

このXPath対CSSセレクタガイドでは、以下の内容を学びます:
- XPath式とは何か、その仕組み、長所と短所。
- – CSSセレクタの定義、動作原理、長所と短所
- パフォーマンス、簡潔さ、使用事例におけるXPath式とCSSセレクタの比較
さあ、始めましょう!
XPath:完全分析
XPath 対 CSS セレクタガイドは、比較の最初の要素である XPath から始めましょう。
定義
XPath(XML Path Languageの略称)は、DOMをナビゲートしクエリを実行するためのクエリ言語です。特に、XML/HTML文書から情報を特定・抽出する強力な手段を提供します。
XPathの構文はファイルシステムに似ており、XML/HTMLツリー内のノードを特定する式に依存しています。XPath式は、文書の階層構造内にある特定の要素や属性へのパスを定義します。
構文
以下にXPath構文の主要な構成要素を分解して示します:
/: ルートノードからノードの選択を開始します。//: 現在のノードから選択条件に一致するドキュメント内のノードを選択します(位置に関係なく)。.:現在のノードを選択します。..: 現在のノードの親ノードを選択します。@: ノードの属性を選択します。element: 特定のタグ(例:div)に基づいてノードを選択します。[条件]: 指定された条件に基づいてノードを選択します(例:[@type="submit"])。function(): 式に対して特定のXPath関数を適用します(例:text()は選択されたノードのテキスト内容を返します)。
XPathの構文をより理解するための例:
//a: ドキュメント内のすべての<a>要素を選択します。//ul/li:<ul>要素の子である全ての<li>要素を選択します。//ul/..:<ul>要素の親ノードをすべて選択します。//ul/li[@category='fiction']:category属性が’fiction’に等しい<ul>タグの子である<li>要素をすべて選択します。//title[@lang='en']: ドキュメント内のlang属性が'en'に等しい全ての<title>要素を選択します。- //title/text(): ドキュメント内の全ての
<title>要素のテキスト内容を取得します。 //div[contains(@class, 'post')]/following-sibling::div[1]: クラス'post'を持つ各<div>要素の直下の最初の<div>要素を選択します。
XPath 式は、複数の関数や条件を組み合わせるためのブール演算子や算術演算子もサポートしていることに注意してください。
長所
- 高い汎用性: XMLとHTML構造の両方をナビゲートでき、要素、属性、テキストノードを正確にターゲットにできます。DOMの前方/後方トラバーサル、親ノードや兄弟ノードの選択もサポートします。
- 豊富な関数と演算子:XML/HTML文書内のデータを操作・比較するための豊富な組み込み関数(例:
contains()、concat()、count()など)と演算子(例:+、or、andなど)を備えています。 - 絶対パスと相対パスの両方のサポート:XPath式は、ドキュメントのルートからのパス(絶対パス)または特定の要素からのパス(相対パス)で目的のノードを記述します。
- テキストノード選択のサポート:テキストノードを直接選択できるため、追加の処理やパースを必要とせずに XML/HTML ドキュメントからテキストコンテンツを抽出することが可能になります。
- プラットフォーム非依存性:特定のプログラミング言語やプラットフォームに依存せず、幅広い環境、ライブラリ、ブラウザ、オペレーティングシステムをサポートします。
欠点
- 複雑で長い構文:XPathの構文は、特に初心者にとって難解な場合があります。DOM内に深くネストされた特定のノードへのパスを記述すると、関数や演算子を含む長い式になる可能性があります。これによりXPath式はエラーが発生しやすく、デバッグが困難になることがあります。
- サポートと普及の制限:すべてのHTMLパースライブラリがXPathをサポートしているわけではありません。これは、CSSセレクタがWeb開発者の間でより広く普及しており、ライブラリがそれらに重点を置く傾向があるためです。さらに、HtmlAgilityPackのようなほとんどのXPathベースのライブラリは、1999年にリリースされたXPath 1.0に依存したままです。現在のバージョンは2017年にリリースされたXPath 3.1です。C#によるウェブスクレイピングのエキスパートになるには、HtmlAgilityPackガイドをお読みください。
ヒントとテクニック
Chromeでは、ブラウザ内で直接XPath式をテスト・取得できます。
特定のウェブページ要素を選択したい場合を考えてみましょう。Chromeでそのページにアクセスし、対象ノードを右クリックして「要素を調べる」を選択します。
対象のDOM要素を右クリックし、「コピー>XPathをコピー」を選択すると、その要素へのXPath式を取得できます。上記の例では、次のような式が得られます:
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
注:これは効果的なXPath選択戦略の構築方法を理解するのに役立ちます。ただし、自動生成されたXPath式は長くなりすぎ、実装依存の傾向があります。そのため、本番環境ではこれだけに依存できません。
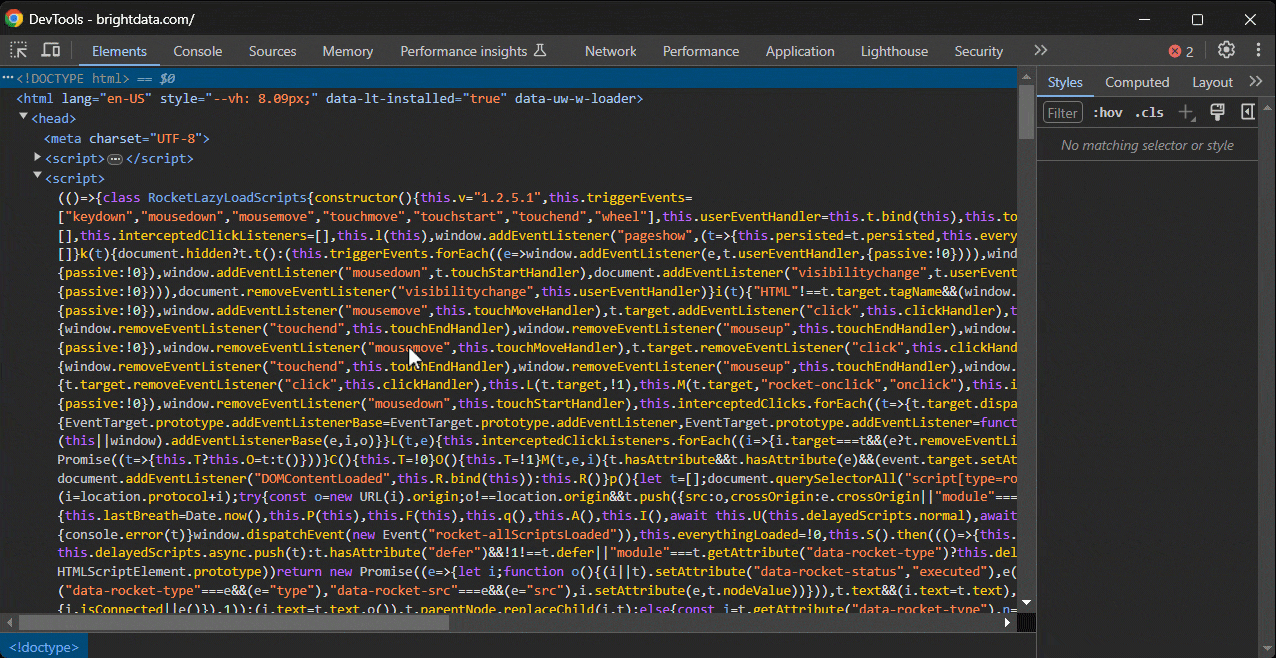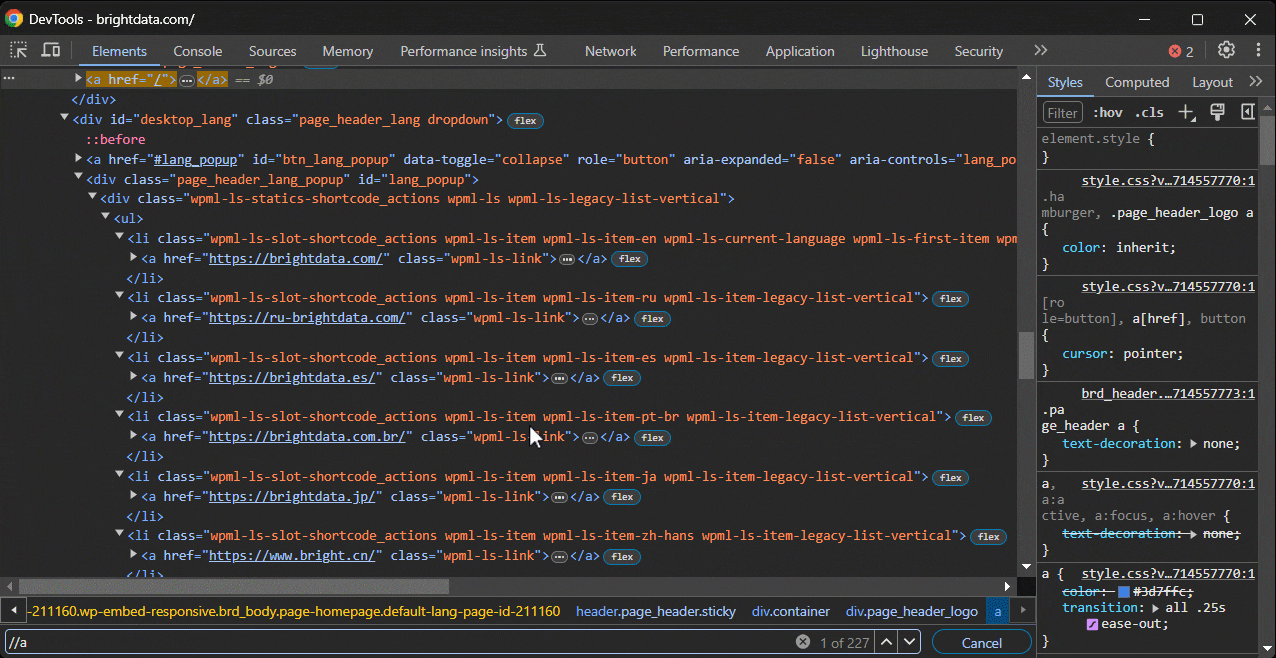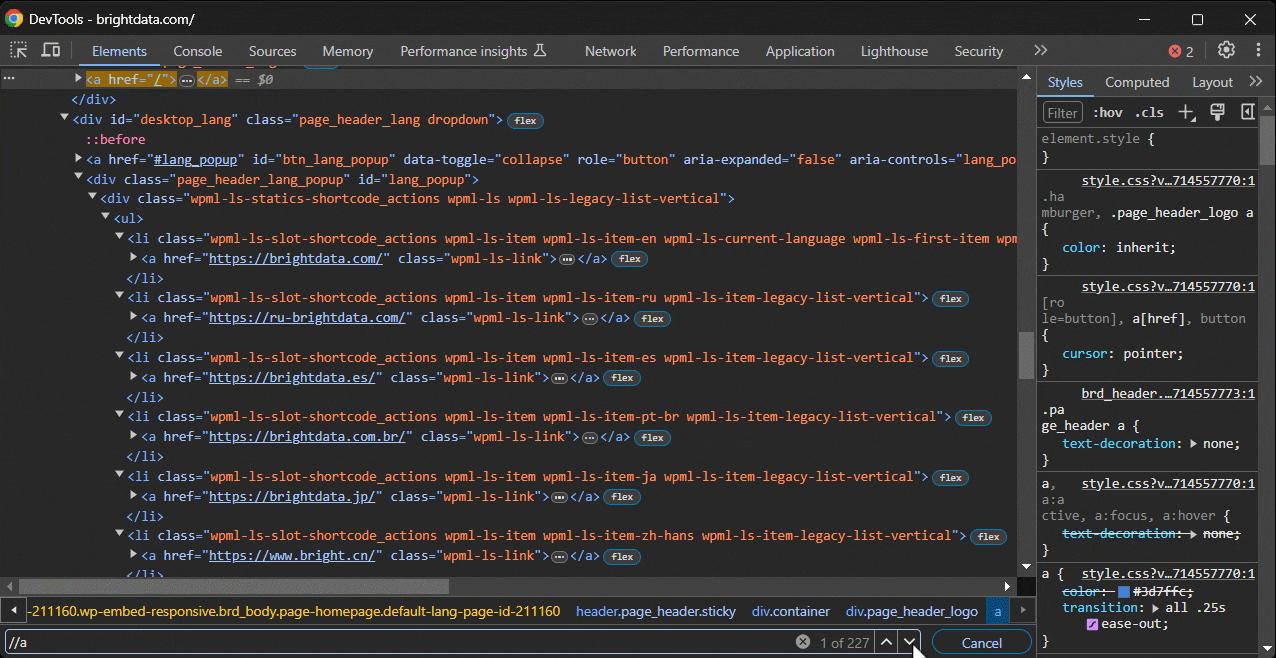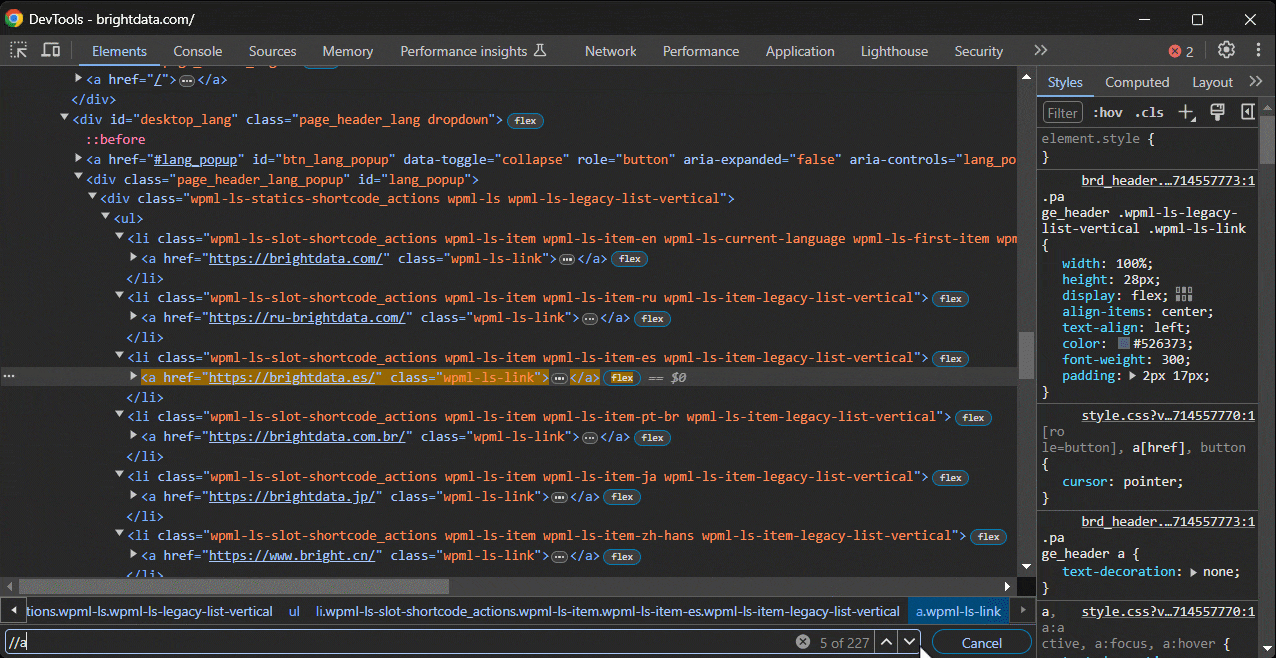
次に、ページ上でXPath式をテストします。Chromeでは2つの方法があります。
まず、XPath式をDevToolsの「要素」セクションの検索バーに貼り付けます(CTRL/Command + Fで表示可能)。
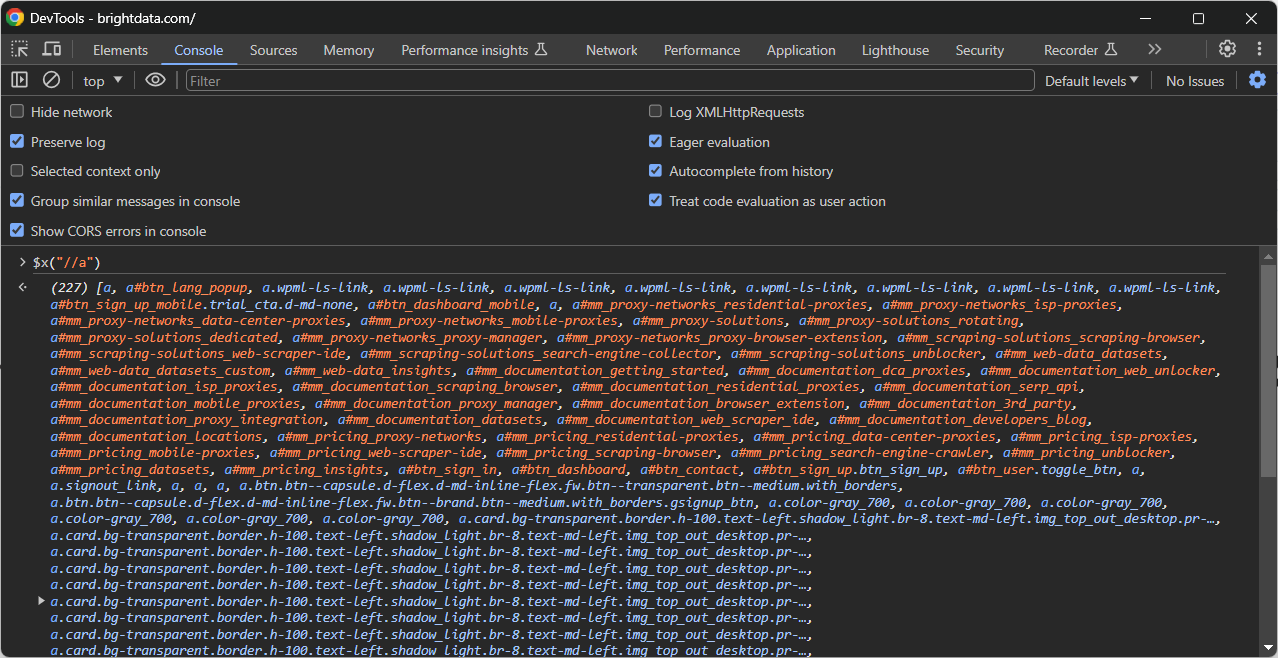
次に、コンソールで特殊関数$x() を呼び出します:
CSSセレクタ:詳細レビュー
XPath対CSSセレクタの比較記事の第二要素であるCSSセレクタについて探求し、この記事を続けます。
定義
CSSセレクターは、ウェブページ内のHTML要素を選択することを可能にします。CSSの一部であり、ウェブページ上のHTML要素をターゲットにするために使用されます。同様に、ヘッドレスブラウザツールやHTMLパースライブラリも、DOM上のノードを選択する方法としてこれをサポートしています。
CSS セレクタは、ID、クラス、属性、ドキュメントツリー内の位置に基づいて、単一の要素または要素のグループをターゲットにできます。CSS セレクタは、Web ページにスタイルや書式を適用する上で重要な役割を果たす一方で、ウェブスクレイピングにおいても優れたツールとなります。
構文
CSSセレクタの構文を説明する最良の方法は、いくつかの例を通じて示すことです:
- 要素セレクタ: タグ名に基づいて要素をターゲットにします。例えば、
p はDOM 内のすべての<p>要素を選択します。 - クラスセレクタ:特定のクラス属性を持つ要素をターゲットにします。例:
.highlight はclass="highlight <other_classes>"HTML 属性を持つ全ての要素を選択します。 - IDセレクタ:ID属性で特定要素を指定します。例:
#navbar はid="navbar"の要素を選択します。 - 属性セレクタ:属性を基に要素をターゲットにします。例:
input[type="text"] はtype="text"属性を有する全ての<input>要素を選択します。 - 子孫セレクタ: 他の要素の子孫である要素をターゲットにします。例えば、
div a は<div>要素の子孫である全ての<a>要素を選択します。 - 子セレクタ: 別の要素の直接の子要素である要素をターゲットにします。例えば、
ul > li は<ul>要素の直接の子であるすべての<li>要素を選択します。 - 隣接兄弟セレクタ:指定された兄弟要素の直前に位置する要素をターゲットにします。例えば、
h2 + p は<h2>要素の直後に位置する<p>要素を選択します。
異なるブラウザではCSS標準の実装が異なることに留意してください。特定のCSS演算子や構文の互換性については、caniuse.comなどのサイトで確認してください。
長所
- 優れたパフォーマンス:ほとんどのブラウザには専用のCSSセレクタエンジンが搭載されており、高いパフォーマンスを保証します。このエンジンは主にスタイリングに使用されますが、ブラウザ自動化ツールを介してページ上でCSSセレクタを使用する際にも役立ちます。
- 習得が容易:直感的な構文のおかげで、初心者でもCSSセレクタを習得するまでの学習曲線はかなり緩やかです。
- 簡潔で広く認知された構文:複雑な演算子や関数を必要としない簡潔な構文を備えています。さらに、ほとんどのウェブ開発者がその使用方法を理解しているため、スタイリング以外の用途でも活用できます。
- 優れた保守性:CSSセレクタは読みやすく更新しやすい設計となっており、コードのメンテナンスを簡素化します。
- 包括的な互換性:現代のウェブブラウザと主要なウェブスクレイピングツールがサポートしているため、環境固有の回避策を必要とせず、異なるプラットフォーム、デバイス、ユースケース間で一貫したノード選択が保証されます。
短所
- 高度な関数や演算子の非対応:XPathとは対照的に、CSSセレクタは非常にシンプルで、多くの関数や演算子を備えていません。例えば、テキストノードの選択やDOMからのデータ抽出には使用できません。
- DOMツリーの上方向探索をサポートしない:DOM内の要素はルートノードから開始し下方向のみ探索可能。
ヒントとテクニック
XPathと同様に、Chromeではページ上で直接CSSセレクタをテスト・生成できます。
特定のノードを対象とするCSSセレクタの作成に興味があると仮定します。Chromeで対象ページにアクセスし、目的の要素を右クリックして「要素を検査」を選択します:
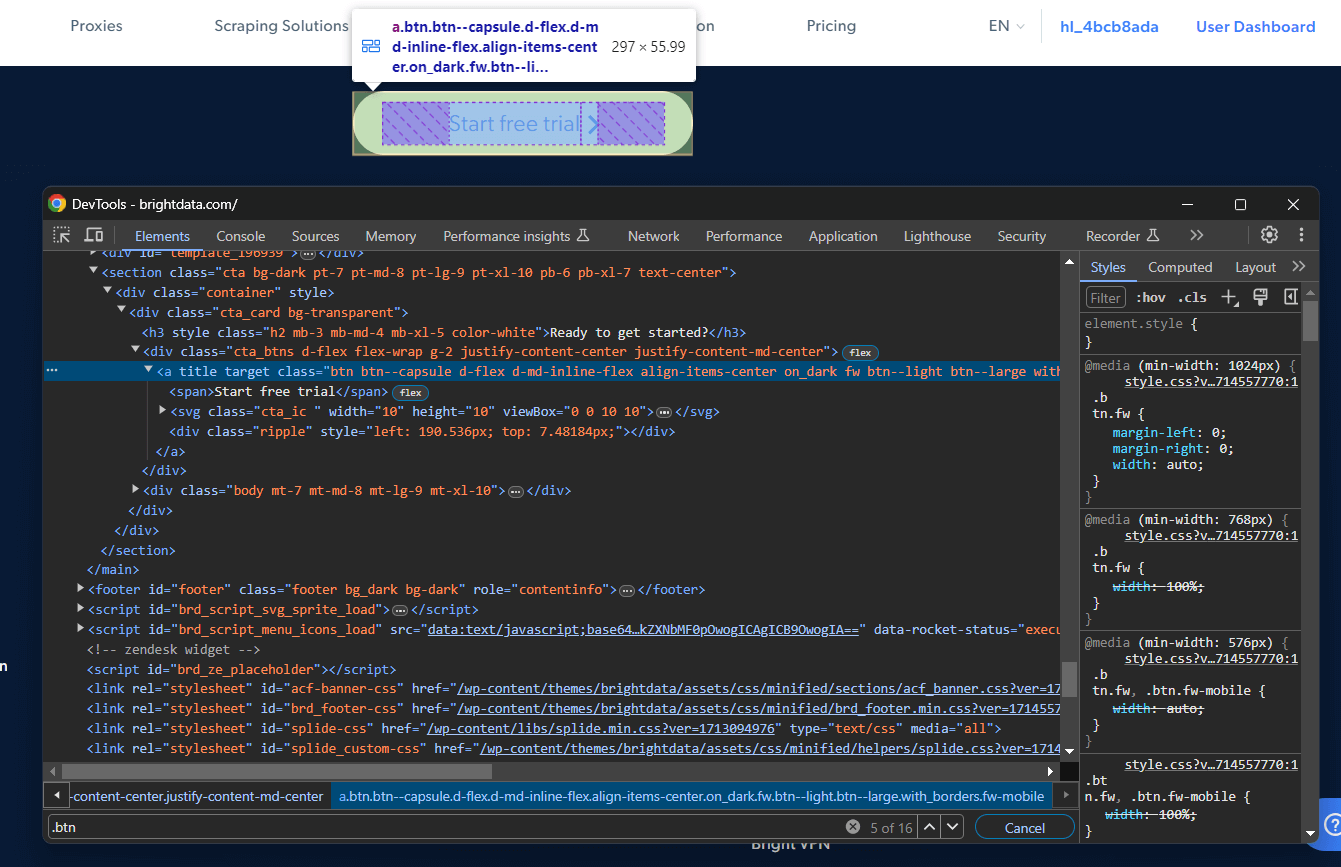
対象のDOM要素を右クリックし、「コピー>セレクタをコピー」を選択すると、完全なCSSセレクタを取得できます。上記の例では以下が取得されます:
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
ご覧の通り、長すぎて実装固有のものです。概要を把握するには有用ですが、この関数で生成されたCSSセレクタを本番環境で使用しないでください。
ウェブページ上のCSSセレクタをテストする必要があるとします。Chromeでは、それを行う方法がいくつかあります。
最初の方法は、以下のように検索バーにCSSセレクタを貼り付けることです(CTRL/Command + Fショートカットで 起動可能)。
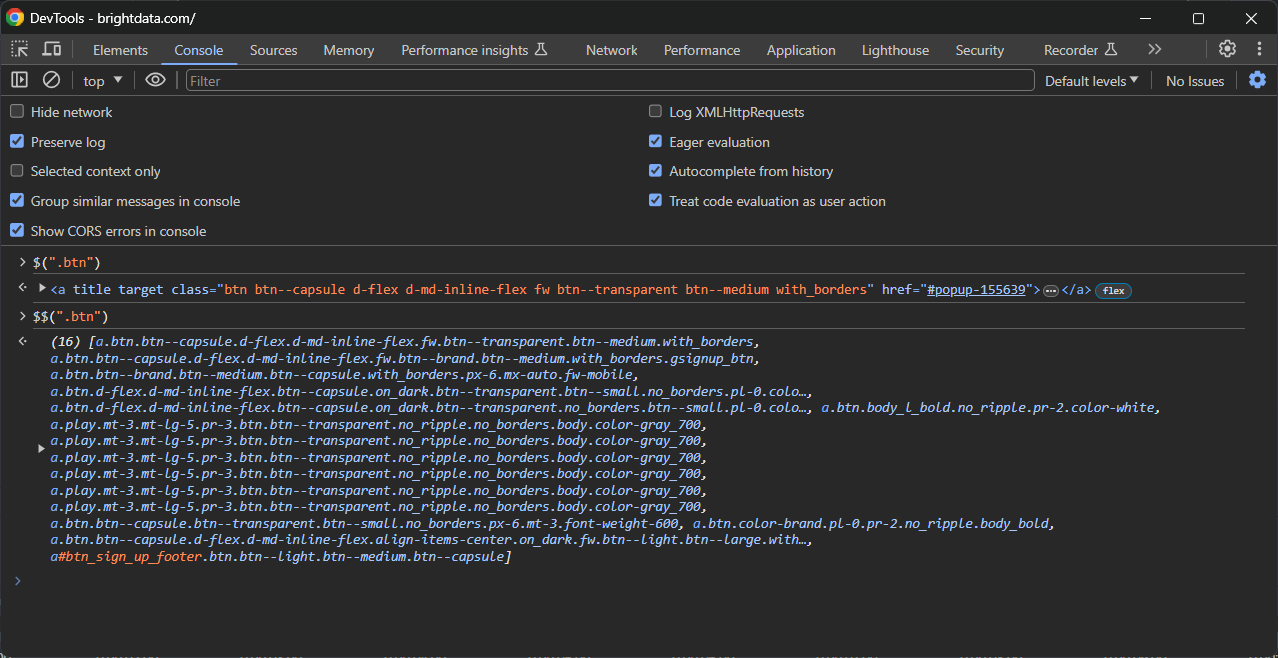
二つ目は、コンソールで以下の特殊関数を使用してテストする方法です:
以下の例のように使用します:
同様に、JavaScriptのquerySelector()およびquerySelectorAll()関数も使用可能です:
XPath vs CSSセレクター:直接比較
XPathとCSSセレクタの概念を理解したところで、XPathとCSSセレクタの比較分析に進みましょう。
一目でわかる直接比較については、以下の要約表をご覧ください:
| 項目 | XPath | CSSセレクター |
| W3C標準 | はい | はい |
| 最新仕様 | XPath 3.1 (2017) | CSS レベル 4 (継続的に更新中) |
| 互換性 | ほとんどのブラウザとスクレイピングツールは依然としてXPath 1.0をサポートしています | ほとんどのブラウザとスクレイピングツールは最新の仕様でサポートしています |
| 構文 | 複雑で冗長 | 簡潔で明瞭 |
| 関数と演算子 | 多数 | 少ない |
| テキストノードの選択 | サポート | サポートされていない |
| ブラウザでのパフォーマンス | 中程度/遅い | 高速 |
| ライブラリサポート | 通常、XMLパースライブラリでサポートされています | ほとんどのHTMLパースライブラリで通常サポートされる |
簡潔さ
XPath構文はCSSセレクタと比較して一般的に非常に複雑に見えます。その構文はパスベースのクエリ言語に似ており、XPathに慣れていない開発者にとっては習得が難しいです。しかし、XPathは要素の選択とトラバースを精密に制御できます。
DOM要素の選択に関しては、CSSセレクタの方が一般的にシンプルで直感的です。タグ名、クラス、IDといった馴染みのあるパターンを使用するため、初心者でも理解・使用が容易です。CSSセレクタはウェブ開発で広く採用されているため、その構文は非常に親しみやすいものとなっています。
速度
ベンチマークが示すように、ブラウザ内のDOMツリーに適用されるXPath式はCSSセレクタよりも遅い傾向があります。その理由は、XPathエンジンは通常、CSSセレクタエンジンよりも複雑なトラバース操作を実行する必要があるためです。さらに、ほとんどの現代的なブラウザは高度に最適化されたCSSセレクタエンジンを備えており、HTML要素の効率的な選択を可能にしています。HTMLパースライブラリに関しては、パフォーマンスの差は基盤となる実装に依存します。
ユースケース
XPathは、XSLTを用いたXMLドキュメントのクエリやナビゲーション、あるいは単純なデータ抽出に最適です。親ノードをターゲットとする場合など、特定のスクレイピングシナリオではその高度な機能が有用です。CSSセレクタは主に、HTMLドキュメントのスタイリングや、現代的なウェブスクレイピングスクリプトにおけるノード選択に使用されます。
結論
XPathとCSSセレクタのどちらを選ぶべきか?本ガイドでは、両者がDOM要素選択に有効な手法であることを学びました。XPathはXML文書に重点を置き高度な機能を提供し、CSSセレクタはHTMLページで優れた性能を発揮しシンプルです。
ウェブスクレイピングでXPath式やCSSセレクタを使用する際の真の問題は、ボット対策技術によるブロックです。採用するノード選択戦略に関わらず、これらのシステムは自動スクレイピングスクリプトを検知・ブロックします。幸い、Bright Dataは優れた解決策を複数提供しています:
- WebスクレイパーAPI: 数十の主要ドメインから構造化されたウェブデータへプログラムでアクセスするための使いやすいAPI。
- スクレイピングブラウザ: CAPTCHA処理、ブラウザフィンガープリント対策、自動リトライなどを自動化し、JavaScriptレンダリング機能を備えたクラウドベースの制御可能ブラウザ。PlaywrightやPuppeteerなど主要な自動化ブラウザライブラリと連携。
- Web Unlocker:あらゆるページの生のHTMLをシームレスに返すアンロックAPI。あらゆるウェブスクレイピング対策も回避します。
ウェブスクレイピング自体には関心がなく、オンラインデータのみが必要な場合でも、当社のすぐに使えるデータセットをご検討ください!





