
この記事では、PySparkと Bright Dataを使用して大規模なウェブスクレイピングワークロードを実行する方法について解説します。数十万もの商品ページをスクレイピングしたり、数百のサイトにわたる価格監視をしたり、数百万ページからトレーニング用データセットを構築したりする必要がある場合、単一マシンのスクリプトでは対応できません。
ここで紹介するパターンでは、リクエスト量が増加してもパイプラインの信頼性を維持しつつ、スクレイピング作業をクラスタ全体に分散させる方法を解説します。
この記事を読み終える頃には、以下の方法が理解できるようになります:
- PySparkを使用して大規模なURLリストを分散データセットとして扱う
- パーティションレベルでスクレイピングワークロードを効率的に実行する
- ジョブ全体を再起動することなく、リトライや障害に対処できるワーカーを設計する
- リクエスト量が増加するにつれて、プロキシルーティングとネットワークの信頼性を確保する
ウェブスクレイピングが分散処理の問題となる時
ほとんどのスクレイピングプロジェクトは、同じように始まります。開発者がスクリプトを書き、URLのリストを読み込み、リクエストを送信し、結果を保存するのです。
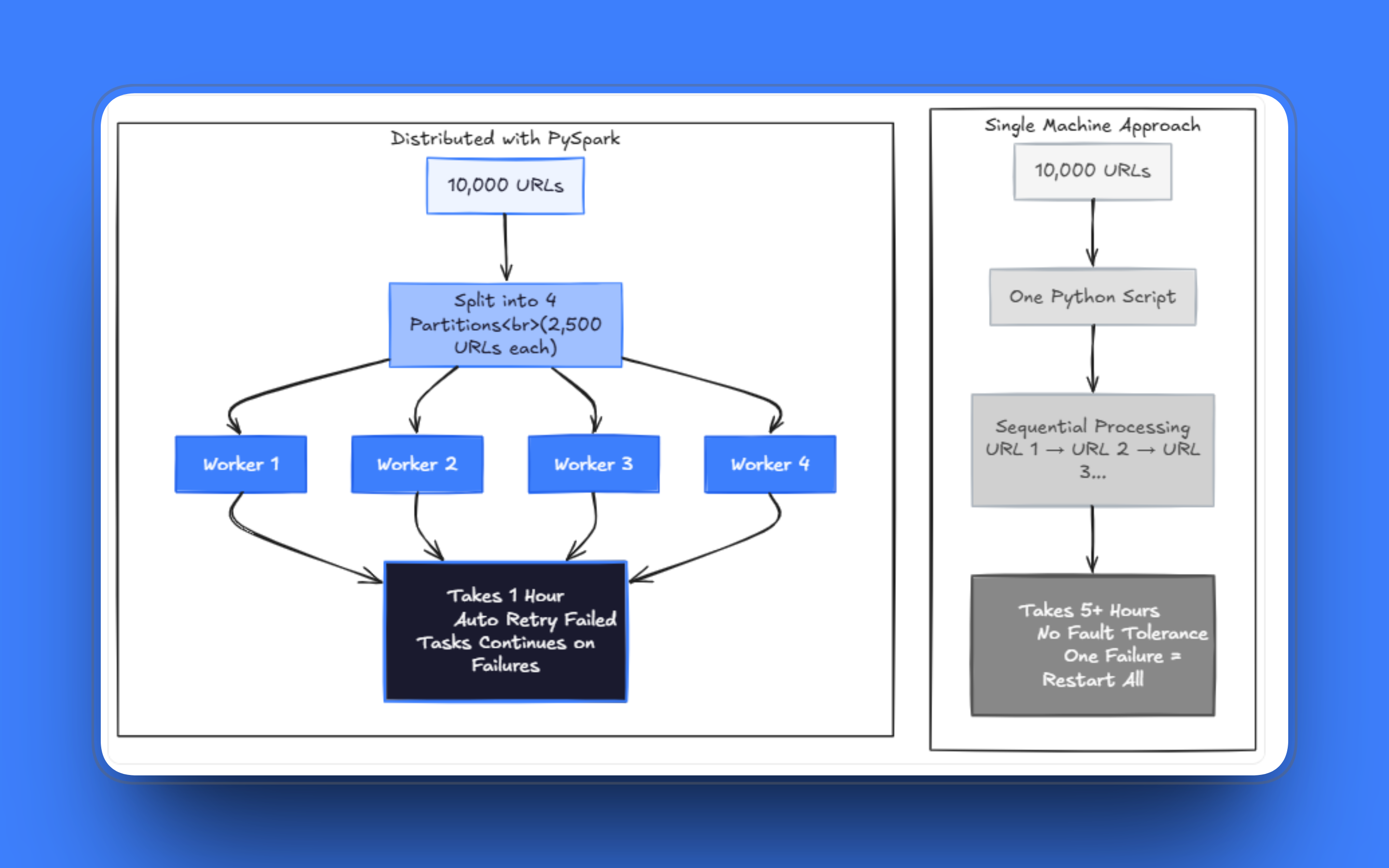
ワークロードがスケールすると、問題点が露呈します。以前は数分で完了していたジョブが、数時間かかるようになります。数千ページを処理した後に数件のリクエストが失敗するだけで実行が停滞し、フェッチやパースを処理しながら同じスクリプト内でリトライを管理することは、すぐに混乱を招くことになります。私は、チームがこうした単一ファイルのスクレイパーを何ヶ月も維持し、次々と発生する例外ケースにパッチを当て続けているのを目にしてきましたが、本当の問題は、そのアーキテクチャがもはや課題に適合していないという点にあります。
1台のマシンで数十万ページをスクレイピングするには、スレッド化を行っても非現実的な時間がかかります。スケールアップするには、複数のワーカーで実行する必要があり、リクエストの一部が失敗してもシステムは稼働し続けなければなりません。解決策は、URLリストを順序付きキューとして考えるのをやめ、分散処理可能なデータセットとして扱うことです。
なぜPySparkがここに適しているのか
PySparkは、データセットをパーティションに分割し、マシン群(クラスタ)全体で並列処理するという考え方に基づいて構築されています。このモデルはウェブスクレイピングにそのまま適用できます。各URLが作業単位となり、パーティションがURLをバッチにグループ化し、エグゼキュータがそれらのバッチを独立して処理します。
Celeryや自作のマルチプロセッシング環境でキューを管理する代わりに、Sparkは、それらを構築することなく、フォールトトレランスとスケジューリングを提供します。タスクが失敗した場合、Sparkはそれを再スケジューリングします。ノードがダウンした場合、作業は再割り当てされます。タスク内部で適切なリトライロジックを記述する必要は依然としてありますが、オーケストレーション層は自動的に処理されます。
パターン1:分散データセットとしてのURL
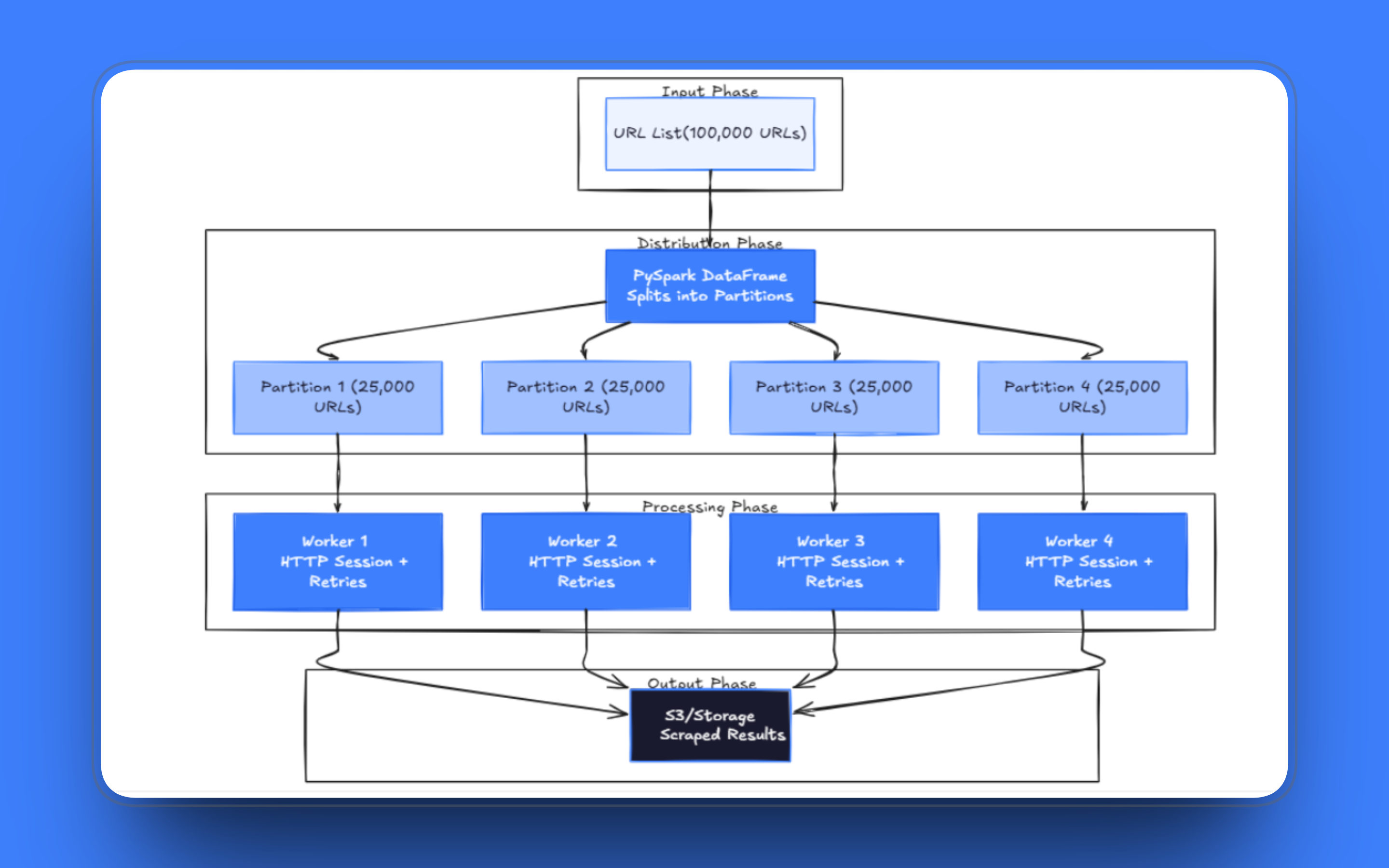
分散スクレイピングパイプラインの基盤となるのは、URLリストの読み込み方法です。PySparkでは、URLをDataFrameに格納すると、Sparkが自動的にそれをワーカー間で分散させます。各パーティションはデータの一部を保持し、Sparkはそれらのパーティションを利用可能なエグゼキュータに割り当てます。
基本的な設定は次のようになります:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])本番環境では、URLリストをハードコーディングするのではなく、ファイル、データベーステーブル、またはオブジェクトストレージから読み込むことになります。クロール優先度や最終取得タイムスタンプなどのメタデータを追加し始めると、スキーマも重要になります。
パーティション数は、最初に検討すべきチューニング項目です。パーティション数が少なすぎると、ワーカーは処理の遅いリクエストを待ちながらアイドル状態になります。逆に多すぎると、Sparkは実際のフェッチ処理ではなく、スケジューリングのオーバーヘッドに不釣り合いな時間を費やすことになります。
スクレイピングワークロードの妥当な初期設定は、エグゼキュータコアあたり2~4パーティションです。その後、タスクログに基づいて調整します。エグゼキュータが1秒未満でパーティションを完了するか、あるいは一貫して10分以上かかる場合は、パーティションサイズを調整する必要があります。
パターン2:パーティションレベルでリクエストを実行する
最初に試みたくなるのは、DataFrame内の各URLに対して行レベルの変換を適用することです。このアプローチは機能しますが、ウェブスクレイピングには適していません。各リクエストが個別の関数呼び出しをトリガーするため、注意を払わない限り、URLごとに新しい接続が確立されてしまいます。数百万行規模になると、このオーバーヘッドは急速に膨れ上がります。
正しいアプローチは`mapPartitions()`です。これは1行ずつ処理する代わりに、関数にパーティション全体をイテレータとして渡します。HTTPセッションを一度作成し、そのパーティション内のすべてのリクエストで再利用します。特にHTTPキープアライブをサポートするサーバーの場合、長時間実行されるセッションでの接続プールは、URLごとに新しいTCP接続を確立するよりも大幅に高速です。
from pyspark.sql import SparkSession
import requests
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
urls = [
("https://example.com/page1",),
("https://example.com/page2",),
("https://example.com/page3",)
]
df = spark.createDataFrame(urls, ["url"])
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception:
yield {
"url": url,
"status_code": None,
"html": None
}
results = df.rdd.mapPartitions(scrape_partition)リクエストが失敗した場合、例外を発生させるのではなく、フィールドがnullのレコードをyieldします。このアプローチは意図的なものです。例外を伝播させるとパーティションタスク全体が停止し、失敗前に実行されたすべての作業が失われてしまいます。nullレコードを返すことで、パーティションの実行を継続させ、後で失敗したURLを特定して再試行するための明確な方法を提供します。
早い段階で実施すべきことの一つは、SparkにRDDからスキーマを推論させるのではなく、StructTypeを使用して明示的な出力スキーマを定義することです。スキーマの推論にはデータのフルスキャンが必要であり、これはコストがかかる上、レスポンスの内容が予期せず空の場合、時折予期しない結果を生じることがあります。
パターン3:長時間の実行に対応できるワーカーの設計
100万ページをスクレイピングするジョブは、数時間にわたって実行されます。長時間の実行中には、接続のリセット、DNSタイムアウト、レート制限されたサーバーからの429エラー、そしてレスポンスの途中でサーバーが接続を切断することが時々発生します。これらはどれもコードのバグではなく、大規模なHTTPリクエストを行う際に必然的に生じる現象です。
これらの問題をすべて処理するには、パーティション関数が最適な場所です。リトライロジック、バックオフ遅延、タイムアウト設定、および障害記録はすべてそこに実装すべきです。すべてを単一のパーティション関数にまとめることで、Sparkパイプラインの残りの部分をクリーンに保ち、ワーカーの動作を独立してテストできるようになります。
import requests
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts) # 指数関数的バックオフ
if not success:
yield {
"url": url,
"status_code": None,
"html": None
}ここでいくつか注意点があります。リトライの遅延には、固定のスリープ時間ではなく、指数関数的バックオフが使用されています。偶発的なネットワークの乱れに対しては2秒の固定遅延で問題ありませんが、常にスロットリングされているサーバーにアクセスした場合、ワーカーの処理速度が大幅に低下してしまいます。また、nullレコードをyieldする前に例外の種類をログに記録してください。接続タイムアウトと403 Forbiddenの違いは、上流で何が起きているかについて、全く異なる情報を教えてくれます。
本番環境でのジョブの監視
ジョブが数時間にわたって数百万のURLを処理する場合、実行中の状況を把握できる必要があります。少なくとも、各パーティションから以下のメトリクスを追跡してください:
def scrape_partition(rows):
session = requests.Session()
partition_stats = {
"urls_attempted": 0,
"urls_succeeded": 0,
"urls_failed": 0,
"status_codes": {}
}
for row in rows:
partition_stats["urls_attempted"] += 1
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
partition_stats["urls_succeeded"] += 1
code = response.status_code
partition_stats["status_codes"][code] =
partition_stats["status_codes"].get(code, 0) + 1
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
partition_stats["urls_failed"] += 1
yield {
"url": url,
"status_code": None,
"html": None
}
# パーティション完了時の統計ログ出力
print(f"Partition stats: {partition_stats}")ジョブの実行中は、Spark UIでタスクの完了率を確認してください。タスクの完了速度に大きな差がある場合は、パーティションのバランスが崩れています。ログに403や429が頻繁に記録されている場合は、プロキシのローテーションを調整するか、リクエストの遅延を追加する必要があります。目標は、ジョブが失敗して6時間後に問題を発見するのではなく、ジョブがまだ実行中のうちに問題を捕捉することです。
ワーカーからの結果書き込み(本番環境でのパターン)
1 時間以上実行されるジョブには、回避できない失敗モードのリトライロジックが存在します。それは、実行中にドライバープロセスが停止してしまうことです。Spark は個々のタスクが失敗した場合に再スケジュールを行いますが、ドライバーがダウンすると、ジョブ全体が失われてしまいます。
この問題を解決するには、すべてのデータをドライバーに送信し、ジョブが完了するまで結果をメモリに保持するのではなく、各パーティションが完了するたびに結果を永続ストレージに書き込むようにします。foreachPartition() を使用すると、各パーティションを処理し、データをドライバーを経由せずにワーカーから直接出力として書き出すことができます:
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
import requests, time, uuid
spark = SparkSession.builder.appName("distributed_scraper").getOrCreate()
spark.sparkContext.setCheckpointDir("s3://your-bucket/checkpoints/")
schema = StructType([
StructField("url", StringType(), True),
StructField("status_code", IntegerType(), True),
StructField("html", StringType(), True)
])
def scrape_and_write(rows):
session = requests.Session()
results = []
for row in rows:
url = row["url"]
attempts = 0
success = False
while attempts < 3 and not success:
try:
response = session.get(url, timeout=30)
results.append((url, response.status_code, response.text))
success = True
except Exception as e:
attempts += 1
time.sleep(2 ** attempts)
if not success:
results.append((url, None, None))
# ワーカーからこのパーティションの結果を直接書き込み
partition_id = str(uuid.uuid4())
spark.createDataFrame(results, schema).write.mode("append").parquet(
f"s3://your-bucket/scrape-results/batch={partition_id}"
)
df.rdd.foreachPartition(scrape_and_write)各ワーカーは独自に出力ファイルを書き込みます。ドライバーが途中で停止した場合でも、完了したパーティションはすでにストレージ上に保存されているため、進行中のパーティションのみを再実行すれば済みます。スクレイピングされたデータに対して下流でSpark変換を行うジョブの場合、rdd.checkpoint() を使用すると負荷を軽減できます。これは、変換の実行前にRDDをチェックポイントディレクトリにマテリアライズするため、後段の処理で障害が発生しても、Sparkがスクレイピングステップ全体を再実行する必要がなくなります。
パターン 4: プロキシネットワーク経由でのリクエストルーティング
複数のワーカーを並列で実行するとスループットは向上しますが、ターゲットサーバーにはクラスタのIP範囲から大量のリクエストが殺到することになります。多くのサイトでは、単一のIP範囲からの集中トラフィックというまさにこのパターンに対して、レート制限やブロックが設定されています。リクエストをレジデンシャルプロキシネットワーク経由でルーティングすることで、トラフィックを複数のIPアドレスに分散させることができ、ブロックを引き起こすことなくワーカーを稼働させ続けるのに役立ちます。
パーティション関数内でセッションごとにプロキシを設定すれば、そのセッションからのすべてのリクエストが自動的にネットワークを経由してルーティングされます:
import requests
BRIGHTDATA_PROXY = (
"http://brd-customer-<CUSTOMER_ID>-ゾーン-<ゾーン_名>:"
"<ゾーン_パスワード>@brd.superproxy.io:33335"
)
def scrape_partition(rows):
session = requests.Session()
session.proxies = {
"http": BRIGHTDATA_PROXY,
"https": BRIGHTDATA_PROXY
}
for row in rows:
url = row["url"]
try:
response = session.get(url, timeout=30)
yield {
"url": url,
"status_code": response.status_code,
"html": response.text
}
except Exception as e:
yield {
"url": url,
"status_code": None,
"html": None
}Bright Dataのゾーンの設定によっては、トラフィックが中間証明書レイヤーを経由するため、リクエストでSSL検証エラーが発生する可能性があります。簡単な回避策としてverify=Falseを指定して処理を進めることもできますが、この方法では証明書の検証が完全に無効化されるため、プロキシとターゲット間の接続が侵害されていることをワーカーが検知できなくなります。
適切な修正方法は、Bright DataのCA証明書をダウンロードし、verify='/path/to/brightdata-ca.crt'として渡すことです。これにより、完全な検証が維持されます。また、留意すべき点として、この例のプロキシURLは、本番環境では環境変数またはシークレットマネージャーから取得する必要があります。分散環境では、これらの認証情報はシリアライズされてすべてのワーカーノードに配信されるため、情報が漏洩した場合、単一のマシン上で漏洩した場合よりも多くの情報が危険にさらされることになります。
JavaScriptでレンダリングされたコンテンツを提供するターゲットの場合、標準的なプロキシを経由するだけでは不十分です。BrightDataのスクレイピングブラウザは、JavaScriptの実行、CAPTCHAの解決、ブラウザフィンガープリンティングに対応しており、PlaywrightやPuppeteerと統合可能です。パーティション関数の構造は変わりません。単に、リクエストセッションを、スクレイピングブラウザのエンドポイントを指すPlaywrightブラウザインスタンスに置き換えるだけです。
よくある問題のトラブルシューティング
本番環境では、いくつかの問題が頻繁に発生します。パーティションタスクが繰り返しタイムアウトする場合は、まずパーティションサイズを確認してください。10,000件以上のURLを含むパーティションでは、リクエストが遅い場合にSparkのデフォルトタイムアウトを超過します。より小さなバッチに再パーティションするか、spark.task.maxFailuresおよびspark.network.timeoutの値を増やしてください。
プロキシを使用しているにもかかわらず429エラーが発生する場合は、複数のワーカーが同時に同じドメインにアクセスしていることを意味します。リクエスト間にランダムなジッターを追加してください:
import random
import time
def scrape_partition(rows):
session = requests.Session()
for row in rows:
time.sleep(random.uniform(1, 3))
# ... スクレイピングロジックの残りの部分エグゼキュータでメモリエラーが発生する場合は、通常、書き込み前にHTML全体を蓄積していることが原因です。結果をより頻繁に書き込むか、抽出されたフィールドのみが必要な場合は、パーティション関数内でHTMLをパースして破棄してください。
パーティションの完了速度に大きな差がある場合は、分散が不均衡であることを示しています。遅いドメインをワーカー全体に分散させるため、カウント数を増やして再パーティションを行ってください。
まとめ
これらのパターンは、大規模な環境でも機能する基盤を提供します。URLリストを分散させ、パーティションレベルでリクエストを実行し、長時間の実行に耐えるワーカーを構築し、トラフィックを、トラフィック量が増加してもブロックされないプロキシネットワーク経由でルーティングします。
本番環境のジョブでは、明示的なスキーマ、チェックポイント、適切なシークレット管理が必要になりますが、規模に関わらず構造的な決定事項は変わりません。ネットワークおよびインフラストラクチャの面では、Bright Dataが、通常であれば自ら構築・維持管理する必要がある要素のほとんどをカバーしています。





