
このチュートリアルでは、以下の内容を扱います:
- Bright DataのSERP APIを使用したNaver検索結果のスクレイピング方法
- Bright Dataプロキシを使用したカスタムNaverスクレイパーの構築
- Bright DataスクレイパーStudio(AIスクレイパー)を用いたノーコードワークフローによるNaverスクレイピング
それでは始めましょう!
なぜNaverをスクレイピングするのか?
Naverは韓国を代表するプラットフォームであり、検索、ニュース、ショッピング、ユーザー生成コンテンツの主要な情報源です。グローバル検索エンジンとは異なり、Naverは独自のサービスを検索結果に直接表示するため、韓国市場をターゲットとする企業にとって重要なデータソースとなります。
Naverのスクレイピングにより、公開APIでは利用できない構造化データや非構造化データにアクセス可能となり、大規模な手動収集が困難なデータを取得できます。
収集可能なデータ
- 検索結果(SERPs):順位、タイトル、スニペット、URL
- ニュース:配信元、見出し、タイムスタンプ
- ショッピング:商品リスト、価格、販売者、レビュー
- ブログとカフェ:ユーザー生成コンテンツとトレンド
主なユースケース
- 韓国市場向けSEOおよびキーワード追跡
- ニュースやユーザーコンテンツにおけるブランドと評判のモニタリング
- Naverショッピングを利用したEコマースと価格分析
- ブログやフォーラムからの市場調査・トレンド調査
この背景を踏まえ、最初のアプローチとして、Bright DataのSERP APIを使用してNaver検索結果をスクレイピングする方法を見ていきましょう。
Bright DataのSERP APIによるNaverスクレイピング
このアプローチは、プロキシ、CAPTCHA、ブラウザ設定を管理せずにNaver SERPデータを取得したい場合に最適です。
前提条件
このチュートリアルを実践するには以下が必要です:
- Bright Dataアカウント
- Bright DataダッシュボードでのSERP API、プロキシ、またはスクレイパー Studioへのアクセス権
- Python 3.9 以降がインストールされていること
- Pythonおよびウェブスクレイピングの基本概念に関する基礎知識
カスタムスクレイパーの例については、以下も必要です:
- ローカルにインストールおよび設定済みのPlaywright
- Playwright経由でインストールされたChromium
Bright DataでSERP APIゾーンを作成
Bright Dataでは、SERP APIには専用のゾーンが必要です。設定手順:
- Bright Dataにサインインします。
- ダッシュボードの SERP API に移動し、新しい SERP API ゾーンを作成します。
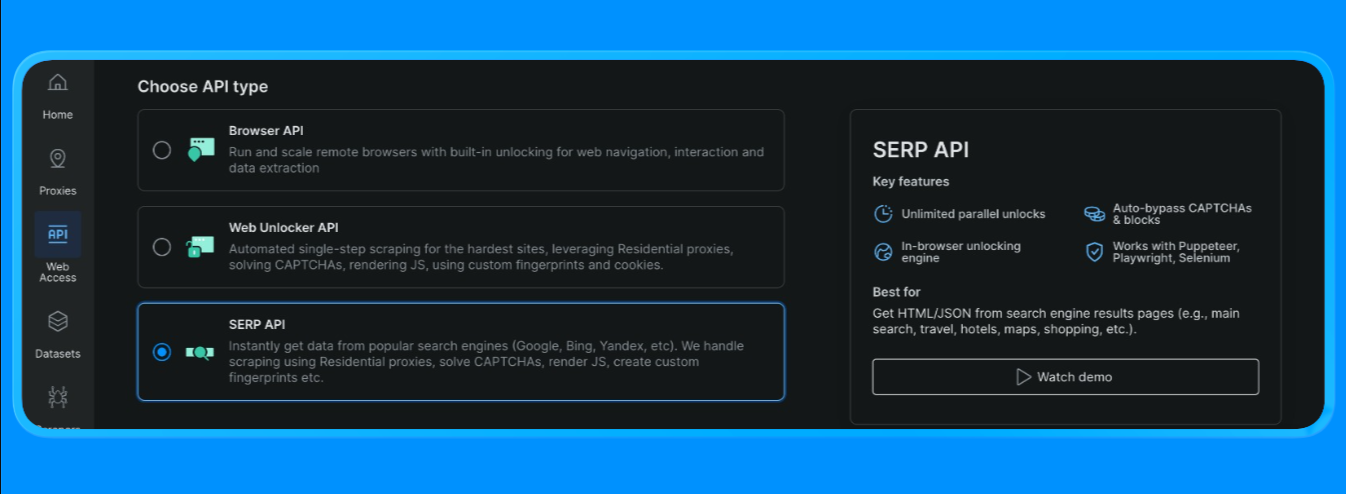
- APIキーをコピーします。
Naver検索URLを構築する
Naver SERPは標準検索URL形式でリクエスト可能です:
- 基本エンドポイント:
https://search.naver.com/search.naver - クエリパラメータ:
query=<検索キーワード>
クエリはquote_plus()でURLエンコードされるため、複数単語のキーワード(「機械学習チュートリアル」など)は正しくフォーマットされます。
SERP APIリクエストの送信(Bright Dataリクエストエンドポイント)
Bright Dataのクイックスタートフローでは単一エンドポイント(https://api.brightdata.com/request)を使用し、以下を渡します:
zone:SERP APIのゾーン名url:Bright Dataに取得させたいNaver SERPのURLformat:HTMLを返すにはrawに設定
Bright Dataは解析済み出力モード(例:brd_json=1によるJSON構造、data_formatオプションによる高速な「トップ結果」取得)もサポートしていますが、このチュートリアルセクションではHTMLパースフローを使用します
Pythonファイルを作成し、以下のコードを含めます
import asyncio
import re
from urllib.parse import quote_plus, urlparse
from bs4 import BeautifulSoup
from playwright.async_api import async_playwright, TimeoutError as PwTimeout
BRIGHTDATA_USERNAME = "your_brightdata_username"
BRIGHTDATA_PASSWORD = "your_brightdata password"
PROXY_SERVER = "your_proxy_host"
def clean_text(text: str) -> str:
return re.sub(r"s+", " ", (text or "")).strip()
def blocked_link(href: str) -> bool:
"""広告/ユーティリティリンクをブロック;ブログ検索結果が必要なため blog.naver.com は許可"""
if not href or not href.startswith(("http://", "https://")):
return True
netloc = urlparse(href).netloc.lower()
# 広告リダイレクト + 明らかな非コンテンツユーティリティをブロック
blocked_domains = [
"ader.naver.com",
"adcr.naver.com",
"help.naver.com",
"keep.naver.com",
"nid.naver.com",
"pay.naver.com",
"m.pay.naver.com",
]
if any(netloc == d or netloc.endswith("." + d) for d in blocked_domains):
return True
# ブログモードでは、以下のいずれかを選択可能:
# (A) Naverブログ/投稿ドメインのみ許可 (より「Naverらしい」動作)
allowed = ["blog.naver.com", "m.blog.naver.com", "post.naver.com"]
return not any(netloc == d or netloc.endswith("." + d) for d in allowed)
def pick_snippet(container) -> str:
"""
ヒューリスティック: タイトル付近の文のようなテキストブロックを選択
"""
best = ""
for tag in container.find_all(["div", "span", "p"], limit=60):
txt = clean_text(tag.get_text(" ", strip=True))
if 40 <= len(txt) <= 280:
# パンくずリスト風の行を回避
if "›" in txt:
continue
best = txt
break
return best
def extract_blog_results(html: str, limit: int = 10):
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
# ブログSERPレイアウトは変更されるため、複数のフォールバックを使用
selectors = [
"a.api_txt_lines", # 共通タイトルリンクラッパー
"a.link_tit",
"a.total_tit",
"a[href][target='_blank']",
]
for sel in selectors:
for a in soup.select(sel):
if a.name != "a":
continue
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 5:
continue
if blocked_link(href):
continue
if href in seen:
continue
seen.add(href)
container = a.find_parent(["li", "article", "div", "section"]) or a.parent
snippet = pick_snippet(container) if container else ""
results.append({"title": title, "link": href, "snippet": snippet})
if len(results) >= limit:
return results
return results
async def scrape_naver_blog(query: str) -> tuple[str, str]:
# Naverブログ垂直検索
url = f"https://search.naver.com/search.naver?where=blog&query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
# プロキシ対応のタイムアウト設定
page.set_default_navigation_timeout(90_000)
page.set_default_timeout(60_000)
# 重いリソースをブロックして高速化 + ハング削減
async def block_resources(route):
if route.request.resource_type in ("image", "media", "font"):
return await route.abort()
await route.continue_()
await page.route("**/*", block_resources)
# 1回リトライ(Naverは時々不安定な場合がある)
for attempt in (1, 2):
try:
await page.goto(url, wait_until="domcontentloaded", timeout=90_000)
await page.wait_for_selector("body", timeout=30_000)
html = await page.content()
await browser.close()
return url, html
except PwTimeout:
if attempt == 2:
await browser.close()
raise
await page.wait_for_timeout(1500)
if __name__ == "__main__":
query = "machine learning tutorial"
scraped_url, html = asyncio.run(scrape_naver_blog(query))
print("Scraped from:", scraped_url)
print("HTML length:", len(html))
print(html[:200])
results = extract_blog_results(html, limit=10)
print("n抽出されたNaverブログ結果:")
for i, r in enumerate(results, 1):
print(f"n{i}. {r['title']}n {r['link']}n {r['snippet']}")fetch_naver_html()関数を使用し、Naver検索URLをBright Dataのリクエストエンドポイントに送信して完全レンダリングされたSERPページを取得しました。Bright DataがIPローテーションとアクセスを自動処理したため、ブロックやレート制限に遭遇することなくリクエストが成功しました。
次に、BeautifulSoupを使用してHTMLをパースし、広告やNaver内部モジュールを除去するカスタムフィルタリングロジックを適用しました。extract_web_results()関数は、ページ内の有効な検索結果タイトル、リンク、および隣接するテキストブロックをスキャンし、重複を除去してクリーンな検索結果リストを返します。
スクリプトを実行すると、以下のような出力が得られます: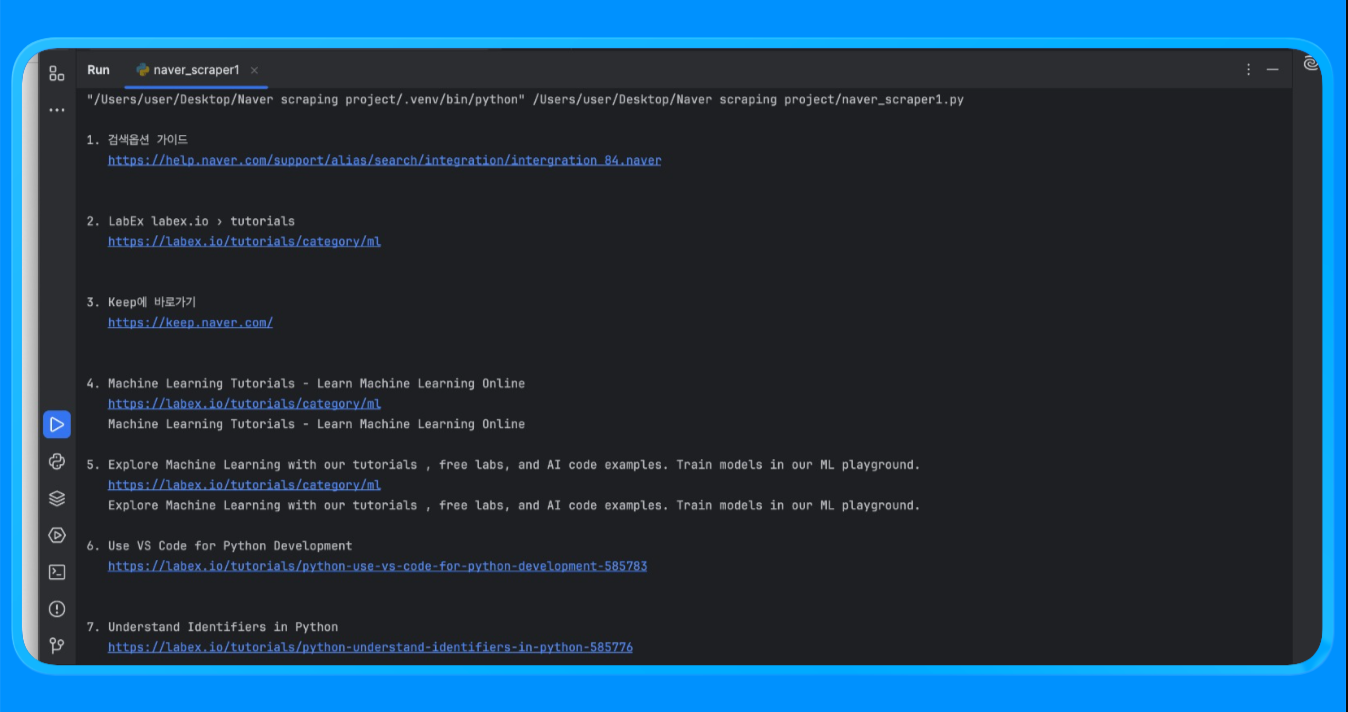
この手法により、カスタムスクレイパーの構築や維持管理なしに構造化されたNaver検索結果を収集できます。
主な活用例
- Naverにおけるキーワード順位と可視性の追跡
- 韓国市場向けSEOパフォーマンス監視
- ニュース・ショッピング・ブログ掲載などのSERP機能分析
このアプローチは、最小限の設定で一貫した出力スキーマと高リクエスト量を必要とする場合に最適です。
SERP レベルのスクラッピングがカバーされたところで、より深いクロールと柔軟性を実現するために、Bright Data プロキシを使用したカスタム Naver スクレイパーの構築に移りましょう。
Bright Dataプロキシを使用したカスタムNaverスクレイパーの構築
このアプローチでは、Bright Dataプロキシを経由してトラフィックをルーティングしながら、実際のブラウザを使用してNaverページをレンダリングします。SERPを超えたリクエスト、JavaScriptレンダリング、ページレベルのデータ抽出を完全に制御する必要がある場合に有用です。
コードを書く前に、まずBright Dataダッシュボードでプロキシゾーンを作成し、プロキシ認証情報を取得する必要があります。
本スクリプトで使用するプロキシ認証情報を取得するには:
- Bright Dataアカウントにログイン
- ダッシュボードから「プロキシ」に移動し、「プロキシを作成」をクリック
- データセンター・プロキシを選択(本プロジェクトではこのオプションを選択。プロジェクトの規模や用途に応じて選択肢は異なります)
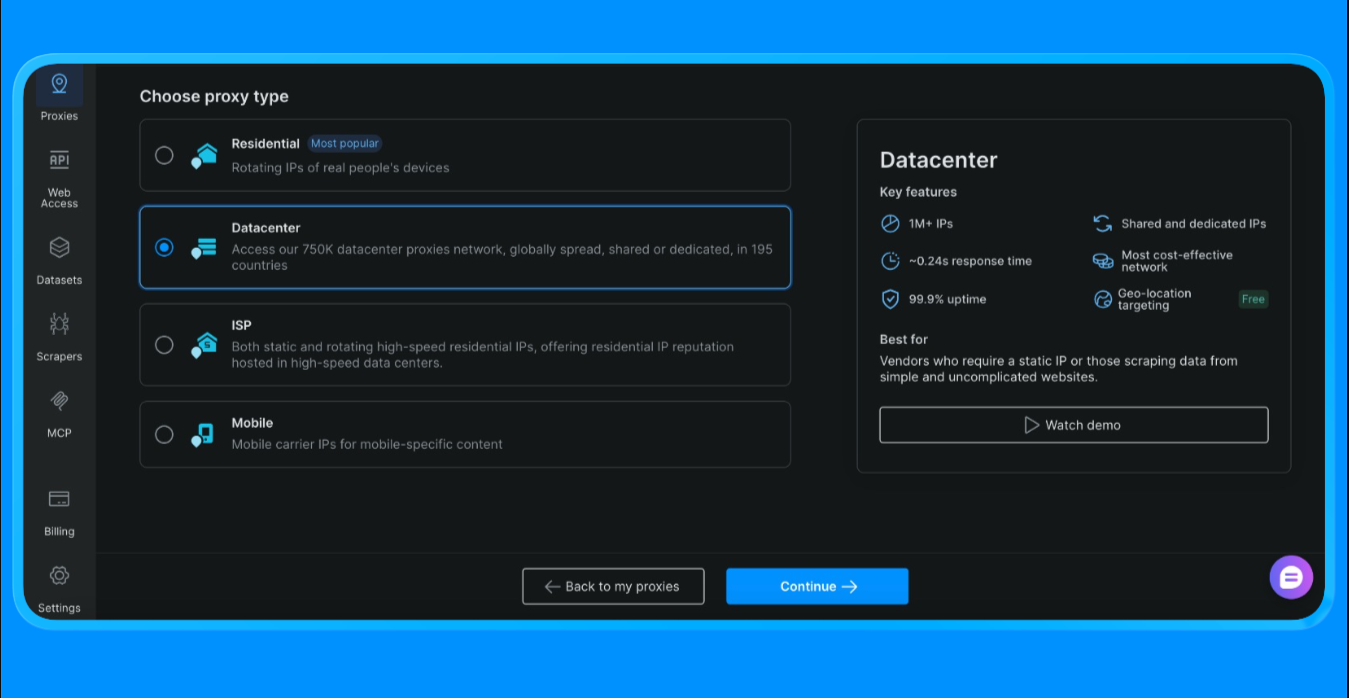
- 新しいプロキシゾーンを作成
- ゾーン設定を開き、以下の値をコピーします:
- プロキシユーザー名
- プロキシパスワード
- プロキシエンドポイントとポート
これらの値は、Bright Dataのプロキシネットワーク経由でルーティングされるリクエストを認証するために必要です。
スクリプトにBright Dataプロキシ認証情報を追加する
プロキシゾーン作成後、ダッシュボードからコピーした認証情報をスクリプトに更新してください。
BRIGHTDATA_USERNAMEには、お客様の顧客IDとプロキシゾーン名が含まれますBRIGHTDATA_PASSWORDにはプロキシゾーンのパスワードが含まれますPROXY_SERVERは Bright Data のスーパープロキシエンドポイントを指します
これらの値を設定すると、Playwrightによって開始されるすべてのブラウザトラフィックが自動的にBright Data経由でルーティングされます。
以下のコードでスクレイピングを実行できます:
import asyncio
import re
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
from playwright.async_api import async_playwright
BRIGHTDATA_USERNAME = "your_username"
BRIGHTDATA_PASSWORD = "your_password"
PROXY_SERVER = "your_proxy_host"
def clean_text(s: str) -> str:
return re.sub(r"s+", " ", (s or "")).strip()
async def run(query: str):
url = f"https://search.naver.com/search.naver?query={quote_plus(query)}"
async with async_playwright() as p:
browser = await p.chromium.launch(
headless=True,
プロキシ={
"server": PROXY_SERVER,
"username": BRIGHTDATA_USERNAME,
"password": BRIGHTDATA_PASSWORD,
},
)
page = await browser.new_page()
await page.goto(url, wait_until="networkidle")
html = await page.content()
await browser.close()
soup = BeautifulSoup(html, "html.parser")
results = []
seen = set()
for a in soup.select("a[href]"):
href = a.get("href", "")
title = clean_text(a.get_text(" ", strip=True))
if len(title) < 8:
continue
if not href.startswith(("http://", "https://")):
continue
if any(x in href for x in ["ader.naver.com", "adcr.naver.com", "help.naver.com", "keep.naver.com"]):
continue
if href in seen:
continue
seen.add(href)
results.append({"title": title, "link": href})
if len(results) >= 10:
break
for i, r in enumerate(results, 1):
print(f"{i}. {r['title']}n {r['link']}n")
if __name__ == "__main__":
asyncio.run(run("machine learning tutorial"))scrape_naver_blog()関数はNaverブログを開き、画像・メディア・フォントなどの重いアセットをブロックして読み込み時間を短縮し、タイムアウト発生時にはナビゲーションを再試行します。ページが完全に読み込まれたら、レンダリングされたHTMLを取得します。
extract_blog_results()関数は、BeautifulSoupでHTMLをパースし、広告やユーティリティページを除外しつつNaverブログドメインを許可するブログ固有のフィルタリングルールを適用し、ブログタイトル、リンク、周辺のテキストスニペットからなるクリーンなリストを抽出します。
このスクリプトを実行すると、以下の出力が得られます:
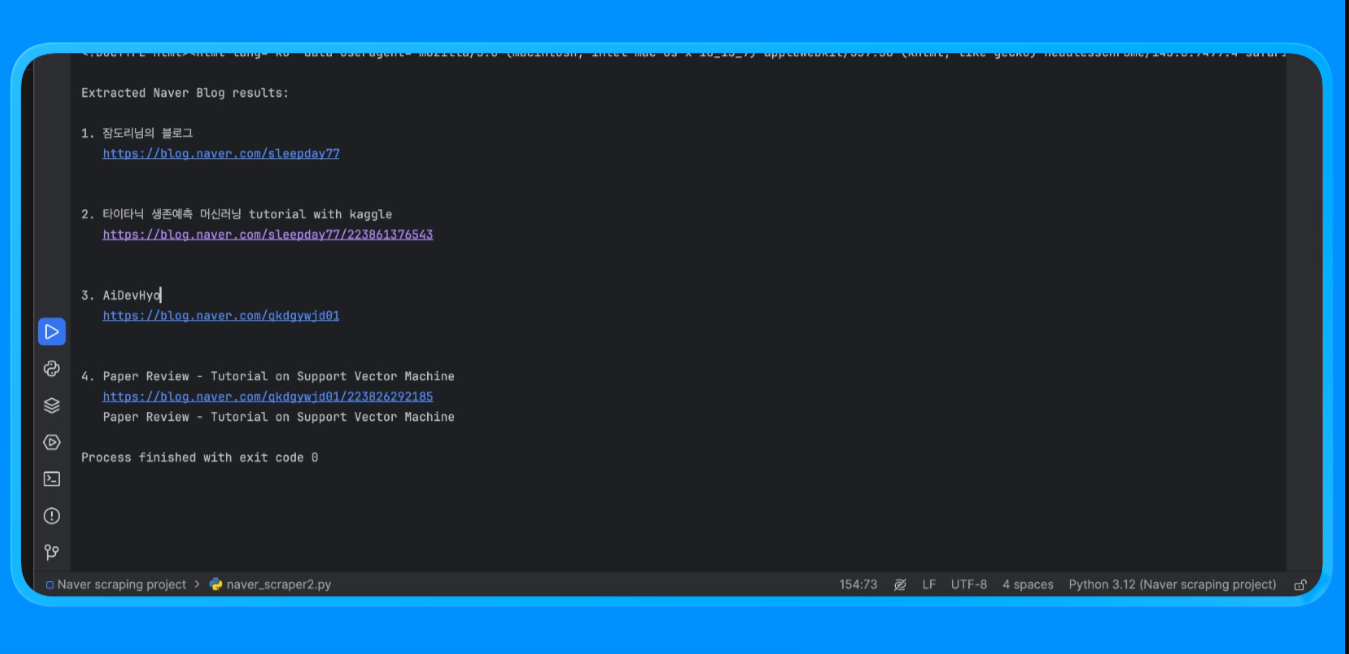
この方法は、ブラウザレンダリングとカスタムパースロジックを必要とするNaverページからコンテンツを抽出するために使用されます。
主な使用例
- Naverブログおよびカフェコンテンツのスクレイピング
- 長文記事、コメント、ユーザーコンテンツの収集
- JavaScript多用ページのデータ抽出
ページレンダリング、再試行、および細かいフィルタリングが必要な場合に最適なアプローチです。
カスタムスクレイパーをBright Dataプロキシ経由で実行する準備が整ったので、コードを書かずにデータを抽出する最速のオプションに移りましょう。次のセクションでは、同じインフラストラクチャ上に構築されたノーコードAIワークフロー「Bright Data Scraper Studio」を使用してNaverをスクレイピングします。
Bright Data Scraper Studio(ノーコードAIスクレイパー)によるNaverのスクレイピング
スクレイピングコードの記述や保守を避けたい場合、Bright Data Scraper StudioはSERP APIやプロキシネットワークと同じ基盤インフラを活用し、ノーコードでNaverデータを抽出する手段を提供します。
開始するには:
- Bright Dataアカウントにログイン
- ダッシュボードから左メニューの「スクレイパー」オプションを開き、「Scraper studio」をクリック。以下のようなダッシュボードが表示されます:
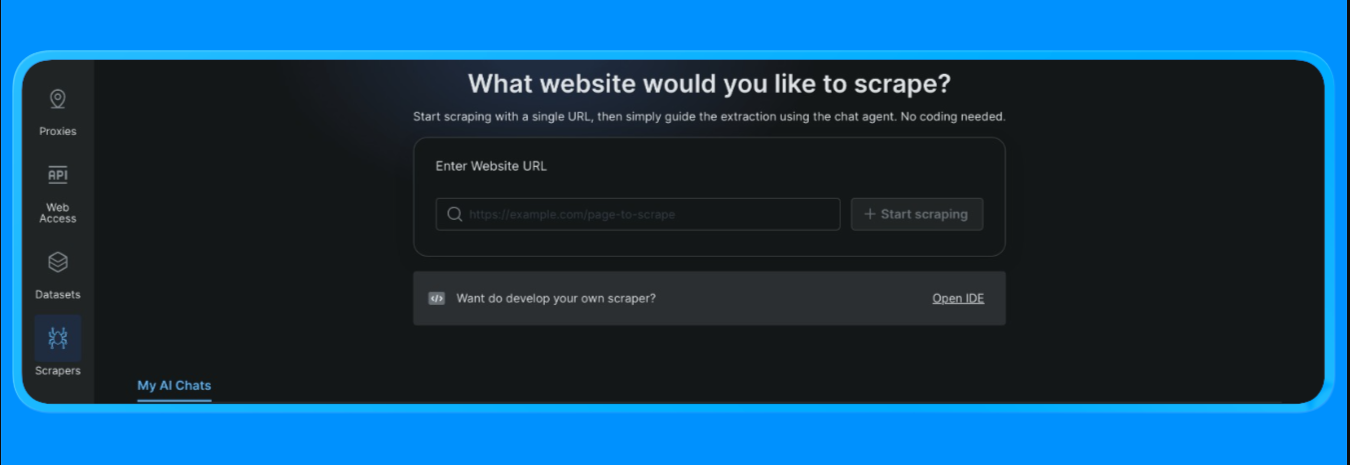
スクレイピング対象のURLを入力し、「スクレイピング開始」ボタンをクリック
スクレイパー Studioがサイトのスクレイピングを実行し、必要な情報を提供します。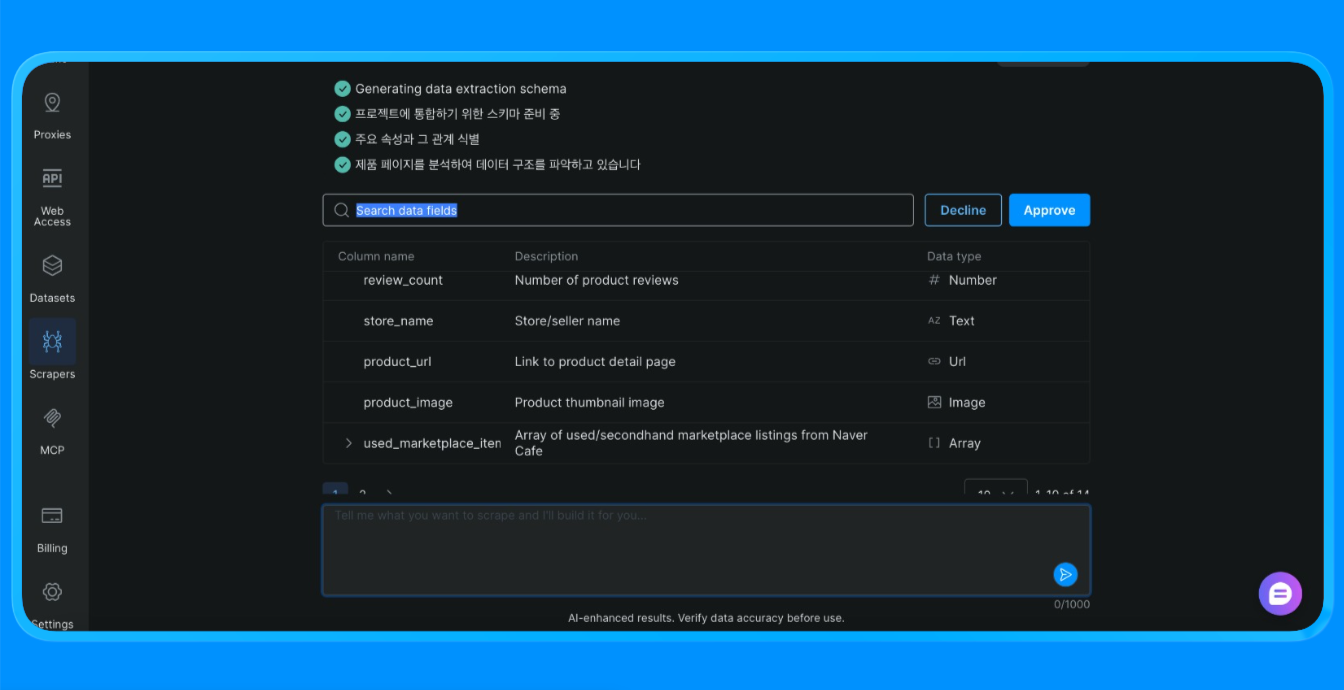
Scraper StudioはBright Dataのインフラを通じてNaverページを読み込み、視覚的抽出ルールを適用し、カスタムスクレイパーやブラウザ自動化が必要な構造化データを返します。
主な活用例
- 単発のデータ収集
- 概念実証プロジェクト
- 非技術チームによるウェブデータ収集
スクレイパー Studio は、カスタマイズよりもスピードとシンプルさが重要な場合には適しています。
3つのNaverスクレイピング手法の比較
| 手法 | 設定の労力 | 制御レベル | 拡張性 | 最適な用途 |
|---|---|---|---|---|
| Bright Data SERP API | 低 | 中 | 高 | SEOトラッキング、キーワード監視、構造化SERPデータ |
| Bright Data プロキシを使用したカスタムスクレイパー | 高 | 非常に高い | 非常に高い | ブログスクレイピング、動的ページ、カスタムワークフロー |
| Bright Dataスクレイパー Studio | 非常に低い | 低~中 | 中 | 高速抽出、ノーコードチーム、プロトタイピング |
選択方法:
- 信頼性の高い構造化された検索結果を大規模に必要とする場合はSERP APIを使用してください。
- レンダリング、再試行、抽出ロジックを完全に制御する必要がある場合は、カスタムスクレイパーとプロキシを使用してください。
- カスタマイズよりも速度と簡便性が重要な場合はスクレイパー Studioを使用してください。
まとめ
本チュートリアルでは、Bright Dataを用いたNaverスクレイピングの3つの本番環境対応手法を解説しました:
- 構造化検索データ用のマネージドSERP API
- 完全な柔軟性と制御を実現するプロキシ付きカスタムスクレイパー
- ノーコードのスクレイパー Studioワークフローによる高速データ抽出
各オプションは同じBright Dataインフラストラクチャ上で構築されています。最適な選択は、必要な制御レベル、スクレイピング頻度、コード記述の有無によって異なります。
SERP API、プロキシインフラストラクチャ、ノーコードのスクレイパー Studioを利用するにはBright Dataを調査し、ワークフローに合った手法を選択してください。
その他のウェブスクレイピングガイドとチュートリアル:





