providing actionable technical "
"strategies to remediate these risks and fortify the system's integrity.nn"
"Analyze the provided website content and produce a structured JSON with:n"
"- `ai_client_prospecting_score`: 0-10 float indicating how good a potential client this company could be.n"
"- `ai_client_prospecting_comment`: short comment (<=30 words) explaining the score.n"
"- `ai_core_business`: short description (<= 50 words) of what the company does based on the website.n"
)
user_prompt = f"WEBSITE CONTENT:n{markdown}"
try:
response = openai_client.responses.parse(
model="gpt-5.4-mini",
input=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
text_format=AIProspectingResult,
)
# Return the parsed result
return response.output_parsed
except Exception as e:
print("Error analyzing website with AI:", e)
return None選択したOpenAIモデル(この場合はGPT-5.4 Mini)が構造化された出力で応答するようにするため、responses.parse()メソッドを呼び出します。これはPydanticデータモデルを受け取り、生成されたレスポンスがそのフォーマットに従うことを保証します。詳細については、ChatGPTを使ったウェブスクレイピングのガイドで実際の動作を確認してください。
素晴らしい!次のステップは、各企業レコードに対してこの関数を並列で呼び出すことです。
ステップ#8:すべての企業を並列で開拓する
先ほどと同様に、AIが複数のエントリーを並列で処理できるようにセルを追加します:
batch_size = 5
total = len(df)
def process_row(idx):
markdown = df.at[idx, "website_markdown"]
# Skip rows with missing markdown
if pd.isna(markdown):
return None
# Call the AI prospecting function
result = analyze_website(markdown)
if result is None:
return None
return idx, result.ai_client_prospecting_score, result.ai_client_prospecting_comment, result.ai_core_business
for start in range(0, total, batch_size):
end = min(start + batch_size, total)
batch_indices = df.index[start:end]
print(f"Processing AI prospecting for records {start} to {end-1}")
# Run AI analysis in parallel
with concurrent.futures.ThreadPoolExecutor(max_workers=batch_size) as executor:
results = list(executor.map(process_row, batch_indices))
# Update the DataFrame with the results (if the array is not full of None values)
for r in results:
if r is None:
continue # Skip
idx, score, comment, core_business = r
df.at[idx, "ai_client_prospecting_score"] = score
df.at[idx, "ai_client_prospecting_comment"] = comment
df.at[idx, "ai_core_business"] = core_business
# Save CSV after each batch
df.to_csv(ENRICHED_CSV_PATH, index=False)
print(f"Batch {start}-{end-1} saved to disk.")実行すると、次のようなメッセージが表示されます:
Crunchbaseデータセットが、Bright Dataの抽出とAIを活用したクライアント開拓分析でエンリッチされました。
結果を確認しましょう!
ステップ#9:エンリッチされたデータを分析する
最後のセルに、エンリッチされたデータを表示するロジックを追加します:
relevant_columns = [
"name",
"cb_rank",
"region",
"ai_client_prospecting_score",
"ai_client_prospecting_comment",
"ai_core_business"
]
pd.set_option("display.max_columns", None) # Show all columns
pd.set_option("display.max_colwidth", None) # Do not truncate text
# Print only the relevant fields
df[relevant_columns].head(10)結果のデータセットには以下が含まれます:
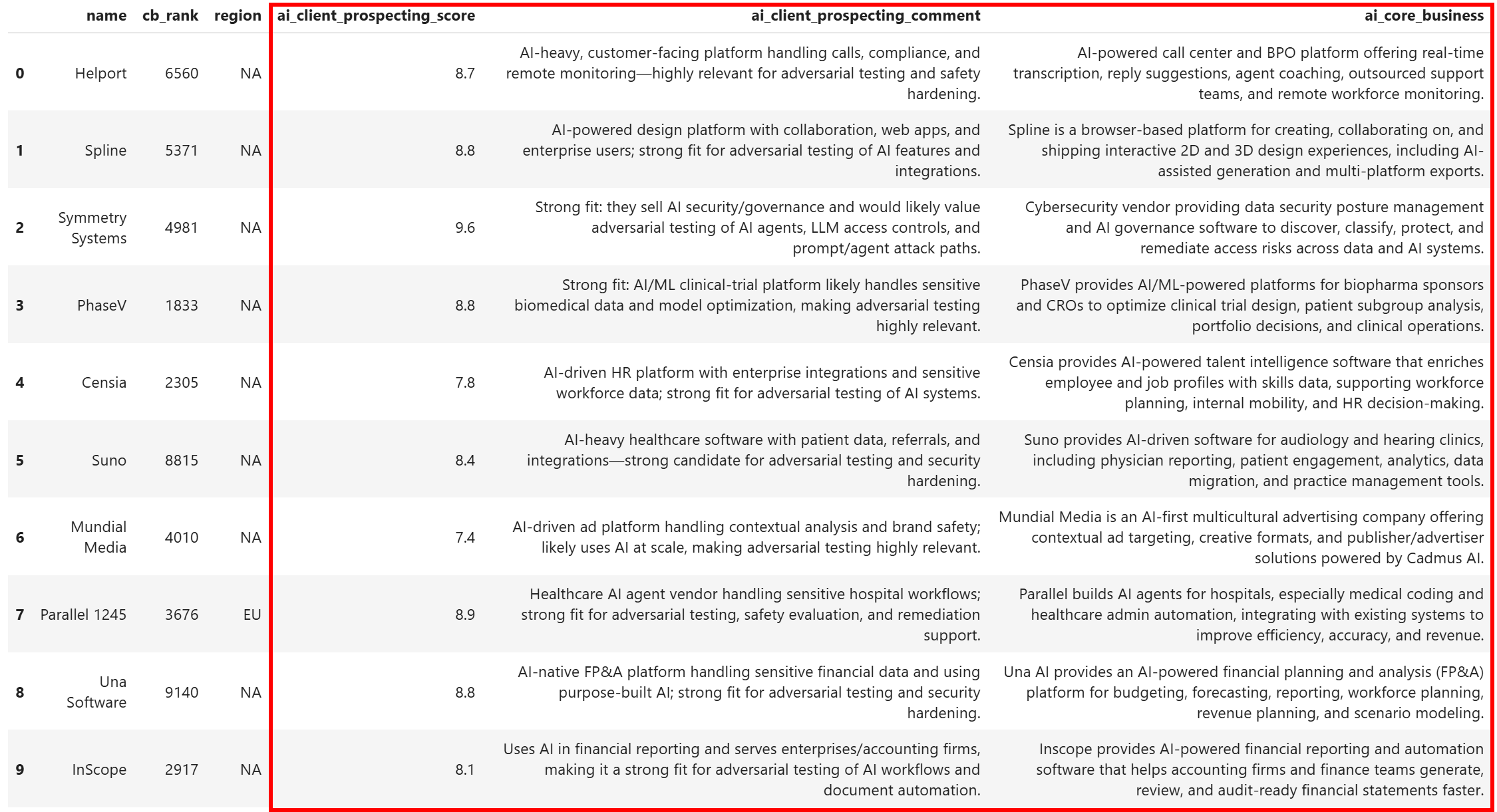
各企業が、明確な開拓スコア、スコアの根拠を説明する短いコメント、そして企業が何をしているかの簡潔な説明でエンリッチされていることに注目してください。これは以下なしには実現できなかったことです:
- Bright DataのFilter API:ターゲットを絞ったフィルタリング済みCrunchbaseデータセットを取得するため。
- Web Unlocker API:どんな企業のウェブサイトもブロックなしに確実にスクレイピングするため。
これで完成です!さらなるデータ分析と処理を適用して、最初にコンタクトする最良の候補者を選択できます。
まとめ
この記事では、Bright Dataのデータセット、Bright Data APIとAIを活用して、完全な本番対応の自動クライアント開拓ワークフローを構築する方法を学びました。このワークフローは以下を実行します:
- 430万件以上のレコードを含むCrunchbaseデータセットから始める。
- Bright DataのFilter APIを使用してプログラム的にフィルタリングし、特定の条件を満たす企業のみを含める。
- Web Unlocker APIを使用して各企業のウェブサイトコンテンツを取得する。
- そのコンテンツをAIに渡してプログラム的にスコアリングし、各企業がどれほど良い潜在クライアントであるかを評価する。
結果は、各企業に自社の製品やサービスへのコンタクトが有意義かどうかを示すスコアと短いコメントが付与されたエンリッチされたデータセットです。Bright Dataのマーケットプレイスからの高品質データ、高度なフィルタリング機能、AIエンリッチメントにより、新規クライアントの発掘がかつてないほど簡単になりました!
今すぐBright Dataの無料アカウントを作成して、AI対応のウェブツールを試してみましょう!






