

このガイドでは以下を学びます:
- – Undetected ChromeDriver の概要とその有用性
- ボット検知を最小化する仕組み
- Pythonを用いたウェブスクレイピングでの活用方法
- 高度な使用法と手法
- 主な制限事項と欠点
- 類似技術
さっそく見ていきましょう!
Undetected ChromeDriverとは?
Undetected ChromeDriverは、SeleniumのChromeDriverを最適化したPythonライブラリです。以下のようなアンチボットサービスによる検知を制限するためにパッチが適用されています:
- Imperva
- DataDome
- Distil Networks
特定のCloudflare保護機能の回避にも役立ちますが、こちらはより困難な場合があります。詳細は、Cloudflare回避方法のガイドを参照してください。
Seleniumのようなブラウザ自動化ツールを使用したことがある方なら、プログラムでブラウザを制御できることをご存知でしょう。これを実現するため、これらのツールは通常のユーザー設定とは異なる方法でブラウザを構成します。
アンチボットシステムは、自動化されたブラウザボットを識別するために、こうした違い、つまり「リーク」を探します。検出されない ChromeDriver は、こうした特徴的な兆候を最小限に抑えるために Chrome ドライバーをパッチし、ボットの検出を減少させます。これにより、アンチスクレイピング対策で保護されているサイトをウェブスクレイピングするのに理想的です。
動作原理
Undetected ChromeDriverは、以下の技術を用いてCloudflare、Imperva、DataDomeなどのソリューションからの検知を低減します:
- – 実際のブラウザが使用するものと同一のSelenium変数名へのリネーム
- 検出回避のため、正当な実在のUser-Agent文字列を使用
- ユーザーが自然な人間の操作をシミュレートできるようにする
- ウェブサイト閲覧時のクッキーとセッションの適切な管理
- プロキシの使用を許可し、IPブロックの回避とレート制限の防止を実現
これらの手法により、ライブラリが制御するブラウザは様々なスクレイピング対策防御を効果的に回避できます。
検出されないChromeDriverを使用したウェブスクレイピング:ステップバイステップガイド
ほとんどのサイトは、自動化されたスクリプトがページにアクセスするのをブロックするために高度なアンチボット対策を使用しています。これらのメカニズムは、ウェブスクレイピングボットも効果的に阻止します。
例えば、以下のGoDaddy製品ページからタイトルと説明をスクレイピングしたい場合を考えてみましょう:
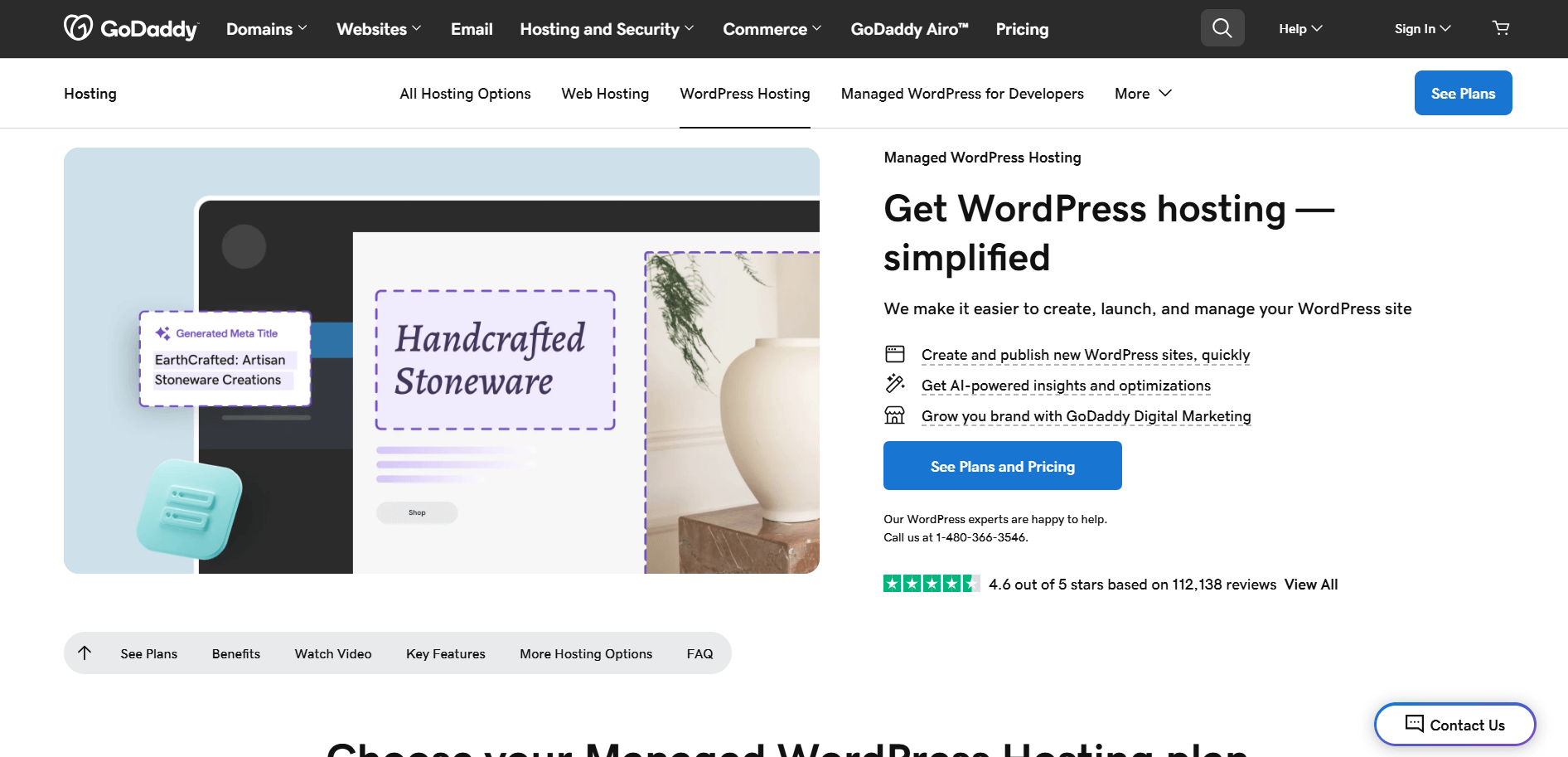
Pythonの標準Seleniumを使用する場合、スクレイピングスクリプトは以下のような形になります:
# pip install selenium
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# ヘッドレスモードで起動するChromeインスタンスを設定
options = Options()
options.add_argument("--headless")
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service(), options=options)
# 対象ページへの接続
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# スクラッピングロジック...
# ブラウザの終了
driver.quit()
このロジックに不慣れな場合は、Seleniumウェブスクレイピングのガイドを参照してください。
スクリプトを実行すると、以下のエラーページにより失敗します:

つまり、Seleniumスクリプトがボット対策ソリューション(この例ではAkamai)によってブロックされている状態です。
では、この問題をどう回避するか?答えはUndetected ChromeDriverです!
以下の手順に従い、ウェブスクレイピング用Pythonライブラリ「undetected_chromedriver」の使用方法を学びましょう。
ステップ #1: 前提条件とプロジェクト設定
Undetected ChromeDriverには以下の前提条件があります:
- Chromeの最新バージョン
- Python 3.6+: お使いのマシンにPython 3.6以降がインストールされていない場合は、公式サイトからダウンロードし、インストール手順に従ってください。
注: このライブラリは自動的にドライバーバイナリをダウンロードしてパッチを適用するため、ChromeDriverを手動でダウンロードする必要はありません。
次に、プロジェクト用のディレクトリを作成するために以下のコマンドを実行してください:
mkdir undetected-chromedriver-スクレイパー
undetected-chromedriver-scraper ディレクトリが Python スクレイパーのプロジェクトフォルダとなります。
このディレクトリに移動し、仮想環境を初期化します:
cd undetected-chromedriver-スクレイパー
python -m venv env
お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual StudioCodeやPyCharm Community Editionが優れた選択肢です。
次に、プロジェクトフォルダ内に以下の構造に従ってscraper.pyファイルを作成します:
現在のところ、scraper.pyは空の Python スクリプトです。間もなく、ここにスクレイピングロジックを追加します。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは以下を使用します:
./env/bin/activate
Windowsの場合は同等のコマンドを実行します:
env/Scripts/activate
素晴らしい!これでブラウザ自動化によるウェブスクレイピング用のPython環境が整いました。
ステップ #2: Undetected ChromeDriver のインストール
アクティブ化された仮想環境内で、pipパッケージ「undetected_chromedriver」を使用してUndetected ChromeDriverをインストールします:
pip install undetected_chromedriver
このライブラリは依存関係としてSeleniumを自動的にインストールします。そのため、Seleniumを別途インストールする必要はありません。これにより、デフォルトですべてのseleniumインポートが利用可能になります。
ステップ #3: 初期設定
undetected_chromedriver をインポートします:
import undetected_chromedriver as uc
次に、Chrome WebDriverを初期化します:
driver = uc.Chrome()
Seleniumと同様に、これによりブラウザウィンドウが開かれ、Selenium APIを使用して制御できます。つまり、このドライバーオブジェクトは標準的なSeleniumメソッドすべてに加え、後述する追加機能を提供します。
主な違いは、このバージョンのChromeドライバーが特定のボット対策ソリューションを回避できるよう修正されている点です。
ドライバーを閉じるには、quit() メソッドを呼び出します:
driver.quit()
基本的なUndetected ChromeDriverの設定例は以下の通りです:
import undetected_chromedriver as uc
# Chromeインスタンスの初期化
driver = uc.Chrome()
# スクラッピングロジック...
# ブラウザを閉じ、リソースを解放
driver.quit()
素晴らしい!これでブラウザ内で直接ウェブスクレイピングを実行する準備が整いました。
ステップ #4: ウェブスクレイピングに活用する
注意: このセクションは標準的なSelenium設定と同じ手順です。Seleniumによるウェブスクレイピングに既に慣れている場合は、最終コードが記載された次のセクションへ進んでください。
まず、get()メソッドを使用してブラウザをターゲットページに移動させます:
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
次に、ブラウザのシークレットモードで該当ページにアクセスし、スクレイピング対象の要素を検査します:
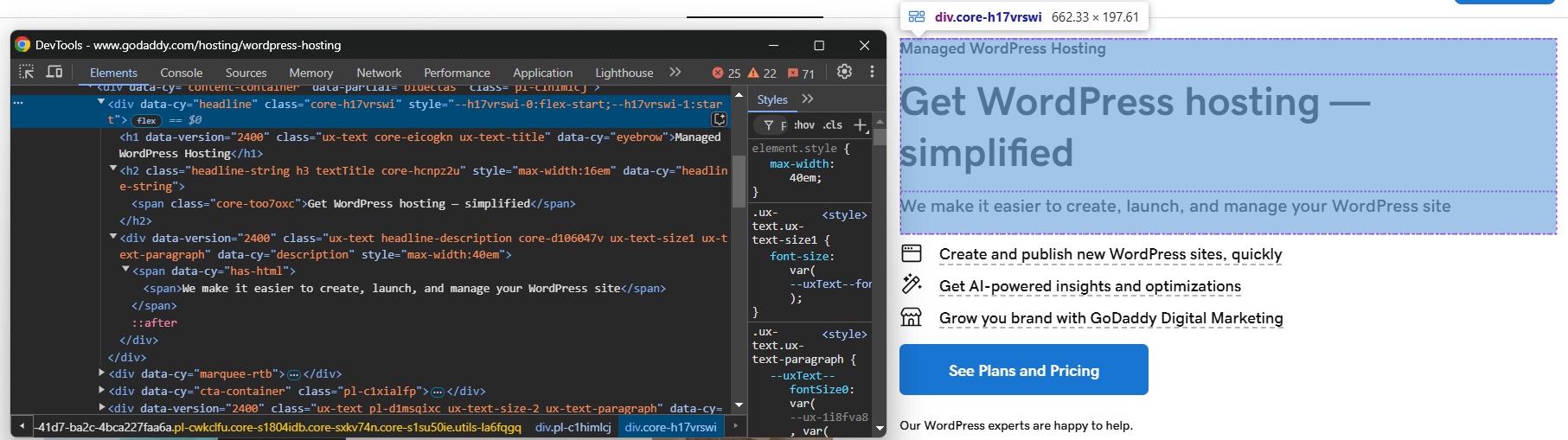
製品タイトル、キャッチコピー、説明文を抽出すると仮定します。
以下のコードでこれら全てをスクレイピングできます:
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
上記のコードを動作させるには、SeleniumからByをインポートする必要があります:
from selenium.webdriver.common.by import By
次に、スクレイピングしたデータをPythonの辞書に格納します:
product = {
"title": title,
"tagline": tagline,
"description": description
}
最後に、データをJSONファイルにエクスポートします:
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
Python標準ライブラリからjsonをインポートすることを忘れないでください:
import json
これで完了です!基本的なUndetected ChromeDriverウェブスクレイピングロジックを実装しました。
ステップ #5: 全てを統合する
これが最終的なスクレイピングスクリプトです:
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
import json
# Chrome WebDriverインスタンスの作成
driver = uc.Chrome()
# 対象ページへの接続
driver.get("https://www.godaddy.com/hosting/wordpress-hosting")
# スクラッピングロジック
headline_element = driver.find_element(By.CSS_SELECTOR, "[data-cy="headline"]")
title_element = headline_element.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
tagline_element = headline_element.find_element(By.CSS_SELECTOR, "h2")
tagline = tagline_element.text
description_element = headline_element.find_element(By.CSS_SELECTOR, "[data-cy="description"]")
description = description_element.text
# スクレイピングしたデータを辞書に格納
product = {
"title": title,
"tagline": tagline,
"description": description
}
# スクレイピングしたデータをJSONにエクスポート
with open("product.json", "w") as json_file:
json.dump(product, json_file, indent=4)
# ブラウザを閉じてリソースを解放
driver.quit()
実行方法:
python3 スクレイパー.py
または、Windowsの場合:
python スクレイパー.py
これにより、Selenium単体使用時のようなエラーページではなく、対象ウェブページを表示するブラウザが開きます:

スクリプトはページからデータを抽出し、以下のproduct.jsonファイルを生成します:
{
"title": "Managed WordPress Hosting",
"tagline": "Get WordPress hosting — simplified",
"description": "We make it easier to create, launch, and manage your WordPress site"
}
undetected_chromedriver: 高度な使用法
ライブラリの動作を理解したところで、より高度なシナリオを探求する準備が整いました。
特定のChromeバージョンの指定
version_main引数を設定することで、ライブラリが使用する特定のChromeバージョンを指定できます:
import undetected_chromedriver as uc
# 対象とするChromeのバージョンを指定
driver = uc.Chrome(version_main=105)
なお、このライブラリは他のChromiumベースのブラウザでも動作しますが、追加の設定が必要です。
with構文の使用
ドライバーが不要になった際にquit()メソッドを手動で呼び出す必要を回避するため、以下のようにwith構文を使用できます:
import undetected_chromedriver as uc
with uc.Chrome() as driver:
driver.get("<YOUR_URL>")
withブロック内の処理が完了すると、Pythonが自動的にブラウザを閉じます。
注: この構文はバージョン 3.1.0 以降でサポートされています。
プロキシの統合
Undetected ChromeDriver にプロキシを追加する構文は、通常の Selenium と同様です。以下の例のように、--proxy-server フラグにプロキシ URL を渡すだけです:
import undetected_chromedriver as uc
proxy_url = "<YOUR_PROXY_URL>"
options = uc.ChromeOptions()
options.add_argument(f"--proxy-server={proxy}")
注: Chrome は--proxy-server フラグ経由での認証済みプロキシをサポートしていません。
拡張API
undetected_chromedriver は通常の Selenium 機能を拡張し、以下のメソッドを提供します:
WebElement.click_safe():リンクのクリックが検出される場合にこのメソッドを使用します。動作を保証するものではありませんが、より安全なクリックのための代替手段を提供します。WebElement.children(tag=None, recursive=False): 子要素を簡単に検索するメソッドです。例:
# body内の6番目の子要素(タグ不問)を取得し、再帰的に全ての<img>要素を検索
images = body.children()[6].children("img", True)
undetected_chromedriver Pythonライブラリの制限事項
undetected_chromedriver は強力な Python ライブラリですが、既知の制限事項がいくつか存在します。特に注意すべき重要な点を以下に示します!
IPブロック
ライブラリのGitHubページには明記されています:このパッケージはIPアドレスを隠しません。したがって、データセンターからスクリプトを実行している場合、検出される可能性が高いです。同様に、自宅のIPアドレスの評判が悪い場合もブロックされる可能性があります!

IPを隠すには、前述のようにプロキシサーバーと制御されたブラウザを統合する必要があります。
GUI操作の非対応
モジュールの内部構造上、get()メソッドを用いたプログラムによる操作が必須です。キーボードやマウスでページを操作する手動ナビゲーション(GUI操作)は検出リスクを高めるため避けてください!
新規タブの操作にも同様のルールが適用されます。複数タブを扱う必要がある場合は、ドライバーが受け付けるURL「data:」(カンマを含む)を使用して空白ページの新規タブを開いてください。その後、通常の自動化ロジックを実行します。
これらのガイドラインを厳守することで初めて、検出リスクを最小限に抑え、よりスムーズなウェブスクレイピングセッションを実現できます。
ヘッドレスモードの限定サポート
公式には、headlessモードはundetected_chromedriverライブラリで完全にはサポートされていません。ただし、以下の構文で試すことは可能です:
driver = uc.Chrome(headless=True)
作者はバージョン3.4.5の変更履歴で、ヘッドレスモードが機能しボット回避能力を保証すると発表しました。しかし、依然として不安定です。この機能は慎重に使用し、スクレイピングの要件を満たすことを確認するために徹底的なテストを行ってください。
安定性の問題
パッケージのPyPIページに記載されている通り、結果は様々な要因により変動します。検出アルゴリズムの理解と対策に向けた継続的な努力以外、いかなる保証も提供されません。
これは、Distil、Cloudflare、Imperva、DataDome、hCaptchaを今日回避できたスクリプトも、ボット対策ソリューションが更新されれば明日には失敗する可能性があることを意味します:
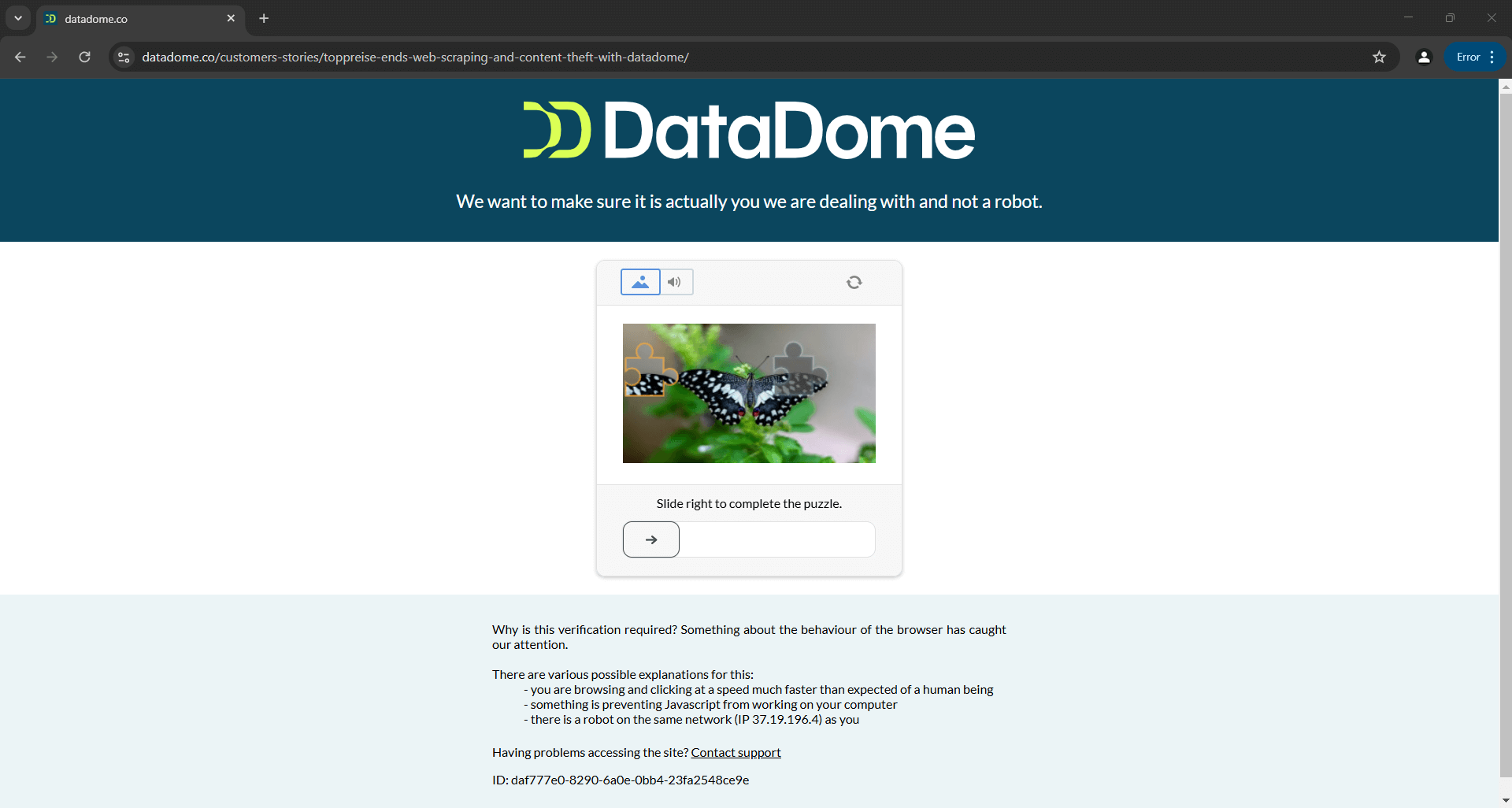
上記画像は公式ドキュメント提供スクリプトの結果です。ツール開発者自身作成のスクリプトでさえ、常に期待通りに動作するとは限らないことを示しています。具体的には、このスクリプトはCAPTCHAをトリガーし、自動化ロジックを容易に停止させ得ます。
PythonでCAPTCHAを回避する方法については、ガイドをご覧ください。
関連記事
Undetected ChromeDriverは、検出回避のためにブラウザドライバーを改変する唯一のライブラリではありません。類似ツールの探索やこのトピックの詳細に興味がある場合は、以下のガイドをお読みください:
まとめ
本記事では、Undetected ChromeDriver を使用して Selenium におけるボット検出に対処する方法を理解しました。このライブラリは、ブロックされることなくウェブスクレイピングを行うための ChromeDriver のパッチ適用版を提供します。
問題は、Cloudflareのような高度なアンチボット技術が依然としてスクリプトを検知・ブロックできる点です。undetected_chromedriverのようなライブラリは不安定であり、今日動作しても明日には機能しなくなる可能性があります。
問題はブラウザ制御のためのSeleniumのAPI自体ではなく、ブラウザの設定そのものにあります。つまり、解決策はクラウドベースで常に更新され、スケーラブルなブラウザであり、アンチボット回避機能を内蔵している必要があります。そのブラウザは存在し、スクレイピングブラウザと呼ばれています!
Bright Dataのスクレイピングブラウザは、Selenium、Puppeteer、Playwrightなどに対応した高スケーラブルなクラウドブラウザです。ブラウザフィンガープリンティング、CAPTCHA解決、自動リトライを処理します。さらに、リクエストごとに出口IPを自動ローテーションします。これは世界規模のプロキシネットワークによって実現されており、以下を含みます:
- データセンター・プロキシ– 77万以上のデータセンターIP
- レジデンシャルプロキシ– 195ヶ国以上で7200万以上のレジデンシャルIP。
- ISPプロキシ– 70万以上のISP IPアドレス。
今すぐBright Dataの無料アカウントを作成し、スクレイピングブラウザをお試しいただくか、プロキシをテストしてください。




