

このガイドで、あなたは学ぶだろう:
- ゼロショット・クラシフィケーションとは何か?
- 長所と短所
- ウェブ・スクレイピングにおけるこの実践の妥当性
- ウェブスクレイピングシナリオでゼロショット分類を実装するためのステップバイステップのチュートリアル
さあ、飛び込もう!
ゼロシュート・クラシフィケーションとは?
ゼロショット分類(ZSC)とは、機械学習モデルが学習段階で一度も見たことのないクラスを予測する能力のことである。クラスとは、モデルがデータの一部に割り当てる特定のカテゴリーやラベルのことである。例えば、電子メールのテキストに「spam」というクラスを割り当てたり、画像に「cat」というクラスを割り当てたりすることができる。
ZSCは転移学習の一例に分類される。転移学習とは、ある問題を解決して得た知識を、別の、しかし関連する問題の解決に役立てる機械学習の手法である。
ZSCの核となる考え方は、以前からいくつかのタイプのニューラルネットワークや機械学習モデルで研究され、実装されてきた。ZSCは、以下のようなさまざまなモダリティに適用することができる:
- テキスト言語を広く理解するように訓練されたモデルがあるが、「持続可能なパッケージングに関する製品レビュー」の例を見せたことがないとする。ZSCを使えば、テキストの山からそのようなレビューを識別するよう求めることができる。ZSCは、特定のラベルごとに事前に学習された例に頼るのではなく、あなたが望むカテゴリー(ラベル)の意味を理解し、入力テキストと照合することでこれを行う。
- 画像:動物画像(猫、犬、馬など)のセットで訓練されたモデルは、訓練中にシマウマを見たことがなくても、シマウマの画像を「動物」、あるいは「縞模様の馬のような動物」と分類できるかもしれない。
- 音声:あるモデルは、”車のクラクション”、”サイレン”、”犬の鳴き声 “といった一般的な都市音を認識するようにトレーニングされるかもしれません。ZSCのおかげで、モデルは、その音響特性を理解し、既知の音と関連付けることで、「ジャックハンマー」のような、明示的に訓練されたことのない音を識別することができます。
- マルチモーダルデータ:ZSCは、見たことのないクラスのテキスト記述に基づいて画像を分類したり、あるいはその逆を行うなど、異なるタイプのデータを横断的に扱うことができる。
ZSCの仕組み
学習済みLLMの人気のおかげで、ゼロショット分類が注目を集めている。これらのモデルは膨大な量のAI指向のデータで学習され、言語、意味、文脈を深く理解することができる。
ZSCでは、事前に訓練されたモデルをNLI(自然言語推論)と呼ばれるタスクで微調整することが多い。NLIでは、”前提 “と “仮説 “という2つのテキストの関係を決定する。モデルは、仮説が含意(前提があれば真)か、矛盾(前提があれば偽)か、中立(無関係)かを判断する。
ゼロ・ショット分類セットアップでは、入力テキストが前提の役割を果たす。カテゴリ・ラベル候補は仮説として扱われる。モデルは、どの「仮説」(ラベル)が「前提」(入力テキスト)に最もよく包含されるかを計算する。最も高い含意スコアを持つラベルが分類として選択される。
ゼロショット・クラシフィケーションの利点と限界
ZSCの利点と欠点を探る時だ。
メリット
ZSCには、以下のような運用上の利点がある:
- 新しいクラスへの適応性:ZSCはデータを未知のカテゴリーに分類する道を開く。ZSCは、モデルの再トレーニングや、新しいクラスに対する特定のトレーニング例の収集を必要とせずに、新しいラベルを定義することでこれを実現します。
- ラベル付きデータ要件の削減:このメソッドは、ターゲットクラスに対する大規模なラベル付きデータセットへの依存を軽減する。これにより、機械学習プロジェクトのタイムラインとコストにおける一般的なボトルネックであるデータラベル付けが軽減される。
- 効率的な分類器の実装:新しい分類スキームを迅速に設定し、評価することができます。これにより、進化する要件に対応するための反復サイクルが高速化されます。
制限事項
強力ではあるが、ゼロショット分類には次のような制限がある:
- 性能のばらつき:ZSCを使用したモデルは、固定クラスセットで広範囲に訓練された教師ありモデルと比較して、精度が低くなる可能性がある。これは、ZSCがターゲットクラスの例で直接学習するのではなく、意味推論に依存しているために起こります。
- モデルの品質への依存:ZSCの性能は、事前に訓練された言語モデルの品質と能力に依存します。強力なベースモデルは、一般的にZSCの結果を向上させます。
- ラベルの曖昧さと言い回し:候補となるラベルの明確さと明確さは精度に影響する。ラベルが曖昧であったり、定義が不十分であったりすると、最適なパフォーマンスが得られない可能性がある。
ウェブスクレイピングにおけるゼロショット分類の妥当性
ウェブ上に新しい情報、製品、トピックが次々と出現するため、適応性の高いデータ処理方法が求められている。それはウェブスクレイピング-ウェブページからデータを取得する自動化されたプロセス-から始まります。
従来の機械学習手法では、スクレイピングされたデータの新しいクラスを処理するために、手作業による分類や頻繁な再学習が必要であり、規模が大きくなると非効率的です。その代わりに、ゼロショット分類は、ウェブコンテンツの動的な性質がもたらす課題に対処します:
- 異種データの動的分類:多様なソースからスクレイピングされたデータは、現在の分析目的に適したユーザー定義のラベルセットを使用してリアルタイムで分類することができます。
- 進化する情報ランドスケープへの適応:新しいカテゴリーやトピックをすぐに分類スキーマに組み込むことができるため、大規模なモデルの再開発サイクルを必要としません。
したがって、ウェブスクレイピングにおけるZSCの典型的な使用例は以下の通りである:
- 動的なコンテンツ分類:複数のドメインからニュース記事や商品リストのようなコンテンツをスクレイピングする場合、ZSCはアイテムを定義済みまたは新しいカテゴリに自動的に割り当てることができます。
- 新しいテーマに対するセンチメント分析:新商品のカスタマーレビューや、新興ブランドに関するソーシャルメディアデータをスクレイピングした場合、ZSCはその商品やブランドに特化したセンチメントトレーニングデータを必要とせずにセンチメント分析を実行できます。これにより、タイムリーなブランド認知のモニタリングや顧客フィードバックの評価が容易になります。
- 新たなトレンドやテーマの特定:潜在的な新傾向を表す仮説ラベルを定義することで、ZSCはフォーラム、ブログ、ソーシャルメディアからスクレイピングされたテキストを分析し、これらのテーマがますます広まっていることを特定するために使用することができます。
ゼロ・ショット・クラシフィケーションの実用化
このチュートリアル・セクションでは、Webから取得したデータにゼロショット分類を適用するプロセスを説明します。対象サイトは “Hockey Teams “です:フォーム、検索、ページネーション“です:

まず、ウェブスクレーパーが上の表からデータを抽出する。次に、LLMがZSCを使って分類します。このチュートリアルでは、Hugging FaceのDistilBart-MNLI:BARTファミリーの軽量LLMを使います。
以下の手順に従って、希望するZSCゴールを達成する方法をご覧ください!
前提条件と依存関係
このチュートリアルを再現するには、マシンにPython 3.10.1以降がインストールされている必要があります。
プロジェクトのメインフォルダーをzsc_project/と呼ぶとします。このステップが終わると、フォルダは以下のような構造になっています:
zsc_project/
├── zsc_scraper.py
└── venv/どこでだ:
zsc_scraper.pyはコーディングロジックを含むPythonファイルです。venv/には仮想環境が含まれる。
venv/ 仮想環境ディレクトリは次のように作成する:
python -m venv venvアクティベートするには、ウィンドウズで以下を実行する:
venvScriptsactivate同様に、macOSとLinuxでは、以下を実行する:
source venv/bin/activateアクティベートされた仮想環境で、以下の方法で依存関係をインストールする:
pip install requests beautifulsoup4 transformers torchこれらの依存関係は以下の通りである:
リクエスト:HTTP ウェブリクエストを行うためのライブラリ。beautifulssoup4: HTMLやXMLドキュメントを解析し、そこからデータを抽出するためのライブラリ。詳しくはBeautifulSoupウェブスクレイピングガイドをご覧ください。transformers:Hugging Faceによるライブラリで、何千もの事前学習済みモデルを提供する。トーチPyTorchはオープンソースの機械学習フレームワークです。
素晴らしい!これで対象のウェブサイトからデータを抽出し、ZSCを実行するために必要なものが揃った。
ステップ1:初期設定と構成
zsc_scraper.pyファイルを初期化し、必要なライブラリをインポートし、いくつかの変数を設定します:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process 上記のコードは次のようになる:
BASE_URLでスクレイピング対象のウェブサイトを定義します。CANDIDATES_LABELSは、ゼロショット分類モデルがスクレイピングされたデータを分類するために使用するカテゴリを定義する文字列のリストを格納します。モデルは、これらのラベルのどれが各チームデータを最もよく説明するかを決定しようとします。- スクレイピングするページの最大数と、取得するチームデータの最大数を定義します。
完璧です!Pythonでゼロ・ショット分類を始めるために必要なものが揃いました。
ステップ2:ページURLの取得
ターゲットページのページネーション要素を調べることから始めよう:

ここでは、ページネーションのURLが.paginationHTMLノードに含まれていることがわかります。
ウェブサイトのページネーション・セクションから、ユニークなページURLをすべて見つける関数を定義する:
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urlsこの機能:
- メソッド
get()を使用して、対象のWebサイトにHTTPリクエストを送信します。 - BeautifulSoupの
select()メソッドでページネーションを管理する。 forループで各ページを繰り返し、一貫した順序を保証する。- ユニークな全ページURLのリストを返す。
クールだ!データをスクレイピングするウェブページのURLを取得する関数を作成しました。
ステップ3:データをかき集める
ターゲットページのページネーション要素を調べることから始めよう:

ここでは、スクレイピングするチームのデータが.tableHTMLノードに含まれていることがわかります。
単一ページのURLを受け取り、そのコンテンツを取得し、チームの統計を抽出する関数を作成する:
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_dataこの機能:
select()メソッドで、テーブルの行からデータを取得します。- 各チーム行を、
for row in table_rows:ループで処理する。 - 取得したデータをリストで返します。
よくやった!ターゲットのウェブサイトからデータを取得する関数を作成しました。
ステップ4:プロセスの編成
以下のステップでワークフロー全体を調整する:
- 分類モデルをロードする
- スクレイピングするページのURLを取得する。
- 各ページからデータをかき集める
- スクレイピングされたテキストをZSCで分類する
以下のコードで実現できる:
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")このコード
pipeline()メソッドで事前学習されたモデルをロードし、そのタスクを"ゼロショット分類 "で指定します。- 前の関数を呼び出し、実際の ZSC を実行する。
完璧です!あなたは、これまでのすべてのステップを編成し、実際のゼロショット分類を実行する関数を作成した。
ステップ#5:すべてをまとめてコードを実行する
以下はzsc_scraper.pyが含むべき内容です:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from transformers import pipeline
# The starting URL for scraping
BASE_URL = "https://www.scrapethissite.com/pages/forms/"
# Predefined categories for the zero-shot classification
CANDIDATE_LABELS = [
"NHL team season performance summary",
"Player biography and career stats",
"Sports news and game commentary",
"Hockey league rules and regulations",
"Fan discussions and forums",
"Historical sports data record"
]
MAX_PAGES_TO_SCRAPE = 2 # Maximum number of pages to scrape
MAX_TEAMS_PER_PAGE_FOR_ZSC = 2 # Maximum number of teams to process per page
# Fetch page URLs
def get_all_page_urls(base_url_to_scrape):
page_urls = [base_url_to_scrape] # Initialize with the base URL
response = requests.get(base_url_to_scrape) # Fetch content of base URL
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML content
# Tags for pagination
pagination_links = soup.select("ul.pagination li a")
discovered_urls = set() # Store unique relative URLs to avoid duplicates
for link_tag in pagination_links:
href = link_tag.get("href")
# Ensure the link is a pagination link for this site
if href and href.startswith("?page_num="):
discovered_urls.add(href)
# Sort for consistent order and construct full URLs
for relative_url in sorted(list(discovered_urls)):
full_url = urljoin(base_url_to_scrape, relative_url) # Create absolute URL
# If you want to add paginated URLs, uncomment the next line:
page_urls.append(full_url)
return page_urls
def scrape_page(url):
page_data = [] # List to store data scraped from this page
response = requests.get(url) # Fetch the content of the page
soup = BeautifulSoup(response.content, "html.parser") # Parse the HTML
# Select all table rows with class "team" inside a table with class "table"
table_rows = soup.select("table.table tr.team")
for row in table_rows:
# Extract text from each row (name, year, wins, losses)
team_stats = {
"name": row.select_one("td.name").get_text(strip=True),
"year": row.select_one("td.year").get_text(strip=True),
"wins": row.select_one("td.wins").get_text(strip=True),
"losses": row.select_one("td.losses").get_text(strip=True),
}
page_data.append(team_stats) # Add the scraped team data to the list
return page_data
# Initialize the zero-shot classification pipeline
classifier = pipeline("zero-shot-classification", model="valhalla/distilbart-mnli-12-3")
# Get all URLs to scrape (base URL + paginated URLs)
all_page_urls = get_all_page_urls(BASE_URL)
all_team_data_for_zsc = [] # List to store team data selected for classification
# Loop through the page URLs
for page_url in all_page_urls[:MAX_PAGES_TO_SCRAPE]:
current_page_team_data = scrape_page(page_url) # Scrape data from the current page
# Maximum teams per page to scrape
all_team_data_for_zsc.extend(current_page_team_data[:MAX_TEAMS_PER_PAGE_FOR_ZSC])
# Start classification
print(f"n--- Classifying {len(all_team_data_for_zsc)} Scraped Hockey Team Snippets ---")
# Loop through the collected team data to classify each one
for i, team_info_dict in enumerate(all_team_data_for_zsc):
name = team_info_dict["name"]
year = team_info_dict["year"]
wins = team_info_dict["wins"]
losses = team_info_dict["losses"]
# Construct a text snippet from the team data for classification
text_snippet = f"Team: {name}, Year: {year}, Wins: {wins}, Losses: {losses}."
print(f"nData Snippet {i+1}: "{text_snippet}"")
# Perform zero-shot classification
result = classifier(text_snippet, CANDIDATE_LABELS, multi_label=False)
# Print the predicted category and its confidence score
print(f"Predicted Category: {result['labels'][0]}")
print(f"Confidence Score: {result['scores'][0]:.4f}")よくやった!あなたは最初のZSCプロジェクトを完了した。
以下のコマンドでコードを実行する:
python zsc_scraper.pyこれが予想された結果だ:
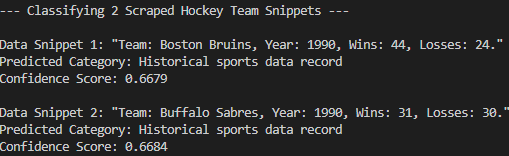
ご覧のように、このモデルはスクレイピングされたデータを “歴史的スポーツデータレコード “に正しく分類している。これはゼロショット分類なしには不可能でした。ミッション完了!
結論
この記事では、ゼロショット分類とは何か、そしてウェブスクレイピングの文脈でそれを適用する方法について学んだ。ウェブデータは常に変化しており、事前に訓練されたLLMがすべてを知っていることは期待できません。ZSCは、再トレーニングすることなく新しい情報を動的に分類することで、そのギャップを埋める手助けをします。
しかし、すべてのウェブサイトが簡単にスクレイピングできるわけではないため、新鮮なデータを入手することが真の課題です。そこで、Bright Dataは、スクレイピングの障害を克服するために設計された一連の強力なツールとサービスを提供します。これらには以下が含まれます。
- ウェブアンロッカー:アンチスクレイピング保護をバイパスし、最小限の労力であらゆるウェブページからクリーンなHTMLを提供するAPI。
- スクレイピング・ブラウザ:JavaScriptレンダリングを備えたクラウドベースの制御可能なブラウザ。CAPTCHA、ブラウザフィンガープリント、再試行などを自動的に処理します。PantherやSelenium PHPとシームレスに統合できます。
- ウェブスクレーパーAPI:数十の一般的なドメインから構造化されたウェブデータにプログラムでアクセスするためのエンドポイント。
機械学習のシナリオについては、当社のAIハブもご覧ください。
今すぐBright Dataに登録し、無料トライアルを開始してスクレイピングソリューションをお試しください!





