

Node.jsはウェブスクレイパー構築の強力な選択肢として台頭し、クライアントサイドとサーバーサイド開発の両方に利便性を提供します。豊富なライブラリ群により、Node.jsを用いたウェブスクレイピングは容易です。本記事ではcheerioに焦点を当て、効率的なウェブスクレイピングのためのその機能を探ります。
CheerioはHTMLおよびXMLドキュメントのパース・操作を行う高速かつ柔軟なライブラリです。jQuery機能のサブセットを実装しているため、jQueryに慣れたユーザーはCheerioの構文にすぐに馴染めます。内部ではHTML/XMLパースにparse5ライブラリを、オプションでhtmlparser2ライブラリも使用します。
本記事では、cheerioを使用したプロジェクトを作成し、動的ウェブサイトや静的ウェブページからデータをスクレイピングする方法を学びます。
cheerio によるウェブスクレイピング
チュートリアルを始める前に、システムにNode.jsがインストールされていることを確認してください。未インストールの場合、公式ドキュメントを参照してインストールできます。
Node.jsのインストールが完了したら、cheerio-demoというディレクトリを作成し、そのディレクトリに移動します:
mkdir cheerio-demo u0026u0026 cd cheerio-demon
次に、ディレクトリ内でnpmプロジェクトを初期化します:
npm init -yn
npm install cheerio axiosn
このチュートリアルのコードを書く場所となるindex.jsファイルを作成します。その後、お気に入りのエディタでこのファイルを開き、作業を開始します。
最初に必要なのは、必要なモジュールをインポートすることです:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);n
このチュートリアルでは、ウェブスクレイパーのテスト用公開サンドボックスである「Books to Scrape」ページをスクレイピングします。まずAxiosを使用して、以下のコードでWebページへのGETリクエストを送信します:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n n});n
コールバック内のレスポンスオブジェクトには、dataプロパティにウェブページのHTMLコードが含まれています。このHTMLをcheerioモ ジュールのload関数に渡す必要があります。この関数はCheerioAPIのインスタンスを返し、以降のコードでDOMへのアクセスや操作に使用されます。CheerioAPIインスタンスは$という変数に格納されますが、これはjQueryの構文を踏襲したものです:
axios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);n});n
要素の検索
cheerioはページから要素を選択するためにCSSおよびXPathセレクタの使用をサポートしています。jQueryを使用したことがある方なら、この構文は馴染み深いでしょう——CSSセレクタを$()関数に渡します。この構文を使用して、Books to Scrapeウェブサイトの最初のページから情報を探して抽出します。
https://books.toscrape.com/ にアクセスし、開発者コンソールを開きます。「要素を検査」タブで検索すると、ページの HTML 構造について詳しく知ることができます。この場合、書籍に関するすべての情報はproduct-pod クラスを持つarticle タグに含まれていることがわかります:
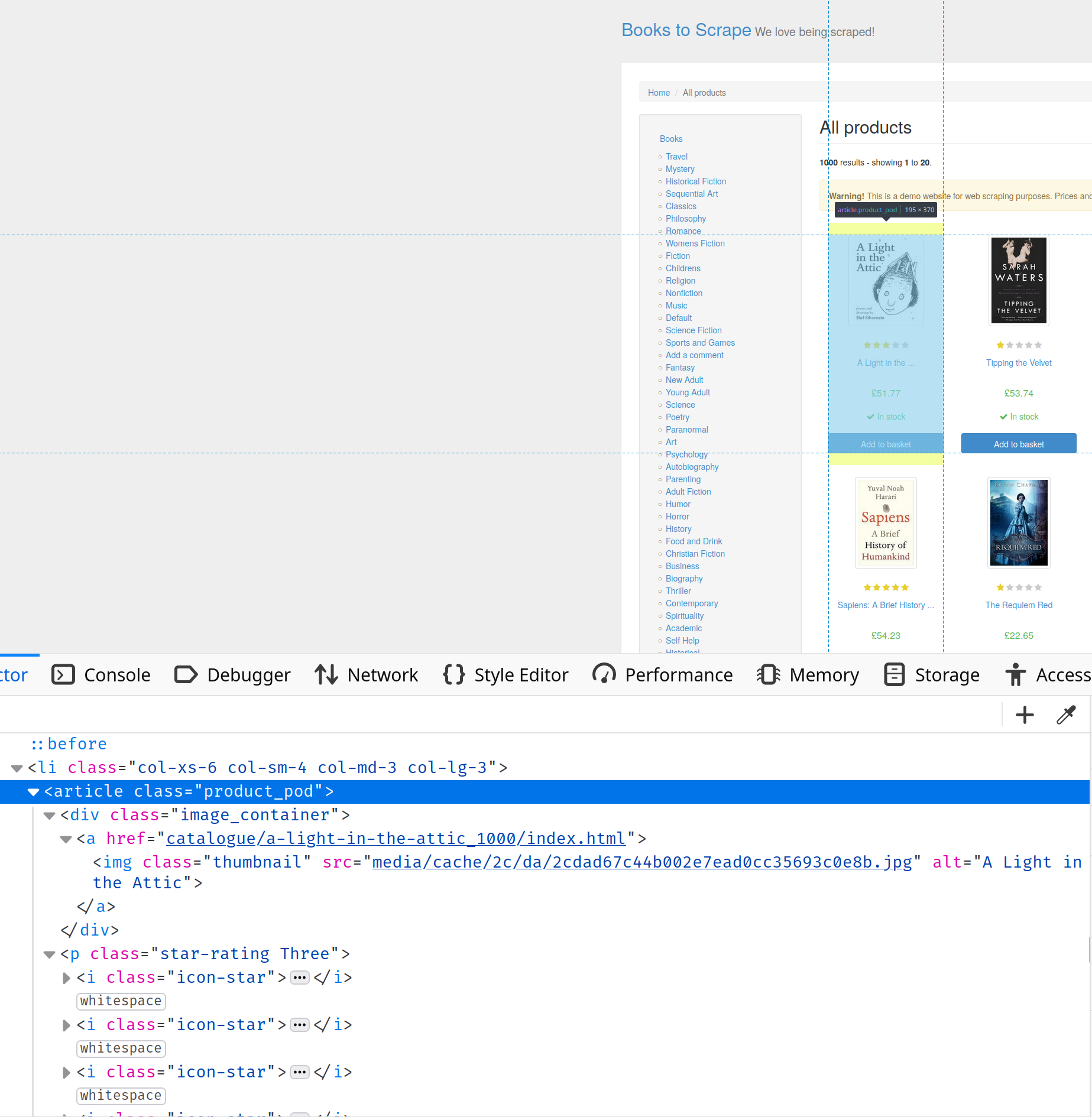
書籍を選択するには、article.product_pod CSS セレクタを次のように使用します:
$(u0022article.product_podu0022);n
この関数はセレクタに一致する全要素のリストを返します。eachメソッドでリストを反復処理できます:
$(u0022article.product_podu0022).each( (i, element) =u003e {nn});n
ループ内でelement変数を使用しデータを抽出できます。
最初のページの書籍タイトルを抽出してみてください。要素の検査コンソールに戻ると、タイトルがどのように格納されているか確認できます:

element変数の子要素であるh3要素を見つける必要があることがわかります。h3要素内には、書籍のタイトルを保持するa要素が存在します。findメソッドとCSSセレクタを使用して要素の子要素を検索できますが、最初にelement を$で変換し、Cheerioのインスタンスにする必要があります:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);nn});n
これでtitleH3内の a要素を検索できます:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022);n});n
注:
titleH3は既にCheerioのインスタンスであるため、$ を介して渡す必要はありません。
テキストの抽出
要素を選択したら、textメソッドを使用してその要素のテキストを取得できます。
前の例を修正し、findメソッドの結果に対してtextメソッドを呼び出して書籍のタイトルを抽出します:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n});n
完全なコードは以下のようになります:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nn console.log(title);n });n});n
node index.js でコードを実行すると、以下の出力が表示されます:
A Light in the ...nTipping the VelvetnSoumissionnSharp ObjectsnSapiens: A Brief History ...nThe Requiem RednThe Dirty Little Secrets ...nThe Coming Woman: A ...nThe Boys in the ...nThe Black MarianStarving Hearts (Triangular Trade ...nShakespeare's SonnetsnSet Me FreenScott Pilgrim's Precious Little ...nRip it Up and ...nOur Band Could Be ...nOlionMesaerion: The Best Science ...nLibertarianism for BeginnersnIt's Only the Himalayasn
DOMのナビゲーション:子要素と兄弟要素の検索
タイトルを抽出した後は、各書籍の価格と在庫状況を抽出します。要素の検査機能から、価格と在庫状況の両方がproduct_price クラスを持つdiv に格納されていることがわかります。このdiv は .product_price CSS セレクタで選択できますが、CSS セレクタについては既に説明済みですので、ここでは別の方法を説明します:
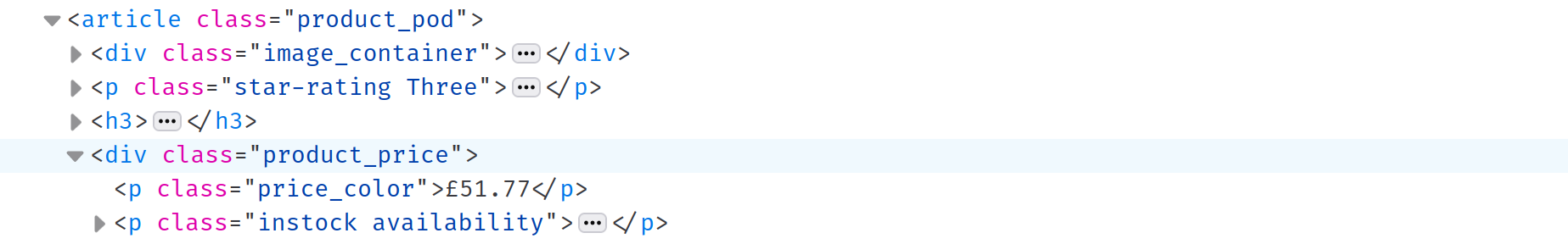
注: この
divは、以前に選択したtitleH3の兄弟要素です。titleH3のnextメソッドを呼び出すことで、次の兄弟要素を選択できます:
const priceDiv = titleH3.next();n
findメソッドでCSSセレクタに基づき要素の子要素を検索できることは既にご存知でしょう。childrenメソッドですべての子要素を選択し、eqメソッドで特定の子要素を選択することも可能です。これはnth-child CSSセレクタと同等です。
この場合、priceはpriceDivの最初の子要素、availabilityはpriceDivの2番目の子要素です。つまりそれぞれpriceDiv.children().eq(0)、priceDiv.children().eq(1)で選択できます。実行して価格と在庫状況を出力しましょう:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n console.log(title, price, availability);n});n
コードを実行すると、以下の出力が得られます:
A Light in the ... £51.77 In stocknTipping the Velvet £53.74 In stocknSoumission £50.10 In stocknSharp Objects £47.82 In stocknSapiens: A Brief History ... £54.23 In stocknThe Requiem Red £22.65 In stocknThe Dirty Little Secrets ... £33.34 In stocknThe Coming Woman: A ... £17.93 In stocknThe Boys in the ... £22.60 In stocknThe Black Maria £52.15 In stocknStarving Hearts (Triangular Trade ... £13.99 In stocknShakespeare's Sonnets £20.66 In stocknSet Me Free £17.46 In stocknScott Pilgrim's Precious Little ... £52.29 In stocknRip it Up and ... £35.02 In stocknOur Band Could Be ... £57.25 In stocknOlio £23.88 In stocknMesaerion: The Best Science ... £37.59 In stocknLibertarianism for Beginners £51.33 In stocknIt's Only the Himalayas £45.17 In stockn
属性の取得
これまでDOMをナビゲートし、要素からテキストを抽出してきました。Cheerioでは要素から属性を抽出することも可能です。このセクションではその方法を学びます。ここでは要素のクラスリストを読み取り、書籍の評価を抽出します。
書籍の評価は興味深い構造を持っています。評価はpタグ内に含まれており、各pタグには必ず5つの星が表示されます。ただし、これらの星はp要素のクラス名に基づいてCSSで色付けされています。例えば、クラス名star-rating.Fourを持つpタグでは、最初の4つの星が黄色で表示され、4つ星評価を示します:

書籍の評価を抽出するには、p要素のクラス名を抽出する必要があります。最初のステップは評価を含む段落を見つけることです:
const ratingP = $(element).find(u0022p.star-ratingu0022);n
attrメソッドに属性名を渡すことで、要素の属性を取得できます。この場合、クラスリストを読み取る必要があり、以下のコードで実演されています:
const starRating = ratingP.attr('class');n
クラスリストは次の形式です:star-rating X(X はOne、Two、Three、Four、Fiveのいずれか)。つまり、スペースでクラスリストを分割し、2番目の要素を取得する必要があります。次のコードはその処理を行い、テキスト評価を数値評価に変換します:
const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];n
すべてを組み合わせると、コードは次のようになります:
$(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();nnn const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();nn const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);n});n
出力結果は次のようになります:
A Light in the ... £51.77 In stock 3nTipping the Velvet £53.74 In stock 1nSoumission £50.10 In stock 1nSharp Objects £47.82 In stock 4nSapiens: A Brief History ... £54.23 In stock 5nThe Requiem Red £22.65 In stock 1nThe Dirty Little Secrets ... £33.34 In stock 4nThe Coming Woman: A ... £17.93 In stock 3nThe Boys in the ... £22.60 In stock 4nThe Black Maria £52.15 In stock 1nStarving Hearts (Triangular Trade ... £13.99 In stock 2nShakespeare's Sonnets £20.66 In stock 4nSet Me Free £17.46 In stock 5nScott Pilgrim's Precious Little ... £52.29 In stock 5nRip it Up and ... £35.02 In stock 5nOur Band Could Be ... £57.25 In stock 3nOlio £23.88 In stock 1nMesaerion: The Best Science ... £37.59 In stock 1nLibertarianism for Beginners £51.33 In stock 2nIt's Only the Himalayas £45.17 In stock 2n
データの保存
ウェブページからデータをスクレイピングした後、通常は保存したいでしょう。ファイルへの保存、データベースへの保存、データ処理パイプラインへの投入など、いくつかの方法があります。このセクションでは、最もシンプルな方法であるCSVファイルへのデータ保存を学びます。
そのためには、node-csvパッケージをインストールします:
npm install csvn
index.jsでfsとcsv-stringifyモジュールをインポートします:
const fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);n
ローカルファイルに書き込むには、WriteStreamを作成する必要があります:
const filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);n
列名を宣言します。これらはCSVファイルのヘッダーとして追加されます:
const columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];n
列名を使用したstringifierを作成します:
const stringifier = stringify({ header: true, columns: columns });n
each関数内で、stringifierを使用してデータを書き込みます:
$(u0022article.product_podu0022).each( (i, element) =u003e {n ...nn const data = { title, rating, price, availability };n stringifier.write(data);nn});n
最後に、each関数の外側で、stringifierの内容をwritableStream変数に書き込む必要があります:
stringifier.pipe(writableStream);n
この時点でのコードは次のようになります:
const axios = require(u0022axiosu0022);nconst cheerio = require(u0022cheeriou0022);nconst fs = require(u0022fsu0022);nconst { stringify } = require(u0022csv-stringifyu0022);nnconst filename = u0022scraped_data.csvu0022;nconst writableStream = fs.createWriteStream(filename);nnconst columns = [n u0022titleu0022,n u0022ratingu0022,n u0022priceu0022,n u0022availabilityu0022n];nconst stringifier = stringify({ header: true, columns: columns });nnaxios.get(u0022https://books.toscrape.com/u0022).then((response) =u003e {n const $ = cheerio.load(response.data);nn $(u0022article.product_podu0022).each( (i, element) =u003e {n const titleH3 = $(element).find(u0022h3u0022);n const title = titleH3.find(u0022au0022).text();n n const priceDiv = titleH3.next();n const price = priceDiv.children().eq(0).text().trim();n const availability = priceDiv.children().eq(1).text().trim();n const ratingP = $(element).find(u0022p.star-ratingu0022);n const starRating = ratingP.attr('class');n const rating = { One: 1, Two: 2, Three: 3, Four: 4, Five: 5 }[starRating.split(u0022 u0022)[1]];nn console.log(title, price, availability, rating);nn const data = { title, rating, price, availability };n stringifier.write(data);nn });nn stringifier.pipe(writableStream);nn});n
コードを実行すると、スクレイピングしたデータを含むscraped_data.csvファイルが生成されます:
title,rating,price,availabilitynA Light in the ...,3,£51.77,In stocknTipping the Velvet,1,£53.74,In stocknSoumission,1,£50.10,In stocknSharp Objects,4,£47.82,In stocknSapiens: A Brief History ...,5,£54.23,In stocknThe Requiem Red,1,£22.65,In stocknThe Dirty Little Secrets ...,4,£33.34,In stocknThe Coming Woman: A ...,3,£17.93,In stocknThe Boys in the ...,4,£22.60,In stocknThe Black Maria,1,£52.15,In stocknStarving Hearts (Triangular Trade ...,2,£13.99,In stocknShakespeare's Sonnets,4,£20.66,In stocknSet Me Free,5,£17.46,In stocknScott Pilgrim's Precious Little ...,5,£52.29,In stocknRip it Up and ...,5,£35.02,In stocknOur Band Could Be ...,3,£57.25,In stocknOlio,1,£23.88,In stocknMesaerion: The Best Science ...,1,£37.59,In stocknLibertarianism for Beginners,2,£51.33,In stocknIt's Only the Himalayas,2,£45.17,In stockn
まとめ
ここで見てきたように、cheerioライブラリはjQuery風の構文と超高速な動作でウェブスクレイピングを容易にします。本記事では以下の方法を学びました:
- cheerioでHTMLウェブページを読み込み、パースする
- CSSセレクタで要素を検索する
- 要素からデータを抽出する
- DOMを操作する
- スクレイピングしたデータをローカルファイルストレージに保存する
完全なコードはGitHubで確認できます。
ただし、cheerioはHTMLパーサーに過ぎないため、JavaScriptコードを実行できません。つまり、動的なウェブページやシングルページアプリケーションのウェブスクレイピングには使用できません。それらをスクレイピングするには、cheerioを超えたSeleniumやPlaywrightのような複雑なツールを検討する必要があります。そこでBright Dataの出番です。 Bright Dataの広範なウェブスクレイピングソリューションには、SeleniumスクレイピングブラウザとPlaywrightスクレイピングブラウザが含まれます。製品の詳細については、当社のスクレイピングブラウザドキュメントをご覧ください。





