
このガイドでは、以下の内容を学びます:
- Puppeteer Real Browserとは
- ボット検知回避とCAPTCHAの解決の仕組み
- 標準Puppeteerとの比較
- 実世界のボット検知システムに対する使用方法
- 主な代替手段
- 主な制限事項
- ボット対策ブラウザ自動化のより優れたアプローチ
さっそく見ていきましょう!
Puppeteer Real Browserとは?
Puppeteer Real Browserは、Puppeteerで制御されるブラウザの動作を実際のユーザーに近づけるJavaScriptライブラリです。これにより、CloudflareなどのWAFサービスにおけるボット検知を低減します。また、Cloudflare Turnstileを含む自動CAPTCHAの解決機能もサポートしています。
このライブラリは、プロキシや標準Puppeteerの全機能をサポートしつつ、カスタム設定でPuppeteerを拡張します。オープンソースでGitHubのスター数は1000以上、npmではpuppeteer-real-browserとして利用可能、デプロイ用にDockerもサポートしています。
注記: 2026年2月、ライブラリ作者であるmdervisayganはプロジェクトの更新終了を発表しました。ただし、コミュニティメンバーによるフォークを通じた開発継続の可能性もあり、Puppeteer Real Browserが完全に終了したとは限りません。
Puppeteer Real Browserの動作原理
Puppeteer、Playwright、Seleniumなどのブラウザ自動化ツールを使用したことがある方なら、これらのツールで制御されるブラウザがアンチボットシステムに検知される可能性があることをご存知でしょう。特にヘッドレスモードで動作する場合、最高のヘッドレスブラウザを使用してもこの傾向は顕著です。
ブロックが発生するのは、自動化ライブラリがブラウザを制御しやすいように設定するためです。アンチボットソリューションは、これらの設定や「リーク」を検知し、リクエストが通常のブラウザを使用する実在の人間からか、自動化されたボットからかを判断します。
Puppeteer Real Browserは、自動化検出を防ぐために設計されたPuppeteerおよびPlaywright向けパッチの集合体であるRebrowserを用いてこの問題に対処します。
Rebrowserはpuppeteer-coreを直接修正し、ブラウザランタイムにパッチを適用してPuppeteerが残すボットのような痕跡を除去します。これらの変更によりブラウザは実際のユーザーセッションに近づき、アンチボットシステムによるブロックの可能性が低減されます。
ただし、CloudflareのようなWAFでは依然としてワンクリックCAPTCHAが表示される場合があります:
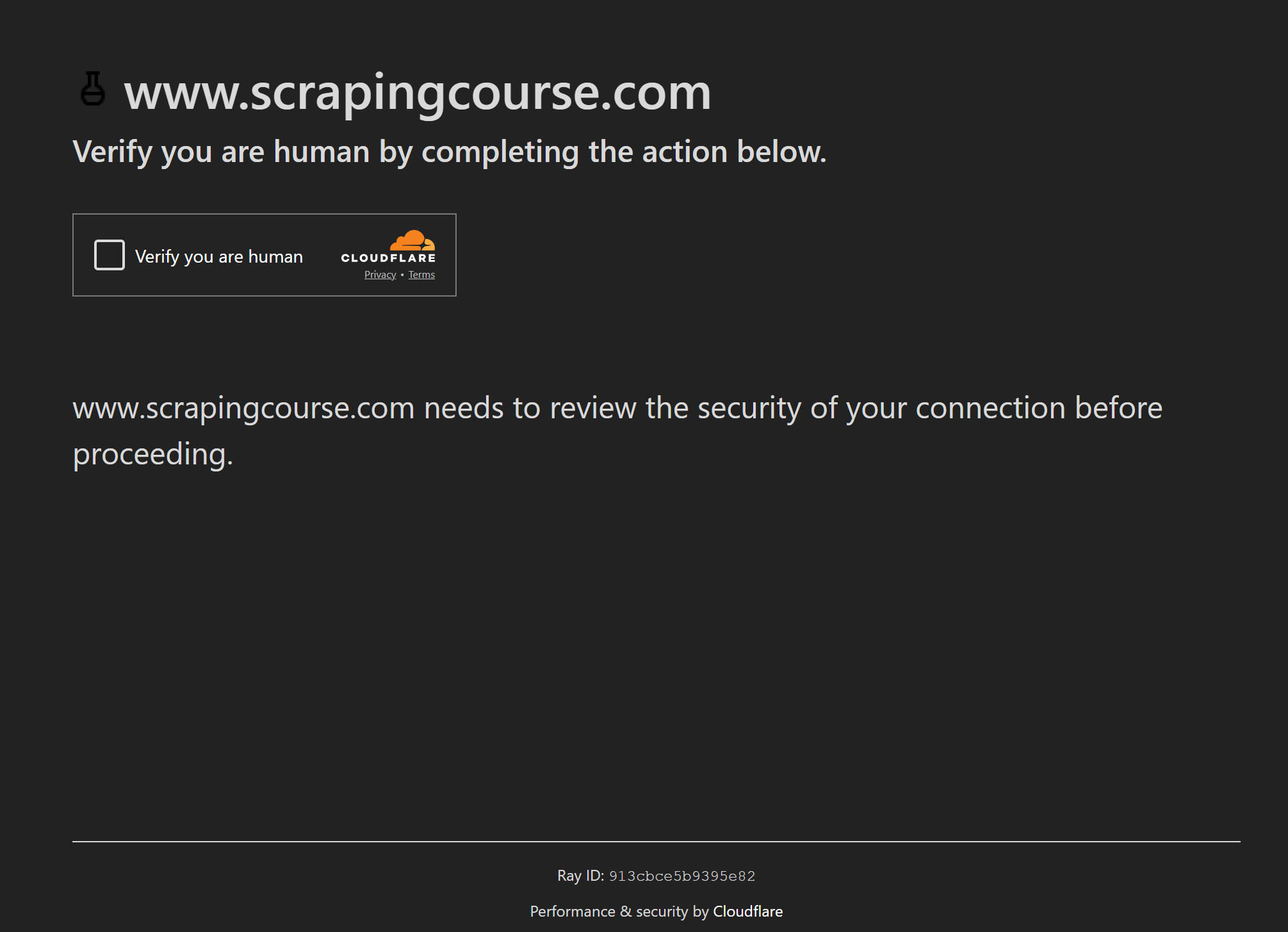
その場合、Puppeteer Real Browserはghost-cursorに依存し、実際のユーザーと同様にCAPTCHAと対話します。これはPuppeteerや任意の2D平面上で人間のようなマウス動作を生成するJavaScriptライブラリです。
問題は、Puppeteerのマウスイベントが不自然なカーソル動作により合成と判定されやすい点です。Puppeteer Real Browserは.screenXと.screenY値の処理方法を改善し、マウス動作をより自然に見せることでこの問題を解決します。これによりCloudflare Turnstile、reCAPTCHA、その他ワンクリックCAPTCHAを欺き、操作が実ユーザーによるものと認識させることが可能になります。
このライブラリには以下も含まれます:
- Puppeteer Extra: プラグインによる機能拡張を可能にします
- Xvfb: 仮想ブラウザ表示を処理し、ヘッドレス環境に最適
要するに、Puppeteer Real Browserは様々な強化機能を組み合わせ、検出を回避しながら人間ユーザーを模倣するステルス性の高い高精度自動化ツールを実現します。
Puppeteer Real Browser と Puppeteer の比較
以下は両技術を比較した要約表です:
| Puppeteer | Puppeteer Real Browser | |
|---|---|---|
| GitHubスター数 | 1kスター | 89.7kスター |
| npmライブラリ | puppeteer |
puppeteer-real-browser |
| npm ダウンロード | 週約360万ダウンロード | 週約1万ダウンロード |
puppeteer-coreバージョン |
標準のpuppeteer-core |
自動化の痕跡を削除するためにrebrowser-puppeteer-coreをパッチ適用 |
| ボット対策 | 高度なボット対策で容易に検知される | ボット検知システム(Cloudflare、Akamaiなど)を回避するよう設計 |
| API | デフォルト | 追加拡張機能付き同一Puppeteer API |
| プロキシサポート | プロキシをサポート | プロキシをサポート |
| CAPTCHA処理 | 組み込みのCAPTCHAの解決機能なし | ワンクリックCAPTCHAの解決をサポート(例:Cloudflare Turnstile、reCAPTCHA) |
| プラグインサポート | ネイティブプラグインサポートなし | プラグインサポートのためpuppeteer-extraと統合 |
| メンテナンスと更新 | Googleによる積極的なメンテナンス | 作者により開発終了(2026年2月)、ただしコミュニティによる継続の可能性あり |
Puppeteer Real Browserを使用してCAPTCHAを回避する方法
Puppeteer Real Browserの機能を実証するため、Scraping CourseのAnti-Bot Challengeページでテストします:
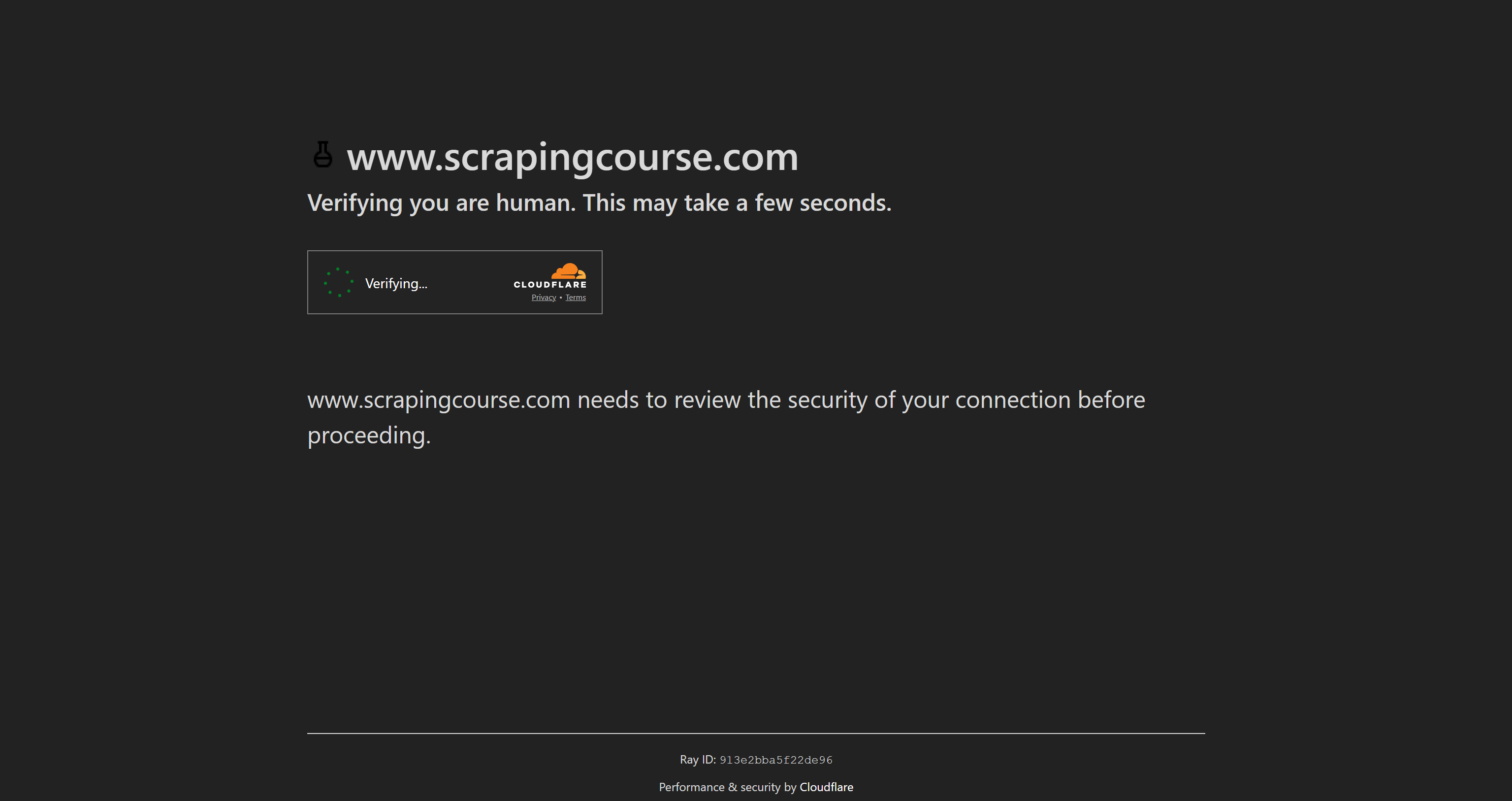
このCloudflare保護ページにはターンスタイル方式のワンクリックCAPTCHAが実装されています。本ステップバイステップ解説では、Puppeteer Real Browserを用いてこれを解決する方法を示します。
代替アプローチについては、PuppeteerでのCAPTCHA回避ガイドを参照してください。重要な点は、標準的なPuppeteerスクリプトでこのページにアクセスしようとすると、常にターンスタイルCAPTCHAに遭遇しブロックされることです。
これからご覧いただく通り、Puppeteer RealBrowserはCloudflareや類似のボット対策機能を回避する効果的な解決策です!
ステップ #1:puppeteer-real-browserのインストール
Node.jsプロジェクトが既に設定されていることを前提とします。設定されていない場合は、npm initを使用して作成できます。
次に、プロジェクトフォルダに移動し、以下のコマンドでpuppeteer-real-browserをインストールします:
npm install puppeteer-real-browserLinuxでは、システムレベルの依存関係としてxvfbもインストールする必要があります。Debianベースのシステムでは、以下でインストールしてください:
sudo apt-get install xvfbこれで準備完了です。Puppeteer Real Browserを使用してCAPTCHAを回避できます。
ステップ #2: 初期設定
JavaScriptスクリプト内で、Puppeteer Real Browserからconnectをインポートします:
const { connect } = require("puppeteer-real-browser");connect()関数を使用すると、非同期関数内で修正されたブラウザエンジンへの接続を確立できます:
(async () => {
const { browser, page } = await connect({
headless: false,
turnstile: true,
});
// スクラッピングロジック...
await browser.close();
})();通常のPuppeteerと同様に、リソースを解放するにはbrowser.close()を呼び出す必要があります。
Puppeteer Real Browser のconnect()関数は以下のパラメータを受け付けます:
headless: デフォルトはfalse。他の値(「new」「true」「shell」など)も使用可能ですが、false が最も安定しています。args: 追加のChromiumフラグを文字列配列として渡せます。サポートされているフラグを参照してください。customConfig: Puppeteer Real Browserはchrome-launcherを使用して初期化されます。ここで渡したオプションは直接初期化引数として追加されます。userDataDirやカスタムChromeパス(chromePath)の設定に使用できます。turnstile:trueの場合、Puppeteer Real BrowserはCloudflare Turnstile CAPTCHAを自動クリックします。connectOption:puppeteer.connect()で Chromium に接続する際に送信されるオプション。disableXvfb: Linux環境でheadless: falseの場合、ブラウザ実行に仮想ディスプレイ(xvfb)が使用されます。trueに設定するとこれを無効化し、実際のブラウザウィンドウを表示します。ignoreAllFlags:trueの場合、初回読み込み時に表示される「はじめに」ページを含む、すべてのデフォルト初期化引数が上書きされます。plugins: Puppeteer Extraプラグインの配列。詳細は公式ドキュメントを参照。
上記関数がサポートするその他のオプションはすべて、Puppeteerのconnect()メソッドに由来します。
Cloudflareをバイパスするため、この例で重要な設定はturnstile をtrueにすることです。
ステップ #3: ターゲットページへの接続
Puppeteer APIのgoto()関数を使用してターゲットページに移動します:
await page.goto("https://www.scrapingcourse.com/antibot-challenge");turnstile が true に設定されているため、Puppeteer Real Browser は自動的に Cloudflare Turnstile CAPTCHA の読み込みを待機し、その解決を試みます。
ステップ #4: CAPTCHAの解決を待機
ターゲットページをシークレットモードで開いて手動でCAPTCHAの解決を行うと、以下の結果が得られます:

開発者ツールでメッセージを検査すると、以下が表示されます:
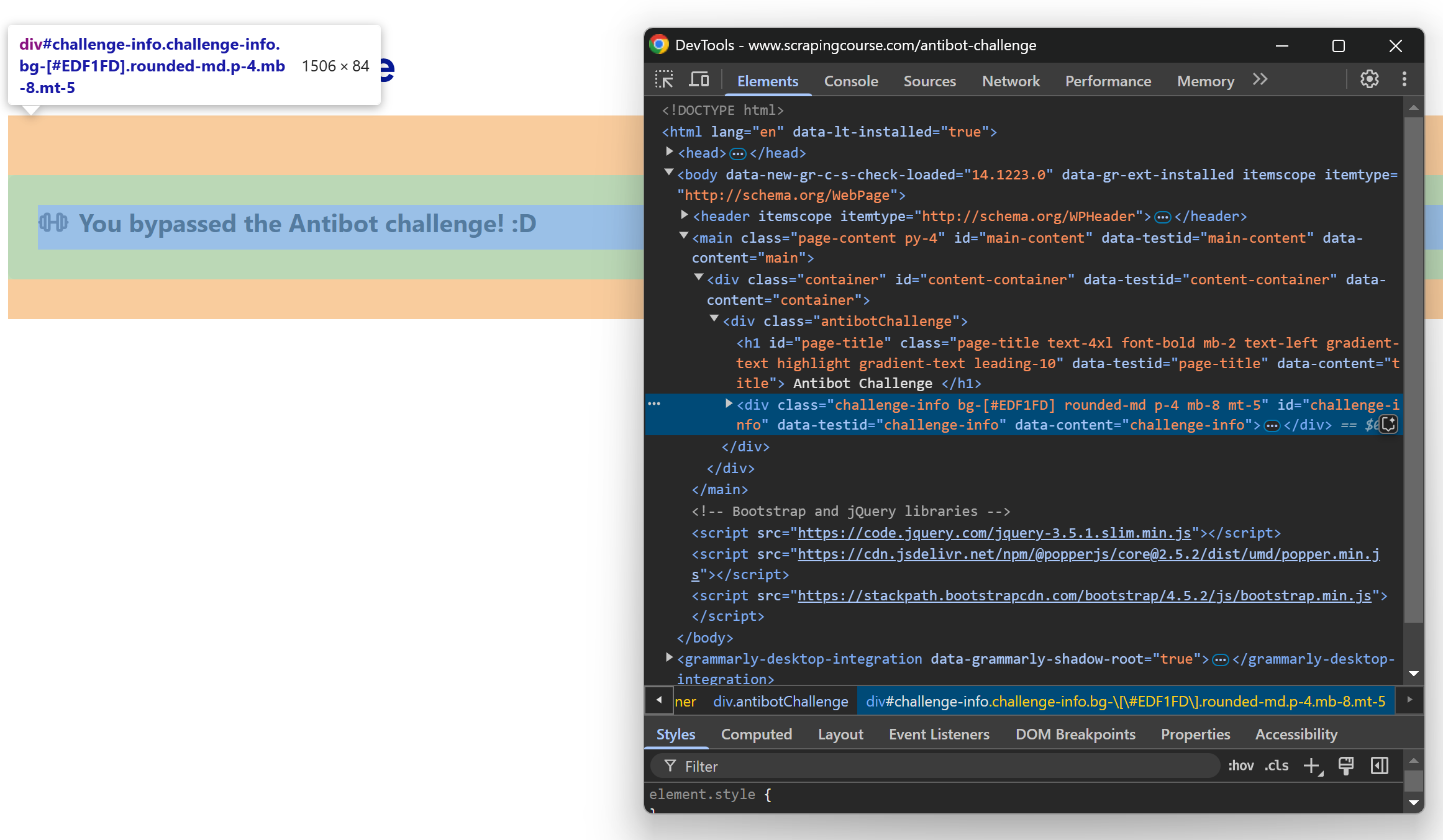
メッセージ要素は#challenge-infoCSS セレクタで選択可能であることに注意してください。
次に、ページDOMの変更を待機するカスタム関数を定義します:
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}この関数は、puppeteer-real-browserがCAPTCHA解決用の組み込みコールバックを提供しないため必要です。Puppeteer Real BrowserがCAPTCHAを正常に回避すると、ページDOMが更新されるため、これらの変更を待機する必要があります。
したがって、以下のようにdelay()を使用して設定した時間待機し、ページが完全に更新されるのを待つことができます:
await delay(10000);次に、対象のメッセージ要素がページ上に表示されるまで待機します:
await page.waitForSelector("#challenge-info", { timeout: 5000 });最後に、その内容を取得して出力します:
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`Page message: "${challengeInfo}"`);すべてが期待通りに動作した場合、スクリプトは以下の出力を生成します:
Page message: "You bypassed the Antibot challenge! :D"ステップ #5: 全てを統合する
以下が最終的なPuppeteer実ブラウザスクリプトです:
const { connect } = require("puppeteer-real-browser");
// ハード待機を実装するカスタム関数
function delay(timeout) {
return new Promise((resolve) => {
setTimeout(resolve, timeout);
});
}
(async () => {
// 制御対象のブラウザに接続
const { browser, page } = await connect({
headless: false,
turnstile: true, // Turnstile CAPTCHA処理を有効化
connectOption: {
defaultViewport: null, // ビューポートをブラウザウィンドウ全体に設定
},
args: ["--start-maximized"], // 最大化状態でブラウザを起動
});
// チャレンジページに移動
await page.goto("https://www.scrapingcourse.com/antibot-challenge", {
waitUntil: "networkidle2", // ページが完全に読み込まれアイドル状態になるまで待機
});
// CAPTCHAの解決まで最大10秒待機
await delay(10000);
// チャレンジ情報要素が表示されるまで最大5秒待機
await page.waitForSelector("#challenge-info", { timeout: 5000 });
// チャレンジ情報テキストを取得して出力
const challengeInfo = await page.$eval(
"#challenge-info",
(el) => el.textContent.trim()
);
console.log(`ページメッセージ: "${challengeInfo}"`);
// ブラウザを閉じ、リソースを解放
await browser.close();
})();上記のコードを実行すると、以下の動作をするブラウザが開きます:
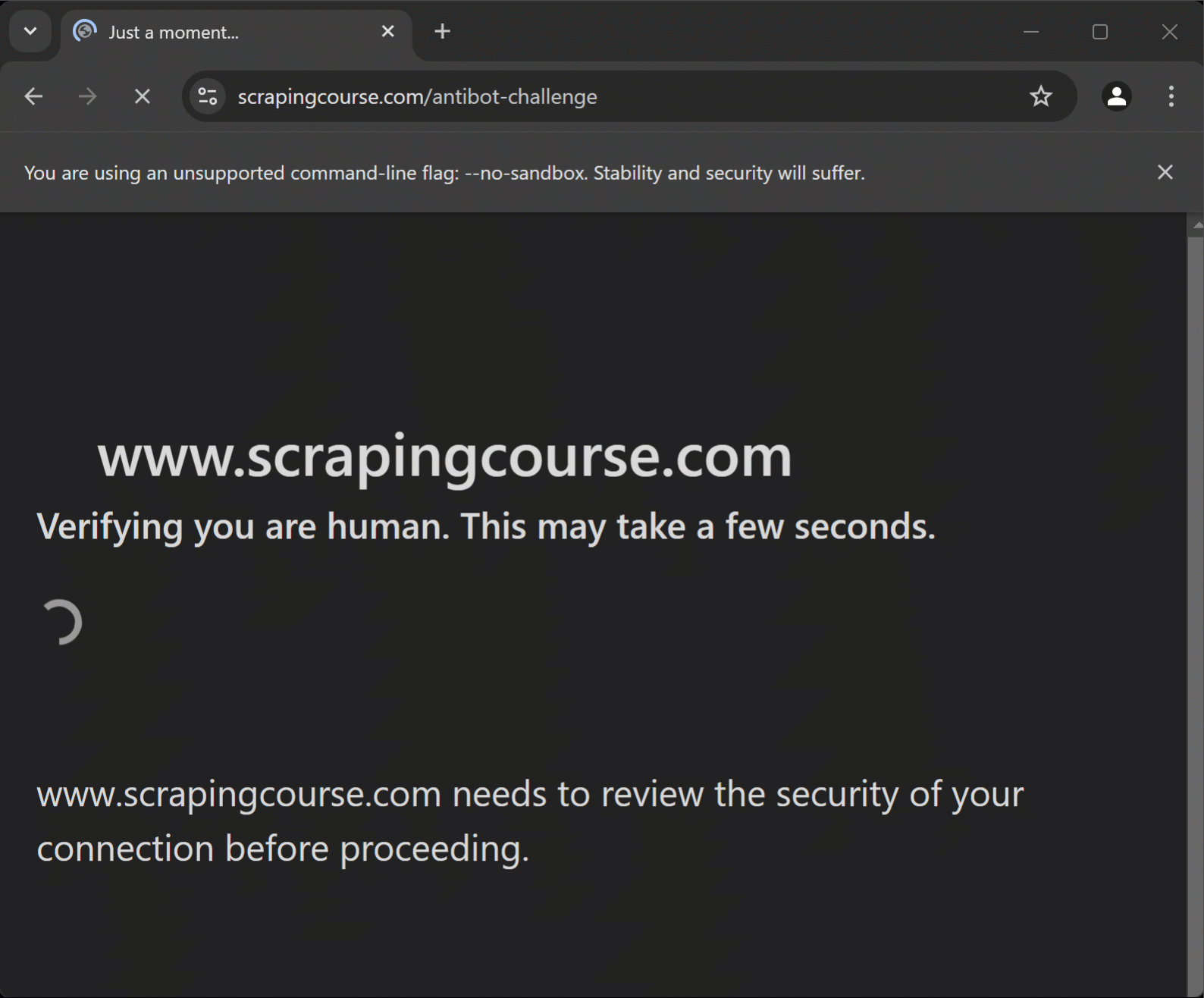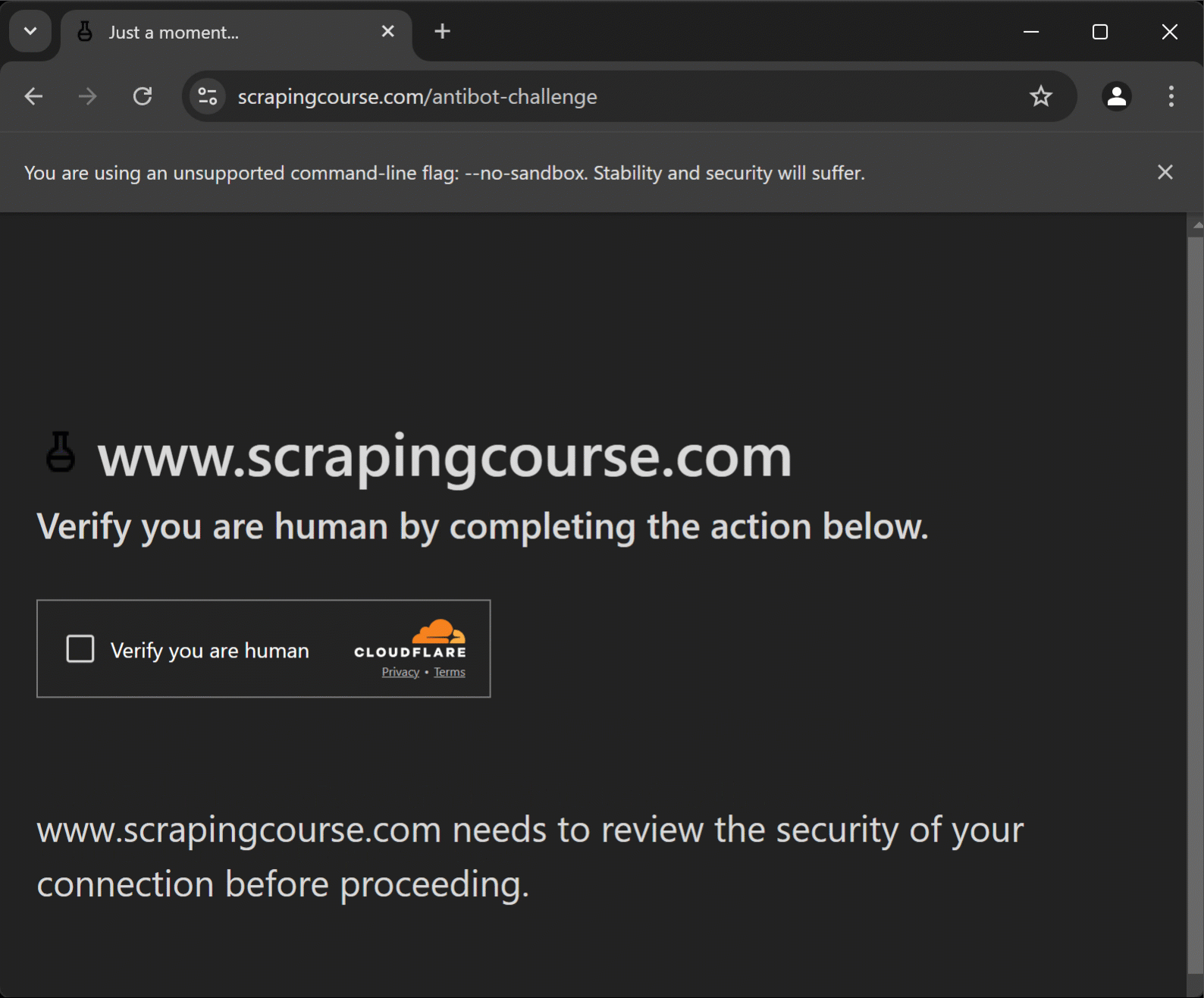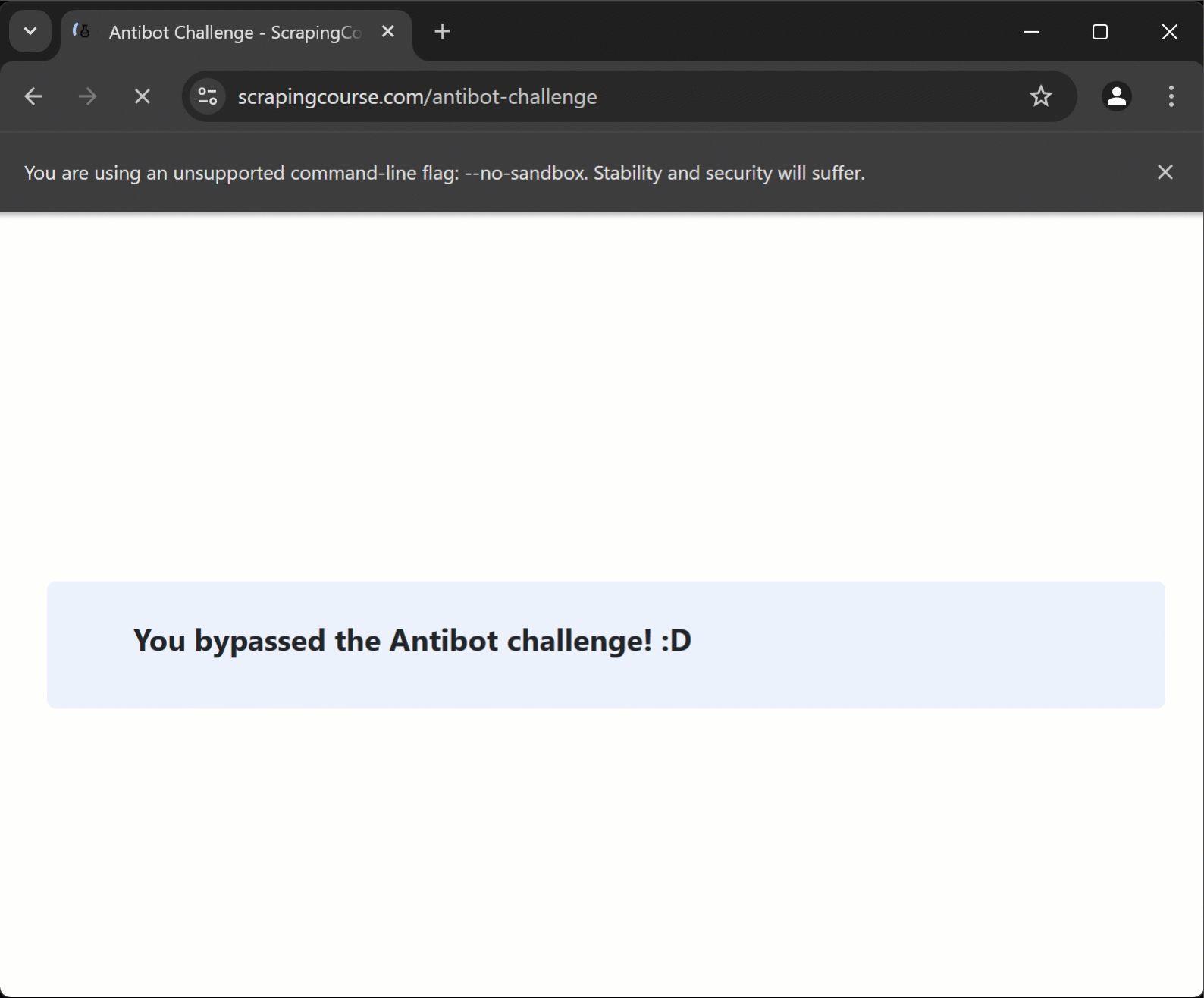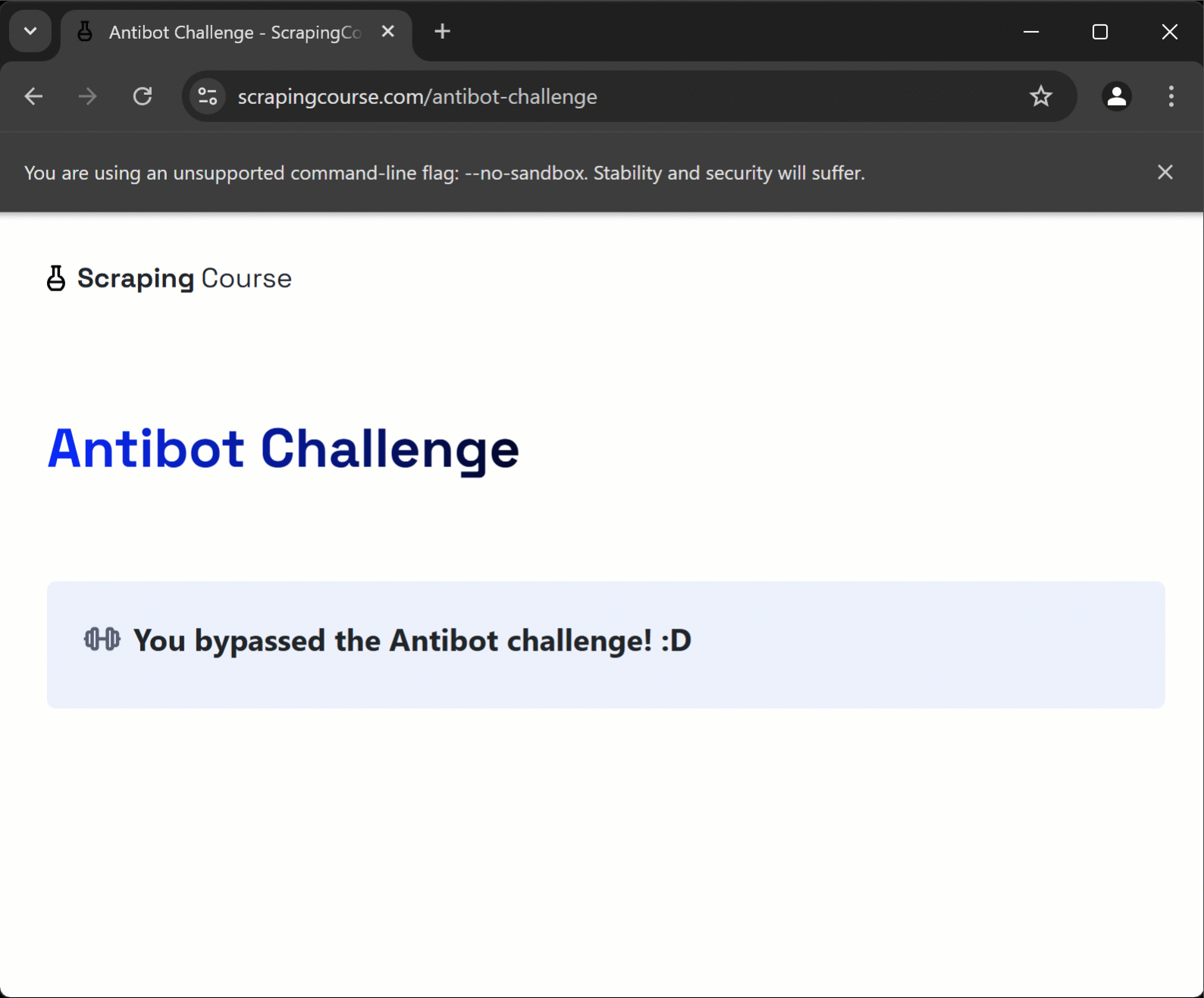
スクリプトはCloudflare保護ページにアクセスし、CAPTCHAの解決後、目的のページに到達してデータを抽出します。
期待通り、スクリプトはターミナルに以下の結果を出力します:
Page message: "You bypassed the Antibot challenge! :D"素晴らしい!Cloudflare CAPTCHAが自動解決されました。
puppeteer-real-browserの代替手段
puppeteer-real-browserはメンテナンスが終了しているため、同様の機能を提供する代替手段を検討する価値があります。例えば:
- Puppeteer Stealth: Puppeteer Extra用プラグイン。自動化を検知されにくくするため、様々な回避策を適用します。ブラウザのフィンガープリントを改変し、WebRTCリークを無効化し、人間のような行動を模倣してアンチボット対策を回避します。
- Playwright Stealth: Puppeteer Stealthと同様のステルス技術を統合したPlaywright Extraプラグイン。ブラウザAPIをパッチ処理し、フィンガープリント漏洩を防止します。
- SeleniumBase: 反ボット検出機能を内蔵した、フル機能のSeleniumベース自動化フレームワーク。ボット回避技術、ユーザーエージェント偽装、CAPTCHA処理、その他Seleniumスクリプトがボット保護を回避するためのツールを含む。
- undetected-chromedriver: Seleniumスクリプトがボット検知を回避するのを支援する、修正されたChromeDriverバージョン。自動化フラグを削除し、WebDriverプロパティを難読化し、ブラウザが人間が操作するセッションのように振る舞うことを保証します。
Puppeteer Real Browserの制限事項
Puppeteer Real Browserは強力なアンチボットブラウザ自動化ツールですが、いくつかの欠点も存在します。作者はこれらの制約について透明性を持って説明し、その限界を明確に示しています。
主な制限事項は以下の通りです:
- メンテナンス終了: 2026年2月時点で、原作者はライブラリの更新を終了すると発表しました。今後の改善は、積極的な開発ではなくコミュニティの貢献に依存します。
- 100%検出不可能ではない:ボット検出を低減しますが、高度なアンチボットシステムは自動化されたトラフィックを依然として検知する可能性があります。
- 追加設定が必要:最適なステルス性と機能性を得るには、プロキシやヘッダーなどの設定を微調整する必要がある場合があります。
- windowオブジェクトの関数にアクセス不可:Rebrowserによるブラウザランタイムの閉鎖が原因。回避策としてpuppeteer-intercept-and-modify-requestsによるJavaScript注入、またはChrome拡張機能の使用が可能。
- 外部ライブラリへの依存: 本ライブラリはRebrowser、Puppeteer Extra、ghost-cursorなどのサードパーティプロジェクトに依存しており、これらは変更または廃止される可能性があります。
- reCAPTCHAに関する問題: reCAPTCHA v3は有効なGoogleセッションの引き渡しを必要とします。検出不能なブラウザを使用しても、有効なセッションなしの自動化試行はフラグが立てられる可能性が高いです。
シームレスなアンチボットブラウザ自動化
上記の欠点は、Puppeteer Real Browser自体を検討する意欲を削ぐかもしれません。代替手段を試すことも可能ですが、同様の課題に直面する可能性が高いでしょう。
重要なのは、ほとんどのアンチボットブラウザ自動化ライブラリが、ブラウザ自動化ライブラリ自体ではなくブラウザのパッチ適用に焦点を当てている点です。これらのライブラリのコアに軽微な修正が必要な場合もありますが、検出漏れを回避するためのブラウザエンジンのパッチ適用に労力のほとんどが費やされます。
ここで想像してみてください。Playwright、Puppeteer、Seleniumといった標準的なブラウザ自動化ライブラリを、その更新と安定したAPIに依存したまま、ウェブスクレイピング専用に設計されたクラウドベースのスケーラブルなブラウザを制御できる姿を。まさにそれがBright Dataのスクレイピングブラウザが提供する体験なのです!
スクレイピングブラウザには、ブロックを自動的に処理する組み込みのウェブサイトアンロック機能が付属しています。400M+ monthly個のIPからなるプロキシネットワークとシームレスに連携し、クラウド上で効率的に動作し、統合されたCAPTCHAソルバーを備えています。
スクレイピングブラウザこそが、ボット対策ブラウザ自動化の真の解決策なのです!
結論
本記事では、Puppeteer Real Browserを使用したPuppeteerにおけるボット検知対策について解説しました。このライブラリは、ブロックされずにウェブスクレイピングを行うためのpuppeteer-coreのパッチ適用版を提供します。
問題は、puppeteer-real-browser がもはやメンテナンスされていないことです。そのため、今日動作していても、アンチボット対策が進化し続ける中で、明日には動作しなくなる可能性があります。
問題はブラウザ制御用のPuppeteer APIではなく、ブラウザ自体にあります。解決策は、スクレイピングブラウザのようなクラウドベースで常に更新され、スケーラブルなブラウザであり、ボット対策回避機能を内蔵していることです!
Bright Dataのスクレイピングブラウザは、Puppeteer、Selenium、Playwrightなどに対応した高拡張性クラウドブラウザです。ブラウザフィンガープリンティング対策、CAPTCHA解決、自動リトライを自動的に処理します。
さらに、グローバルプロキシネットワークにより、リクエストごとに出口IPを自動ローテーションします。ネットワーク構成は以下の通りです:
- データセンター・プロキシ– 77万以上のデータセンターIP
- レジデンシャルプロキシ–195ヶ国以上で1億5000万以上のレジデンシャルIP。
- ISPプロキシ– 70万以上のISP IPアドレス。
今すぐBright Dataの無料アカウントを作成し、スクレイピングブラウザをお試しいただくか、プロキシをテストしてください。





