
このブログ記事では、以下のことを学びます:
- Kubeflow Pipelinesに専用のWebデータ収集コンポーネントを含めるべき理由
- – 特定のTikTok感情分析パイプラインへの本手法の適用例
- 特定のスクレイピングソリューションを介してTikTokコメントデータフィードに接続し、そのパイプラインを実装する方法。
さっそく見ていきましょう!
構造化されたウェブスクレイピングデータがKubeflow Pipelinesにもたらす利点
現代の機械学習およびAIワークフローは、高品質なデータに大きく依存しています。一方、従来のパイプラインは静的なデータセットや前処理済みのファイルを取り込むことが多く、こうしたデータソースはすぐに陳腐化し、古い情報で訓練されたモデルを残すことになります。
そこで構造化されたウェブスクレイピングデータの出番です!ウェブからリアルタイムの文脈データを集めることで、パイプラインは最新のトレンド、ユーザー行動、新興コンテンツに常に対応し続けられます。
モジュール化・再現性・拡張性を備えたMLワークフロー向けに設計されたKubeflow Pipelinesは、ウェブデータ収集コンポーネントの統合により多大な恩恵を受けます。こうしたコンポーネントは最新の構造化フィードを提供し、自動的に取り込み、フィルタリングし、下流で処理することが可能です。
パイプラインにウェブデータ収集コンポーネントを組み込むことは、モデルの精度向上に確実に寄与します。したがって、専用のウェブデータ収集コンポーネント(あるいは複数のソースに対応する複数コンポーネント)を追加することは戦略的に意味があります。これによりパイプラインは継続的に適応し、再学習を行い、ほぼリアルタイムで洞察を生成できるようになり、あらゆるAI駆動プロジェクトの強固な基盤を構築します。
TikTok感情分析向けKubeflowパイプラインの紹介
ウェブデータ収集コンポーネントがKubeflowパイプラインをいかに強化するか理解するため、実例を考えてみましょう。TikTok投稿の集合を処理し、そのコンテンツの感情分析を行うデータ分析ワークフローを構築したいと想像してください。
2つのコンポーネントからなるパイプラインを設計できます:
- TikTokコメントデータコンポーネント:ウェブスクレイピングによりTikTok投稿から構造化されたコメントデータを取得。
- データ分析コンポーネント:それらのコメントに感情分析結果(
ポジティブ、ネガティブ、ニュートラル)を付与します。
問題は、TikTok(および他の多くの人気プラットフォーム)のスクレイピングが非常に困難であることです。これは、CAPTCHA、JavaScriptによる制限、IPブロック、レート制限などの反スクレイピング対策が原因です。このプロセスをスケールさせると、スロットリングや禁止措置によってデータ収集が容易に中断されるため、複雑さが増すだけです。
これらの問題を回避するには、Bright Dataのような最高水準のウェブデータサービスで収集コンポーネントを強化するのが合理的です。Bright Dataは、195カ国にまたがる1億5000万のプロキシIP、99.95%の成功率、99.99%の稼働率を基盤とした高度にスケーラブルなインフラにより、大規模かつ信頼性の高いウェブスクレイピングを実現します。
具体的には、TikTok投稿から構造化データを収集する作業を簡素化するウェブスクレイピングAPI「TikTok Scraper」を活用します。これは人気ドメインからデータを取得可能な数多くのウェブスクレイピングAPIの一つです。同様に、Filter Dataset APIを使用 すればBright Dataデータセットからフィルタリング済みデータを取得でき、すぐに使えるデータでML/AIパイプラインを強化できます。
動的ウェブスクレイピングデータコンポーネントを用いたKubeflowパイプライン構築方法
このガイドセクションでは、前述のTikTok感情分析用Kubeflowパイプラインの構築方法を解説します。
以下の手順に従ってください!
前提条件
このチュートリアルを実行するには、以下の環境が必要です:
- Dockerがインストールされ、マシン上で実行されていること。
- ローカルにPython 3.10以上がインストールされていること。
- APIキーが正しく設定されたBright Dataアカウント(今すぐ設定する必要はありません。後述の専用セクションで手順を案内します)。
Kubeflow Pipelinesの基本的な動作を理解していると、以下の手順の理解に役立ちます。
以下の例を実行する推奨OSは、Linux、macOS、またはWSL(Windows Subsystem for Linux)です。
ステップ #1: プロジェクト設定
ターミナルを開き、Kubeflow Pipelinesプロジェクト用の新規ディレクトリを作成します:
mkdir kfp-bright-data-pipelineプロジェクトディレクトリに移動し、その中にPython仮想環境を作成します:
cd kfp-bright-data-pipeline
python -m venv .venv次に、お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeまたはPyCharm Community Editionを推奨します。
プロジェクトディレクトリのルートにtiktok_sentiment_analysis_kfp_pipeline.pyという名前の新規ファイルを作成します。ディレクトリ構造は次のようになります:
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSの場合は以下を実行:
source venv/bin/activateWindowsでは同等の操作として以下を実行します:
venv/Scripts/activate仮想環境をアクティブ化した状態で、必要な依存関係をインストールします:
pip install kfp必要なライブラリはkfpのみです。これにより、ポータブルでスケーラブルな機械学習パイプラインを構築・コンパイルできます。
最後に、tiktok_sentiment_analysis_kfp_pipeline.pyを開き、必要なモジュールをインポートします:
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Datasetこれで完了です!Kubeflowパイプラインを構築できるPython開発環境が整いました。
ステップ #2: Bright Data の利用開始
パイプラインの最初のコンポーネントでは、Bright DataのウェブスクレイピングAPIを使用してライブWebデータを取得します。実装前に、Bright Dataアカウントを適切に設定する必要があります。
ウェブスクレイピングAPIを使用するため、公式ドキュメントを数分間確認することをお勧めします。簡単に言うと、これらのAPIは人気ウェブサイトからの構造化データフィードを提供し、ML/AIワークフロー(またはその他のサポートされているユースケース)で利用可能です。
アカウントをお持ちでない場合は新規作成してください。既存アカウントをお持ちの場合はログインし、ユーザーダッシュボードを開きます。そこから「Webスクレイパー」セクションに移動します:
「Web Scrapers Library」タブに移動します。インターネット上で最も人気のあるプラットフォーム向けに、120以上の既製スクレイパーが用意されています。
本チュートリアルでは「tiktok.com」を検索します。目的はTikTok投稿のリアルタイムコメントデータを取得し、感情分析を実行することです。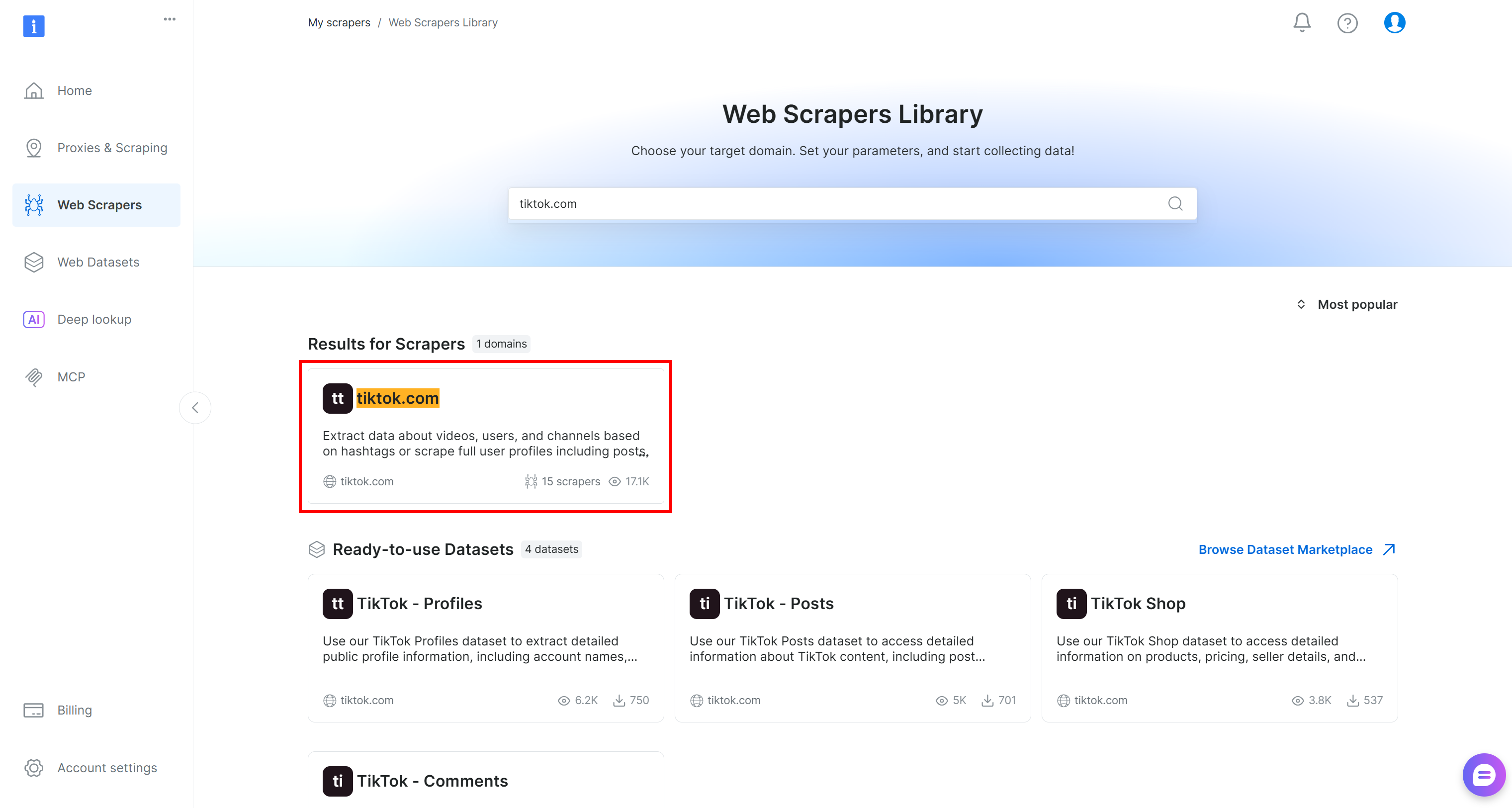
TikTokスクレイパーページ内で、利用可能なスクレイピングエンドポイントを確認してください。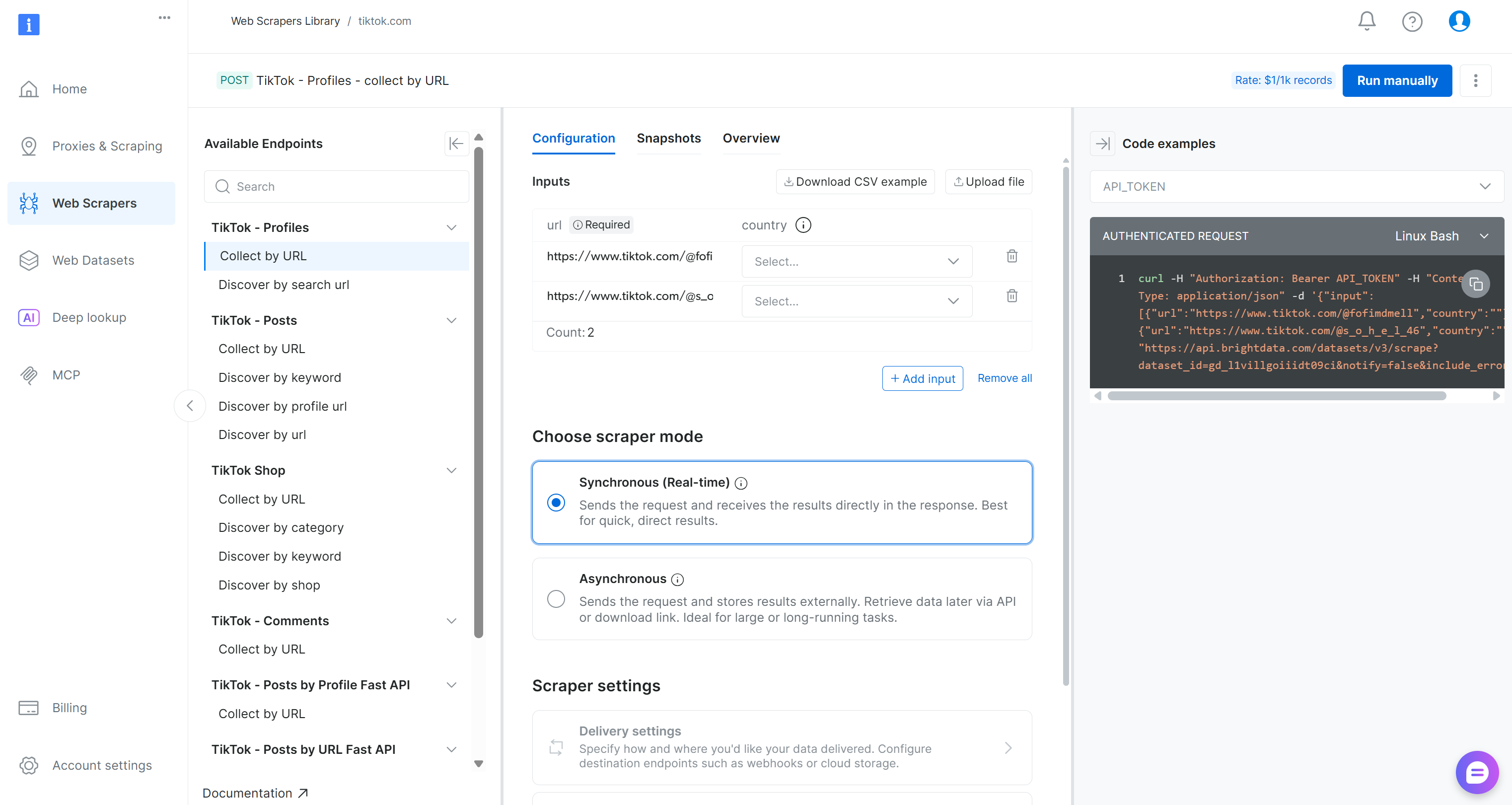
ここでは入力パラメータの設定、リクエスト/レスポンス形式の確認、API呼び出し例の確認などが可能です。
このパイプラインでは、「TikTok – Comments」ドロップダウンから「Collect by URL」スクレイパーを探します: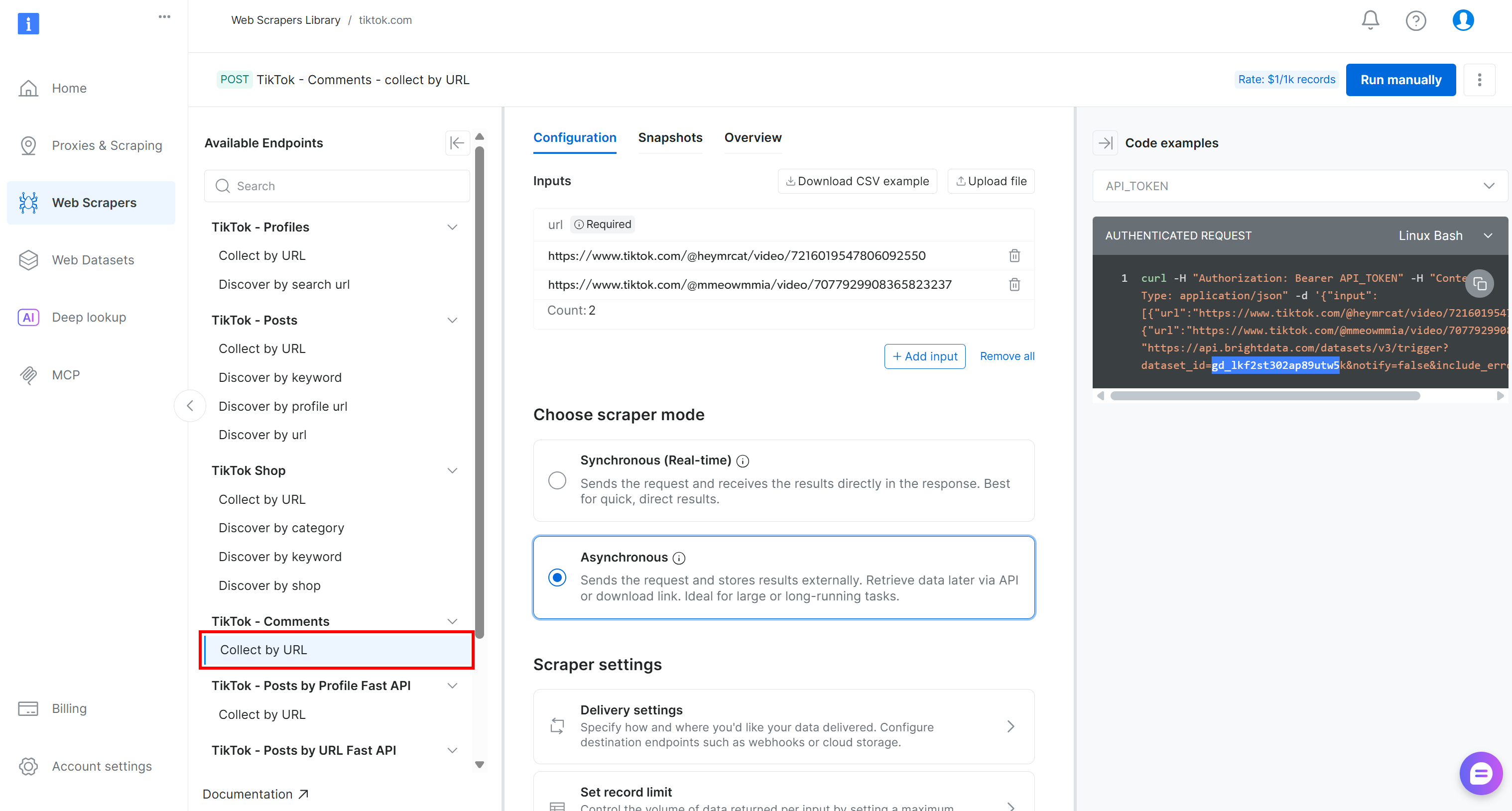
これが、Kubeflowパイプラインのデータ収集コンポーネントで使用するBright Data提供のエンドポイントです。
そのデータセットIDをメモしてください:
gd_lkf2st302ap89utw5kこのIDは、TikTokコメントデータ収集用の特定のウェブスクレイピングAPIをトリガーするために必要です。
また、右側のスニペットで確認できるように、Bright Data APIによるウェブスクレイピングAPIへの呼び出しはAPI_TOKENを使用して認証されます。この値は、APIリクエストの認証に推奨される方法である、ご自身のBright Data APIキーに置き換える必要があります。
ドキュメントの説明に従ってAPIキーを取得し、安全な場所に保管してください。次のステップで使用します!
ステップ #3: Webデータ収集コンポーネントの定義
TikTokスクレイピング用にBright DataウェブスクレイピングAPIを統合し、ウェブデータ収集用のKubeflowパイプラインコンポーネントを実装します:
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
# Bright Data ウェブスクレイピングAPI「TikTok – コメント → URLで収集」のID
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Bright Dataへの全リクエストに共通するHTTPヘッダー
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# 入力されたTikTok投稿に対してBright DataウェブスクレイピングAPIを実行
trigger = requests.post(
f"https://api.brightdata.com/データセット/v3/trigger?データセット_ID={TIKTOK_データセット_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# データスナップショットIDを取得
snapshot_id = trigger.json()["snapshot_id"]
# 対象データを含むスナップショットが生成されたか確認するため、スナップショットエンドポイントをポーリング
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# JSONレスポンスデータにアクセス
response_data = progress.json()
# レスポンスにステータスが含まれていない場合、スクレイピングされたデータが含まれていることを意味する
if isinstance(response_data, dict) and "status" in response_data:
# 現在のスナップショットステータスを抽出
status = progress.json()["status"]
# 次のチェックまで5秒待機
time.sleep(5)
else:
scraped_data = response_data
break
# スクレイピングしたデータセットを保存
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)注:<YOUR_BRIGHT_DATA_API_KEY>プレースホルダーは、事前に取得した Bright Data API キーに置き換えてください。本番環境向けのパイプラインでは、コンポーネントにシークレットをハードコーディングしないでください。代わりに、ドキュメントで説明されているように安全に管理してください。
Kubeflow Pipelinesにおいて、コンポーネントとは特定のタスクを実行する自己完結型ユニット(dsl.componentアノテーションで定義)です。本例では、コンポーネントがBright Dataからウェブデータを取得します。各コンポーネントはDockerコンテナにパッケージ化されます。
このコンポーネントのベースイメージはPython 3.10環境です。さらに、Bright DataのAPIエンドポイントへのHTTPリクエスト送信に使用されるため、requestsライブラリが含まれています。デプロイ時にコンポーネントがビルドされると、Python 3.10イメージがプルされ、requestsが自動的にインストールされます。
Bright DataのウェブスクレイピングAPIは同期/非同期両方のデータ配信をサポートします。同期方式は迅速なデータ取得に最適ですが、非同期方式は大規模データセットに適しています。本番環境向けパイプラインでは、一般的に非同期方式の利用が推奨されます。
非同期方式では、データリクエスト後、即座にデータが利用可能とは限りません。代わりにBright Dataがリクエストされたデータのスナップショットを生成しますが、これには数秒以上かかる場合があります。そのため、スナップショットが利用可能になるまで繰り返し確認するポーリング機構が必要です。
この仕組みを踏まえ、Webデータコンポーネントの動作を段階的に説明します:
- データリクエストの送信:コンポーネントはBright DataにAPI呼び出しを送信し、要求したデータの生成を開始します。
- スナップショットエンドポイントのポーリング:コンポーネントはスナップショットエンドポイントを繰り返し呼び出し、ステータスを確認します。レスポンスに「running」
ステータスフィールドが含まれている場合、スナップショットはまだ準備中です。ステータスフィールドが存在しない場合、スナップショットが準備完了し、スクレイピングされたデータを含んでいることを意味します。 - データの取得:スナップショットの準備が整うと、コンポーネントはAPIレスポンスからデータを抽出し、パイプライン内の下流コンポーネントが利用できるようにします。
素晴らしい!ウェブデータ収集用のKubeflowパイプラインコンポーネントが完成しました。
ステップ #4: センチメント分析コンポーネントの構築
TikTokからスクレイピングしたデータは、以下の構造を持つJSON配列として取得されます: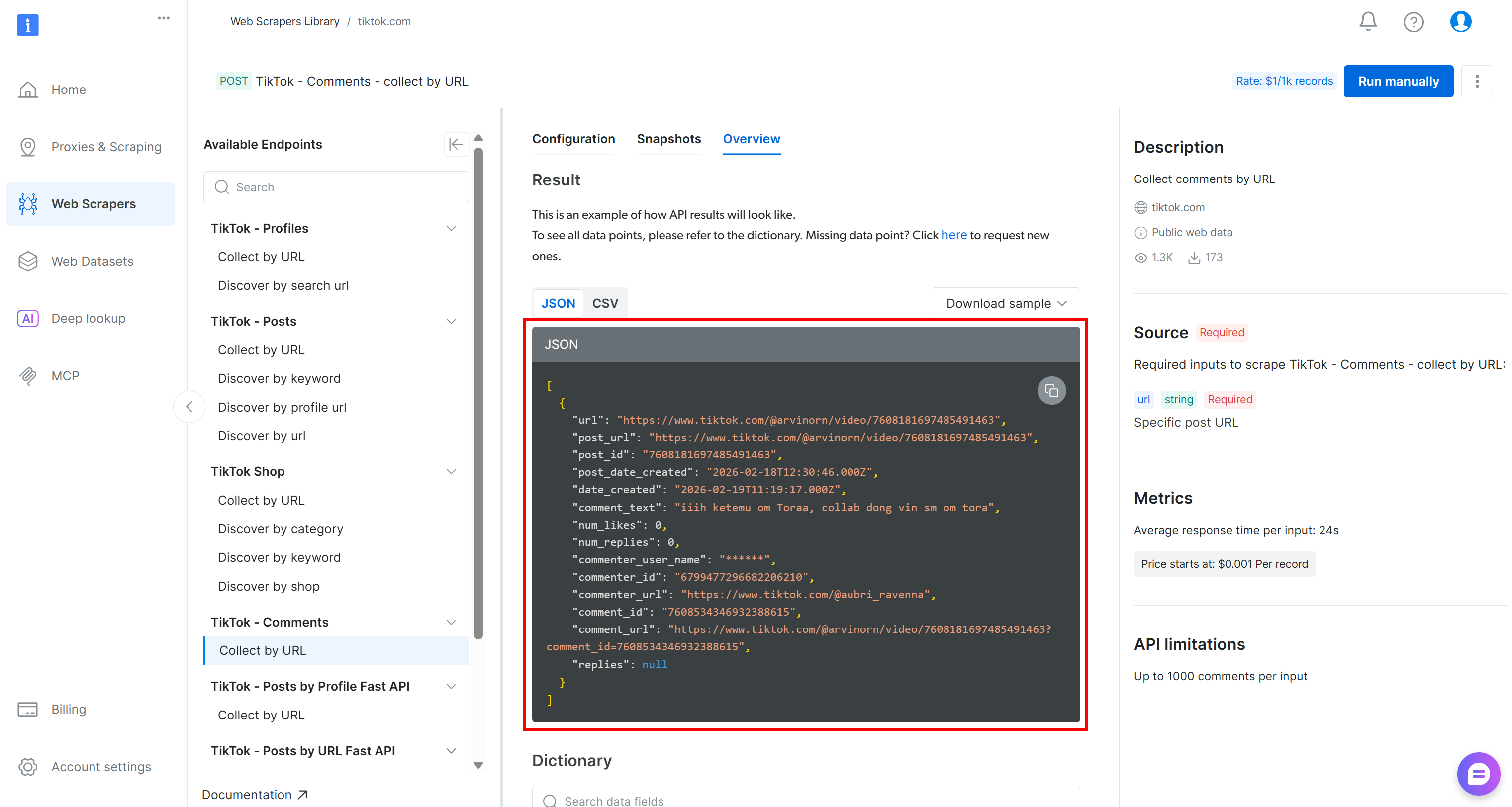
このデータに対して感情分析を行うには、comment_textフィールドを VADER Sentiment Analysisなどの感情分析ツールに渡します。VADERはソーシャルメディアで表現される感情を捕捉するために設計された、語彙とルールベースのツールです。もちろん、AIベースのモデルを含む他の感情分析手法も使用可能です。
VADERは自然言語処理で最も普及しているPythonツールキットの一つであるNLTKに含まれています。典型的なワークフローは以下の通りです:
- 前のコンポーネントから入力JSON配列(スクレイピングしたTikTokコメント)を読み込みます。
pandasを使用してデータのフィルタリングと選択を簡素化する。- テキストデータを
nltk経由でVADER感情分析ツールに渡す。 - 分析結果を保存し、下流コンポーネントで使用できるようにする。
これらを統合すると、感情分析コンポーネントは以下のように実装できます:
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# VADER感情語彙(NLTKの感情スコアリングで使用)をダウンロード
nltk.download("vader_lexicon")
# TikTokコメントを含む入力データセットを読み込み
df = pd.read_json(input_dataset.path)
# 感情分析器を初期化
sia = SentimentIntensityAnalyzer()
# 各コメントに感情分析を適用し、ポジティブ、ネガティブ、ニュートラルに分類
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negative" if sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# 下流コンポーネント用に結果を出力データセットに保存
df.to_json(sentiment_output.path, orient="records")素晴らしい!パイプラインの主要な2つのコンポーネント(ウェブデータ収集と感情分析)が完全に実装されました。
ステップ #5: Kubeflow パイプラインの最終化
2つのコンポーネントが準備できたので、dsl.pipelineでアノテーションされた関数を使用して、単一のKubeflowパイプラインに組み立てることができます:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# コメントをスクレイピングするTikTok投稿URLのリスト
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Bright Dataのウェブスクレイピングコンポーネントを使用してTikTokコメントを収集
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# 収集したコメントに対して感情分析を実行
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)このパイプラインはまず、同じプロフィール(@nike)の2つの対象動画に対してTikTokコメント収集コンポーネントを実行します。具体的には、2つのソースTikTok動画が選ばれた理由は、新製品のシューズを紹介しているからです。これらの動画に対して感情分析を行うことは、ローンチに対する視聴者の反応を理解する上でビジネス上重要です。
Bright DataウェブスクレイピングAPIで生成されたデータセットは、下流の感情分析コンポーネントに渡されます。感情分析ステップでは、ウェブスクレイピングされたコメントを処理し、感情ラベル(ポジティブ、ネガティブ、ニュートラル)を含む新しいデータセットを生成します。この出力は、レポート作成や可視化などの追加の下流コンポーネントで使用できます。
素晴らしい!これでKubeflowパイプラインの定義が完了しました。
ステップ #6: パイプラインのコンパイル
最終ステップとして、パイプラインをKubeflow YAMLパイプラインファイルにコンパイルします:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)tiktok_sentiment_analysis_kfp_pipeline.pyスクリプトを実行すると、このコードはtiktok_sentiment_analysis_kfp_pipeline.yamlという名前のファイルを生成します。このYAMLファイルには、Kubeflowデプロイに必要な完全なパイプライン仕様が含まれています。ミッション完了!
ステップ #7: 最終コード
以下は、tiktok_sentiment_analysis_kfp_pipeline.pyファイルに記述すべき完全な Kubeflow パイプラインです:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"]
)
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data APIキーに置き換えてください
# Bright DataウェブスクレイピングAPI「TikTok – コメント → URLで収集」のID
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Bright Dataへの全リクエストに共通するHTTPヘッダー
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# 入力されたTikTok投稿に対してBright DataウェブスクレイピングAPIを実行
trigger = requests.post(
f"https://api.brightdata.com/データセット/v3/trigger?データセット_ID={TIKTOK_データセット_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# データスナップショットIDを取得
snapshot_id = trigger.json()["snapshot_id"]
# 対象データを含むスナップショットが生成されたか確認するため、スナップショットエンドポイントをポーリング
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/データセット/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# JSONレスポンスデータにアクセス
response_data = progress.json()
# レスポンスにステータスが含まれていない場合、スクレイピングされたデータが含まれていることを意味する
if isinstance(response_data, dict) and "status" in response_data:
# 現在のスナップショットステータスを抽出
status = progress.json()["status"]
# 次のチェックまで5秒待機
time.sleep(5)
else:
scraped_data = response_data
break
# スクレイピングしたデータセットを保存
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"]
)
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# VADER感情語彙をダウンロード(NLTKの感情スコアリングで使用)
nltk.download("vader_lexicon")
# TikTokコメントを含む入力データセットを読み込み
df = pd.read_json(input_dataset.path)
# 感情分析器を初期化
sia = SentimentIntensityAnalyzer()
# 各コメントに感情分析を適用し、ポジティブ、ネガティブ、ニュートラルに分類
df["sentiment"] = df["comment_text"].apply(lambda t: (
"positive" if sia.polarity_scores(str(t))["compound"] >= 0.05 else
"negative" if sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# 下流コンポーネント用に結果を出力データセットに保存
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# コメントをスクレイピングするTikTok投稿URLのリスト
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Bright Dataのウェブスクレイピングコンポーネントを使用してTikTokコメントを収集
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# 収集したコメントに対して感情分析を実行
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)上記スクリプトを以下で実行:
python3 tiktok_sentiment_analysis_kfp_pipeline.pyコマンド実行後、以下のようにtiktok_sentiment_analysis_kfp_pipeline.yamlというファイルが生成されます: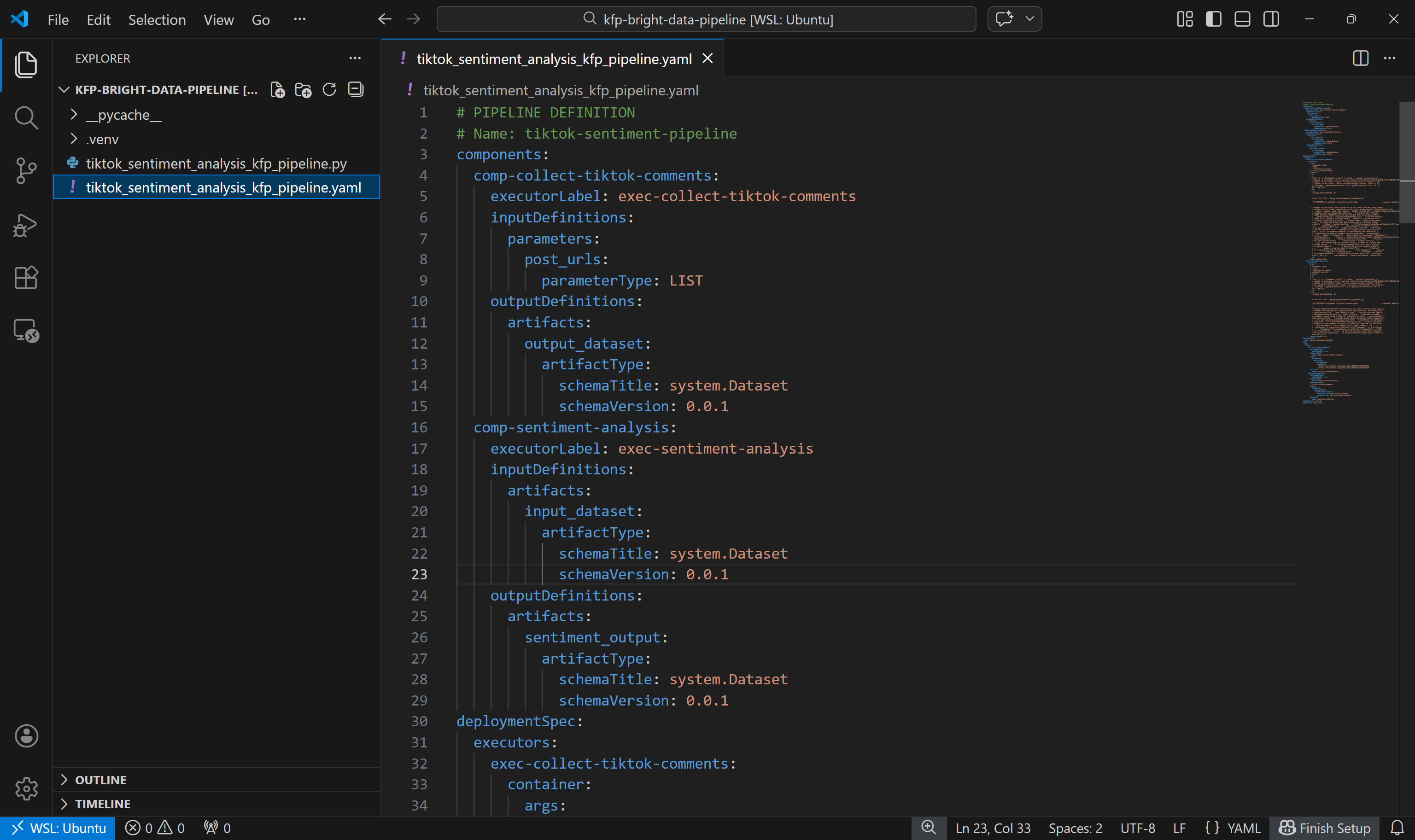
これで、テスト用にKubeflowにデプロイするか、Dockerを使用してローカルで実行できます。このガイドでは、後者の方法に焦点を当てます。
ステップ #8: Kubeflow パイプラインのローカルテスト
Kubeflowパイプラインをローカルで実行するには、DockerRunnerクラスを使用します。これには、お使いのマシンにDockerがインストールされ、実行されている必要があります。
DockerRunnerは各パイプラインタスクを個別のDockerコンテナ内で実行します。つまり、実際のKubeflow環境でのパイプライン実行をシミュレートします。
仮想環境をアクティブにした状態で、必要なdockerライブラリをインストールします:
pip install docker 次に、プロジェクトフォルダにrun_pipeline_local.pyファイルを追加します:
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yaml以下のように記述します:
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# ローカル Docker ランナーを初期化
local.init(runner=local.DockerRunner())
# Python関数呼び出しとしてパイプラインを実行
pipeline_task = tiktok_sentiment_pipeline()このスクリプトは、tiktok_sentiment_analysis_kfp_pipeline.pyからtiktok_sentiment_pipeline()関数をインポートし、ローカル Docker ランナーを通じて実行します。各コンポーネントは独自のコンテナ内で実行されます。
パイプラインをテストするには、Dockerが実行されていることを確認してください。その後、以下を実行します:
python3 run_pipeline_local.py実行ログには、以下のような成功メッセージが表示されるはずです:
パイプラインの出力は./local_outputsフォルダに保存されます。結果を確認しましょう!
ステップ #9: パイプライン結果の探索
パイプライン実行後、./local_outputsフォルダを開きます。内部には、生成された全成果物を含む現在の実行用サブフォルダが存在します。
まず、collect-tiktok-commentsコンポーネントが生成した出力データセットを確認しましょう: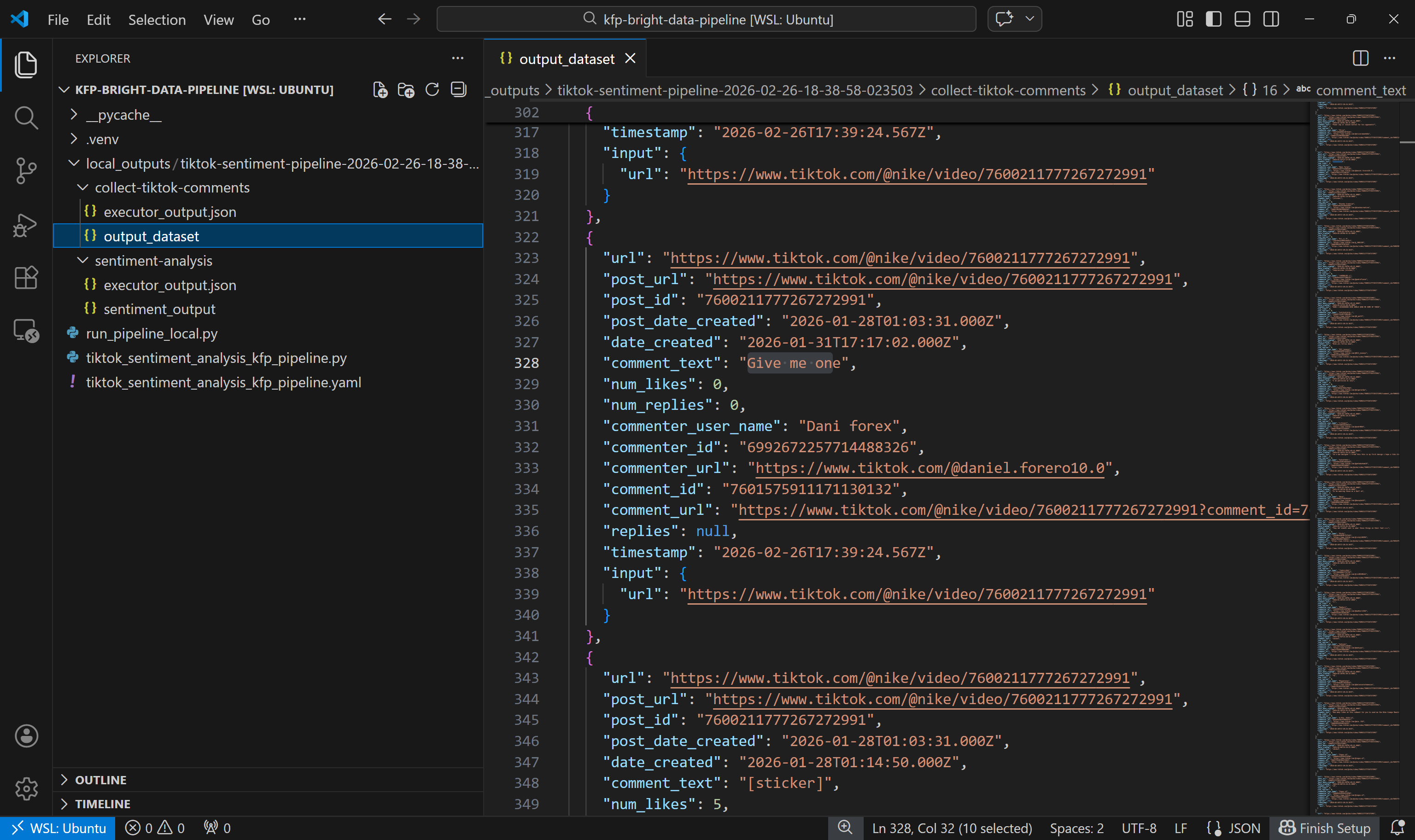
このデータセットには、指定した2つの投稿について、Bright Data経由のTikTokスクレイパーが返したコメントが期待通り含まれています。
次に、感情分析出力データセットを確認します: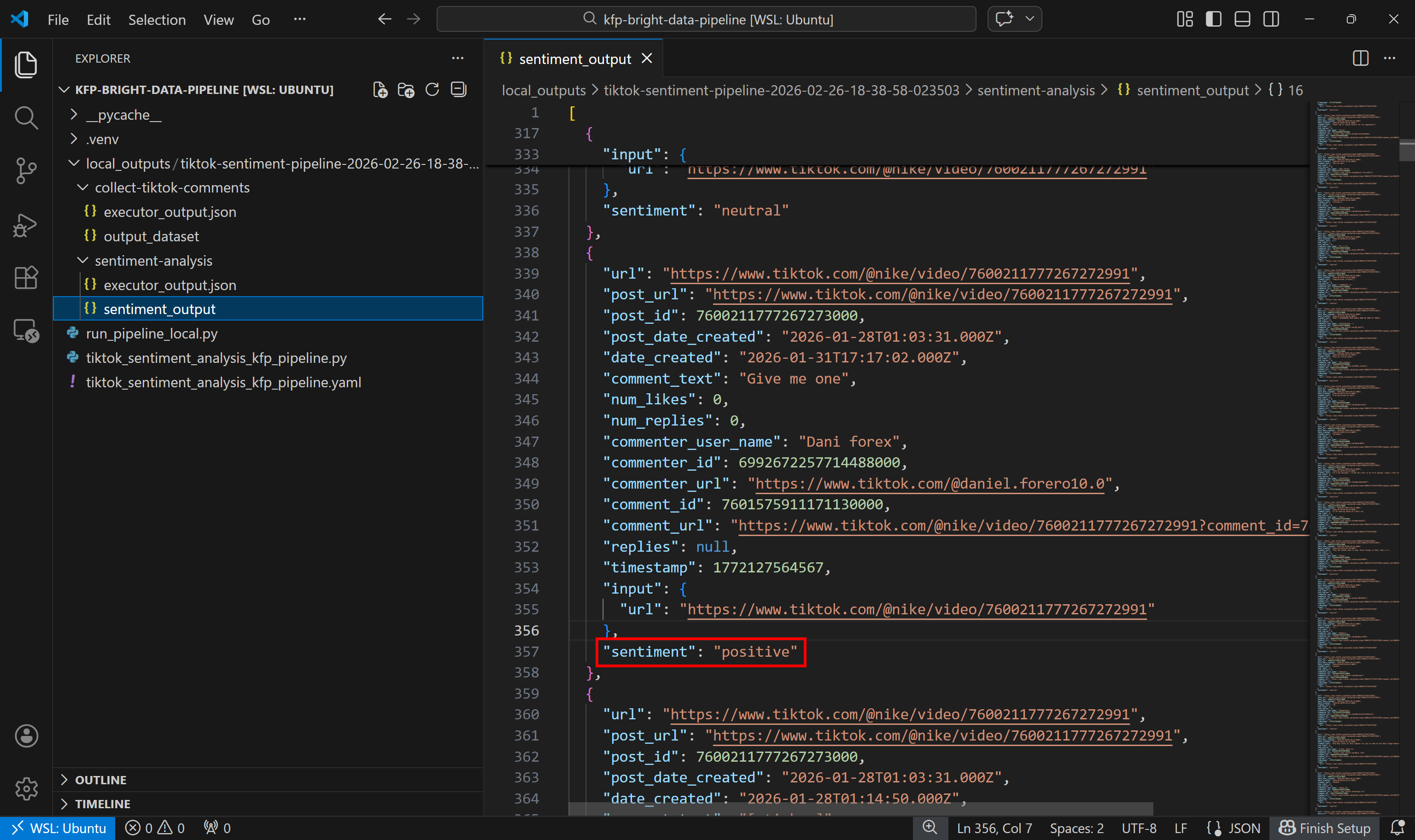
各コメントが感情分析コンポーネントによって肯定的、否定的、中立のいずれかに分類されている点に注目してください。
これで完了です!Bright Dataを使用して最新のウェブデータを取得し、分析するKubeflowパイプラインの構築方法をご覧いただきました。
結論
このチュートリアルでは、ウェブスクレイピングで取得した最新データがKubeflowパイプラインに有益である理由を理解しました。特に、ウェブから最新かつ文脈に沿った構造化データを収集するための専用コンポーネントをパイプラインに組み込む重要性を確認しました。
Bright Dataは、パイプライン向けの構造化データフィードとして機能する多様なウェブスクレイピングAPIを通じてこれを実現します。実演の通り、Bright DataのウェブスクレイピングAPIを活用すれば、Kubeflowパイプライン内にWebデータ収集コンポーネントを構築するのは非常に簡単です!
今すぐ無料のBright Dataアカウントを作成し、当社のウェブデータソリューションを探索しましょう!





