

Pythonを使ったデータ分析に関するこのガイドでは、以下のことを学びます:
- データ分析にPythonを使う理由
- Pythonによるデータ分析のための共通ライブラリ
- Pythonでデータ分析を行うためのステップバイステップのチュートリアル
- データを分析する際のプロセス
さあ、飛び込もう!
データ分析にPythonを使う理由
データ分析は通常、主に2つのプログラミング言語を使って行われる:
特に、データ分析にPythonを使う主な理由は以下の通りです:
- 学習曲線が浅い:Pythonの構文はシンプルで読みやすく、初心者から上級者までアクセスしやすい。
- 汎用性:Pythonは、CSV、Excel、JSON、SQLデータベース、Parquetなど、さまざまなデータタイプやフォーマットを扱うことができる。また、単純なデータクリーニングから複雑な機械学習やディープラーニングのアプリケーションまで、幅広いタスクに適している。
- スケーラビリティ:Pythonはスケーラブルで、小規模なデータセットから大規模なデータ処理タスクまで対応できる。例えば、Daskや PySparkのようなライブラリは、労力をかけずにビッグデータを処理するのに役立ちます。
- コミュニティのサポートPythonには、エコシステムに貢献する開発者やデータサイエンティストの大規模で活発なコミュニティがある。
- 機械学習とAIの統合:Pythonは、TensorFlow、PyTorch、Kerasなどのライブラリが高度な分析と予測モデリングをサポートする、機械学習とAIのための主要言語です。
- 再現性とコラボレーション:Jupyterノートブックは、データ分析のスニペットを共有し、再現するのに役立ちます。
- 目的別のユニークな環境Pythonには、同じ環境を異なる目的で使用する可能性がある。例えば、同じJupyter Notebookを使ってウェブからデータをスクレイピングし、それを分析することができる。同じ環境で、機械学習モデルを使って予測を行うこともできる。
Pythonによるデータ分析のための共通ライブラリ
Pythonは幅広いライブラリーのエコシステムがあるため、分析分野でも広く使われている。ここでは、Pythonでデータ分析を行うための最も一般的なライブラリを紹介します:
- NumPy:数値計算と多次元配列を扱う。
- パンダ:データ操作と分析、特に表形式のデータを扱う。
- Matplotlibと Seaborn:データの可視化と洞察に満ちたプロットの作成に。
- SciPy:科学計算と高度な統計解析用。
- Plotly:アニメーションプロット作成用。
この後のガイド・セクションで、彼らの動きを見てみよう!
Pythonによるデータ分析:完全な例
データ分析にPythonを使う理由と、そのタスクをサポートする一般的なライブラリはお分かりいただけたと思います。このステップバイステップのチュートリアルに従って、Pythonでデータ分析を行う方法を学んでください。
このセクションでは、Bright Dataの無料データセットから取得したAirbnb物件情報を分析します。
必要条件
このガイドに従うには、マシンにPython 3.6以上がインストールされている必要があります。
ステップ1:環境のセットアップと依存関係のインストール
プロジェクトのメイン・フォルダーをdata_analysis/と呼ぶとする。このステップが終わると、フォルダは次のような構造になっている:
data_analysis/
├── analysis.ipynb
└── venv/どこでだ:
analyze.ipynbは、すべてのPythonデータ解析コードを含むJupyter Notebookです。venv/にはPython仮想環境が含まれる。
venv/ 仮想環境ディレクトリは次のように作成する:
python -m venv venvWindowsでアクティベートするには、以下を実行する:
venvScriptsactivate同様に、macOS/Linuxでは、次のように実行する:
source venv/bin/activate起動した仮想環境で、必要なライブラリをすべてインストールする:
pip install pandas jupyter matplotlib seaborn numpyanalysis.ipynbファイルを作成するには、まずdata_analysis/フォルダに入る必要がある:
cd data_analysis次に、このコマンドで新しいJupyter Notebookを初期化する:
jupyter notebookブラウザからJupyter Notebook Apphttp://locahost:8888にアクセスできるようになりました。
New > Python 3 (ipykernel) “をクリックして新規ファイルを作成する:
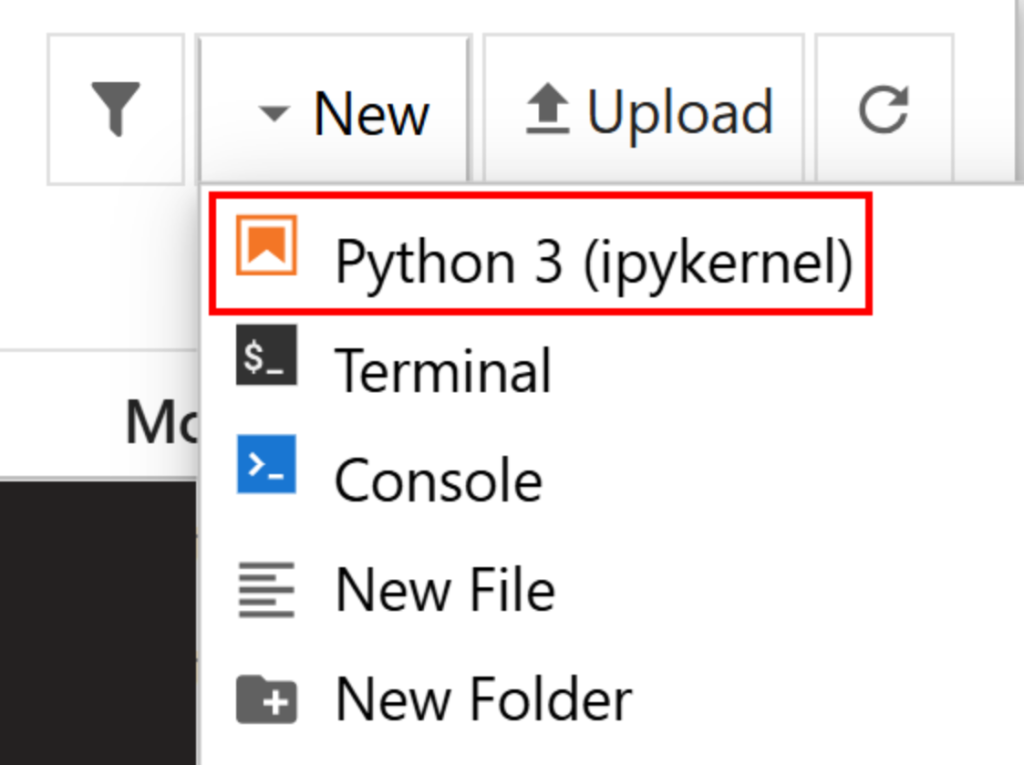
デフォルトでは、新しいファイルはuntitled.ipynbという名前になります。ダッシュボードで以下のように名前を変更できます:
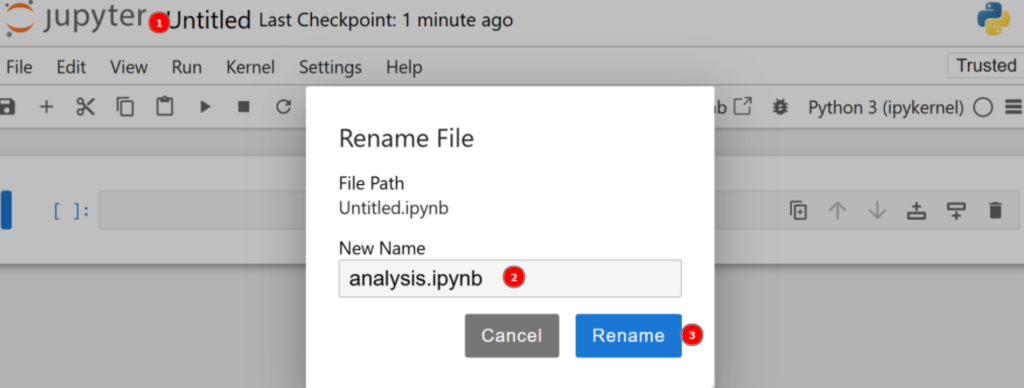
素晴らしい!これでPythonを使ったデータ分析の準備は完璧だ。
ステップ2:データをダウンロードして開く
このチュートリアルで使用するデータセットは、Bright Dataのデータセット・マーケットプレイスから入手した。ダウンロードするには、Bright Dataに無料でサインアップし、ユーザーダッシュボードに移動してください。そして、”Web Datasets > Dataset “のパスに従い、データセットマーケットプレイスにアクセスする:
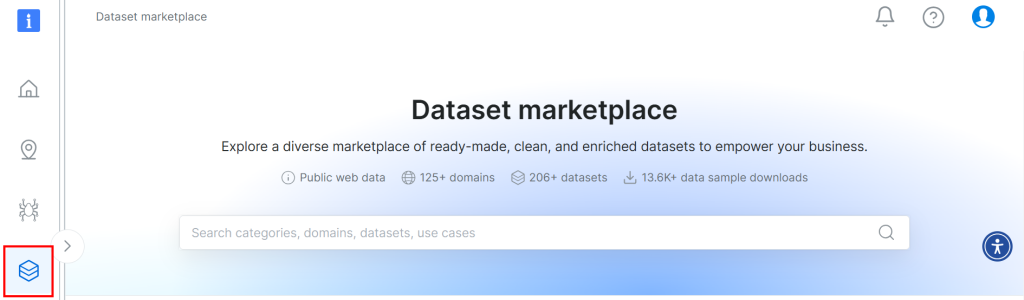
下にスクロールして「Airbnb物件情報」カードを検索してください:
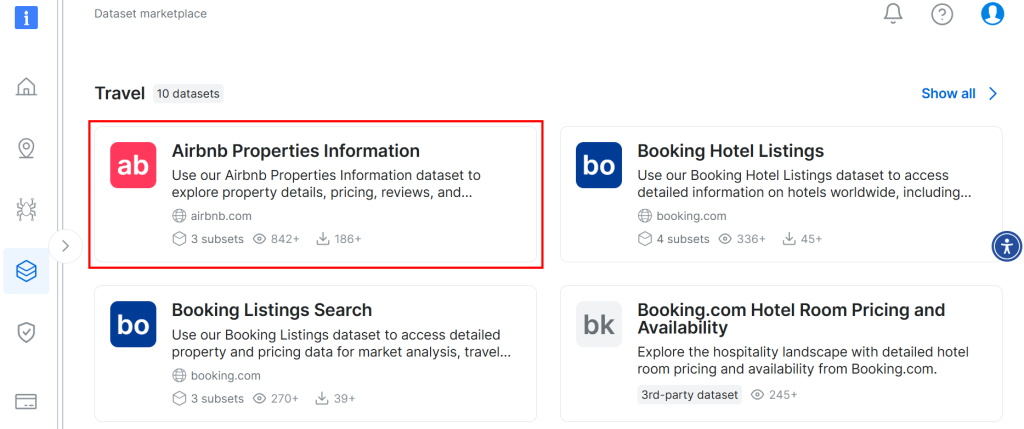
データセットをダウンロードするには、「Download sample > Download as CSV」オプションをクリックしてください:
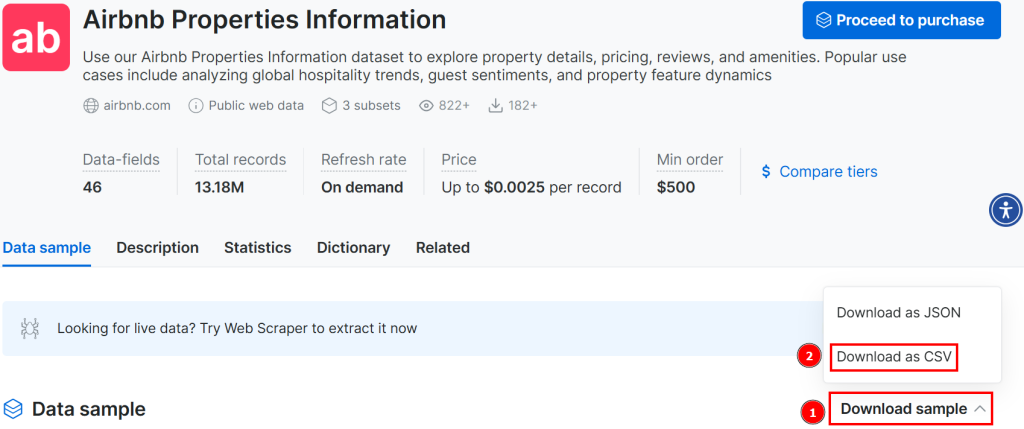
ダウンロードしたファイルの名前を、例えばairbnb.csvのように変更することができます。JupyterノートブックでCSVファイルを開くには、新しいセルに次のように記述します:
import pandas as pd
# Open CSV
data = pd.read_csv("airbnb.csv")
# Show head
data.head()このスニペットでは
read_csv()メソッドは、CSVファイルをpandasデータセットとして開きます。head()メソッドは、データセットの最初の5行を表示する。
以下は期待される結果である:
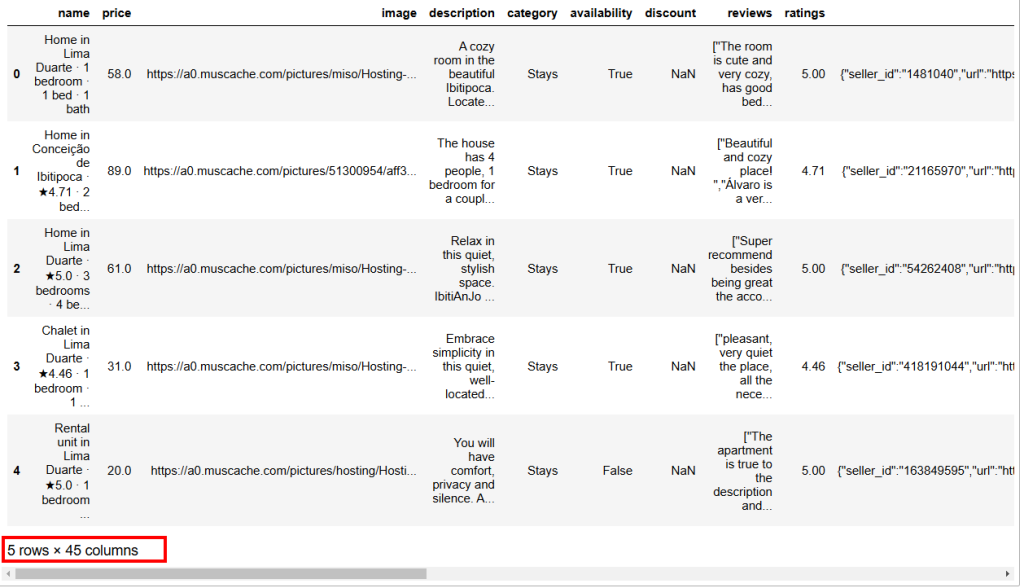
ご覧のように、このデータセットには45の列がある。そのすべてを見るには、バーを右に動かす必要がある。しかし、この場合は列数が多いので、バーを右にスクロールするだけでは、いくつかの列が隠れてしまい、すべての列を見ることはできない。
すべての列を本当に視覚化するには、別のセルに次のように入力する:
# Show all columns
pd.set_option("display.max_columns", None)
# Display the data frame
print(data)ステップ3:NaNの管理
計算においてNaNは「Not a Number」の略である。Pythonでデータ分析をしていると、空の値を持つデータセットや、数値があるはずの文字列、すでにNaNのラベルが貼られたセルに遭遇することがある(例えば、上の画像の割引の列を参照)。
データを分析することが目的なので、NaNを適切に扱わなければならない。そのためには、主に3つの方法がある:
NaNを含む行をすべて削除する。- ある列の
NaN を、同じ列の他の数値について計算された平均で代用する。 - ソースデータセットを充実させるために新しいデータを検索する。
簡単のために、最初のアプローチに従おう。
まず、割引カラムの値がすべてNaNかどうかを確認する必要がある。もしそうなら、その列全体を削除することができる。それを確認するには、新しいセルに次のように書く:
import numpy as np
is_discount_all_nan = data["discount"].isna().all()
print(f"Is the 'discount' column all NaNs? {is_discount_all_nan}")このスニペットでは、メソッドisna().all()は、data["discount"]でデータセットからフィルタリングされたdiscount列のNaNを分析している。
得られる結果は「True」であり、これは割引****列の値がすべてNaNであるため、その列を削除できることを意味する。そのためには、次のように書く:
data = data.drop(columns=["discount"])元のデータセットは、割引カラムのない新しいデータセットに上書きされた。
これでデータセット全体を分析し、次のように行にNaNがあるかどうかを確認できる:
total_nans = data.isna().sum().sum()
print(f"Total number of NaN values in the data frame: {total_nans}")あなたが受け取る結果はこうだ:
Total number of NaN values in the data frame: 1248これは、データ・フレーム内に1248個のNaNがあることを意味する。少なくとも1つのNaNを含む行を削除するには、次のようにタイプする:
data = data.dropna()これでデータフレームにはNaNがなくなり、結果の歪みを心配することなくPythonデータ解析の準備が整った。
プロセスがうまくいったことを確認するには、こう書けばいい:
print(data.isna().sum().sum())期待される結果は0である。
ステップ4:データ探索
Airbnbのデータを可視化する前に、データに慣れる必要があります。データセットの統計情報を視覚化することから始めるのが良い方法です:
# Show statistics of the entire dataset
statistics = data.describe()
# Print statistics
print(statistics)これが予想された結果だ:
price ratings lat long guests
count 182.000000 182.000000 182.000000 182.000000 182.000000
mean 147.523352 4.804505 6.754955 -68.300942 6.554945
std 156.574795 0.209834 27.795750 24.498326 3.012818
min 16.000000 4.000000 -21.837300 -106.817450 2.000000
25% 50.000000 4.710000 -21.717270 -86.628968 4.000000
50% 89.500000 4.865000 30.382710 -83.479890 6.000000
75% 180.750000 4.950000 30.398860 -43.925480 8.000000
max 1003.000000 5.000000 40.481580 -43.801300 16.000000
property_id host_number_of_reviews host_rating hosts_year
count 1.820000e+02 182.000000 182.000000 182.000000
mean 1.323460e+17 3216.879121 4.776099 7.324176
std 3.307809e+17 4812.876819 0.138849 2.583280
min 3.089381e+06 2.000000 4.290000 1.000000
25% 3.107102e+07 73.000000 4.710000 6.000000
50% 4.375321e+07 3512.000000 4.710000 9.000000
75% 4.538668e+07 3512.000000 4.890000 9.000000
max 1.242049e+18 20189.000000 5.000000 11.000000
host_response_rate total_price
count 182.000000 182.000000
mean 98.538462 859.317363
std 8.012156 1498.684990
min 25.000000 19.000000
25% 100.000000 111.500000
50% 100.000000 350.000000
75% 100.000000 934.750000
max 100.000000 13165.000000 describe()メソッドは、数値を持つカラムに関連する統計情報を報告します。これはデータを理解するための最初の方法です。たとえば、host_ratingカラムは次のような興味深い統計情報を報告します:
- データセットには合計182件のレビューがある(
カウント値)。 - 最高評価は5点、最低評価は4.29点、平均評価は4.77点である。
それでも、上記の統計では満足できないかもしれない。そこで、host_ratingカラムの散布図を視覚化して、後で調べたくなるような興味深いパターンがないか確認してみましょう。以下はseabornで散布図を作成する方法です:
import seaborn as sns
import matplotlib.pyplot as plt
# Define figure size
plt.figure(figsize=(15, 10))
# Plot the data
sns.scatterplot(data=data, x="host_rating", y="listing_name")
# Labeling
plt.title("HOST RATINGS SCATTERPLOT", fontsize=20)
plt.xlabel("Host ratings", fontsize=16)
plt.ylabel("Houses", fontsize=16)
# Show plot
plt.show()上記のスニペットは次のようなものである:
- メソッド
figure()で画像のサイズ(インチ)を定義します。 - で設定されたメソッド
scatterplot()を用いて seaborn を用いて散布図を作成します。
これが期待される結果だ:
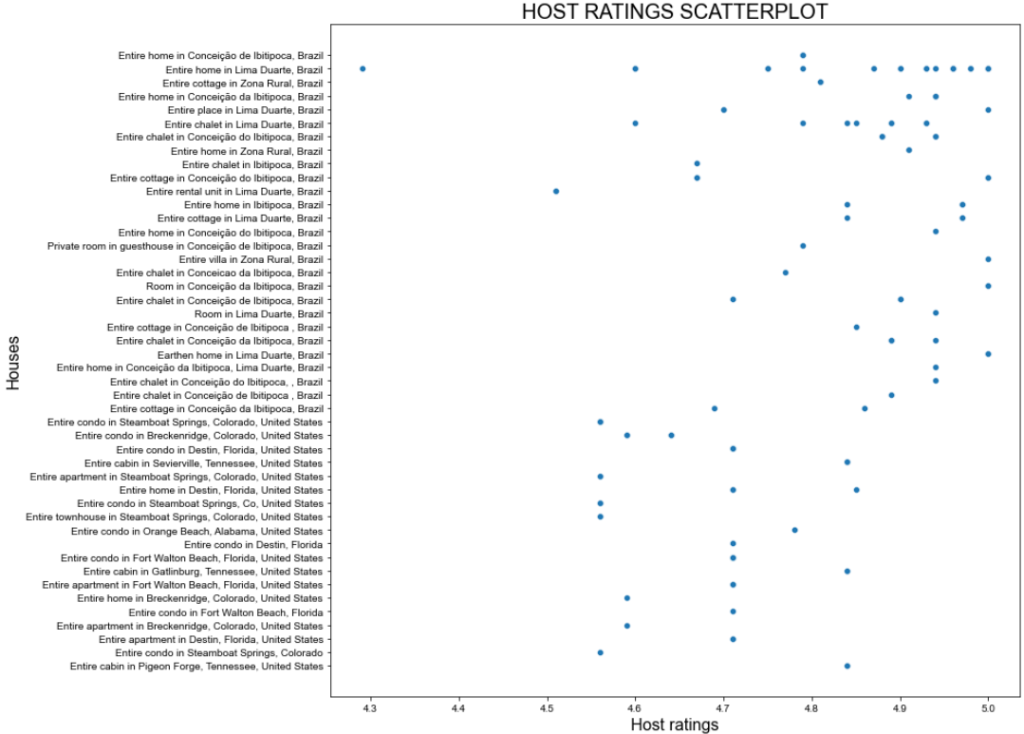
素晴らしい筋書きだが、もっとうまくやれるはずだ!
ステップ5:データの変換と可視化
先ほどの散布図を見ると、ホストの評価には特にパターンがないことがわかる。しかし、大半は4.7ポイント以上である。
あなたが休暇を計画しており、最高の場所に滞在したいと想像してみてください。少なくとも評価4.8の家に泊まるにはいくらかかるのだろう?
その質問に答えるには、まずデータを変換する必要がある!
あなたができる変換は、評価が4.8以上の新しいデータフレームを作成することです。このデータフレームには、listing_n``ame列にアパートメントの名前、total_price列にアパートメントの価格が入ります。
そのサブセットを取得し、統計情報を表示する:
# Filter the DataFrame
high_ratings = data[data["host_rating"] > 4.8][["listing_name", "total_price"]]
# Caltulate and print statistics
high_ratings_statistics = high_ratings.describe()
print(high_ratings_statistics)上記のスニペットは、high_ratingsという新しいデータ・フレームを次のように作成する:
data["host_rating"]>4.8は、データ・データセットのhost_ratingカラムの4.8より大きい値をフィルターする。[["listing_name", "total_price"]]はhigh_ratingsデータ・フレームからlisting_name列とtotal_price列のみを選択します。
以下は期待される出力である:
total_price
count 78.000000
mean 321.061026
std 711.340269
min 19.000000
25% 78.250000
50% 116.000000
75% 206.000000
max 4230.000000統計によると、選ばれたアパートの平均総価格は321ドルで、最低19ドル、最高4230ドルである。これはさらなる分析が必要である!
前に使ったのと同じスニペットを使って、高評価の家の価格の散布図を可視化する。グラフで使用する変数を次のように変更するだけです:
# Define figure size
plt.figure(figsize=(12, 8))
# Plot the data
sns.scatterplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show grid for better visualization
sns.set_style("ticks", {'axes.grid': True})
# Show plot
plt.show()そして、これが出来上がったプロットである:
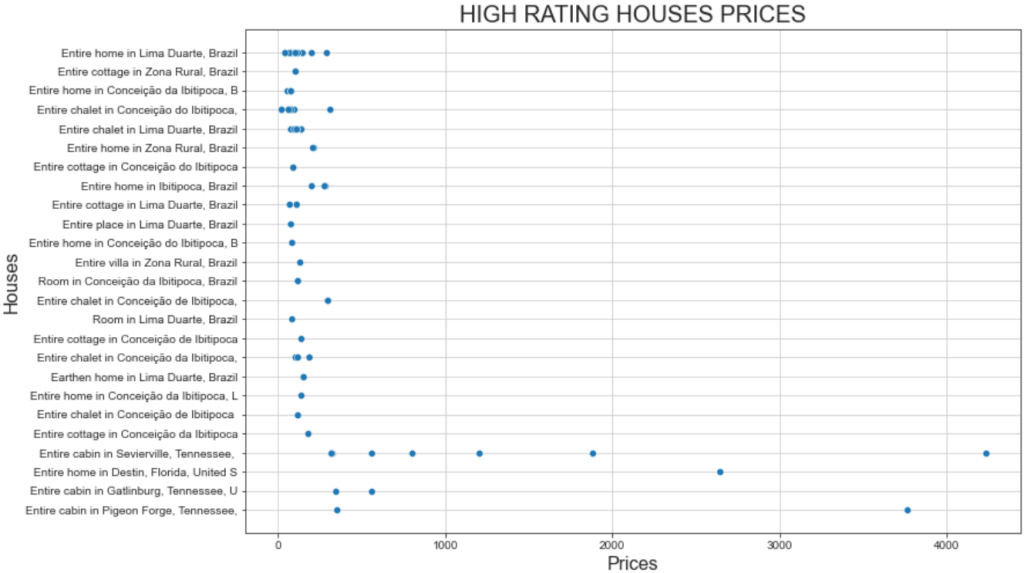
このプロットは2つの興味深い事実を示している:
- 価格はどれも500ドル以下が中心だ。
- セヴィアビルのキャビン全体」と「ピジョンのキャビン全体」は、1000ドルをはるかに超える価格を提示している。
価格帯を視覚化するより良い方法は、ボックス・プロットを表示することである。これがその方法です:
# Define figure size
plt.figure(figsize=(15, 10))
# Plotting the boxplot
sns.boxplot(data=high_ratings, x='total_price', y='listing_name')
# Labeling
plt.title('HIGH RATING HOUSES PRICES - BOXPLOT', fontsize=20)
plt.xlabel('Prices', fontsize=16)
plt.ylabel('Houses', fontsize=16)
# Show plot
plt.show()今回、出来上がったチャートはこうなる:
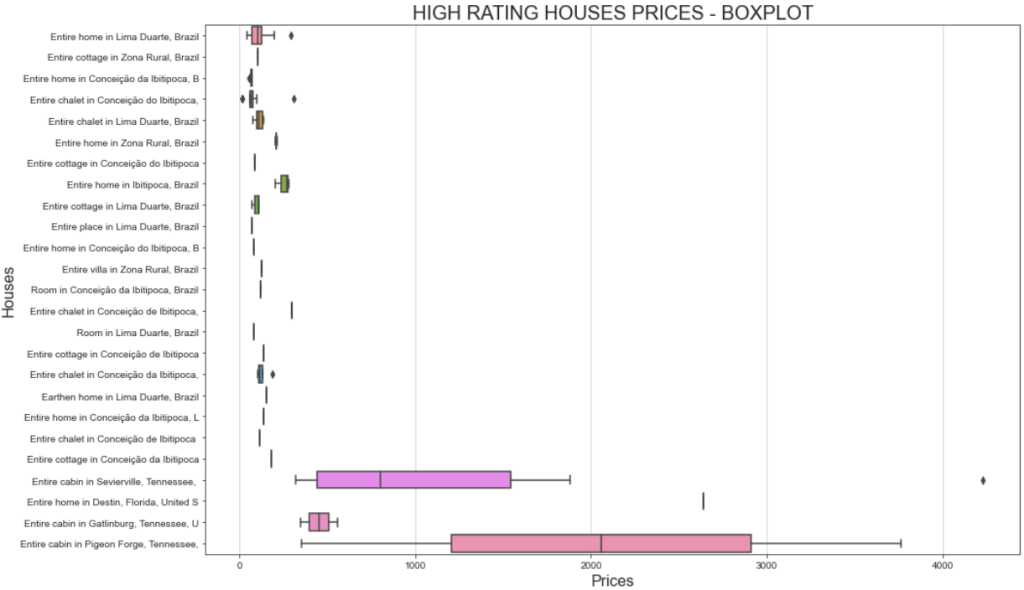
同じ家なのに、なぜ費用が違うのか、と疑問に思うのなら、ユーザーの評価をフィルターにかけたことを忘れてはならない。つまり、ユーザーによって支払いも評価も異なるということだ。
さらに、「セヴィアヴィルのキャビン全体」の価格が、1,000ドル以下から4,000ドル以上まで大きく変動しているのは、滞在期間に起因している可能性がある。詳細には、元のデータセットにはtravel_detailsというカラムがあり、このカラムには滞在期間に関する情報が含まれている。価格の幅が広いのは、何人かのユーザーが長期にわたって家を借りたことを示している可能性がある。Pythonを使ってより深く分析すれば、それに関するより多くの洞察を明らかにすることができるだろう!
ステップ6:相関マトリックスによるさらなる調査
Pythonのデータ分析とは、手持ちのデータの中で質問を投げかけ、答えを探すことです。これらの質問を喚起する効果的な方法の1つは、相関行列を可視化することです。
相関行列は、さまざまな変数の相関係数を示す表である。最も使用される相関係数は,ピアソン相関係数(Pearson Correlation Coefficient:PCC)で,これは2つの変数の間の線形相関を測定する.その値は,-1 から +1 までの範囲である.
- +1:ある変数の値が増加すると、他の変数も直線的に増加する。
- -1 : ある変数の値が増加すると、もう一方の変数の値は直線的に減少する。
- 0: 2つの変数の線形関係については何も言えない(非線形分析が必要)。
統計学では、線形相関の値は次のように定義される:
- 0.1~0.5:相関が低い。
- 0.6-1:高い相関。
- 0:相関なし。
データ・データ・フレームの相関行列を表示するには、次のようにタイプする:
# Set the images dimensions
plt.figure(figsize=(12, 10))
# Labeling
plt.title('CORRELATION MATRIX', fontsize=20)
plt.xticks(fontsize=16) # x-axis font size
plt.yticks(fontsize=16) # y-axis font size
# Applying mask
mask = np.triu(np.ones_like(numeric_data.corr()))
dataplot = sns.heatmap(numeric_data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})
#Add this code before creating the correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix
dataplot = sns.heatmap(data.corr(), annot=True, fmt='.2f', mask=mask, annot_kws={"size": 12})上記のスニペットは次のようなものである:
np.triu()メソッドは、行列を対角化するために使用される。これは、行列を正方形ではなく三角形として表示し、より見やすくするために使用されます。sns.heatmap()メソッドはヒートマップを作成します。これは、よりよい視覚化のためにも使用されます。その中で、data.corr()メソッドは、データフレームデータの各列のピアソン係数を実際に計算するものです。
以下はその結果である:

相関行列を解釈するときの主な考え方は、相関の高い変数を見つけることである。例えば
緯度と経度の変数には-0.98の相関がある。緯度と経度は地球上の特定の場所を定義するときに強い相関があるので、これは予想されることである。host_rating変数とlong変数の相関は-0.69である。これは興味深い結果で、ホストの評価が経度変数と高い相関があることを意味します。つまり、世界のある地域にある家は、ホストの評価が高いようです。緯度変数と経度変数の価格との相関は、それぞれ0.63と-0.69である。これは、1日あたりの価格が場所の影響を強く受けていることを示すのに十分である。
分析では、相関のない変数も検索する必要があります。例えば、変数is_supperhostと priceの係数は-0.18であり、これはスーパーホストが最も高い価格を持っていないことを意味します。
主なコンセプトが明らかになったところで、次はデータを探索し、分析する番だ!
ステップ7:すべてをまとめる
これがPythonによるデータ分析のための最終的なJupyter Notebookの姿です:









異なるセルが存在し、それぞれに出力があることに注目してほしい。
Pythonによるデータ分析のプロセス
上記のセクションでは、Pythonを使ったデータ分析のプロセスをご案内しました。機会によって段階的なアプローチに見えたかもしれませんが、実際には以下のベストプラクティスに基づいて構築されています:
- データ検索:必要なデータがデータベースにある場合はラッキーだ!そうでない場合は、ウェブスクレイピングの ような一般的なデータソーシング手法を使ってデータを取得する必要がある。
- データのクリーニング:
NaNの処理、データの 集約、初期データセットの最初のフィルターの適用。 - データ探索データ探索はデータ発見とも呼ばれ、Pythonを使ったデータ分析で最も重要な部分です。データがどのような構造になっているのか、あるいは特定のパターンに従っているのかを理解するために、基本的なプロットを作成する必要があります。
- データの操作:分析するデータの背後にある主要なアイデアをつかんだら、それを操作しなければならない。このパートでは、データセットをフィルタリングし、しばしば2つ以上のデータセットを1つにまとめる必要がある(SQLでテーブルの結合を行うように)。
- データの視覚化:これは最後のパートで、操作したデータセットに複数のプロットを作成し、データを視覚的に表示する。
結論
Pythonによるデータ分析に関するこのガイドでは、データ分析にPythonを使うべき理由と、そのために使える一般的なライブラリについて学びました。また、ステップバイステップのチュートリアルを経て、Pythonでデータ分析を行いたい場合に従うべきプロセスを学びました。
Jupyter Notebookは、データのサブセットを作成し、それらを視覚化し、強力な洞察を発見するのに役立つことはお分かりいただけたと思います。すべて同じ環境で構造化されたものを維持しながら。では、すぐに使えるデータセットはどこにあるのでしょうか?Bright Dataにお任せください!
Bright Dataは、多くのフォーチュン500企業や20,000以上の顧客に利用されている、大規模で高速、信頼性の高いプロキシネットワークを運営しています。このネットワークは、ウェブから倫理的にデータを取得し、広大なデータセット市場で提供するために使用されます:
- ビジネスデータセット:LinkedIn、CrunchBase、Owler、Indeedなどの主要ソースからのデータ。
- Eコマースのデータセット:Amazon、Walmart、Target、Zara、Zalando、Asosなどのデータ。
- 不動産データセット:Zillow、MLSなどのウェブサイトからのデータ。
- ソーシャルメディアのデータセット:Facebook、Instagram、YouTube、Redditのデータ。
- 金融データセット:Yahoo Finance、Market Watch、Investopediaなどのデータ。
今すぐBright Dataの無料アカウントを作成し、データセットをご覧ください。






