

Rustによるウェブスクレイピング完全ガイド
このガイドでは以下を学びます:
- – Rustがウェブスクレイピングに適した言語かどうか
- 最適なRustウェブスクレイピングライブラリとは。
- Rustでウェブスクレイパーを構築する方法
- スクレイピング作業を倫理的かつ尊重ある方法で実施する方法
さっそく見ていきましょう!
Rustはウェブスクレイピングに適した言語か?
Rustは、セキュリティ、パフォーマンス、並行性に重点を置いた静的型付けプログラミング言語です。近年、その高い効率性から人気を集めています。そのため、ウェブスクレイピングを含む様々なアプリケーションに最適な選択肢となります。
Rustはオンラインウェブスクレイピングに有益な機能を提供します。特に堅牢な並行処理モデルにより、複数のウェブリクエストを同時に実行可能です。この特性により、多様なウェブサイトから大量のデータを効率的に抽出する多目的言語としての地位を確立しています。
さらに、RustのエコシステムにはHTTPクライアントやHTMLパースライブラリが含まれており、ウェブページの取得やデータ抽出のプロセスを効率化します。代表的なライブラリをいくつか見てみましょう!
Rust向けウェブスクレイピングライブラリベストセレクション
最も人気があり広く採用されているRustウェブスクレイピングライブラリには以下が含まれます:
- reqwest: Rust向けの強力なHTTPクライアント。シームレスなウェブリクエストとインタラクションを実現。
- スクレイパー: Rustの柔軟なHTMLパースライブラリ。HTML文書からの効率的なデータ抽出を実現します。
- rust-headless-chrome: Rustを用いたヘッドレスChromeブラウザの自動化を提供し、動的なウェブスクレイピングのための堅牢なソリューションを実現します。
- thirtyfour: SeleniumのRustバインディング。ウェブブラウザとの連携による自動テストとウェブスクレイピングを実現します。
前提条件
以下の手順に従って、Rust コードを記述する準備をしてください。
環境設定
開始前に、コンピュータに Rust がインストールされている必要があります。既にインストールされているか確認するには、ターミナルを開き、次のコマンドを入力してください:
rustc --version以下のような結果が表示されれば準備完了です:
rustc 1.75.0 (82e1608df 2023-12-21)Rustを最新版に更新するには:
rustup updateこのコマンドがエラーを返す場合は、Rustをインストールする必要があります。公式サイトからインストーラーをダウンロードし、起動してウィザードに従ってください。これにより以下が設定されます:
- rustup: Rustプログラミング言語用のインストーラーおよびバージョン管理ツール。様々なツールチェーンのインストールと管理を容易にします。
- cargo: Rustの公式パッケージマネージャーおよびビルドツール。依存関係の管理とRustプロジェクトのビルドプロセスを効率化します。
開いているターミナルウィンドウをすべて閉じ、このセクションの冒頭にあるコマンドを再度実行してください。今回は期待通りの結果が得られます。
素晴らしい!これでRust環境が整いました!
Rustプロジェクトの作成
simple_rust_web_scraper という名前の新しい Rust プロジェクトを作成したいとします。ターミナルを開き、次のcargo newコマンドを実行します:
cargo new simple_rust_web_scraperすべてが正常に進行した場合、以下のメッセージが表示されます:
バイナリ(アプリケーション)`simple_rust_web_scraper` パッケージを作成しました具体的には、このコマンドにより simple_rust_web_scraper フォルダが作成されます。このフォルダを開くと、以下の内容が含まれていることが確認できます:
- Cargo.toml: プロジェクトの依存関係を指定するマニフェストファイル。
- src/: Rustファイルを配置するフォルダ。デフォルトでサンプルmain.rsファイルが生成されます。
Rust IDEでsimple_rust_web_scraperを開きます。例えば、Rust拡張機能付きのVisual Studio Codeが最適です:
src/フォルダ内を移動し、main.rsファイルを開くと、以下のコードが表示されます:
fn main() {
println!("Hello, world!");
}これは単にターミナルに「Hello, world!」を出力するシンプルなRustスクリプトです。特にmain()関数はRustアプリケーションのエントリポイントであり、ここにスクレイピングロジックを記述します。
素晴らしい!あとは新しいRustプロジェクトが動作するか確認するだけです!
IDEのターミナルを開き、次のコマンドを実行してRustアプリケーションをコンパイルします:
cargo buildプロジェクトのルートフォルダに、いくつかのバイナリファイルを格納した target/ フォルダが出現します。
コードに関連付けられたコンパイル済みバイナリ実行ファイルを以下で実行します:
cargo runするとターミナルに以下が表示されます:
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
Hello, world!最初の2行はログ情報なので無視して構いません。最後の行に注目し、プロジェクトが期待通り「Hello, World!」メッセージを出力したことを確認してください。
完璧です!これでRustプロジェクトが完成しました。さあ、Rustでウェブスクレイピングロジックを書き始めましょう!
RustでWebスクレイパーを構築する方法
このステップバイステップチュートリアルでは、Rustでウェブスクレイピングを実行する方法を学びます。具体的には、Scrape This Site Countryサンドボックスから自動的にデータを収集するRustウェブスクレイパーを構築します。対象ページは以下のようになっています:
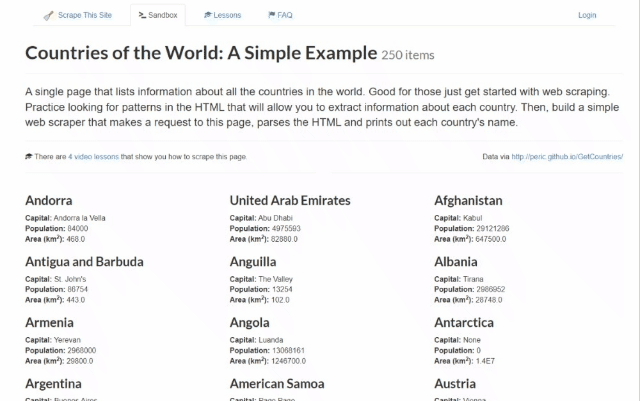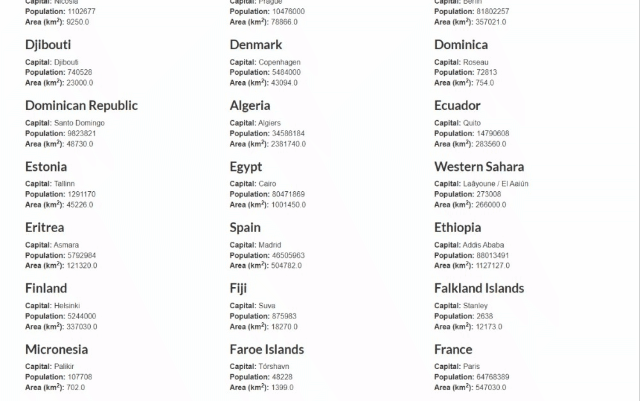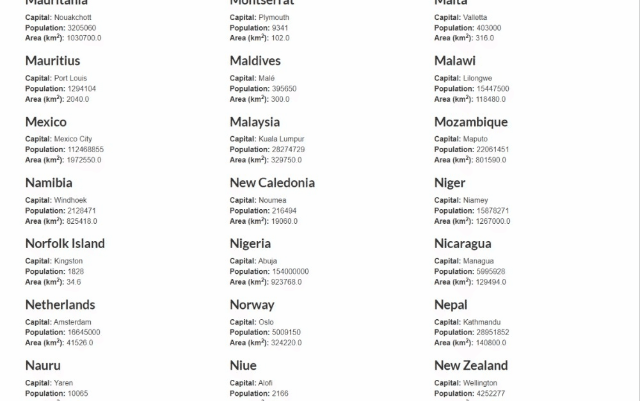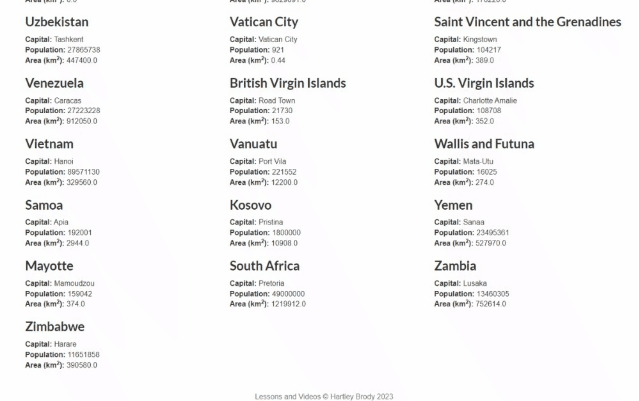
ご覧の通り、世界の全国のリストと、それらに関する興味深い情報が掲載されています。
Rustウェブスクレイピングスクリプトが実行する処理は以下の通りです:
- 対象ページに接続し、HTMLをパースします。
- ページから国を表すHTML要素を選択します。
- それらからデータを抽出し、Rustのデータ構造に格納します。
- 収集したデータをCSVなどの人間が読みやすい形式に変換します。
以下の手順に従ってスクレイピング目標を達成しましょう!
ステップ #1: 対象サイトの調査
Rustでウェブスクレイピングを行うにはいくつかのライブラリをインストールする必要がありますが、どのライブラリが特定のシナリオに最適でしょうか?これには、対象サイトが静的コンテンツページか動的コンテンツページかを判断する必要があります。そのため、ブラウザでサイトにアクセスしてください。
対象ページに移動し、空白部分を右クリックして「要素を検査」を選択し、開発者ツールを開きます。「ネットワーク」タブに移動し、ページを再読み込みします。「Fetch/XHR」セクションに表示される内容に注目してください:
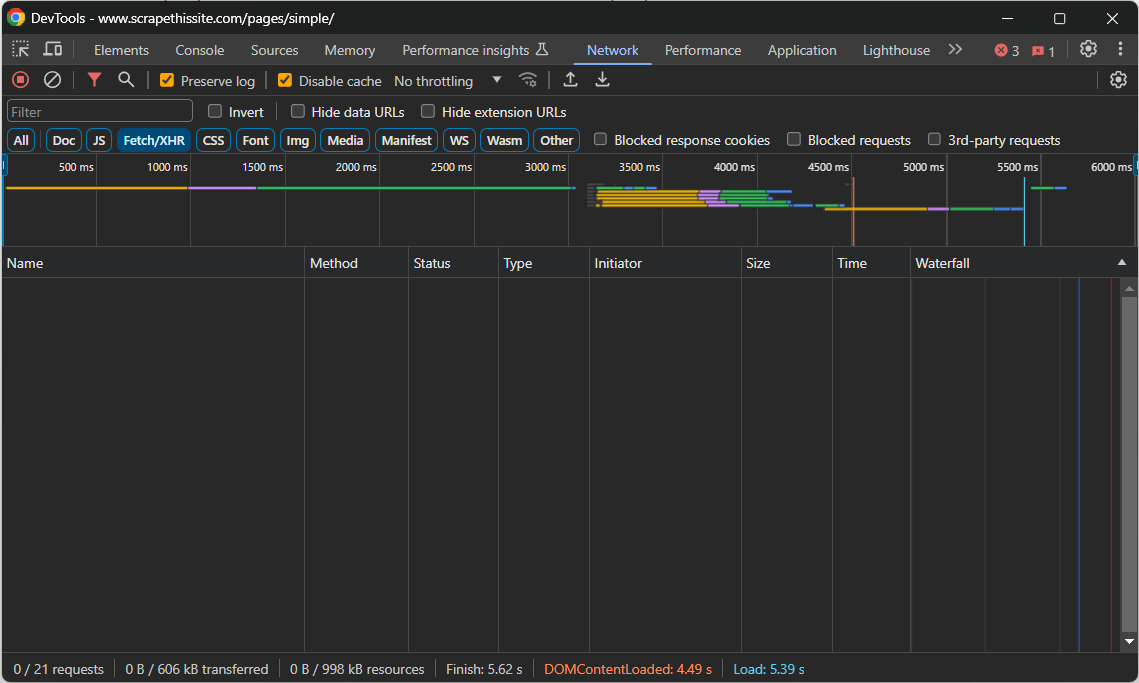
ページが読み込み・レンダリングされている間は、このセクションは空のままです。これは、そのウェブページがAJAXリクエストを一切行わないことを意味します。つまり、JavaScriptを介してクライアント側で動的にデータを取得していないのです。したがって、これは静的コンテンツページであり、HTML文書自体に既に必要なデータが全て含まれています。
さらに確認するため、右クリックして「ページのソースを表示」を選択します:
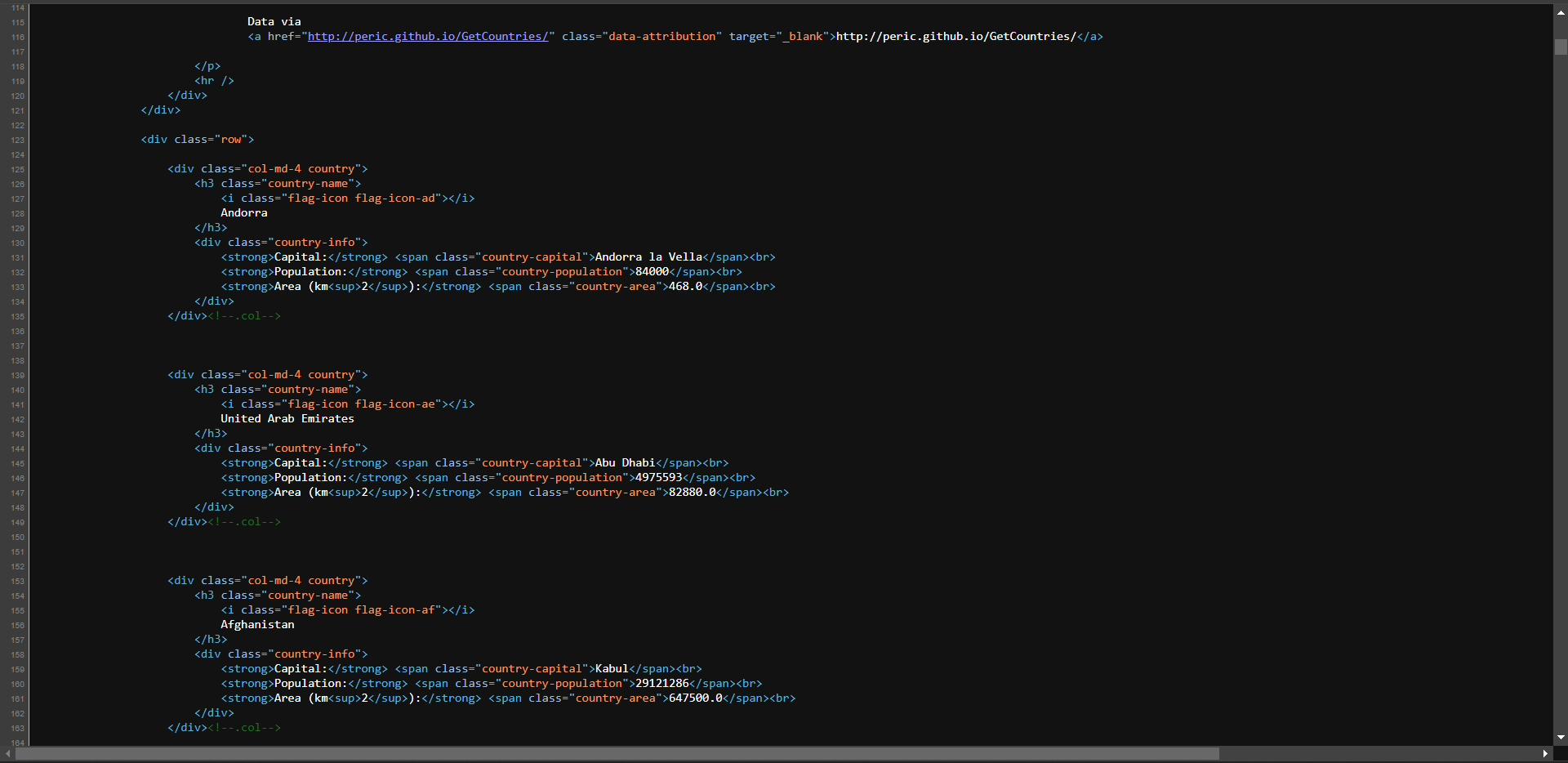
コードを確認すると、ページ内の全データがサーバーから返されるHTMLに埋め込まれていることがわかります。
複数ページから成るサイトでは、対象となる全ページでこの手順を繰り返します。
対象ページがJavaScriptを使用しないため、rust-headless-chromeのようなブラウザ自動化ライブラリは不要です。使用することも可能ですが、Chromeの実行には時間とリソースを要するため、パフォーマンスのオーバーヘッドが生じるだけで実質的な利点はありません。
代わりに、HTTPクライアントライブラリでページのHTMLドキュメントを取得し、HTMLパーサーライブラリでデータを抽出する手法を採用すべきです。つまり、必要なRustウェブスクレイピングライブラリはreqwestとスクレイパーの2つです!
ステップ #2: スクラッピングライブラリのインストール
reqwestとスクレイパーをインストールしましょう。
プロジェクトのルートフォルダでターミナルを開くか、IDEのターミナルを使用します。以下のコマンドを実行して、プロジェクトの依存関係にreqwestとスクレイパーを追加します:
cargo add スクレイパー reqwest --features "reqwest/blocking"注: reqwest/blocking 機能により、reqwest は現在のスレッドをブロックする同期 HTTP 呼び出しを実行できます。詳細はドキュメントを参照してください。
cargo add コマンドは Cargo.toml ファイルを適切に更新し、以下を含むことを保証します:
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
スクレイパー = "0.18.1"
また、2つのライブラリとその依存関係もすべてインストールされます。
完璧です!これでRustを用いたウェブスクレイピングに必要な環境が整いました!
ステップ #3: 対象ページへの接続
reqwest::blocking のget()メソッドを使用して、指定された URL に対して GET リクエストを発行し、関連する HTML ドキュメントをダウンロードします:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;この処理は同期実行であるため、サーバーからの応答があるまでスクリプトの実行は中断されることに注意してください。
レスポンスを取得したら、次の方法で対象ページのHTMLコードにアクセスできます:
let html = response.text()?;min.rs の main() 関数に次の2行を記述します:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// ターゲットページに接続
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 生のHTMLを抽出して出力
let html = response.text()?;
println!("{html}");
Ok(())
}Result<(), Box<dyn std::error::Error>> が何なのか疑問に思うかもしれませんが、これは残留値(Residuals)を使用するためです。また、最後に取得したHTMLを出力するprintln()関数にも注目してください。
スクリプトを実行すると、ターミナルに以下が出力されます:
<!doctype html>
<HTML lang="en">
<HEAD>
<META charset="utf-8">
<TITLE>Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learningウェブスクレイピング</TITLE>
<!-- 簡略化のため省略... -->よくできました!まさにターゲットページのHTMLそのものです!
ステップ #4: HTML ドキュメントのパース
目的のページのソースHTMLが文字列変数に格納されました。これをスクレイパーのparse_document()関数に渡してパースします:
let document = scraper::Html::parse_document(&html);返されるドキュメントオブジェクトは、Rustでウェブスクレイピングを行うために必要なDOM探索APIを公開します。
現時点での main.rs ファイルは次のようになります:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 対象ページに接続
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 生のHTMLを抽出して出力
let html = response.text()?;
// HTMLドキュメントをパース
let document = scraper::Html::parse_document(&html);
Ok(())
}データのパースロジックを記述する準備が整いました。ただし、まずは対象ページの構造を研究する必要があります!
ステップ #5: ページを調査する
ウェブスクレイピングでは、ページ上のHTMLノードを選択し、そこからデータを抽出します。CSSセレクタはHTMLノードを選択する最も一般的な手法の一つです。ウェブ開発者であれば、おそらく既にご存知でしょう。そうでない場合は、ドキュメントを参照してください。
効果的なCSSセレクタを定義する唯一の方法は、対象ページのHTMLを調査することです。ブラウザで「Scrape This Site Country」サンドボックスを開き、国要素を右クリックして「要素を検査」を選択してください。
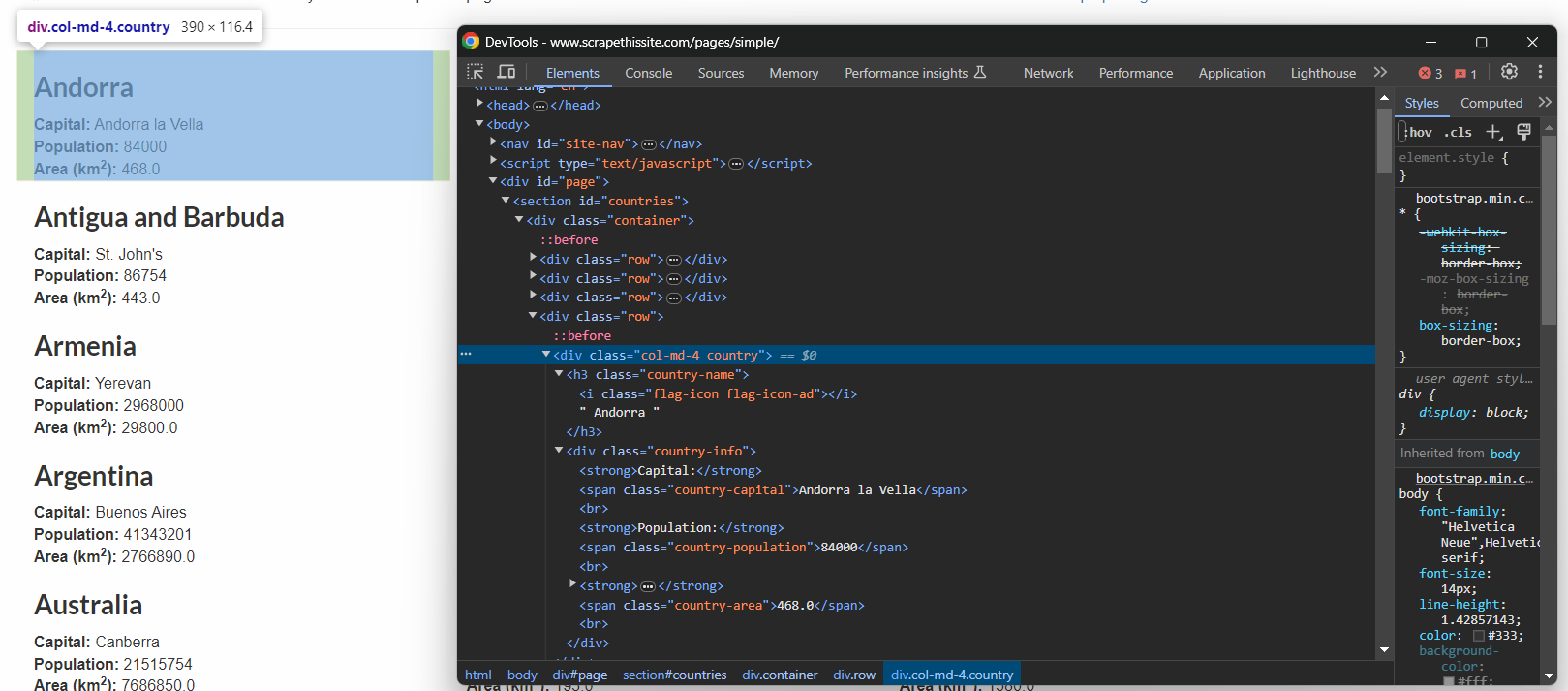
そこで、各国情報ボックスが.country HTMLノードであり、以下を含むことが確認できます:
- 国名を格納する.country-name要素
- .country-capital要素内の首都名
- 人口情報は .country-population 要素に格納されています。
- .country-area要素内の国土面積(km²)。
上記の段落には、目的のHTMLノードを選択するために必要なすべてのCSSセレクタが含まれています。ページ上の全要素に適用する前に、国情報ボックスでセレクタをテストしてください!
ステップ #6: 単一要素からのデータ取得
スクレイパー::Selector の parse() 関数は、CSS セレクタを表す文字列を受け取り、セレクタオブジェクトを返します。以下のように使用します:
let html_country_info_box_selector = scraper::Selector::parse(".country")?;このセレクタを document が公開する select() メソッドに渡せます:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Country info box element not found!")?;これにより、ページ上でCSSセレクタが適用され、選択されたHTML要素が返されます。select()は常にイテレータを返すため、最初の国情報ボックスノードを取得するには.next()呼び出しが必要です。
select()が返すオブジェクトはselect()関数も公開している点に注意してください。この場合、現在のノードの子要素のみを検索対象とします。したがって、Rustでのウェブスクレイピングロジック全体は以下のように実装できます:
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国名が見つかりません")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国都が見つかりません")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国の人口が見つかりません")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;text()メソッドを使用すると、選択したHTMLノードに含まれるテキストにアクセスできます。その他のデータ抽出方法については、ドキュメントを参照してください。抽出されたテキストには不要なスペースが含まれる可能性があるため、trim()で削除します。
スクレイピングされたデータを印刷して、スクレイピングロジックが期待通りに動作することを確認します:
println!("Country name: {name}");
println!("Country capital: {capital}");
println!("Country name: {population}");
println!("Country area: {area}");
すると以下のように出力されます:
Country name: Andorra
Country capital: Andorra la Vella
Country population: 84000
Country area: 468.0はい!これでRustでのウェブスクレイピングが完了しました!
ステップ #7: ページ上の全要素をスクレイピング
今回は、上記のコードを拡張して、ページ上のすべての国情報ボックスノードを処理します。
まず、収集したデータを格納するためのカスタムデータ構造を定義する必要があります。そのための新しい構造体を指定するには、main.rsファイルの先頭に以下の行を追加します:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}次に、main()内でCountryオブジェクトのVecインスタンスを作成します:
let mut countries: Vec<Country> = Vec::new();このベクターにはスクレイピングした全データが格納されます。
次に、すべての国情報ボックスを取得するために .next() の呼び出しを削除し、それらを反復処理して countries に格納します:
// スクレイピングしたデータの保存先
let mut countries: Vec<COUNTRY> = Vec::new();
// 国情報ボックスのHTML要素を選択
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 国情報ボックスHTML要素を反復処理
// 全てをスクレイピング
for html_country_info_box_element in html_country_info_box_elements {
// 単一の国情報ボックスHTML要素に対するスクレイピングロジック...
// 新しいCountryオブジェクトを作成しベクターに追加
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}その後、スクレイピングしたすべての国を以下のように出力できます:
// 結果を出力
for country in countries {
println!("国名: {}", country.name);
println!("首都: {}", country.capital);
println!("人口: {}", country.population);
println!("国面積: {}", country.area);
println!();
}
新しい main.rs Rust ウェブスクレイピングファイルには以下が含まれます:
// スクラッピングデータを格納するカスタム構造体
struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 対象ページに接続
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 生のHTMLを抽出して出力
let html = response.text()?;
// HTMLドキュメントをパース
let document = scraper::Html::parse_document(&html);
// スクレイピングしたデータの保存先
let mut countries: Vec<COUNTRY> = Vec::new();
// 国情報ボックスのHTML要素を選択
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 国情報ボックスのHTML要素を反復処理
// 全てをスクレイピング
for html_country_info_box_element in html_country_info_box_elements {
// 単一の国情報ボックスHTML要素のスクレイピングロジック
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国名が見つかりません")?;
let country_capital_selector =スクレイパー::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国都が見つかりません")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国の人口が見つかりません")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// 新しいCountryオブジェクトを作成し、ベクターに追加
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// 結果を出力
for country in countries {
println!("Country name: {}", country.name);
println!("国都: {}", country.capital);
println!("人口: {}", country.population);
println!("国土面積: {}", country.area);
println!();
}
Ok(())
}
実行すると、以下の出力が生成されます:
国名: アンドラ
首都: アンドラ・ラ・ベリャ
人口: 84000
面積: 468.0
# 簡略化のため省略...
国名: ジンバブエ
首都: ハラレ
人口: 11651858
面積: 390580.0ミッション完了!対象ページから全国の情報をスクレイピングしました!
ステップ #8: 抽出したデータをCSVにエクスポート
収集したデータは現在Rustベクトルに格納されていますが、他者と共有するには最適な形式ではありません。そのため、CSVなどの探索しやすい形式にエクスポートする必要があります。
データをCSVファイルにエクスポートするには、csvライブラリを使用します。以下のコマンドでインストールしてください:
cargo add csv次に、以下のコマンドでCSVエクスポートファイルを生成できます:
// 出力CSVファイルの初期化
let mut writer = csv::Writer::from_path("countries.csv")?;
// CSVヘッダーの書き込み
writer.write_record(&["name", "capital", "population", "area"])?;
// 各国データをファイルに追加
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}このスニペットはCSVファイルを作成し、ヘッダー行で初期化した後、countriesベクトルを反復処理してデータを書き込む。
ステップ #9: 全体をまとめる
以下が、ウェブスクレイピング用Rustスクリプトの完全なコードです:
// スクレイピングデータを格納するカスタム構造体
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 対象ページに接続
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 生のHTMLを抽出して出力
let html = response.text()?;
// HTMLドキュメントをパース
let document = scraper::Html::parse_document(&html);
// スクレイピングしたデータの保存先
let mut countries: Vec<COUNTRY> = Vec::new();
// 国情報ボックスのHTML要素を選択
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 国HTML要素を反復処理
// 全てをスクレイピング
for html_country_info_box_element in html_country_info_box_elements {
// 単一の国情報ボックスHTML要素のスクレイピングロジック
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国名が見つかりません")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国都が見つかりません")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("国の人口が見つかりません")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<STRING>().trim().to_owned())
.ok_or("国面積が見つかりませんでした")?;
// 新しいCountryオブジェクトを作成しベクトルに追加
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// 出力CSVファイルを初期化
let mut writer = csv::Writer::from_path("countries.csv")?;
// CSVヘッダーを書き込み
writer.write_record(&["name", "capital", "population", "area"])?;
// 各国データをファイルに追加
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}信じられますか?100行未満のコードでRustデータスクレイパーを構築できます。
以下のコマンドでアプリケーションをコンパイルします:
cargo build次に、以下で起動します:
cargo runスクリプトが終了すると、プロジェクトのルートフォルダに countries.csv ファイルが生成されます。開くと、以下のデータが表示されるはずです:
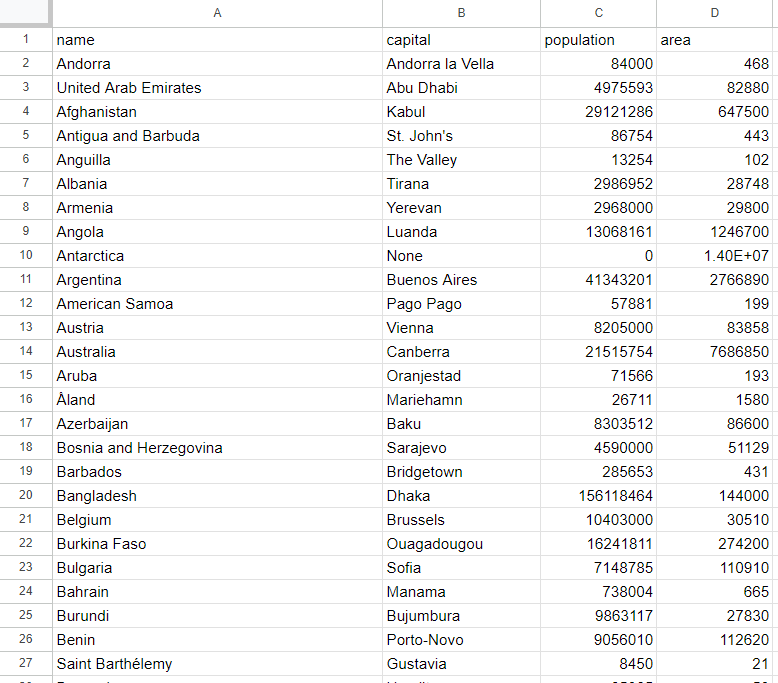
これで完了です!Rustによるウェブスクレイピングの基本を理解できましたね!
ウェブスクレイピングを倫理的かつ尊重ある方法で実施しましょう
インターネットからデータを自動取得することは、有用な情報を得る効果的な方法です。ただし、その過程で対象サイトに損害を与えてはいけません。したがって、適切な予防策を講じてこの操作に臨む必要があります。
責任あるウェブスクレイピングを行うには、以下のポイントに留意してください:
- robots.txtファイルを遵守する:すべてのサイトには 、自動クローラーがページにアクセスする方法を規定するrobots.txtファイルがあります。 倫理的なスクレイピングを実践するには、これらのガイドラインに従う必要があります。詳細は、 ウェブスクレイピングのためのrobots . txtガイドをご覧ください。
- リクエスト頻度の制限: 短時間に過剰なリクエストを行うと サーバー負荷が上昇し、全ユーザーのサイトパフォーマンスに影響します。レート制限措置が発動され、アクセスがブロックされる可能性もあります。対象サーバーへの過剰な負荷を避けるため、リクエストにランダムな遅延を追加しましょう。
- サイトの利用規約を確認し遵守する:ウェブサイトをスクレイピングする前に、その利用規約を確認し遵守してください。利用規約には、著作権、知的財産権、およびデータの使用方法や使用時期に関するガイドラインが含まれている場合があります。
- 公開情報のみをスクレイピングする: ログイン認証やその他の認可形式で保護されていない、サイト上で公開されているデータに焦点を当てて 抽出してください。 適切な許可なく非公開データや機密データをスクレイピングすることは非倫理的であり、法的措置につながる可能性があります。
- 信頼性が高く最新のウェブスクレイピングツールを利用すること: 評判の良いプロバイダーを選び 、適切に保守され定期的に更新されるライブラリやツールを選択してください。 そうすることで初めて、最新の倫理的なウェブスクレイピング原則とベストプラクティスに沿っていることを保証できます。疑問がある場合は、最適なウェブスクレイピングサービスの選び方に関する記事をお読みください。
結論
本チュートリアルでは、Rustがウェブスクレイピングに適した選択肢である理由と、その実行に用いるべきライブラリについて解説しました。ここでは、reqwestとスクレイパーを用いて実在サイトからデータを抽出するRustウェブスクレイパーを構築する方法を学びました。わずか数行のコードで実現可能です!
ただし、ウェブスクレイピングが常にこれほど簡単とは限らない点に留意してください。その理由は、反スクレイピング対策や反ボット対策が普及しつつあるためです。これらの技術はスクリプトの自動化を検知してブロックするため、スクレイピング作業に深刻な課題をもたらします。
Bright Dataが提供する次世代の高度なウェブスクレイピングツールで、この頭痛の種を回避しましょう。ブロック回避方法の詳細を知りたい場合は、複数のプロキシサービスからウェブプロキシを採用するか、高度なWeb Unlockerの利用を開始してください。
ウェブスクレイピングを扱いたくない?当社のデータセットをご覧ください。
どの製品を選べばよいか迷っていますか?今すぐ登録して、ビジネスに最適なソリューションを見つけましょう。





