

このブログ記事では、以下の内容をご紹介します:
- AutoGPTとは何か、そしてAIエージェント構築フレームワークとして何が特別なのか。
- AutoGPTエージェントが、ウェブ検索、探索、対話、データスクレイピング機能を利用することでどのようなメリットを得られるか。
- Bright DataをAutoGPTに統合し、AIエージェントにこれらの機能を正確に提供する方法。
さっそく見ていきましょう!
AutoGPTとは
AutoGPTは、自律型AIエージェントを構築、デプロイ、実行するためのオープンソースプラットフォームです。
その特徴は、ローコードでブロックベースのインターフェース、エージェントの継続的な実行、そしてツール、API、データソースをエンドツーエンドの自動化パイプラインに接続できる点にあります。
単純なスクリプトとは異なり、AutoGPTエージェントは持続的に実行され、トリガーに反応し、多段階のタスクを管理することができます。このプロジェクトは、大規模なオープンソースコミュニティによって支えられています。GitHubでは18万3千以上のスターを獲得し、目覚ましい人気を博しています。
こうした実績から、AutoGPTは現在最も人気のあるAIエージェントフレームワークの一つとなっています。
なぜWeb探索とデータ取得機能をAutoGPTに統合するのか
AutoGPTが機能豊富なソリューションであることは疑いようがありません。しかし、LLM(大規模言語モデル)ベースのAIエージェントにはすべて、固有の限界があります。標準的な言語モデルは静的なデータセットで学習されるため、その知識は特定の時点でのものに固定されています。
そのため、エージェントが最新のデータを必要とする現実世界のタスクを実行しようとすると、情報が古くなっていたり、誤った情報を生成したり、知識に欠落が生じたりする可能性があります。さらに、LLMはウェブを含む現実世界と対話することができません。したがって、基本的なAIエージェントは、こうした固有の制限に縛られています。
AutoGPTには、ウェブ検索、探索、その他のインタラクションのためのネイティブツールが含まれています。しかし、これらの組み込み機能は、エンタープライズグレードのソリューションと比較すると、スケーラビリティ、信頼性、および高度なボット対策において課題を抱えている可能性があります。
そこでBright Dataの出番となります。世界最大級のプロキシネットワーク(195カ国にまたがる1億5,000万以上のIPアドレス)を基盤とするそのインフラは、99.99%の稼働率と無制限の同時接続を実現します。
AutoGPTにBright Dataを統合することで、エージェントはあらゆるウェブサイトのライブコンテンツ、検索結果、構造化データにアクセスできるようになります。具体的には、AutoGPTのワークフローを強化できる主なBright Data製品には以下が含まれます:
- Web Unlocker API:CAPTCHAやボット対策機能を回避し、あらゆるウェブサイトのコンテンツを生のHTMLまたはMarkdown形式で取得します。
- SERP API:Google、Bing、Yandex、その他多数の検索エンジンから検索結果を収集します。
- Web スクレイパー API:Amazon、LinkedIn、Instagram、Yahoo Financeなどのプラットフォームから構造化データを抽出します。
- Crawl API:ウェブサイト全体を構造化データセットに変換し、下流のAI処理に活用します。
AutoGPTのエージェント機能とBright Dataのソリューションを組み合わせることで、AIエージェントはリアルタイムの情報を自律的に取得し、標準的なLLMの限界をはるかに超えた複雑なワークフローを実行できるようになります。
AutoGPTへのBright Dataの統合方法:ステップバイステップガイド
このガイドセクションでは、Webデータ取得のためにBright Dataと連携するAutoGPT用AIエージェントの構築方法を学びます。
具体的には、このエージェントはブックマークアシスタントとして機能し、オンライン記事が後で読む価値があるかどうかを判断する手助けをします。これは統合を紹介するための単純な例に過ぎませんが、他にも多くのユースケースが考えられます。
以下の手順に従ってください!
前提条件
AutoGPTをセルフホストするには、お使いのシステムが以下のハードウェア要件を満たしていることを確認してください:
- オペレーティングシステム:Linux(Ubuntu 20.04以降推奨)、macOS(10.15以降)、またはWSL2を搭載したWindows 10/11。
- CPU:4コア以上推奨。
- RAM:最低8 GB(16 GB推奨)。
- ストレージ:10 GB以上の空き容量。
また、お使いのマシンに以下のツールがローカルにインストールされている必要があります:
- Docker Engine 20.10.0 以降
- Docker Compose 2.0.0 以上
- Git 2.30 以降
- Node.js 16.x 以上(npm 8.x 以上を含む)
- Visual Studio Code 1.60 以降、またはその他の最新のコードエディタ
さらに、以下のネットワーク要件が満たされていることを確認してください:
- 安定したインターネット接続。
- 必要なポートへのアクセス(Docker 経由で設定されます)。
- HTTPS による外部への接続が可能であること。
AutoGPTでAIエージェントを実装するには、以下も必要です:
- Web Unlocker APIゾーンが設定され、APIキーが構成されたBright Dataアカウント。
- AutoGPTがサポートするLLMプロバイダーのいずれかからのAPIキー(この例ではOpenAIを使用します)。
Bright Dataアカウントの設定については、専用の章で手順を案内しますので、現時点では心配する必要はありません。
ステップ #1: AutoGPTをローカルにインストールする
お使いのシステムがハードウェア、ソフトウェア、ネットワークの前提条件を満たしていることを確認してください。また、Dockerが起動して動作していることも確認してください。
AutoGPTをセルフホスティングするためのセットアッププロセスを簡略化するには、公式のワンラインインストールスクリプトを使用することをお勧めします。これにより、必要な依存関係がすべてインストールされ、最新のコードが取得され、アプリケーションが起動します。
macOSまたはLinuxでは、以下のコマンドでワンラインインストールスクリプトを実行してください:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.sh同様に、Windows では PowerShell で次のコマンドを実行します:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"インストールには数分かかる場合がありますので、しばらくお待ちください。完了すると、次のような出力が表示されます: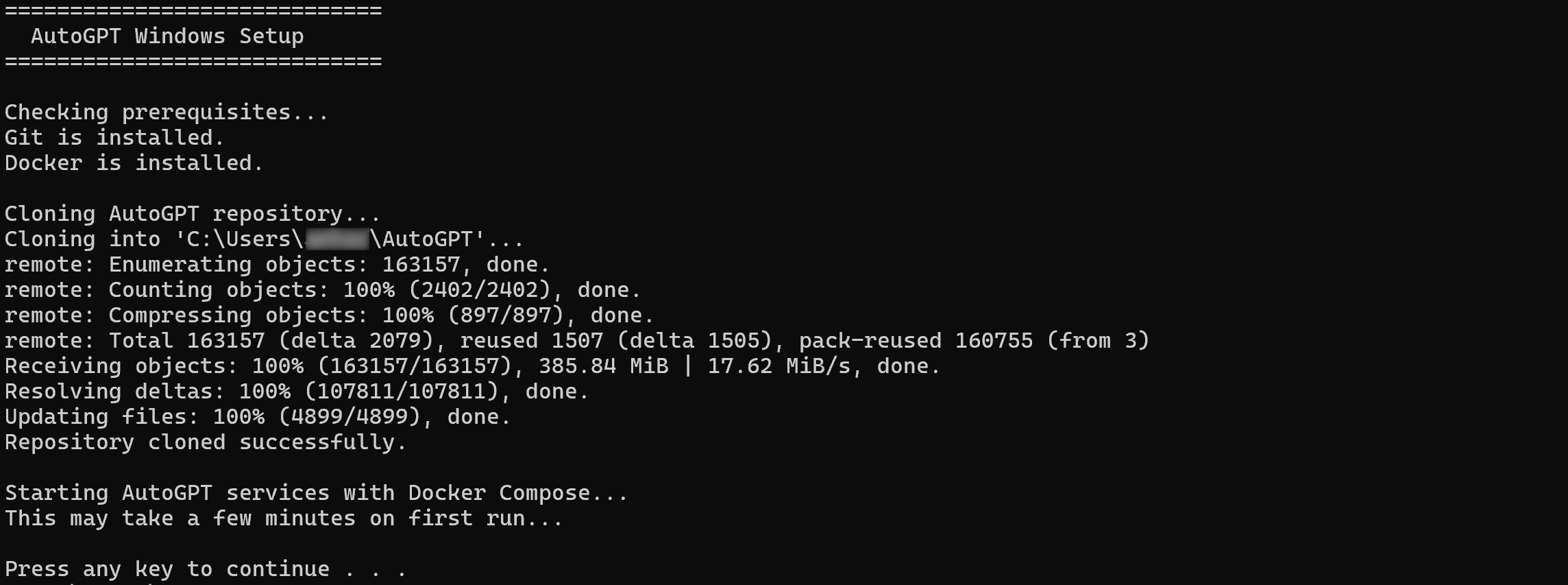
素晴らしい!これで、AutoGPTはローカルに正常にセットアップされ、実行可能な状態になっています。
ステップ #2: プラットフォームを起動する
インストールフォルダに移動します:
cd AutoGPT/autogpt_platform次に、クローンしたリポジトリに含まれる.env.defaultファイルを.env にコピーします:
cp .env.default .envこのコマンドにより、autogpt_platformディレクトリ内にデフォルト設定を使用した.envファイルが作成されます。カスタム設定が必要な場合のみ、このファイルを編集して独自の環境変数を定義してください。それ以外の場合は、デフォルト値のままにしておいてください。
次に、以下のコマンドで AutoGPT プラットフォームを起動します:
docker compose up -d --buildこのコマンドは、docker-compose.ymlファイルで定義されたすべての必要なバックエンドサービスをビルドし、デタッチドモードで起動します。
サービスの起動が完了したら、ブラウザでhttp://localhostにアクセスし、すべてが正常に動作していることを確認してください。
デフォルトでは、各 AutoGPT サービスは以下の URL で利用可能です:
- フロントエンド UI サーバー:
http://localhost - バックエンド WebSocket サーバー:
http://localhost:8001. - 実行 API REST サーバー:
http://localhost:8006.
以下のように表示されるはずです:
アカウントを作成してサインアップしてください。ログイン後、AutoGPTフロントエンドの「Agent Builder」画面に移動します:
よし!これで、最初のエージェントを作成し、Bright Dataに接続する準備が整いました。
ステップ #3: AIエージェントのワークフローを設計する
AutoGPTには、それぞれ特定のアクションやタスクを処理する複数のブロックが用意されています。この例では、次のようなエージェントワークフローを構築します:
- (任意のサイトからの)記事のURLを入力として受け付けます。
- Bright Data Web Unlocker APIを使用して、記事のコンテンツをMarkdown形式で取得する。
- そのコンテンツをLLMに渡して、その記事がブックマークする価値があるかどうかを示す1から10までのスコアと、そのスコアを説明する人間らしいコメントを生成する。
- 構造化された出力を返す。

AutoGPTでは、このワークフローは以下のブロックを使用して実装できます:
- エージェント入力:ユーザーから記事のURLを受け取ります。
- 辞書の作成:指定されたURLを使用して、Bright Data Web Unlocker APIへのリクエスト本文を構築します。
- 認証済みWebリクエストの送信:Bright Data Web Unlocker APIにリクエストを送信し、記事コンテンツを取得します。
- AI構造化応答ジェネレーター:記事コンテンツをLLMに渡して、構造化されたブックマーク評価(スコア+コメント)を生成します。
- エージェント出力:最終的な構造化された結果を返します。
完璧です!エージェント型ワークフローの手順が明確になったので、次はそれを実装します。しかしその前に、まずはBright Dataの設定から始めましょう。
ステップ #4: Bright Data アカウントの設定
前述の通り、実装しようとしているAIエージェントのワークフローは、Bright DataのWeb Unlocker製品に依存しています。AutoGPTでこれと連携するには、Web Unlocker APIゾーンが設定されたBright Dataアカウントと、APIキーが必要です。
手っ取り早い手順については、「Bright DataのWeb Unlocker APIクイックスタートガイド」の記事をご参照ください。あるいは、以下の手順に従ってください。
Bright Dataアカウントをお持ちでない場合は、新規作成してください。すでにアカウントをお持ちの場合は、ログインしてください。コントロールパネルにアクセスし、「Proxies & Scraping」ページに移動します。「My Zones」テーブルを確認してください: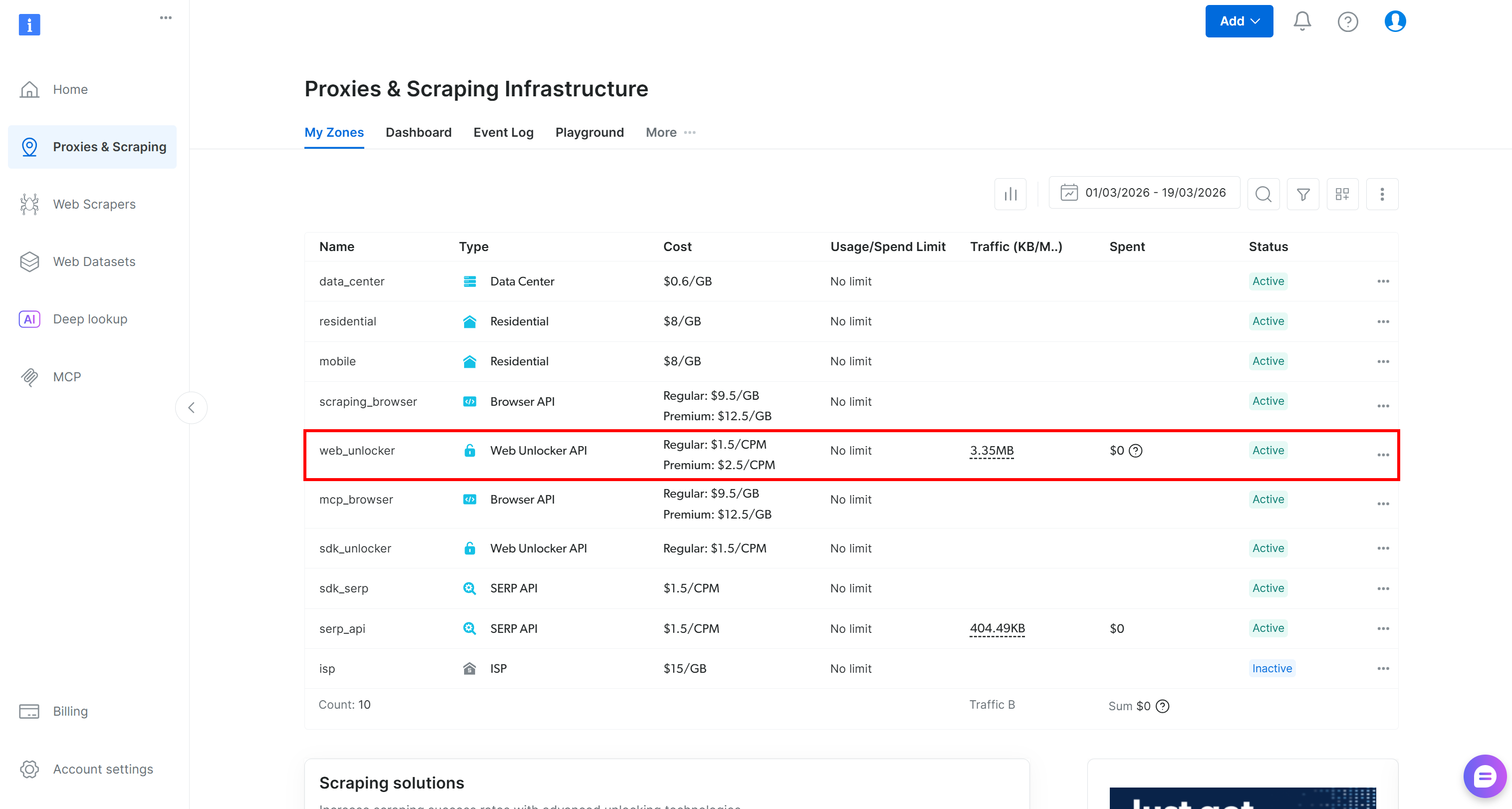
テーブルに Web Unlocker API ゾーン(例:web_unlocker)がすでに存在している場合は、準備完了です。
存在しない場合は、作成する必要があります。「Unblocker API」カードまでスクロールし、「ゾーンを作成」ボタンをクリックして、ウィザードの手順に従ってください。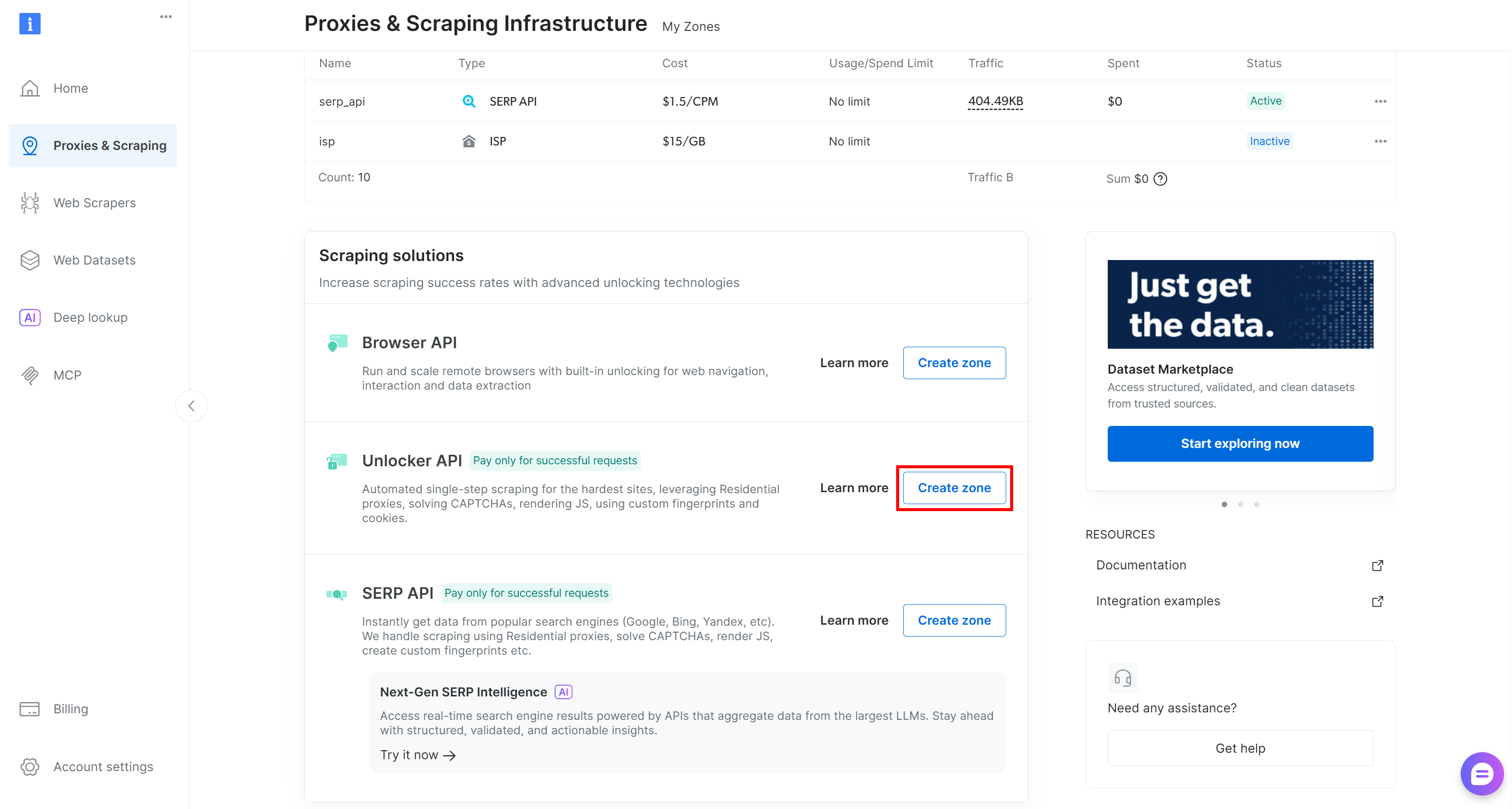
ゾーン名は後で必要になるため、慎重に命名してください。このガイドでは、ゾーン名をweb_unlocker とすることを前提とします。
最後に、Bright Data APIキーを生成し、安全に保管してください。AutoGPTからBright DataへのHTTPリクエストを認証するために必要になります。
これで完了です!Bright Dataに関する前提条件はすべて整いました。
ステップ #5: エージェントの初期化
すべての AutoGPT エージェントワークフローには、入力と出力が必要です。まず、「Build」セクションに移動して、Agent Builder ページにアクセスします:
「Save」ボタンを押して、エージェントに「Bookmark Likelihood Evaluator」のような名前を付け、「Save Agent」をクリックします: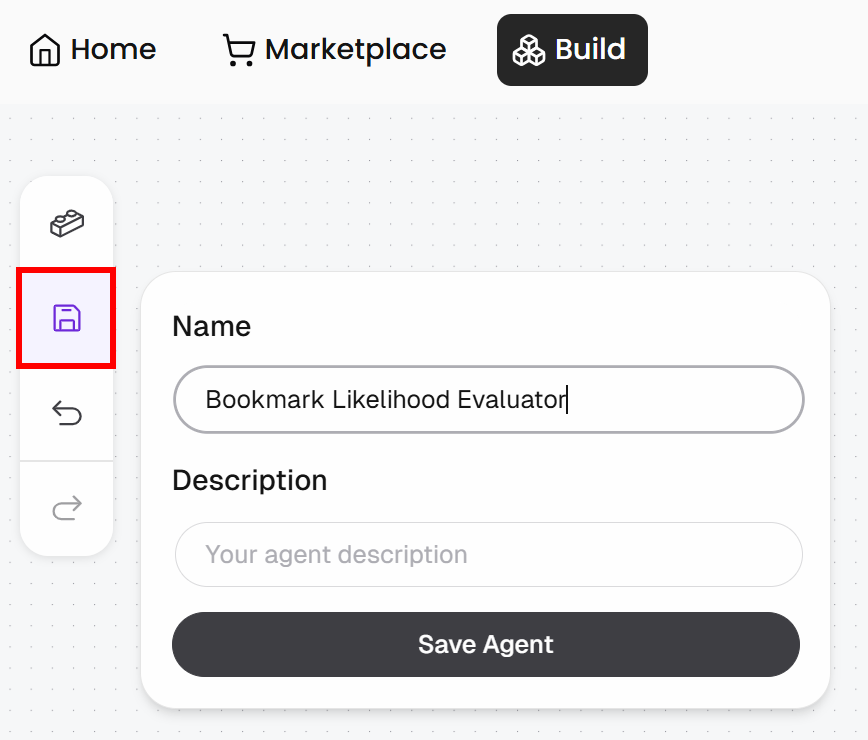
Agent Builderページで、左側の「Blocks」ボタンを押して、「Agent Input」ブロックを追加します: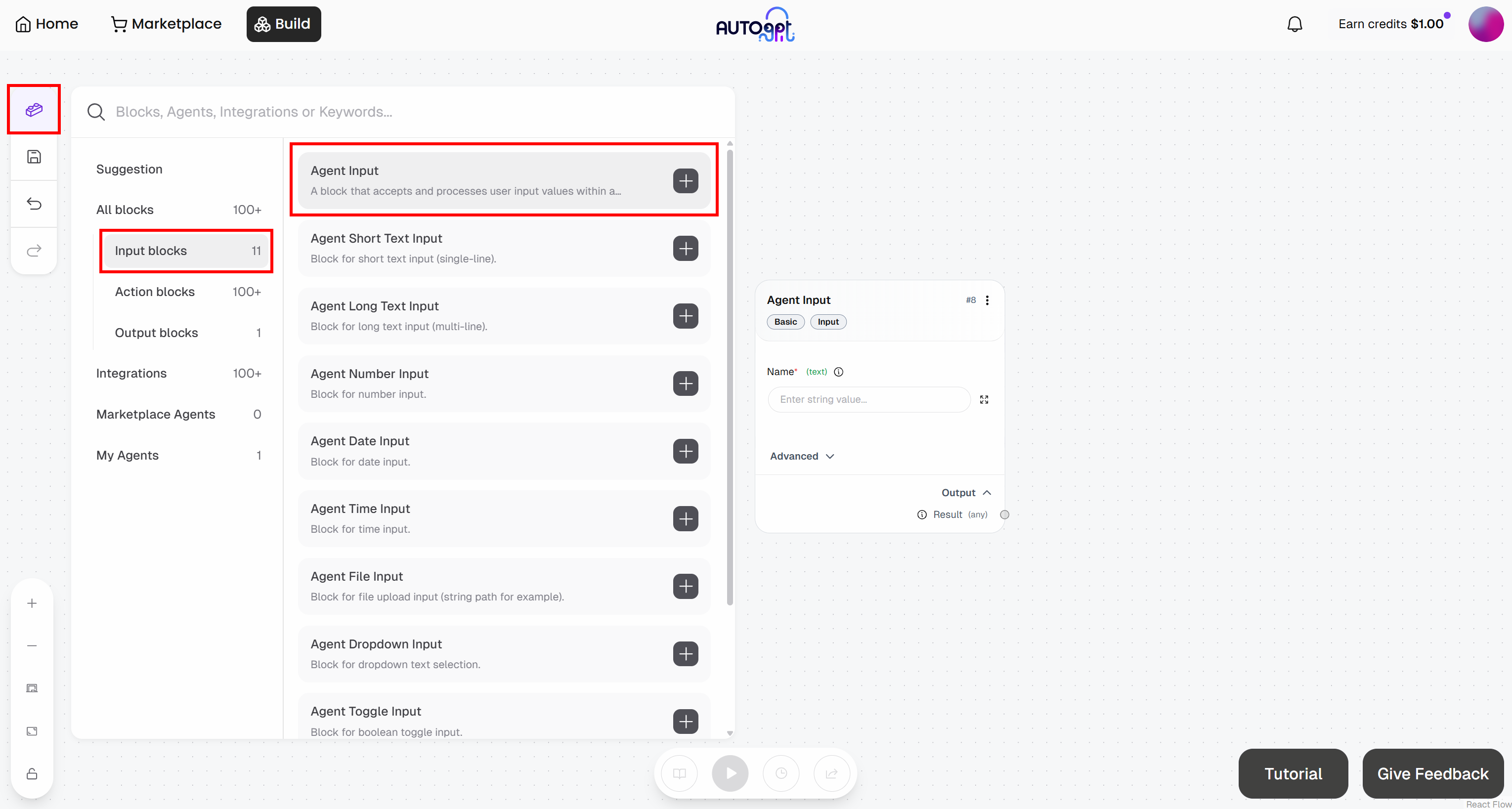
同様に、「Agent Output」ブロックを追加します: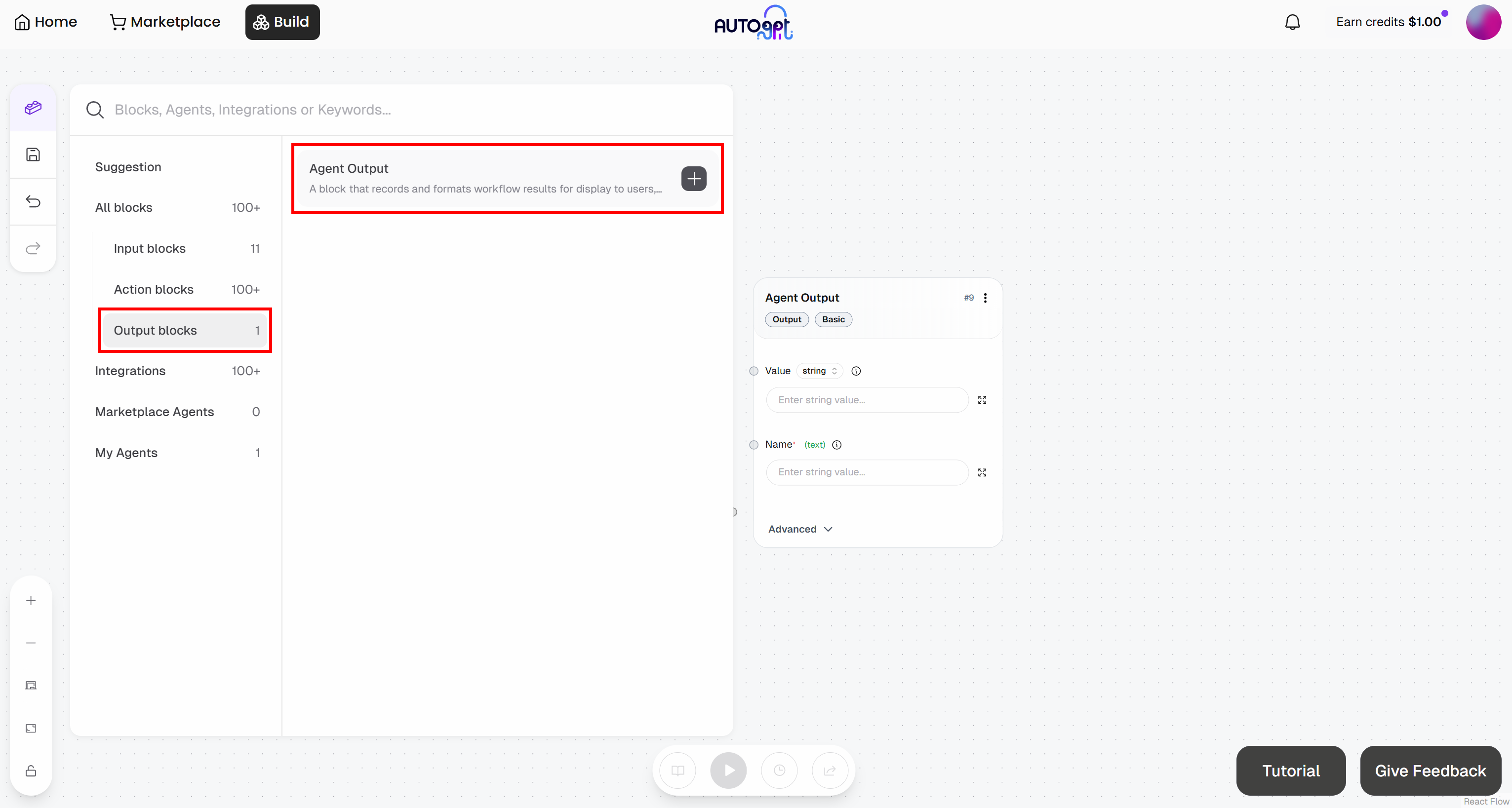
ブロックを次のように設定します:
- エージェント入力:名前を「記事URL」に設定
- エージェント出力ブロック:名前を「ブックマークの可能性」に設定
これで、初期のエージェントワークフローは次のようになります: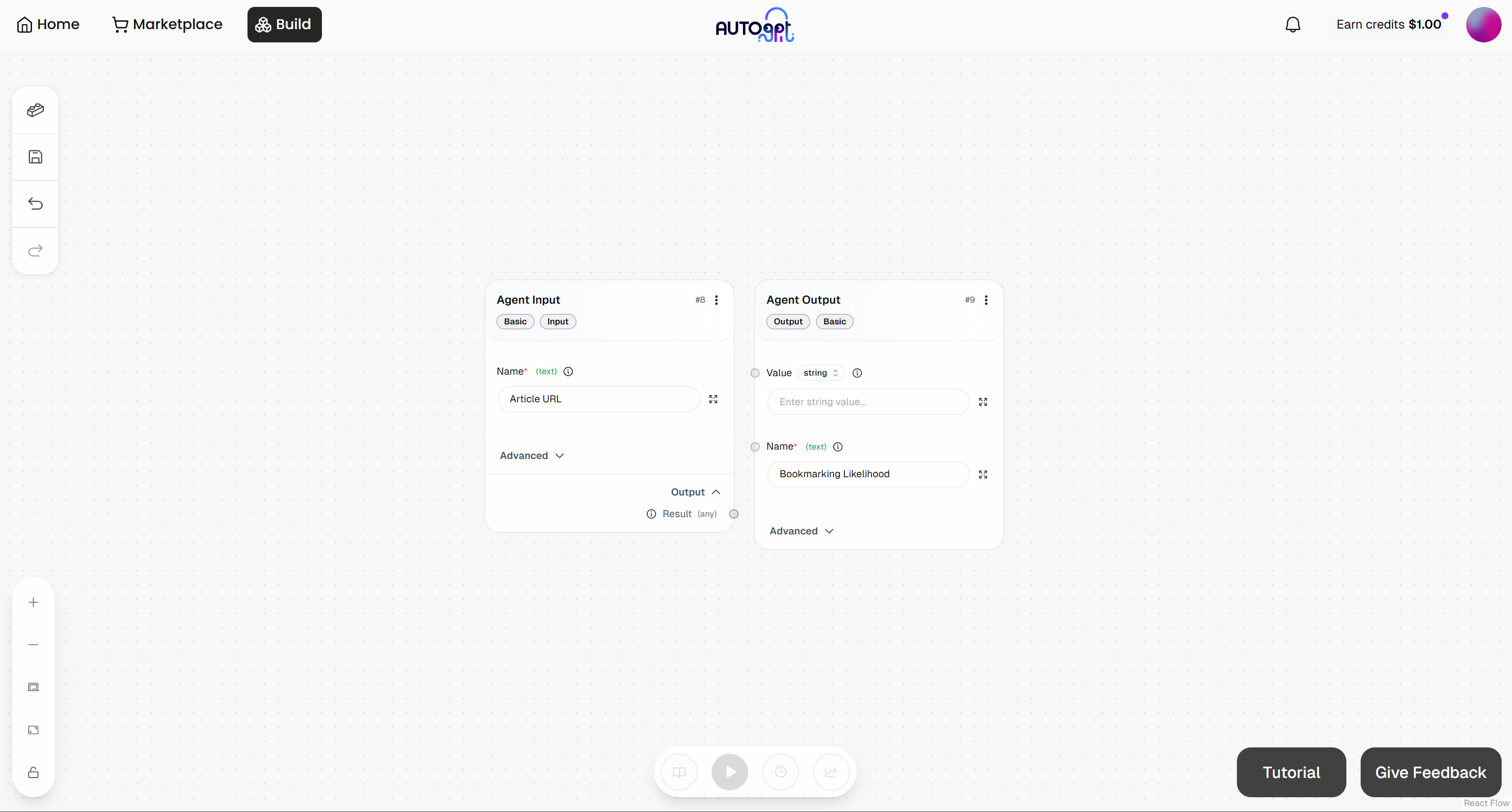
素晴らしい! それでは、エージェントワークフローの残りの部分を定義していきましょう。
ステップ 6: スクレイピングリクエストを実行する
Bright Data Web Unlocker API への HTTP リクエストを実行するには、次の 2 つのブロックが必要です:
- 辞書の作成:リクエスト本文を定義します。
- 認証済みWebリクエストの送信:Bright Data API上のWeb Unlockerエンドポイントへ認証済みリクエストを送信します。
まず、「Create Dictionary」ブロックを追加します: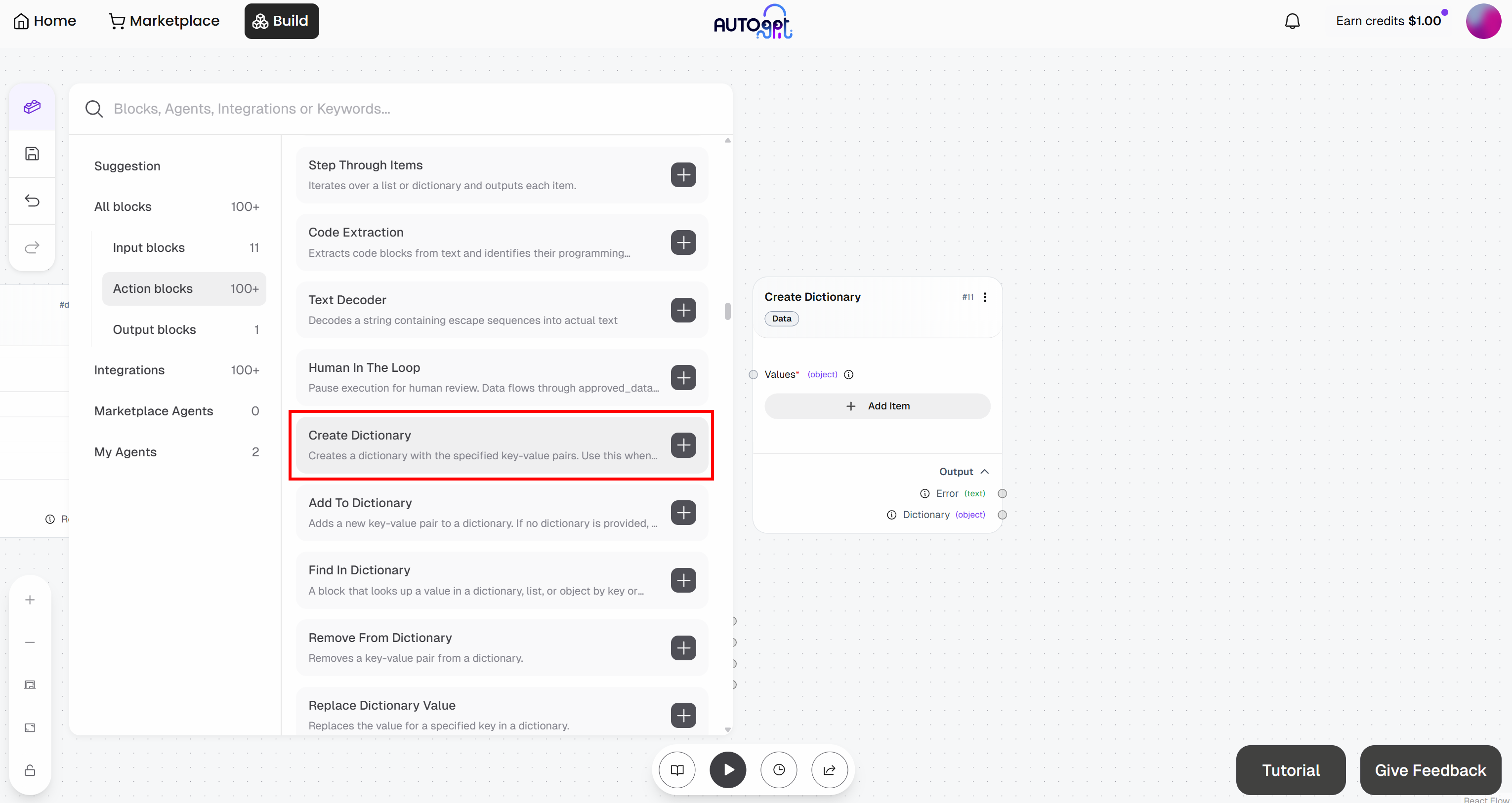
次に、「認証済みWebリクエストの送信」ブロックを追加します: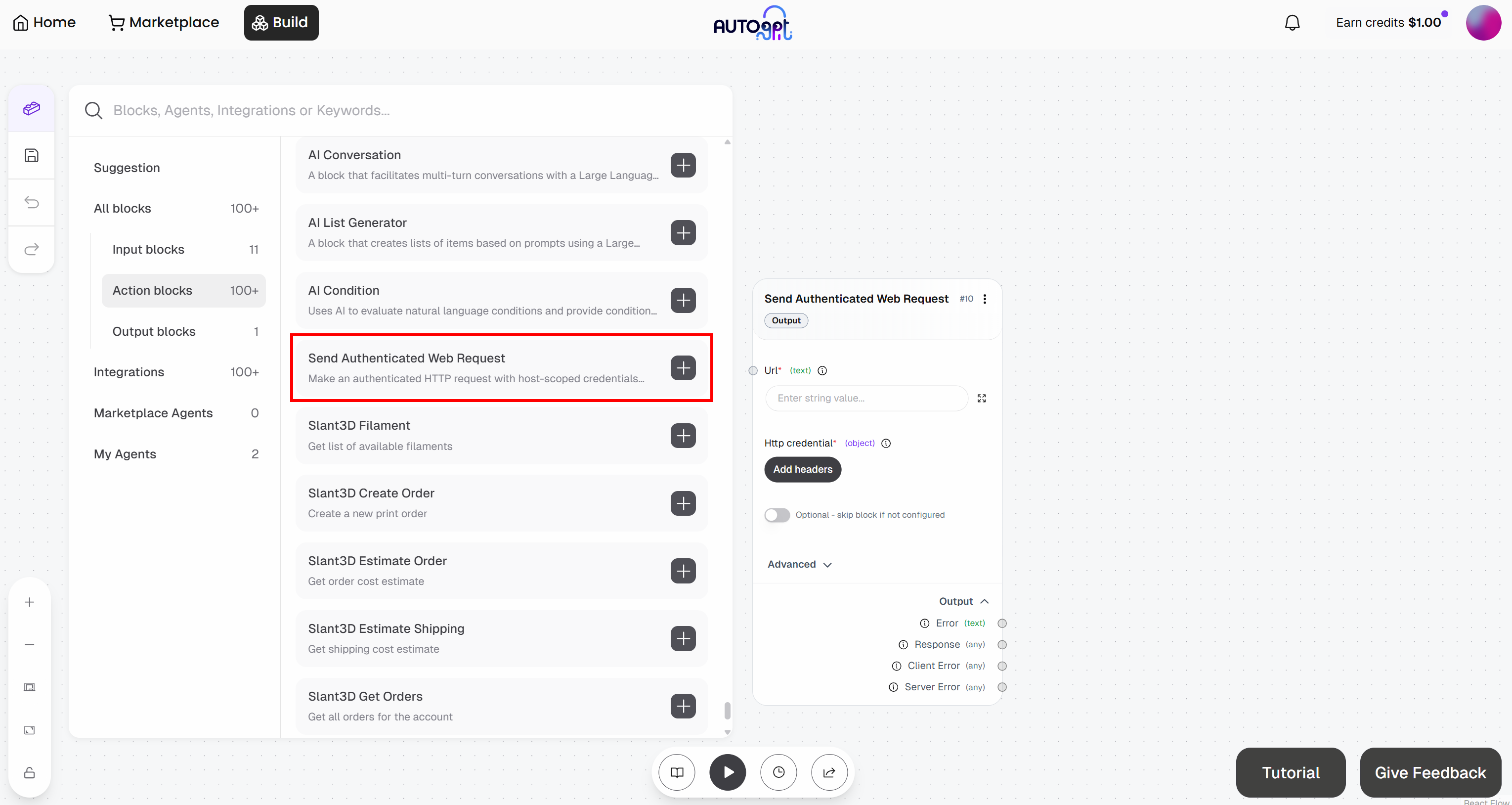
「Send Authenticated Web Request」ブロックの設定準備をします。これにより、Web Unlocker API へリクエストが送信されます。このエンドポイントの動作や呼び出し方法の詳細については、公式ドキュメントを参照してください。
「詳細」ドロップダウンを展開し、ブロック全体を次のように設定します:
- Url:
https://api.brightdata.com/request. - HttpMethod:
POST
次に、「Http credentials」の下にある「Add headers」ボタンをクリックします: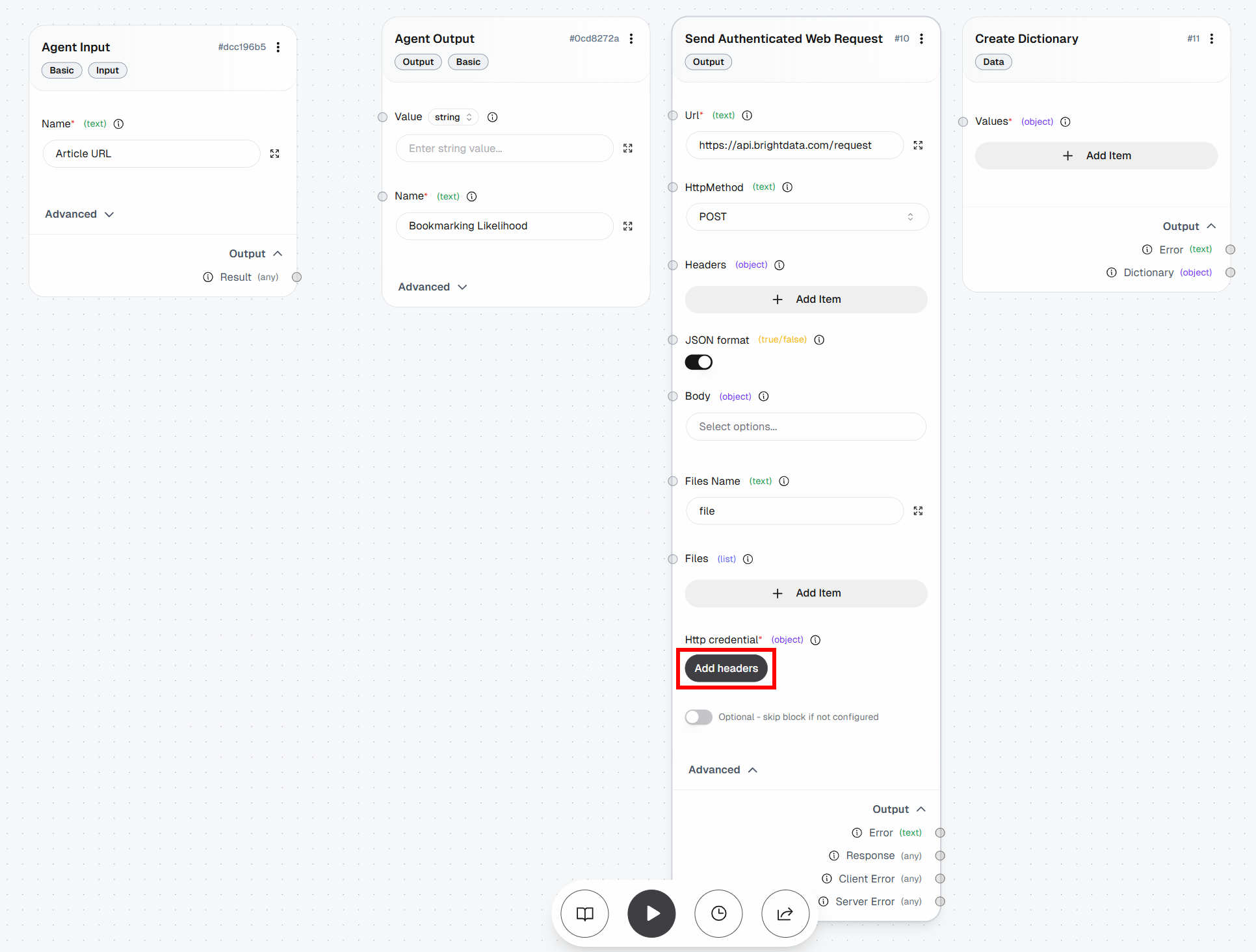
ヘッダーベースの認証を次のように設定します:
- ヘッダー名:
Authorization - ヘッダー値:
Bearer <YOUR_BRIGHT_DATA_API_KEY>
<YOUR_BRIGHT_DATA_API_KEY>というプレースホルダーを、実際のBright Data APIキーに置き換えることを忘れないでください。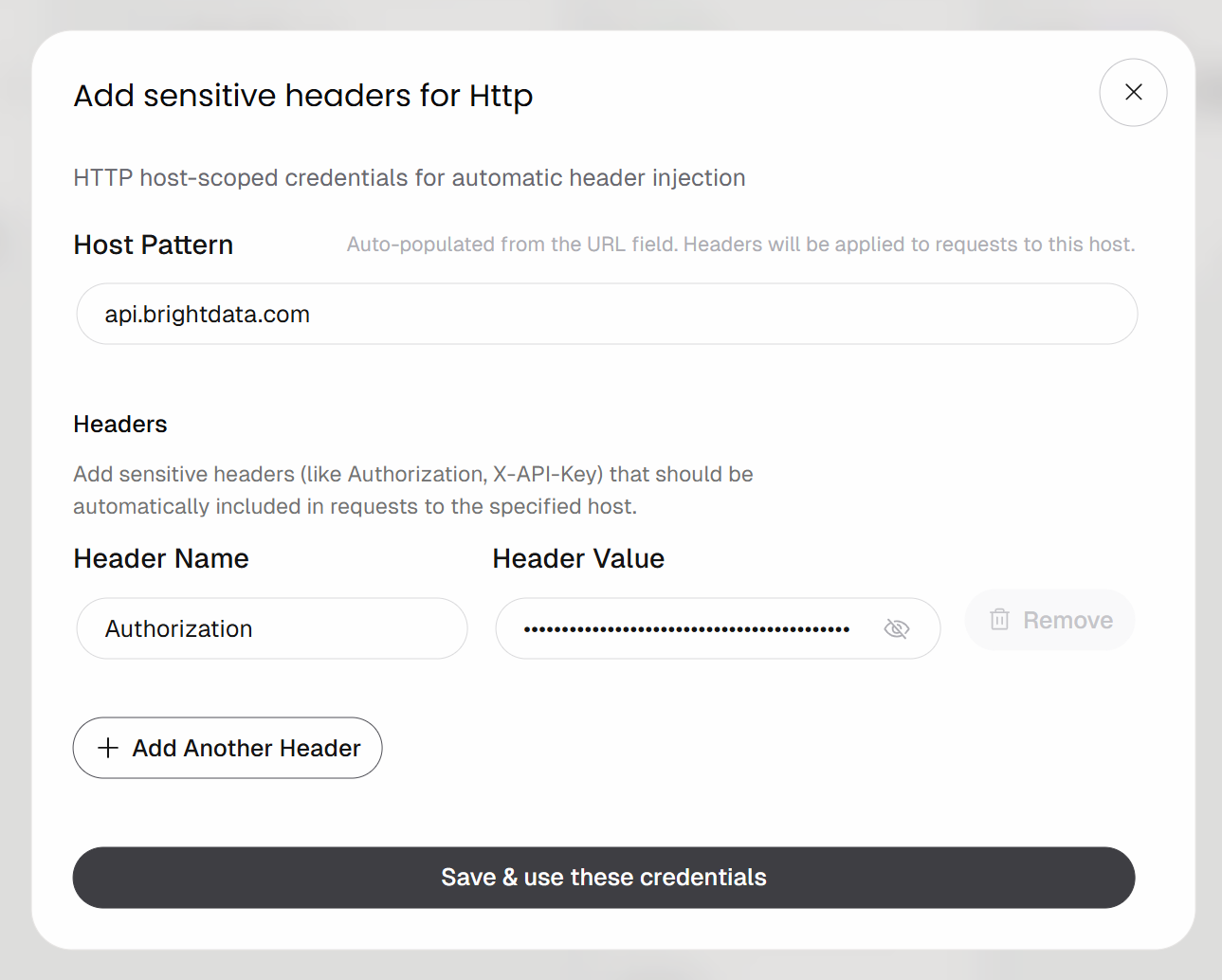
「Save & use these credentials」ボタンをクリックして確定します。
POSTリクエストは、Authorizationヘッダーを使用して認証されます。これが、Bright Data APIを呼び出す際の推奨される認証方法です。
次に、リクエストボディを定義する必要があります。この場合、次のような JSON ペイロードが必要です:
{
"ゾーン": "<YOUR_WEB_UNLOCKER_API_ゾーン_名>",
"url": "<INPUT_URL>",
"format": "raw",
"data_format": "markdown"
}これにより、Bright Data APIは「Agent Input」ブロックから提供されるターゲットURLに対して、指定されたWeb Unlocker APIゾーン(例:web_unlocker)を使用するよう指示されます。format: "raw"パラメータを指定することで、APIがJSON構造ではなく、レスポンス本文に直接出力結果を返すようにします。data_format: "markdown"パラメータを指定すると、APIが記事コンテンツをMarkdown形式で抽出するよう設定され、これはAIエージェントへの取り込みに最適な形式です。
これを行うには、「Create Dictionary」ブロックに移動し、「Add Item」をクリックします。以下のフィールドを定義します:
ゾーン:<YOUR_WEB_UNLOCKER_API_ゾーン_名>(例:"web_unlocker")url: (動的に設定されるため、現時点では空欄のままにしておきます)format:"raw"data_format:"markdown"
次に、「Create Dictionary」ブロックの「Dictionary」出力を、「Send Authenticated Web Request」ブロックの「Body」入力に接続します: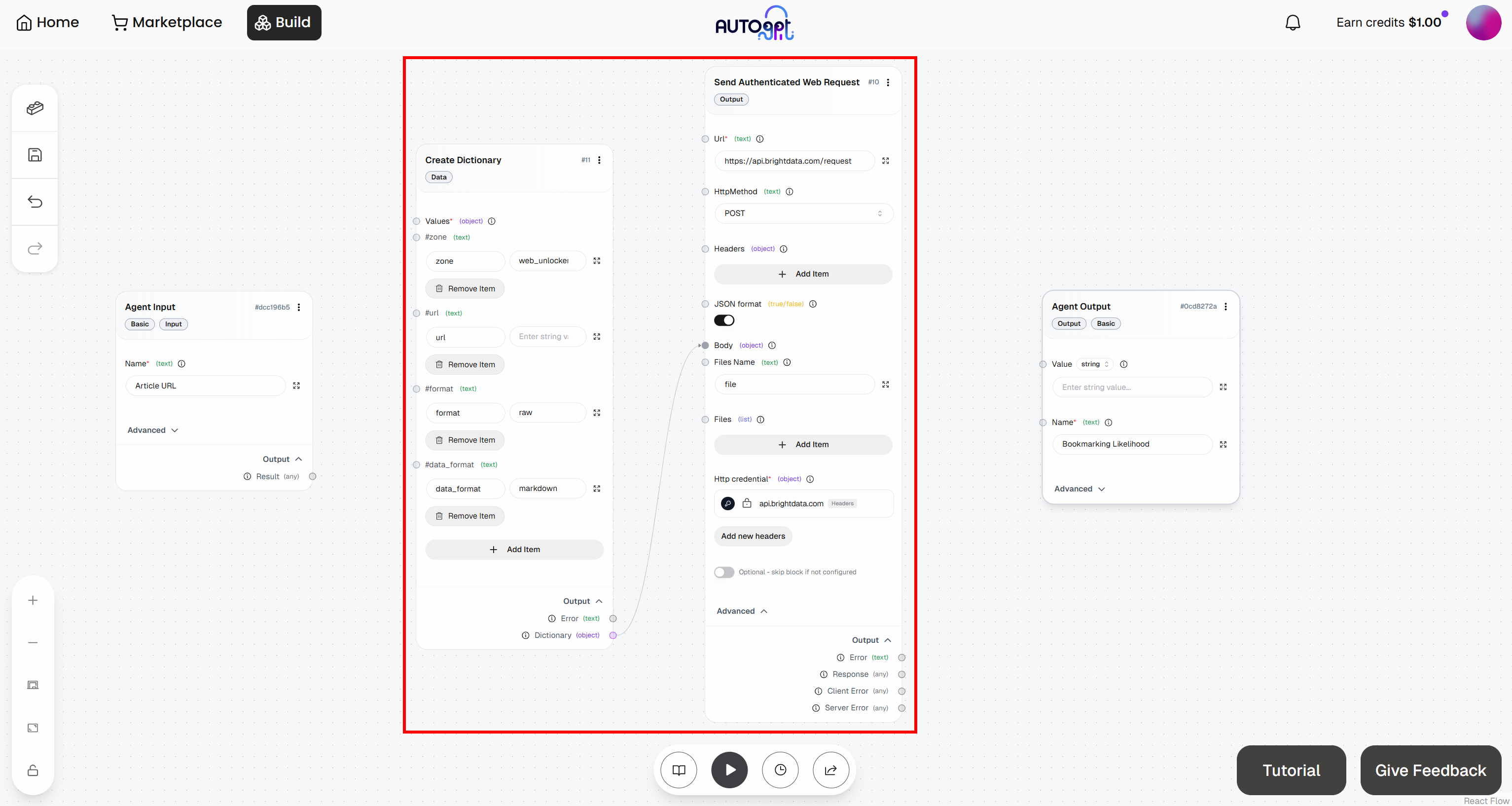
素晴らしい!これで、AutoGPTワークフローへのBright Dataの統合が完了しました。
ステップ #7: LLMエンジンの追加
最後に追加するブロックは、Web Unlocker API を通じてウェブスクレイピングで取得した Markdown コンテンツを分析し、ブックマークスコアを割り当てる役割を担う LLM エンジンです。
このワークフローでは、時間の経過とともにさまざまな記事を評価したいので、一貫性のある構造化された出力を生成する必要があります。
この目標を達成するには、「AI Structured Response Generator」ブロックを活用します。これにより、LLMにタスクを実行させ、事前に定義された形式で結果を返すよう指示できます。
まず、このブロックをワークフローに追加します: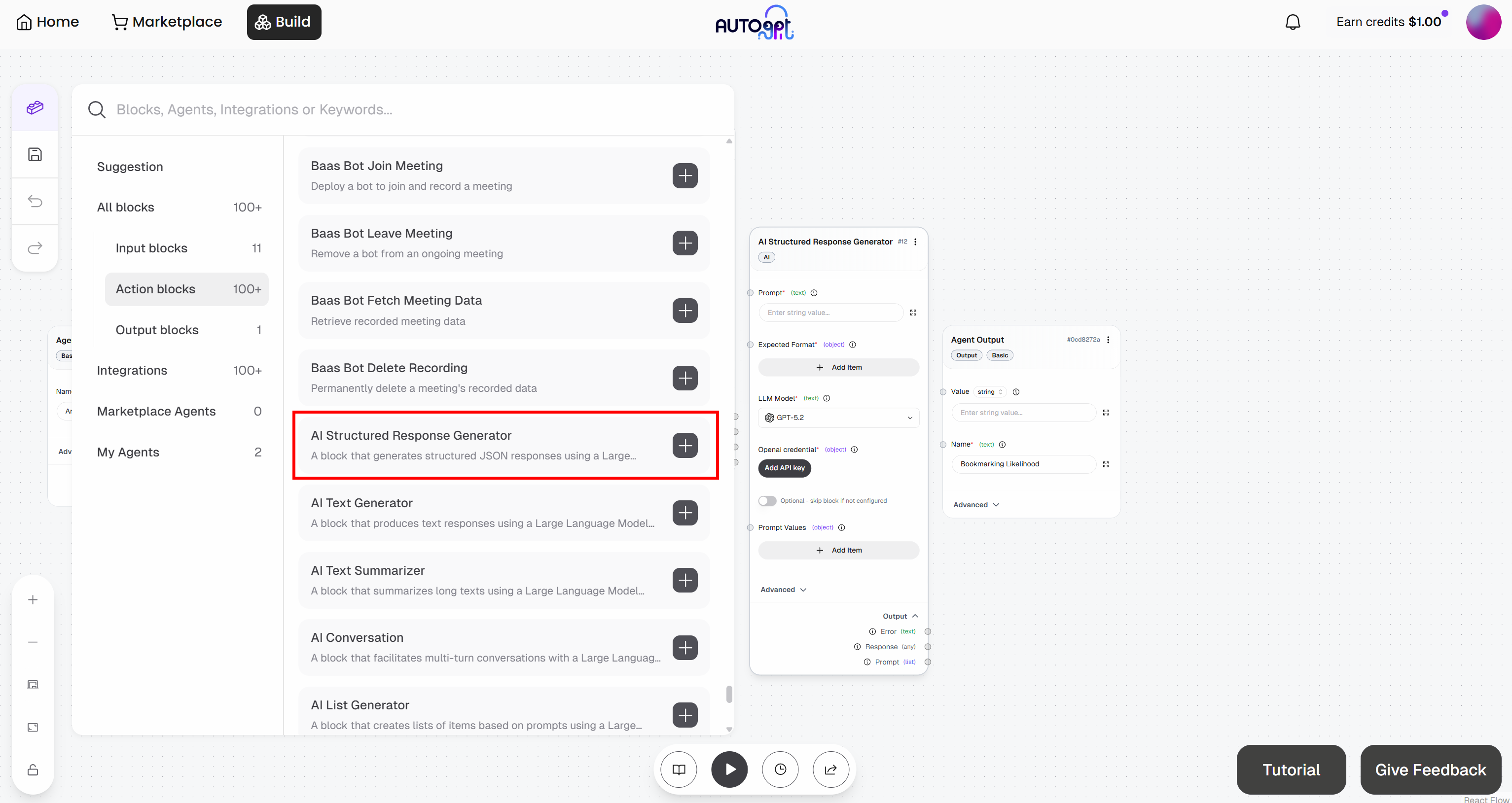
「APIキーを追加」ボタンをクリックして、ブロックをOpenAIアカウントに接続します。キーの名前を入力し、OpenAI APIキーを貼り付けて、「APIキーを追加」をクリックします: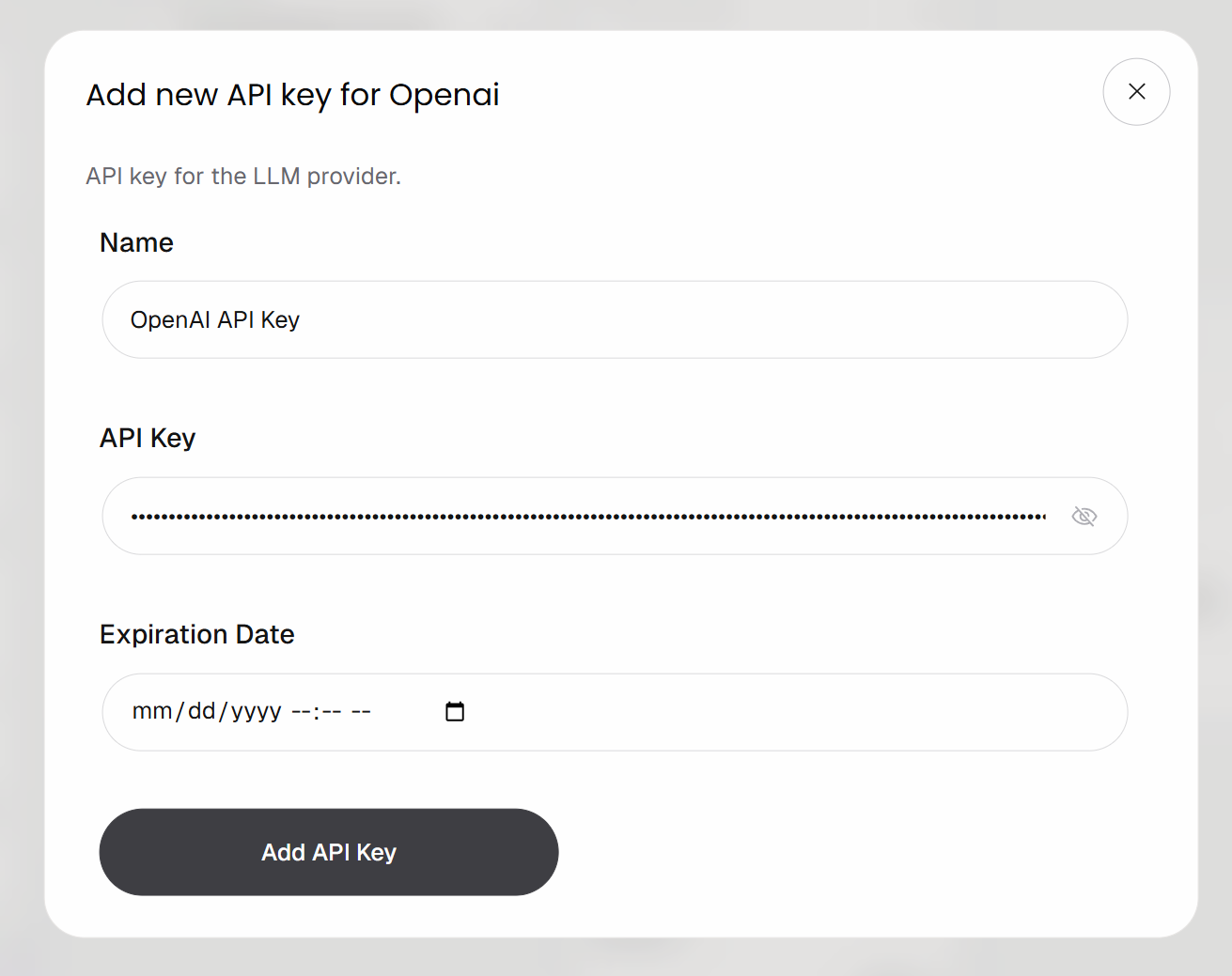
これで「AI Structured Response Generator」ブロックの認証が完了し、設定済みのOpenAIモデルを呼び出す準備が整いました。
次に、ブロックに以下の内容を入力します:
- プロンプト:
あなたはコンテンツ評価の専門家です。
あなたの任務は、以下の記事を分析し、将来参照するためにブックマークする価値があるかどうかを判断することです。
記事:
"{{article}}"
以下の基準に基づいて記事を評価してください:
- 実用性(実践的な洞察を提供していますか?)
- 深さ(表面的な内容か、それとも深い内容か?)
- 信号対雑音比(簡潔か、それとも無駄な情報が多いか?)
- 再利用性(後で再読する価値があるか?)
以下の内容を含む JSON オブジェクトを返してください:
- "score": 1 から 10 までの整数(1 = ブックマークする価値なし、10 = 必ずブックマークすべき)
- "comment": 簡潔で人間らしい説明(最大1~2文)
ガイドライン:
- 批判的な視点を持ち、過大評価を避ける
- 長期的な価値のあるコンテンツにのみ高いスコアを付ける
- ありきたりなコメントは避ける
- *モデル*: GPT-5.1 Mini(またはその他の汎用OpenAIモデル)プロンプト内の{{article}}というプレースホルダーに注意してください。これは「プロンプト値」で動的に置換される変数です。具体的には、「認証済みWebリクエストの送信」ブロックによって返されるMarkdownコンテンツで置換されます。
「プロンプト値」を設定するには、「アイテムを追加」をクリックし、articleという名前の変数を定義します。次に、「認証済みWebリクエストの送信」ブロックの「レスポンス」出力をarticleプロンプト値に接続します: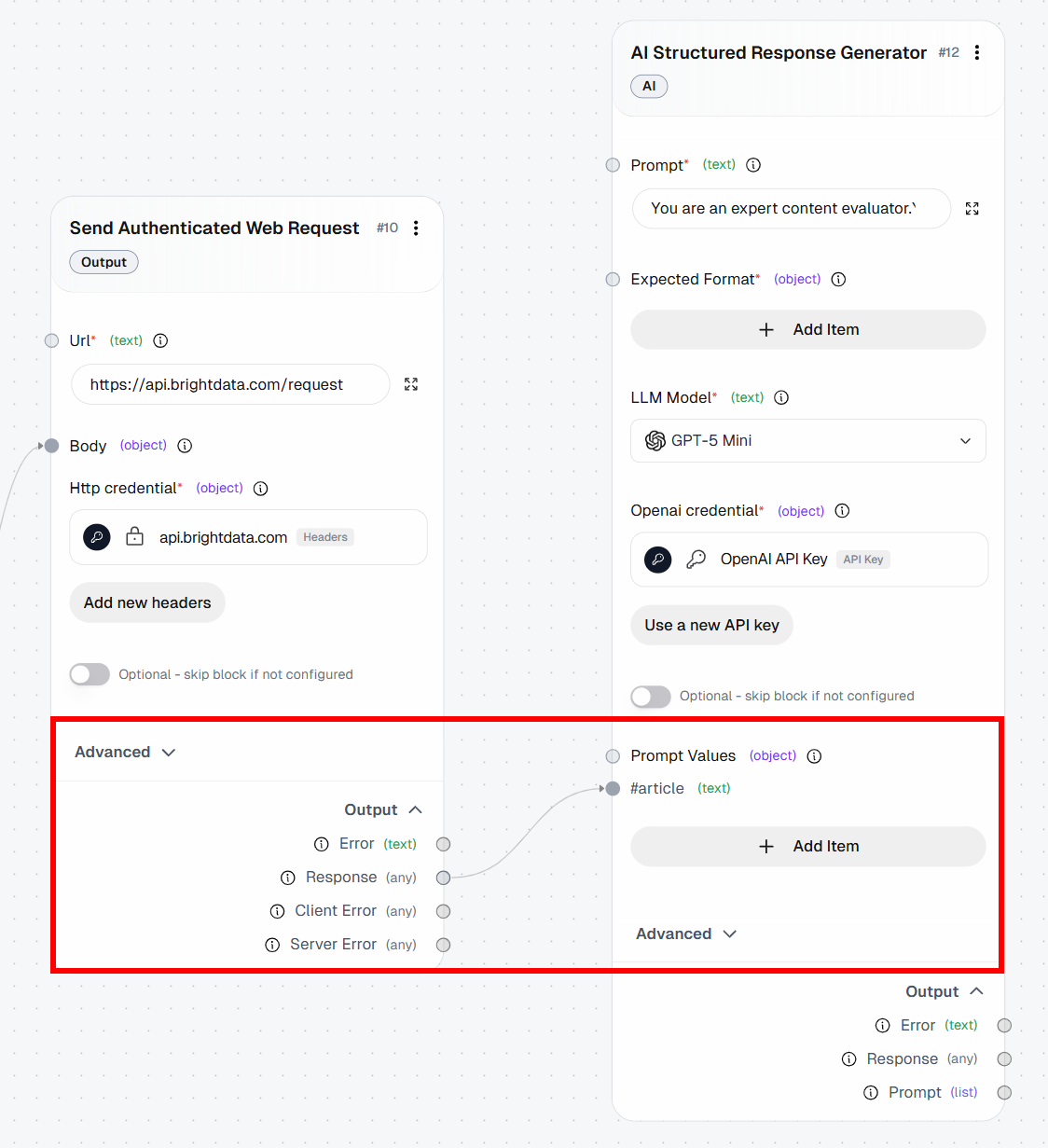
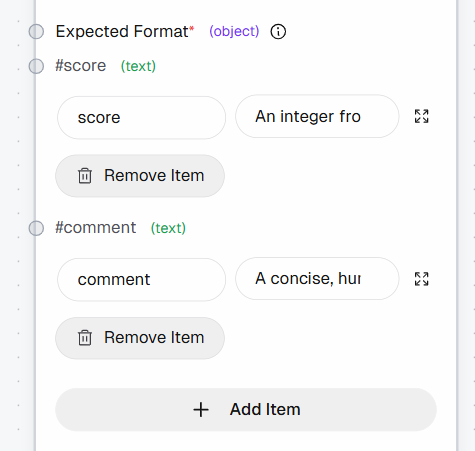
次に、「Expected Format」セクションに以下のフィールドを追加して、構造化された出力を定義します:
score: 「1から10までの整数(1 = ブックマークする価値なし、10 = 必ずブックマークすべき)」comment: 「簡潔で人間らしい説明(最大1~2文)」
素晴らしい!これで、Bright Dataを活用したAutoGPTエージェントワークフローの構成要素がすべて揃いました。あとはこれらをすべて接続するだけです。
ステップ #8: すべてのブロックを接続する
ワークフローを完成させるには、すべてのブロックを接続して完全なパイプラインを作成します。
まず、「Agent Input」ブロックの「Result」出力を、「Create Dictionary」ブロックのurlフィールドに接続します。これにより、入力URLがワークフローの入力からWeb Unlocker APIリクエストへと流れ、ページをウェブスクレイピングして結果をLLMに渡し、分析が行われるようになります。
最後に、「AI Structured Response Generator」ブロックの「Response」出力を「Agent Output」ブロックに接続します。これによりワークフローが閉じられ、データフローが完了します。
以下は、Bright Dataのおかげでウェブスクレイピング機能が強化された、最終的なAutoGPTワークフローの構成例です: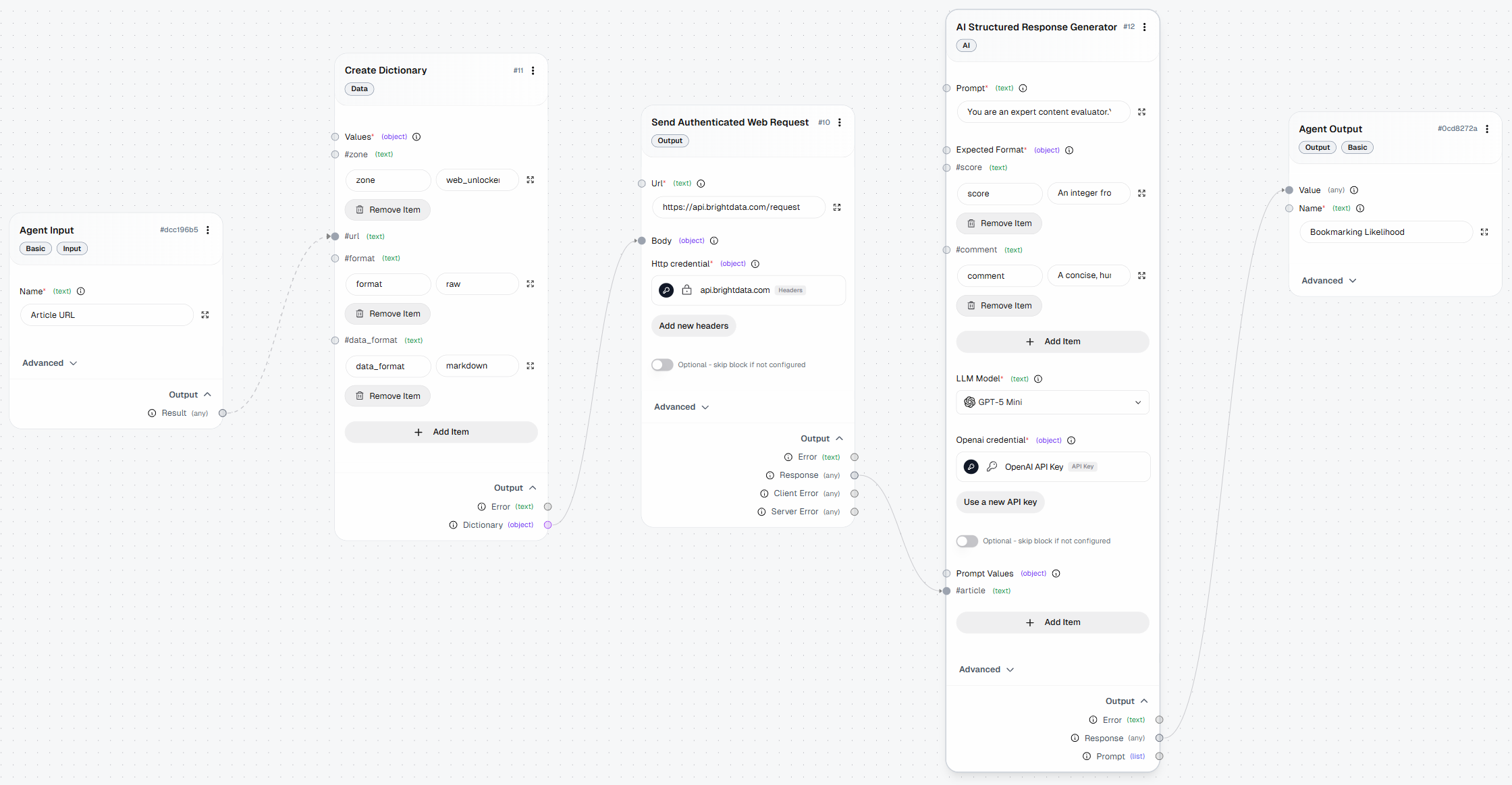
ステップ 9: エージェントのテスト
「Run agent」ボタンをクリックしてエージェントワークフローを起動し、テストします: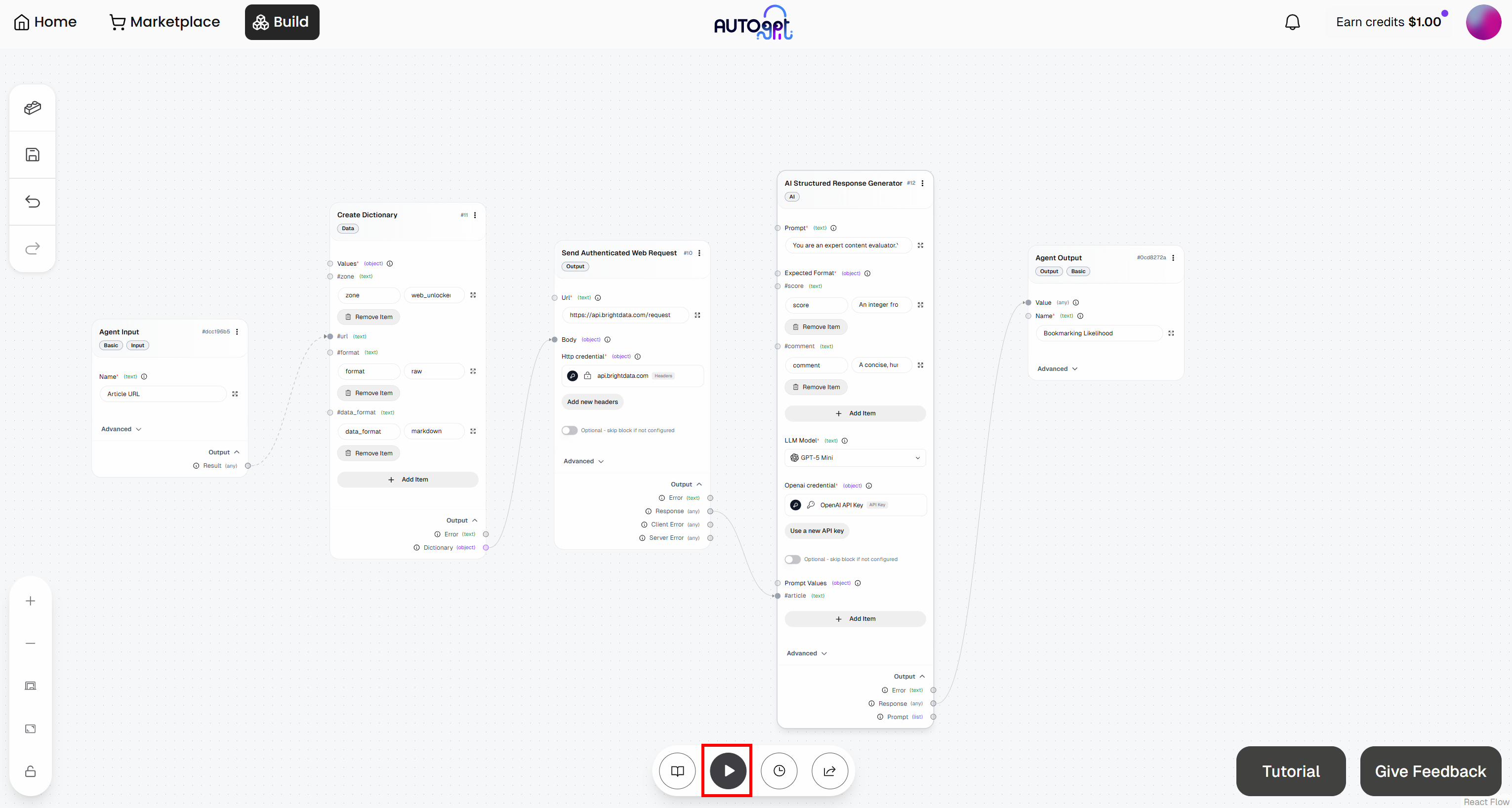
ワークフローの入力URL(つまり記事のURL)を入力するよう求められます。次のようなブログ記事を貼り付けてください:
https://awealthofcommonsense.com/2024/03/whats-the-investment-case-for-gold/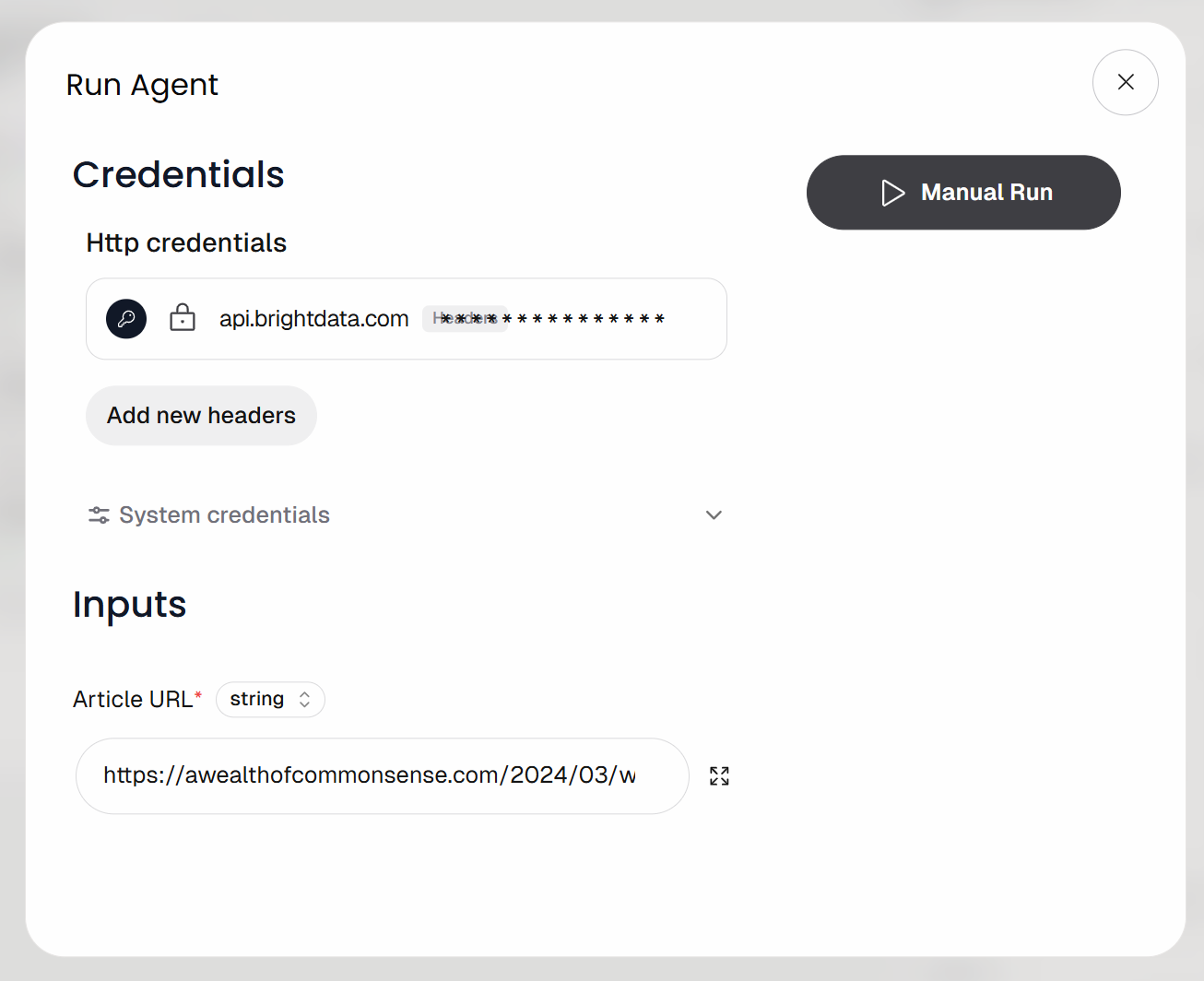
次に、「手動実行」ボタンをクリックしてワークフローを実行します。次のような画面が表示されます: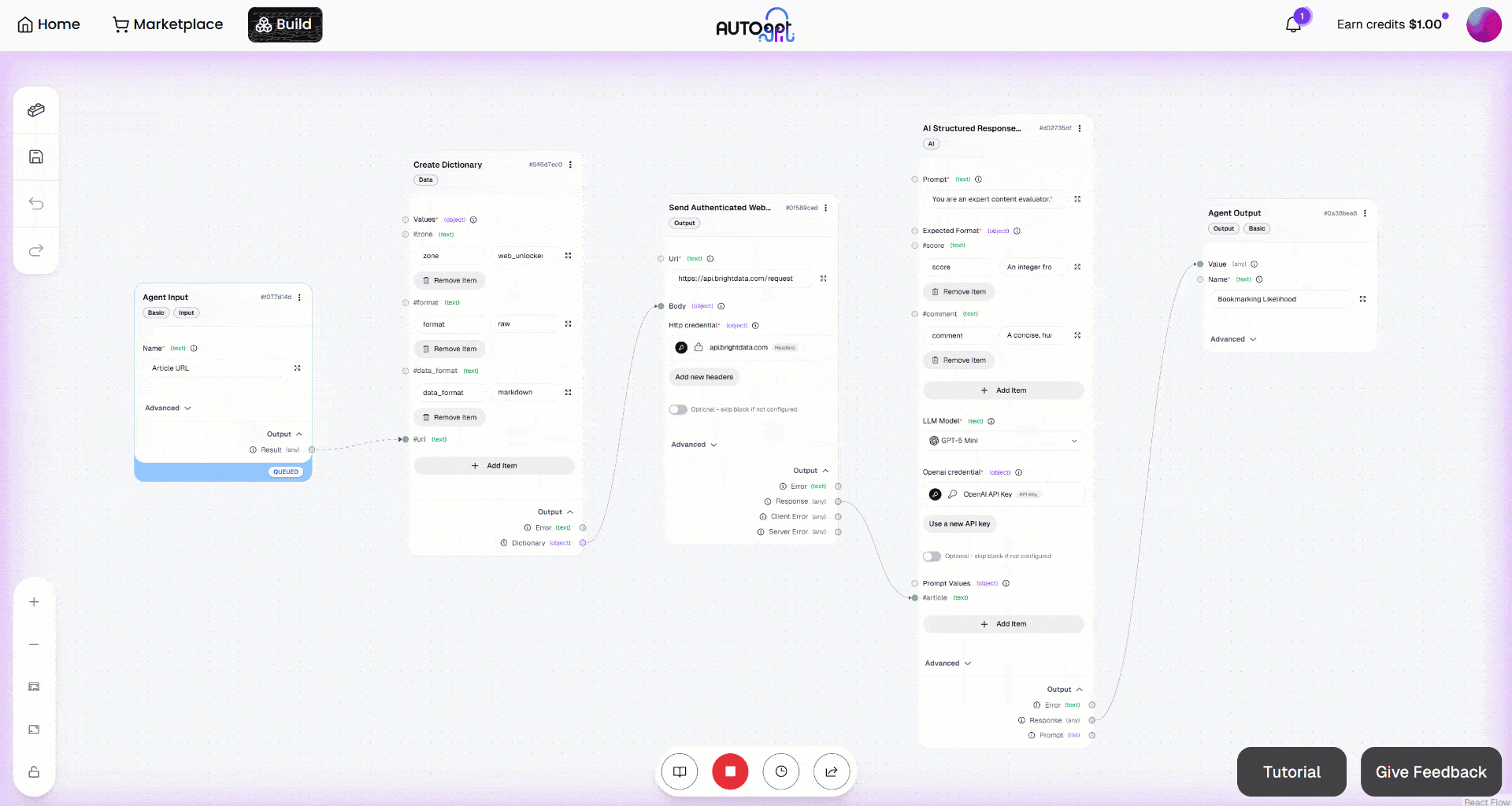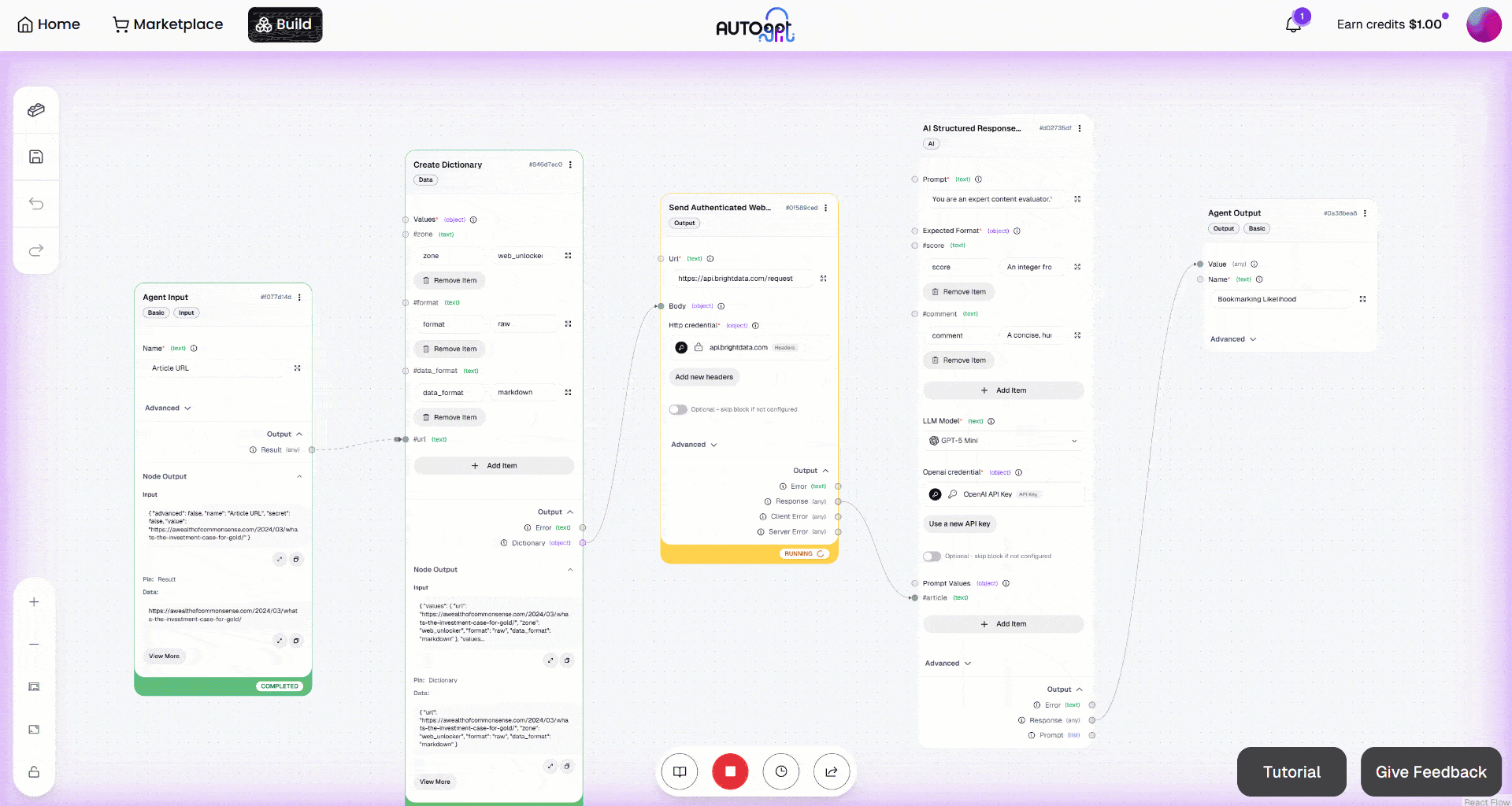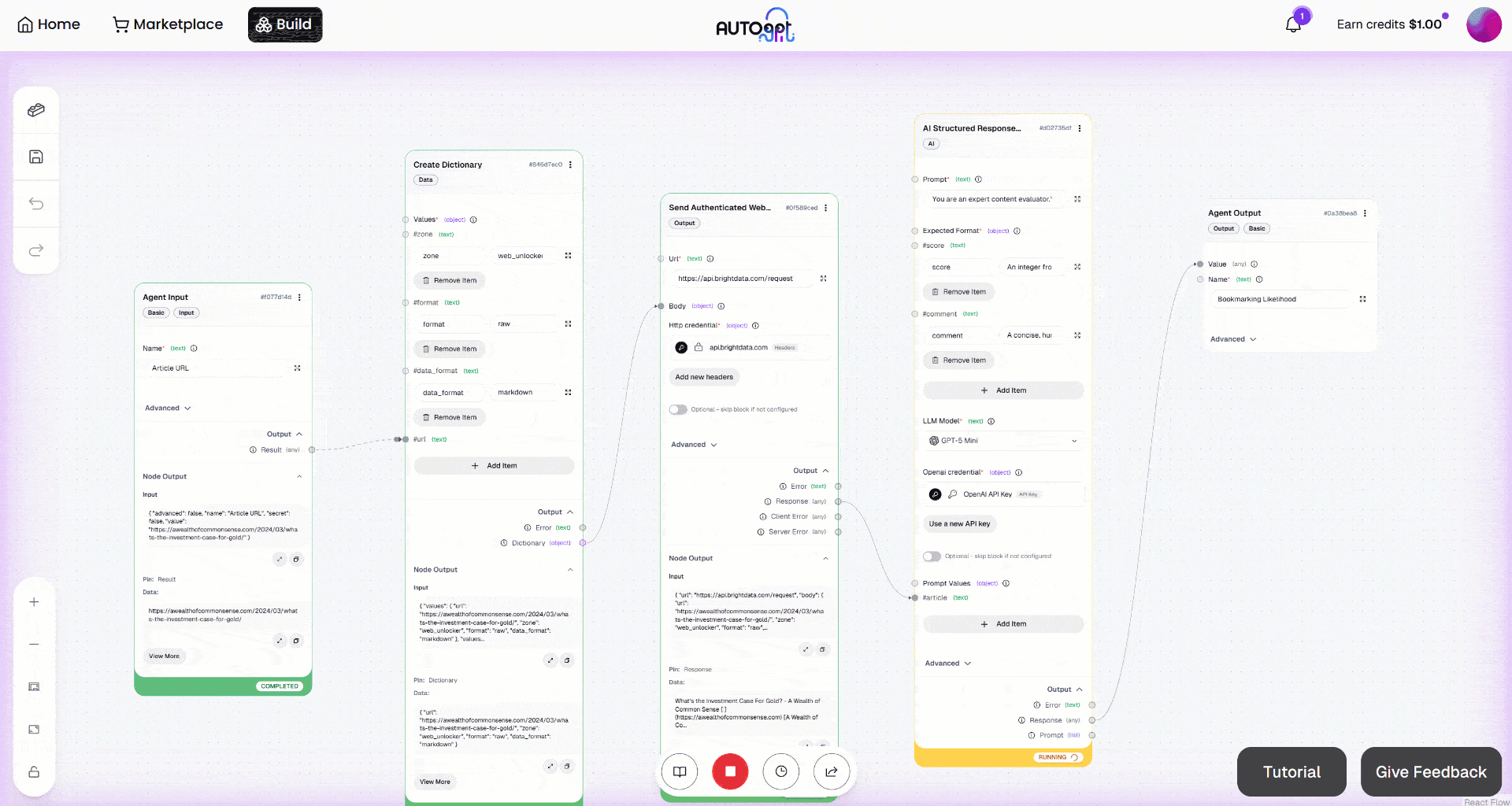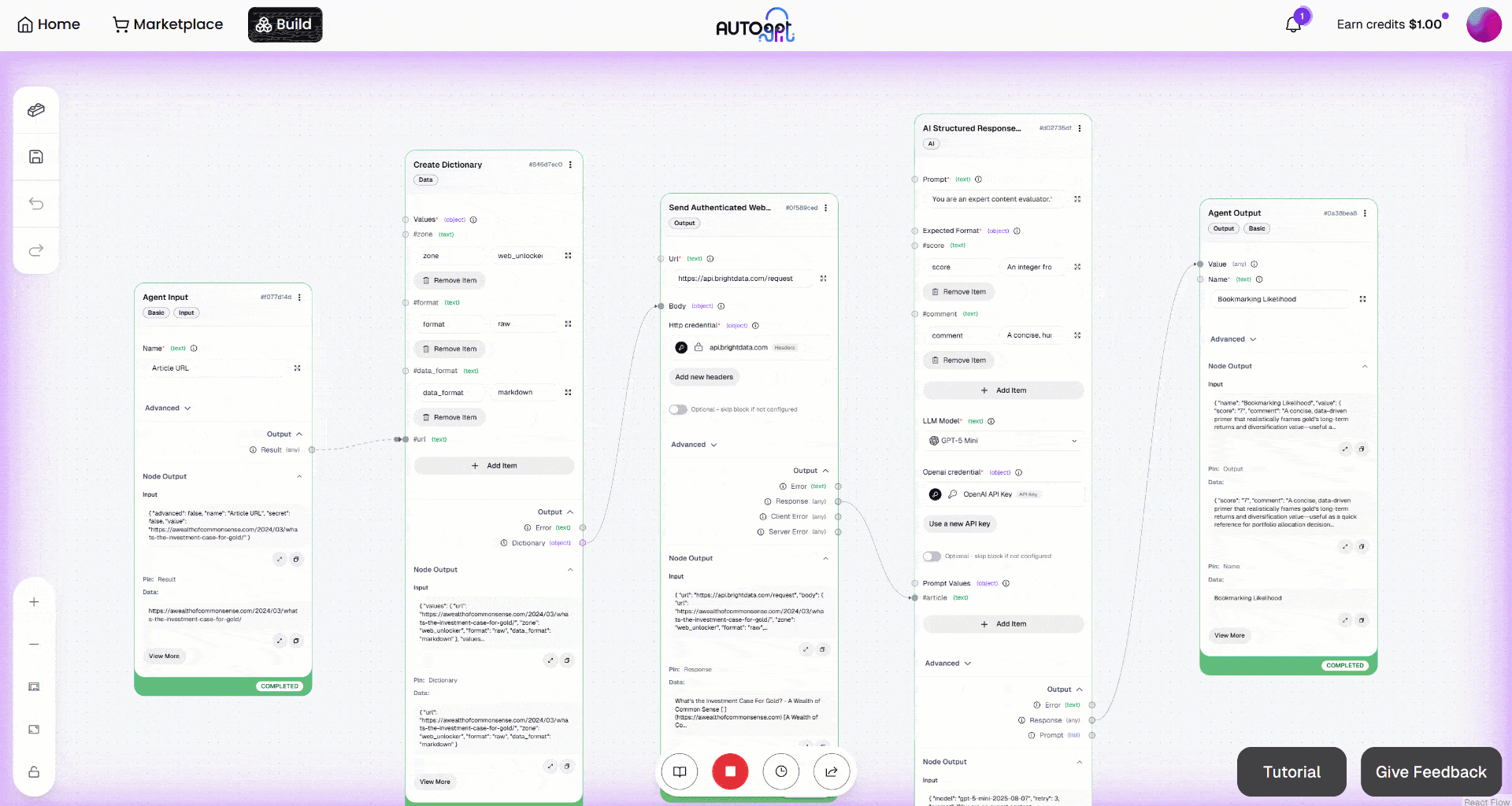
「エージェント出力」ブロックの出力を展開してください。AIエージェントが次のような結果を生成していることがわかります: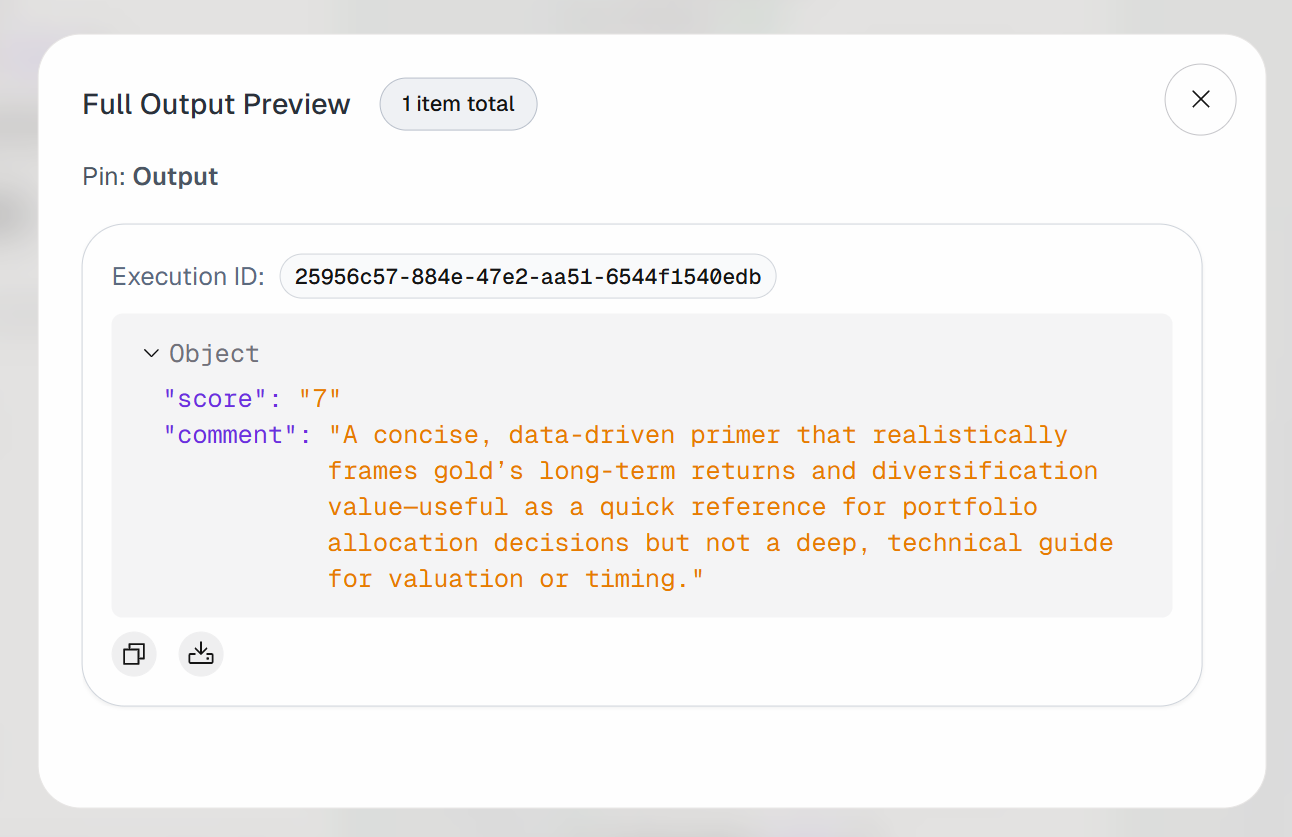
したがって、入力された記事は、後で読むためにブックマークする価値があるものと判断されました。
「Send Authenticated Web Request」ブロックの出力を確認すると、次のような内容が表示されます:
これは、対象の入力記事のMarkdown版に対応しています: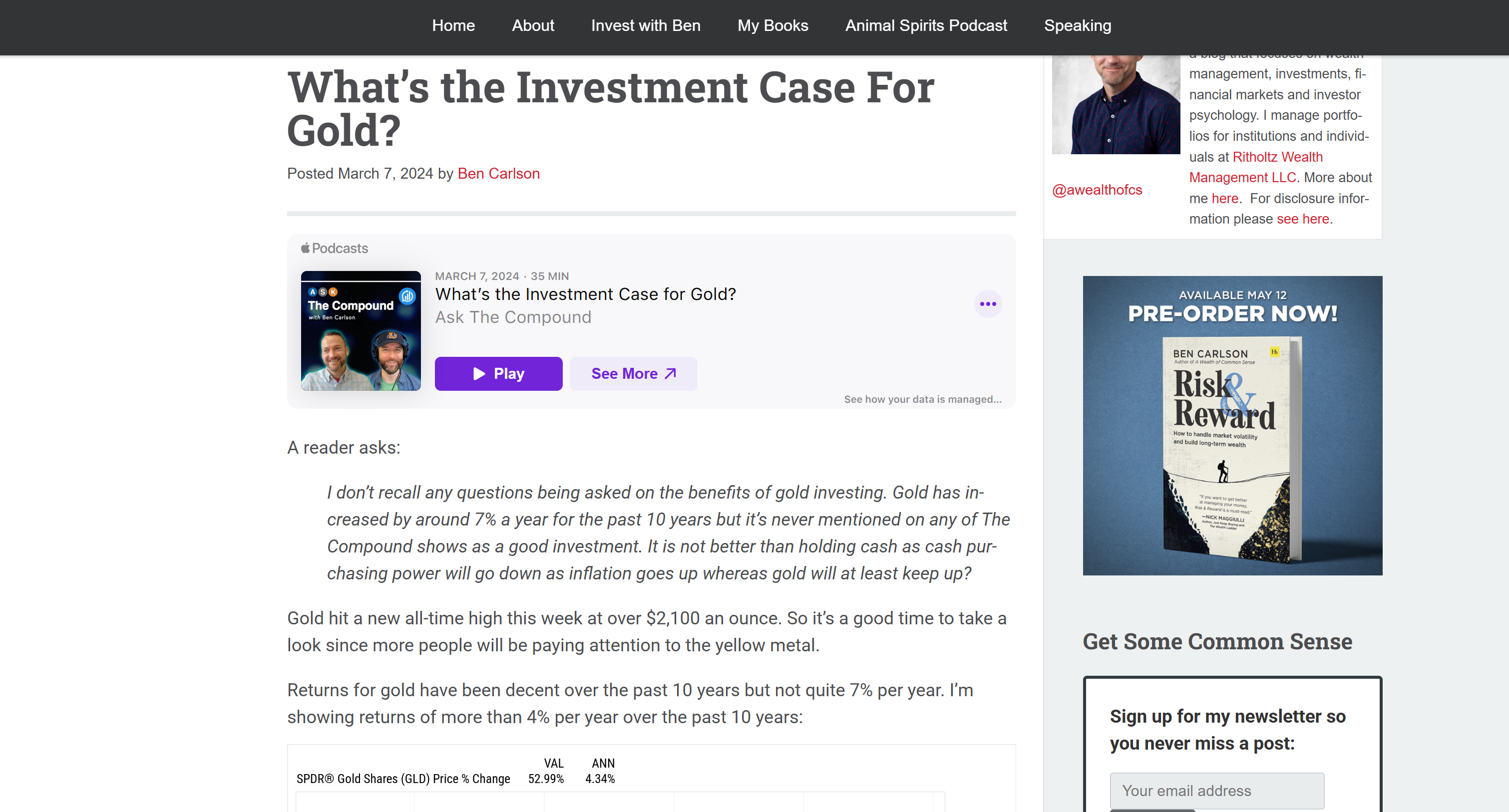
これにより、Bright Data Web Unlocker APIがページコンテンツを迅速に取得し、LLM処理をより効率的かつ効果的に行う形式で提供できたことが確認できます。
これで完了です!AutoGPT上で、動的なWebデータ取得のためにBright Dataと連携するAIエージェントを構築しました。
次のステップ
これは単純な例ですが、AutoGPTとBright Dataの連携は、より高度なエージェントワークフローに対応できるよう拡張できることを覚えておいてください。
例えば、同様のアプローチで、エージェントを他の Bright Data API ベースの製品に接続し、ウェブ検索やクローリング機能を追加することができます。同様に、複数のドメインから直接データフィードを提供するスクレイピング API と統合することも可能です。
エージェントの機能をさらに強化するには、公式ドキュメントを詳しく確認し、AutoGPTが提供する幅広い機能をぜひ活用してください。
まとめ
このブログ記事では、AutoGPTにBright DataのWeb探索、対話、検索、およびデータスクレイピング機能を追加する方法について学びました。これにより、AIエージェントは、標準的なLLMに典型的な知識や対話の制限を克服できるようになります。
ここでは、シンプルなブックマークアドバイザーAIエージェントの構築方法をご紹介しました。ライブWebフィードへのアクセス、Web検索、またはWebインタラクションを必要とする、より複雑なエージェントワークフローを作成するには、AutoGPTをBright DataのAIのためのデータとAI向けサービススイートと統合してください。
今すぐ無料でBright Dataアカウントを作成し、AI対応のWebデータソリューションを試してみましょう!






