

ウェブスクレイピングに興味があるなら、HTMLの理解が鍵となります。なぜなら全てのウェブサイトはHTMLで構築されているからです。ウェブスクレイピングは様々なシナリオで活用でき、APIのないウェブサイトからのデータ収集、製品価格の監視、見込み顧客リストの作成、学術研究の実施などに役立ちます。
この記事では、HTMLの基本と、Pythonを使用したデータの抽出・パース・処理方法を学びます。
詳細なPythonウェブスクレイピングガイドに興味がありますか?こちらをクリックしてください。
ウェブサイトのスクレイピングとHTML抽出の方法
チュートリアルを始める前に、HTMLの主要な構成要素を簡単に復習しましょう。
HTML入門
HTMLは、ウェブサイトの構造や要素をブラウザに伝えるタグの集合体です。例えば、<h1> テキスト </h1>はタグに続くテキストがヘッディングであることをブラウザに伝え、<a href=""> リンク </a>はハイパーリンクを識別します。
HTML属性はタグに関する追加情報を提供します。例えば、<a> </a>タグのhref属性は、その属性が指すページのURLに関する情報を示します。
クラスとIDは、ページ上の要素を正確に識別するための重要な属性です。クラスは類似した要素をグループ化し、CSSで一貫したスタイルを適用したり、JavaScriptで統一的に操作したりします。クラスは.class-name で指定します。
W3Schoolsウェブサイトでは、クラスグループは次のように記述されます:
<div class="city">
<h2>ロンドン</h2>
<p>ロンドンはイングランドの首都です。</p>
</div>
<div class="city">
<h2>パリ</h2>
<p>パリはフランスの首都です。</p>
</div>
<div class="city">
<h2>東京</h2>
<p>東京は日本の首都です。</p>
</div>
各タイトルと都市ブロックが、同じcityクラスを持つdivで囲まれていることがわかります。
一方、IDは各要素に固有のもので(つまり、2つの要素が同じIDを持つことはできません)、例えば以下のH1要素は固有のIDを持ち、個別にスタイル設定や操作が可能です:
<h1 id="header1">Hello World!</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>
IDで要素を指定する構文は#id-name です。
HTMLの基本を理解したところで、ウェブスクレイピングを始めましょう。
スクレイピング環境のセットアップ
このチュートリアルではPythonを使用します。Pythonには多くのHTMLスクレイピングライブラリが用意されており、言語自体も習得しやすいからです。お使いのコンピュータにPythonがインストールされているか確認するには、PowerShell(Windows)またはターミナル(macOS)で次のコマンドを実行してください:
python3
Pythonがインストールされている場合はバージョン番号が表示され、インストールされていない場合はエラーが表示されます。Pythonがインストールされていない場合は、インストールしてください。
次に、WebScraperというフォルダを作成し、その中にscraper.py というファイルを作成します。その後、お好みの統合開発環境(IDE)でこのファイルを開きます。ここではVisual Studio Codeを使用します:
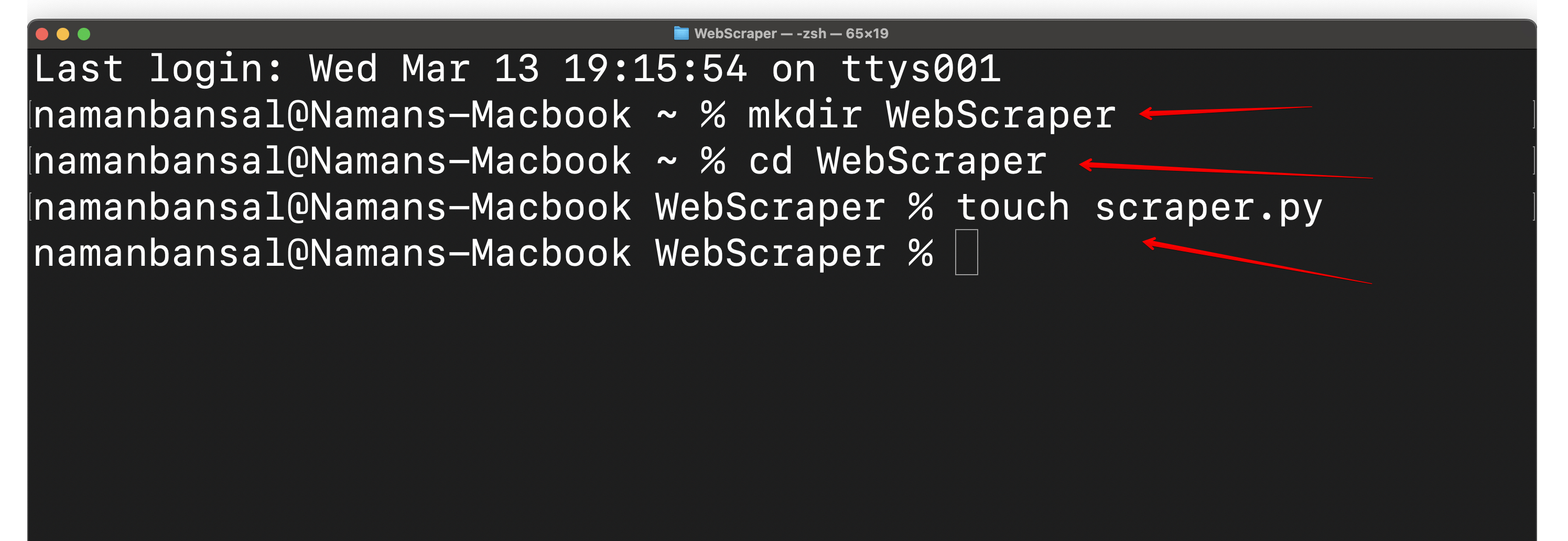
IDE(統合開発環境)とは、プログラマーがコードの記述、デバッグ、プログラムのテスト、自動化の構築などを行うための多目的アプリケーションです。ここではHTMLスクレイパーのコーディングに使用します。
次に、仮想環境を作成して、グローバルなPythonインストールとスクレイピングプロジェクトを分離する必要があります。これにより、依存関係の競合を回避し、アプリケーション全体を整理できます。
以下のコマンドでvirtualenvライブラリをインストールします:
pip3 install virtualenv
プロジェクトフォルダに移動します:
cd WebScraper
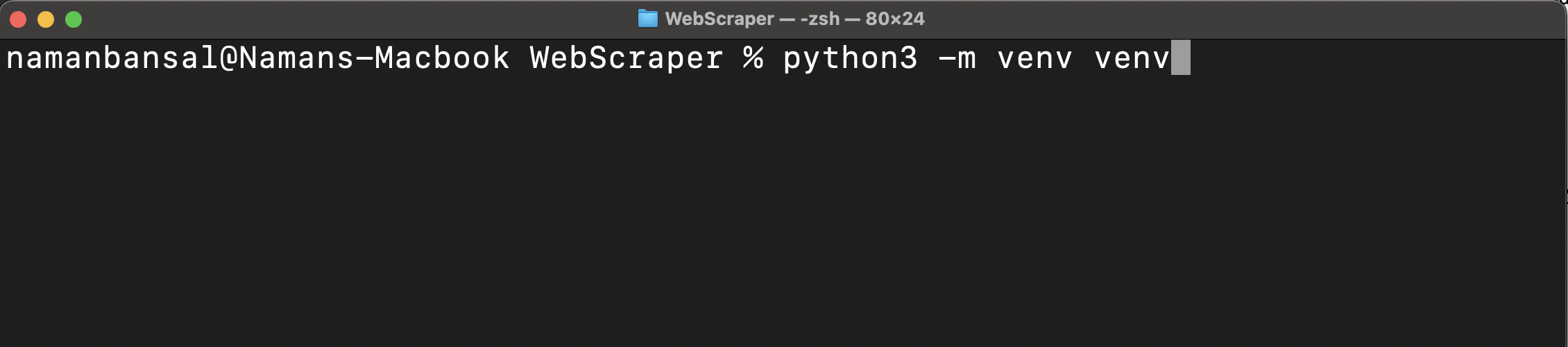
仮想環境を作成します:
python<バージョン> -m venv <仮想環境名>
このコマンドにより、プロジェクトフォルダ内に全てのパッケージとスクリプト用のフォルダが作成されます:
次に、お使いのプラットフォームに応じて以下のいずれかのコマンドで仮想環境を有効化します:
source <仮想環境名>/bin/activate #MacOSおよびLinuxの場合
<仮想環境名>/Scripts/activate.bat #CMDの場合
<仮想環境名>/Scripts/Activate.ps1 #PowerShellの場合
正常にアクティベートされると、画面左側に仮想環境名が表示されます:
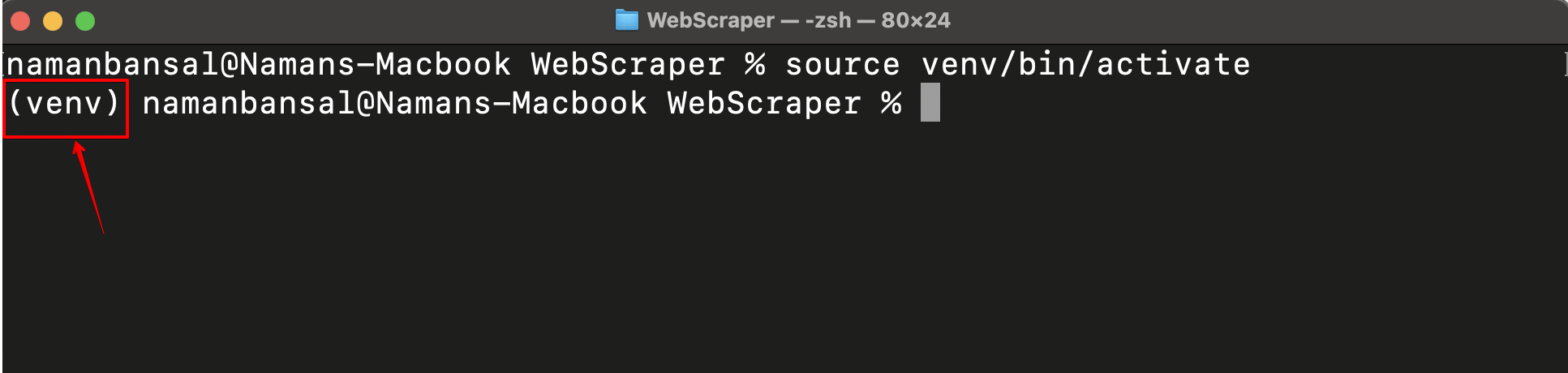
仮想環境がアクティブ化されたら、ウェブスクレイピングライブラリをインストールする必要があります。Playwright、Selenium、Beautiful Soup、Scrapyなど多数の選択肢がありますが、ここではPlaywrightを利用します。Playwrightは使いやすく、複数のブラウザをサポートし、動的コンテンツを処理でき、ヘッドレスモード(グラフィカルユーザーインターフェース(GUI)なしでのスクレイピング)を提供するためです。
Playwrightをインストールするには`pip install pytest-playwright`を実行し、必要なブラウザは`playwright install`でインストールします。
Playwrightのインストールが完了したら、ウェブスクレイピングを開始する準備が整います。
WebサイトからHTMLを抽出する
ウェブスクレイピングプロジェクトの最初のステップは、スクレイピング対象のウェブサイトを特定することです。ここではこのテストサイトを利用します。
次に、ページからスクレイピングしたい情報を特定します。このケースでは、ページの完全なHTMLコンテンツです。
スクレイピング対象情報を特定したら、スクレイパーのコーディングを開始できます。Pythonでは、まずPlaywrightに必要なライブラリをインポートします。Playwrightではsyncとasyncの2種類のAPIをインポートできます。asyncライブラリは非同期コード記述時のみ使用するため、以下のコマンドでsyncライブラリをインポートします:
from playwright.sync_api import sync_playwright
同期ライブラリをインポートした後、以下のコードスニペットを使用してPython関数を宣言します:
def main():
# 残りのコードはこの関数内に記述します
前述の注記からもわかるように、この関数内にウェブスクレイピングコードを記述します。
通常、ウェブサイトから情報を取得するには、ウェブブラウザを開き、新しいタブを作成してそのウェブサイトにアクセスします。サイトをスクレイピングするには、これらの操作をコードに変換する必要があり、そのためにPlaywrightを使用します。ドキュメントによると、先にインポートしたsync_apiを呼び出し、以下のスニペットでブラウザを開くことができます:
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
角括弧内に`headless=False`を追加することで、ウェブサイトのコンテンツを表示できるようになります。
ブラウザを開いたら、新しいタブを開き対象URLにアクセスします:
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
注:上記のコードは、ブラウザを起動した前の行の下に追加する必要があります。このコード全体はmain関数内、かつ1つのファイル内に記述します。
このコードスニペットでは、エラー処理を強化するためgoto()関数をtry-exceptブロックで囲んでいます。
検索バーにサイトのURLを入力すると、読み込みを待つ必要があります。これをコードで再現するには以下を使用できます:
page.wait_for_timeout(7000) #括弧内のミリ秒値
注:上記の行は、前述の行の下に追加する必要があります。
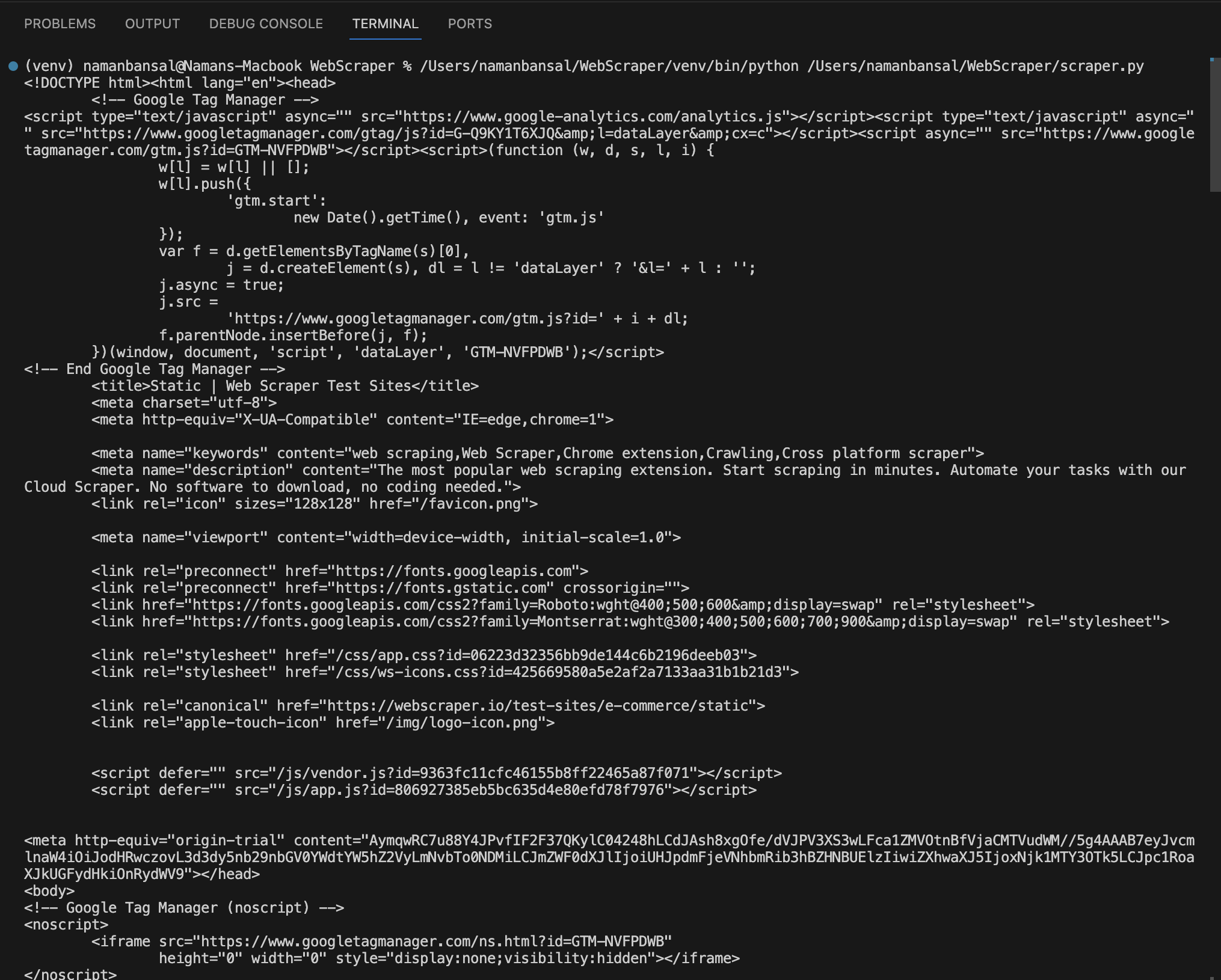
最後に、以下のコード行を使用してページからすべてのHTMLコンテンツを抽出します:
print(page.content())
ページのHTMLを抽出する完全なコードは以下のようになります:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
page.wait_for_timeout(7000)
print(page.content())
main()
Visual Studio Codeでは、抽出されたHTMLは次のようになります:
特定の属性を使用してHTMLを抽出する
以前は Web Scraper ウェブページの全要素を抽出しましたが、必要な情報のみをウェブスクレイピングするように制限しなければ、ウェブスクレイピングは有用ではありません。このセクションでは、ウェブサイトの最初のページにあるすべてのノートパソコンのタイトルのみを抽出します:
特定の要素を抽出するには、対象ウェブサイトの構造を理解する必要があります。これを行うには、右クリックして「要素を検査」オプションを選択します:
キーボードショートカットを使用する方法もあります:
- macOSの場合:Cmd + Option + I
- Windowsの場合:Control + Shift + C
対象ページの構造は以下の通りです:
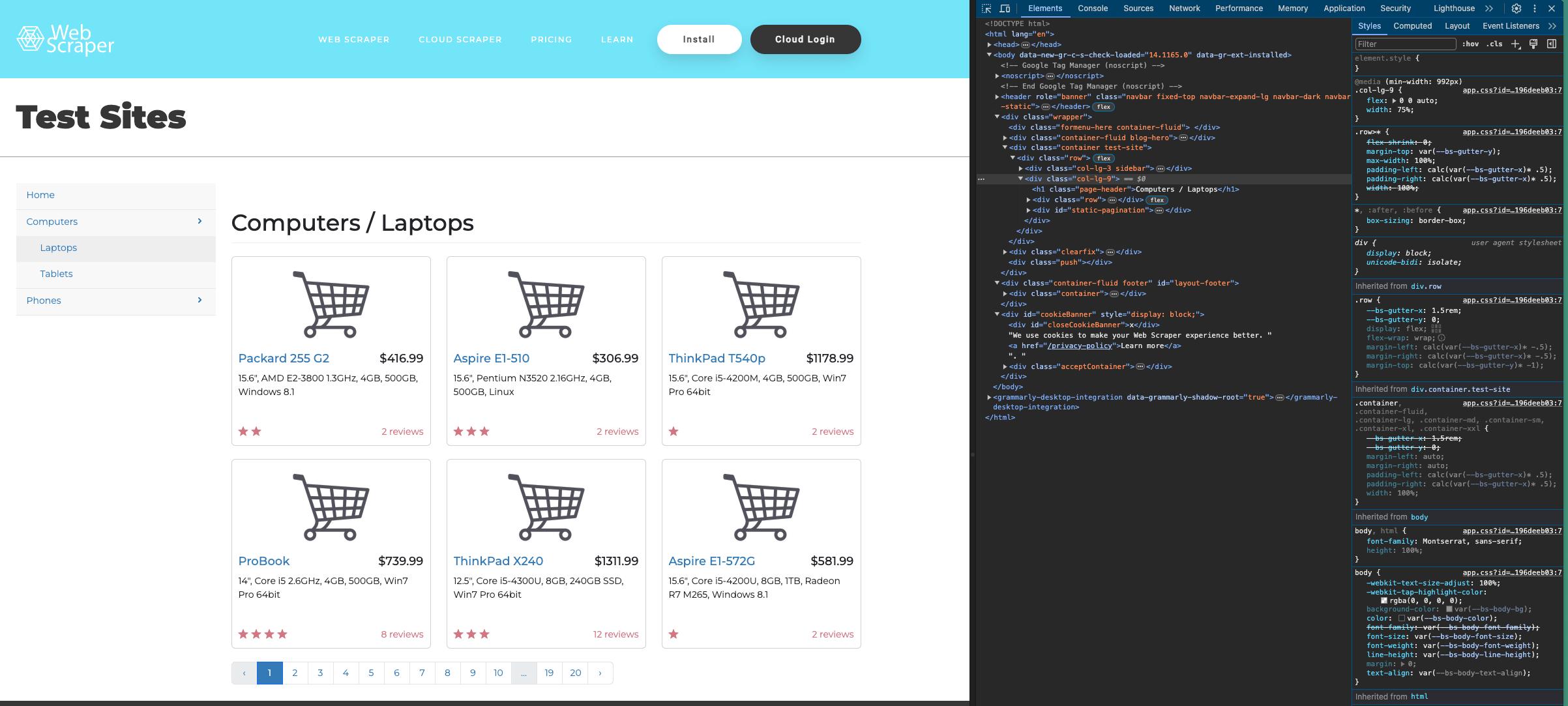
ページ上の特定項目のコードは、検査ウィンドウ左上の選択ツールで確認できます:

Inspectウィンドウでノートパソコンのタイトルのいずれかを選択します:
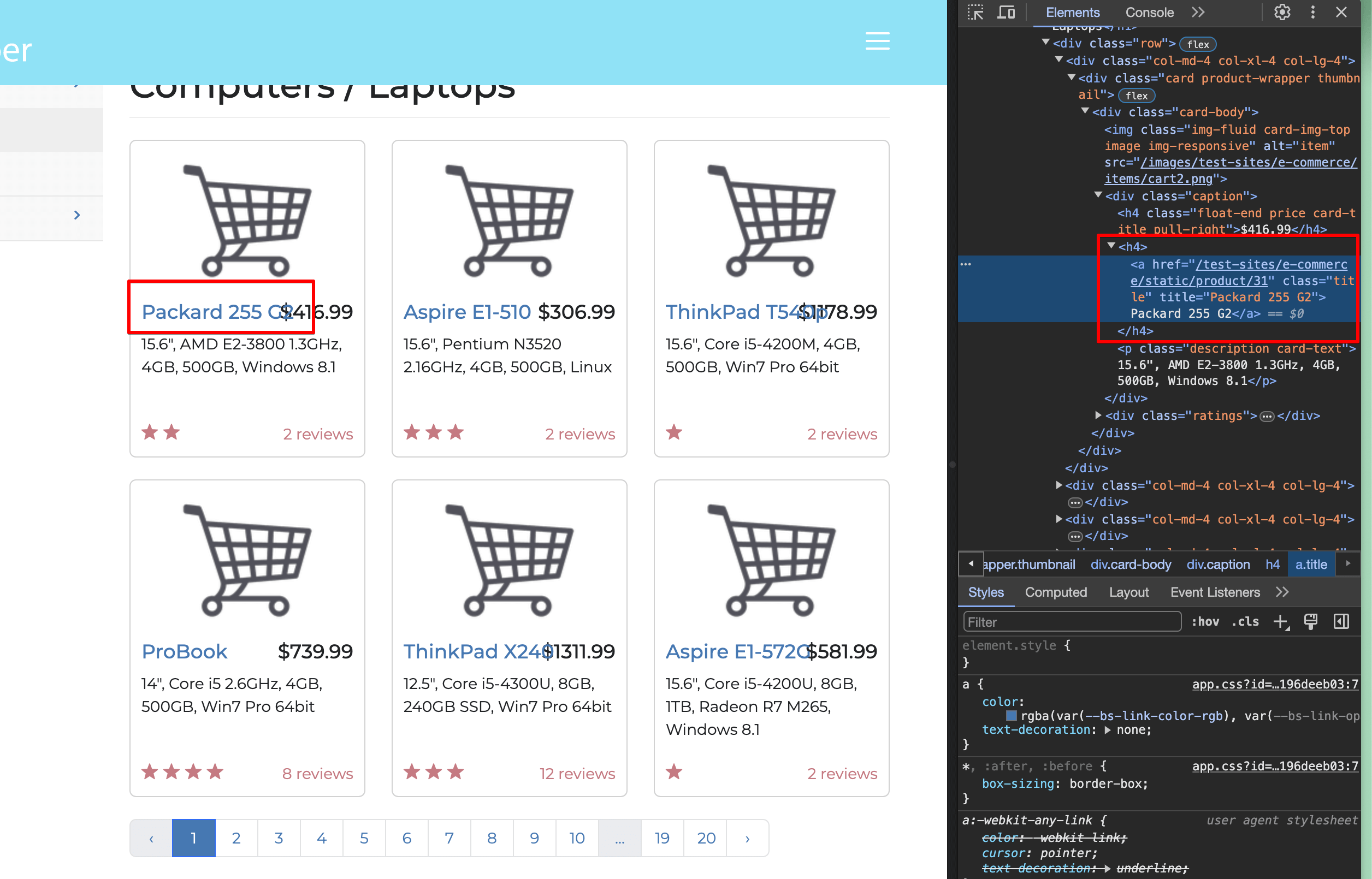
タイトルが<a> </a>タグ内にあり、h4タグで囲まれていること、リンクにtitleクラスが設定されていることが確認できます。つまり、<h4>タグ内でtitleクラスを持つ< a href>タグ(URL)を探す必要があります。
これらの要素を正確にターゲットとするスクレイピングプログラムを作成するには、ライブラリをインポートしてPython関数を作成し、ブラウザを起動して対象ウェブサイトに移動する必要があります:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
page.goto()関数内のターゲットURLが、ノートパソコンのリストを含む最初のページを指すように更新されていることに注意してください。
スクレイピングプログラムを作成したら、ウェブサイトの構造分析に基づいて対象要素を特定する必要があります。Playwrightにはロケーターと呼ばれるツールがあり、以下のような様々な属性に基づいてページ上の要素を特定できます:
get_by_label()は要素に関連付けられたラベルを使用してターゲット要素を特定します。get_by_text():要素に含まれるテキストを使用してターゲット要素を特定します。get_by_alt_text()は、altテキストを使用してターゲット要素を特定し、画像に対して操作を実行します。get_by_test_id()は要素のテストIDを使用してターゲット要素を特定します。
要素を特定するその他のメソッドについては、公式ドキュメントを参照してください。
すべてのノートパソコンのタイトルをスクレイピングするには、ノートパソコンのタイトルをすべて囲んでいる<h4>タグを特定する必要があります。get_by_role()ロケーターを使用すると、ボタン、チェックボックス、見出しなど、要素の機能に基づいて要素を見つけることができます。つまり、ページ上のすべての見出しを見つけるには、次のように記述します:
titles = page.get_by_role("heading").all()
その後、コンソールで出力するには次のコードを使用します:
print(titles)
出力後、要素の配列が返されることに気づくでしょう:
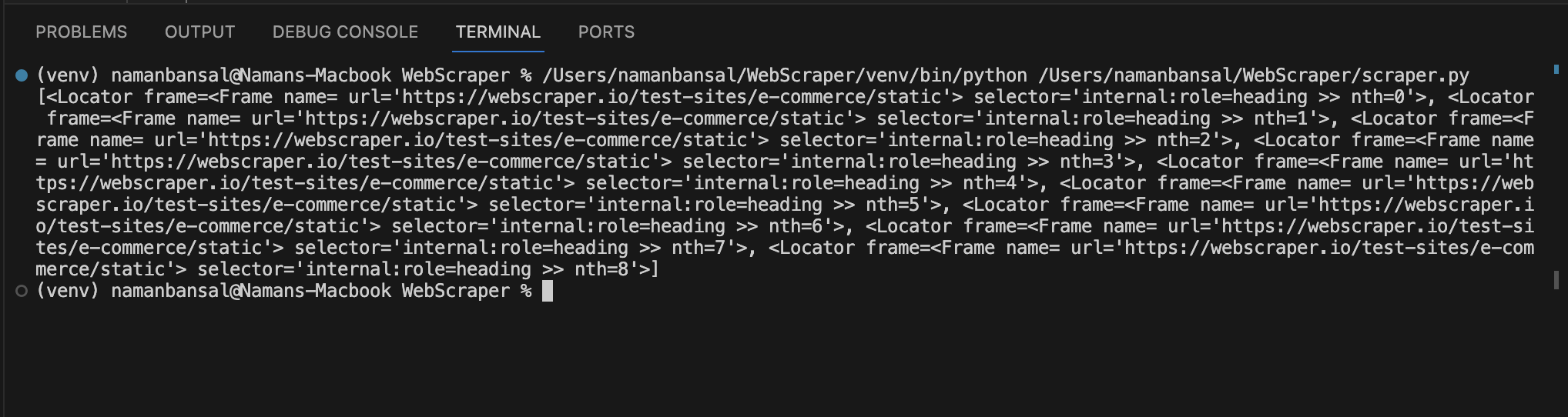
この出力にはタイトルは含まれませんが、セレクタ条件に一致する要素を参照しています。タイトルクラスを持つ<a>タグとその内部テキストを見つけるには、これらの要素をループ処理する必要があります。
要素のパスとクラスに基づいて探すにはCSSロケーターの使用が推奨されます。また、要素の内部テキストを抽出するにはall_inner_texts()関数を次のように使用できます:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
このコードを実行すると、出力は次のようになります:
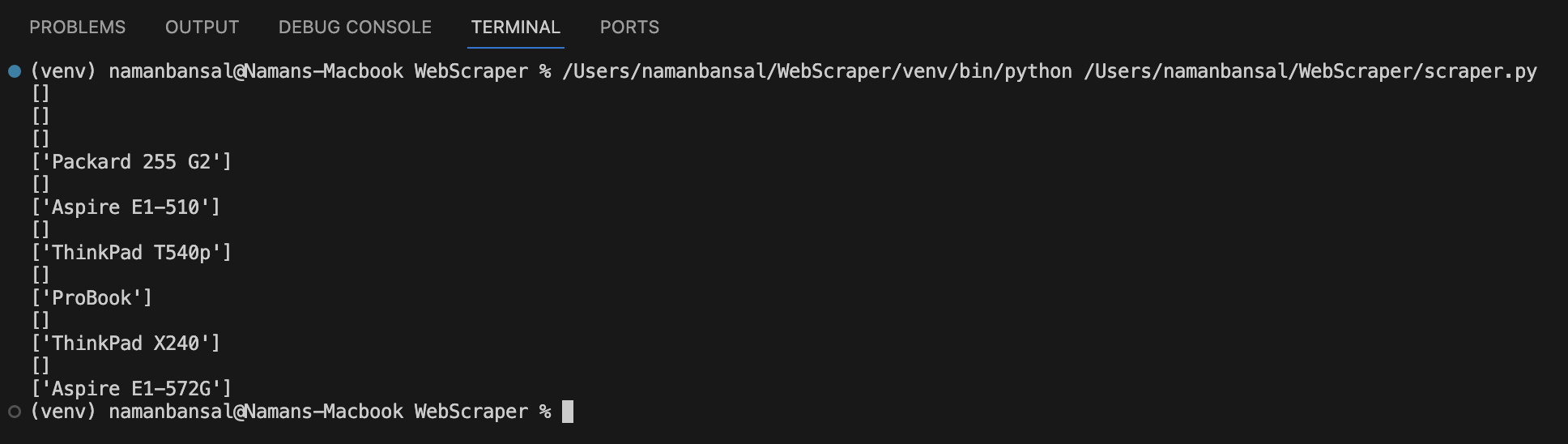
値のない配列を拒否するには、以下のように記述します:
if len(laptop) == 1:
print(laptop[0])
値のない配列を除外すれば、特定の要素のみを抽出するスクレイピングプログラムの構築に成功します。
このスクレイパーの完全なコードは以下の通りです:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
要素との対話
さらに一歩進んで、ノートパソコンが掲載されている最初のページからタイトルを抽出し、次のページに移動してそれらのタイトルも抽出するプログラムを作成しましょう。
ページのタイトル抽出方法は既に理解しているので、次のノートパソコンページへ移動する方法だけを考えればよい。
現在表示されているページにページネーションボタンがあることに気づいているかもしれません。
スクレイピングプログラムで「2」を見つけ、クリックする必要があります。ページを検査すると、必要な要素はリスト要素(<li>タグ)であり、内部テキストが「2」であることがわかります:
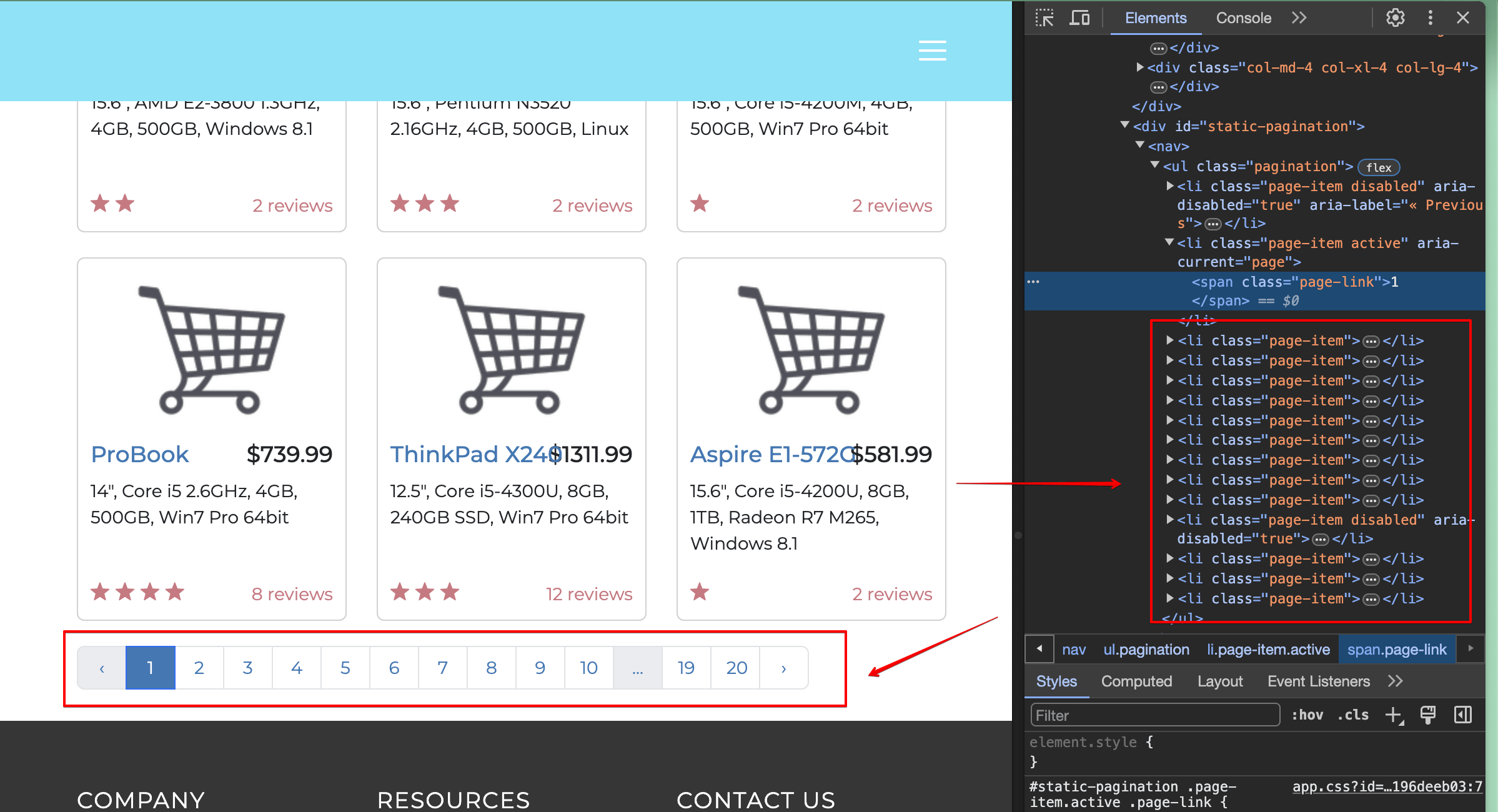
つまり、リスト項目を見つけるにはget_by_role() セレクターを、テキストが「2」の要素を見つけるにはget_by_text() セレクターを使用できます。
ファイルへの記述例:
page.get_by_role("listitem").get_by_text("2", exact=True)
これは二つの条件に一致する要素を検索します:第一にリスト項目であること、第二にテキストが「2」であること。
exact=True は、指定されたテキストを持つ要素を見つけるための関数引数です。
ボタンをクリックするには、前のコードを次のように変更します:
page.get_by_role("listitem").get_by_text("2", exact=True).click()
このコードでは、click()関数が指定された要素をクリックします。
ページが読み込まれるのを待ち、再度すべてのタイトルを抽出します:
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
完全なコードブロックは以下のようになります:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
page.get_by_role("listitem").get_by_text("2", exact=True).click()
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()
HTMLを抽出してCSVに書き込む
スクレイピングしたデータを保存・分析しなければ意味がありません。このセクションでは、スクレイピングするノートパソコンのページ数をユーザー入力で受け取り、タイトルを抽出してプロジェクトフォルダ内のCSVファイルに保存する高度なプログラムを作成します。
このプログラムには事前インストール済みのCSVライブラリが必要です。以下のコマンドでインポートできます:
import csv
CSVライブラリをインストールしたら、ユーザーの入力に応じて可変ページ数を訪問する方法を考えます。
ウェブサイトのURL構造を見ると、各ノートパソコンページがURLパラメータで指定されていることがわかります。例えば、ノートパソコンディレクトリの2ページ目のURLはhttps://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2です。
URLパラメータ?page=2 の数値を変更することで異なるページにアクセスできます。つまり、以下のコマンドでユーザーにスクレイピングするページ数を指定してもらう必要があります:
pages = int(input("スクレイピングするページ数を入力してください: "))
ユーザーが入力したページ数(1から)までの各ページを訪問するには、次のようなforループを使用します:
for i in range(1, pages+1):
このrange関数内では、ループの開始値と終了値を表す引数として1とpages+1を使用します。2番目の引数はループから除外されます。例えばrange(1,5)の場合、プログラムは1から4までのみループします。
次に、反復処理内で各ページを訪問する際、URLパラメータとしてiの値を指定します。Pythonのf-stringを使用すれば、文字列に変数を追加できます。
文字列を出力する際、引用符の前にfを付けることでf-stringであることを示します。引用符内では、変数を示すために中括弧を使用できます。
変数と文字列を組み合わせて出力するf文字列の例:
print(f"変数の値は {variable_name_goes_here} です")
スクレイパーに戻ると、ファイルに次のコードブロックを記述することでf-stringsを活用できます:
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
タイムアウト関数でページ読み込みを待機し、以下の方法でタイトルを抽出します:
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
すべてのタイトル要素を取得したら、CSVファイルを開き、各タイトルをループ処理して必要なテキストを抽出し、ファイルに書き込む必要があります。
CSVファイルを開くには以下の構文を使用します:
with open("laptops.csv", "a") as csvfile:
ここでは、laptops.csvファイルを追記モード(a)で開いています。ファイルを開くたびに古いデータを失わないようにするため、追記モードを使用します。ファイルが存在しない場合、ライブラリはプロジェクトフォルダ内にファイルを作成します。CSVでは、ファイルを開く際に以下のモードを含め、いくつかのモードを提供しています:
- rは何も指定しない場合のデフォルトオプションです。ファイルを読み取り専用で開きます。
- w は書き込み専用で開きます。ファイルを開くたびに以前のデータが上書きされます。
- a はデータを追記する目的で開きます。既存データは上書きされません。
- r+は読み書き両方のモードで開きます。
- xは新規ファイルを作成します。
上記のコードの下で、CSVファイルを操作するためのライターオブジェクトを宣言する必要があります:
writer = csv.writer(csvfile)
次に、各タイトル要素をループ処理し、以下の方法でテキストを抽出します:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
これにより、個々のノートパソコンのタイトルを含む複数の配列が得られます。空の配列を拒否するには、以下の条件付きコードをCSVファイルに書き込みます:
if len(laptop) == 1:
writer.writerow([laptop[0]])
writerow関数はCSVファイルに新しい行を書き込むことを可能にします。
プログラムの完全なコードは以下の通りです:
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("スクレイピングするページ数を入力してください: "))
for i in range(1, pages+1):
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("エラー")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
with open("laptops.csv", "a") as csvfile:
writer = csv.writer(csvfile)
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
writer.writerow([laptop[0]])
browser.close()
main()
このコードを実行すると、CSVファイルは次のようになります:
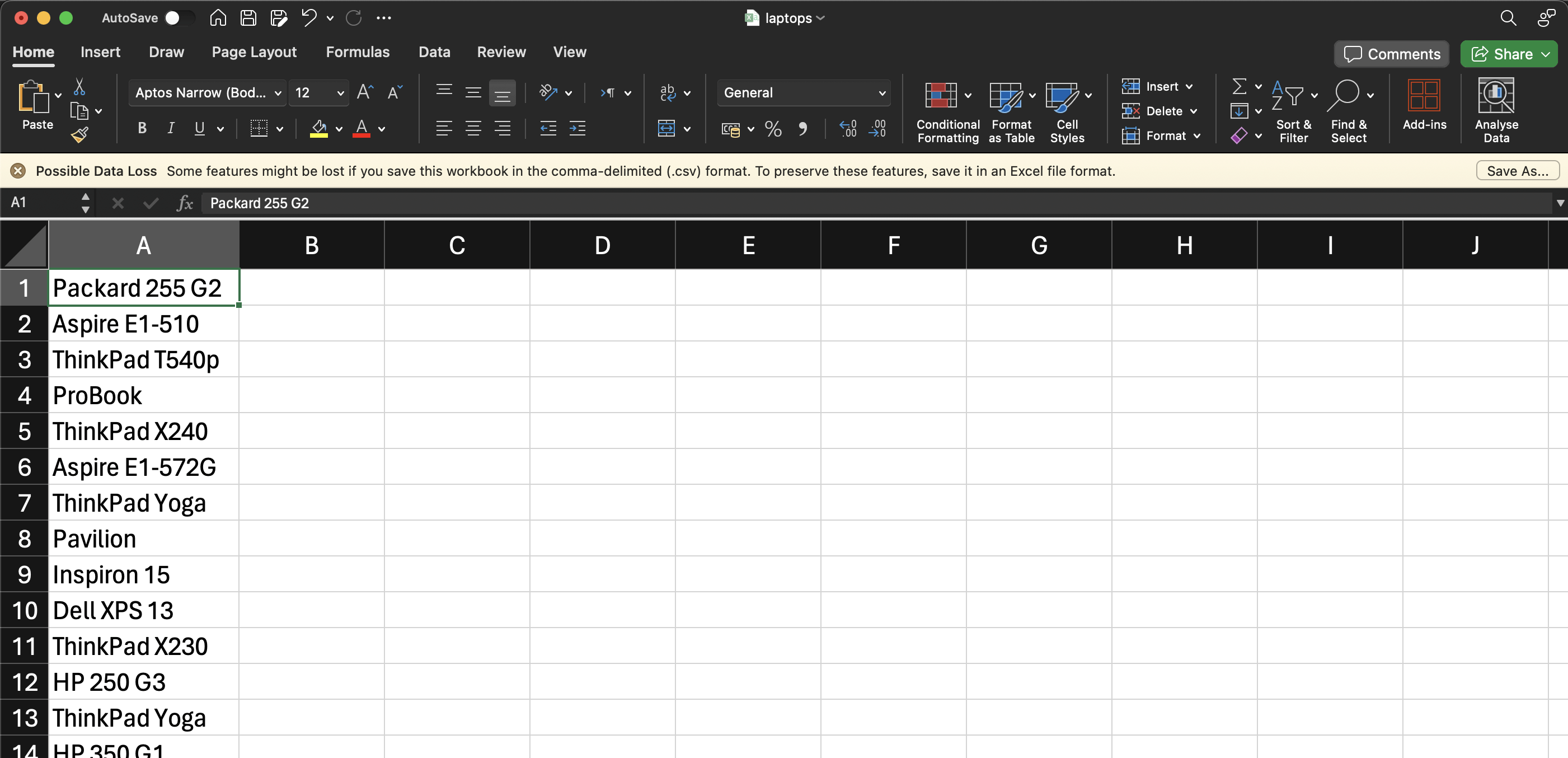
結論
この記事では、Python を使用して HTML を抽出、パース、保存する方法を学びました。
このチュートリアルは比較的単純でしたが、実際のシナリオでは、スクレイピング中にCAPTCHA、レート制限、ウェブサイトのレイアウト変更、規制要件など、様々な障害に直面する可能性があります。幸いなことに、Bright Dataが解決策を提供します。 Bright Dataは、高度なレジデンシャルプロキシによるウェブスクレイピングの改善、大規模スクレイパー構築用のWebScraper IDE、公開ウェブサイトのブロック解除(CAPTCHAの解決を含む)を実現するWeb Unblockerなどのツールを提供します。これらのツールは、正確なデータを大規模に収集し、障害を克服するのに役立ちます。さらに、Bright Dataの倫理的なスクレイピングへの取り組みにより、ウェブサイトの利用規約や法的規制を遵守できます。
Bright Dataの機能豊富なプラットフォームを活用すれば、複雑なウェブスクレイピングの手間を省き、必要な価値あるデータ抽出に集中できます。今すぐ無料トライアルを開始しましょう!





