

このブログ記事では、以下のことを学びます:
- – 機械学習によるデータ分析にTensorFlowが理想的なツールである理由
- ビジネスに有益な洞察を提供する高品質なデータを収集するために頼るべきソリューション。
- Bright Data経由で取得したAmazon商品レビューに対し、TensorFlowを用いた感情分析を実行する方法。
さあ、始めましょう!
機械学習を用いたTensorFlowによるデータ分析の意義
データが価値を持つのは、そこから得られる洞察のためです。これは特に、意思決定や戦略調整、結果最適化のためにデータを活用する企業にとって当てはまります。顧客満足度の向上やマーケティング戦略全体のパフォーマンス最適化などが一般的な目標です。
データ分析において、TensorFlowは最も人気のあるオープンソースライブラリの一つです。機械学習や人工知能システムを支え、幅広いタスクをサポートします。
本記事では特に、TensorFlowを用いて製品レビューの感情分析を行います。同時に、この技術は顧客フィードバック分析、レコメンデーションシステム、予測モデリングなど、他の多くのユースケースにも応用可能です。
ビジネスデータ取得の方法
機械学習や人工知能のパイプラインがどれほど高度であっても、すべてのデータアナリストが「より多くのデータは優れたアルゴリズムに勝る」ことを知っています。端的に言えば、意味のある洞察を得る鍵はデータの質と量にあります。
では、良質なデータを大量に取得するにはどうすればよいでしょうか?データ収集は困難を伴うため、Bright Dataのような信頼できるデータプロバイダーに依存することが重要です。
Bright Dataは以下のような幅広いデータソリューションを提供します:
- Web Scraper API:ウェブスクレイピングにより取得した、数十の主要ドメインからの構造化ウェブデータへのプログラムによるアクセス。
- データセットマーケットプレイス:100以上のウェブサイトから収集した数十億件のエントリーを含む、新鮮で即利用可能なデータセット。
- マネージドデータ取得サービス:開発やメンテナンスの手間なくデータとインサイトを取得できる、完全管理型のエンタープライズグレードデータ収集サービス。
これらの製品は、研究者、中小企業(SMB)、大企業に対応しています。具体的には、機械学習ワークフロー、AIトレーニング、エージェント開発、その他数多くのシナリオを 推進するための公開ウェブデータの収集を可能にします。
Bright Data経由で取得したAmazon商品レビューに対する感情分析の実施方法
このステップバイステップセクションでは、TensorFlowを使用して現実世界のデータ分析ワークフローを構築します。製品レビューに対する感情分析を実行するという実用的なユースケースを扱います。
Amazonで複数の商品を販売する企業を想定します。顧客満足度向上のため、各商品に対するユーザーレビューを定期的に監視し、感情分析を実施して「効果的な点」と「改善が必要な点」を把握するプロセスが必要です。
この例では、以下のAmazon商品に焦点を当てます:
注:Bright Data Amazon Reviewsスクレイパーは複数の商品から無制限にスケーラブルにレビューをスクレイピングできるため、このワークフローを複数のAmazon商品に拡張可能です。
この例は、5段階評価の全レベルに比較的均等に分布した大量のレビューが存在するため、非常に適しています: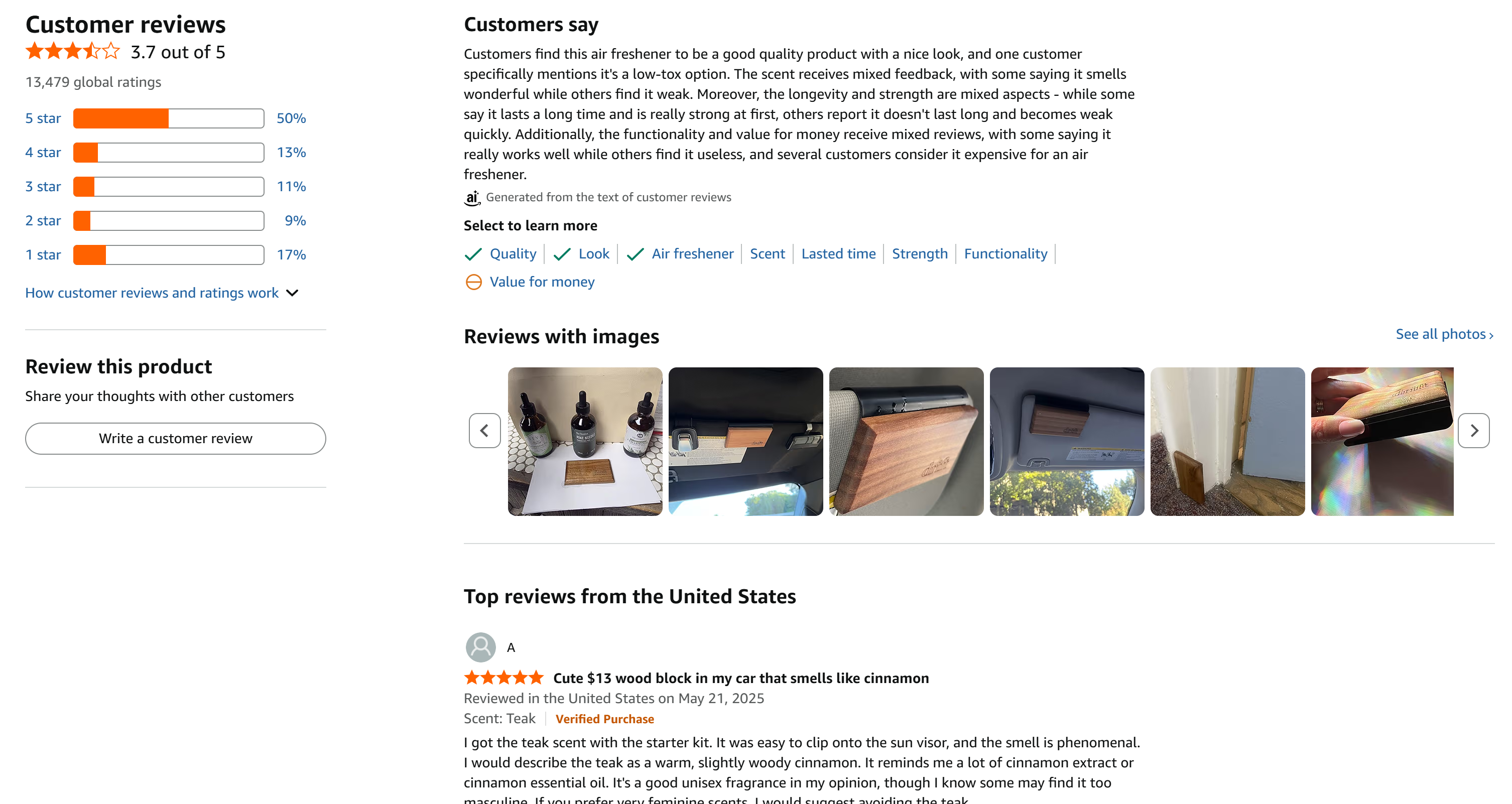
以下の手順に従い、エンタープライズ対応の感情分析プロセスを構築します。商品のレビューはBright Data経由で取得後、Pythonを用いたTensorFlowの機械学習ワークフローで分析します。
前提条件
このチュートリアルを実践するには、以下の環境が整っていることを確認してください:
- ローカルにPython 3.9以上がインストールされていること。
- APIキーが設定済みのBright Dataアカウント。
Bright Dataアカウントをお持ちでない場合でも、以下の手順で設定プロセスをガイドしますのでご安心ください。
ユニバーサルセンテンスエンコーダーモデル、ベクトル埋め込みの仕組み、および密なニューラルネットワーク層を備えたKerasSequentialモデルの動作に関する知識は、感情分析のTensorFlowロジックを完全に理解する上で非常に役立ちます。
ステップ #1: JupyterLabプロジェクトの設定
このTensorFlow機械学習プロセスではチャートやデータ可視化も扱うため、開発環境としてJupyterLabを使用するのが合理的です。これにより、コードを本番環境対応のMLパイプラインへ容易に移行できます。
まず、プロジェクトフォルダを作成します。そのフォルダに移動します:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysis次に、フォルダ内で仮想環境を初期化します:
python -m venv .venv仮想環境を有効化します。macOS/Linuxでは以下を実行:
source .venv/bin/activateWindowsの場合は以下を実行:
.venvScriptsactivateアクティブな環境で、 jupyterlabパッケージ経由でJupyterLabをインストールします:
pip install jupyterlab以下のコマンドでJupyterLabを起動します:
jupyter labJupyterLabインターフェースが表示されます:
「ノートブック」セクションの「Python 3 (ipykernel)」ボタンをクリックして新しいノートブックを作成します:
ノートブックに名前を付けて保存します。
完了!これでPython環境が設定され、TensorFlowを用いた機械学習データ分析ワークフローの開発に最適な環境が整いました。
ステップ #2: ライブラリのインストール
コードブロックを追加し、必要なライブラリを以下のようにインストールします:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requestsこの実装に必要なすべてのライブラリをインストールするには、このブロックを実行してください:
tensorflow: 機械学習モデルの構築とトレーニング用。tensorflow-hub: 事前学習済み機械学習モデルの読み込み用。scikit-learn: データ前処理、訓練データとテストデータの分割、メトリクス、クラス重み付けのため。pandas: 表形式データの処理と集計を実行するため。numpy: 数値計算と配列処理のため。matplotlib: グラフのプロットと結果の可視化。requests: HTTPリクエストの実行とBright DataスクレイパーAPIとの連携に使用します。
次に、必要なライブラリをすべてインポートして設定するためのコードブロックを追加します:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)素晴らしい!これで、以降のすべてのコードブロックがBright Dataの取得とTensorFlowベースの分析ワークフローを実行する準備が整いました。
ステップ #3: Bright Data Amazon レビュースクレイパーの開始
Amazonレビューデータを取得するコードを書く前に、Bright Dataアカウントの設定と必要なデータスクレイピングソリューションの理解に時間を割きましょう。
このチュートリアルでは、Bright Data Amazon Reviews APIを利用します。これにより、指定した商品の最新レビューデータをプログラムでスクレイピングできます。自社製品のレビューを監視したい場合に最適です。
より一般的なシナリオでは、Bright Dataが提供する2860万件以上のレビューを含む既製の「Amazon Reviews」データセットも利用可能です: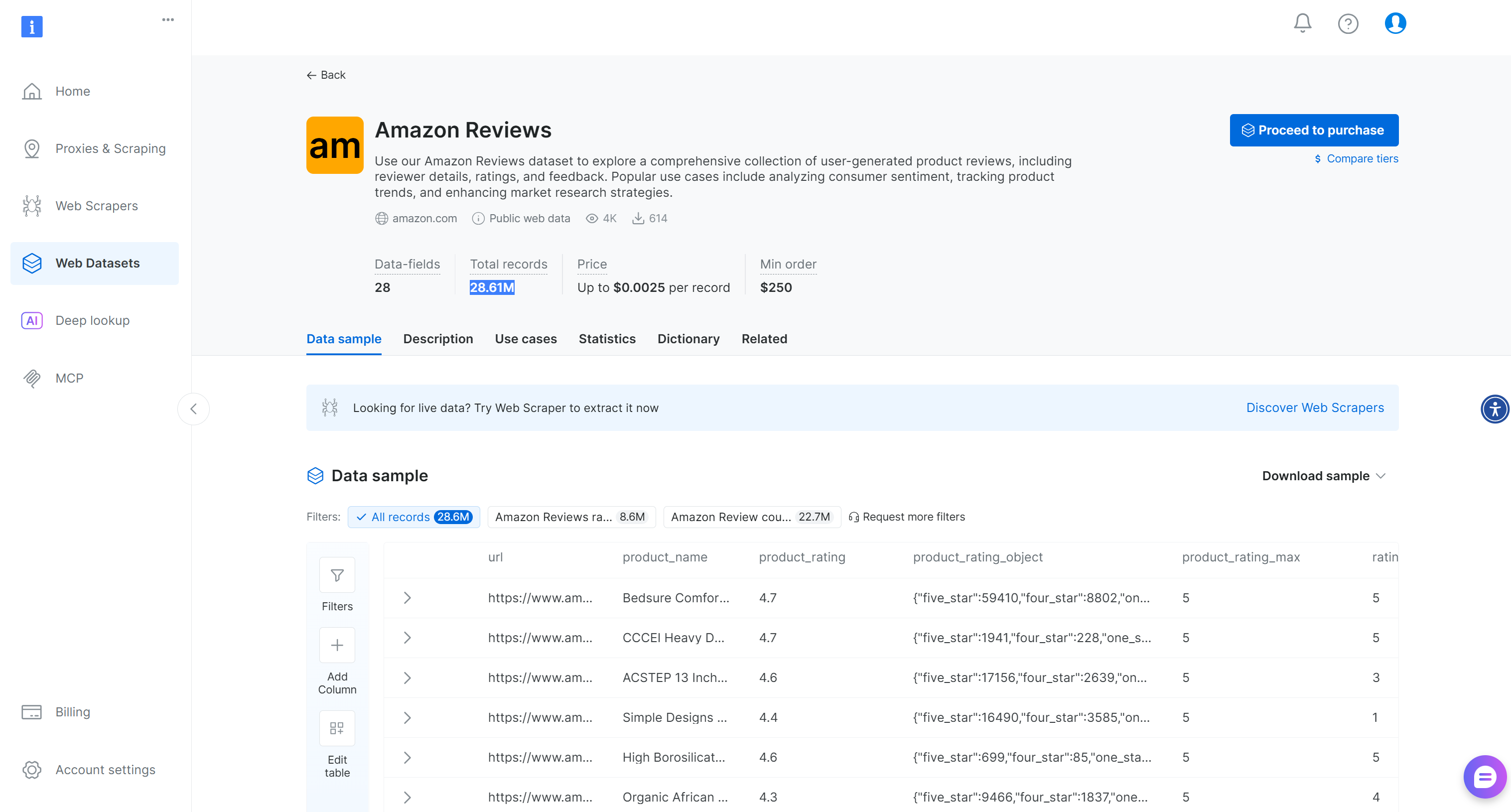
Bright Dataアカウントをお持ちでない場合は新規作成してください。既にアカウントをお持ちの場合はログイン後、アカウントの「スクレイパー Library」ページに移動します:
「amazon」を検索し、「Amazon Reviews – collect by URL」スクレイパーを選択してください:
このページでは、統合準備完了コードの生成方法や、スクレイパーによる直接試用の方法を確認できます。
「スクレイパー API」オプションを選択すると、以下のページに移動します:
ここでは、サポートされている入力パラメータと出力形式を確認してください。特に、このデータセットはAmazonレビューのリストを返し、IDはgd_le8e811kzy4ggddlqです。
このスクレイパーをAPI経由で呼び出すには、Bright Data APIキーを使用してリクエストを認証する必要があります。キーをお持ちでない場合は、公式ガイドに従って生成してください。すぐに必要になるため、安全な場所に保管してください。
これで準備完了です。Bright DataのAmazonレビュースクレイパーを使用して、分析用の商品レビューデータを取得できます。
ステップ #4: Amazon商品レビューデータの取得
新しいノートブックセルを作成し、以下のコードを貼り付けます:
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
def trigger_snapshot(amazon_product_url):
# 指定されたAmazon商品URLに対してBright Data WebスクレイパーAPIをトリガー
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # "Amazon Reviews - collect by URL" スクレイパーのID
"include_errors": "true",
}
# API呼び出し用の入力データをフォーマット
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # リクエストを認証
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"リクエスト成功! スナップショットID: {snapshot_id}")
return snapshot_id
else:
print(f"リクエスト失敗!ステータスコード: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# スナップショットが準備できるまでBright DataスクレイパーAPIをポーリングし、保存する
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"スナップショットID: {snapshot_id} の取得を開始...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("スナップショットの準備が完了しました。ダウンロード中...")
snapshot_data = response.text
# スナップショットをファイルに書き込む
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"スナップショットを {output_file} に保存しました")
return
elif response.status_code == 202:
print(f"スナップショットはまだ準備できていません。 {polling_timeout}秒後に再試行します...")
time.sleep(polling_timeout)
else:
print(f"リクエスト失敗!ステータスコード: {response.status_code}")
print(response.text)
break
# レビューを取得するAmazon商品URL
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# スナップショットをトリガーしレビューをダウンロード
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")プレースホルダー<YOUR_BRIGHT_DATA_API_KEY>を、事前に生成した実際の Bright Data API キーで置き換えてください。
上記のコードは:
data sets/v3/triggerを使用してレビュースクレイパーをトリガーし、Amazon Reviews スクレイパーを用いて Bright Data のクラウド上でスクレイピングジョブを開始します。datasets/v3/snapshot/{snapshot_id}を使用して生成されたデータセットのスナップショットをポーリングし、Bright Data がレビューのスクレイピングを完了するまで待機します。- 最終データをCSV形式(
format="csv"が指定されているため)でエクスポートし、product-reviews.csvとしてローカルに保存します。
これがWebスクレイパーAPIワークフローの動作原理です。詳細はBright Data公式ドキュメントを参照してください。
コードブロックを実行すると、以下のような結果が表示されます:
その後、プロジェクトフォルダ内にproduct-reviews.csvファイルが生成されます。開くと、構造化された形式でスクレイピングされたレビューが表示されます: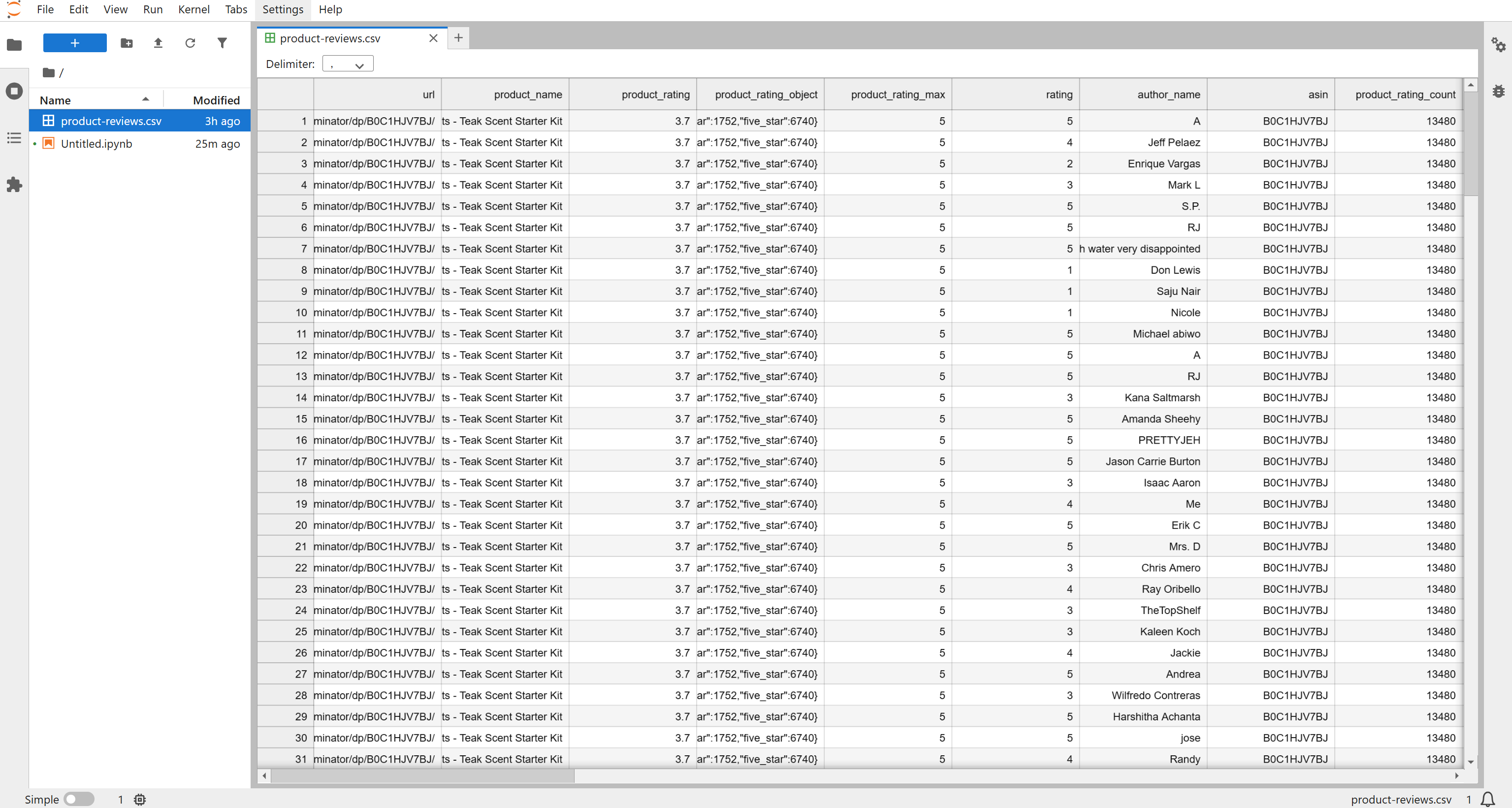
デフォルトではスクレイパーは最新の約200件のレビューを返しますが、必要に応じてAPI入力を調整してより多くのデータを取得できます。このチュートリアルでは、取得した196件のレビューで感情分析パイプラインを完了させるには十分です。
素晴らしい!これでTensorFlow分析用の最新のAmazon商品レビューデータが準備できました。
ステップ #5: スクレイピングしたデータの探索
まず、product-reviews.csvファイルからスクレイピングしたデータを読み込みます:
# Bright Dataで生成したCSVファイルから商品レビューを読み込み
df = pd.read_csv("product-reviews.csv")
# レビュー投稿日日時を変換
df["date"] = pd.to_datetime(df["review_posted_date"])
# テキスト欠落のあるレビューを削除
df = df.dropna(subset=["review_text"])
# レビューを投稿日順(昇順)でソート
df = df.sort_values(by="date", ascending=True)
print(f"{len(df)}件のレビューを読み込みました。")このセルを実行すると、読み込まれたレビューの総数が表示されます:
196件のレビューを読み込みました。次に、評価の分布を分析します:
print(df["rating"].value_counts())以下のような結果が表示されるはずです:
評価
1 74
2 31
3 16
4 12
5 63上記のように、レビューは1~5つ星の範囲でほぼ均等に分布しています。この分布をより視覚化するために、Matplotlibで棒グラフを使用します:
# 評価別(1~5つ星)のレビュー数を計算
rating_counts = df["rating"].value_counts().sort_index()
# 評価分布を棒グラフでプロット
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("評価分布 (1~5つ星)")
plt.xlabel("星の数")
plt.ylabel("件数")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()以下のようなグラフが表示されます: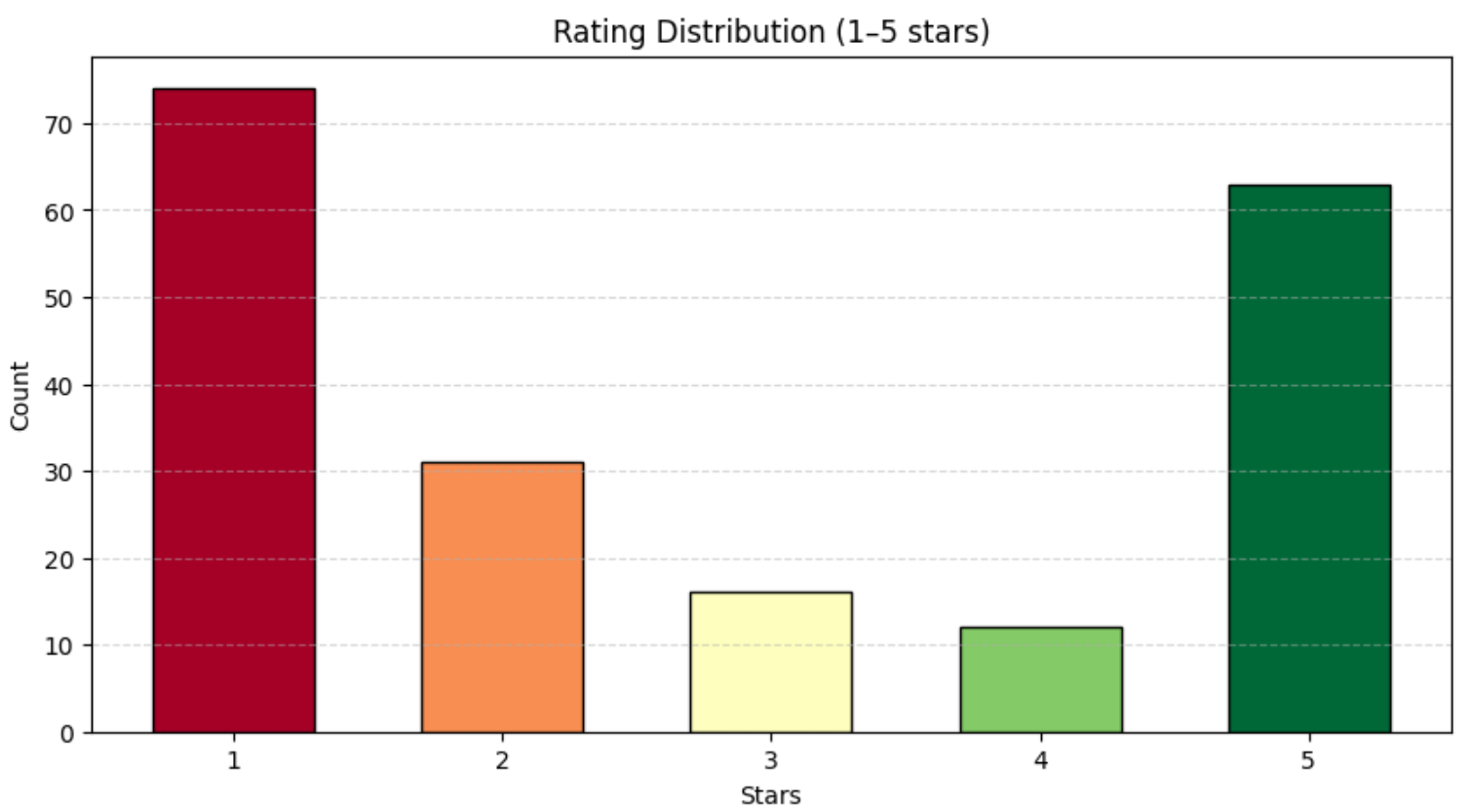
完璧です!これで、取得したAmazonレビューデータセットについて、明確で高水準の理解を得られました。この基礎は、モデルトレーニングや感情分析に進む前に不可欠です。
ステップ #6: レビューに感情分析スコアを割り当てる
機械学習を適用する前に、3つ星レビューを無視することで感情分類タスクを簡略化します。これらのレビューは通常中立的であり、明確な肯定的・否定的感情を示さないためです。
これらを含めると、モデルは3クラス問題(肯定的/中立/否定的)を学習する必要が生じ、より多くのデータと複雑なモデリングが要求されます。代わりに、以下の基準でタスクを二値感情分類に変換します:
- 4~5つ星レビューを「肯定的」(
1)とみなす; - 1~2つ星レビューを「否定的」(
0)
これに基づき、TensorFlowで感情分析ロジックを以下のように実装します:
# 二値感情分析の明確化のため中立レビュー(評価=3)を除外
df = df[df["rating"] != 3]
# 評価を感情にマッピング:1=肯定的(>=4)、0=否定的(<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# Universal Sentence Encoder埋め込みをロード
print("Universal Sentence Encoder埋め込みをロード中...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # 浮動小数点型を固定化
y = df["sentiment_label"].values
# データセットを訓練セットと検証セットに分割
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# クラス不均衡を処理するためのクラス重みを計算
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# 入力層から始まる単純な全結合分類器を構築
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# 再学習を回避するため、モデル構築を強制
_ = model(X_emb[:1])
# モデルの学習
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# 検証セットで予測し評価
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("nSentiment Model 分類レポート:")
print(classification_report(y_val, y_pred))
# 全データセットで予測し感情スコアを保存
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()このコードブロックは、各レビューを意味ベクトルに変換するためにユニバーサルセンテンスエンコーダー(USE)に依存しています。このモデルに不慣れな方のために説明すると、USEはGoogleが開発したモデルであり、分類や意味的類似性などの自然言語処理タスク向けに、テキストを512次元の埋め込みベクトルに変換します。
これらの埋め込みは、各レビューに表現されたトーン、感情、意図といった意味を捉えます。その後、KerasのSequentialモデルは 全結合(Dense)層を用いて、ポジティブ感情とネガティブ感情を区別する埋め込み内のパターンを学習します。その出力は確率スコアであり、以下の通りです:
1.0に近い値は肯定的感情を示し、0.0に近い値はネガティブな感情を示します。
モデルは各レビューにこれらのスコアのいずれかを割り当てます。検証セットからの分類レポートは以下の通りです:
感情モデル分類レポート:
精度 再現率 F1スコア サポーティング件数
0 0.91 0.95 0.93 21
1 0.93 0.87 0.90 15
精度 0.92 36
マクロ平均 0.92 0.91 0.91 36
加重平均 0.92 0.92 0.92 36これは次のことを示しています:
- モデルは未見の検証データで92%の精度を達成。
- 陽性クラスと陰性クラスの両方で、精度と再現率が一貫して高い。
- トレーニング精度と検証精度は近く、モデルが著しく過学習していないことを示している。
機械学習のトレーニングプロセスをより視覚化するために、以下のようなチャートを追加することを検討してください:
plt.plot(history.history["accuracy"], label="Train Accuracy")
plt.plot(history.history["val_accuracy"], label="Validation Accuracy")
plt.title("Sentiment Model Training Performance")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()これにより、完全なトレーニング履歴が表示されます: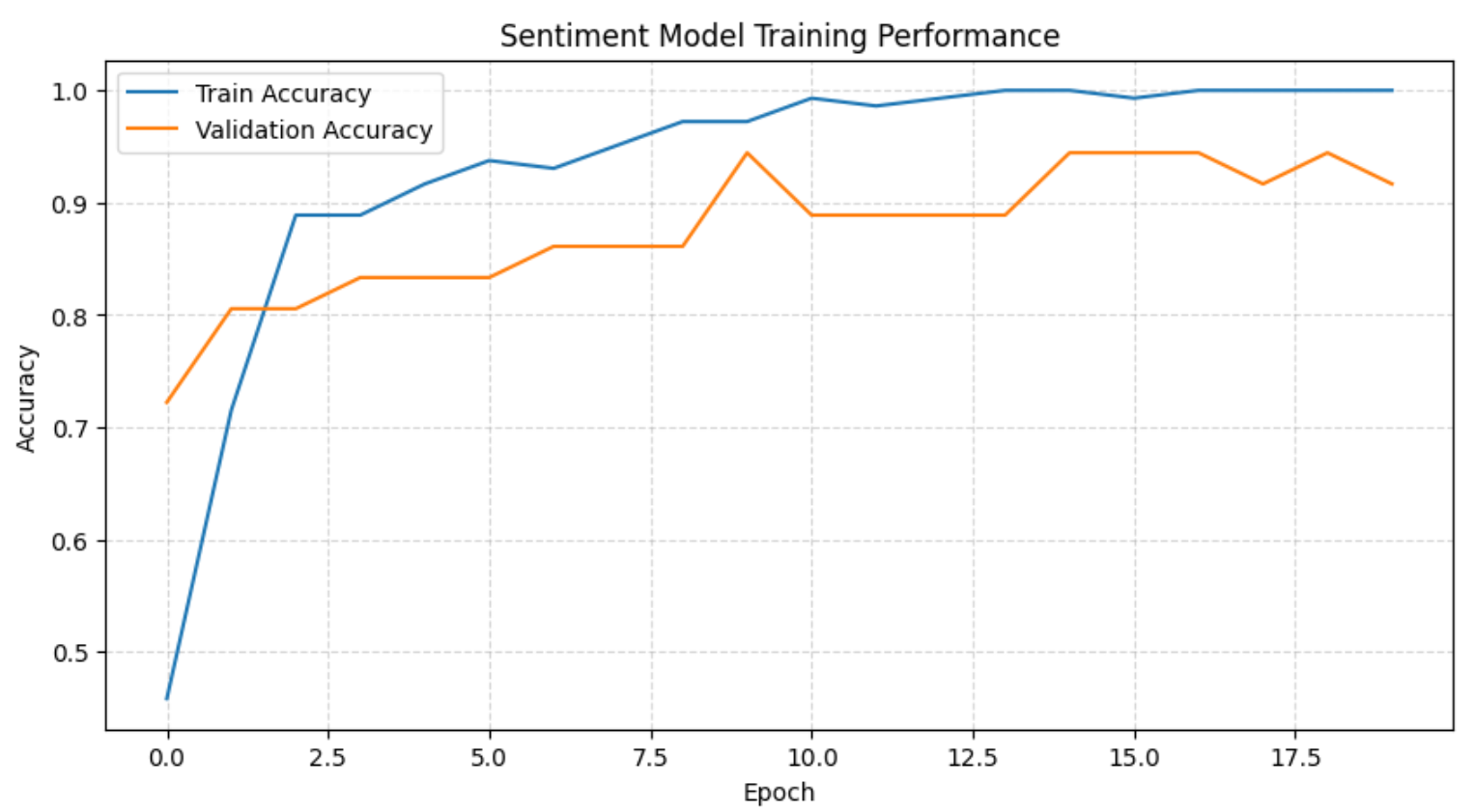
上記のグラフとトレーニングログから、モデルは最初の数エポックで感情境界を迅速に学習し、その後高い検証精度で安定することがわかります。トレーニングが進むにつれ、トレーニングセットの精度は100%に達しますが、検証精度は一貫して高く維持されており、データセットのサイズを考慮すると、わずかで許容範囲内の過学習を示しています。
最後に、予測された感情確率を可視化します:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("予測感情スコア分布")
plt.xlabel("感情スコア")
plt.ylabel("カウント")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()結果は次のようになります: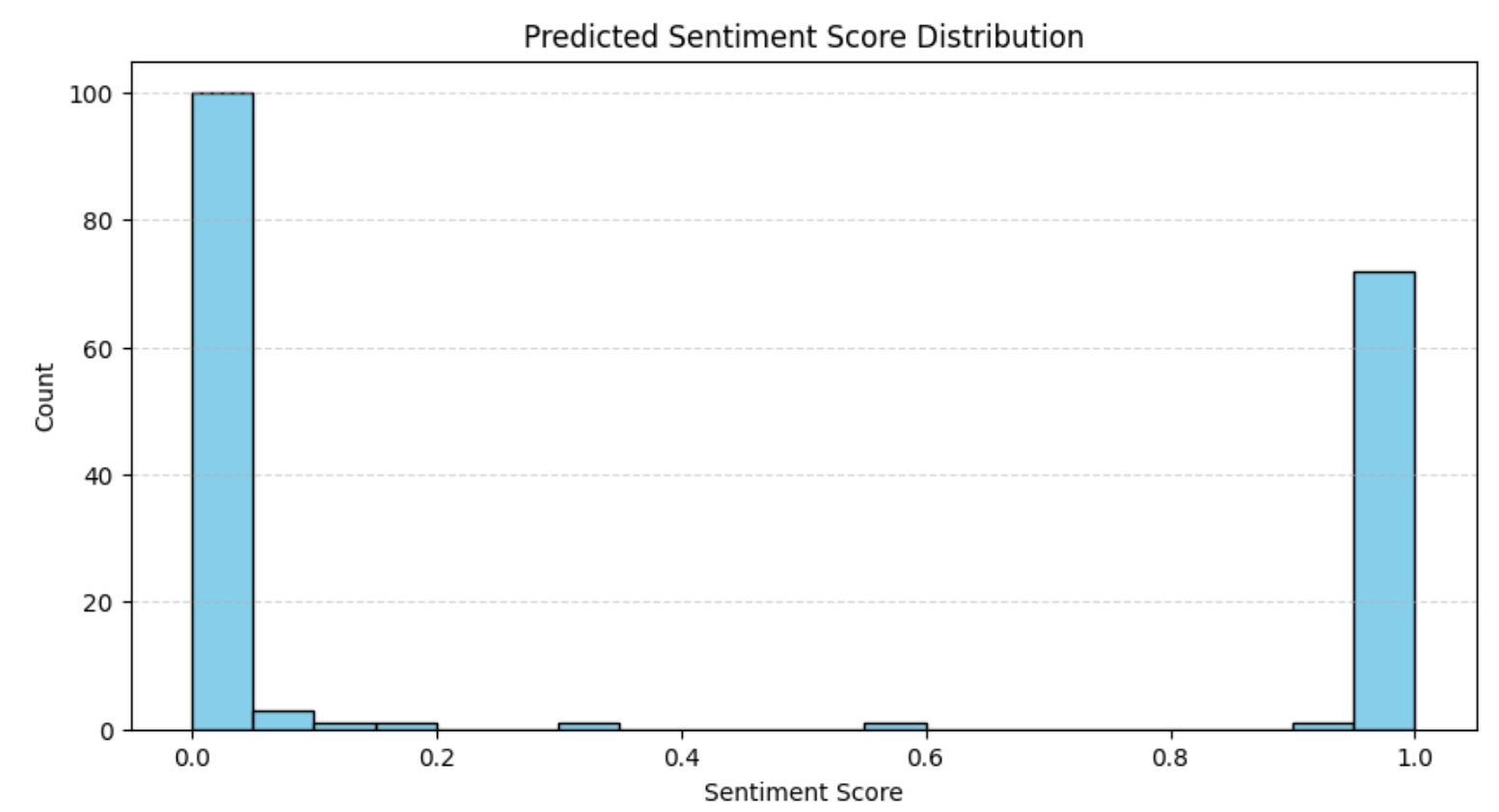
この分布は、評価分析で以前に観察した結果と一致しています。つまり、ほとんどのレビューは強く肯定的か強く否定的なかのどちらかです。このパターンは、二極化した意見が支配的になりがちなeコマースプラットフォームでは一般的です。
素晴らしい!感情分析が完了しました。
ステップ #7: 感情分析の時系列推移を調査
すべてのレビューに感情スコアが付与されたので、過去1年間の顧客感情の推移を可視化します。日々の変動を平滑化するため、日次平均感情スコアに7日間の移動平均トレンドを適用します:
# 日次平均感情値の準備
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# 過去1年に絞り込み
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# 7日移動平均トレンドの計算
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# 月ごとのX軸ラベルを設定
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # 月単位開始
)
# 日次センチメントと移動平均トレンドをプロット
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="日次センチメント")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="7日間移動平均トレンド")
# x軸ラベルの設定
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("日次平均センチメント(過去1年)+トレンド")
plt.xlabel("日付")
plt.ylabel("センチメントスコア")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()これにより、以下の感情推移チャートが生成されます: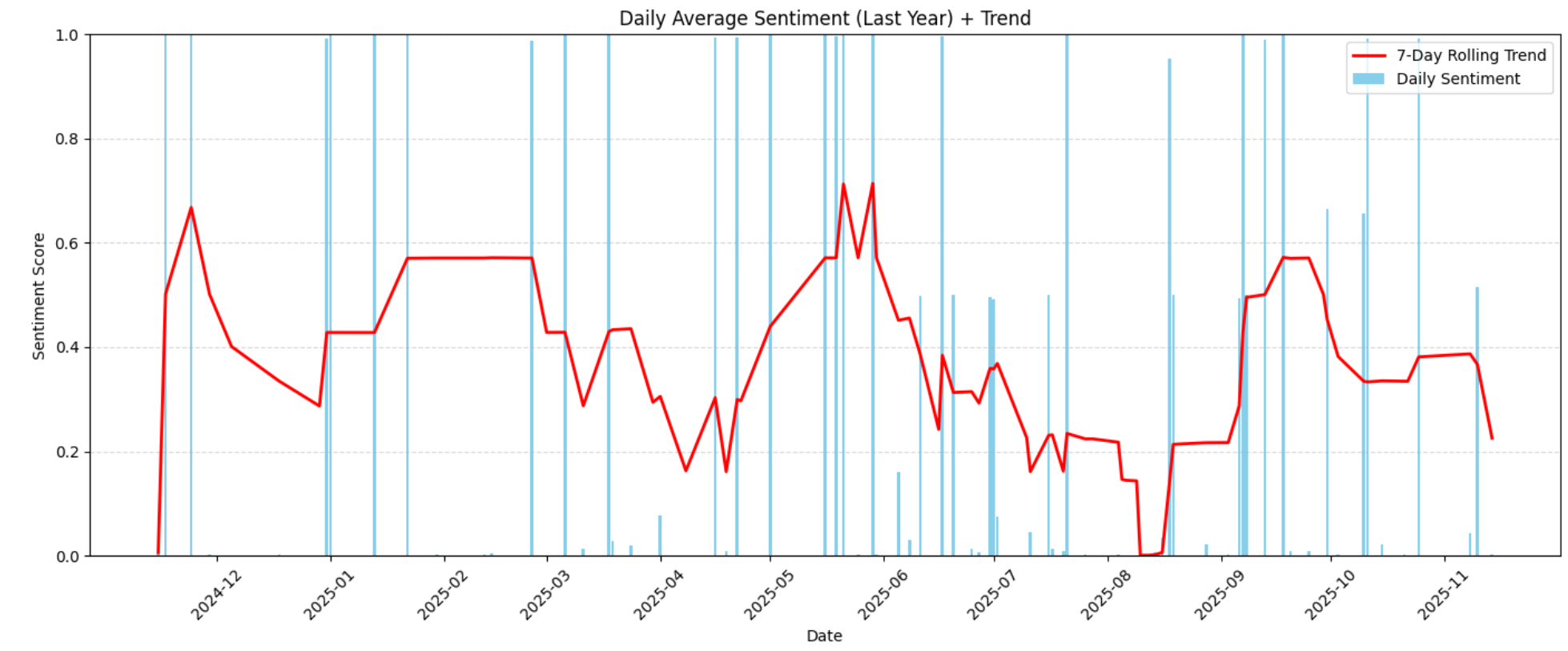
この可視化では、年間を通じた感情の高まりや低下のパターンが強調されています。これらの傾向から、顧客満足度が向上した時期、低下した時期、そして外部要因(製品変更、遅延、欠陥、価格更新など)が感情の変化を引き起こした可能性があるかどうかを認識できます。
例えば、このグラフでは2026年6月から8月中旬にかけて、感情が急激に低下し、中程度のポジティブ(約0.6)から極端なネガティブ(0.0近く)へと変化したことが明確に確認できます: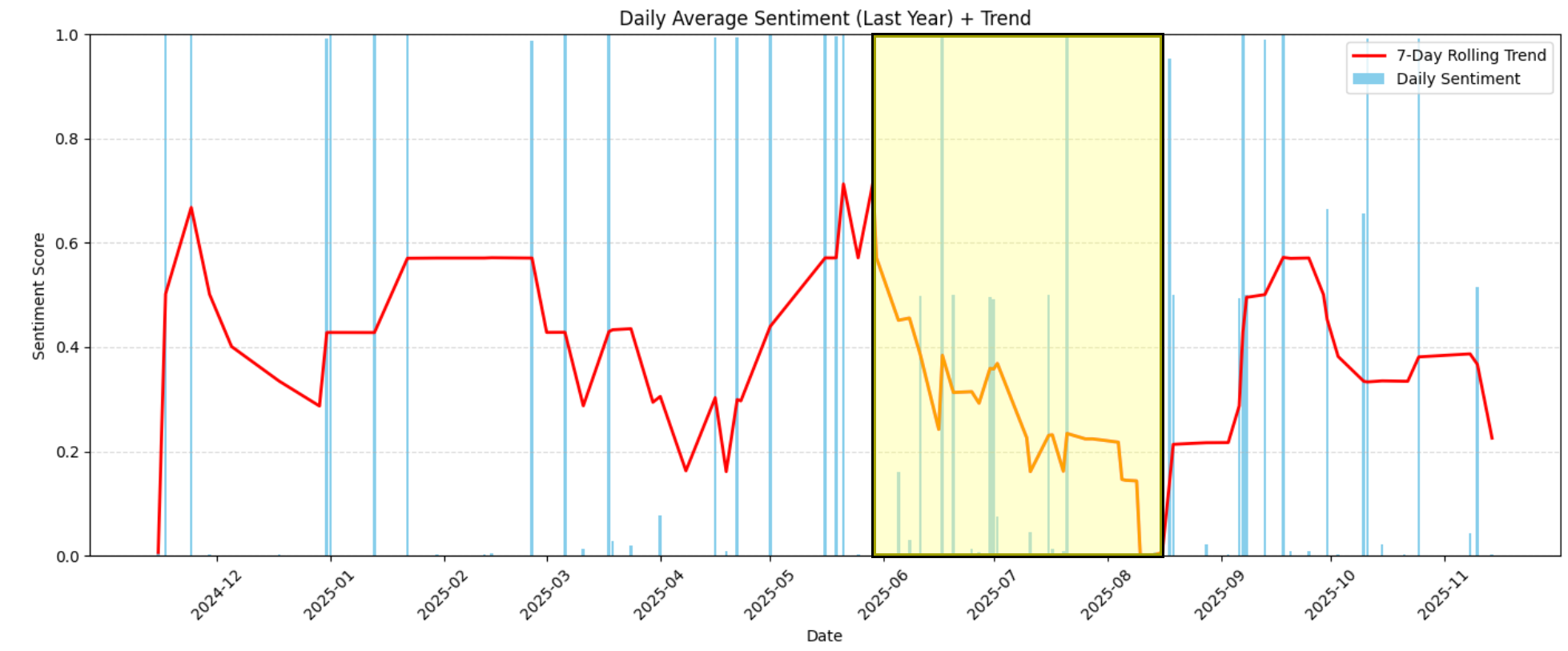
この期間に何が起きたかを理解するには、データセットを該当期間に絞り込みます:
# 2026年6月から8月中旬のレビューを抽出
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"期間内のレビュー数: {len(df_filtered)}")出力結果から、この期間内のレビュー数は34件であることがわかる:
期間内のレビュー数: 34次に、評価点数ごとの感情分布を要約します:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("n評価要約:")
print(rating_summary)結果は次のようになります:
評価サマリー:
評価 レビュー数 平均感情スコア
0 1 16 0.004767
1 2 11 0.048928
2 4 2 0.998977
3 5 5 0.993221これは、34件のレビューのうち27件が1つ星または2つ星であり、それらの感情スコアが0.0に極めて近いことを示しています。
評価と感情の相関関係をプロットする:
# 感情と評価をチャートでプロット
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="レビュー数")
ax1.set_xlabel("評価")
ax1.set_ylabel("レビュー数", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="平均感情スコア")
ax2.set_ylabel("平均感情スコア", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("感情分析 vs 評価 (2026-06-01 to 2026-08-15)")
fig.tight_layout()
plt.show()結果のグラフは以下のようになります: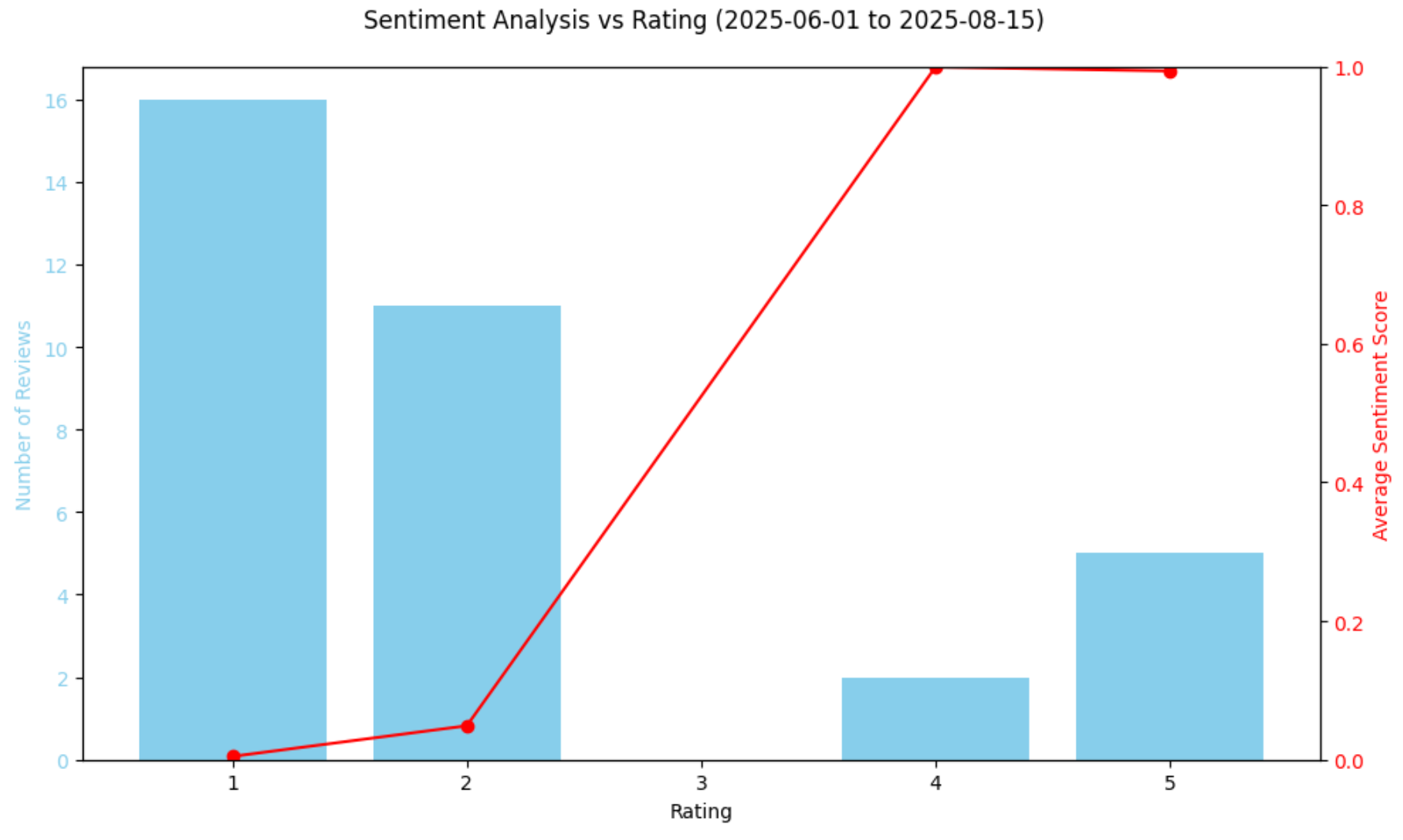
上記のグラフは感情評価の急激な低下を確認しており、当該期間のレビューの大半が完全に否定的な内容でした。興味深いことに、モデルは感情分析スコアを通じて4つ星レビューを5つ星レビューよりわずかに高く評価しています。これは誤りではなく、星評価だけでは感情のニュアンスを必ずしも反映しないことを示しています。5つ星レビューにも懸念が含まれる場合がある一方、4つ星レビューには極めて肯定的な表現が見られることもあるのです。
結局のところ、星評価は顧客の感情を素早く把握できるものの、レビュー本文のニュアンスを完全に捉えるとは限りません。モデルが予測した感情スコアと数値評価を比較することで、レビューの表現が割り当てられた星評価と一致しているかを確認できます。これにより、高評価レビュー内の否定的な表現や、低評価レビュー内の微妙な肯定性といった異常値を特定するのに役立ちます。
この興味深いパターン(評価スコアの低下傾向)の分析を続けましょう!
ステップ #8: 関連レビューの読解
2026年6月から8月中旬にかけてのレビュー減少の真の原因を把握する最終ステップは、レビューを直接検証することです。以下の手順で実現します:
# 関連列の選択
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# HTML経由でノートブックにテーブル表示
display(HTML(df_table.to_html(index=False)))結果は以下のHTMLテーブルとなります:

ご覧の通り、この期間の大半のレビューでは「香りがすぐに消える」「香りが弱すぎる」といった不満が寄せられています。これは出荷された製品において、当該週に製造上の問題が発生した可能性を示唆しています。
この知見は非常に価値が高く、製造工程の調査、繰り返し発生する問題への対応、さらには不満を持つ顧客へのクーポンや割引などの解決策の提供が可能になります。
注:このレビュー分析プロセスはLLMを活用してさらに自動化でき、完全に自律的な本番環境対応パイプラインとすることも可能です。
さあ、完成です!Bright Dataのスクレイピング機能によりAmazon商品データを取得し、TensorFlowを用いた感情分析を実施。トレンドを分析し、特定期間におけるレビュー減少の背景要因を特定しました。
結論
本記事では、Bright Dataを介したAmazon商品レビューデータの取得方法と、Pythonノートブックで構築したTensorFlowの機械学習ワークフローを用いた感情分析トレンドの特定プロセスを紹介しました。
ここで紹介したプロジェクトは、ユーザーレビューを監視し顧客満足度を向上させる方法を模索する中小企業や大企業のニーズに応えます。このような分析は、Bright Dataが企業向けに提供するデータサービスなしでは実現できません。
これらのソリューションには、豊富なデータセットマーケットプレイスと ウェブスクレイパーAPIが含まれ、Amazon、LinkedIn、Yahoo Financeなど100以上のドメインから過去データや最新データを収集できます。取得したデータはTensorFlowなどの技術に投入し、機械学習による分析が可能です。
今すぐBright Dataの無料アカウントを作成し、スクレイパーAPIをお試しいただくか、当社のデータセットをご覧ください!




