

この記事では、以下をご覧いただきたい:
- Agnoとは何か、AIエージェントフレームワークとして何が特別なのか。
- データ検索ツールと統合することで、AIエージェントが格段に強力になる理由。
- AgnoとBright Dataツールを組み合わせて、ライブデータ検索が可能なエージェントを構築する方法。
さあ、飛び込もう!
アグノとは?
Agnoは、軽量のAIエージェントやマルチエージェントシステムを構築するためのオープンソースのPythonフレームワークです。メモリ、知識統合、高度な推論などのサポートが組み込まれています。
アグノの特徴は次のような点にある:
- モデルにとらわれない:23以上のLLMプロバイダーに統一されたインターフェースを提供。
- 高いパフォーマンス:エージェントは約3マイクロ秒でインスタンス化され、平均してわずか6.5KiBのメモリを使用します。
- 一流の市民としての推論:エージェントの信頼性を向上させ、困難なタスクを処理するために推論を重視します。推論モデル、推論ツール、カスタム思考連鎖パイプラインの3つの推論アプローチをサポートします。
- ネイティブのマルチモダリティ:エージェントは、テキスト、画像、音声、ビデオをすぐに処理し、生成することができます。
- マルチエージェントシナリオのサポート:共有メモリ、コンテキスト、協調推論を持つエージェントの協調チームを構築します。
- 組み込みのエージェント検索:エージェントは、最先端のエージェント型RAGワークフローのために、20以上のベクターデータベースを実行時に検索することができます。
- 統合メモリとセッションストレージ:エージェントはストレージとメモリドライバを内蔵しており、長期メモリと永続的なセッショントラッキングを提供します。
- 構造化された出力:完全に型付けされた応答を返す。
その上、Agnoは50以上のサードパーティのAIツールプロバイダをビルトインサポートしています。これは、Agnoで構築されたAIエージェントは、市場で最も優れたAIソリューションと簡単に統合できることを意味します。
AIエージェントは正確で効果的であるためにウェブデータにアクセスする必要がある
すべてのAIエージェントフレームワークは、そのベースとなるLLMから重要な制限を受け継いでいる。ほとんどのLLMは静的なデータセットで事前に訓練されているため、リアルタイムの認識に欠け、ライブのウェブコンテンツに確実にアクセスすることができません。
これはしばしば時代遅れの回答や幻覚にさえつながる。この制限を克服するために、エージェント(そして、そのエージェントが依存するLLM)は、信頼できるウェブデータにアクセスする必要がある。なぜウェブデータなのか?ウェブは最も包括的な情報源だからだ。
したがって、それを達成する効果的な方法は、Agnoエージェントにライブ検索クエリを実行し、あらゆるウェブページからコンテンツをスクレイピングする能力を与えることです。それは、Agnoのブライトデータツールによって可能です!
これらのツールはAgnoにネイティブに統合されており、エージェントにAI対応の大規模なウェブデータツール群へのアクセスを提供します。機能には、ウェブスクレイピング、SERPデータ検索、スクリーンショット機能、40以上の有名サイトからのJSON形式のデータフィードへのアクセスが含まれます。
ブライトデータスクレイピングツールをAgnoエージェントに統合する方法
このセクションでは、Bright Dataツールに接続できるPython AIエージェントを構築するためにAgnoを使用する方法を学びます。これらにより、エージェントはあらゆるページからデータをスクレイピングし、最新の検索エンジン結果を取得することができます。
以下の手順に従って、AgnoでBright Dataを活用したAIエージェントを構築してください!
前提条件
このチュートリアルに従うには、以下のものを用意してください:
- Python 3.7以上をローカルにインストール(最新版を推奨)。
- Bright Data APIキー。
- サポートされているLLMプロバイダーのAPIキー(ここではOpenAIを使用しますが、サポートされているプロバイダーであれば何でもかまいません)。
Bright Data APIキーをまだお持ちでない方も、次のステップで作成方法をご案内しますのでご安心ください。
ステップ1:プロジェクトのセットアップ
ターミナルを開き、Bright Dataを利用したデータ検索でAgno AIエージェント用の新しいフォルダを作成します:
mkdir agno-bright-data-agentagno-bright-data-agentフォルダには、AIエージェントのすべてのPythonコードが格納されます。
次に、プロジェクトフォルダーに移動し、その中に仮想環境を作成する:
cd agno-bright-data-agent
python -m venv venvプロジェクトフォルダをお好みのPython IDEで開きます。Visual Studio Code(Python拡張機能付き)か PyCharm Community Editionをお勧めします。
プロジェクトフォルダ内にagent.pyという新しいファイルを作成します。プロジェクトの構造は以下のようになります:
agno-bright-data-agent/
├── venv/
└── agent.pyターミナルで仮想環境をアクティブにする。LinuxまたはmacOSでは、以下のコマンドを実行する:
source venv/bin/activate同様に、Windowsでは、起動します:
venv/Scripts/activate次のステップでは、必要な依存関係をインストールする手順を説明します。今すぐすべてをインストールしたい場合は、起動した仮想環境で以下のコマンドを実行してください:
pip install agno python-dotenv openai requests 注:このチュートリアルではLLMプロバイダーとしてOpenAIを使用しているため、openaiをインストールしています。もし別のLLMを使うつもりなら、代わりにそのプロバイダーに適したライブラリをインストールしてください。
これで準備完了です!これで、AgnoとBright Dataツールを使ってAIエージェントを構築するためのPython開発環境が整いました。
ステップ2:環境変数の設定 読み込み
Agnoエージェントは、OpenAIやBright DataのようなサードパーティサービスとAPI統合を介してやり取りします。それを安全に行うために、APIキーをPythonコードに直接ハードコードすべきではありません。代わりに、環境変数として保存してください。
環境変数のロードを簡単にするには、python-dotenvライブラリを利用します。仮想環境を有効にした状態で、python-dotenv を実行してインストールします:
pip install python-dotenv次に、agent.pyファイルでライブラリをインポートし、load_dotenv() を使用して環境変数をロードします:
from dotenv import load_dotenv
load_dotenv()この関数を使うと、スクリプトがローカルの.envファイルから変数を読み込めるようになります。プロジェクトフォルダーのルートに.envファイルを作成してください:
agno-bright-data-agent/
├── venv/
├── .env # <-------------
└── agent.py素晴らしい!これで、環境変数を使ってサードパーティーの統合秘密を安全に管理する準備が整った。
ステップ3:ブライト・データを使い始める
この記事を書いている時点では、Agnoと統合されたBright Dataのツールがこれらのソリューションへのアクセスを提供している:
- SERP API:主要な検索エンジンの検索結果をリアルタイムで提供するAPI。
- Web Unlocker API:高度なスクレイピングAPIで、高度なボット保護を回避し、あらゆるウェブページにアクセスできます(AI利用に最適化されたMarkdown形式)。
- ウェブスクレーパーAPI:いくつかの一般的なドメインから新鮮で構造化されたウェブデータを倫理的に抽出するための専用のスクレイピングエンドポイント。
上記のツールを統合するには、以下のことが必要だ:
- Bright DataアカウントでSERP APIとWeb Unlockerソリューションを設定します。
- Bright Data API トークンを取得して、これらのサービスにアクセスしてください。
以下の指示に従って、両方を行う!
まず、Bright Dataのアカウントをお持ちでない場合は、アカウントを作成することから始めてください。すでにお持ちの場合は、ログインしてダッシュボードを開いてください:
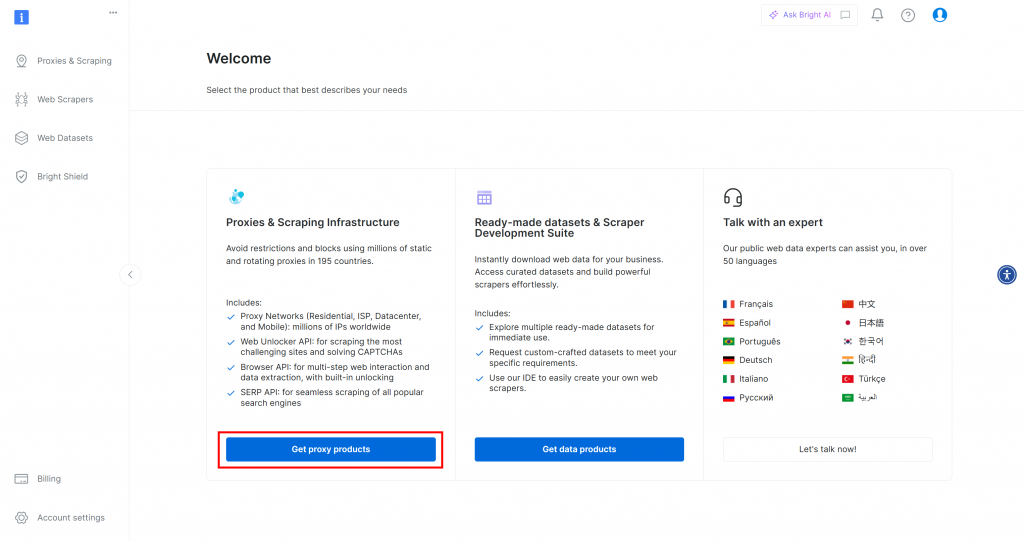
プロキシ製品を入手する “ボタンをクリックすると、”プロキシ&スクレイピング・インフラストラクチャ “ページに移動します:
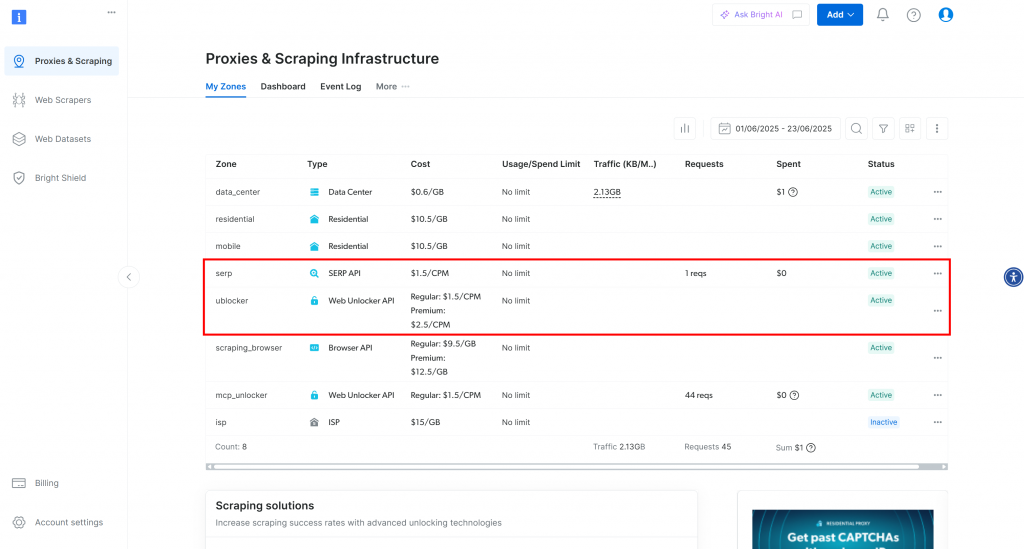
この場合、SERP APIとWeb Unlocker APIの両方がすでに有効化され、使用可能な状態になっていることがわかる。ゾーン名はそれぞれserpと unblockerです。
そうでない場合は、設定する必要があります。ここではWeb Unlocker APIゾーンの作成方法を説明しますが、SERP APIゾーンの作成方法も同様です。
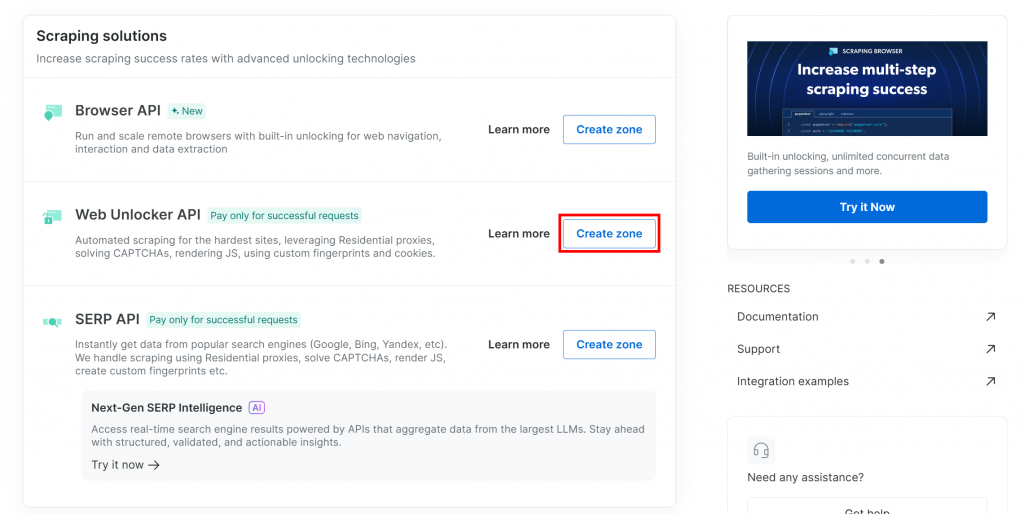
下にスクロールし、「Web Unlocker API」カードの「Create zone」をクリックします:
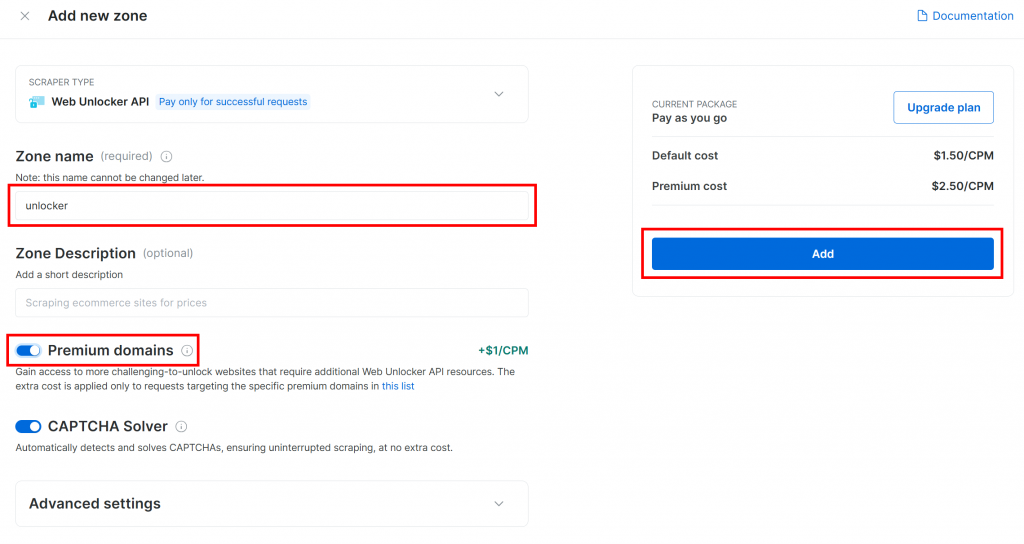
ゾーンに名前(アンロッカーなど)をつけ、最大の効果を得るために高度な機能を有効にし、「追加」を押します:
ゾーンページにリダイレクトされます:
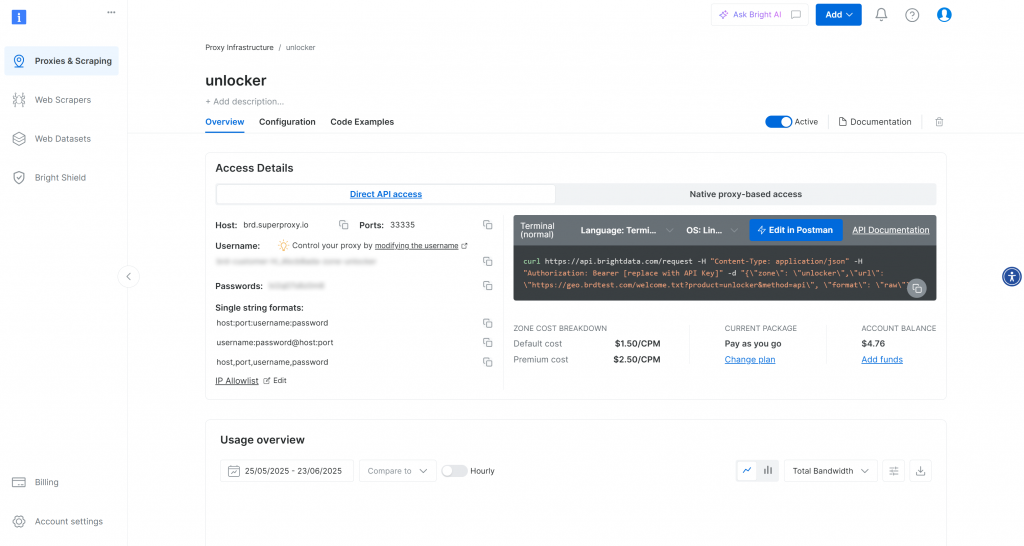
有効化トグルが「有効」に設定されていることを確認してください。これは、ゾーンが正しく設定され、使用する準備ができていることを意味します。
次に、Bright Dataの公式ガイドに従ってAPIキーを生成します。取得したら、.envファイルに以下のように追加します:
BRIGHT_DATA_API_KEY="<YOUR_BRIGHT_DATA_API_KEY>"プレースホルダを プレースホルダを実際のAPIキー値に置き換える。
素晴らしいBright DataツールをAgnoエージェントスクリプトに統合する時が来ました。
ステップ#4: Agno Bright データツールのインストールと設定
プロジェクトフォルダで、仮想環境をアクティブにした状態で、Agnoをインストールしてください:
pip install agno注:agnoパッケージには、Bright Dataツールのビルトインサポートがすでに含まれているため、このセットアップには統合専用のパッケージは必要ありません。
Bright DataツールはPythonrequestsライブラリに依存しているため、Pythonrequestsライブラリもインストールしてください:
pip install requestsagent.pyファイルで、AgnoのBright Dataツールをインポートします:
from agno.tools.brightdata import BrightDataToolsそして、このようにツールを初期化する:
bright_data_tools = BrightDataTools(
serp_zone="YOUR_SERP_ZONE_NAME",
web_unlocker_zone="YOUR_UNLOCKER_ZONE_NAME"
)YOUR_SERP_ZONE_NAME "と “YOUR_UNLOCKER_ZONE_NAME "を先ほど設定したBright Dataゾーンの名前に置き換えてください。例えば、ゾーンの名前がserpと unlockerの場合、コードは次のようになります:
bright_data_tools = BrightDataTools(
serp_zone="serp",
web_unlocker_zone="unlocker"
)コード内でゾーン名を直接渡すのを省略することもできる。その代わりに、.envファイルで以下の環境変数を使用してください:
BRIGHT_DATA_WEB_UNLOCKER_ZONE="<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE>"
BRIGHT_DATA_SERP_ZONE="<YOUR_BRIGHT_DATA_SERP_ZONE>"プレースホルダを Bright Data ゾーンの実際の名前に置き換えます。次に、BrightDataTools のserp_zoneとweb_unlocker_zone引数を削除します、
注意: Bright Dataソリューションに接続するために、BrightDataToolsは BRIGHT_DATA_API_KEY環境変数に依存します。具体的には、BRIGHT_DATA_API_KEY環境変数に Bright Data API キーが含まれていることを期待します。これが、前のステップで.envファイルに追加した理由です。
驚いたよ!次の統合はLLMとの統合だ。
ステップ5:LLMモデルのセットアップ
このチュートリアルで使用するLLMプロバイダーであるOpenAIに接続するには、必要なopenai依存関係をインストールすることから始めます:
pip install openaiそして、AgnoからOpenAI統合クラスをインポートします:
from agno.models.openai import OpenAIChatLLMモデルを以下のように初期化します:
llm_model = OpenAIChat(id="gpt-4o-mini")上記で、"gpt-4o-mini "はこのガイドで使用しているOpenAIのモデル名です。必要に応じて、他のサポートされているOpenAIのモデルに変更することができます。
裏では、OpenAIChat は OpenAI API キーがOPENAI_API_KEY という環境変数に定義されていることを期待しています。これを設定するには、.envファイルに以下の行を追加します:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"プレースホルダを プレースホルダを実際のOpenAI API キーに置き換えてください。
注:Agnoがサポートする別のLLMに接続したい場合は、公式ドキュメントを参照してください。
よくできました!これで、ウェブデータ検索機能を持つAgnoエージェントを構築するためのすべての構成要素が揃いました。
ステップ6:エージェントの作成
agent.pyファイルでエージェントを定義します:
agent = Agent(
tools=[bright_data_tools],
show_tool_calls=True,
model=llm_model,
)これは、ユーザー入力を処理するために設定されたLLMモデルを使用し、データ検索のためにBright DataツールにアクセスできるAgnoエージェントを作成します。show_tool_calls=Trueオプションは、エージェントがリクエストを処理するために使用しているツールを表示するので、何が起こっているかを理解するのに役立ちます。
AgnoからAgentクラスをインポートすることを忘れないでください:
from agno.agent import Agent素晴らしい!Agno + Bright Dataの統合は完了です。あとは、エージェントにクエリーを送り、その動きを見るだけです。
ステップ#7: ブライトデータツールによるエージェントへの問い合わせ
次の2行のコードを使って、Agno AIエージェントと対話することができます:
prompt = "Search for AAPL news"
agent.print_response(prompt, markdown=True)最初の行は、エージェントに処理させたいタスクや質問を記述するプロンプトを定義します。2行目は、それを実行し、その出力を表示します。
markdown=Trueオプションは、レスポンスがMarkdownでフォーマットされることを保証します。
注:好きなプロンプトを試すことができるが、「AAPLニュースを検索」はSERPデータ検索機能をテストするのに最適な出発点である。
ステップ8:すべてをまとめる
これがagent.pyファイルの最後のコードになります:
from dotenv import load_dotenv
from agno.tools.brightdata import BrightDataTools
from agno.models.openai import OpenAIChat
from agno.agent import Agent
# Load the environment variables from the .env file
load_dotenv()
# Configure the Bright Data tools for Agno integration
bright_data_tools = BrightDataTools(
serp_zone="serp", # Replace with your SERP API zone name
web_unlocker_zone="unlocker" # Replace with your Web Unlocker API zone name
)
# The LLM that will be used by the AI agent
llm_model = OpenAIChat(id="gpt-4o-mini")
# The definition of your Agno agent, with Bright Data tools
agent = Agent(
tools=[bright_data_tools],
show_tool_calls=True, # Useful for understanding what happens behind the scenes
model=llm_model,
)
# Run a task in the AI agent
prompt = "Search for AAPL news"
agent.print_response(prompt, markdown=True)30行以下のコードで、あらゆるウェブページからデータをスクレイピングし、主要な検索エンジンでリアルタイム検索を実行できるAIエージェントを構築することができます。これが、AIエージェントを構築するためのフルスタックフレームワークとしてのAgnoの力です!
ステップ #9: Agnoエージェントの実行
AgnoのAIエージェントを実際に動かしてみましょう。ターミナルで
python agent.pyエージェントが “Search for AAPL news “プロンプトを処理していることを示すアニメーション出力がターミナルに表示されます。完了すると、エージェントはこのような結果を出力します:
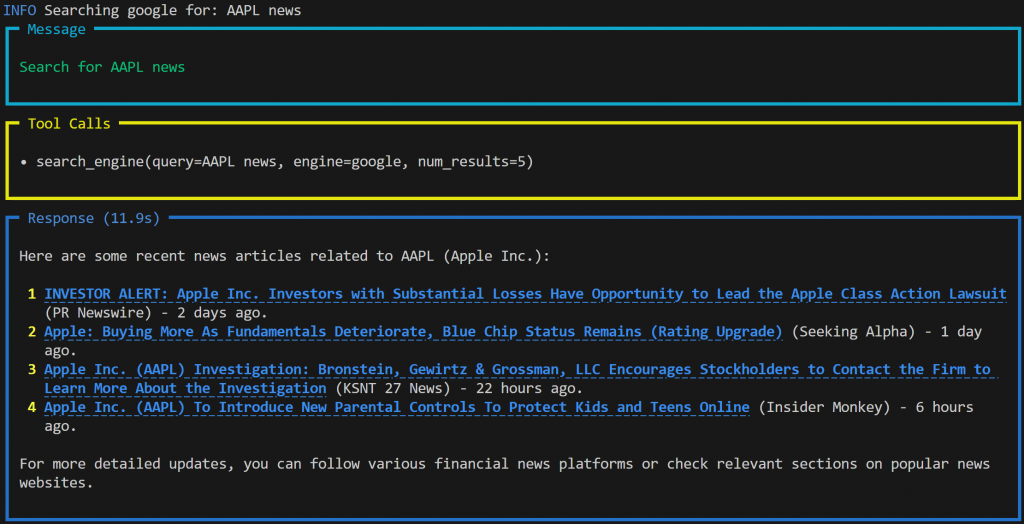
出力は以下の通り:
- 送信したプロンプト
- エージェントがタスクを完了するために使用したツール。このケースでは、Bright Dataツールの
search_engine()関数を使用して、SERP API経由でGoogleにアクセスし、AAPL株に関するリアルタイムのニュースを取得した。 - 取得したデータに基づいてOpenAIのモデルによって生成されたMarkdown形式のレスポンス。
注:この結果には、Markdownフォーマットのおかげで、クリック可能なリンク付きのライブ・ニュース・コンテンツが含まれている。また、プロンプトを実行するわずか数時間前に発表された、非常に新鮮なニュースもあります。
さて、もう一歩進めてみよう。検索されたニュース記事の要約が欲しいとしよう。プロンプトを更新するだけでいい:
prompt = """
Give me a summary of the following news in around 150 words.
NEWS URL:
https://www.msn.com/en-us/money/other/apple-inc-aapl-to-introduce-new-parental-controls-to-protect-kids-and-teens-online/ar-AA1HdVd6
"""
agent.print_response(prompt, markdown=True)今回の出力は次のようになる:
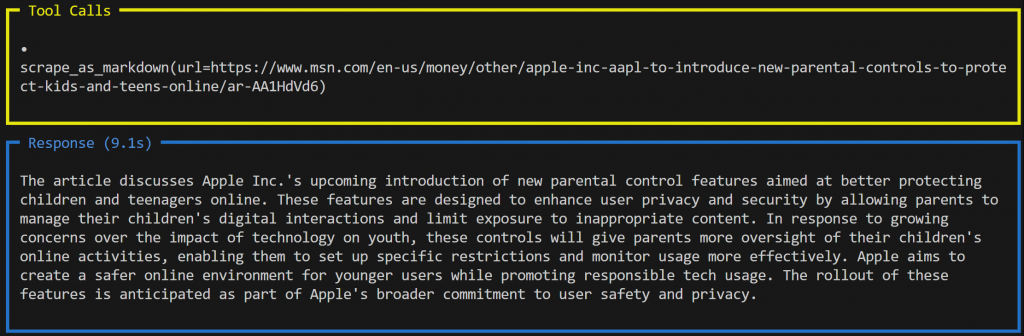
この場合、エージェントは別のツールを使用した:Web Unlocker APIに接続するscrape_as_markdown()である。このツールはウェブページの内容をMarkdownフォーマットで取得し、要約のためにLLMに渡す。
出来上がりです!ブライトデータツールとAgnoを利用したAIエージェントで、シームレスなデータ検索と処理が可能になります。
次のステップ
このチュートリアルでAgnoを使って構築したAIエージェントは、出発点に過ぎません。詳細には、可能なことの表面を引っ掻いただけです。あなたのプロジェクトをさらに進めるために、次のステップを検討してください:
- ナレッジストアの追加ブライトデータツールを使用してウェブデータを取得し、Agnoの内蔵ベクターデータベースに保存することで、エージェントを改善します。これにより、長期記憶を可能にし、エージェントのRAGをサポートします。
- エージェントの記憶と推論を有効にします:エージェントに記憶と多段階推論を装備することで、学習、反映、情報に基づいた意思決定ができるようになります。これにより、人気のあるReAct(Reasoning + Acting)エージェントアーキテクチャのような高度なパターンを実装することができます。
- シンプルな対話のためのUIを構築します:ユーザーインターフェースを追加してChatGPTのような体験を提供し、AIエージェントとのより自然な会話の扉を開きます。
より多くのアイデアや高度な統合については、Agnoの公式ドキュメントをご覧ください。
結論
この記事では、Agnoを使用して、Bright Dataツールを使用したリアルタイムのデータ検索機能を持つAIエージェントを構築する方法を学びました。この統合により、エージェントはウェブサイトと検索エンジンの両方から公開ウェブコンテンツにアクセスできるようになります。
ここで見たものは、単純な例に過ぎないことを忘れないでください。より高度なエージェントを構築するのであれば、ライブウェブデータを取得、検証、変換するソリューションが必要です。それこそが、Bright DataのAIインフラストラクチャです。
無料のBright Dataアカウントを作成し、当社のAI対応データツールの実験を開始してください!






