

プロキシは、ユーザーの代わりにインターネットに接続するプロキシサーバーのIPアドレスです。プロキシを経由してインターネットに接続すると、リクエストは、訪問先のウェブサイトに直接送信される代わりに、プロキシサーバーを経由して送信されます。プロキシサーバーを利用することは、ユーザーのオンラインプライバシーを守り、セキュリティを強化する素晴らしい方法です。
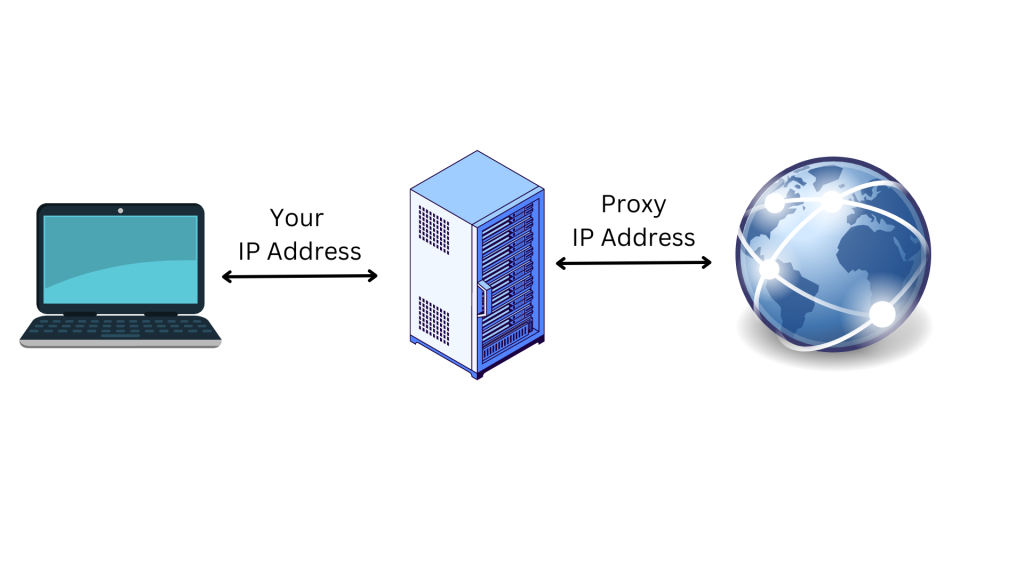
プロキシサーバーは仲介コンピュータとして機能するため、ユーザーの元のIPアドレスと所在地はウェブサイトから隠されます。これにより、オンライン追跡やターゲット広告からユーザーを保護し、アクセスしようとしているウェブサイトによってブロックされるのを防ぎます。さらにプロキシは、ユーザーのデバイスとプロキシサーバー間をデータが移動するときに暗号化を行うことによって、追加のセキュリティレイヤーも提供します。
この記事では、プロキシの詳細と、Pythonリクエストでプロキシを使う方法を説明します。また、ウェブスクレイピングプロジェクトに取り組む際に、なぜこれが役立つのかも解説します。
ウェブスクレイピングにプロキシが必要な理由
ウェブスクレイピングは、データ集計、市場調査、データ分析など、さまざまな目的でウェブサイトからデータを抽出するための自動プロセスです。ただし、これらのウェブサイトの多くには制限があり、欲しい情報にアクセスするのは困難です。
ありがたいことに、プロキシはIPやロケーションベースの制限を回避するのに役立ちます。たとえば、国や州など、場所ごとに異なる情報を提供するウェブサイトがあります。ユーザーがその特定の場所にいない場合、IPを回避して所在地を変えることができるプロキシなしには、探している情報にアクセスすることはできません。
さらに、ほとんどのウェブサイトは、ウェブスクレイピングアクティビティに関与するデバイスのIPアドレスをブロックします。このような場合、プロキシを導入してIPアドレスと所在地を隠すことで、ウェブサイトがユーザーを特定してブロックするのを防げます。
また、複数のプロキシを同時に使用することで、ウェブスクレイピングのアクティビティを異なるIPアドレスに分散させ、ウェブスクレイピングのプロセスを高速化し、スクレイパーが複数のリクエストを同時に行うことができます。
これで、ウェブスクレイピングプロジェクトにおいてプロキシがどのように役立つかをご理解いただけたことでしょう。次にRequests Pythonパッケージを使ってプロジェクトにプロキシを実装する方法を説明します。
Pythonリクエストでプロキシを使う方法
Pythonリクエストでプロキシを使用するには、お使いのコンピュータ上に新しいPythonプロジェクトを作成し、ウェブスクレイピング用のPythonスクリプトを記述して実行する必要があります。ソースコードファイルを格納するディレクトリ(つまりweb_scrape_project)を作成します。
このチュートリアルのコードはすべて、このGitHubリポジトリにあります。
パッケージのインストール
ディレクトリを作成したら、ウェブページにリクエストを送信してリンクを収集するために、以下のPythonパッケージをインストールする必要があります。
- Beautiful Soup
プロキシIPアドレスの構成要素
プロキシを使う前に、その構成要素を理解するのが最善です。以下は、プロキシサーバーの3つの主要な構成要素です。
- プロトコルは、インターネット上でアクセスできるコンテンツの種類を示します。最も一般的なプロトコルはHTTPとHTTPSです。
- アドレスは、プロキシサーバーの所在地を示します。アドレスはIP(例:
192.167.0.1)またはDNSホスト名(例:proxyprovider.com)です。 - ポートは、1台のマシンで複数のサービスが実行されている場合に、トラフィックを適切なサーバープロセスに誘導するために使用されます(例:ポート番号
2000)。
これら3つの構成要素をすべて使うと、プロキシIPアドレスは、192.167.0.1:2000またはproxyprovider.com:2000のようになります。
リクエスト内で直接プロキシを設定する方法
Pythonリクエスト内でプロキシを設定する方法はいくつかありますが、この記事では3つの異なるシナリオを紹介します。この最初の例では、リクエストモジュールで直接プロキシを設定する方法を学びます。
最初に、ウェブスクレイピング用のPythonファイルにRequestsとBeautiful Soupパッケージをインポートする必要があります。次に、ウェブページをスクレイピングする際にIPアドレスを隠すためのプロキシサーバー情報を含むproxiesというディレクトリを作成します。ここでは、プロキシURLへのHTTP接続とHTTPS接続の両方を定義する必要があります。
また、データをスクレイピングしたいウェブページのURLを設定するPython変数を定義することも必要です。このチュートリアルのURLはhttps://brightdata.com/です。
次に、request.get()メソッドを使ってウェブページにGETリクエストを送信する必要があります。このメソッドは、ウェブサイトのURLとプロキシという2つの引数を取ります。そして、ウェブページからのレスポンスが、response変数に格納されます。
リンクを収集するには、Beautiful Soupパッケージを使用して、response.contentとhtml.parserを引数としてBeautifulSoup()メソッドに渡すことで、ウェブページのHTMLコンテンツを解析します。
次に、find_all()メソッドにaを引数として与えて、ウェブページ上のすべてのリンクを見つけます。最後に、get()メソッドを使って各リンクのhref属性を抽出します。
以下は、リクエスト内でプロキシを直接設定するための完全なソースコードです。
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
このコードブロックを実行すると、プロキシIPアドレスを使って定義されたウェブページにリクエストを送信し、そのウェブページへのすべてのリンクを含むレスポンスが返されます。
環境変数でプロキシを設定する方法
時には、異なるウェブページへのリクエストすべてに同じプロキシを使用することが必要な場合があります。この場合、プロキシに環境変数を設定するのは理にかなっています。
シェルでスクリプトを実行するときにいつでもプロキシの環境変数を利用できるようにするには、ターミナルで以下のコマンドを実行します。
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
ここで、HTTP_PROXY変数にはHTTPリクエスト用のプロキシサーバーを設定し、HTTPS_PROXY変数にはHTTPSリクエスト用のプロキシサーバーを設定します。
この時点で、Pythonコードには数行のコードが含まれており、ウェブページにリクエストするたびにこれらの環境変数が使用されます。
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
カスタムメソッドとプロキシの配列を使用してプロキシをローテーションさせる方法
ウェブサイトは、同じIPアドレスから大量のリクエストを受けると、しばしばボットやスクレイパーのアクセスをブロックしたり制限したりするため、プロキシをローテーションさせることは非常に重要です。このような場合、ウェブサイトは悪質なスクレイピングアクティビティを疑い、その結果、アクセスをブロックまたは制限する措置を講じることがあります。
異なるプロキシIPアドレスをローテーションすれば、検出を回避し、複数のオーガニックユーザーに見せかけ、ウェブサイトに実装されているほとんどのスクレイピング対策を回避できます。
プロキシをローテーションさせるためには、いくつかのPythonライブラリ、Requests、Beautiful Soup、Randomをインポートする必要があります。
次に、ローテーションのプロセスで使用するプロキシのリストを作成します。このリストには、プロキシサーバーのURLを次の形式で含める必要があります: http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
そして、get_proxy()というカスタムメソッドを作成します。このメソッドではrandom.choice()メソッドを使用して、プロキシのリストからランダムにプロキシを選択し、選択したプロキシを辞書形式で返します(HTTPキーとHTTPSキーの両方)。新しいリクエストを送るときはいつもこのメソッドを使用します。
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
get_proxy()メソッドを作成したら、ローテーションするプロキシを使って、一定数のGETリクエストを送信するループを作成する必要があります。各リクエスト内で、get()メソッドは、get_proxy()メソッドで指定されたランダムに選ばれたプロキシを使用します。
次に、最初の例で説明したように、Beautiful Soupパッケージを使って、ウェブページのHTMLコンテンツからリンクを収集する必要があります。
最後に、Pythonコードはリクエストプロセス中に発生した例外をキャッチし、エラーメッセージをコンソールに出力します。
この例の完全なソースコードを以下に示します。
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
PythonでBright Dataプロキシサービスを使用する
ウェブスクレイピングタスク用に信頼性が高く、高速で安定したプロキシをお探しなら、幅広いユースケースに対応するさまざまなタイプのプロキシを提供するウェブデータプラットフォームであるBright Dataにお任せください。
Bright Dataには、信頼性が高く、高速なプロキシソリューションの提供に役立つ、400M+ monthlyを超えるレジデンシャルIPと77万を超えるデータセンタープロキシの大規模なネットワークがあります。同社のプロキシ製品は、ウェブスクレイピング、広告検証、および匿名で効率的なウェブデータ収集を必要とするその他のオンライン活動における課題の克服を支援するよう設計されています。
Bright DataのプロキシをPythonリクエストに統合するのは簡単です。例えば、データセンタープロキシを使って、前掲の例で使ったURLにリクエストを送信します。
まだアカウントをお持ちでないなら、Bright Dataの無料トライアルにサインアップし、ユーザー情報を追加してプラットフォームにアカウントを登録してください。
完了したら、以下の手順に従って最初のプロキシを作成します。
Bright Dataが提供するさまざまなタイプのプロキシを表示するには、ウェルカムページのプロキシ製品を見るをクリックしてください。
データセンタープロキシを選択して新しいプロキシを作成し、次のページで詳細を追加して保存します。

プロキシが作成されると、重要なパラメータ(つまりホスト、ポート、ユーザー名、パスワード)が表示可能になり、プロキシへのアクセスと使用を開始できます。
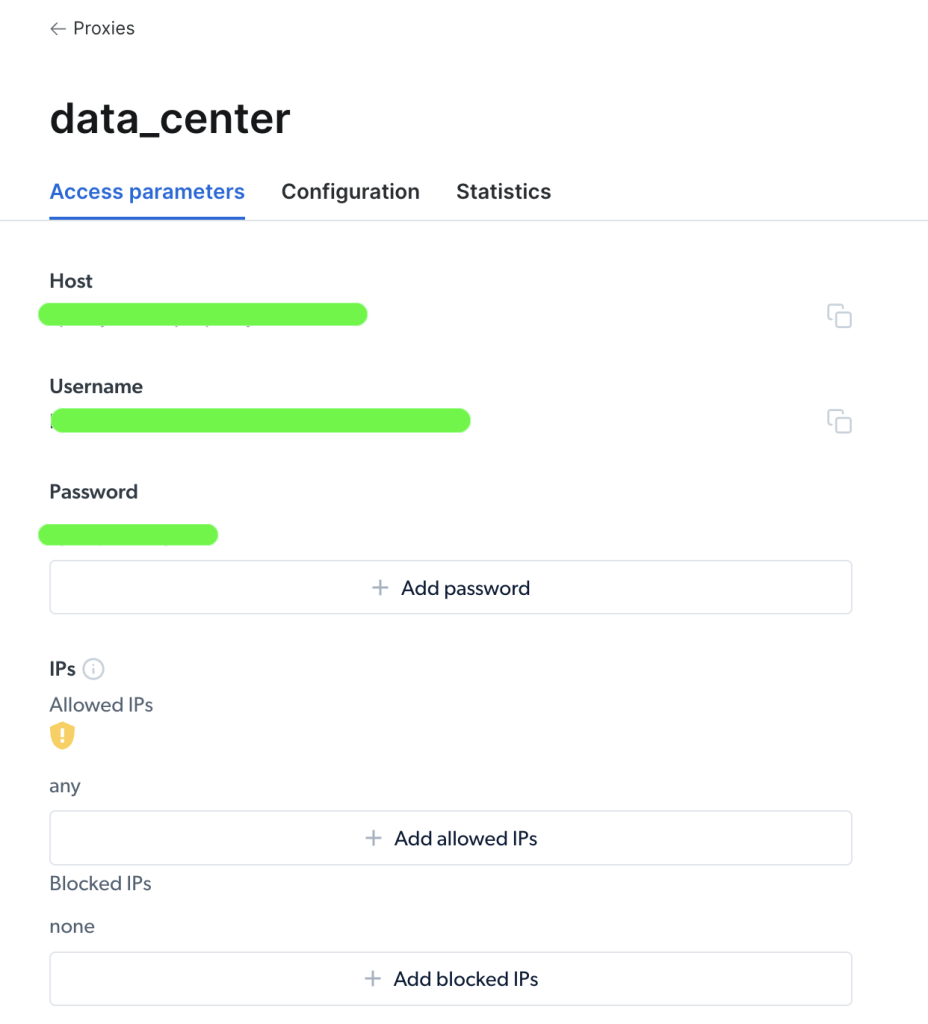
プロキシにアクセスしたら、パラメータ情報を使ってプロキシURLを構成し、Requests Pythonパッケージを使ってリクエストを送信できます。プロキシURLの形式は、username-(session-id)-password@host:portです。
注:
session-idは、randomと呼ばれるPythonパッケージを使用して作成される乱数です。
以下に、PythonリクエストでBright Dataからプロキシを設定するコードサンプルを示します。
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
ここで、パッケージをインポートし、プロキシのホスト、ポート、ユーザー名、パスワード、session_id変数を定義します。次に、httpとhttpsのキーとプロキシ資格情報を含むproxies辞書を作成します。最後に、proxiesパラメータをrequests.get()関数に渡してHTTPリクエストを行い、URLからリンクを収集します。
以上です!これで、Bright Dataのプロキシサービスを使用したリクエストの作成が無事完了しました。
まとめ
この記事では、プロキシが必要な理由、およびプロキシを使用して、Requests Pythonパッケージでウェブページにリクエストを送るさまざまな方法について説明しました。
Bright Dataのウェブプラットフォームでは、世界中のどの国や都市にも対応する信頼性の高いプロキシを入手できます。さまざまなタイプのプロキシやウェブスクレイピング用のツールを使って、必要なデータを取得する方法がいくつも提供されています。
市場調査データの収集、オンラインレビューの監視、競合他社の価格設定の追跡など、Bright Dataは迅速かつ効率的に業務を遂行するために必要なリソースを備えています。






