

このガイドでは以下を学びます:
- – SeleniumBaseとは何か、ウェブスクレイピングに有用な理由
- 標準Seleniumとの比較
- SeleniumBaseが提供する機能と利点
- – シンプルなスクレイパー構築方法
- より複雑なユースケースでの活用方法
さあ、始めましょう!
SeleniumBaseとは?
SeleniumBaseはブラウザ自動化のためのPythonフレームワークです。Selenium/WebDriver APIを基盤として構築され、ウェブ自動化のためのプロフェッショナルグレードのツールキットを提供します。テストからウェブスクレイピングまで、幅広いタスクをサポートします。
SeleniumBaseは、ウェブページのテスト、ワークフローの自動化、ウェブベースの操作の拡張を可能にするオールインワンライブラリです。CAPTCHA回避、ボット検知回避、生産性向上ツールなどの高度な機能が備わっています。
SeleniumBaseとSeleniumの比較:機能とAPIの対照
SeleniumBaseが存在する理由をより深く理解するには、その基盤となるツールである標準版Seleniumと直接比較することが有効です。
SeleniumとSeleniumBaseの簡単な比較については、以下の要約表をご覧ください:
| 機能 | SeleniumBase | Selenium |
|---|---|---|
| 組み込みテストランナー | pytest、pynose、behaveとの統合 |
テスト統合には手動設定が必要 |
| ドライバー管理 | ブラウザのバージョンに一致するブラウザドライバーを自動的にダウンロード | 手動でのドライバーダウンロードと設定が必要 |
| Web自動化ロジック | 複数のステップを単一メソッド呼び出しに統合 | 同様の機能を実現するために複数のコード行が必要 |
| セレクター処理 | CSSまたはXPathセレクタを自動検出 | メソッド呼び出しで明示的にセレクタタイプを定義する必要がある |
| タイムアウト処理 | デフォルトのタイムアウトを適用して失敗を防止 | タイムアウトが明示的に設定されていない場合、メソッドは直ちに失敗する |
| エラー出力 | デバッグを容易にするため、明確で読みやすいエラーメッセージを提供 | 詳細だが解釈しにくいエラーログを生成 |
| ダッシュボードとレポート | 組み込みのダッシュボード、レポート、障害発生時のスクリーンショットを含む | 組み込みのダッシュボードやレポート機能はなし |
| デスクトップGUIアプリケーション | テスト実行用の視覚的ツールを提供 | テスト実行用のデスクトップGUIツールが不足している |
| テストレコーダー | 手動のブラウザ操作からスクリプトを作成するための組み込みテストレコーダー | 手動でのスクリプト記述が必要 |
| テストケース管理 | テストの整理とステップの文書化をフレームワーク内で直接行うためのCasePlansを提供 | 組み込みのテストケース管理ツールなし |
| データアプリサポート | PythonからJavaScriptを生成するChartMakerを内蔵し、データアプリを作成可能 | データアプリ構築用の追加ツールはなし |
さあ、違いを掘り下げてみましょう!
組み込みテストランナー
SeleniumBaseは、pytest、pynose、behaveなどの一般的なテストランナーと連携します。これらのツールは、体系的な構造、シームレスなテストの発見、実行、テスト状態の追跡(合格、不合格、スキップなど)、ブラウザ選択などの設定をカスタマイズするためのコマンドラインオプションを提供します。
標準の Selenium では、オプションパーサーを手作業で実装するか、コマンドラインからテストを設定するためにサードパーティ製ツールに依存する必要があります。
強化されたドライバー管理
デフォルトでは、SeleniumBase はブラウザのメジャーバージョンに一致する互換性のあるドライバーバージョンをダウンロードします。pytest コマンドで--driver-version=VER オプションを使用してこれを上書きできます。例:
pytest my_script.py --driver-version=114
一方、Seleniumでは適切なドライバーを手動でダウンロード・設定する必要があります。この場合、ブラウザバージョンとの互換性を確保する責任はユーザーにあります。
マルチアクションメソッド
SeleniumBaseは、ウェブ自動化を簡素化するため、複数のステップを単一メソッドに統合します。例えば、driver.type(selector, text)メソッドは以下を実行します:
- 要素が表示されるまで待機
- 要素がインタラクティブになるのを待機
- 既存のテキストをクリア
- 指定されたテキストを入力
- テキストが
「n」で終わる場合、送信する
生のSeleniumでは、同じロジックを再現するには数行のコードが必要です。
簡略化されたセレクタ処理
SeleniumBaseはCSSセレクタとXPath式を自動的に判別します。これによりBy.CSS_SELECTORや By.XPATHで明示的に指定する必要がなくなります。ただし必要に応じて明示的に指定することも可能です。
SeleniumBase使用例:
driver.click("button.submit") # CSSセレクタとして自動検出
driver.click("//button[@class='submit']") # XPathとして自動検出
標準Seleniumでの同等コード:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
デフォルトおよびカスタムタイムアウト値
SeleniumBaseはメソッドにデフォルトで10秒のタイムアウトを自動的に適用し、要素が読み込まれる時間を確保します。これにより、生のSeleniumでよくある即時失敗を防ぎます。
以下の例のように、メソッド呼び出し内で直接カスタムタイムアウト値を設定することも可能です:
driver.click("button", timeout=20)
同等のSeleniumコードは、はるかに冗長で複雑になります:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
明確なエラー出力
スクリプトが失敗した場合、SeleniumBaseは明確で読みやすいエラーメッセージを提供します。一方、生のSeleniumは冗長で解釈しにくいエラーログを生成することが多く、デバッグに追加の労力を要します。
ダッシュボード、レポート、スクリーンショット
SeleniumBaseには、テスト実行のダッシュボードやレポートを生成する機能が含まれています。また、デバッグを容易にするため、失敗時のスクリーンショットを./latest_logs/フォルダに保存します。生のSeleniumには、これらの機能が標準では備わっていません。
追加機能
Seleniumと比較して、SeleniumBaseには以下が含まれます:
- テストを視覚的に実行するためのデスクトップGUIアプリケーション(例:
pytest用SeleniumBaseCommander、behave用SeleniumBase Behave GUI)。 - 手動のブラウザ操作に基づいてテストスクリプトを作成する組み込みレコーダー/テストジェネレーター。これにより複雑なワークフローのテスト作成労力が大幅に削減されます。
- テストケース管理ソフトウェア「CasePlans」:テストの整理やステップ説明の文書化をフレームワーク内で直接行えます。
- ChartMakerなどのツール。PythonからJavaScriptコードを生成してデータアプリを構築します。これにより標準的なテスト自動化を超えた汎用的なソリューションとなります。
SeleniumBase: 機能、メソッド、および CLI オプション
SeleniumBaseの機能とAPIを探索し、その特長を確認してください。
機能
SeleniumBaseの主な機能の一部を以下に示します:
- Pythonでブラウザテストを即座に生成するレコーダーモードを搭載。
- 同一テスト内で複数ブラウザ、タブ、iframe、プロキシをサポート。
- Markdown技術を活用したテストケース管理ソフトウェアを搭載。
- スマート待機メカニズムにより、信頼性が自動的に向上し、不安定なテストが減少します。
pytest、unittest、nose、behaveとの互換性によりテストの発見と実行を実現。- ダッシュボード、レポート、スクリーンショット用の高度なロギングツールを搭載。
- ブラウザインターフェースを非表示にするヘッドレスモードでのテスト実行が可能。
- 並列ブラウザでのマルチスレッドテスト実行をサポート。
- Chromiumのモバイルデバイスエミュレーターを使用したテスト実行が可能。
- 認証が必要なプロキシサーバー経由でのテスト実行をサポート。
- テスト用にブラウザのユーザーエージェント文字列をカスタマイズ可能。
- Selenium自動化をブロックするウェブサイトによる検知を防止します。
- ブラウザのネットワークリクエストを検査するためのselenium-wireとの統合。
- カスタムテスト実行オプションのための柔軟なコマンドラインインターフェース。
- テスト設定を管理するためのグローバル設定ファイル。
- GitHub Actions、Google Cloud、Azure、S3、Dockerとの連携をサポート。
- PythonからJavaScriptを実行可能。
- CSSセレクタで
::shadowを使用することでShadow DOM要素とやり取り可能。
全リストについては、ドキュメントをご確認ください。プロキシを使用したSeleniumBaseの活用方法については、当社のブログ記事も必ずお読みください。
メソッド
以下は最も有用なSeleniumBaseメソッドの一覧です:
driver.open(url): ブラウザウィンドウを指定されたURLに移動します。driver.go_back():前のURLに戻ります。driver.type(selector, text): 指定されたテキストでセレクターで識別されるフィールドを更新します。driver.click(selector): セレクタで特定された要素をクリックします。driver.click_link(link_text): 指定されたテキストを含むリンクをクリックします。driver.select_option_by_text(dropdown_selector, option): 表示テキストでドロップダウンメニューからオプションを選択します。driver.hover_and_click(hover_selector, click_selector): 要素にホバーし、別の要素をクリックします。driver.drag_and_drop(ドラッグ用セレクタ, ドロップ先セレクタ): 要素をドラッグし、別の要素上にドロップします。driver.get_text(selector): 指定された要素のテキストを取得します。driver.get_attribute(selector, attribute): 要素の指定された属性を取得します。driver.get_current_url(): 現在のページのURLを取得します。driver.get_page_source(): 現在のページのHTMLソースを取得します。driver.get_title(): 現在のページのタイトルを取得します。driver.switch_to_frame(frame): 指定された iframe コンテナに切り替えます。driver.switch_to_default_content(): iframeコンテナを終了し、メインドキュメントに戻る。driver.open_new_window(): 同じセッション内で新しいブラウザウィンドウを開きます。driver.switch_to_window(window): 指定されたブラウザウィンドウに切り替えます。driver.switch_to_default_window():元のブラウザウィンドウに戻る。driver.get_new_driver(OPTIONS): 指定されたオプションで新しいドライバセッションを開きます。driver.switch_to_driver(driver): 指定されたブラウザドライバに切り替えます。driver.switch_to_default_driver(): 元のブラウザドライバに戻る。driver.wait_for_element(selector): 指定された要素が表示されるまで待機します。driver.is_element_visible(selector): 指定された要素が表示されているかどうかを確認します。driver.is_text_visible(text, selector): 指定されたテキストが要素内で表示されているかどうかを確認します。driver.sleep(seconds): 指定された時間だけ実行を一時停止します。driver.save_screenshot(name): 指定された名前でスクリーンショットを.png形式で保存します。driver.assert_element(selector): 指定された要素が表示されていることを検証します。driver.assert_text(text, selector): 指定されたテキストが要素内に存在することを検証します。driver.assert_exact_text(text, selector): 指定されたテキストが要素内で完全に一致することを検証します。driver.assert_title(title): 現在のページタイトルが指定されたタイトルと一致することを検証します。driver.assert_downloaded_file(file): 指定されたファイルがダウンロードされたことを確認します。driver.assert_no_404_errors(): ページにリンク切れがないことを検証します。driver.assert_no_js_errors(): ページ上に JavaScript エラーが存在しないことを検証します。
完全なリストについては、ドキュメントを参照してください。
CLI オプション
SeleniumBase は以下のコマンドラインオプションでpytest を拡張します:
--browser=BROWSER: ウェブブラウザを設定します(デフォルト: “chrome”)。--chrome:--browser=chromeのショートカット。--edge:--browser=edgeのショートカット。--firefox:--browser=firefoxのショートカット。--safari:--browser=safariのショートカット。--settings-file=FILE: SeleniumBase のデフォルト設定を上書きします。--env=ENV: テスト環境を設定します。driver.env経由でアクセス可能です。--account=STR: アカウントを設定します。driver.account経由でアクセス可能です。--data=文字列: 追加テストデータ。driver.data経由でアクセス可能。--var1=文字列: 追加テストデータ。driver.var1経由でアクセス可能。--var2=文字列: 追加テストデータ。driver.var2経由でアクセス可能。--var3=文字列: 追加テストデータ。driver.var3経由でアクセス可能。--variables=DICT: 追加テストデータ。driver.variables経由でアクセス可能。--proxy=サーバー:ポート: プロキシサーバーに接続します。--proxy=ユーザー名:パスワード@サーバー:ポート: 認証プロキシサーバーを使用。--proxy-bypass-list=文字列: プロキシをバイパスするホスト(例: “*.foo.com”)。--proxy-pac-url=URL: プロキシ PAC URL 経由で接続。--proxy-pac-url=ユーザー名:パスワード@URL: PAC URL を使用した認証済みプロキシ。--proxy-driver: ドライバーダウンロードにプロキシを使用する。--multi-proxy: マルチスレッドで複数の認証済みプロキシを許可。--agent=文字列: ブラウザのUser-Agent文字列を変更します。--mobile: モバイルデバイスエミュレータを有効化。--metrics=文字列: モバイルメトリクスを設定(例: “CSSWidth,CSSHeight,PixelRatio”)。--chromium-arg="ARG=N,ARG2": Chromium引数を設定します。--firefox-arg="ARG=N,ARG2": Firefox引数を設定します。--firefox-pref=SET: Firefoxの設定を指定します。--extension-zip=ZIP: Chrome拡張機能の.zip/.crxファイルを読み込みます。--extension-dir=DIR: Chrome拡張機能ディレクトリを読み込みます。--disable-features="F1,F2": 機能を無効化します。--binary-location=PATH: Chromiumバイナリパスを設定します。--driver-version=VER: ドライバーのバージョンを設定します。--headless: デフォルトのヘッドレスモード。--headless1: Chromeの旧ヘッドレスモードを使用。--headless2: Chromeの新ヘッドレスモードを使用。--headed: LinuxでGUIモードを有効化。--xvfb: Linux で Xvfb を使用してテストを実行します。--locale=LOCALE_CODE: ブラウザの言語ロケールを設定します。--reuse-session: すべてのテストでブラウザセッションを再利用する。--reuse-class-session: クラステスト用にセッションを再利用します。--crumbs: 再利用セッション間でクッキーを削除する。--disable-cookies: クッキーを無効化します。--disable-js: JavaScriptを無効化します。--disable-csp: コンテンツセキュリティポリシーを無効化します。--disable-ws: Webセキュリティを無効化。--enable-ws: Webセキュリティを有効化。--log-cdp: Chrome DevTools Protocol (CDP) イベントをログに記録します。--remote-debug: Chrome リモートデバッガーと同期する。--visual-baseline: レイアウトテストの視覚的ベースラインを設定します。--timeout-multiplier=MULTIPLIER: デフォルトのタイムアウト値を乗算します。
コマンドラインオプションの定義の完全なリストは、ドキュメントを参照してください。
ウェブスクレイピングのためのSeleniumBaseの使用:ステップバイステップガイド
このステップバイステップチュートリアルに従い、SeleniumBase スクレイパーを構築してQuotes to Scrape サンドボックスからデータを取得する方法を学びましょう:
標準のSeleniumを使用した同様のチュートリアルについては、Seleniumによるウェブスクレイピングガイドをご覧ください。
ステップ #1: プロジェクトの初期化
開始前に、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ダウンロードしてインストールしてください。
ターミナルを開き、以下のコマンドを実行してプロジェクト用ディレクトリを作成します:
mkdir seleniumbase-スクレイパー
seleniumbase-scraper ディレクトリに SeleniumBase スクレイパーを格納します。
そのディレクトリに移動し、仮想環境を初期化します:
cd seleniumbase-スクレイパー
python -m venv env
次に、お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトディレクトリ内にscraper.py ファイルを作成します。これで以下のファイル構成が整います:

scraper.pyにはまもなくスクレイパーのロジックが記述されます。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSでは以下のコマンドを実行:
./env/bin/activate
Windowsでは同等の操作として以下を実行します:
env/Scripts/activate
アクティベートされた環境で、SeleniumBase をインストールするコマンドを実行します:
pip install seleniumbase
素晴らしい!これでSeleniumBaseによるウェブスクレイピング用のPython環境が整いました。
ステップ #2: SeleniumBase テスト環境のセットアップ
SeleniumBaseはテスト構築にpytest構文をサポートしていますが、ウェブスクレイピングボットはテストスクリプトではありません。SB構文を使用することで、SeleniumBaseのpytestコマンドライン拡張オプションをすべて活用できます:
from seleniumbase import SB
with SB() as sb:
pass
# スクラッピングロジック...
テストは以下のように実行できます:
python3 スクレイパー.py
注: Windowsではpython3を pythonに置き換えてください。
ヘッドレスモードで実行するには以下を実行します:
python3 スクレイパー.py --headless
複数のコマンドラインオプションを組み合わせられることに留意してください。
ステップ #3: 対象ページへの接続
open()メソッドを使用して、制御されたブラウザにターゲットページを訪問するよう指示します:
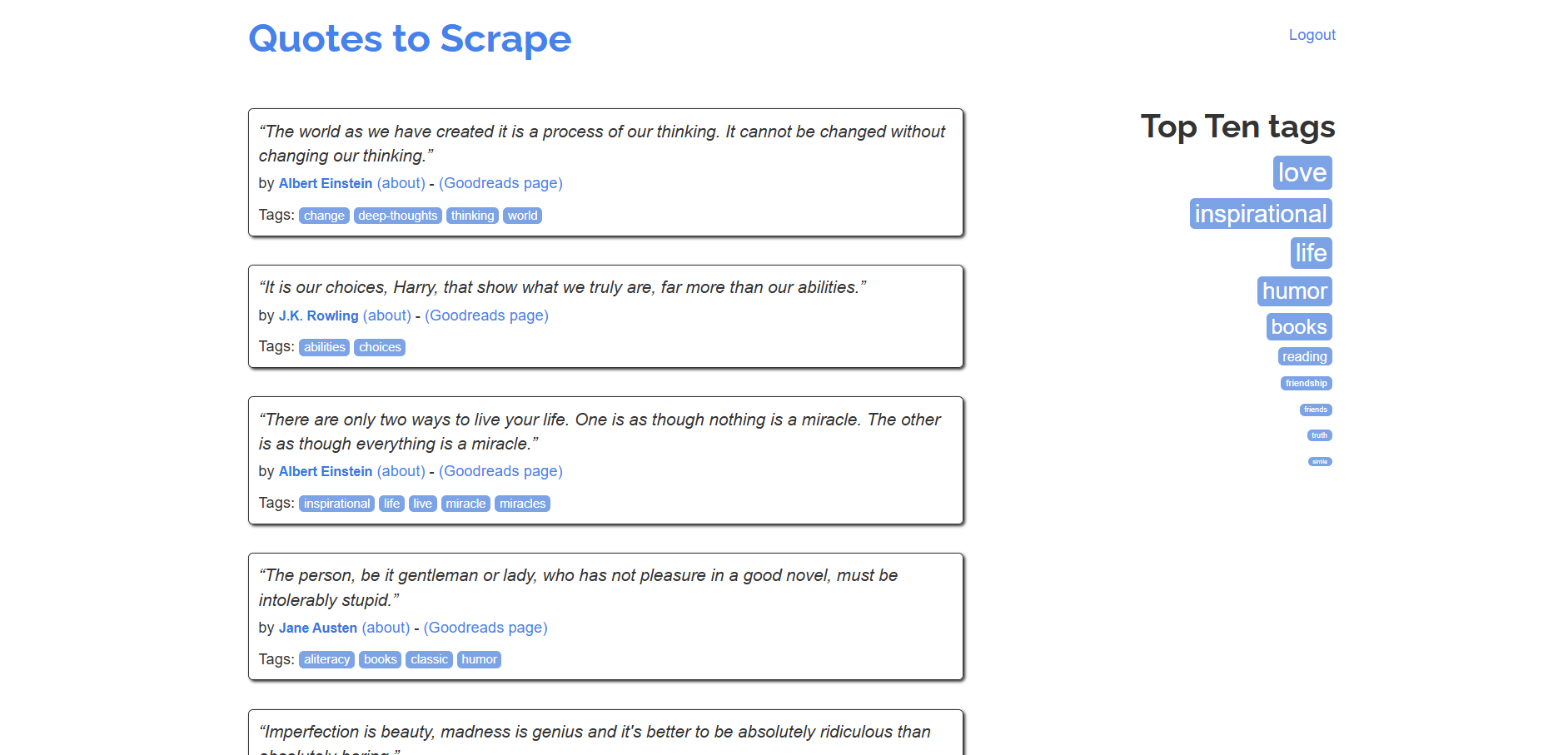
sb.open("https://quotes.toscrape.com/")
ヘッドモードでスクレイピングテストスクリプトを実行すると、一瞬だけ以下のような画面が表示されます:
通常のSeleniumと異なり、ドライバーを手動で閉じる必要はありません。SeleniumBaseが自動的に処理します。
ステップ #4: 引用要素の選択
ブラウザのシークレットモードで対象ページを開き、引用要素を検査します:
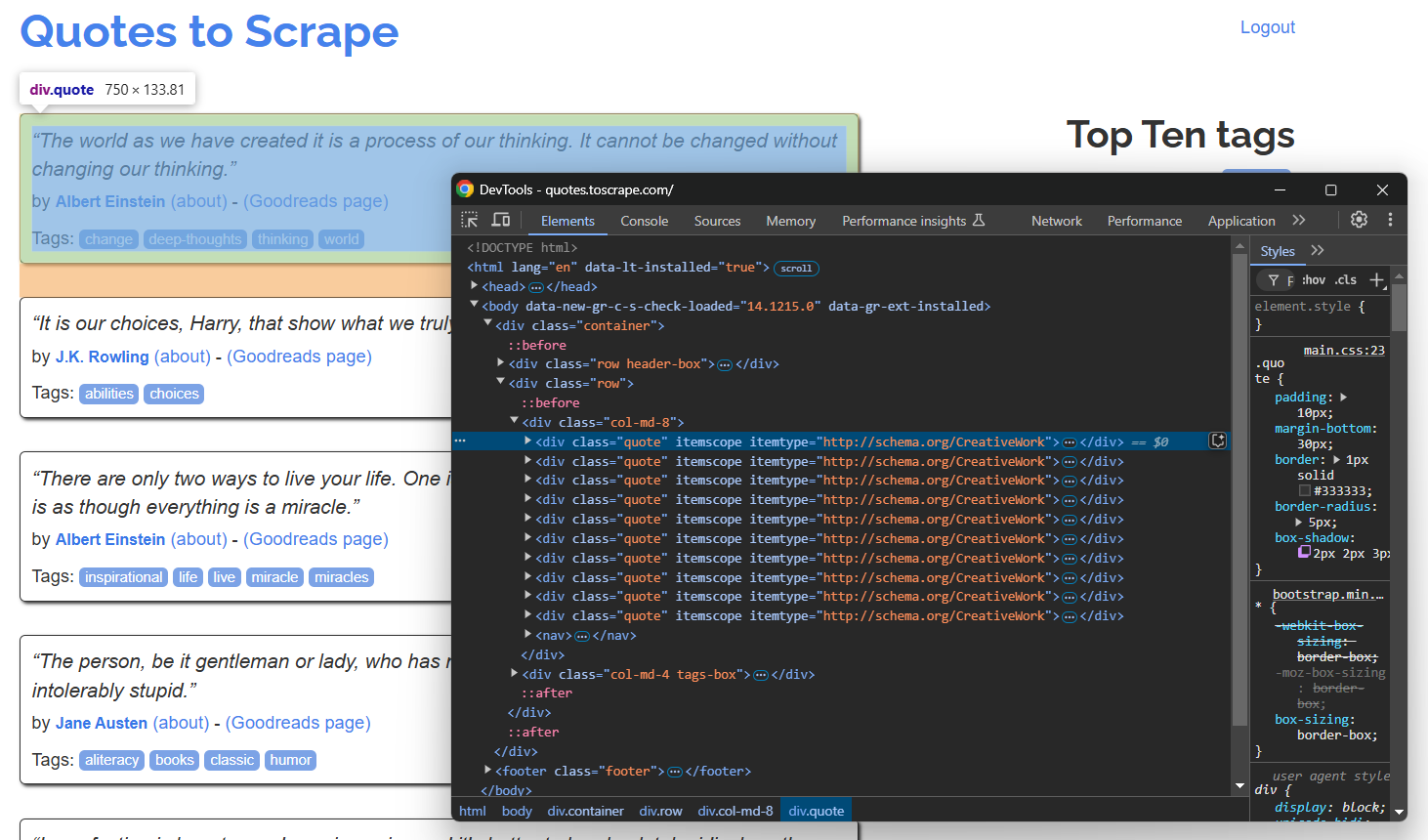
ページには複数の引用が含まれるため、スクレイピングしたデータを格納するquotes配列を作成します:
quotes = []
上記のDevToolsセクションでは、すべての引用文が.quote CSSセレクターで選択可能であることが確認できます。find_elements()を使用してそれらをすべて選択します:
quote_elements = sb.find_elements(".quote")
次に、各引用要素を反復処理してデータをスクレイピングする準備をします。スクレイピングしたデータを配列に追加します:
for quote_element in quote_elements:
# スクレイピングロジック...
素晴らしい!高レベルのスクレイピングロジックの準備が整いました。
ステップ #5: 引用データのスクレイピング
単一の引用要素を検査します:
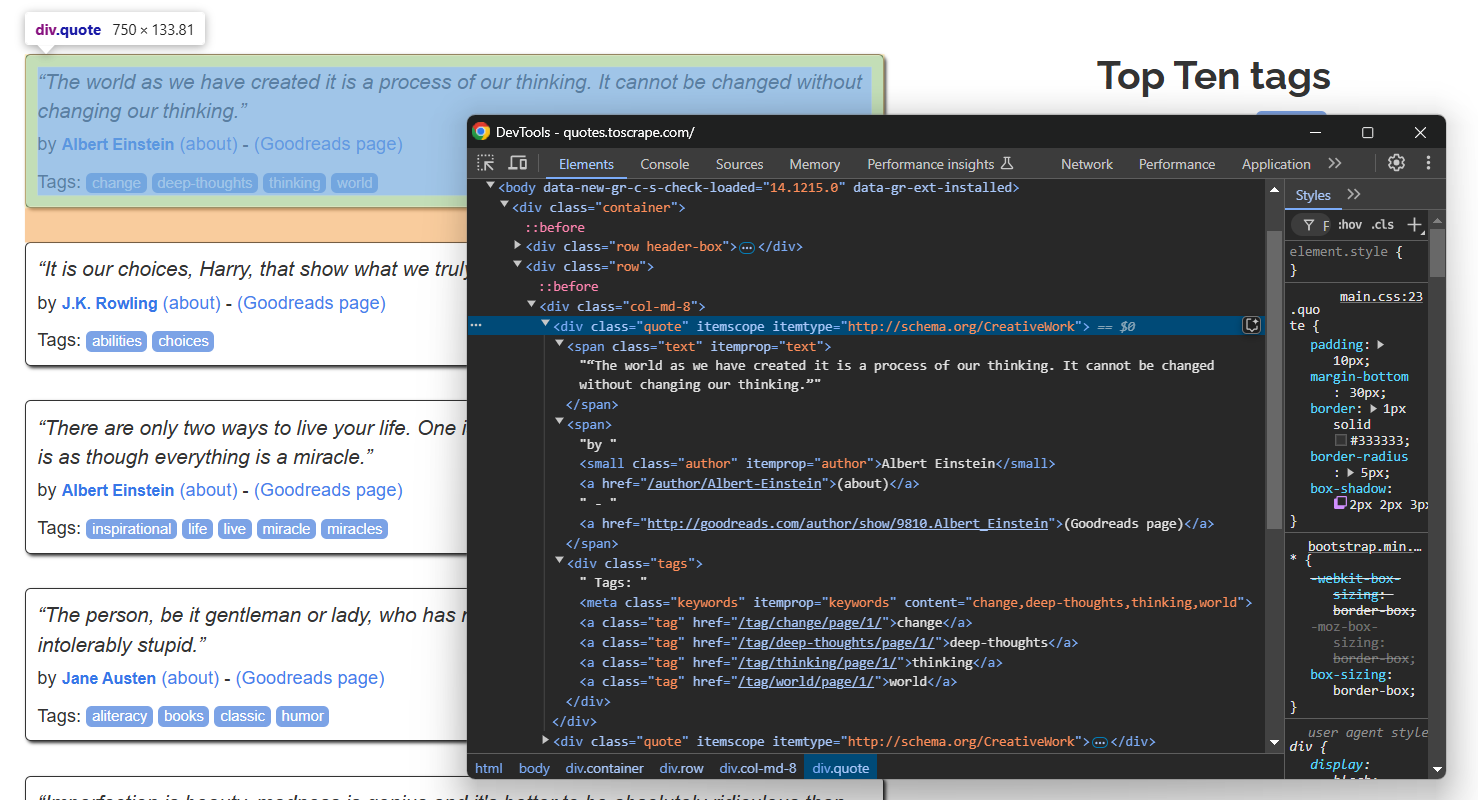
以下のデータをスクレイピングできることに注意してください:
.textからの引用テキスト.author属性から引用元著者- 引用タグ
.tag
各ノードを選択し、text属性からデータを抽出:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
find_elements() は標準の SeleniumWebElement オブジェクトを返すことに注意してください。そのため、その内部の要素を選択するには、Selenium のネイティブメソッドを使用する必要があります。これが、ロケーターとしてBy.CSS_SELECTOR を指定しなければならない理由です。
スクリプトの先頭でBy をインポートすることを忘れないでください:
from selenium.webdriver.common.by import By
タグのスクレイピングにはループが必要である点に注意してください。単一の引用符が1つ以上のタグを含む可能性があるためです。また、テキストを囲む特別な二重引用符を削除するためにreplace()メソッドが使用されている点にも注目してください。
ステップ #6: Quotes配列へのデータ投入
スクレイピングしたデータで新しいquotesオブジェクトを作成し、quotesに追加します:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
素晴らしい!SelenumBaseのスクレイピングロジックが完成しました。
ステップ #7: クローリングロジックの実装
対象サイトには複数のページが存在します。次のページへ移動するには、下部の「次へ →」ボタンをクリックします:
最終ページではこのボタンは存在しません。
全ページをウェブスクレイピングしてスクレイピングするには、スクレイピングロジックをループで囲み、「次へ →」ボタンをクリックし、ボタンが存在しなくなるまで繰り返します:
while sb.is_element_present(".next"):
# スクラッピングロジック...
# 次のページへ移動
sb.click(".next a")
ボタンが存在するかどうかを確認するために、SeleniumBase の特別なメソッド `is_element_present()` を使用している点に注意してください。
完璧です!これでSeleniumBaseスクレイパーがサイト全体を巡回します。
ステップ #8: スクレイピングしたデータのエクスポート
スクレイピングしたデータを引用符付きでCSVファイルにエクスポートします:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# CSV書き込み用に引用文オブジェクトをフラット化
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Python標準ライブラリのcsvをインポートすることを忘れないでください:
import csv
ステップ #9: 全てを統合する
script.pyファイルには以下のコードが含まれるはずです:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# 対象ページに接続
sb.open("https://quotes.toscrape.com/")
# スクレイピングしたデータの保存先
quotes = []
# 全ての引用ページを反復処理
while sb.is_element_present(".next"):
# ページ上の全ての引用要素を選択
quote_elements = sb.find_elements(".quote")
# 各引用要素のデータをスクレイピング
for quote_element in quote_elements:
# データ抽出ロジック
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# スクレイピングしたデータで新しい引用オブジェクトを作成
quote = {
"text": text,
"author": author,
"tags": tags
}
# スクレイピングした引用リストに追加
quotes.append(quote)
# 次のページに移動
sb.click(".next a")
# スクレイピングしたデータをCSVにエクスポート
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# CSV書き込み用に引用オブジェクトをフラット化
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
SeleniumBase スクレイパーをヘッドレスモードで実行するには:
python3 script.py --headless
数秒後、プロジェクトフォルダにquotes.csv ファイルが生成されます。
開くと以下が表示されます:
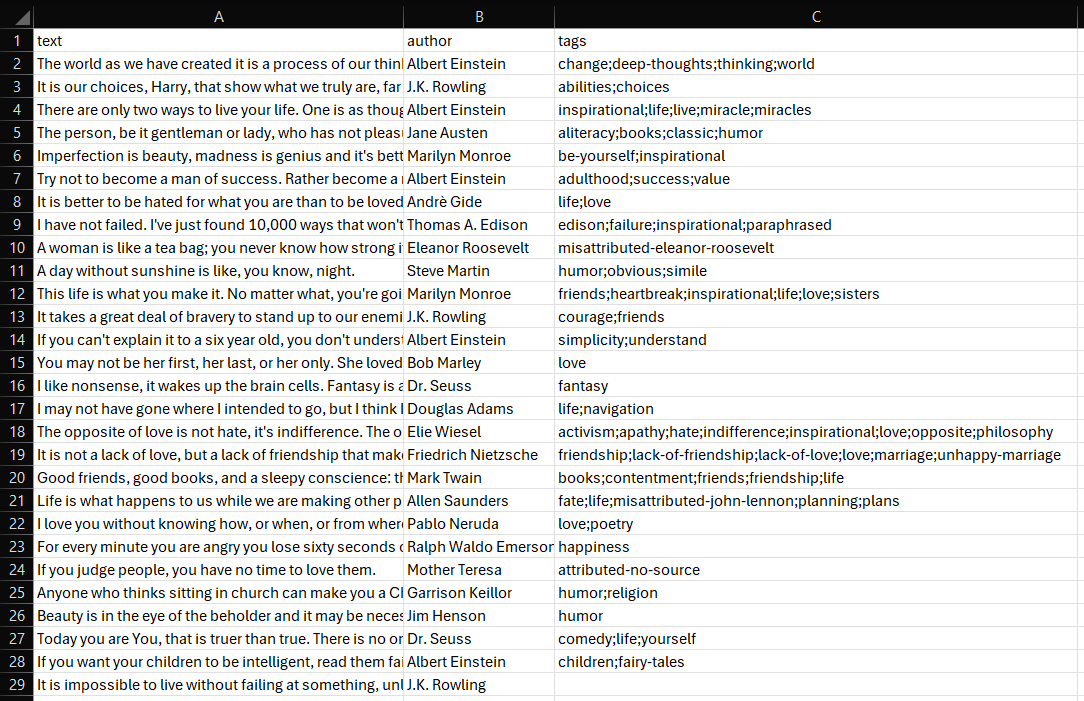
これで完了! SeleniumBaseウェブスクレイピングスクリプトが見事に動作しました。
高度な SeleniumBase スクラッピング活用例
SeleniumBaseの基本を理解したところで、より複雑なシナリオを探求する準備が整いました。
フォーム入力と送信の自動化
注:Bright Dataはログイン後のスクレイピングは行いません。
SeleniumBaseでは、人間のユーザーと同様にページ上の要素と対話することも可能です。例えば、以下のようなログインフォームを操作する必要があるとします:
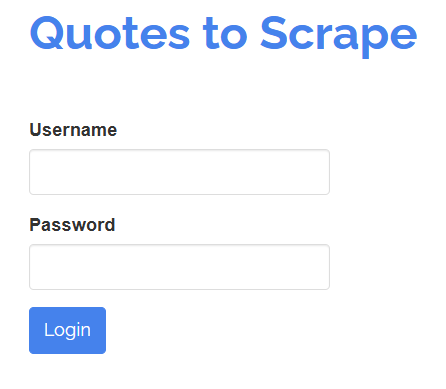
「ユーザー名」と「パスワード」フィールドに入力し、「ログイン」ボタンをクリックしてフォームを送信することが目的です。SeleniumBaseテストでは次のように実現できます:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# 対象ページにアクセス
self.open("https://quotes.toscrape.com/login")
# フォーム入力
self.type("#username", "test")
self.type("#password", "test")
# フォーム送信
self.click("input[type="submit"]")
# 正しいページへの遷移確認
self.assert_text("Top Ten tags")
この例はテスト構築に最適です。BaseCaseクラスの使用に注意してください。これによりpytestテストを作成できます。
テストは次のコマンドで実行します:
pytest login.py
ブラウザが開き、ログインページが読み込まれ、フォームが入力され、送信され、指定されたテキストがページに表示されることを確認します。
ターミナルの出力は以下のような形式になります:
login.py . [100%]
======================================== 1 passed in 11.20s =========================================
簡易的なボット対策技術の回避
多くのサイトは、ボットによるデータアクセスを防ぐため、高度なスクレイピング対策を実施しています。これにはCAPTCHAチャレンジ、レート制限、ブラウザフィンガープリンティングなどが含まれます。ブロックされずに効果的にウェブサイトをスクレイピングするには、これらの保護機能を回避する必要があります。
SeleniumBaseはUCモード(Undetected-Chromedriver Mode)と呼ばれる特殊機能を提供し、スクレイピングボットを人間ユーザーのように見せかけます。これにより、ボット対策サービスによる検知を回避でき、スクレイピングボットの直接ブロックやCAPTCHAのトリガーを防止できます。
UCモードはundetected-chromedriverを基盤として構築され、以下のような更新・修正・改良が施されています:
- 検出回避のための自動ユーザーエージェントローテーション。
- 必要に応じてChromium引数を自動設定。
- CAPTCHA回避用の専用
メソッドuc_*()
それでは、SeleniumBaseでUCモードを使用してアンチボット対策を回避する方法を見ていきましょう。
このデモでは、Scraping Courseサイトからアンチボットページにアクセスする方法を紹介します:
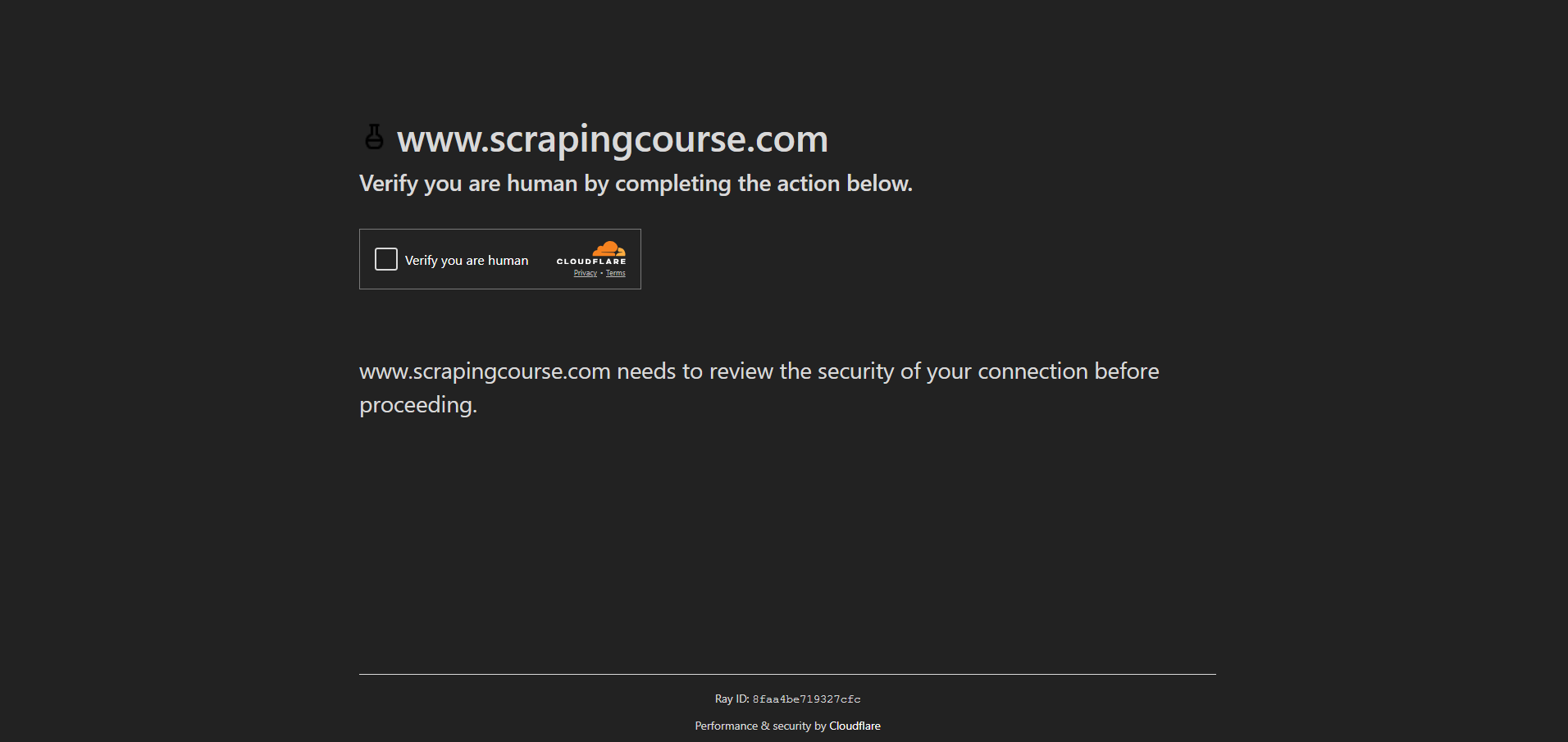
アンチボット対策を回避しCAPTCHAを処理するには、UCモードを有効化しuc_open_with_reconnect() とuc_gui_click_captcha()メソッドを使用します:
from seleniumbase import SB
with SB(uc=True) as sb:
# ボット対策が施された対象ページ
url = "https://www.scrapingcourse.com/antibot-challenge"
# 初期検知回避のため再接続時間4秒でUCモードを使用しURLを開く
sb.uc_open_with_reconnect(url, reconnect_time=4)
# CAPTCHAの回避を試行
sb.uc_gui_click_captcha()
# ページのスクリーンショットを保存
sb.save_screenshot("screenshot.png")
スクリプトを実行し、期待通りに動作することを確認してください。uc_gui_click_captcha() は動作にPyAutoGUI を必要とするため、SeleniumBase は初回実行時にこれをインストールします:
PyAutoGUIが必要です!インストール中...
ブラウザが自動的にマウスを動かして「人間であることを確認」チェックボックスをクリックする様子が確認できます。プロジェクトフォルダ内のscreenshot.pngファイルには以下のように表示されます:
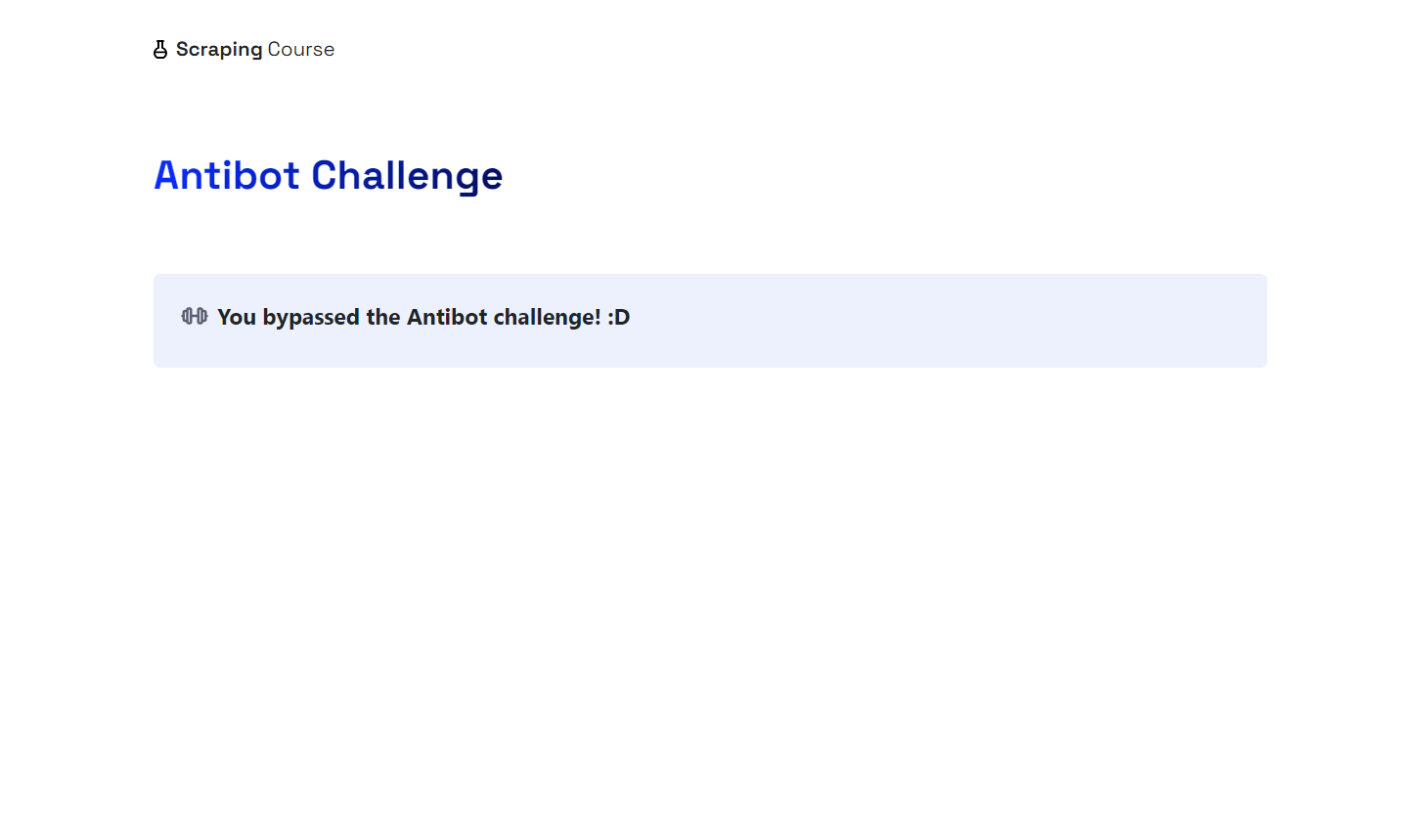
すごい!Cloudflareを回避できました。
複雑なボット対策技術の回避
ボット対策ソリューションは高度化が進んでおり、UCモードでは常に効果的とは限りません。そのためSeleniumBaseでは特別なCDPモード(Chrome DevTools Protocolモード)も提供しています。
CDPモードはUCモード内で動作し、CDP-Driverを介してブラウザを制御することでボットの挙動をより人間らしく見せます。通常のUCモードではブラウザとドライバーが切断されるとWebDriver操作が不可能ですが、CDP-Driverはブラウザとの対話を継続できるため、この制限を克服します。
CDPモードはpython-cdp、trio-cdp、nodriverを基盤としています。実世界のサイトにおける高度なアンチボット対策を回避するよう設計されており、以下の例のように動作します:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# 高度なアンチボット対策が施された対象ページ
url = "https://gitlab.com/users/sign_in"
# CDPモードでページを訪問
sb.activate_cdp_mode(url)
# CAPTCHA処理
sb.uc_gui_click_captcha()
# ページ再読み込みとドライバー制御復帰を2秒待機
sb.sleep(2)
# ページスクリーンショット取得
sb.save_screenshot("screenshot.png")
結果は次のようになります:
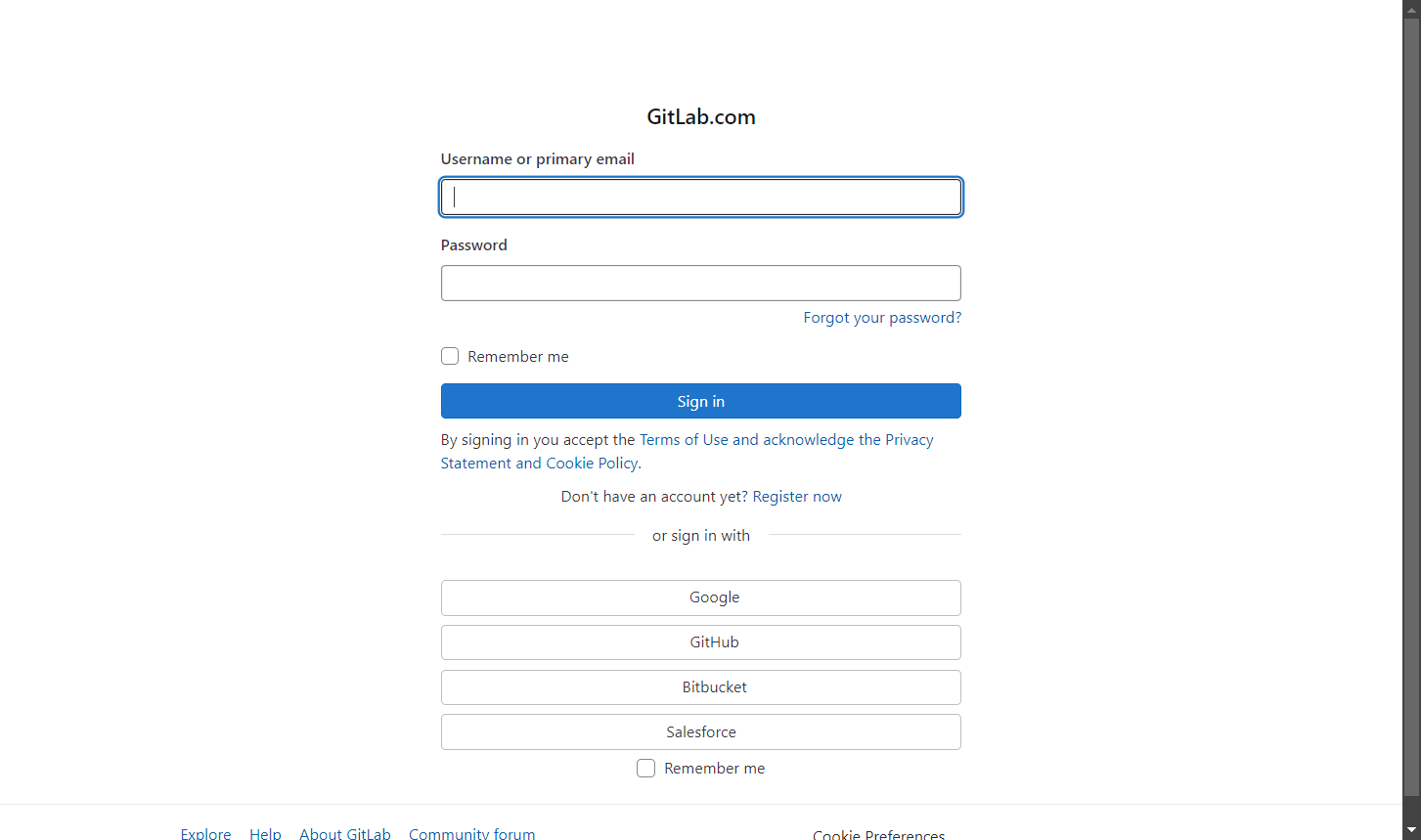
さあ、これであなたはSeleniumBaseスクレイピングの達人です。
まとめ
本記事では、SeleniumBaseの機能とメソッド、およびウェブスクレイピングへの活用方法を学びました。基本的なシナリオから始め、より複雑なユースケースを探求しました。
UCモードやCDPモードは特定のボット対策回避に有効ですが、完全ではありません。
リクエストを過剰に送信するとIPアドレスがブロックされたり、複数の操作を必要とする複雑なCAPTCHAで挑戦されたりする可能性があります。より効果的な解決策は、Seleniumのようなウェブブラウザ自動化ツールと、Bright Dataのスクレイピングブラウザのようなスクレイピング専用・クラウドベース・高スケーラブルなブラウザを組み合わせることです。
スクレイピングブラウザはPlaywright、Puppeteer、Seleniumなどに対応したブラウザです。リクエストごとに自動的に出口IPをローテーションし、ブラウザフィンガープリンティング、再試行、CAPTCHA解決などに対応しています。ブロックされる心配を忘れ、スクレイピング作業を効率化しましょう。
今すぐ登録して無料トライアルを開始しましょう!




