
グローバル金融機関は、ウェブからのライブ市場データと機密性の高い社内分析データを統合する必要があります。データはオンプレミスデータウェアハウス(機密性の高い顧客データ用)とAzure Data Lake(スケーラブルな分析用)に分割されています。本ガイドでは、Bright DataのAPIを介して両者を接続し、安全かつほぼリアルタイムの統合を実現する方法を解説します。
学習内容:
- – 金融機関がハイブリッドデータ構成を必要とする理由
- Bright Dataによるコンプライアンス準拠のウェブデータ収集方法
- Azure Data Lakeとオンプレミス・ウェアハウス間の安全な双方向同期設定方法
- エンドツーエンドのデータ同期を検証する方法
- 機密データを移動せずに統合分析を実行する方法
- GitHubでサンプル構成とスクリプトを入手できる場所
ハイブリッドデータ統合とは何か、そして金融業界がそれを必要とする理由
金融機関は、GDPR、SOC 2、MiFID II、バーゼルIIIなどの厳格な規制のもとで運営されており、データの保管場所が制限されています。公開ウェブデータはリアルタイムの市場インテリジェンスを促進し、既存の社内データセットは長期的なモデリングとコンプライアンスをサポートします。従来のETLシステムでは、これら両方を安全に統合することはほとんどありません。
課題:セキュリティやコンプライアンスを損なうことなく、外部市場データと内部分析をどう統合するか?
解決策:Bright DataはAPI経由で構造化されコンプライアンス対応のウェブデータを提供し、Azureのハイブリッドインフラは機密データをオンプレミスに保持します。
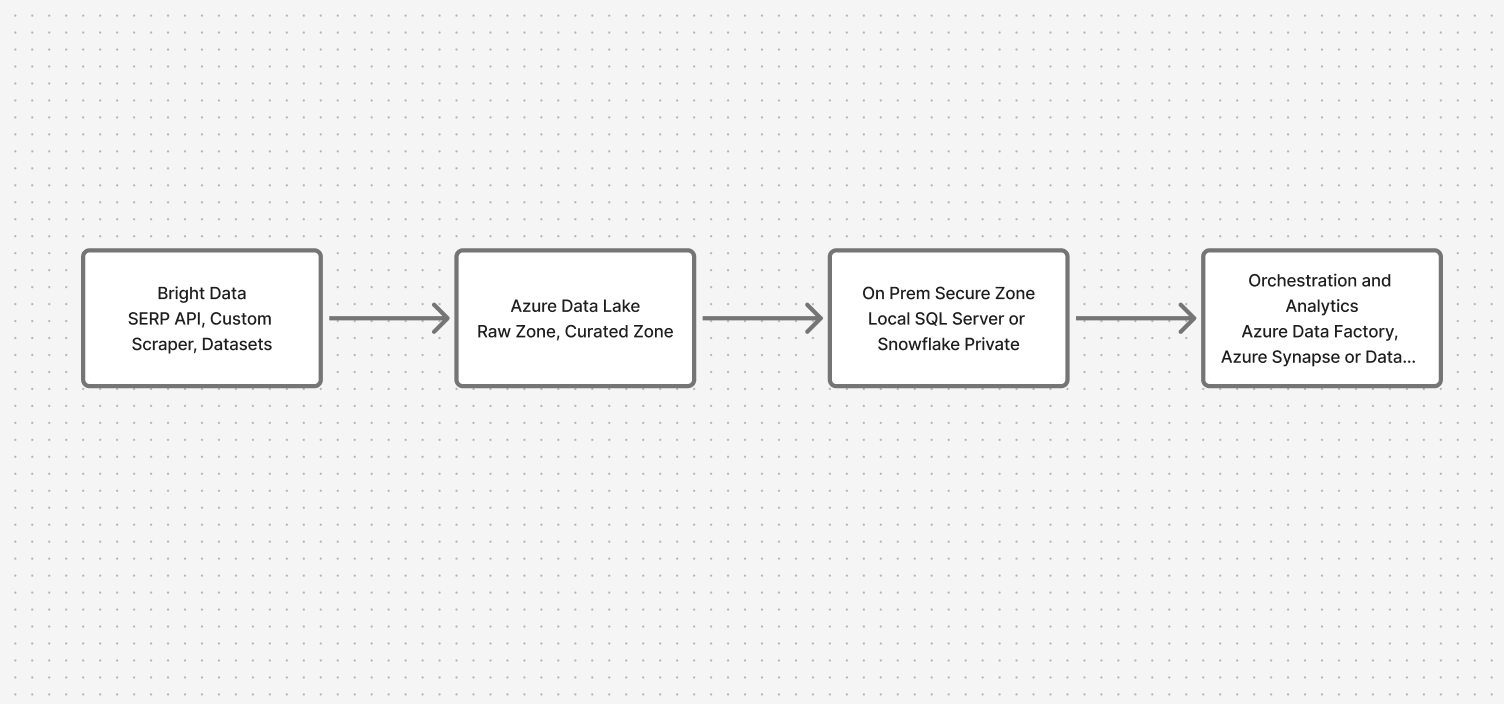
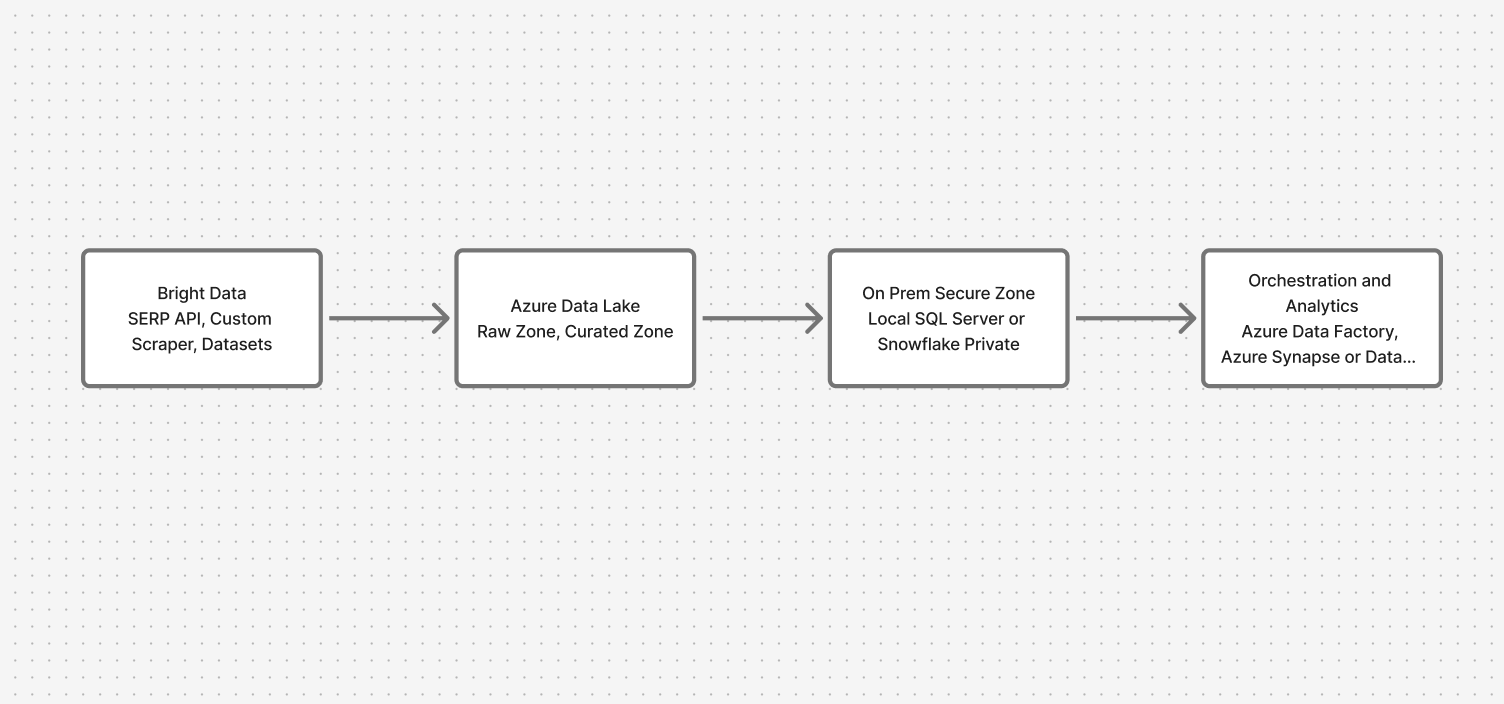
アーキテクチャ概要:クラウドとオンプレミスを安全に橋渡し
システムは4つの主要レイヤーを経由します:
- データ収集:Bright Data API(SERP、カスタムスクレイパー、データセット)
- クラウドランディングゾーン:Azure Data Lake(生データゾーンとキュレーション済みデータゾーン)
- オンプレミス セキュアゾーン:ローカル SQL Server または Snowflake
- オーケストレーション&分析:プライベートエンドポイント付きAzure Data Factory、フェデレーテッドクエリ用Synapse/Databricks
これにより、ウェブデータは流入しつつ、機密データは元の場所に留まります。
前提条件
開始前に:
- APIアクセス権限付きの有効なBright Dataアカウント
- Azureサブスクリプション(Data Lake、Data Factory、SynapseまたはDatabricksを含む)
- プライベートネットワーク経由でアクセス可能なオンプレミスデータベース(ODBCまたはJDBC)
- セキュアなプライベートリンク(ExpressRoute、サイト間VPN、またはプライベートエンドポイント)
- サンプルリポジトリをクローンするための GitHub アカウント
💡 ヒント: すべてのステップは、まず本番環境以外のワークスペースで実行してください。
ステップバイステップの実装
1. Bright Dataで金融ウェブデータを収集
Bright Dataのカスタムスクレイパーを設定し、株価、規制当局への提出書類、金融ニュースを抽出します。スクレイパーは分析可能な構造化JSONを出力します。
データの例:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
設定をシンプルに:scraper_config.yamlはスクレイピング対象と頻度を定義します。金融サイトをターゲットとし、特定のデータポイントを抽出し、1時間ごとの収集とWebhook通知をスケジュールします。
このアプローチにより、手動介入なしでクリーンで構造化されたデータを確実に取得できます。
# scraper_config.yaml
name: financial_data_aggregator
description: >
リアルタイム株価、SEC提出書類、金融ニュースの見出しを収集し、
ハイブリッドクラウド統合に活用します。
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- name: price
type: text
selector: "fin-streamer[data-field='regularMarketPrice']"
- name: headline
type: text
selector: "article h3 a"
- name: filing_type
type: text
selector: "td[class*='filetype']"
- name: filing_date
type: text
selector: "td[class*='filedate']"
- name: filing_url
type: link
selector: "td[class*='filedesc'] a"
pagination:
type: next-link
selector: "a[aria-label='Next']"
output:
format: json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. Azure Data Lakeへの安全なデータ取り込み
収集したデータをAzure Functionを使用してAzure Data Lakeにルーティングします。この関数は安全なゲートウェイとして機能します:
- Bright DataからHTTPS POST経由でJSONデータを受信
- マネージドIDによる認証(シークレット管理不要)
- ソースとタイムスタンプでファイルを整理し追跡を容易化
- コンプライアンス追跡用のメタデータタグを追加
結果:市場データはパーティション化されたフォルダーに格納され、管理とクエリが容易になります。
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# 環境変数
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # 例: "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# マネージド ID で Blob クライアントを初期化
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Bright Dataからの受信JSONをパース
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# 保存先パスを準備
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# JSONファイルをアップロード
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"{source}からのデータが{blob_path}に保存されました",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""ソース名を識別する簡易ヘルパー"""
# 配列の最初の要素で'source'フィールドを検索
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. 非機密サブセットのオンプレミス同期
すべてのデータを環境間で移動させる必要はありません。Azure Data Factoryをスマートフィルターとして活用し、オンプレミスウェアハウスとの同期が安全なデータサブセットのみを慎重に選択します。
実際のプロセスは以下の通りです:
パイプラインは、データレイクに新規に追加されたファイルをスキャンすることから始まります。次に、公開済みで機密性のないデータ(顧客情報や独自の分析データではなく、市場価格や銘柄コードなど)のみを含むよう、インテリジェントなフィルタリングを適用します。
セキュリティと信頼性を確保する仕組み:
プライベートエンドポイントにより、Azureとオンプレミスインフラ間の専用トンネルが構築され、パブリックインターネットを完全に迂回します。これにより外部脅威への曝露を排除しつつ、一貫したパフォーマンスを確保します。
増分ロードとウォーターマーク追跡により、システムは新規または変更されたレコードのみを移動します。自動スキーマ検証と組み合わせることで、重複を防止しつつ両環境を完全に同期させます。
では、これを実際のパイプラインコードにどう反映させるか見てみましょう:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_データセット",
"type": "データセットReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataSet": {
"referenceName": "ADLS_NewFiles_DataSet",
"type": "DataSetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
"preCopyScript": "IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));"
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}主要コンポーネントの解説:
- Lookup_NewFiles はパイプラインのチェック機能として動作し、まずデータレイクに処理が必要な新規データが到着したかどうかを識別します。これにより、古いファイルを不必要に再処理するのを防ぎます。
- Get_Metadataは次にこれらのファイルを詳細に検査し、サイズ、変更日時、構造を確認します。このステップにより、完全かつ有効なファイルのみを処理対象として確実にします。
- Filter_PublicDataではセキュリティ処理が行われます。事前に埋め込んだ分類メタデータを使用し、機密データを自動的に除外。公開市場情報のみがパイプラインを継続して通過します。
- Copy_To_OnPrem_SQLは実際の転送を担当しますが、スマートな安全対策を備えています。preCopyScriptは宛先テーブルが正しいスキーマで存在することを保証し、プライベートエンドポイント接続によりすべてをセキュアなネットワーク内に保持します。
- Log_Load_Statusは、各同期操作がオンプレミスデータベースに記録される重要な可視性を提供します。これによりコンプライアンスチームが求める監査証跡が作成されると同時に、運用担当者はパイプラインの健全性を即座に把握できます。
真のメリット:オンプレミスチームは必要な市場コンテキストとリアルタイムインテリジェンスを獲得しつつ、機密性の高い顧客データや独自モデルは本来あるべき場所に安全に保管されます。俊敏性とセキュリティの両立という理想的な状態を実現します。
4. 双方向同期検証の実現
信頼性の高いビジネス判断にはデータ整合性が不可欠です。クラウド分析とオンプレミスレポートが同一の数値を示す確信が必要です。この保証を提供するため、継続的に実行される自動データ検証チェックを構築しました。
検証プロセスの仕組みは以下の通りです:
- 行数比較が最初のアラートシステムとして機能します。この初期チェックにより、転送失敗やデータロード不完全といった重大な問題を迅速に特定します。クラウドとオンプレミスでカウントが一致しない場合、直ちに調査が必要な事象が発生したと判断できます。
- ハッシュチェックサムはデータのデジタル指紋を作成します。数千件のレコードを手動で比較する代わりに、各データセットに固有の暗号ハッシュを生成します。たった1文字の変更でも完全に異なるハッシュが生成されるため、データの破損や部分的な転送を即座に検出できます。
- ほぼリアルタイムの同期により、検証は数分ごとに実行されます。問題発見のために夜間バッチジョブを待つ必要はありません。システムは数日ではなく数分以内に問題を捕捉し、データの最新性と信頼性を維持します。
- 自動アラート機能により、データ問題は即時対応へと転換されます。システムが不一致を検知すると、Slack、メール、または既存の監視ツールを通じて通知が送信されます。チームはビジネス判断に影響が出る前に問題に対処できます。
実際の動作例は以下の通りです:
def validate_sync():
# システム間のレコード数を比較
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"レコード数不一致: クラウド {cloud_count} vs オンプレミス {onprem_count}")
return False
# データ整合性検証用のチェックサム生成
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"データ整合性エラー: チェックサムが一致しません")
return False
# 同期タイミングの確認
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"同期遅延を検出: 最終同期時刻 {last_sync_time}")
return False
return True5. 機密データを移動せずに統合分析を構築
強力な点はここです:機密情報を移動することなく、クラウドとオンプレミスのデータを仮想的に結合できます。
例となるクエリ:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapseはオンプレミスウェアハウスを指す外部テーブルを作成し、Databricksはロールベースのアクセス制御を備えたJDBC接続を使用します。
コンプライアンスと監査証跡のベストプラクティス
監査および法的要件を満たすには、データ追跡とセキュリティに対する体系的なアプローチが必要です。コンプライアンス対応フレームワークの構築方法は以下の通りです:
- 完全なデータ移動ログにより、すべての転送が Azure Monitor およびオンプレミス SIEM に記録されます。これにより、どのデータがいつどこに移動したかの不変の記録が作成され、監査担当者に完全なトレーサビリティを提供します。
- 明確なデータプロビネンスでは、Bright DataソースIDをデジタル指紋として使用します。これらのタグはデータのライフサイクル全体に付随し、あらゆる分析を元のソース収集まで遡って追跡可能にします。
- Azure Purviewによる自動化されたデータ系譜追跡は、データがパイプライン内でどのように変換されるかをマッピングします。特定のレポートにどの生データフィードが貢献し、どのような変換が適用されたかを自動的に文書化します。
- 集中型アクセス制御はAzure ADとオンプレミスLDAPを同期します。これにより既存のセキュリティポリシーが両環境に適用され、クラウドとオンプレミスシステム全体で一貫した権限管理が実現します。
その結果、コンプライアンス報告の自動化、セキュリティ管理の一元化、そしてチームの作業速度を低下させることなくデータを保護するフレームワークが実現します。
一般的な課題とBright Dataの解決策
| 課題 | Bright Dataの機能 |
|---|---|
| IPブロックまたはレート制限 | レジデンシャルプロキシおよびISPプロキシ(1億5000万以上のIPアドレス) |
| CAPTCHAやログイン障壁 | 自動解決用Web Unlockerツール |
| 重度のJavaScriptサイト | スクレイピングブラウザ(Playwrightベースのレンダリング) |
| 頻繁なサイト変更 | AI自動修正機能付きマネージドデータサービス |
結論と今後の手順
金融機関は、Bright DataのAPIとAzureのハイブリッドインフラストラクチャを組み合わせて、公開データと非公開データを安全に統合できます。
その結果、俊敏性と制御性の両方を実現するコンプライアンス対応システムが構築されます。
💡 完全に管理されたデータアクセスをご希望の場合は、Bright Dataのマネージドデータサービスをご利用ください。スクレイピングから配信までをエンドツーエンドで処理します。






