

金融市場は毎秒大量のデータを生成している。ナスダックは世界最大級の取引所であり、アップル、マイクロソフト、テスラ、アマゾンなどの大企業を擁している。
取引アルゴリズム、調査ダッシュボード、またはフィンテックアプリケーションを構築している場合、この金融データを収集することは大きなチャンスであると同時に技術的な課題でもあります。このガイドでは、NASDAQから金融データを収集するための3つの実証済みの方法について説明します:内部エンドポイントを介した直接APIアクセス、スケールのためのエンタープライズプロキシインフラストラクチャの実装、およびMCP(モデルコンテキストプロトコル)を使用したAIを搭載したWebスクレイピングの使用。
ナスダックのデータ状況を理解する
NASDAQは、リサーチ、バックテスト、分析アプリケーションに最適な包括的なマーケットデータを提供しています。一般的にアクセスできるものは以下の通りです:
- 価格データ– 上場銘柄の最終取引価格、毎日の高値/安値、始値/終値、出来高、変動率
- 過去のデータ– 毎日のOHLC(始値、高値、安値、終値)データ、配当履歴、株式分割、過去の取引量
- 会社情報– 会社の基本情報、セクター分類、SEC提出書類や会社ニュースへのリンク。
- 追加機能– インタラクティブ・チャート、業績カレンダー、機関投資家の保有データ
トレーダーや投資家は、実際の取引に導入する前に、バックテストで戦略の過去のパフォーマンスを分析する。企業は、競合他社の動きを追跡し、市場動向や機会を特定するために、この市場データを競争インテリジェンスに活用しています。より高度なシナリオについては、包括的な金融データの使用例をご覧ください。
では、このデータをスクレイピングする方法を見てみよう。
データ抽出方法
NASDAQ、yahoo finance、google financeのような最新の金融サイトは、動的コンテンツをレンダリングするためにJavaScriptを使用するシングルページのアプリケーションとして構築されています。もろいHTMLを解析する代わりに、内部のJSON APIエンドポイントを直接呼び出す方がより堅牢です。
NASDAQのJSONエンドポイントを特定する方法は以下の通り:
- 任意のティッカー・ページ(例:https://www.nasdaq.com/market-activity/stocks/aapl)を開き、ブラウザのデベロッパー・ツールを開く。
- Networkタブで、Fetch/XHRフィルターを選択してAPIトラフィックを分離する。
- ページをリロードして、すべてのリクエストをキャプチャする。
リロードすると、market-info、chart、watchlistなどのリクエストが表示される。
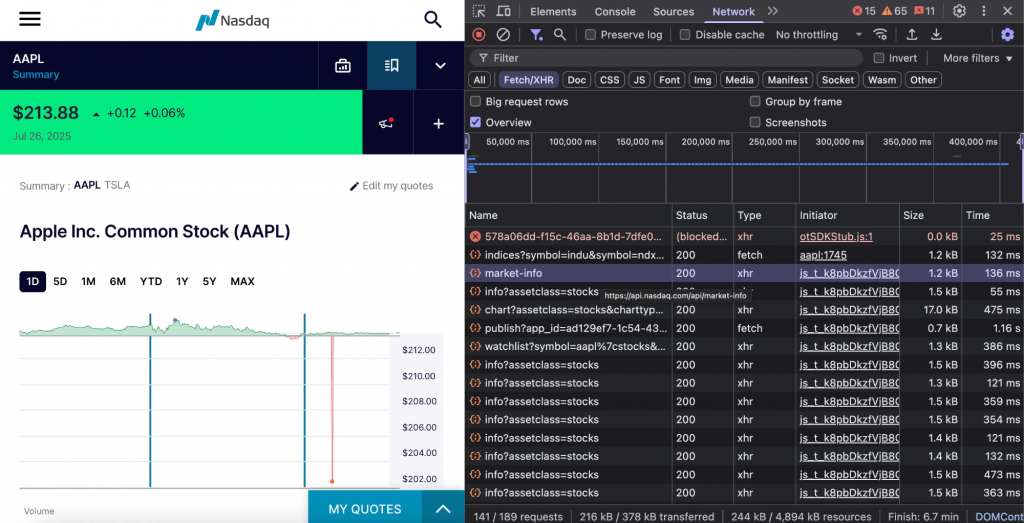
たとえば、market-infoリクエストは、リアルタイムのマーケット情報を含む包括的なデータ構造を表示します。
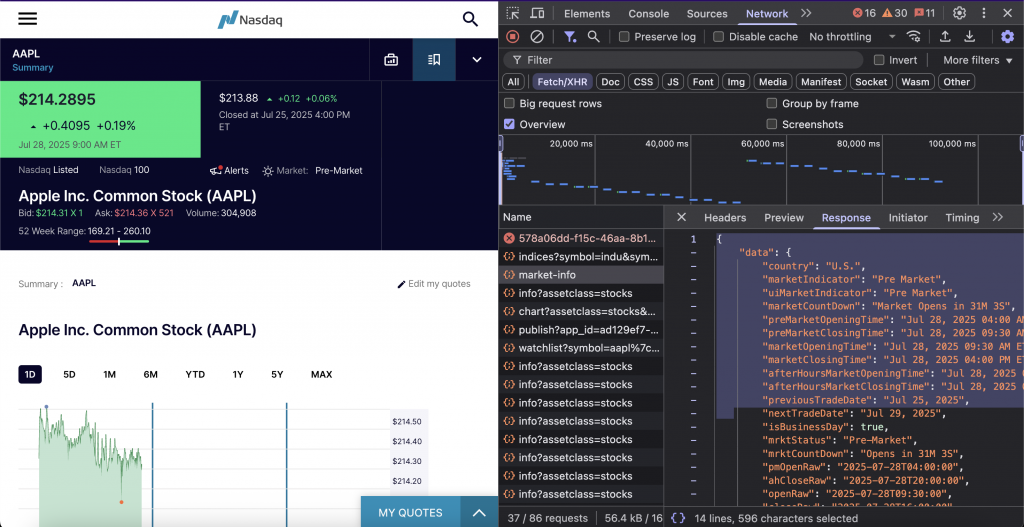
これらのエンドポイントを特定した上で、必要なツールをセットアップしよう。
前提条件
- Python 3.x
- コードエディタ(VS Code、PyCharmなど)
- Chrome Developer Toolsの基本的な操作方法
- Pythonスクレイピングの基礎とデータ抽出ライブラリの理解
requestsライブラリー。pip install requestsコマンドを使ってインストールします。
もしあなたがリクエストライブラリに慣れていないのであれば、Python requests guideでこのチュートリアルで使うテクニックをすべてカバーしています。
これらのツールの準備ができたので、最初の方法を探ってみよう。
方法1 – 直接APIアクセスによるウェブスクレイピング
我々が使用する主要なエンドポイントは、クリーンなJSONレスポンスを通じて包括的な市場データを提供する。
市場の状況と取引スケジュール
このエンドポイントは、カウントダウン情報と完全な取引スケジュールで米国市場の状況を返します。通常時間帯、市場前、時間外セッションをカバーし、簡単に統合できるように複数のタイムスタンプ形式で前と次の取引日を提供します。
終点はhttps://api.nasdaq.com/api/market-info。
簡単な実装を紹介しよう:
import requests
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
response = requests.get('https://api.nasdaq.com/api/market-info', headers=headers)
print(response.json())APIはこのような市場状況データを返す:
{
"data": {
"country": "U.S.",
"marketIndicator": "Market Open",
"uiMarketIndicator": "Market Open",
"marketCountDown": "Market Closes in 3H 7M",
"preMarketOpeningTime": "Jul 29, 2026 04:00 AM ET",
"preMarketClosingTime": "Jul 29, 2026 09:30 AM ET",
"marketOpeningTime": "Jul 29, 2026 09:30 AM ET",
"marketClosingTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketOpeningTime": "Jul 29, 2026 04:00 PM ET",
"afterHoursMarketClosingTime": "Jul 29, 2026 08:00 PM ET",
"previousTradeDate": "Jul 28, 2026",
"nextTradeDate": "Jul 30, 2026",
"isBusinessDay": true,
"mrktStatus": "Open",
"mrktCountDown": "Closes in 3H 7M",
"pmOpenRaw": "2026-07-29T04:00:00",
"ahCloseRaw": "2026-07-29T20:00:00",
"openRaw": "2026-07-29T09:30:00",
"closeRaw": "2026-07-29T16:00:00"
}
}素晴らしい!これは、リアルタイムのマーケットタイミングデータを取得するためのAPIアプローチを示している。
株価データ
NASDAQの気配エンドポイントでは、最新の価格、取引量、企業情報、市場統計など、あらゆる上場企業の詳細な株式データを提供しています。
エンドポイントはhttps://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks です。株式データについては、ティッカーシンボル(AAPL、TSLA)とアセットクラスが stocksに設定されている必要があります。
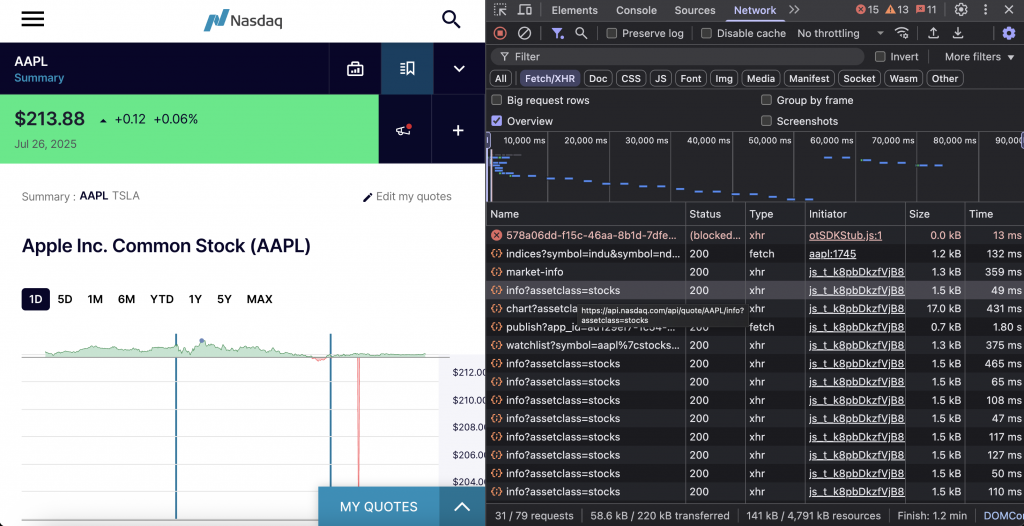
これが簡単なコード・スニペットだ:
import requests
def get_stock_info(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/info?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
stock_info = get_stock_info('AAPL', headers)
print(stock_info)APIはこのように株価データを返す:
{
"data": {
"symbol": "AAPL",
"companyName": "Apple Inc. Common Stock",
"stockType": "Common Stock",
"exchange": "NASDAQ-GS",
"isNasdaqListed": true,
"isNasdaq100": true,
"isHeld": false,
"primaryData": {
"lastSalePrice": "$211.9388",
"netChange": "-2.1112",
"percentageChange": "-0.99%",
"deltaIndicator": "down",
"lastTradeTimestamp": "Jul 29, 2026 12:51 PM ET",
"isRealTime": true,
"bidPrice": "$211.93",
"askPrice": "$211.94",
"bidSize": "112",
"askSize": "235",
"volume": "23,153,569",
"currency": null
},
"secondaryData": null,
"marketStatus": "Open",
"assetClass": "STOCKS",
"keyStats": {
"fiftyTwoWeekHighLow": {
"label": "52 Week Range:",
"value": "169.21 - 260.10"
},
"dayrange": {
"label": "High/Low:",
"value": "211.51 - 214.81"
}
},
"notifications": [
{
"headline": "UPCOMING EVENTS",
"eventTypes": [
{
"message": "Earnings Date : Jul 31, 2026",
"eventName": "Earnings Date",
"url": {
"label": "AAPL Earnings Date : Jul 31, 2026",
"value": "/market-activity/stocks/AAPL/earnings"
},
"id": "upcoming_events"
}
]
}
]
}
}企業のファンダメンタルズと主要指標
NASDAQのサマリーAPIは、あらゆる銘柄シンボルの時価総額、取引高、配当情報、セクター分類を含む主要な財務データを提供します。
NASDAQの企業ページにアクセスし、「主要データ」セクションまでスクロールすると、ブラウザは特定のエンドポイントを呼び出します。このエンドポイントはhttps://api.nasdaq.com/api/quote/{SYMBOL}/summary?assetclass=stocksで、その会社のすべてのファンダメンタルズ・データを含んでいます。
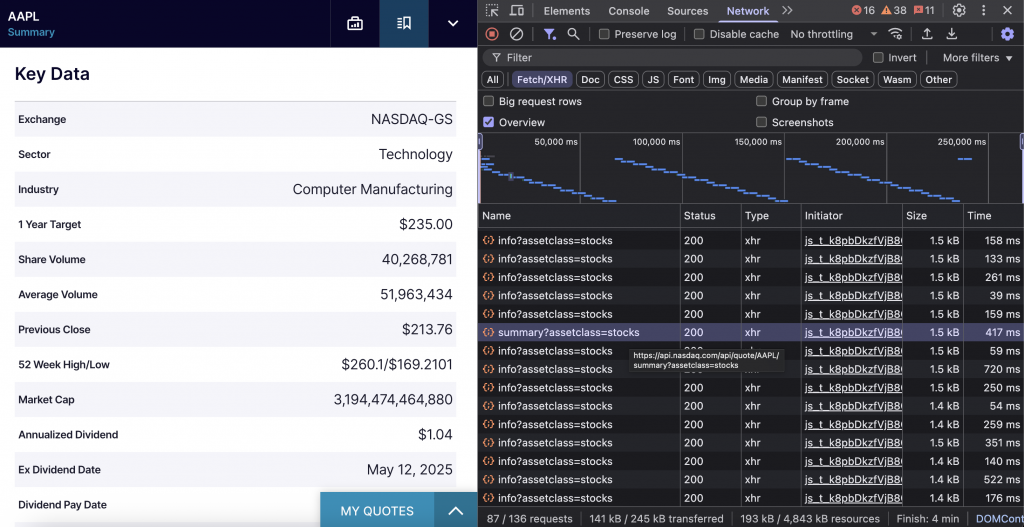
これがコード・スニペットだ:
import requests
def get_company_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/summary?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
company_data = get_company_data('AAPL', headers)
print(company_data)APIはこのように会社のキーデータを返す:
{
"data": {
"symbol": "AAPL",
"summaryData": {
"Exchange": {
"label": "Exchange",
"value": "NASDAQ-GS"
},
"Sector": {
"label": "Sector",
"value": "Technology"
},
"Industry": {
"label": "Industry",
"value": "Computer Manufacturing"
},
"OneYrTarget": {
"label": "1 Year Target",
"value": "$235.00"
},
"TodayHighLow": {
"label": "Today's High/Low",
"value": "$214.81/$210.825"
},
"ShareVolume": {
"label": "Share Volume",
"value": "25,159,852"
},
"AverageVolume": {
"label": "Average Volume",
"value": "51,507,684"
},
"PreviousClose": {
"label": "Previous Close",
"value": "$214.05"
},
"FiftTwoWeekHighLow": {
"label": "52 Week High/Low",
"value": "$260.1/$169.2101"
},
"MarketCap": {
"label": "Market Cap",
"value": "3,162,213,080,720"
},
"AnnualizedDividend": {
"label": "Annualized Dividend",
"value": "$1.04"
},
"ExDividendDate": {
"label": "Ex Dividend Date",
"value": "May 12, 2026"
},
"DividendPaymentDate": {
"label": "Dividend Pay Date",
"value": "May 15, 2026"
},
"Yield": {
"label": "Current Yield",
"value": "0.49%"
}
},
"assetClass": "STOCKS",
"additionalData": null,
"bidAsk": {
"Bid * Size": {
"label": "Bid * Size",
"value": "$211.75 * 280"
},
"Ask * Size": {
"label": "Ask * Size",
"value": "$211.79 * 225"
}
}
}
}NASDAQチャートとヒストリカルデータ
NASDAQは、異なる時間枠とデータ粒度用に設計された特別なエンドポイントを通じてチャートデータを提供する。

NASDAQは、タイムフレーム要件に基づき、エンドポイント間でチャートデータを分割する:
- 日中エンドポイント– 1Dおよび5D時間枠の分単位のデータ。
- ヒストリカルエンドポイント– 1M、6M、YTD、1Y、5Y、MAXタイムフレームの日次OHLCデータ。
日中チャートデータ(1Dタイムフレーム)
このエンドポイントは、取引セッション中の分単位の値動きを分析するのに最適である。
エンドポイントはhttps://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs です。
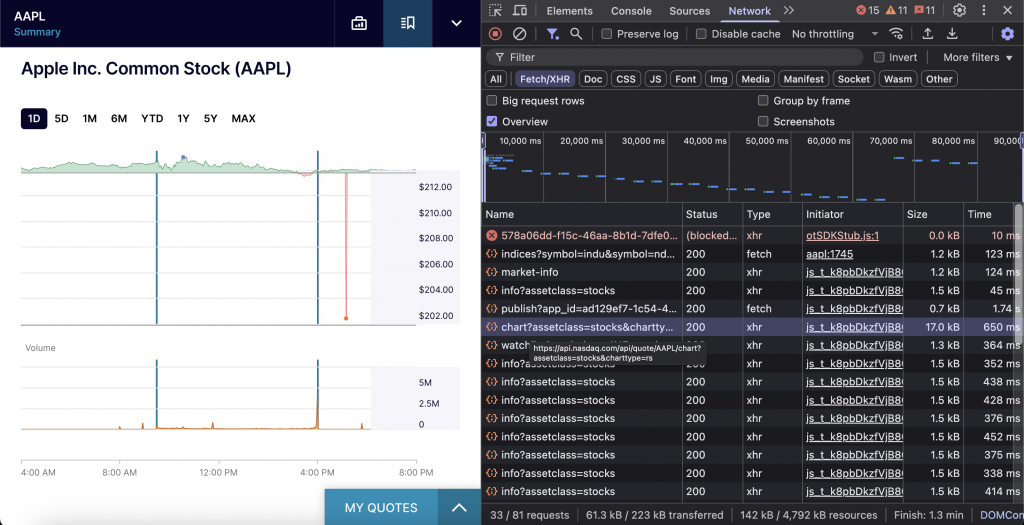
このエンドポイントには3つのパラメータが必要です:銘柄のティッカーシンボル、株式データのためのstocksに設定されたassetclass、そして通常の取引時間のためのcharttype=rsです。
簡単な実装を紹介しよう:
import requests
def get_chart_data(symbol, headers):
url = f'https://api.nasdaq.com/api/quote/{symbol}/chart?assetclass=stocks&charttype=rs'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
chart_data = get_chart_data('AAPL', headers)
print(chart_data)APIは、企業の日中データを以下のような構造で返す:
{
"data": {
"chart": [
{
"w": 995, // Trading volume for this minute
"x": 1753416000000, // Timestamp (milliseconds)
"y": 214.05, // Price
"z": { // Human-readable format
"time": "4:00 AM",
"shares": "995",
"price": "$214.05",
"prevCls": "213.7600" // Previous day's close
}
}
]
}
}5日分のデータについては、別のエンドポイントを使う必要がある:
https://charting.nasdaq.com/data/charting/intraday?symbol=AAPL&mostRecent=5&includeLatestIntradayData=1これは次のような構造のデータを返す(簡潔にするためにトリミングされている):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2026-07-22 09:30:00",
"Value": 212.639999,
"Volume": 2650933
},
{
"Date": "2026-07-22 09:31:00",
"Value": 212.577103,
"Volume": 232676
}
],
"latestIntradayData": {
"Date": "2026-07-28 16:00:00",
"High": 214.845001,
"Low": 213.059998,
"Open": 214.029999,
"Close": 214.050003,
"Change": 0.169998,
"PctChange": 0.079483,
"Volume": 37858016
}
}過去データ(1M、6M、YTD、1Y、5Y、MAX)
より長い時間枠については、NASDAQはヒストリカル・エンドポイントを通じて日次OHLCデータを提供している。
エンドポイントはhttps://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date={start}~{end}&である。
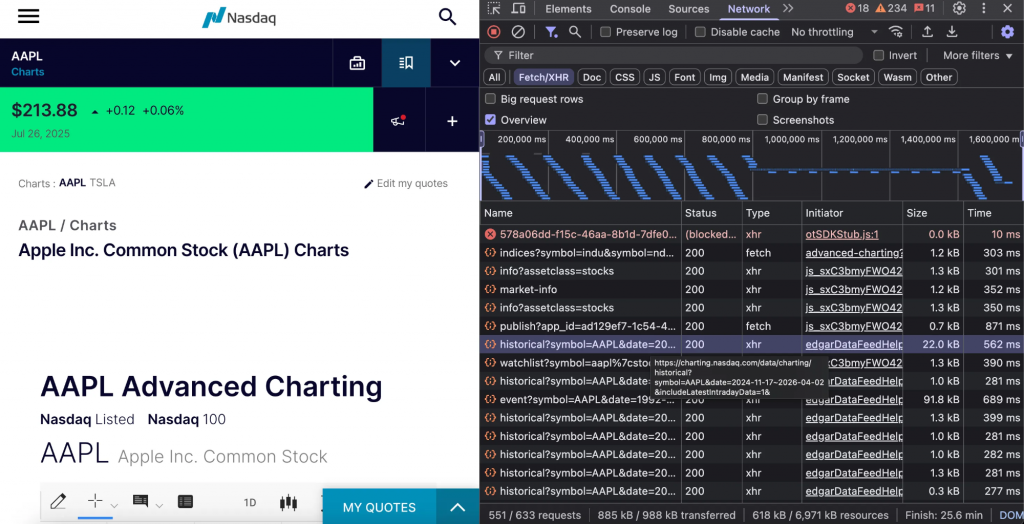
このエンドポイントには、株式ティッカー・シンボルと「YYYY-MM-DD~YYYY-MM-DD」形式の日付範囲が必要です。
これがサンプル・コードです:
import requests
def get_historical_data(symbol, headers):
url = f"https://charting.nasdaq.com/data/charting/historical?symbol={symbol}&date=2024-08-24~2024-10-23&"
response = requests.get(url, headers=headers)
return response.json()
headers = {
"accept": "*/*",
"referer": "https://charting.nasdaq.com/dynamic/chart.html",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
historical_data = get_historical_data("AAPL", headers)
print(historical_data)これは、以下のような構造のデータを返す(簡潔にするためにトリミングされている):
{
"companyName": "APPLE INC",
"marketData": [
{
"Date": "2024-11-18 00:00:00",
"High": 229.740000,
"Low": 225.170000,
"Open": 225.250000,
"Close": 228.020000,
"Volume": 44686020
}
],
"latestIntradayData": {
"Date": "2026-07-25 16:00:00",
"High": 215.240005,
"Low": 213.399994,
"Open": 214.699997,
"Close": 213.880005,
"Change": 0.120010,
"PctChange": 0.056143,
"Volume": 40268780
}
}ETFの保有
NASDAQ ETF Holdings APIは、保有上位10銘柄に特定の銘柄が含まれる上場投資信託(ETF)を特定します。このデータは機関投資家の保有パターンを示し、関連する投資機会の特定に役立ちます。
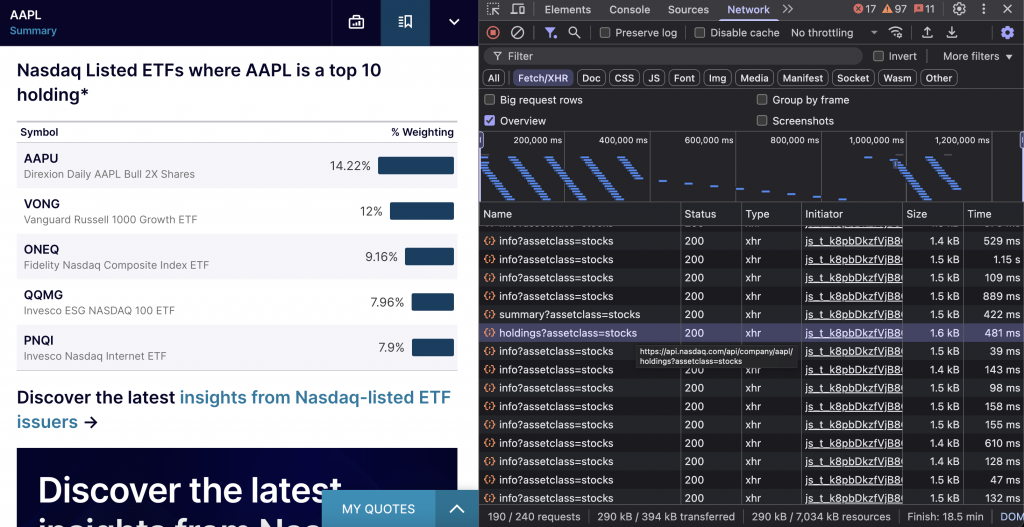
エンドポイントはhttps://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks です。
これが実装だ:
import requests
def get_holdings_data(symbol, headers):
url = f'https://api.nasdaq.com/api/company/{symbol}/holdings?assetclass=stocks'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
holdings_data = get_holdings_data('AAPL', headers)
print(holdings_data)APIはETFデータの2つのカテゴリーを返します: トップ10ポジションとしてその銘柄を保有するすべてのETFと、特に同じ条件でNASDAQに上場しているETFです。レスポンスには、加重パーセンテージ、ETFパフォーマンスデータ、およびファンドの詳細が含まれます。
{
"data": {
"heading": "ETFs with AAPL as a Top 10 Holding*",
"holdings": { ... }, // All ETFs with the stock as top 10 holding
"nasdaqheading": "Nasdaq Listed ETFs where AAPL is a top 10 holding*",
"nasdaqHoldings": { ... } // Specifically NASDAQ-listed ETFs
}
}最新ニュース
このエンドポイントは、特定の株式シンボルに関連する最近のニュース記事を取得します。ヘッドライン、出版物の詳細、関連するシンボル、記事のメタデータを含む詳細なニュース報道を提供します。
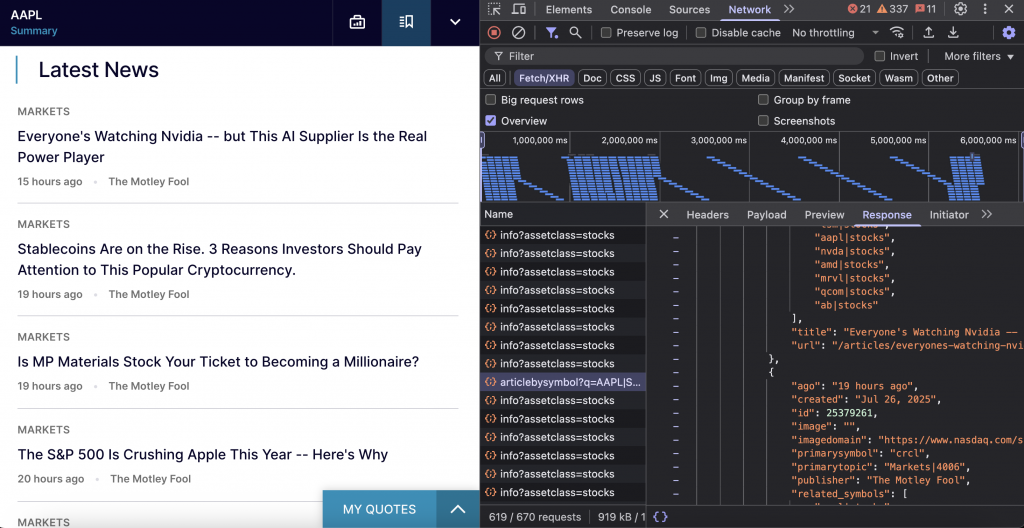
エンドポイントはhttps://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset={offset}&limit={limit}&fallback=true です。
合格に必要なもの
- q– 株式のティッカーシンボルに|STOCKS|の接尾辞を付けたもの(AAPL|STOCKSやMSFT|STOCKSのように)。
- offset– ページ分割のためにスキップするレコード数(0から始まります)。
- limit– 返す記事の最大数(デフォルトは10)。
- fallback– フォールバック動作を表すブール値のフラグ(推奨:true)。
簡単に実装してみよう:
import requests
def get_news_data(symbol, headers):
url = f'https://www.nasdaq.com/api/news/topic/articlebysymbol?q={symbol}|STOCKS&offset=0&limit=10&fallback=true'
response = requests.get(url, headers=headers)
return response.json()
headers = {
'accept': 'application/json',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36',
}
news_data = get_news_data('AAPL', headers)
print(news_data)APIは、次のような構造化されたJSONレスポンスを返す:
{
"data": {
"message": null,
"rows": [...], // Array of news articles
"totalrecords": 8905 // Total number of available articles
}
}各ニュース記事には詳細な情報が含まれている:
{
"ago": "15 hours ago",
"created": "Jul 26, 2026",
"id": 25379586,
"image": "",
"imagedomain": "https://www.nasdaq.com/sites/acquia.prod/files",
"primarysymbol": "tsm",
"primarytopic": "Markets|4006",
"publisher": "The Motley Fool",
"related_symbols": [
"tsm|stocks",
"aapl|stocks",
"nvda|stocks"
],
"title": "Everyone's Watching Nvidia -- but This AI Supplier Is the Real Power Player",
"url": "/articles/everyones-watching-nvidia-ai-supplier-real-power-player"
}APIはシンプルなオフセットベースのページネーションを使って、何千もの記事を効率的にナビゲートします。ページネーションの仕組みは以下の通りです:
- 最初のバッチ–
offset=0&limit=10記事1~10を検索 - 第2バッチ–
offset=10&limit=10記事11-20を検索。 - 第3バッチ–
offset=20&limit=10記事21-30を検索
次の記事セットを取得するには、オフセットをリミット値だけインクリメントする。
方法2 – NASDAQのデータスクレイピングを住宅プロキシでスケールアップする。
APIへの直接アクセスはほとんどのユースケースでうまく機能するが、企業レベルのデータ収集にスケールアップすると、ウェブスクレイピングに大きな課題が生じる。大量のオペレーションは、レート制限、ボット検出システム、データ収集を完全に停止させるIPブロックに直面する。
大規模なスクレイピングにおける主なボトルネックは、IPレピュテーション管理である。NASDAQのような金融サイトは、個々のIPアドレスからのリクエストパターンと頻度を積極的に監視する高度なアンチボットシステムを配備している。これらのシステムは、単一のIPソースからの自動化されたトラフィックパターンを検出すると、レート制限から完全なIP禁止まで、さまざまなブロックを実行します。
レジデンシャルプロキシは、実際の家庭のインターネット接続を介してリクエストをルーティングすることにより、これらの問題を解決します。これにより、リクエストは異なる地理的ロケーションに分散された正当なユーザートラフィックのように見え、アンチボットシステムをトリガーする可能性が大幅に減少します。
当社の住宅用プロキシインフラストラクチャは、195以上のロケーションに150M以上の住宅用IPを提供し、特に企業規模のデータ収集用に設計されています。新規ユーザーは、基本的な実装のためのクイックスタートガイドから始めることができ、高度な設定を必要とする企業のお客様は、当社の詳細なセットアップドキュメントを参照することができます。
Pythonリクエストで住宅用プロキシを設定するには、最小限の設定しか必要ありません。プロキシの認証情報を以下のように設定します:
proxies = {
'http': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}',
'https': 'http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}'
}これが完全な実装だ:
import requests
import urllib3
# Disable SSL warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
proxies = {
"http": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
"https": "http://brd-customer-{CUSTOMER_ID}-zone-{ZONE_NAME}:{PASSWORD}@brd.superproxy.io:{PORT}",
}
headers = {
"accept": "application/json, text/plain, */*",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36",
}
response = requests.get(
"https://www.nasdaq.com/api/news/topic/articlebysymbol?q=AAPL|STOCKS&offset=0&limit=10&fallback=true",
headers=headers,
proxies=proxies,
verify=False,
timeout=30,
)
print(f"Status Code: {response.status_code}")
print(response.json())この住宅用プロキシのセットアップでは、レート制限をトリガーすることなく、異なるIPアドレス間で数百または数千の同時リクエストを実行することができます。
また、集中プロキシ管理、リアルタイムリクエスト監視、高度なローテーション設定など、プロキシ運用の高度な制御を提供する無料のオープンソースプロキシマネージャツールも提供しています。私たちのセットアップガイドが設定プロセスを説明します。
方法3 – MCPによるAIを活用したNASDAQデータのスクレイピング
Model Context Protocolは、AIとデータの統合を標準化し、ウェブスクレイピングインフラストラクチャとの自然言語インタラクションを可能にします。Bright DataのMCP実装は、データ収集ソリューションとAIを活用した抽出を組み合わせ、会話型インターフェイスを通じてスクレイピング操作を合理化します。
この金融データ抽出用MCPサーバーは、ウェブデータインフラストラクチャを活用することで、エンドポイントの発見、ヘッダー管理、ボット対策の複雑さを簡素化します。このシステムは、構造化されたデータ出力を提供しながら、JavaScriptレンダリング、動的コンテンツ、セキュリティシステムを処理し、NASDAQのような最新のウェブサイトからインテリジェントにナビゲートし、データを抽出します。
それでは、Bright Data MCPとClaudeデスクトップを統合して、実際に使ってみましょう。Claudeデスクトップアプリケーションに移動し、Settings > Developer > Edit Configに進みます。claude_desktop_config.jsonファイルが表示されるので、以下の設定を追加します:
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "<your-brightdata-api-token>",
"WEB_UNLOCKER_ZONE": "<optional – override default zone name 'mcp_unlocker'>",
"BROWSER_AUTH": "<optional – enable full browser control via Scraping Browser>"
}
}
}
}構成要件:
- APIトークン– Bright Dataアカウントを設定し、ダッシュボードからAPIトークンを生成します。
- Web Unlockerゾーン– Web Unlockerゾーン名を指定するか、デフォルトの
mcp_unlockerを使用します。 - スクレイピングブラウザ(Browser API)設定– ダイナミックコンテンツシナリオのために、JavaScriptでレンダリングされたページのためにBrowser APIを設定します。ブラウザAPIゾーンの[概要]タブから、
ユーザー名:パスワードの認証情報を使用します。
設定が完了したら、Claude デスクトップアプリケーションを終了し、再度開きます。Bright Data オプションが表示され、MCP ツールが Claude 環境に統合されたことがわかります。

ClaudeとBright Data MCPの統合により、コードを書くことなく、会話のプロンプトを通してデータを抽出することができます。
プロンプトの例:“NASDAQ URL から JSON フォーマットでキーデータを抽出: https://www.nasdaq.com/market-activity/stocks/aapl.NASDAQはJavaScriptレンダリングを使用しているため、ダイナミックローディングを処理する。”
プロンプトが表示されたら、ツールの許可を許可します。システムは自動的にBright Data MCPツールを呼び出し、ブラウザAPIを使用してJavaScriptレンダリングを処理し、アンチボット保護をバイパスします。そして、包括的な株式情報を含む構造化されたJSONデータを返します。
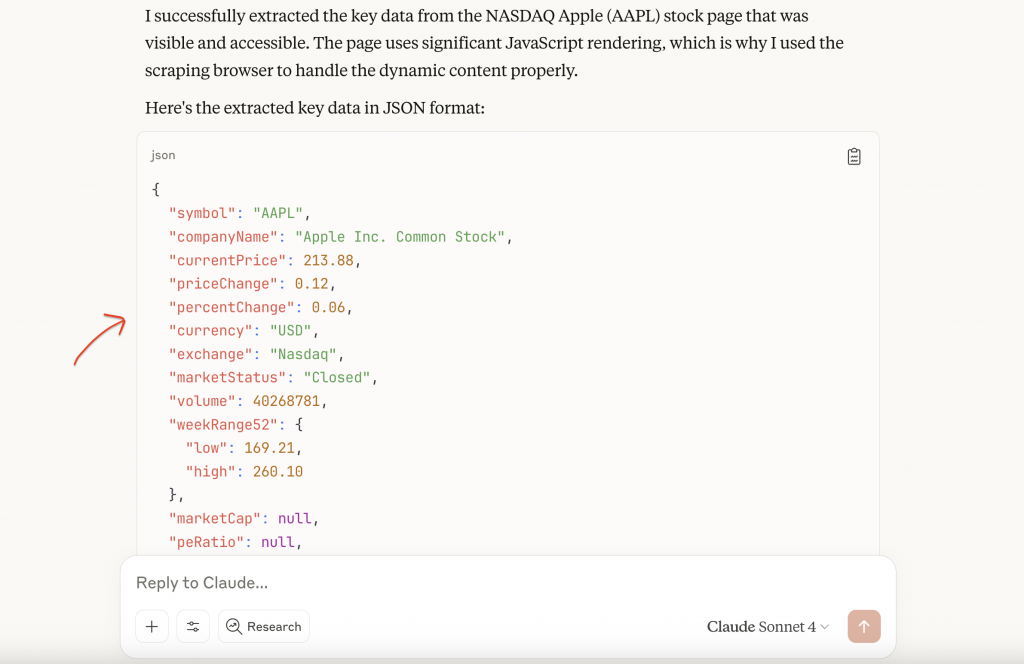
これは、金融データ抽出のためのMCPの1つのアプリケーションを示している。AIワークフローを構築するチームは、複数のMCPサーバーを組み合わせて異なる機能を提供するのが常である。
主要なMCPサーバーの概要では、ウェブデータの抽出やブラウザの自動化からコード統合やデータベース管理まで、各プロバイダーのユニークな機能を比較し、紹介しています。
結論
NASDAQ データを効果的にスクレイピングするには、特定のニーズに適したアプローチを選択する必要があります。基本的なスクレイピングは少量のデータ抽出には有効ですが、プロダクション・アプリケーションは、堅牢なプロキシ・インフラとエンタープライズ・ソリューションから大きな恩恵を受けます。
企業レベルの財務データソリューションを必要とする組織にとって、さまざまな選択肢を評価する価値はあります。主要な財務データ・プロバイダーに関する当社の分析は、カスタムスクレーパーの構築と専門ベンダーからのデータセットの購入のどちらを選択するかを決める際に役立ちます。
金融データセットだけでなく、Bright Dataの広範なマーケットプレイスでは、ビジネスデータセット、ソーシャルメディアデータセット、不動産データセット、eコマースデータセット、その他多数のデータセットを提供しています。
多くのデータセットオプションと収集アプローチがある中で、ブライトデータのどの製品とサービスがお客様の特定の要件に最も適しているか、当社のデータエキスパートにご相談ください。





