

このチュートリアルでは
- Firebase Studioとは何か?
- CamelCamelのようなウェブ体験を構築するために、Bright DataのようなAmazonウェブデータプロバイダが必要な理由。
- Bright DataのAmazonスクレイパーAPIからAmazonデータを使用して、Firebase StudioでAmazon価格トラッカーウェブアプリを作成する方法。
さあ、飛び込もう!
Firebase Studioとは?
Firebase Studioは、Googleによって構築されたAIを搭載したクラウドベースの開発環境です。その主な目的は、AIを使ったプロダクション品質のアプリケーションの作成とデプロイを加速することだ。特に、開発ライフサイクル全体を通して、Geminiを搭載したAIアシスタンスが統合された包括的なワークスペースを提供する。
主な機能
Firebase Studioで利用可能な主な機能は以下の通り:
- クラウドベースの開発環境:コードの提案、生成、説明を含むAI支援による完全なコーディングワークスペースを装備。
- アプリプロトタイピングエージェント:AIサポートにより、Next.jsウェブアプリなどのアプリケーションのラピッドプロトタイピングをサポートし、大規模なマニュアルコーディングの必要性を低減します。
- さまざまなフレームワークと言語をサポート:Flutter、Go、Angular、Next.jsなど、人気の高いテクノロジーと連携し、好みのフレームワークを使用できます。
- Firebaseサービスとの統合:Firebase App Hosting、Cloud Firestore、Firebase Authenticationなどのサービスと統合。
- 開発とデプロイのためのツール:エミュレーション、テスト、デバッグ、アプリのパフォーマンス監視をサポートします。
- インポートとカスタマイズオプション:GitHub、GitLab、Bitbucket、圧縮アーカイブから既存のプロジェクトをインポートし、AIを使って完全にカスタマイズできます。
Amazon Price Trackerウェブアプリを構築するために必要なもの
CamelCamelCamelは、Amazonの商品価格を追跡するオンラインサービスで、価格履歴チャートや価格下落のアラートを提供し、ユーザーが最もお買い得な商品を見つけられるようにします。簡単に言うと、その中心的な機能はAmazonの価格追跡であり、まさにこのガイドで焦点を当てるものです。
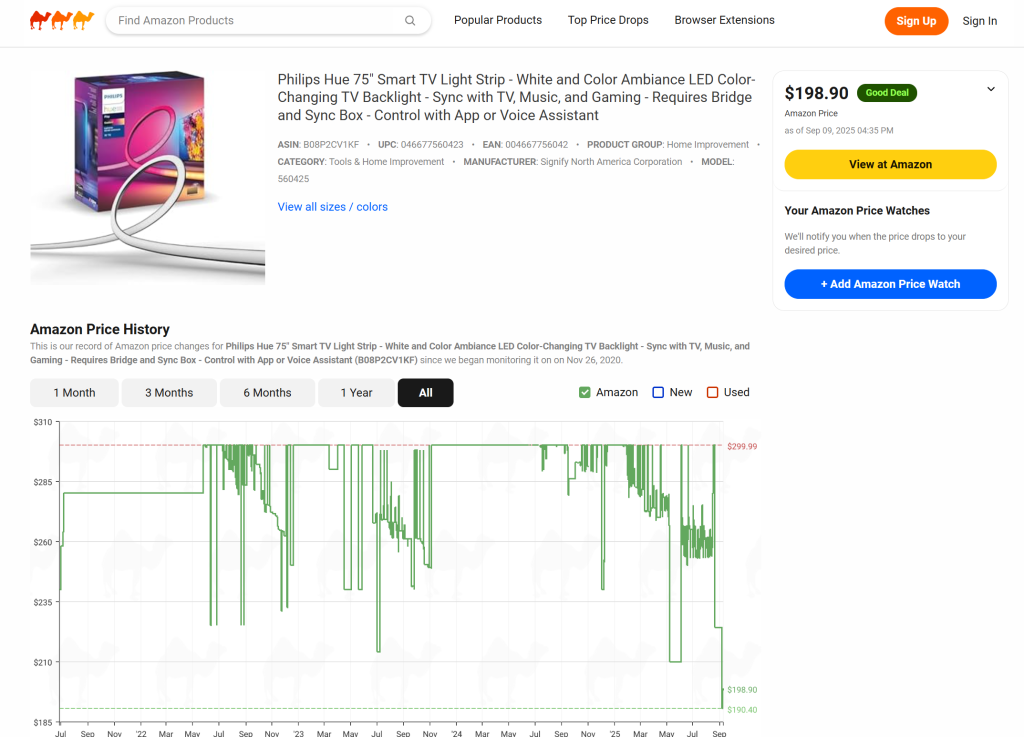
ここでのアイデアは、Amazon価格追跡をシンプルな方法で実装し、代替機能として動作するウェブアプリを構築することです。通常、開発には何日も(あるいは何ヶ月も)かかりますが、Firebase Studioのおかげで、ほんの数分でプロトタイプを完成させることができます。
このタスクの大きな課題は、Amazonの商品データを取得することです。Amazonのスクレイピングは、CAPTCHA(悪名高いAmazon CAPTCHAを思い出してください)のような厳しいボット対策により、自動化されたリクエストのほとんどをブロックすることができるため、悪名高く困難です:
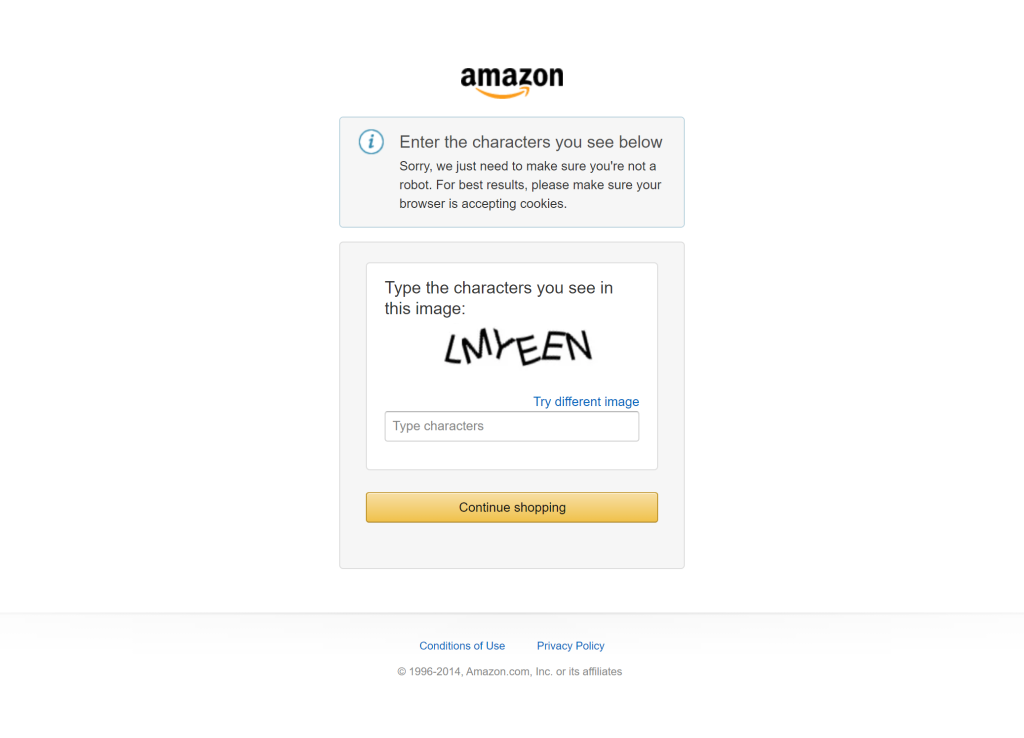
そこでBright Dataの出番です!
Bright Dataは、事実上あらゆるウェブサイトから生データと構造化された形式のウェブデータを取得するためのソリューション一式を提供しています。IPローテーション、ブラウザフィンガープリント、CAPTCHAの解決、その他多くの重要な側面が自動的に処理されるため、ブロックや制限を心配する必要はありません。
具体的には、Bright DataのAmazonスクレイパーAPIが返すAmazon商品データを使用します。これにより、APIエンドポイントを呼び出すだけで、新鮮なAmazon商品データを取得することができます。
Firebase StudioとBright Dataがどのように連携し、CamelCamelのようなウェブ体験を素早く作り上げるかをご覧ください!
Firebase StudioでCamelCamelCamelのようなAmazon価格トラッカーを構築する方法
以下の手順に従って、Amazonの価格を追跡するCamelCamelCamelのようなWebアプリの作成方法を学びましょう。Bright DataをFirebase Studioプロトタイプに統合します!
前提条件
このチュートリアルに従うには、以下のものが必要です:
- Googleアカウント
- Firebase Studioアカウント
- Gemini APIキー
- API経由で接続できるように設定されたFirestoreデータベース
- APIキーが設定されたBright Dataアカウント
注意: すべての設定はまだ必要ありません。
以下のものも必要です:
- TypeScriptによるNext.js開発の知識
- Bright DataスクレイパーAPIの仕組みに精通していること(詳細はBright Dataのドキュメントを参照)
ステップ #1: Firebase Studioのセットアップ
Firebase Studio のウェブサイトにアクセスし、”Get Started” ボタンをクリックします:

Googleアカウントでログインするよう求められます。Googleアカウントでログインするよう求められます。
ログインすると、アプリの作成ページに移動します:
ここで、AIにプロジェクトを初期化するよう依頼するプロンプトを入力できます。素晴らしい!
ステップ2:プロンプトを工夫する
ここでの目標は、CamelCamelCamelの代替アプリを作ることです。簡単に言うと、このウェブアプリは、ユーザーが商品リストからアマゾンの商品価格を監視できるようにする必要があります。
Firebase Studio(またはv0)のようなソリューションで作業する場合、プロンプトエンジニアリングが鍵となります。ですから、可能な限り最高のプロンプトを作るために時間をかけてください。高品質な結果を得るには、構造化されたプロンプトが必要です。以下はベストプラクティスです:
- 核となる機能だけに集中する。機能を増やせば増やすほど、ごちゃごちゃしたデバッグしにくいコードになる危険性が高まります。
- 使用したい技術(フロントエンド、バックエンド、データベースなど)を明確に記載する。
- Bright Dataとの統合は後で行うことを明記してください。今は、モックロジックで十分です。
- 番号付きのリストを使って、主なタスクを分解してください。
- プロンプトは詳細に、しかし簡潔に。長くなりすぎるとAIが混乱してしまいます。
これはプロンプトの例です:
## ゴール
Amazonの商品価格をトラッキングするNext.jsウェブアプリを作る。
## 要件
### 1.ランディングページ
- きれいなUIと、ユーザーがAmazonの商品URLを送信できるフォームを持つインデックスページ。
### 2.データ処理
- ユーザーがURLを送信すると
- モックされたAPIエンドポイント(Bright DataのAmazonスクレイパーを表す)を呼び出し、商品の詳細を取得する:
- URL
- タイトル
- 価格
- 画像
- ASIN
- ...
- この商品データをFirestoreに保存します。
- 各商品を表示するカードリストを持つ商品ダッシュボードに商品を追加します。クリックすると、各商品カードが特定の商品ページにつながるようにします。
### 3.価格トラッキング
- 保存された各商品について、モックされたBright Data APIを再コールするスケジュールされたジョブ(例えば、1日1回)を作成します。
- 商品のASINをIDとして使用し、価格履歴に追加して、Firestoreに新しい価格レコードを保存します。
### 4.商品ページ
- 商品ページに、以下の表を表示します:
- 商品情報(タイトル、画像、URLなど)
- 最新価格
- 価格履歴(表の行として、または価格の推移を示すシンプルなグラフが理想的です)
---
**重要**:
- 外部 Bright Data API 呼び出しを、静的な JSON を返すモック関数として実装します。後でこれらを実際のAPI統合に置き換えます。
## 技術スタック
- Next.jsとスタイリング用のTailwindCSS
- Firestoreをデータベースとして使用("products "というコレクションを使用)
## アクション
ページ、Firestoreスキーマ、モックされたAPI関数、毎日の価格更新のためのスケジュールされた関数など、プロジェクト全体の構造を説明します。プロンプトがMarkdownフォーマットで書かれていることに注目してください。さらに、AIモデルは一般的にMarkdownをよく理解する。
上記のプロンプトの例は、すべてのベストプラクティスに従っており、AIが意図したアプリをうまく構築するのに役立ちます。完璧だ!
ステップ#3: プロンプトを実行し、初期のアウトプットを調べる
プロンプトをFirebase Studioの “Prototype an app with AI “テキストエリアに貼り付け、Enterキーを押します。
Firebase Studio App Prototyping エージェントが、主要な情報をすべて含むアプリのブループリントを生成します:
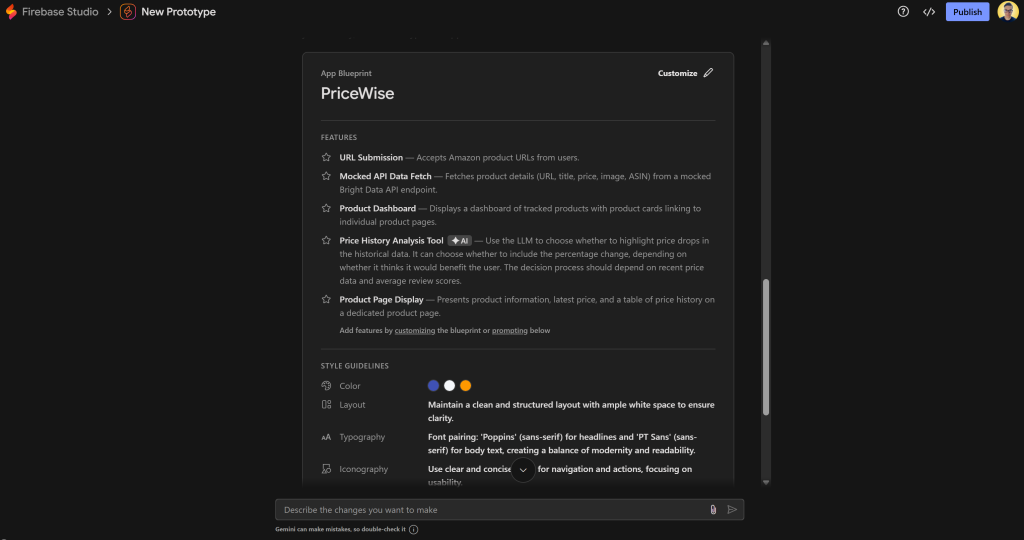
ニーズに合わせて自由にカスタマイズしてください。
準備ができたら、下にスクロールして “Prototype this App” ボタンをクリックし、AI にアプリの生成を指示します:
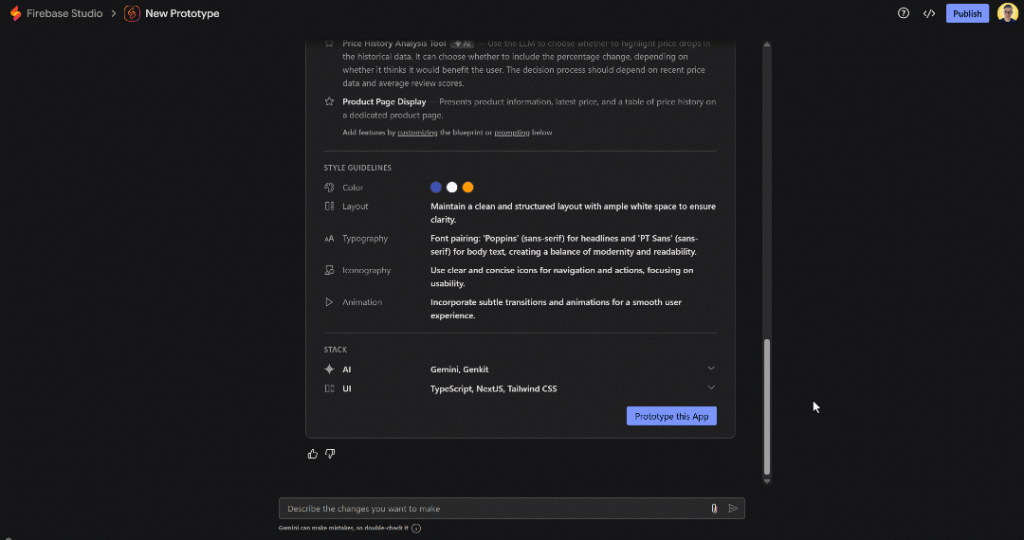
Firebase Studioは、Next.jsプロジェクトのファイルのビルドを開始します。数分かかる場合がありますので、しばらくお待ちください。
プロセスが完了すると、実行中のプロトタイプがプレビューウィンドウに表示されます:
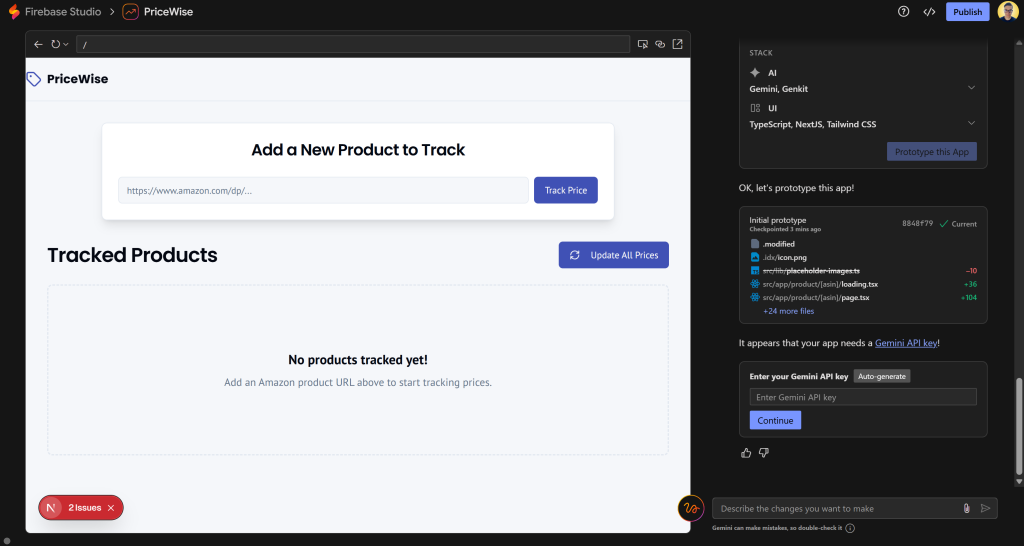
アプリのUIが、プロンプトで説明した構造と密接に一致していることに注目してください。アプリのUIが、あなたがプロンプトで説明した構造と密接に一致していることに注目してください!
ステップ #4: Geminiインテグレーションを完了する
左下に、Gemini APIキーを入力してGemini統合を完了するよう求めるプロンプトが表示されます:
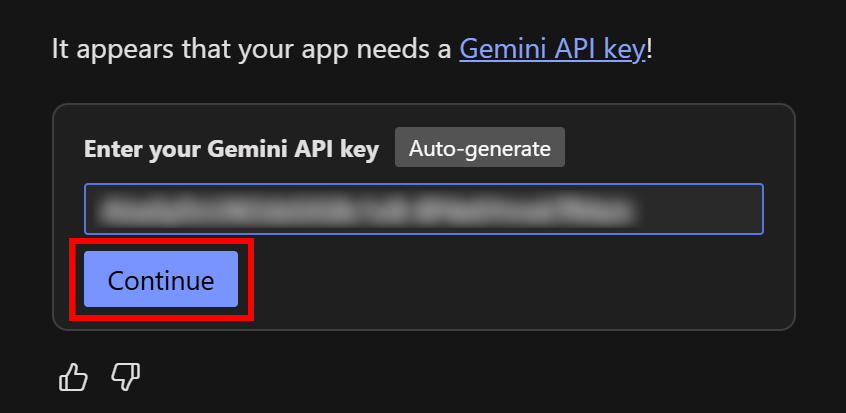
Google AI StudioからGemini APIキーを取得し、フィールドに貼り付けて、”Continue “ボタンを押してください。すべてが正しく動作すれば、このような成功メッセージが表示されるはずです:
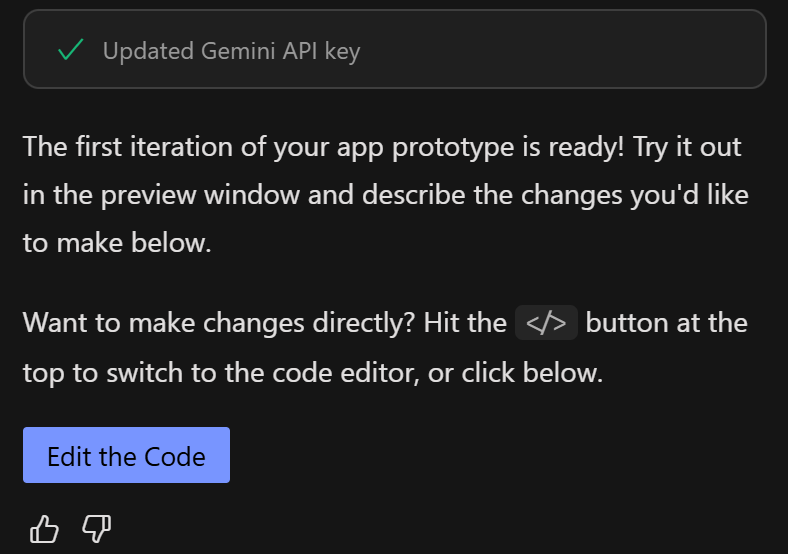
一方、Firebase Studioは自動的に開発環境(Visual Studio Codeベース)のロードを終了するはずです。そうでなければ、”Switch to Code “ボタンをクリックしてください。表示されるものは以下の通りです:
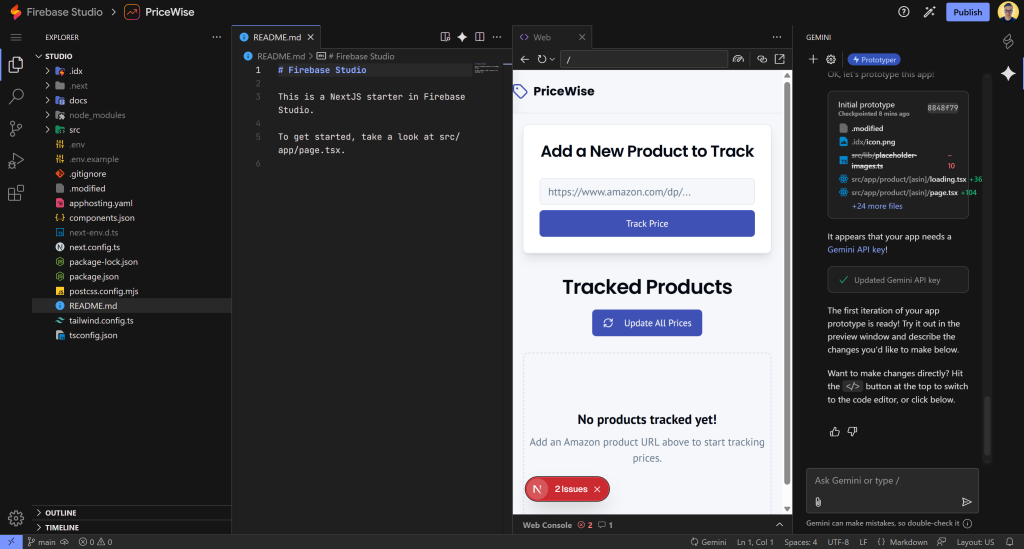
右側に、Geminiパネルが表示されます。ここから、ビルド中にGeminiにコンテキストに沿ったヒント、新機能、修正、ガイダンスを求めることができます。よくできました!
ステップ #5: 問題を修正する
Web “プレビュータブ(前のスクリーンショットに表示)を見てわかるように、現在のアプリケーションには2つの問題があります。AIが生成したコードが完璧であることは稀で、通常は微調整や修正が必要だからです。
先に進む前に、報告された問題を確認してください。アプリのNext.jsビジュアル要素を使用して、何が壊れているかを特定し、1つずつ修正してください。結局のところ、壊れたアプリの上に構築してもあまり意味がありません。
サーバー側のデバッグについては、「OUTPUT」パネルのログを確認してください。Ctrl + <backtick>を押して、ターミナル・セクションを開く。そこで “OUTPUT “タブに切り替え、”Previews “要素を選択します:
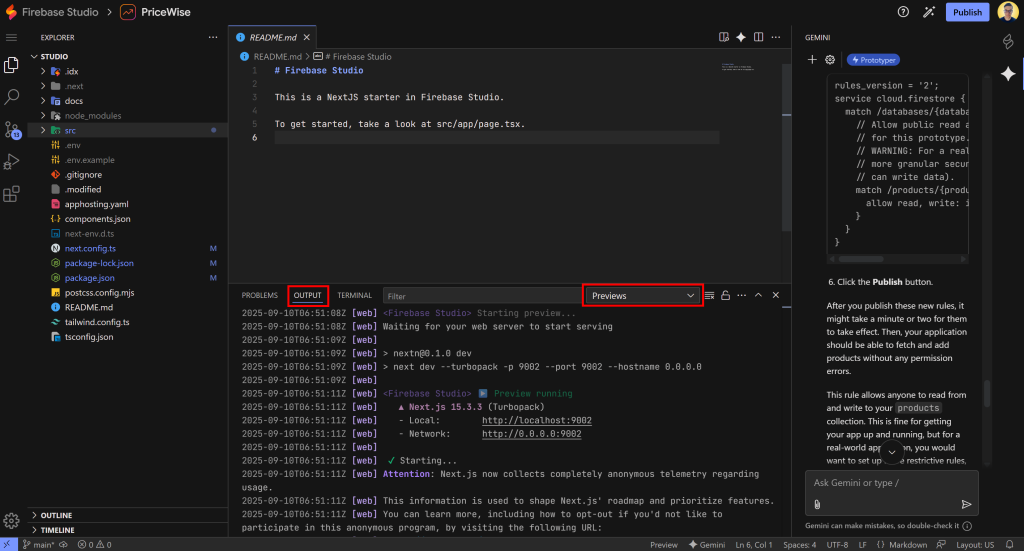
覚えておいてください: これらの問題を解決するために、Geminiにエラーを直接問い合わせることもできます。
すべての問題を修正すると、アプリはこのようになるはずです:
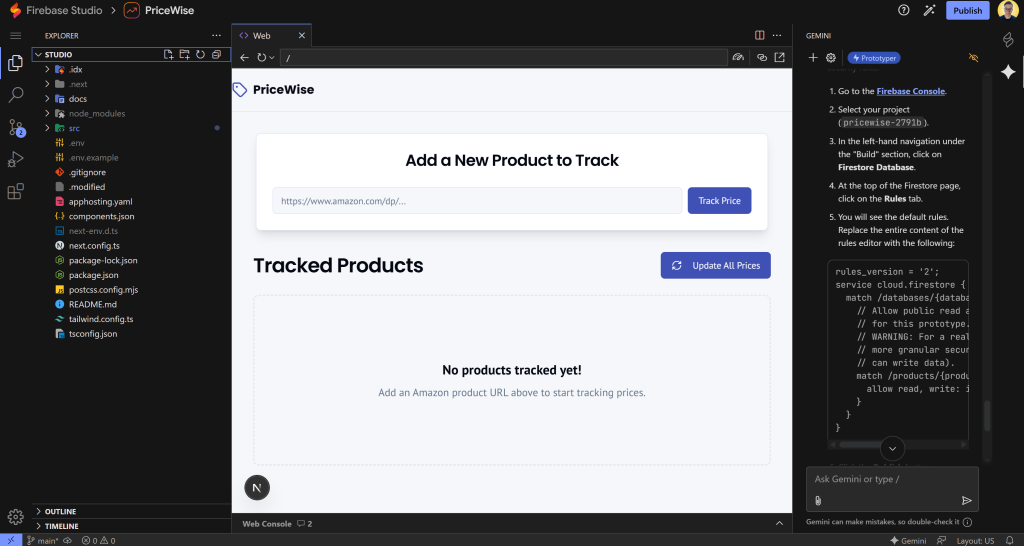
左上の「Issues」インジケータが消えていることに注目してください。これは、Next.jsの問題がすべて解決されたことを意味します!
ステップ #6: Firestoreの設定
Firebase Studio の大きな特徴のひとつは、Firebase 環境で直接動作するため、他のすべてのFirebase 製品と簡単に統合できることです。
このプロジェクトでは、Firestore データベースをセットアップして、アプリがデータを読み込んで保存し、状態を追跡できるようにする必要があります。これは、プロンプトでFirestoreがデータベース技術として指定されているため、必要です。
ヒント統合を簡素化するために、Geminiにタスク全体のガイドを依頼することができます。
まずFirebaseにログインし、新しいプロジェクトを作成します:
プロジェクト名を付け、プロジェクト作成ウィザードに従ってください。Firebaseがプロジェクトの作成を開始します:
アプリを追加” ボタンを押し、ウェブアプリのアイコンを選択すると、新しいFirebase ウェブアプリが初期化されます:

ウェブアプリに名前を付け、指示に従ってください。最後に、Firebaseの設定を含む接続スニペットが表示されます:
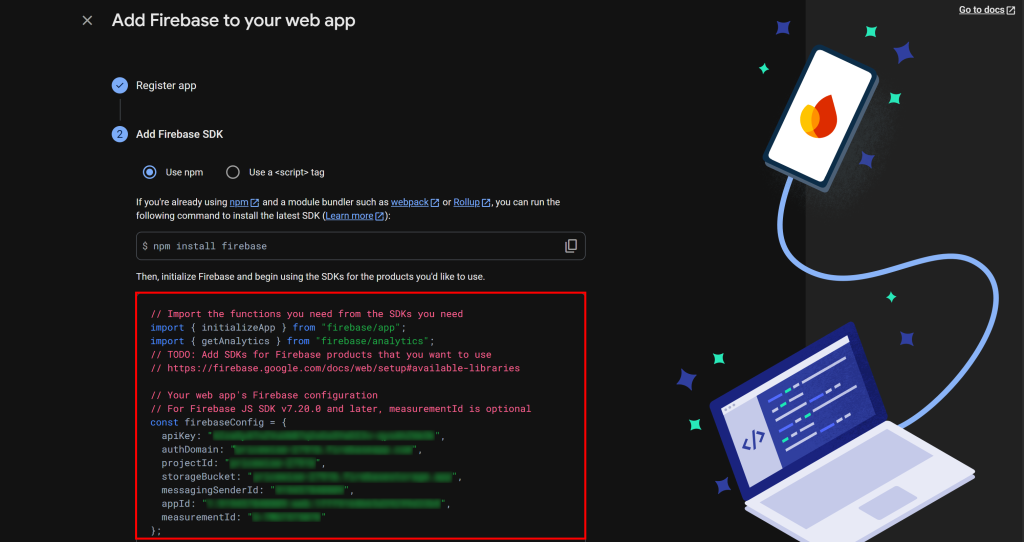
プロトタイプアプリを Firebase に接続するために必要なので、firebaseConfigオブジェクトからこれらの認証情報を安全な場所に保存してください。
次に、Firebase Console のプロジェクトページの “Build” セクションで、”Firestore Database” オプションを選択します:
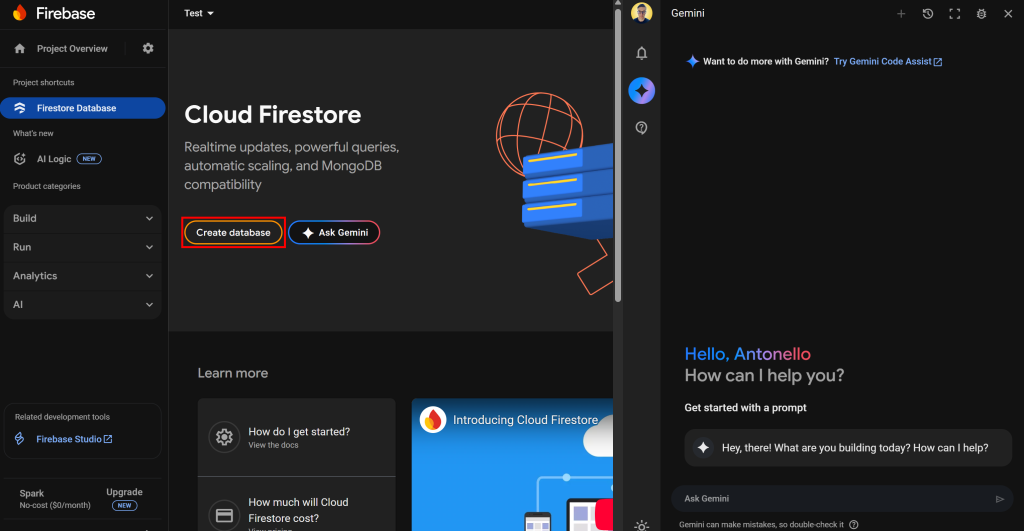
Create database “ボタンをクリックし、本番モードで標準データベースを初期化します:
Firestoreページの上部で、”Rules “タブに到達します。以下のルールを追加し、読み取りと書き込みを許可します:
rules_version = '2';
サービスcloud.firestore {
match /データベース/{データベース}/ドキュメント { /{ドキュメント=**}にマッチする。
match /{document=**}{
読み取り、書き込みを許可する;
}
}
}そして、”Publish “をクリックしてルールを更新する:
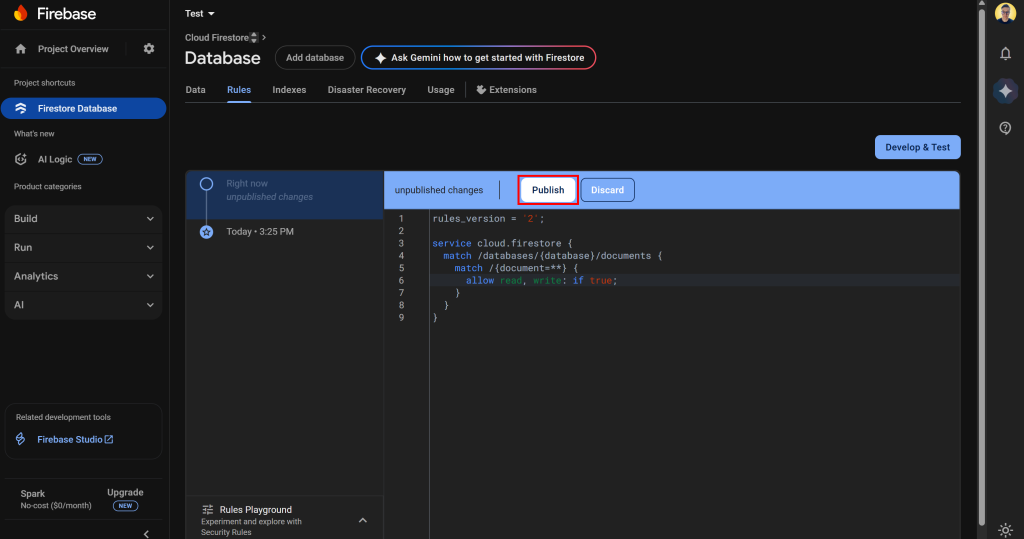
注意:これらのルールはデータベースを公開するので、誰でもデータを読んだり、変更したり、削除したりすることができます。プロトタイプではこれでよいのですが、本番ではより安全できめ細かいルールを構成する必要があります。
productsという新しいコレクションを作成します(プロンプトで指定された名前と同じです):
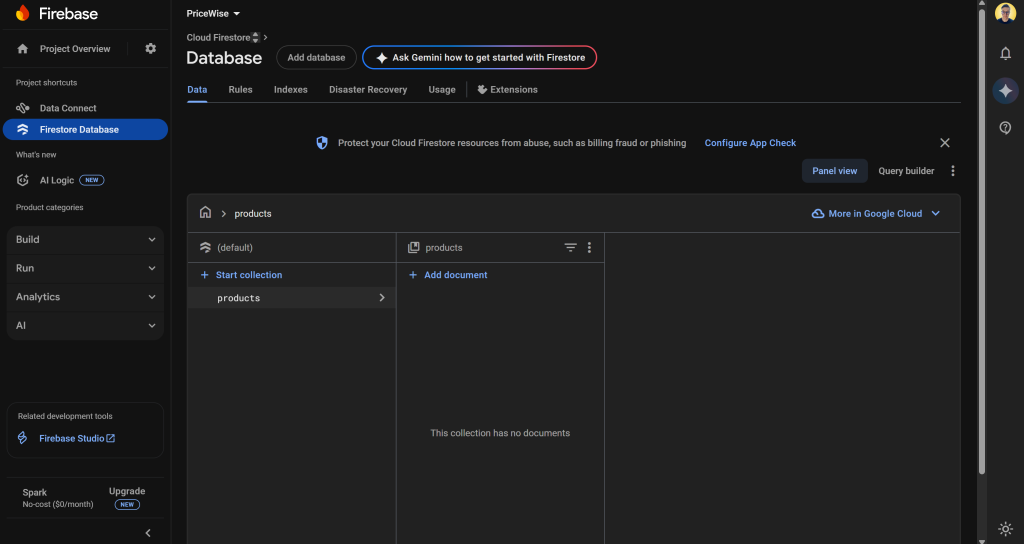
新しいエントリを作成し、asincフィールドを文字列キーとして設定します。アプリケーションがFirestoreに正常に書き込めることをテストしたら、このサンプルエントリを忘れずに削除してください。
次に、Google Cloud Console で “Google Cloud Firestore API” ページに移動します。ここで API を有効にします:
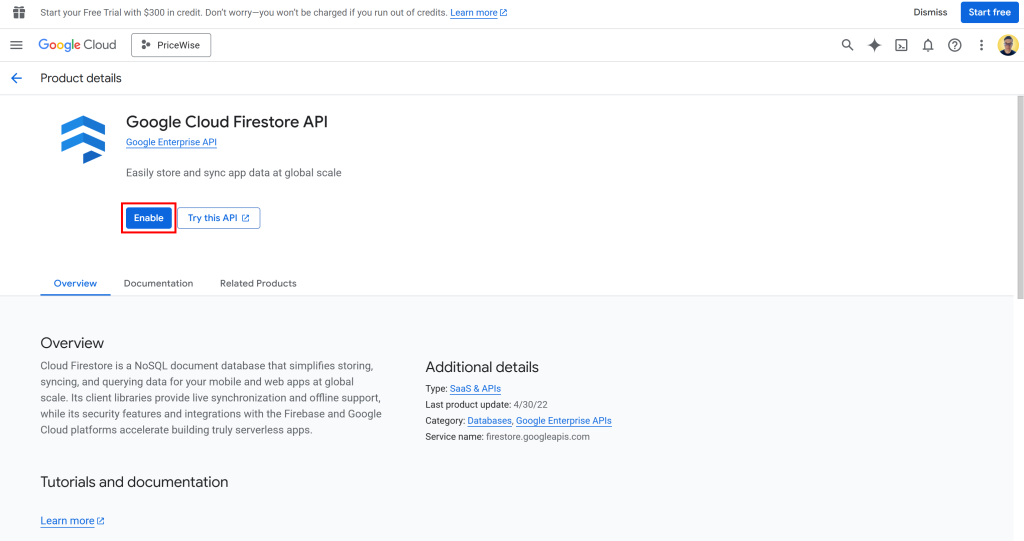
firebaseConfigオブジェクトで指定したapiKeyフィールドが、Firestore データベースへの接続に使用できるようになります。
これで完了です!これでFirebase StudioアプリにFirestoreデータベースを統合する準備ができました。
ステップ #7: Firestore に接続する
Firebase Studioに戻ってプロジェクトを確認します。ファイル構造のどこかに、Firestore 接続用のファイルがあるはずです。この場合はsrc/lib/firebase.ts です:
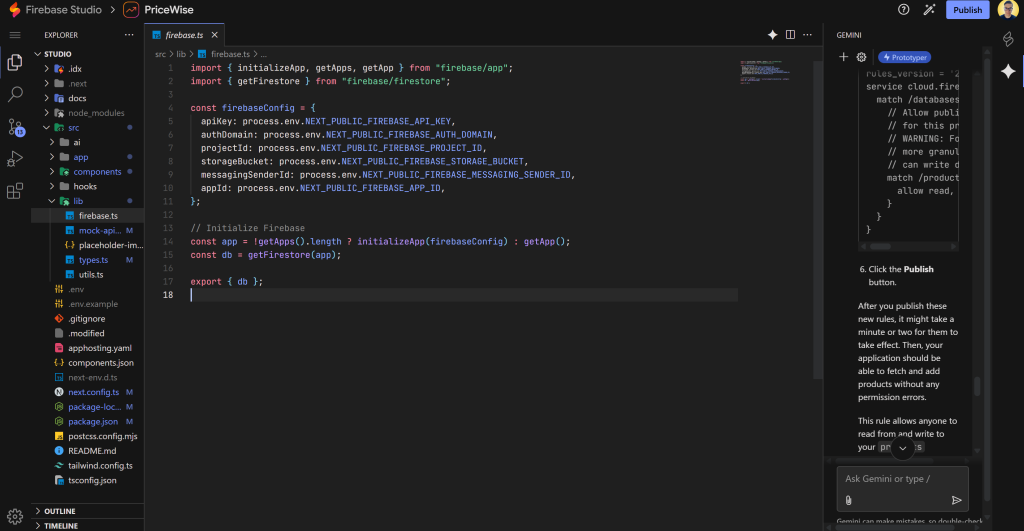
おわかりのように、このファイルは、Firebase接続の認証情報がNext.jsのパブリック環境変数で定義されていることを想定しています。.envファイルに追加してください(AIによって作成されているはずです:)
next_public_firebase_api_key="<your_firebase_api_key>"
next_public_firebase_auth_domain="<your_firebase_auth_domain>"
next_public_firebase_project_id="<firebase_project_id>"
next_public_firebase_storage_bucket="<your_firebase_storage_bucket>"
next_public_firebase_messaging_sender_id="<your_firebase_messaging_sender_id>"
next_public_firebase_app_id="<your_firebase_app_id>"注意: これらの値は、先ほど取得したfirebaseConfigオブジェクトから取得したものです。
Web “タブで、ハードリスタートを行い、すべての変更が適切にリロードされることを確認します。これでFirebaseアプリケーションはFirestoreに接続できるはずです。
アプリケーションがproductsコレクション上で正しく動作していることを確認したい場合は、コードを調べてみてください。このように表示されるはずです:
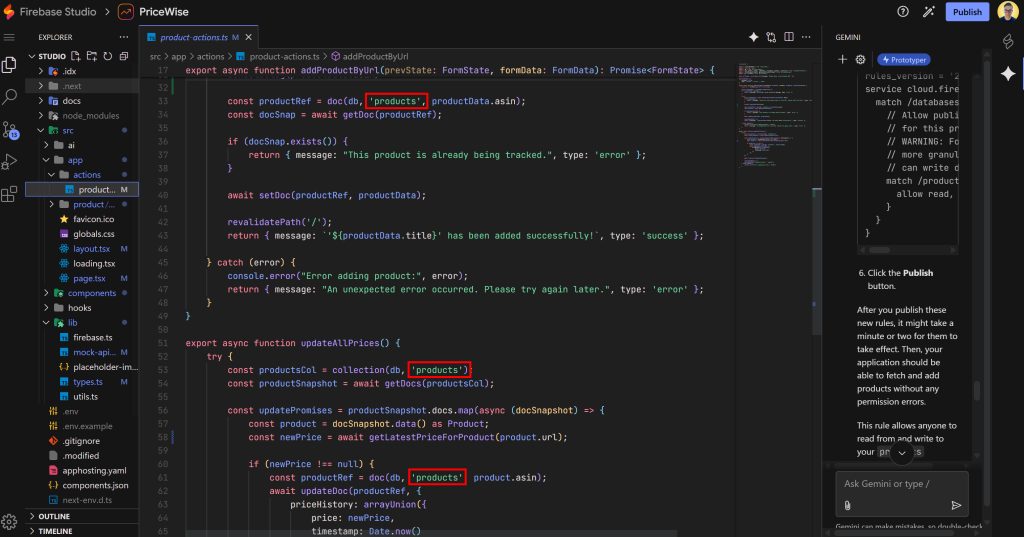
アプリケーションがproductsコレクション上で意図したとおりに動作していることがわかります。
素晴らしい!プロトタイプの完成に一歩近づきました。
ステップ#8: Brightデータを統合する
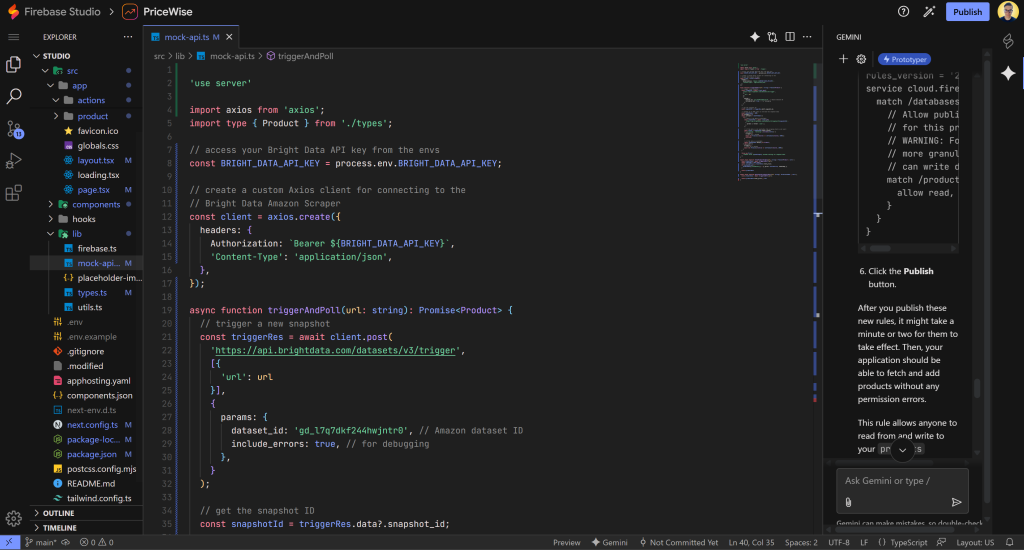
現在、Amazonの商品情報と価格の取得ロジックはモック化されています(この場合、src/lib/mock-api.tsファイル):
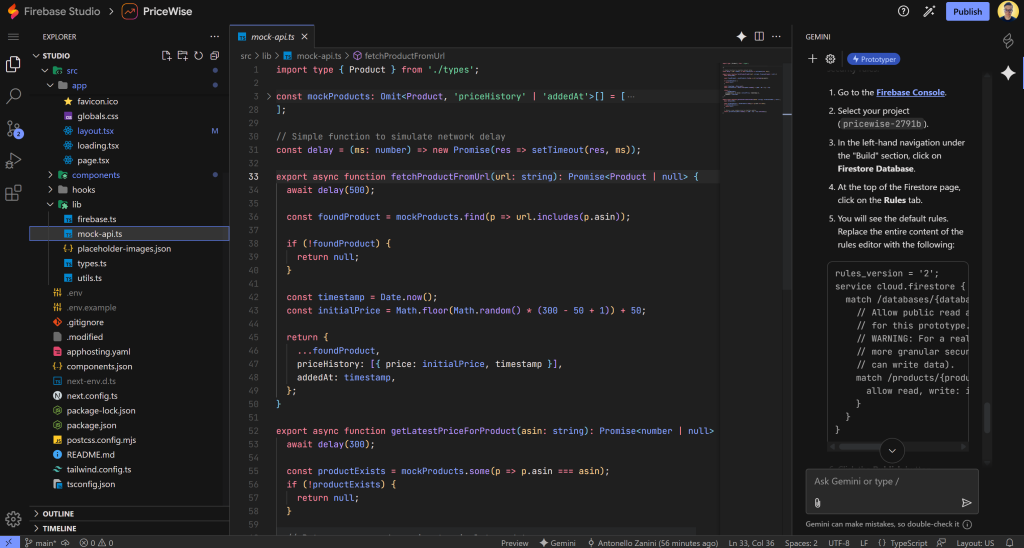
このファイルには、”Track Price “と “Update All Prices “ボタンのビジネスロジックで呼び出される2つの主要な低レベルデータ検索関数が含まれています:
具体的には、mock-api.tsは2つの関数を定義しています:
fetchProductFromUrl():与えられた商品URLからAmazonの商品情報をフェッチするモック。getLatestPriceForProduct():指定されたAmazon商品の最新価格を取得するモック。
次に行うことは、このモックロジックをAPI経由でBright DataのAmazonスクレイパーを実際に呼び出すことに置き換えることです。
Bright Dataのアカウントにログインするか、新規アカウントを作成します。Amazon Products – Collect by URL” スクレイパーの “API Request Builder” タブに移動します。Node (Axios)” オプションを選択し、商品データを取得するためにAPIを呼び出す方法を示すコードスニペットを取得します:
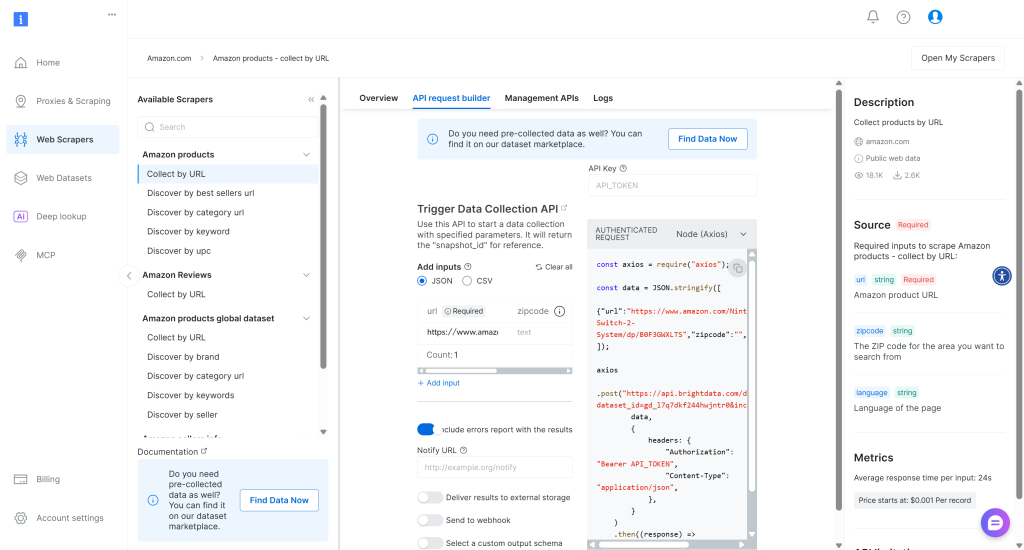
Bright DataのウェブスクレイパーAPIがどのように機能するかご存じない方のために、簡単に説明しましょう。
まず、/triggerエンドポイントを使用してスクレイピングタスクをトリガーし、指定された商品URLのスクレイピングスナップショットを作成します。スナップショットが開始されると、snapshot/{snapshot_id}エンドポイントを使用して定期的にステータスをチェックし、スクレイピングされたデータが準備できているかどうかを確認します。準備ができたら、同じAPIを呼び出してスクレイピングされたデータを取得する。
これらのウェブスクレイパーAPIは、Bright Data APIキーで認証することで、プログラムから呼び出すことができます。公式ガイドに従ってキーを取得し、.envファイルに以下のように追加する:
bright_data_api_key="<your_bright_data_api_key>"基本的に、必要なことは以下の通りだ:
- 製品のURLで
/triggerエンドポイントを呼び出し、Bright Data APIトークンを使用して認証し、新しいスクレイピングタスクを開始します。 snapshot/{snapshot_id}でポーリング処理を開始し、スクレイピングされたデータを含むスナップショットの準備ができたかどうかを定期的にチェックする。- スナップショットの準備ができたら、Amazonの商品データにアクセスします。
まず、Axios HTTPクライアントをプロジェクトにインストールします:
npm install axios
次に、src/lib/mock-api.tsの内容を以下のロジックに置き換える:
'use server'
import axios from 'axios';
import type { Product } from './types';
// envからBright Data APIキーにアクセスする
const BRIGHT_DATA_API_KEY = process.env.BRIGHT_DATA_API_KEY;
// に接続するためのカスタムAxiosクライアントを作成します。
// Bright Data Amazonスクレイパーに接続するためのカスタムAxiosクライアントを作成する。
const client = axios.create({
ヘッダ{
Authorization: `ベアラ ${BRIGHT_DATA_API_KEY}`、
'Content-Type': 'application/json'、
},
});
async function triggerAndPoll(url: string):Promise<Product> { // 新しいスナップショットをトリガーする。
// 新しいスナップショットをトリガする
const triggerRes = await client.post(
'https://api.brightdata.com/datasets/v3/trigger'、
[{
'url': url
}],
{
params:{
dataset_id: 'gd_l7q7dkf244hwjntr0', // AmazonのデータセットID
include_errors: true, // デバッグ用
},
}
);
// スナップショットIDを取得
const snapshotId = triggerRes.data?.snapshot_id;
// スナップショット・データの取得を最大600回試みる
const maxAttempts = 600;
let attempts = 0;
while (attempts < maxAttempts) { // 600回までスナップショットデータの取得を試みる。
try {
// データが利用可能かチェックする
const snapshotRes = await client.get(
`https://api.brightdata.com/datasets/v3/snapshot/${snapshotId}`、
{
params:params: { format:'json' }、
}
);
// データが利用できない場合(スクレイピングタスクが終了していない場合)
const status = snapshotRes.data?.status;
if (['running', 'building'].includes(status)) { // スクレイピングタスクが終了していない。
attempts++;
// 1秒間待つ
await new Promise((resolve) => setTimeout(resolve, 1000));
続行します;
}
// データが利用可能な場合
return snapshotRes.data[0] as Product;
} catch (err) { // データが利用可能な場合
attempts++;
// 1秒間待つ
await new Promise((resolve) => setTimeout(resolve, 1000));
}
}
throw new Error(
スナップショットデータの待ち時間が${maxAttempts}秒後にタイムアウトしました`。
);
}
export async function fetchProductFromUrl(url: string):Promise<Product | null> { {商品データを取得します。
const productData = await triggerAndPoll(url);
const timestamp = Date.now();
const initialPrice = productData.final_price;
if (initialPrice) { { productData['priceHistory
productData['priceHistory'] = [{ price: initialPrice, timestamp }].
}
return productData
}
export async function getLatestPriceForProduct(url: string):Promise<number | null> { {プロダクトデータ
const productData = await triggerAndPoll(url);
return productData.final_price || null
}
新しい実装では、Axiosを使用してBright Dataに接続し、指定されたURLのスナップショットをトリガーし、データが準備できるまでポーリングし、商品情報を返します。
triggerAndPoll()ユーティリティは、Bright DataスクレイパーAPIからのデータ取得ロジック全体を処理します。fetchProductFromUrl()は、初期価格履歴を含む完全な商品オブジェクトを返し、getLatestPriceForProduct()は、final_priceフィールドから読み取った現在の価格のみを返します。
Bright Data AmazonスクレイパーAPIによって返されるフィールドを理解するには、ダッシュボードの “概要 “セクションを参照してください:
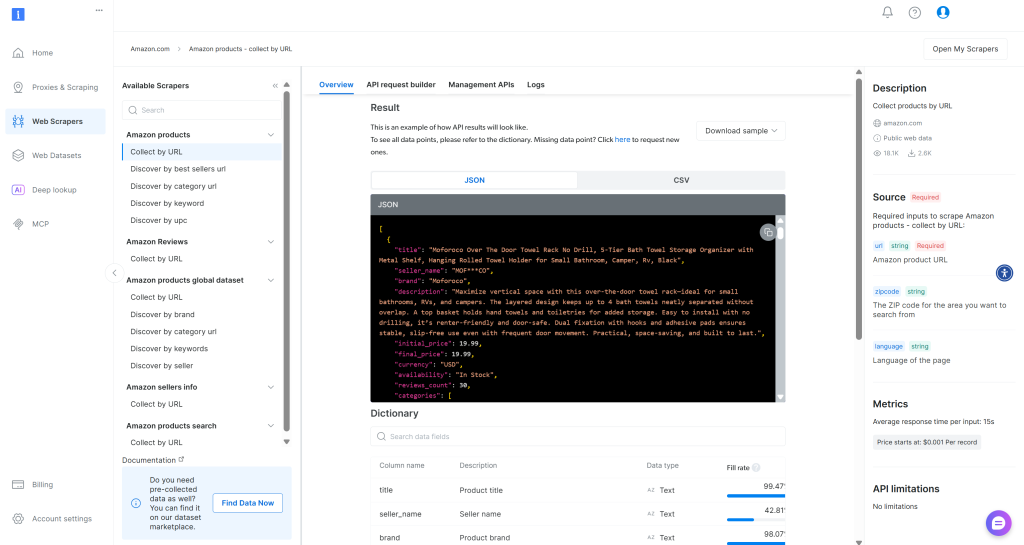
サンプルのJSONをGeminiに送り、それに応じてTypeScriptのProductタイプを更新するようAIに依頼します:
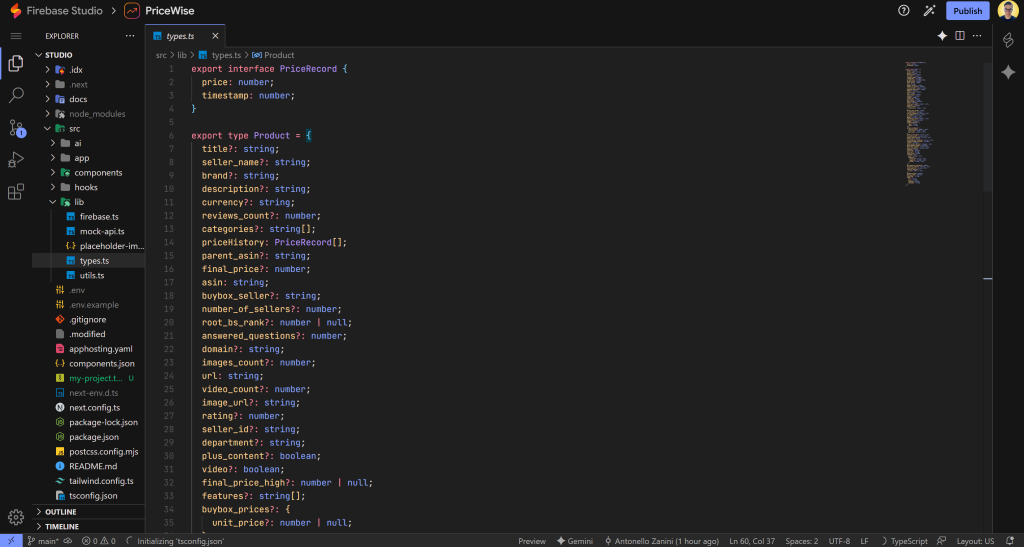
素晴らしい!これ以上のステップは必要ありません。この時点で、アプリケーションは完全に機能し、ライブの商品データが取得され、表示され、テストする準備ができているはずです。
ステップ #9: プロトタイプアプリのテスト
CamelCamelCamelの代用品が完成しました。完全なコードは、この記事をサポートしているGitHubリポジトリにあります。それをクローンしてください:
git clone https://github.com/Tonel/price-wiseこれはMVP(Minimal Viable Product)以外の何物でもありませんが、あなたのアイデアを探求し、さらには本番用のアプリケーションに拡張するのに十分な機能を備えています。
コードベースのすべてのアップデートが適用されていることを確認するために、ハードリスタートを実行してください:

次に、”新しいウィンドウで開く “アイコンをクリックします:

これで、Firebase Studioプロトタイプに専用ブラウザタブでアクセスできるようになります:
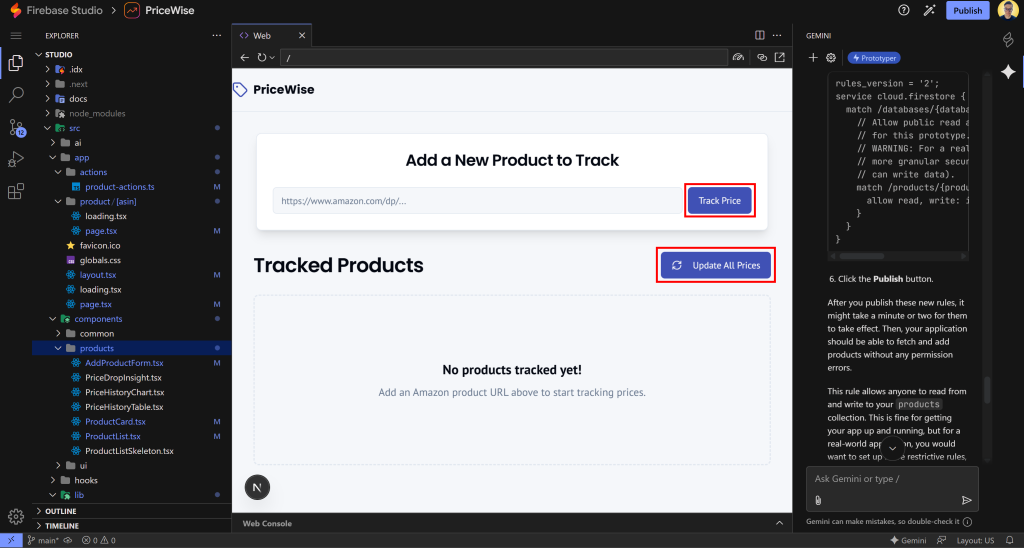
Amazonの商品URLを貼り付け、”Track Price “ボタンを押して、CamelCamelのようなウェブアプリをテストします:
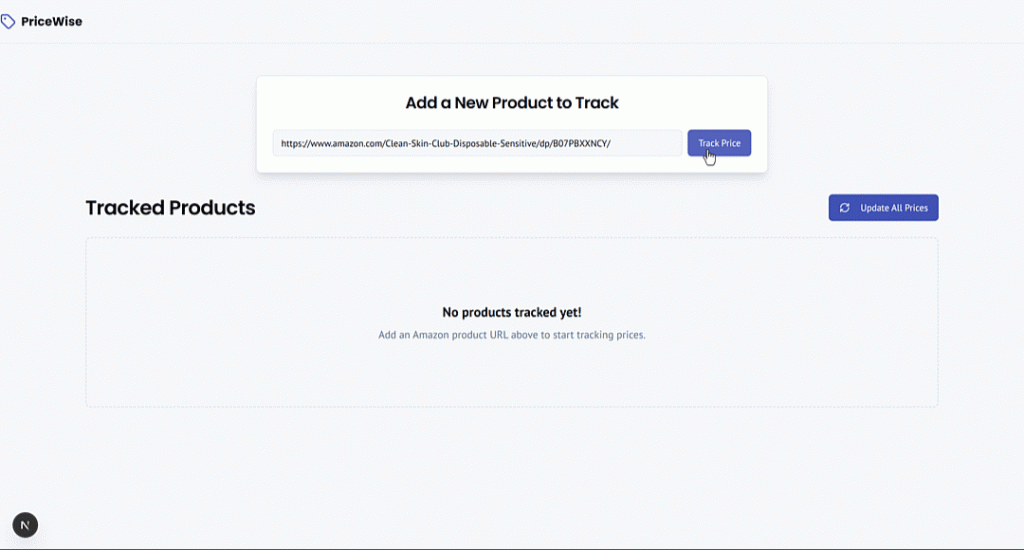
その商品は “Tracked Products “セクションに追加され、Amazonのページに表示されている通りのデータが表示されます。
これはBright Data WebスクレイパーAPIの威力を示しており、数秒で商品データを取得することに成功しています。
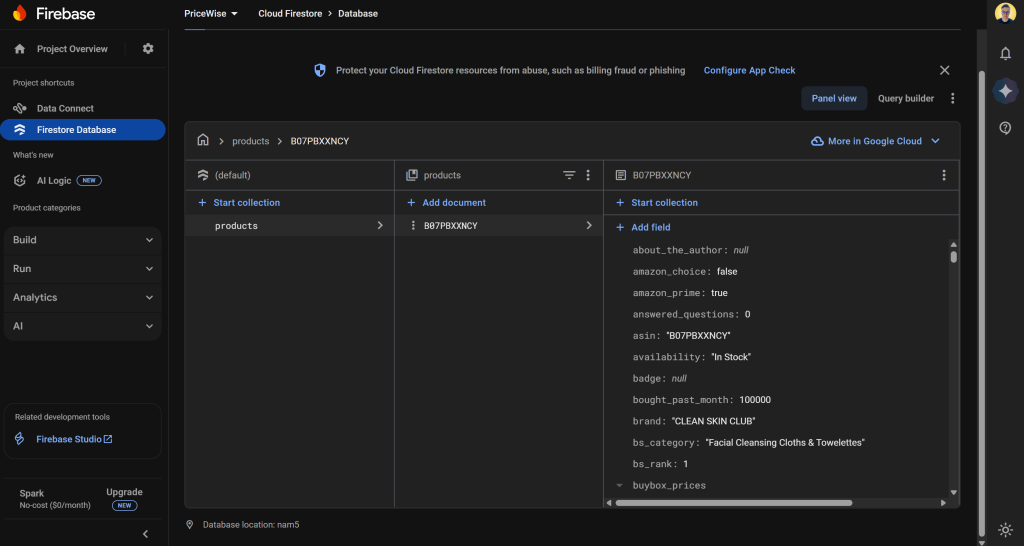
商品データがFirestoreデータベースに保存されていることを確認してください:
さて、数日が経過し、価格が変動したとします。商品ページにアクセスし、更新された価格を確認してください:
さらに詳しく言うと、商品ページには、その商品の価格の推移を示すチャートとテーブルの両方が含まれていることに注目してください:
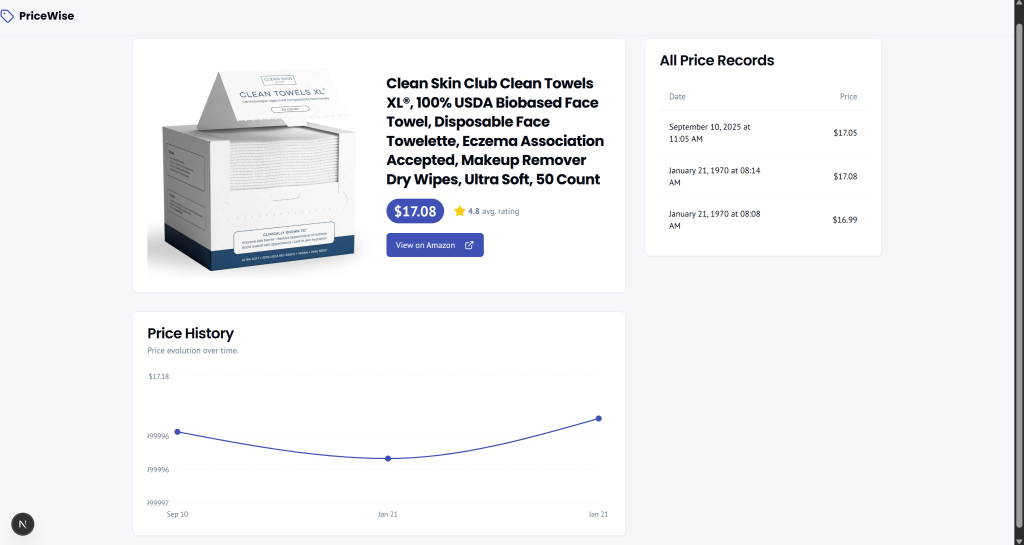
印象的でしょう?
どうです!わずか数分とわずかなコードで、Amazon商品価格追跡のためのCamelCamelCamelスタイルのウェブアプリを構築することができました。Bright Dataのリアルタイムのウェブデータ機能とFirebase Studioのシンプルな開発環境がなければ、このようなことはできなかったでしょう。
次のステップ
ここで作られたアプリケーションはプロトタイプに過ぎません。本番環境に対応させるには、次のステップを検討してください:
- 認証を統合する:Firebase Authenticationを使用してログインシステムを素早く追加し、各ユーザーが自分の製品を保存、監視できるようにする。
- さらに機能を追加する:新しい機能をリクエストしてGeminiで反復を続けるか、プロジェクトコードをダウンロードして手動で追加機能を統合します。
- アプリを公開する:Firebase Studio が提供するデプロイオプションのいずれかを使用してアプリケーションを公開します。
まとめ
このブログポストでは、Firebase StudioのAI主導のアプリ構築機能により、わずか数分でCamelCamelの競合サイトを作成できることをご覧いただきました。これは、Bright DataのAmazonスクレイパーのような、Amazonの商品と価格データの信頼性が高く、統合しやすいソースがなければ不可能です。
私たちがここで構築したものは、スクレイピングデータとダイナミックなAI生成ウェブアプリを組み合わせたときに何が可能になるかのほんの一例に過ぎません。同様のアプローチは、他の無数のユースケースにも適用できることを覚えておいてほしい。必要なのは、ニーズに合ったデータにアクセスするための適切なツールだけだ!
なぜここで止めるのか?当社のウェブスクレイパーAPIは、120以上の人気のあるウェブサイトから、新鮮で構造化され、完全に準拠したウェブデータを抽出するための専用エンドポイントを提供します。
今すぐ無料のBright Dataアカウントにサインアップして、AIのためのウェブデータ検索ソリューションを構築しましょう!





