

この記事では、財務データを手動で収集する方法や、Bright Data財務データスクレイパーAPIを使用してプロセスを自動化する方法を学びます。
スクレイピングしたいコンテンツとその構成について知っておく
財務データには、広範で複雑な情報が含まれることが一般的です。スクレイピングを開始する前には、必要なデータの種類を確実に特定しておく必要があります。
例として、株式の最新価格だけでなく、その日の始値・終値や高値・安値、また時間の経過とともに発生した価格変動情報のスクレイピングが必要となる場合があります。また業績の評価には、会社の損益計算書、貸借対照表(資産と負債の概要)、キャッシュフロー計算書(入出金の追跡)などの財務情報も必要となります。財務比率やアナリストによる評価、レポートは売買時の意思決定の指針となり、最新情報やSNSの心理分析は市場動向についてのさらなるインサイトを提供します。
ウェブページ上のデータ構成を理解しておくことにより、必要なデータの特定とスクレイピングが簡単に実現します。
法的および倫理的考慮事項を分析する
ウェブサイトをスクレイピングする前に、当該サイトの利用規約を必ず確認しましょう。多くのウェブサイトは、事前の同意や許可なしでのスクレイピングを禁止しています。
また、 robots.txt ファイルのルールに従う必要があります。このファイルには、サイトのどの部分にアクセスできるかが記載されています。また、リクエストによりサーバーが過負荷状態にならないようにし、リクエスト間には遅延を実装するようにしましょう。これにより、ウェブサイトのリソースを保護し、あらゆる問題を回避することができます。
ブラウザ開発ツールを使用する
ウェブページのHTML要素を表示するには、ブラウザの開発者ツールを使用します。これらのツールは、ChromeやSafari、Edgeなど、ほとんどの最新ブラウザに組み込まれています。開発者ツールを開くには、Windowsでは Ctrl+Shift+I 、Macでは Cmd+Option+I を押すか、ページを右クリックして 要素を検証を選択します。
ツールが開き次第、ページのHTML構造を検証し、特定のデータ要素を識別することができます。 Elements タブにはドキュメントオブジェクトモデル(DOM)ツリーが表示され、ページ上の要素を見つけて強調表示することができます。 Network タブにはすべてのネットワークリクエストが表示され、APIエンドポイントや動的に読み込まれたデータを検索するのに役立ちます。 Console タブでは、JavaScriptコマンドを実行したり、ページのスクリプトを操作したりすることができます。
このチュートリアルでは、 Yahoo!ファイナンスから APPL株をスクレイピングします。関連するHTMLタグを特定するには、 APPL株 ページに移動し、ページに表示されている価格を右クリックして、 要素を検証をクリックします。 Elements タブでは、価格を含むHTML要素が強調表示されます。

スクレイパーでこの要素を見つけやすいように、タグ名や、 class または idなどの固有の属性を記録しておきましょう。
環境およびプロジェクトの設定方法
このチュートリアルでは、簡潔なだけでなく、優れたライブラリが利用可能な [Python]((https://www.python.or) をWebスクレイピングに使用します。開始する前には、必ずシステムに Python 3.10以上 がインストールされていることを確認しましょう。
Pythonを入手し次第、ターミナルまたはシェルを開き、次のコマンドを実行してディレクトリおよび仮想環境を作成します。
mkdir scrape-financial-data
cd scrape-financial-data
python3 -m venv myenv
仮想環境は、作成後にアクティブにする必要があります。アクティベーションコマンドはオペレーティングシステムによって異なります。
Windowsの場合、次のコマンドを実行します。
.myenvScriptsactivate
macOS/Linuxの場合、次のコマンドを実行します。
source myenv/bin/activate
仮想環境を有効にしたら、 pipを使用して必要なライブラリをインストールします。
pip3 install requests beautifulsoup4 lxml
このコマンドは、HTTPリクエストの処理には Requests ライブラリ、HTMLコンテンツの解析には Beautiful Soup 、またXMLとHTMLの効率的な解析には lxml をインストールします。
財務データを手動でスクレイピングする方法
財務データを手動でスクレイピングするには、 manual_scraping.py という名前のファイルを作成し、次のコードを追加して必要なライブラリをインポートします。
import requests
from bs4 import BeautifulSoup
スクレイピングしたい財務データのURLを設定します。前述のとおり、このチュートリアルではApple株(AAPL)について記載された Yahoo!ファイナンス のページを使用します。
url = 'https://finance.yahoo.com/quote/AAPL?p=AAPL&.tsrc=fin-srch'
URLを設定したら、次のURLにGETリクエストを送信します。
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
このコードには、ブラウザのリクエストを模倣する User-Agent ヘッダーが含まれており、ターゲットウェブサイトによるブロックを回避するのに役立ちます。
このとおり、リクエストが成功したことを確認します。
if response.status_code == 200:
print('Successfully retrieved the webpage')
else:
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')
exit()
次に、 lxml パーサを使用してウェブページのコンテンツを解析します。
soup = BeautifulSoup(response.content, 'lxml')
固有の属性に基づいて要素を特定し、テキストの内容を抽出して、抽出されたデータを出力します。
# Extract specific company details
try:
# Extract specific company details
previous_close = soup.find('fin-streamer', {'data-field': 'regularMarketPreviousClose'}).text.strip()
open_price = soup.find('fin-streamer', {'data-field': 'regularMarketOpen'}).text.strip()
day_range = soup.find('fin-streamer', {'data-field': 'regularMarketDayRange'}).text.strip()
week_52_range = soup.find('fin-streamer', {'data-field': 'fiftyTwoWeekRange'}).text.strip()
market_cap = soup.find('fin-streamer', {'data-field': 'marketCap'}).text.strip()
# Extract PE Ratio (TTM)
pe_label = soup.find('span', class_='label', title='PE Ratio (TTM)')
pe_value = pe_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Extract EPS (TTM)
eps_label = soup.find('span', class_='label', title='EPS (TTM)')
eps_value = eps_label.find_next_sibling('span').find('fin-streamer').text.strip()
# Print the scraped details
print("n### Stock Price ###")
print(f"Open Price: {open_price}")
print(f"Previous Close: {previous_close}")
print(f"Day's Range: {day_range}")
print(f"52 Week Range: {week_52_range}")
print("n### Company Details ###")
print(f"Market Cap: {market_cap}")
print(f"PE Ratio (TTM): {pe_value}")
print(f"EPS (TTM): {eps_value}")
except AttributeError as e:
print("Error while scraping data. Some fields may not be found.")
print(e)
コードを実行してテストする
コードをテストするには、ターミナルまたはシェルを開き、次のコマンドを実行します。
python3 manual_scraping.py
次のように出力されるはずです。
Successfully retrieved the webpage
### Stock Price ###
Open Price: 225.20
Previous Close: 225.00
Day's Range: 225.18 - 229.74
52 Week Range: 164.08 - 237.49
### Company Details ###
Market Cap: 3.447T
PE Ratio (TTM): 37.50
EPS (TTM): 37.50
手動スクレイピングで課題に対処する
データの手動スクレイピングは、回避戦略が必要となるCAPTCHAやIPブロックの発生など、さまざまな理由で困難になる場合があります。データが乱雑であったり、構造化されていなかったりすると、解析エラーの原因となる可能性があり、適切な権限なしでのスクレイピングは、法的な問題を引き起こす可能性があります。また、ウェブサイトの頻繁な更新によってスクレイパーが機能しなくなり、継続的な機能のために定期的なコードのメンテナンスが必要になる場合があります。
スクレイパーを構築して自動化するには、データの分析ではなく、コードの作成および修正により多くの時間を費やす必要があります。大量のデータを扱う際には、データがクリーンで整理されていることを確認する必要があるため、さらに困難になる可能性があります。さまざまなウェブサイトの構造を管理する場合、あらゆるウェブ技術について理解しておく必要があります。
これは、データを頻繁かつ迅速にスクレイピングする必要がある場合、手動によるWebスクレイピングが最適な選択肢ではないことを意味します。
Bright Data財務データスクレイパーAPIを使用してデータをスクレイピングする方法
Bright Data は、データ抽出の自動化を行う財務データスクレイパーAPIにより、手動スクレイピングの課題に対処しています。このAPIには、IPブロックを防ぐためのローテーションプロキシによるプロキシ管理が組み込まれています。JSONやCSVなどの形式で構造化データを返し、拡張性も高いため、大量のデータを簡単に処理することができます。
財務データスクレイパーAPIを使用するには、 Bright Dataのウェブサイトで無料アカウントの登録を行ってください。メールアドレスを確認し、必要な本人確認手順をすべて完了してください。
アカウントを設定したら、ログインしてダッシュボードにアクセスし、APIキーを取得します。
財務データスクレイパーAPIを設定する
ダッシュボード内の左側のナビゲーションタブから、 WebスクレイパーAPI に移動します。 カテゴリ から
財務データ を選択し、 Yahoo!ファイナンスのビジネス情報 – URLで収集をクリックして開きます。
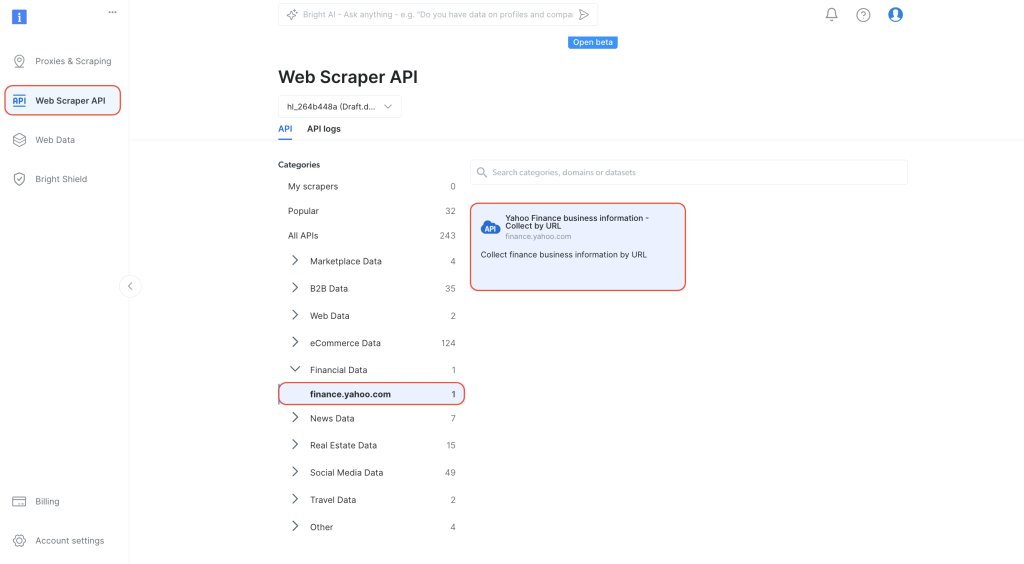
API呼び出しの設定を開始をクリックします。
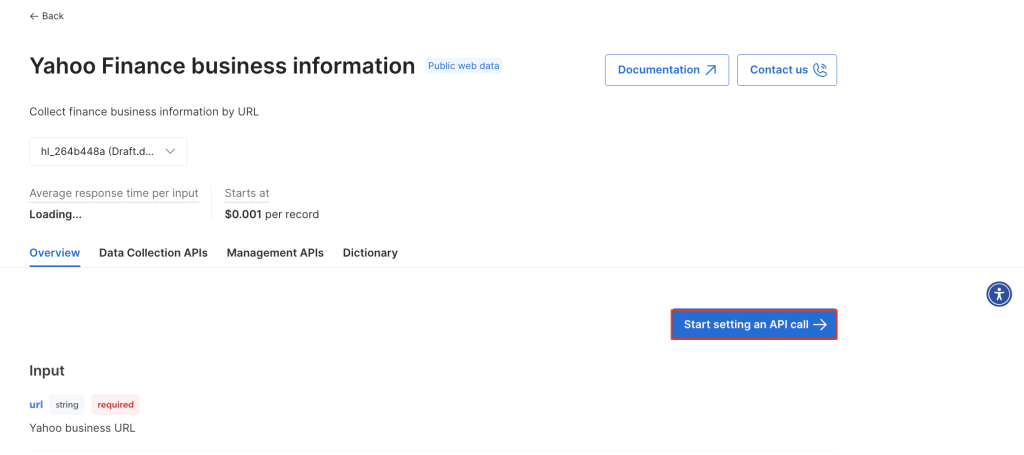
APIを使用するには、Bright DataスクレイパーでのAPI呼び出しを認証するトークンを作成する必要があります。新しいトークンを作成するには、 トークンの作成をクリックします。

ダイアログが開きます。 権限 を「管理者」に、期間を「無制限」に設定します。

この情報を保存すると、トークンが作成され、新しいトークンの入力が求められます。これはすぐにまた必要になるため、必ず安全な場所に保存しておきましょう。
トークンがすでに作成されている場合、 APIトークンの ユーザー設定から取得することができます。ユーザーの 詳細 タブを選択し、 トークンのコピー をクリックします。
スクレイパーを実行して財務データを取得する
Yahoo!ファイナンスのビジネス情報 ページより、 APIトークン フィールドにAPIトークンを追加し、ターゲットウェブサイトの株式URL( https://finance.yahoo.com/quote/AAPL/)を追加します。右側の 認証済みリクエスト セクションにあるリクエストをコピーします。
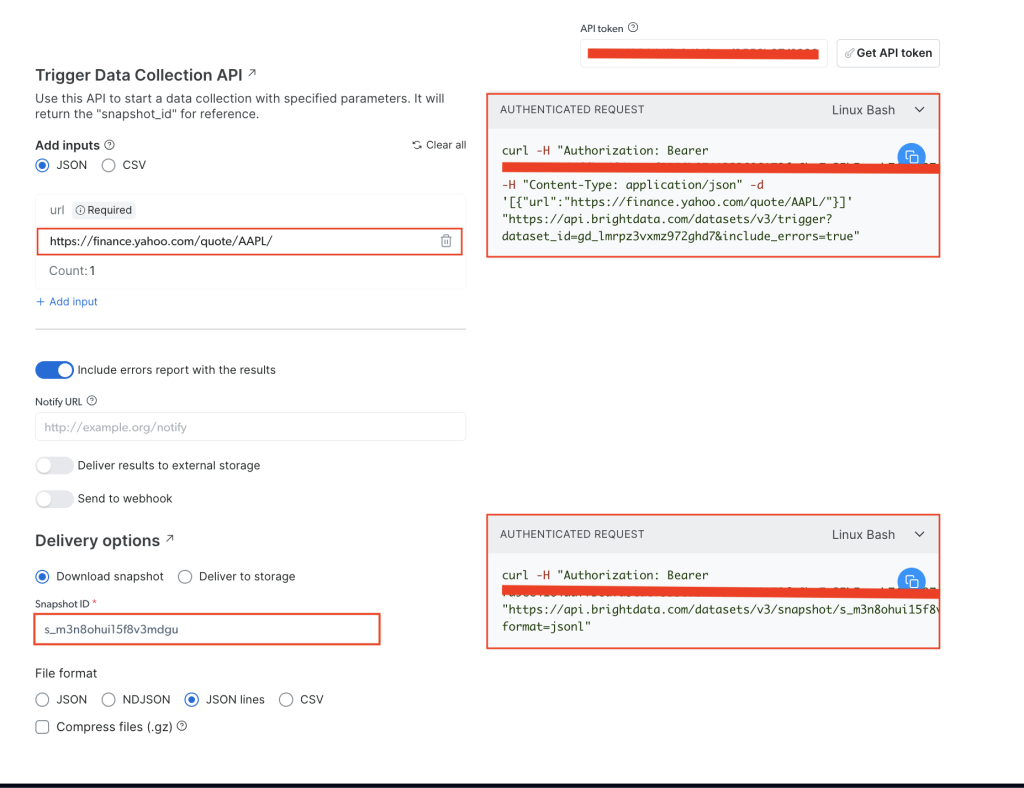
ターミナルまたはシェルを開き、 curlを使用してAPI呼び出しを実行します。次のように表示されるはずです。
curl -H "Authorization: Bearer YOUR_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://finance.yahoo.com/quote/AAPL/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=YOUR_DATA_SET_ID&include_errors=true"
コマンドを実行すると、 snapshot_id というレスポンスが返されます。
{"snapshot_id":"s_m3n8ohui15f8v3mdgu"}
snapshot_id をコピーして、ターミナルまたはシェルから次のAPI呼び出しを実行します。
curl -H "Authorization: Bearer YOUR_TOKEN" "https://api.brightdata.com/datasets/v3/snapshot/YOUR_SNAP_SHOT_ID?format=jsonl"
YOUR_TOKENとYOUR_SNAP_SHOT_IDの欄は、必ずご自身の認証情報に置き換えてください。
このコードを実行すると、スクレイピングされたデータが出力されるはずです。データは、次の JSONファイルのように表示されるはずです。
スナップショットが準備できていないというレスポンスが返された場合は、10秒待ってから再試行してください。
HTML構造を分析したり、特定のタグを見つけたりする必要なく、Bright Data財務データスクレイパーAPIにより、必要なデータがすべて抽出されました。 earning_estimate、 earnings_history、 growth_estinatesなどの追加フィールドを含む、ページ全体のデータが取得されました。
このチュートリアルで使用されたコードは、 このGitHubリポジトリより利用可能です。
Bright Data APIを使用するメリット
Bright Data財務データスクレイパーAPIでは、スクレイピングコードを書いたり管理したりする必要がないため、スクレイピングプロセスが簡素化されます。また、このAPIはプロキシローテーションを管理し、ウェブサイトの利用規約を厳守することでコンプライアンス遵守の徹底も行うため、ブロックされたりルールに違反したりすることを恐れずにデータを収集することができます。
Bright Data財務データスクレイパーAPIは、必要最低限のコーディングで信頼性の高い構造化データを提供します。ページナビゲーションとHTML解析が自動的に処理されるため、プロセスが効率化されるのです。また、APIの拡張性により、コードに大きな変更を加えることなく、数多くの株式およびその他の財務指標に関するデータを収集することができます。ウェブサイトの構造が変更されるとBright Dataによりスクレイパーが更新されるため、メンテナンスも最小限に抑えられ、余分な作業なしでデータ収集をスムーズに継続することができます。
まとめ
財務データの収集は、財務分析やアルゴリズム取引、市場調査に携わる開発者やデータチームにとって重要なタスクです。今回の記事では、Pythonと Bright Data財務データスクレイパーAPIを使用して財務データを手動でスクレイピングする方法を学びました。データの手動スクレイピングでは制御が可能となりますが、スクレイピング対策やメンテナンスのオーバーヘッドを処理するのは難しく、拡張も困難です。
Bright Data財務データスクレイパーAPIは、プロキシローテーションやCAPTCHA解決などの複雑なタスクを管理することにより、データ収集の効率化を実現します。API以外にも、 Bright Data は データセットや 住宅用プロキシ、 Web スクレイピングプロジェクトを強化するためのスクレイピングブラウザ などを提供しています。 無料トライアルに登録し 、Bright Dataが提供する機能のすべてを体験しましょう。






