

このブログでは、アプリケーションに最適な概念を選択できるよう、並行性と並列処理について詳細に解説します。
並行処理とは何か?
平易に言えば、並行処理とはソフトウェア開発において複数のタスクを同時に処理するための概念です。ただし理論上、全てのタスクが完全に同時実行されるわけではありません。代わりに、システムやアプリケーションがタスク間を高速に切り替えることで複数のタスクを同時に管理し、並列処理の錯覚を生み出します。このプロセスはタスクのインターリーブとも呼ばれます。
例えば、複数のユーザーリクエストを処理する必要があるWebサーバーを考えてみましょう。
- ユーザー1がデータを取得するリクエストをサーバーに送信します。
- ユーザー2がファイルをアップロードするリクエストをサーバーに送信します。
- ユーザー3が画像取得のリクエストをサーバーに送信する。
並行処理がない場合、各ユーザーは前のリクエストが完了するまで待機する必要があります。
- ステップ 1: CPU はスレッド 1 でデータ取得リクエストの処理を開始します。
- ステップ2:スレッド1が結果を待機している間、CPUはスレッド2でファイルアップロード処理を開始する。
- ステップ3:スレッド2がファイルアップロード完了を待機している間、CPUはスレッド3で画像取得を開始する。
- ステップ4:その後、CPUはリソースの空き状況に基づいてこれら3つのスレッド間で切り替えを行い、3つのタスクを同時に完了させます。
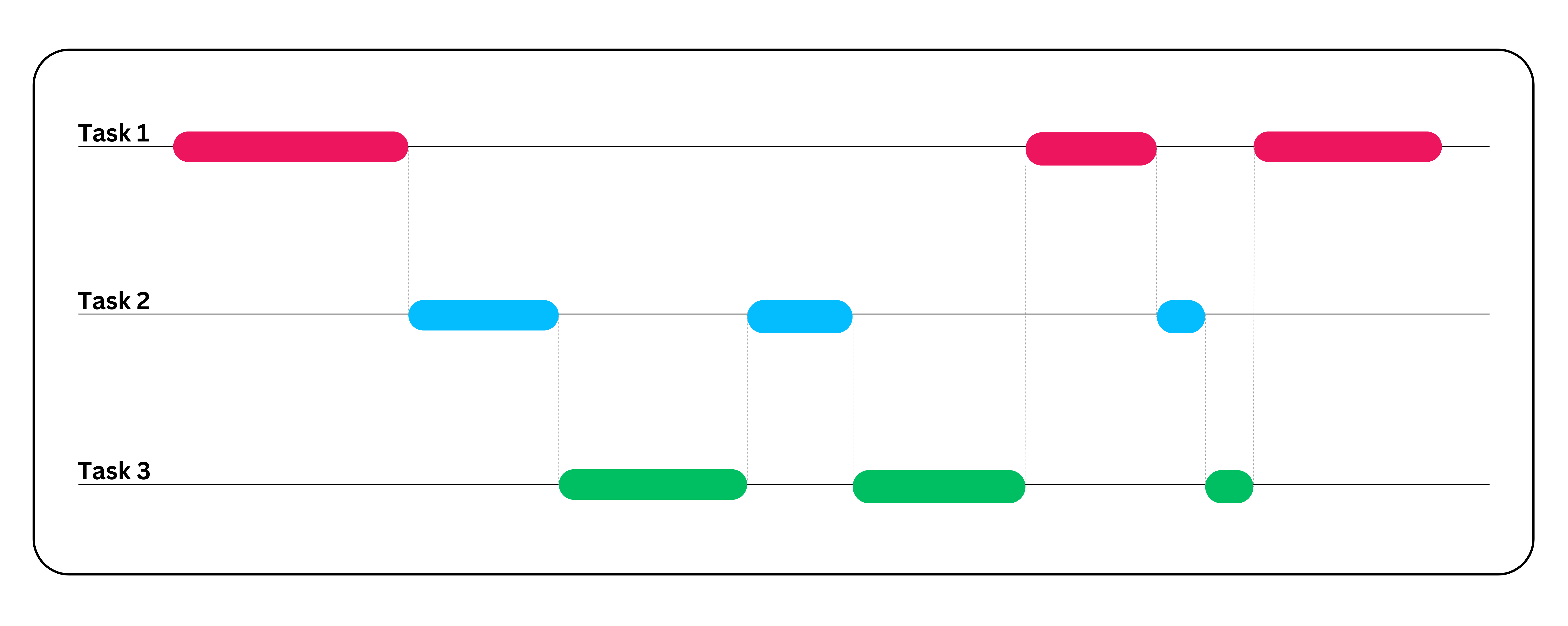
同期実行アプローチと比較して、並行処理アプローチははるかに高速であり、シングルコア環境においてシステム全体の応答時間、リソース利用率、システムスループット能力を向上させるのに極めて有用です。ただし、並行処理はシングルコアに限定されず、マルチコア環境でも実装可能です。
並行処理のユースケース
- レスポンシブなユーザーインターフェース。
- Webサーバー。
- リアルタイムシステム。
- ネットワークおよびI/O操作。
- バックグラウンド処理。
異なる並行処理モデル
現代のアプリケーションの複雑さと要求の高まりに伴い、開発者は従来のアプローチの欠点を解決するために新しい並行モデルを導入しています。主な並行モデルとその用途を以下に示します。
1. 協調型マルチタスク
このモデルでは、タスクは適切な時点で自発的にスケジューラに制御を譲り、スケジューラが他のタスクを処理できるようにします。この制御の譲渡は、タスクがアイドル状態にある場合や I/O 操作を待機している場合によく発生します。コンテキストの切り替えはアプリケーションコード内で管理されるため、実装が最も容易なモデルの 1 つです。
例:
- 軽量組み込みシステム
- 初期バージョンの Microsoft Windows (Windows 3.x)
- クラシック Mac OS
実世界のアプリケーション:
2. プリエンプティブ型マルチタスク
オペレーティングシステムまたはランタイムスケジューラがタスクを強制停止させ、スケジューリングアルゴリズムに基づいて他のタスクにCPU時間を割り当てます。このモデルは全てのタスクが均等にCPU時間を共有することを保証します。ただし、より複雑なコンテキストスイッチングを必要とします。
例:
- JVMによって管理されるJavaスレッド。
- Pythonのスレッドモジュール。
実世界のアプリケーション:
- 現代のオペレーティングシステム(Windows、macOS、Linux)
- Webサーバー。
3. イベント駆動型並行処理
このモデルでは、タスクは小さなノンブロッキング操作に分割され、キューに格納されます。その後、タスクはキューからジョブを取得し、必要なアクションを実行して次のジョブに移行し、システムの対話性を維持します。
例:
- Node.js(JavaScriptランタイム)。
- JavaScript の async/await パターン。
- Pythonのasyncioライブラリ。
実世界のアプリケーション:
- Node.jsのようなWebサーバー。
- リアルタイムチャットアプリケーション。
4. アクターモデル
アクターを用いて非同期でメッセージを送受信する。各アクターは一度に1つのメッセージのみを処理するため、共有状態を回避しロックの必要性を低減する。
例:
- Akkaフレームワーク(Java/Scala)。
- Erlangプログラミング言語。
- Microsoft Orleans(分散.NETアプリケーション)。
実世界の応用例:
- 分散システム。
- 電気通信システム。
- リアルタイムデータ処理システム。
5. リアクティブプログラミング
このモデルでは、データストリーム(オブザーバブル)を作成し、その処理方法(演算子)や反応方法(オブザーバ)を定義できます。データ変更やイベントが発生すると、それらは自動的にストリームを通じて購読している全てのオブザーバに伝播されます。このアプローチにより、非同期データやイベントの管理が容易になり、複雑なデータフローを扱うための明確で宣言的な方法を提供します。
例:
実世界の応用例:
- リアルタイムデータ処理パイプライン。
- インタラクティブなユーザーインターフェース。
- 動的で応答性の高いデータ処理を必要とするアプリケーション。
並列処理とは何か?
並列処理は、ソフトウェア開発において複数のタスクを同時に処理するために用いられるもう一つの一般的な概念です。タスク間を高速に切り替えることで並列処理の錯覚を生み出す並行処理とは異なり、並列処理は複数のCPUコアやプロセッサを使用して複数のタスクを実際に同時に実行します。これは、より大きなタスクを並列実行可能な小さな独立したサブタスクに分割することを含みます。このプロセスはタスク分解として知られています。
例えば、分析とシミュレーションを実行した後にレポートを生成するデータ処理アプリケーションを考えてみましょう。並列処理なしでは、これは1つの大きなタスクとして実行され、完了までにかなりの時間を要します。しかし、並列処理を選択すれば、タスク分解によってタスクをはるかに迅速に完了させることができます。
並列処理の仕組みは以下の通りです:
- ステップ1:メインタスクを独立したサブタスクに分割します。これらのサブタスクは、他のタスクからの入力を待たずに実行できる必要があります。ただし、依存関係がある場合は、正しい順序で実行されるよう適切にスケジューリングする必要があります。この例では、サブタスク間に依存関係がないものと仮定します。
- サブタスク1:データ分析の実行
- サブタスク2:レポート生成
- サブタスク3:シミュレーションの実行
- ステップ2: 3つのサブタスクを3つのコアに割り当てる。
- ステップ3:最終的に、各サブタスクの結果を統合し、元のタスクの最終出力を得る。
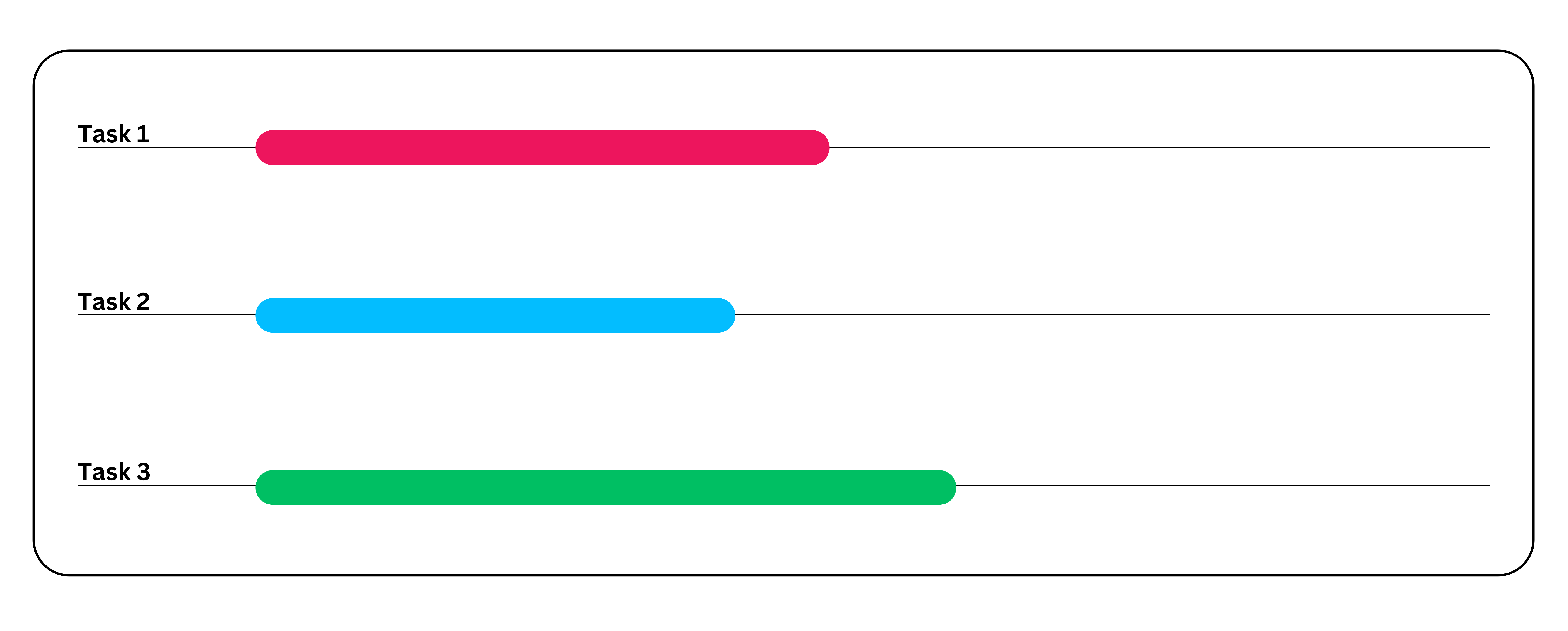
並列処理のユースケース
- 科学計算とシミュレーション。
- データ処理。
- 画像処理。
- 機械学習。
- リスク分析。
様々な並列処理モデル
並行処理と同様に、並列処理にもマルチコアプロセッサや分散コンピューティングリソースを効率的に活用するための複数のモデルが存在します。主な並列処理モデルとその用途は以下の通りです:
1. データ並列処理
このモデルでは、データを複数のプロセッサに分散し、各データサブセットに対して同一の操作を同時に実行します。独立したサブタスクに容易に分割可能なタスクにおいて特に効果的です。
例:
- SIMD(単一命令、複数データ)演算
- 並列配列処理。
- MapReduceフレームワーク。
実世界の応用例:
- 画像および信号処理
- 大規模データ分析
- 科学シミュレーション
2. タスク並列処理
タスク並列処理とは、全体タスクを複数の独立した小タスクに分割し、異なるプロセッサ上で並行実行する手法である。各タスクは異なる操作を実行する。
例:
- Javaにおけるスレッドベースの並列処理
- .NETにおける並列タスク。
- POSIXスレッド。
実世界の応用例:
- 複数のクライアント要求を処理するWebサーバー。
- 並列アルゴリズムの実装。
- リアルタイム処理システム。
3. パイプライン並列処理
パイプライン並列処理では、タスクは段階に分割され、各段階が並行して処理される。データはパイプラインを流れ、各段階が同時に動作する。
例:
- Unixパイプラインコマンド。
- 画像処理パイプライン。
- ETL(抽出、変換、ロード)ツールにおけるデータ処理パイプライン。
実世界の応用例:
- 動画・音声処理。
- リアルタイムデータストリーミングアプリケーション。
- 製造および組立ラインの自動化。
4. フォーク/ジョインモデル
このモデルでは、タスクを小さなサブタスクに分割(分岐)し、それらを並列に実行した後、結果を結合(合流)します。分割統治法アルゴリズムに有用です。
例:
- Javaのフォーク/ジョインフレームワーク。
- 並列再帰アルゴリズム(例:並列マージソート)。
- Intel Threading Building Blocks (TBB)。
実世界の応用例:
- 大規模データセットのソートなど複雑な計算タスク。
- 再帰アルゴリズム。
- 大規模な科学計算。
5. GPU並列処理
GPU並列処理は、グラフィックス処理装置(GPU)の大規模並列処理能力を活用し、数千のスレッドを同時に実行するため、高度に並列化されたタスクに最適です。
例:
- NVIDIAのCUDA(Compute Unified Device Architecture)。
- OpenCL(オープンコンピューティング言語)。
- 深層学習向けTensorFlow。
実世界での応用例:
- 機械学習および深層学習。
- リアルタイムグラフィックスレンダリング。
- 高性能科学計算。
並行処理と並列処理
並行処理と並列処理の仕組みについて理解が深まったところで、両者の長所を最大限に活かすために、いくつかの側面から比較してみましょう。
1. リソース利用率
- 並行処理: 単一コア内で複数のタスクを実行し、タスク間でリソースを共有します。例えば、CPUはアイドル状態や待機期間中にタスクを切り替えます。
- 並列処理:複数のコアまたはプロセッサを使用してタスクを同時に実行する。
2. 焦点
- 並行処理: 複数のタスクを同時に管理することに重点を置く。
- 並列処理:複数のタスクを同時に実行することに焦点を当てる。
3. タスク実行
- 並行性: タスクは交互に実行される。CPUの高速なコンテキストスイッチにより、並列実行の錯覚が生じる。
- 並列処理:タスクが異なるプロセッサやコア上で真の並列性をもって実行される。
4. コンテキストスイッチ
- 並行性: CPUがタスク間で頻繁にコンテキストを切り替えることで同時実行の様相を呈する。タスクが頻繁にアイドル状態になると、パフォーマンスに悪影響を及ぼす場合がある。
- 並列性:タスクが別々のコアまたはプロセッサ上で実行されるため、コンテキストスイッチは最小限か発生しない。
5. ユースケース
- 並行性: ディスクI/O、ネットワーク通信、ユーザー入力などのI/Oに制約されるタスク。
- 並列処理: 数学的計算、データ分析、画像処理など、集中的な処理を必要とするCPUバウンドなタスク。

並行処理と並列処理を併用できるか?
上記の比較から、多くの状況で並行処理と並列処理が互いに補完し合うことがわかります。しかし、実際の例に入る前に、マルチコア環境下でこの組み合わせが内部でどのように機能するかを見てみましょう。そのために、データの読み取り、書き込み、分析を行うWebサーバーを考えてみましょう。
ステップ1: タスクの特定
まず、アプリケーション内のI/Oに制約されるタスクとCPUに制約されるタスクを特定する必要があります。このケースでは:
- I/O 制約 – データの読み取りと書き込み。
- CPUバウンド – データ分析。
ステップ2:並行実行
データ読み書きタスクはI/Oバウンドであるため、単一コア内で別々のスレッドで実行可能です。サーバーはイベントループを用いてこれらのタスクを管理し、スレッド間を素早く切り替えながらタスクの実行を交互に行います。Pythonのasyncioのような非同期プログラミングライブラリを使用して、この並行動作を実装できます。
ステップ3: 並列実行
CPUバウンドタスクには複数のコアを割り当て、並列処理が可能です。この場合、データ分析を複数のサブタスクに分割し、各サブタスクを独立したコアで実行します。Pythonのconcurrent.futuresのような並列実行フレームワークでこの動作を実装できます。
ステップ4: 同期と調整
異なるコアで実行されるスレッドが相互に依存する場合があります。このような状況では、データの整合性を確保し競合状態を回避するために、ロックやセマフォなどの同期メカニズムが必要です。
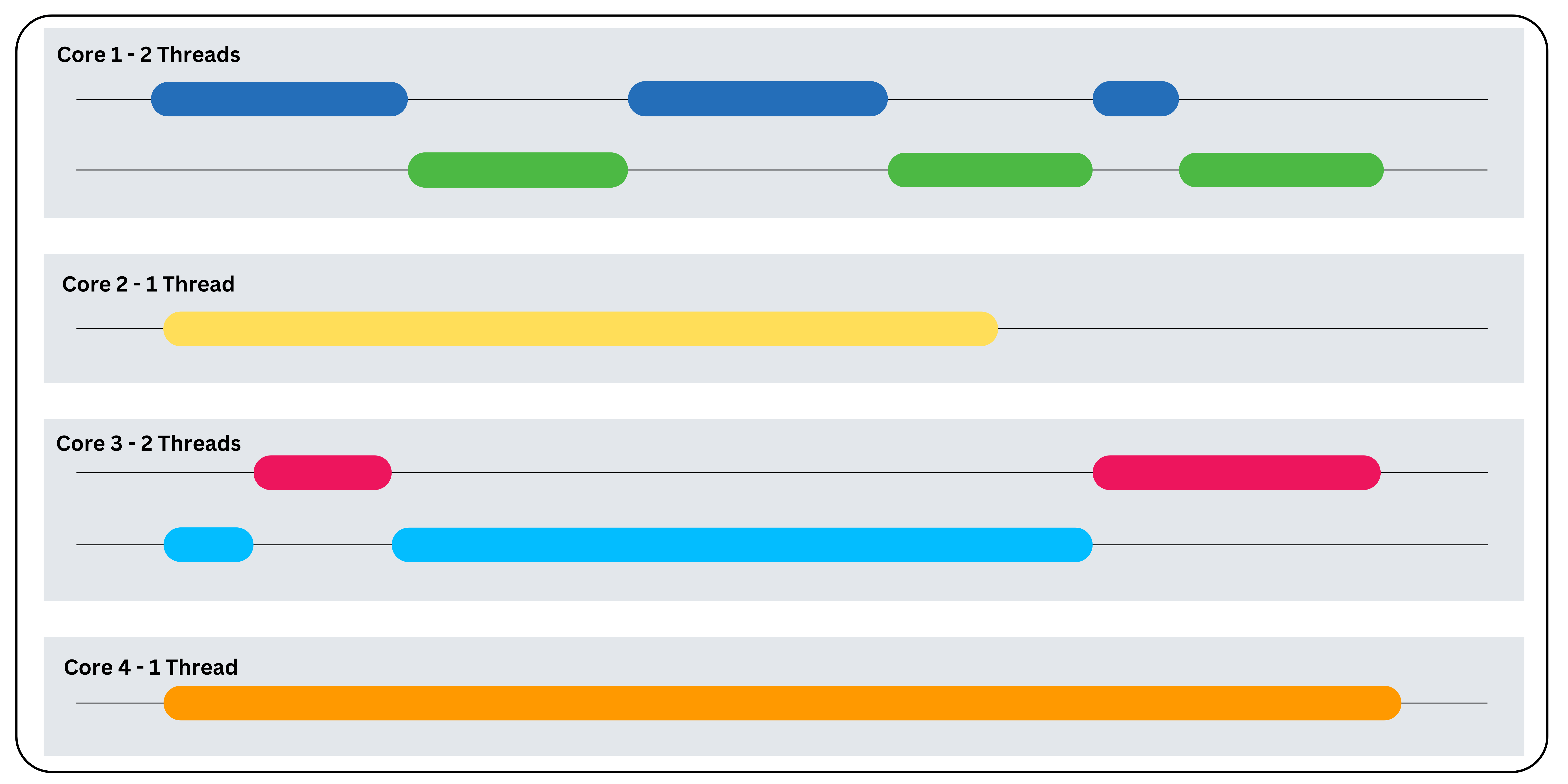
以下のコードスニペットは、Pythonで同一アプリケーション内で並行処理と並列処理を併用する方法を示しています:
import asyncio
from concurrent.futures import ProcessPoolExecutor
import os
# I/O 結合タスク(データ読み取り)のシミュレーション
async def read_data():
await asyncio.sleep(1) # I/O 遅延のシミュレーション
data = [1, 2, 3, 4, 5] # ダミーデータ
print("データ読み込み完了")
return data
# I/O ボトルネックとなるタスクのシミュレーション (データ書き込み)
async def write_data(data):
await asyncio.sleep(1) # I/O 遅延のシミュレーション
print(f"データ書き込み完了: {data}")
# CPU ボトルネックとなるタスクのシミュレーション (データ分析)
def analyze_data(data):
print(f"データ解析開始: CPU {os.getpid()}")
result = [x ** 2 for x in data] # 計算をシミュレート
print(f"データ解析完了: CPU {os.getpid()}")
return result
async def handle_request():
# 並行性: データの非同期読み込み
data = await read_data()
# 並列処理: データの並列分析
loop = asyncio.get_event_loop()
with ProcessPoolExecutor() as executor:
analyzed_data = await loop.run_in_executor(executor, analyze_data, data)
# 並行処理: データの非同期書き込み
await write_data(analyzed_data)
async def main():
# 複数リクエスト処理のシミュレーション
await asyncio.gather(handle_request(), handle_request())
# サーバーの実行
asyncio.run(main())
並行処理と並列処理を組み合わせた実世界の例
では、並行処理と並列処理を組み合わせて最適なパフォーマンスを実現する一般的なユースケースについて説明します。
1. 金融データ処理
金融データ処理システムの主なタスクには、日常業務の遂行と並行して、データの収集、処理、分析が含まれます。
- 並行処理は、非同期I/O操作を用いて株式市場などの様々なリソースから金融データを取得するために使用されます。
- 収集したデータを分析してレポートを生成します。これはCPU負荷の高いタスクであり、日常業務に影響を与えずに並行して実行するために並列処理が使用されます。
2. 動画処理
動画処理システムの主なタスクには、動画ファイルのアップロード、エンコード/デコード、分析が含まれます。
- 非同期I/O操作を用いた並行処理により、複数の動画アップロード要求を同時に処理できます。これにより、ユーザーは他のアップロード完了を待たずに動画をアップロードできます。
- エンコード、デコード、動画ファイルの分析といったCPU負荷の高いタスクには並列処理が用いられます。
3. データスクレイピング
データスクレイピングサービスの主なタスクには、様々なウェブサイトからのデータ取得と、収集したデータのパース・分析による知見の抽出が含まれます。
- データ取得は並行処理で処理できます。これにより、データ収集が効率的に行われ、応答待ちでブロックされることがありません。
- 収集したデータの処理には並列処理が用いられます。これにより複数のCPUコアで処理が行われ、リアルタイムレポートの提供を通じて組織の意思決定プロセスを改善します。
結論
並行処理と並列処理は、アプリケーションのパフォーマンス向上に用いられるソフトウェア開発の二大概念です。並行処理は複数のタスクを同時に実行可能にし、並列処理は複数のCPUコアを活用してデータ処理を高速化します。両者は異なる機能を持ちますが、統合することでI/OバウンドタスクとCPUバウンドタスクの両方を持つアプリケーションのパフォーマンスを大幅に向上させられます。
Bright Dataのツール(Web Scraper API、Web Scraper Functions、スクレイピングブラウザなど)は、これらの技術を最大限に活用し、一般的なウェブスクレイピングの課題を解決するよう設計されています。非同期操作を用いて複数のソースから同時にデータを収集し、並列処理でデータを迅速に分析・整理します。 したがって、Bright Dataのように並行処理と並列処理をコアに組み込んだデータプロバイダーを選択すれば、ウェブスクレイピング時にこれらの概念を一から実装する必要がなく、時間と労力を節約できます。
今すぐ無料トライアルを開始しましょう!





