

このガイドでは、以下のことがわかります:
- リサーチエージェントとは何か、なぜ従来の方法では失敗するのか
- 信頼性の高いデータ収集のためのBright Dataの設定方法
- Streamlit UIを使用したローカルAIリサーチエージェントの構築方法
- 構造化された洞察のためにBright Data APIとローカルモデルを統合する方法
インテリジェントなリサーチアシスタントの構築に飛び込んでみましょう。また、データベースのようにウェブを検索できるBright DataのAI搭載検索エンジン、Deep Lookupをチェックすることをお勧めします。
業界の問題
- 研究者は、多くのソースからあまりにも多くの情報に直面しており、手作業によるレビューが現実的ではありません。
- 従来のリサーチでは、検索、抽出、合成に時間がかかり、手作業に頼らざるを得なかった。
- 結果は不完全で、バラバラで、整理されていないことが多い。
- 単純なスクレイピングツールは、信頼性や文脈のない生データを提供する。
解決策リサーチエージェント
ディープリサーチエージェントは、収集から報告までのリサーチを自動化するAIシステムです。コンテキストを処理し、タスクを管理し、構造化された洞察を提供します。
主なコンポーネント
- プランナーエージェント:リサーチをタスクに分割
- リサーチサブエージェント: 検索を実行し、データを抽出します。
- ライターエージェント: 構造化されたレポートを作成します。
- 条件エージェント: 品質をチェックし、必要に応じてより深いリサーチをトリガーします。
このガイドでは、Bright Data の API、Streamlit UI、プライバシーとコントロールのためのローカル LLM を使用して、ローカルリサーチシステムを構築する方法を紹介します。
前提条件
- APIキーを持つBright Dataアカウント
- Python 3.10 以上
- 依存関係
リクエストfaissまたはchromadbpython-dotenvstreamlitollama(ローカルモデル用)
Bright Dataの設定
Bright Dataアカウントの作成
- Bright Dataにサインアップする
- API認証情報セクションに移動する
- APIトークンを生成する
環境変数を使用してAPI認証情報を安全に保存します。.envファイルを作成して認証情報を保存し、機密情報をコードから分離します。
BRIGHT_DATA_API_KEY="your_bright_data_api_token_here"環境のセットアップ
# venvを作成する
python -m venv venv
ソース venv/bin/activate
# 依存関係のインストール
pip install requests openai chromadb python-dotenv streamlit実装
ステップ1:リサーチ
これが我々のリサーチタスクとなる。
query = "ヘルスケアにおけるAIのユースケース"ステップ2:データの取得
このステップでは、Bright DataのData Collection APIを使ってウェブからデータをプログラムで取得する方法を示します。このコードでは、リサーチクエリを送信し、APIクレデンシャルを安全に扱いながら関連するデータを取得します。
import requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit":20}
headers = {"Authorization": f "ベアラ{os.getenv('BRIGHT_DATA_API_KEY')}"}"}。
res = requests.post(url, json=payload, headers=headers)
print(res.json())ステップ 3: 処理と埋め込み
このステップでは、取得したリサーチデータを処理し、意味検索と類似性マッチングを可能にするベクトルデータベースであるChromaDBに格納する。これにより、研究結果から検索可能な知識ベースが作成され、ヘルスケアやその他の研究トピックにおけるAIのユースケースを検索することができます。
インポート chromadb
from chromadb.config import Settings
# ChromaDBの初期化
client = chromadb.PersistentClient(path="./research_db")
コレクション = client.get_or_create_collection("research_data")
# リサーチ結果の保存
def store_research_data(results):
ドキュメント = [].
メタデータ = [].
ids = [].
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'source': item.get('source', '')、
'query': query、
'timestamp': item.get('タイムスタンプ', '')
})
ids.append(f "doc_{i}")
collection.add(
documents=documents、
metadatas=metadatas、
ids=ids
)ステップ4:ローカルモデルの要約
このステップでは、Ollamaを通じてローカルで実行される大規模言語モデル(LLM)を活用し、研究内容の簡潔な要約を生成する方法を示します。このアプローチはデータ処理を非公開にし、オフライン要約機能を可能にします。
インポートサブプロセス
インポート json
def summarize_with_ollama(content, model="llama2"):
"""ローカルのOllamaモデルを使って研究内容を要約する"""
try:
result = subprocess.run(
['ollama', 'run', model, f "この研究内容を要約する:{capture_output=True、
capture_output=True、
text=True、
タイムアウト=120
)
return result.stdout.strip()
except Exception as e:
return f "要約に失敗しました:{str(e)}""要約に失敗しました。
# 使用例
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f "Summary: {summary}")ollama run llama2 "ヘルスケアにおけるAIのユースケースを要約する"ストリームリットUI
最後に、Bright Dataからのデータ収集とOllamaによるローカルのAI要約を組み合わせた完全なウェブUIを作成する。このインターフェースにより、ユーザーは直感的なダッシュボードを通じて、リサーチパラメーターの設定、データ収集の実行、AI要約の生成を行うことができる。
app.pyの作成
stとしてstreamlitをインポート
import requests, os
from dotenv import load_dotenv
インポートサブプロセス
インポート json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="ᔎ")
st.title("ᔎ明るいデータを持つローカル・ディープ・リサーチ・エージェント")
# サイドバーの設定
st.sidebarを使用します:
st.header("設定")
api_key = st.text_input(
"Bright Data API Key"、
type="パスワード"、
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollamaモデル"、
["llama2", "mistral", "codellama"]。
)
research_depth = st.slider("研究の深さ", 5, 50, 20)
# メインリサーチインターフェース
query = st.text_input("研究トピックを入力してください:", "AI use cases in healthcare")
col1, col2 = st.columns(2)
col1:
if st.button("🚀リサーチの実行", type="primary"):
if not api_key:
st.error("ブライトデータのAPIキーを入力してください")
elif not query:
st.error("リサーチトピックを入力してください")
else:
with st.spinner("Collecting research data..."):
# Bright Dataからデータを取得する
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": research_depth}.
headers = {"Authorization": f "ベアラ{api_key}"}。
res = requests.post(url, json=payload, headers=headers)
if res.status_code == 200:
st.success(f "Successfully collected {len(res.json().get('results', []))} sources!")
st.session_state.research_data = res.json()
# 結果を表示する
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f "Source {i+1}:st.expander(f "ソース{i+1}: {item.get('タイトル', 'タイトルなし')}"):
st.write(item.get('content','コンテンツなし'))
else:
st.error(f "データの取得に失敗しました: {res.status_code}")
col2:
if st.button("🤖 Ollamaで要約"):
if 'research_data' in st.session_state:
with st.spinner("Generating AI summaries..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('コンテンツ', '')[:1500]: # コンテンツの長さを制限する。 # コンテンツの長さを制限する
を試す:
result = subprocess.run(
['ollama', 'run', model_choice, f "このコンテンツを要約します:{content}"]、
capture_output=True、
text=True、
タイムアウト=60
)
summary = result.stdout.strip()
st.expander(f "AIサマリー{i+1}")を使用する:
st.write(summary)
except Exception as e:
st.error(f "Summarization failed for source {i+1}:{str(e)}")。
else:
st.warning("データを収集するために最初にリサーチを実行してください")
# 生データがあれば表示する
if 'research_data' in st.session_state:
with st.expander("View Raw Research Data"):
st.json(st.session_state.research_data)アプリケーションを実行します:
streamlit run app.pyアプリケーションを実行し、ポート 8501 にアクセスすると、このような UI になるはずです:
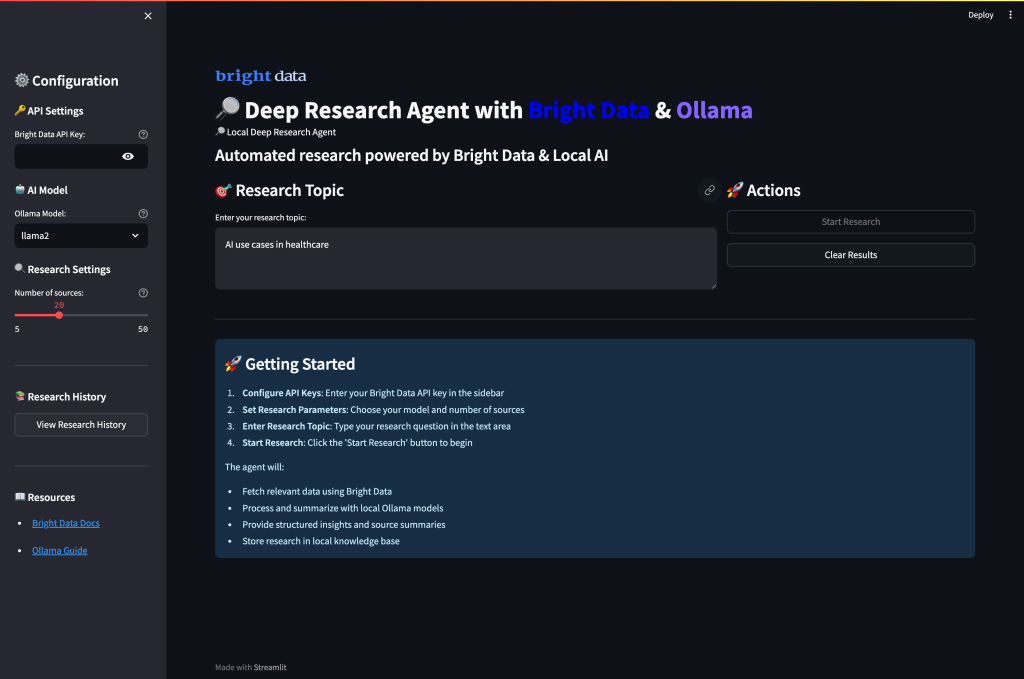
ディープリサーチエージェントの実行
アプリケーションを実行し、AI による包括的な調査を開始します。ターミナルを開き、プロジェクトディレクトリに移動します。
streamlit run app.pyシステムのインテリジェントなマルチエージェントワークフローが、あなたのリサーチリクエストを処理する様子を見ることができます:
- データ収集フェーズ:エージェントは、Bright Dataの信頼性の高いAPIを使用して、多様なウェブソースから包括的なリサーチデータを取得し、関連性と信頼性を自動的にフィルタリングします。
- コンテンツ処理:各ソースはインテリジェントな分析を受け、システムは主要な情報を抽出し、主要なテーマを特定し、意味理解を用いてコンテンツの品質を評価します。
- AI要約:ローカルのOllamaモデルが収集されたデータを処理し、重要な洞察を保持しながら簡潔な要約を生成し、すべてのソースにわたって文脈の正確性を維持します。
- 知識の統合:複数のソースにまたがる情報を同時に分析することで、繰り返し発生するパターンを特定し、関連する概念を結びつけ、新たな傾向を検出します。
- 構造化された報告:最後に、エージェントはすべての調査結果を、適切な構成、明確な引用、専門的な書式を備えた包括的な調査レポートにまとめ、重要な発見や洞察を強調します。
強化されたリサーチパイプライン
より高度なリサーチ機能については、実装を拡張してください。
この強化されたパイプラインは、単純な要約にとどまらず、収集したリサーチデータから構造化された分析、重要な洞察、実用的な発見を提供する完全なリサーチワークフローを作成します。このパイプラインは、情報収集のための Bright Data と、インテリジェントな分析のためのローカル Ollama モデルを統合します。
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""データ収集とAIのための分析を含む完全なリサーチパイプライン"""
# ステップ1: Bright Dataからデータを取得する
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit":20}
headers = {"Authorization": f "ベアラ{api_key}"}。
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200:
return {"error":「データ収集に失敗しました。}
research_data = response.json()
# ステップ2: Ollamaを使った処理と分析
insights = [].
for item in research_data.get('results', []):
content = item.get('content', '')
# 各ソースに対してインサイトを生成する
analysis_prompt = f""
このコンテンツを分析し、重要な洞察を提供します:
{コンテント[:2000]}」。
焦点を当てる
- 要点と発見
- 主要データと統計
- 潜在的なアプリケーション
- 言及された限界
"""
を試す:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt]、
capture_output=True、
text=True、
タイムアウト=90
)
insights.append({
'source': item.get('source', '')、
'analysis': result.stdout.strip()、
'title': item.get('title', '')
})
except Exception as e:
insights.append({
'source': item.get('source', '')、
'analysis': f "解析に失敗しました:{'タイトル': item.get('title')、
'title': item.get('title', '')
})
return {
'research_data': research_data、
'ai_insights': insights、
'query': クエリ
}まとめ
このローカルディープリサーチエージェントは、Bright Dataの信頼性の高いウェブデータ収集とOllamaを使用したローカルAI処理を組み合わせた自動リサーチシステムの構築方法を示している。この実装は以下を提供する:
- プライバシー第一のアプローチ:すべてのAI処理はOllamaを使用してローカルで行われます。
- 信頼性の高いデータ収集:Bright Dataが高品質で構造化されたウェブデータを確保
- ユーザーフレンドリーなインターフェース:Streamlit UIにより、複雑なリサーチにもアクセス可能
- カスタマイズ可能なワークフロー:様々な研究領域や要件に適応可能
このシステムは、データ収集、処理、分析を自動化することで、業界の主要な課題に対応しています。
お客様のリサーチ能力をさらに高めるために、業界に特化したデータのためのBright Dataのデータセットソリューションや、世界最大のウェブデータベースのクエリと検索のためのDeep Lookupのご利用をご検討ください。
独自のリサーチエージェントを構築する準備はできましたか?無料のブライトデータアカウントを作成して、信頼性の高いウェブデータ収集を始めましょう。






