
この記事では以下を学びます:
- Amazon価格トラッカーとは何か、その有用性
- Pythonを用いたステップバイステップチュートリアルによる構築方法
- この手法の限界と克服方法
それでは始めましょう!
Amazon価格トラッカーとは?
Amazon価格トラッカーとは、1つ以上のAmazon商品の価格を時間経過とともに監視するツール、サービス、またはスクリプトです。価格変動を定期的に更新することで、値下げ、割引、変動を特定できるようにします。
Amazon商品の価格を追跡する理由
Amazon価格を追跡することで、以下のメリットがあります:
- 最安値で購入して節約
- セールやプロモーション期間に購入のタイミングを計る
- 出品者であれば、自社商品の競争力のある価格設定が可能
さらに、季節的なトレンドの監視や市場動向の把握にも不可欠です。
Amazon価格トラッカーの作成:ステップバイステップガイド
このチュートリアルセクションでは、Pythonを使用してAmazon価格トラッカーを構築する方法を学びます。以下の手順に従って、以下の機能を持つスクレイピングボットを作成してください:
- 指定商品のAmazonページに接続
- 該当ページから価格データをスクレイピング
- 時間の経過に伴う価格変動を追跡する
その他のデータにも関心がある場合は、Amazon商品データのスクレイピング方法に関するガイドを参照してください。
Amazon価格追跡スクリプトの実装を始めましょう!
ステップ #1: プロジェクト設定
開始前に、お使いのマシンにPython 3以上がインストールされていることを確認してください。インストールされていない場合は、公式サイトからダウンロードし、インストール手順に従ってください。
次に、Amazon価格追跡プロジェクト用のディレクトリを以下のコマンドで作成します:
mkdir amazon-price-tracker
そのディレクトリに移動し、仮想環境を設定します:
cd amazon-price-tracker
python -m venv venv
お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトフォルダ内にスクレイパー.pyファイルを作成します。これで以下のファイル構成が整います:
scraper.pyにはAmazon価格追跡ロジックを記述します。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を使用:
./venv/bin/activate
Windowsでは同等のコマンドとして以下を実行します:
venv/Scripts/activate
完了!これで準備が整い、作業を開始できます。
ステップ #2: スクラッピングライブラリの設定
ECサイトスクレイピングガイドで説明した通り、Amazonのスクレイピングにはブラウザ自動化ツールが必要です。これはサイトが特に動的だからではなく、Amazonが自動リクエストを検知・ブロックするボット対策を採用しているためです。
簡単に言えば、Amazonからデータを取得するにはSeleniumのようなブラウザ自動化ツールが必要です。まずSeleniumを以下のようにインストールします:
pip install selenium
このライブラリに不慣れな場合は、Seleniumウェブスクレイピングチュートリアルを参照してください。
スクレイパー.pyスクリプトにSeleniumライブラリをインポートします:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
次に、Chromeブラウザインスタンスを制御するChromeDriverオブジェクトを作成します:
# Chromeを制御するWebDriverを初期化
driver = webdriver.Chrome(service=Service())
# スクラッピングロジック...
# ドライバリソースを解放
driver.quit()
driverはAmazon商品ページとのやり取り(価格追跡)に使用されます。
Amazonはスクレイピング対策を採用しており、ヘッドレスブラウザをブロックする可能性があることに注意してください。問題を回避するには、Seleniumで制御するブラウザをヘッド付きモードで実行してください。
素晴らしい!Amazonスクレイピングロジックの自動化を始めましょう。
ステップ #3: 対象ページへの接続
AmazonでPS5の価格を追跡したい場合を想定します:
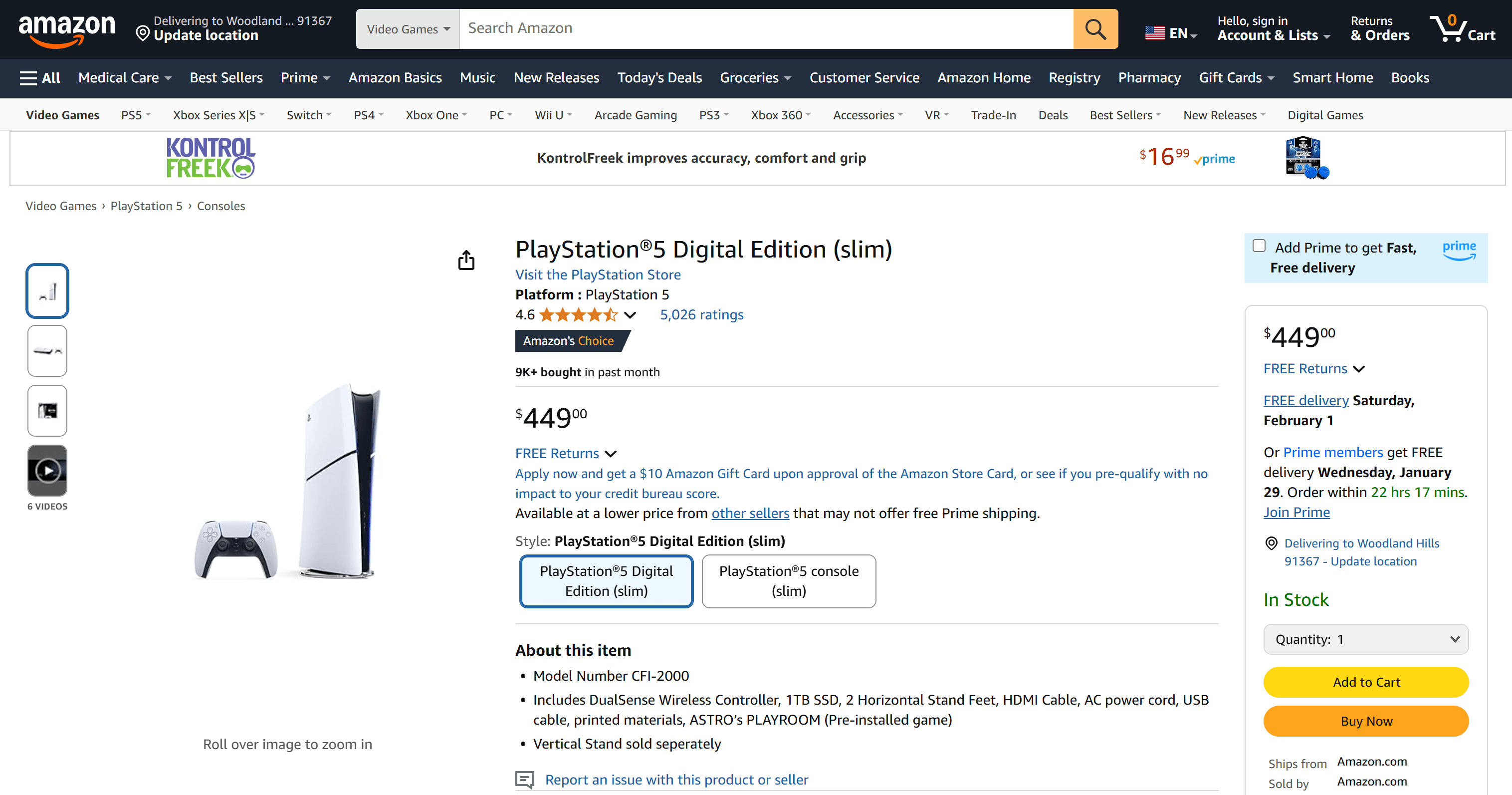
商品ページのURLはこちらです:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M/
amazon.com以降の部分は可読性のためのスラッグに過ぎませんが、重要なのは/dp/以降のコードです。このコードはAmazon ASINと呼ばれ、Amazon商品の一意の識別子です。
つまり、以下の形式でASINを直接使用しても同じ商品ページにアクセスできます:
https://www.amazon.com/product/dp/<AMAZON_ASIN>
この例では、PS5のASINはB0CL5KNB9Mです。このASINを変数に格納し、Amazon商品URLを生成するために使用します:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
次に、Seleniumのget()メソッドを使用してブラウザにターゲットページへの移動を指示します:
driver.get(amazon_url)
driver.quit() 命令の前にブレークポイントを設定し、スクリプトを実行します。これでブラウザにAmazon商品ページが表示されるはずです:
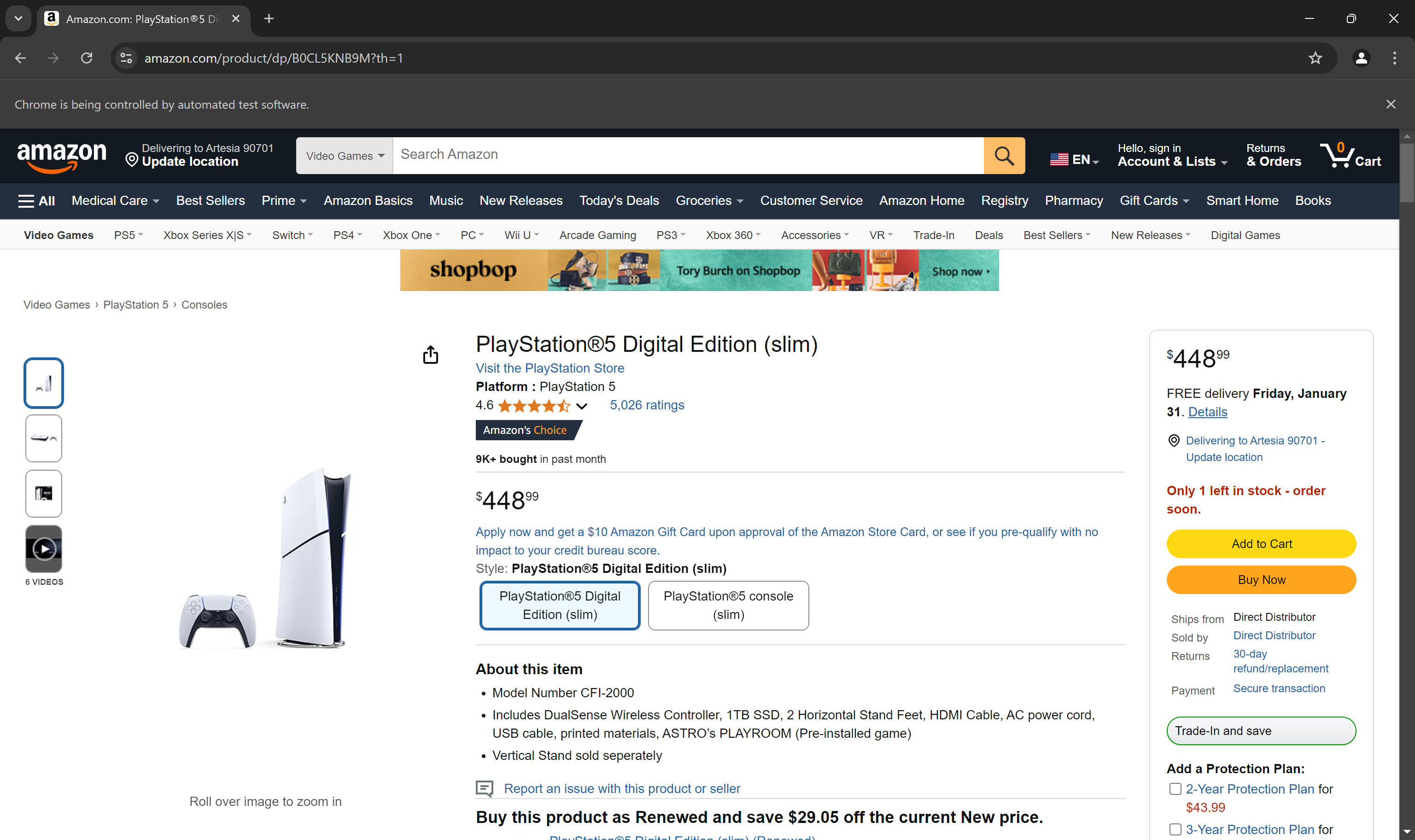
「Chromeは自動化されたソフトウェアによって制御されています」というメッセージは、Seleniumが意図した通りにブラウザを操作している証拠です。
Amazonはボット対策を実施しており、CAPTCHAの提示やリクエストのブロックが発生する可能性がある点に留意してください。これらの問題への対処法については後述しますのでご安心ください。
Bright DataのAmazon ASINスクレイパーの詳細はこちら。
ステップ #4: 価格情報のスクレイピング
対象商品ページをブラウザのシークレットモードで開きます。次に、ページに表示されている価格を右クリックし、「要素を検査」を選択します:
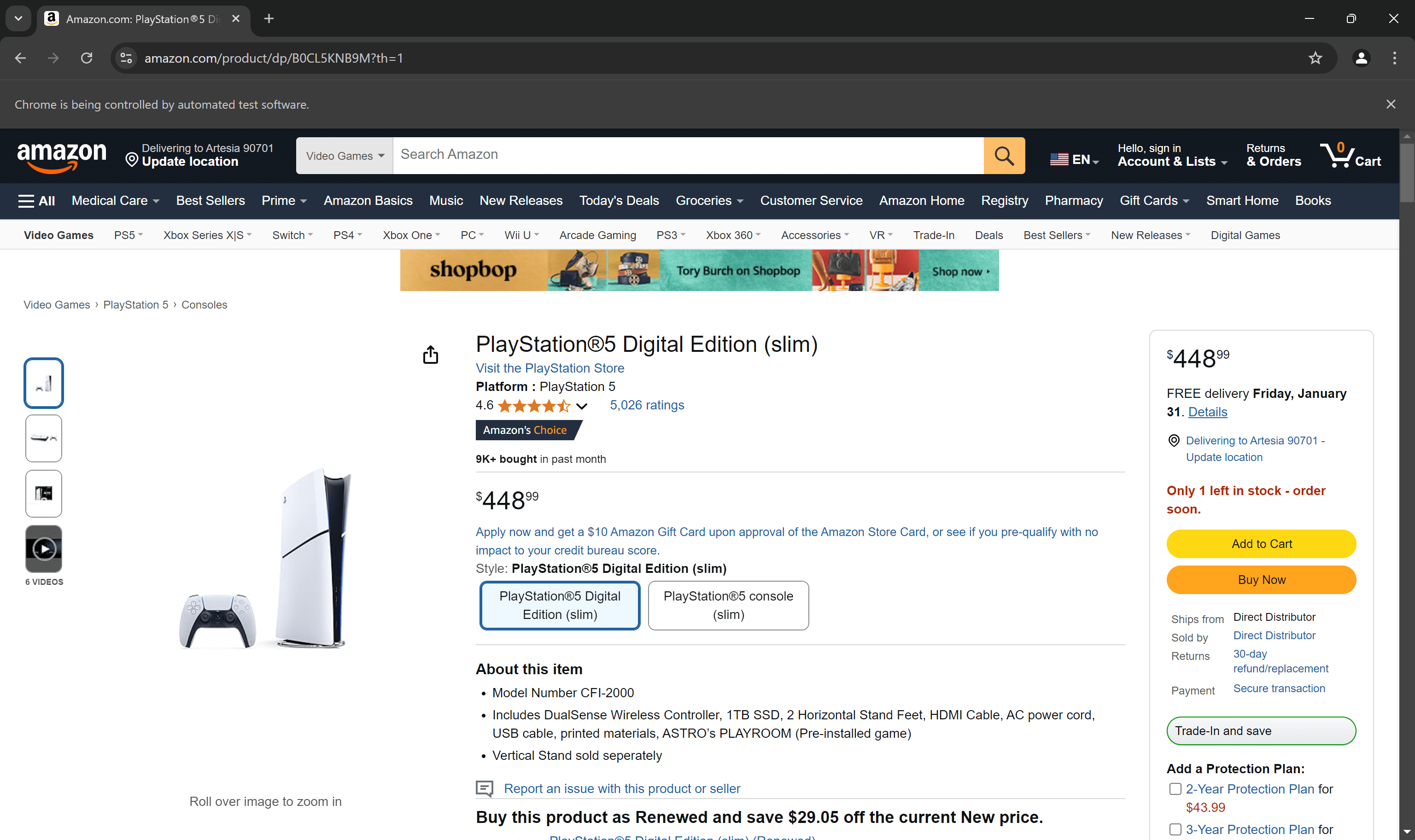
開発者ツール(DevTools)セクションで、価格要素のHTMLを確認します。価格は.a-price要素内に含まれていることに注意してください。
CSSセレクタで要素を選択し、データを抽出します:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("n", ".")
replace()関数は、価格から改行文字を除去するために使用されます。
Byのインポートを忘れないでください:
from selenium.webdriver.common.by import By
素晴らしい!Amazon価格トラッカーの主要機能である価格スクレイピングの実装に成功しました。
ステップ #5: 価格の保存
Amazon価格トラッカーの決定的な機能は、価格履歴を追跡できることです。これにより、時間の経過に伴う変化や変動を評価できます。これを実現するには、データベースやファイルなど、どこかに価格データを保存する必要があります。
簡素化のため、データベースとしてJSONファイルを使用します。このファイルには商品のASINと過去の価格履歴リストを保存します。
まず、以下の構造でJSONファイルが存在することを確認します:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}
ファイルが存在しない場合のPythonでの初期化方法は以下の通りです:
# JSONデータベースファイル名と初期データ
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# JSONデータベースファイルが存在しない場合、書き込み
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Seleniumロジック...
上記のスニペットを動作させるには、以下の2つのインポートが必要です:
import os
import json
スクレイピングロジックの前に、現在のデータにアクセスするためJSONファイルを読み込みます:
# JSONファイルを読み書き可能で開く
with open(file_name, "r+") as file:
# 現在の価格データをロード
price_data = json.load(file)
# スクラッピングロジック...
価格をスクレイピングした後、新しい価格とタイムスタンプをprices リストに追加します:
price = price_element.text.replace("n", "")
# 現在のタイムスタンプ
timestamp = datetime.now().isoformat()
# 新しい価格情報を追加
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
以下のインポートを追加:
from datetime import datetime
最後にJSONファイルを更新します:
# ファイルポインタを先頭に移動
file.seek(0)
# スクレイピングしたデータを上書き
json.dump(price_data, file, indent=4)
# ファイルを切り詰める(新規コンテンツが元のファイルより短い場合、余分なデータが消去される)
file.truncate()
素晴らしい!価格追跡ロジックが実装されました。
ステップ #6: 価格追跡ロジックのスケジュール設定
現在、Amazonの価格をスクレイピングして追跡するには、スクリプトを手動で実行する必要があります。これは時折の使用には有効かもしれません。しかし、スクリプトを定期的に自動実行するように設定することで、はるかに効果的になります。
Pythonのスケジュールライブラリを使用してこれを実現します。これはPythonでタスクをスケジュールするための直感的なAPIを提供します。
仮想環境を有効化した状態で、以下のコマンドを実行してライブラリをインストールします:
pip install schedule
次に、Amazon価格追跡ロジック全体をASINをパラメータとして受け取る関数にカプセル化します:
def track_price(amazon_asin):
# Amazon価格追跡ロジック全体...
これで12時間ごとに実行するPythonジョブが作成できました:
# 即時実行
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# その後、12時間ごとにジョブをスケジュール
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
whileループは、スケジュールされたタスクを処理するためにスクリプトがアクティブな状態を維持することを保証します。
以下の2つのインポートを忘れないでください:
import schedule
import time
完璧です!これでプロセス全体を自動化し、スクリプトを手放しで動作するAmazon価格トラッカーに変えました。
ステップ #7: 全てを統合する
これでPython Amazon価格トラッカーは次のようになります:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# WebDriverを初期化してChromeを制御
driver = webdriver.Chrome(service=Service())
# Amazon商品URL生成
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# JSONデータベースファイル名と初期データ
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# JSONデータベースファイルが存在しない場合作成
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# JSONファイルを読み書き可能でオープン
with open(file_name, "r+") as file:
# 現在の価格データをロード
price_data = json.load(file)
# 対象ページに移動
driver.get(amazon_url)
# 価格をスクレイピング
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("n", ".")
# 現在のタイムスタンプ
timestamp = datetime.now().isoformat()
# 新しい価格情報ポイントを追加
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# ファイルポインタを先頭に移動
file.seek(0)
# スクレイピングしたデータを上書き
json.dump(price_data, file, indent=4)
# ファイルを切り詰める(新規コンテンツが元のデータより短い場合、余分なデータが消去されるように)
file.truncate()
# ドライバーリソースを解放
driver.quit()
# 即時実行
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# その後、12時間ごとにジョブをスケジュール
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)
以下のように起動:
python3 スクレイパー.py
または、Windowsでは:
python スクレイパー.py
スクリプトを数時間実行させます。スクリプトは以下のようなprice_history.json ファイルを生成します:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2026-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2026-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2026-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2026-01-29T08:02:22.123612"
}
]
}
価格配列の各エントリが、前のエントリからちょうど12時間後に記録されていることに注目してください。
ミッション完了!
ステップ #8: 次のステップ
機能するAmazon価格トラッカーを構築しましたが、さらにレベルアップさせる余地があります。考えられる改善点は以下の通りです:
- ログ追加: 無人プロセスでは、動作状況を把握することが重要です。スクリプトの動作を追跡するログを追加しましょう。
- データベースの使用:データを保存するためにJSONファイルをデータベースに置き換えます。これにより、複数のデバイスやアプリケーションから価格履歴を共有・アクセスしやすくなります。
- エラー処理の実装: ボット対策、ネットワークタイムアウト、予期せぬ障害を管理するための堅牢なエラー処理を追加します。エラー発生時にスクリプトが適切に再試行またはスキップされるようにします。
- CLIからのオプション読み取り: スクリプトがコマンドラインからの入力(ASINやスケジュール設定など)を受け付けられるようにします。これにより柔軟性が向上します。
- 通知システム:メールやメッセージングアプリ経由のアラートを統合し、大幅な価格変動を通知します。
このアプローチの限界と克服方法
前章で構築したAmazon価格追跡スクリプトは基本的な例に過ぎません。次のステップを実装しない限り、このような単純なスクリプトを長期的に使用することはできません。これらのステップはスクリプトを強化しますが、同時に複雑化させ管理を困難にします。
しかし、スクリプトがどれほど洗練されても、AmazonはCAPTCHAでそれを阻止できます:
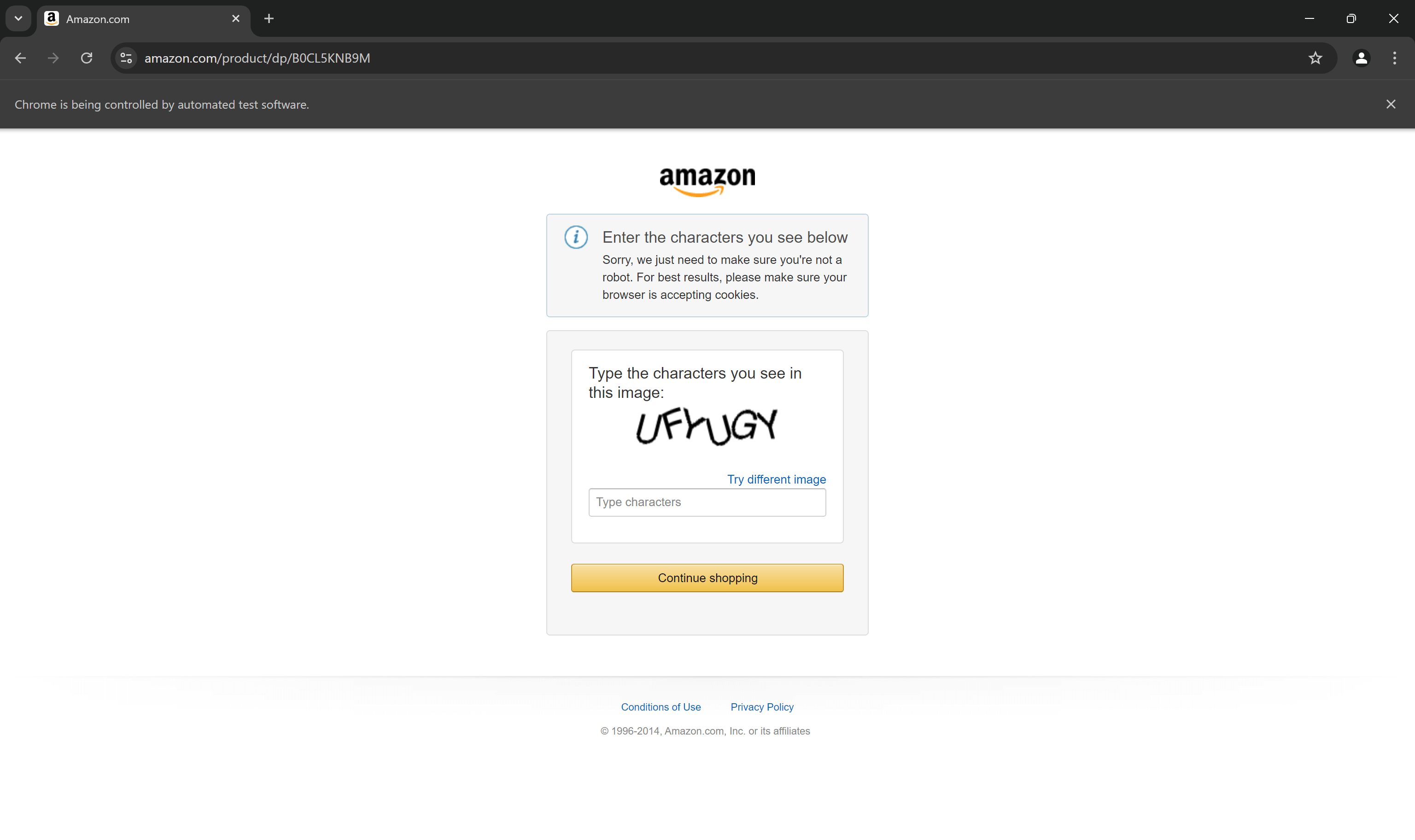
実際、現在のSeleniumベースのAmazonスクレイピングスクリプトは既にCAPTCHAでブロックされている可能性が高いです。最初のステップとして、PythonでCAPTCHAを回避する方法に関するガイドを参照してください。
それでも、厳格なレート制限により「429 Too Many Requests」エラーが発生する可能性があります。そのような場合、Seleniumにプロキシを統合して出口IPをローテーションさせるのが有効な対策です。
こうした課題は、適切なツールなしではAmazonのようなサイトのスクレイピングがいかに困難かを浮き彫りにします。さらに、ブラウザ自動化ツールが使えないと、スクリプトは低速でリソースを大量に消費します。
では諦めるべきか?決してそうではありません!真の解決策はBright Insightsのようなサービスに頼ることです。AI駆動の実践的なeコマースインサイトを提供し、以下を支援します:
- 売上損失の防止:商品削除、在庫切れ、表示問題による収益損失を特定し対策を講じます。
- 売上と市場シェアの追跡:未開拓の市場機会を発見し、競合他社の売上を追跡し、トレンドを早期に把握します。
- 価格最適化:競合他社の価格をリアルタイムで監視し、競争力を維持。
- 小売メディアの最大化:分析を活用して広告を最適化し、ROIを最大化、成果の成長を確保。
- 商品品揃えの最適化:競合追跡と収益最大化による商品品揃えの改善。
- クロスチャネル最適化:クロスチャネル情報を活用し、製品販売を管理し、全プラットフォームで優位性を確立する。
Bright Insightsは、Amazon価格追跡機能を含む、必要なすべてのeコマースデータを提供します。
まとめ
本記事では、Amazon価格トラッカーの定義とその利点について解説しました。さらにPythonとSeleniumを用いたウェブスクレイピングによる構築方法も紹介しました。
課題は、AmazonがCAPTCHA、ブラウザフィンガープリンティング、IP禁止などの厳格なボット対策を採用し、自動スクリプトをブロックしている点です。しかし当社のAmazon価格トラッカーを使えば、これらの課題を気にせずAmazon価格を取得できます。
ウェブスクレイピングが得意で、様々な種類のAmazonデータに興味がある方は、当社のAmazonスクレイパーAPIもぜひご検討ください!
今すぐBright Dataの無料アカウントを作成し、当社のサービスをご覧ください。




