

このガイドでは以下を学びます:
- Selenium Wireとは
- ウェブスクレイピングにSelenium Wireを使用すべき理由
- Selenium Wireの主要機能
- プロキシローテーション機能を活用したSelenium Wireのウェブスクレイピング活用事例
- Bright DataプロキシとSelenium Wireの連携
さあ、始めましょう!
Selenium Wireとは?
Selenium Wireは、ブラウザリクエストを制御するSeleniumのPythonバインディング用拡張機能です。具体的には、Selenium使用中にPythonコードから直接、リクエストとレスポンスの両方をリアルタイムで傍受・変更することを可能にします。
注:ライブラリ自体はメンテナンス終了していますが、複数のスクレイピング技術やスクリプトが依然として依存しています。
ウェブスクレイピングにSelenium Wireを使う理由
Seleniumは、ウェブスクレイピングにおいてサイトを通常のユーザーと同様に操作するために使用される人気のブラウザ自動化フレームワークです。詳細は当社のSeleniumウェブスクレイピングガイドをご覧ください。
問題は、ブラウザには特定の制限があり、ウェブスクレイピングを困難にすることです。例えば、認証済みプロキシURLの設定やローテーションプロキシはできません。Selenium Wireはこれらの制限を克服するのに役立ちます。
ウェブスクレイピングにSelenium Wireを使用すべき3つの理由:
- ネットワーク層へのアクセス:高度なデータ抽出のために、AJAXネットワークトラフィックを解釈、検査、変更できます。
- アンチボット回避:
ChromeDriverはアンチボットシステムがボットと識別する可能性のある大量の情報を露出します。Selenium Wireはundetected-chromedriverなどの技術で使用され、これを回避し、ほとんどのアンチボットソリューションを迂回するのに役立ちます。 - ブラウザの制限を克服:現代のブラウザは起動時の動作設定にフラグを使用しますが、これらの設定は静的で変更には再起動が必要です。Selenium Wireは動的変更をサポートすることでこの制限を克服します。これにより、同じブラウザセッション中にリクエストヘッダーやプロキシを更新でき、ウェブスクレイピングに最適です。
Selenium Wireの主な機能
Selenium Wireの機能とウェブスクレイピングでの活用理由が理解できたところで、その主要機能を探ってみましょう!
リクエストとレスポンスへのアクセス
Selenium Wireはブラウザが生成するHTTP/HTTPSトラフィックをキャプチャし、以下の属性へのアクセスを可能にします:
| 属性 | 説明 |
|---|---|
driver.requests |
キャプチャされたリクエストのリストを時系列順に報告します |
driver.last_request |
直近にキャプチャされたリクエストを報告します ( driver.requests[-1]を使用するよりも効率的です) |
driver.wait_for_request(pat, timeout=10) |
このメソッドは、patパラメータで定義されたパターン(部分文字列または正規表現)に一致するリクエストを検出するまで待機します。待機時間はtimeoutパラメータで定義されます。 |
driver.har |
発生した HTTP トランザクションの JSON 形式のHARアーカイブ。 |
driver.iter_requests() |
キャプチャされたリクエストをイテレータで返します。 |
詳細には、Selenium WireRequestオブジェクトは次の属性を持ちます:
| 属性 | 説明 |
|---|---|
body |
リクエストの本文はバイト列として表現されます。本文がない場合、body の値は空になります(例:b'')。 |
cert |
サーバーのSSL証明書に関する情報を辞書形式で報告します(非HTTPSリクエストの場合は空です)。 |
date |
リクエストが行われた日時を表示します。 |
headers |
リクエストのヘッダーを辞書形式のオブジェクトで報告します(Selenium Wireではヘッダーの文字列は大小文字を区別せず、重複も許可されることに注意してください)。 |
host |
リクエストのホストを報告します(例:https://brightdata.com/)。 |
method |
HTTPメソッド(GET、POSTなど)を指定します。 |
params |
リクエストのパラメータの辞書(同じ名前のパラメータがリクエスト内で複数回出現する場合、辞書内のその値はリストになります)を報告します。 |
path |
リクエストパスを報告します。 |
クエリ文字列 |
クエリ文字列を報告します。 |
response |
リクエストに関連付けられたレスポンスオブジェクトを報告します(リクエストにレスポンスがない場合、値はNone になります)。 |
url |
ホスト、パス、クエリ文字列を含む完全なリクエストURLを報告します。 |
ws_messages |
リクエストが WebSocket の場合(この場合、URL は通常wss:// のようになります)、ws_messages には送受信された WebSocket メッセージが含まれます。 |
代わりに、Responseオブジェクトは次の属性を公開します:
| 属性 | 説明 |
|---|---|
body |
レスポンスの本文はバイト列として提示されます。レスポンスに本文がない場合、bodyの値は空になります(例:b'')。 |
date |
レスポンスが受信された日時を表示します。 |
ヘッダー |
レスポンスのヘッダーを辞書のようなオブジェクトとして報告します(Selenium Wireではヘッダーの区別は大小文字を問わず、重複も許可されることに注意してください)。 |
reason |
レスポンスの理由フレーズ(例:OK、Not Foundなど)を報告します。 |
status_code |
レスポンスのステータスコードを報告します(例:200、404など)。 |
この機能をテストするには、以下のようなPythonスクリプトを作成できます:
from seleniumwire import webdriver
# Selenium WireでWebDriverを初期化
driver = webdriver.Chrome()
try:
# 対象ウェブサイトを開く
driver.get("https://brightdata.com/")
# キャプチャされた全リクエストにアクセスして出力
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Method: {request.method}")
print(f"Headers: {request.headers}")
print(f"Response Status Code: {request.response.status_code if request.response else 'No Response'}")
print("-" * 50)
finally:
# ブラウザを閉じる
driver.quit()
上記のコードは、driver.requests を使用して対象ウェブサイトを開き、リクエストをキャプチャします。その後、for ループでURL、メソッド、ヘッダーなどのリクエスト属性を取得します。
期待される結果は次の通りです:
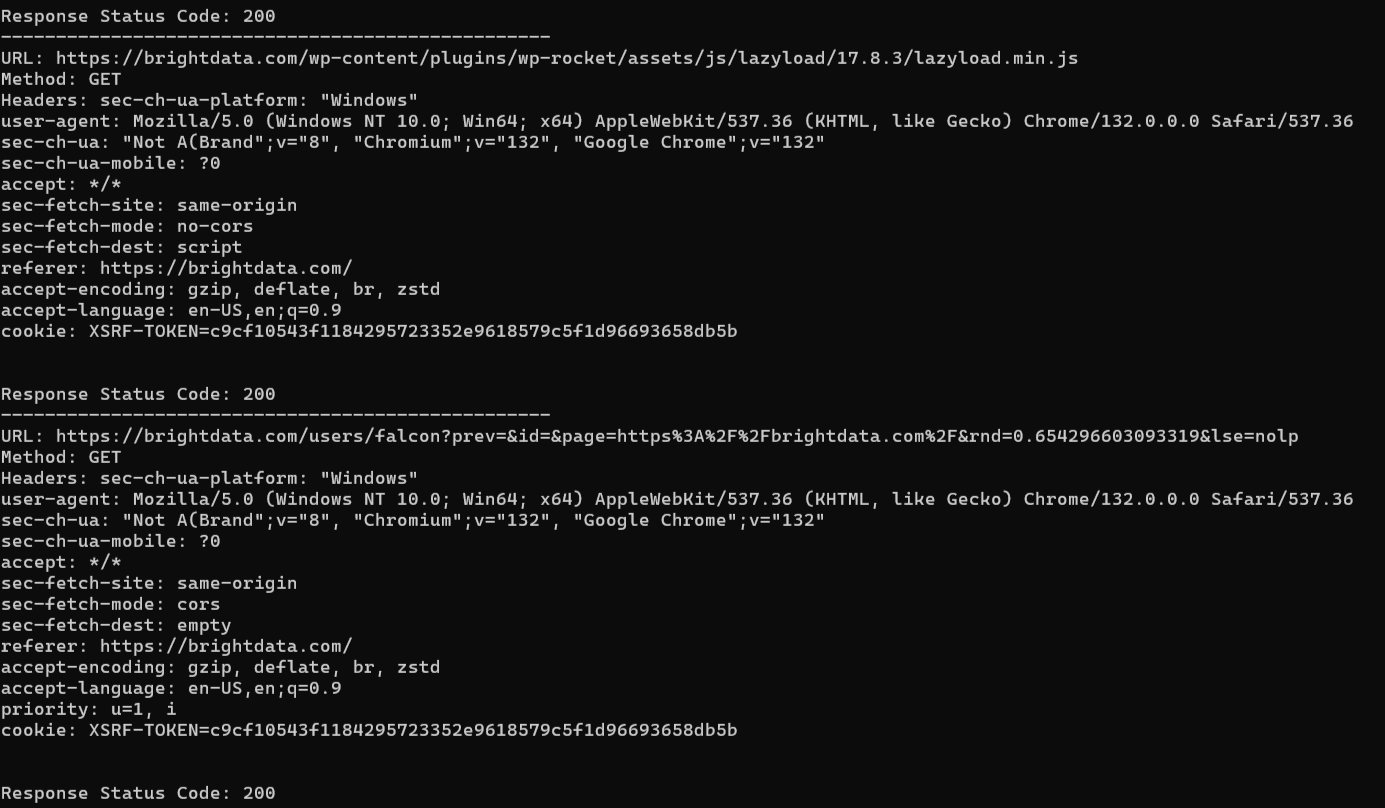
対象ページは複数のリクエストを送信し、スクリプトはそれら全てを追跡します。
リクエストとレスポンスのインターセプト
Selenium Wireはインターセプターによりリクエストとレスポンスを傍受・変更できます。インターセプターとは、ブラウザを通過するリクエストやレスポンスを引数として呼び出される関数です。
2種類のインターセプターがあります:
driver.request_interceptor: リクエストをインターセプトし、単一の引数を受け取ります。driver.response_interceptor: レスポンスをインターセプトし、2つの引数(元のリクエストとレスポンス)を受け取ります。
リクエストインターセプターの使用例:
from seleniumwire import webdriver
# リクエストインターセプタ関数の定義
def interceptor(request):
# 全リクエストにカスタムヘッダを追加
request.headers["X-Test-Header"] = "MyCustomHeaderValue"
# 特定ドメインへのリクエストをブロック
if "example.com" in request.url:
print(f"Blocking request to: {request.url}")
request.abort() # リクエストを中止
# Selenium WireでWebDriverを初期化
driver = webdriver.Chrome()
# インターセプター関数をドライバーに割り当て
driver.request_interceptor = interceptor
try:
# 複数のリクエストを発行するウェブサイトを開く
driver.get("https://brightdata.com/")
# キャプチャした全リクエストを出力
for request in driver.requests:
print(f"URL: {request.url}")
print(f"Headers: {request.headers}")
print("-" * 50)
finally:
# ブラウザを閉じる
driver.quit()
このスニペットの動作:
- インターセプター関数: 送信される全リクエストに対して呼び出されるインターセプター関数を作成します。これにより、
request.headers[]を使用して全送信リクエストにカスタムヘッダーを追加します。また、example.comドメインへのブラウザリクエストをブロックします。 - リクエストのキャプチャ: ページ読み込み後、変更されたヘッダーを含むすべてのキャプチャされたリクエストを出力します。
注: リクエストブロックは、広告、解析スクリプト、サードパーティウィジェットなど、目的と無関係な追加リソースをページが読み込む場合に有効です。これらのリクエストをブロックすることで、スクレイピング速度が大幅に向上し、ブラウザの帯域幅の使用量が削減されます。
期待される結果は次のようになります:
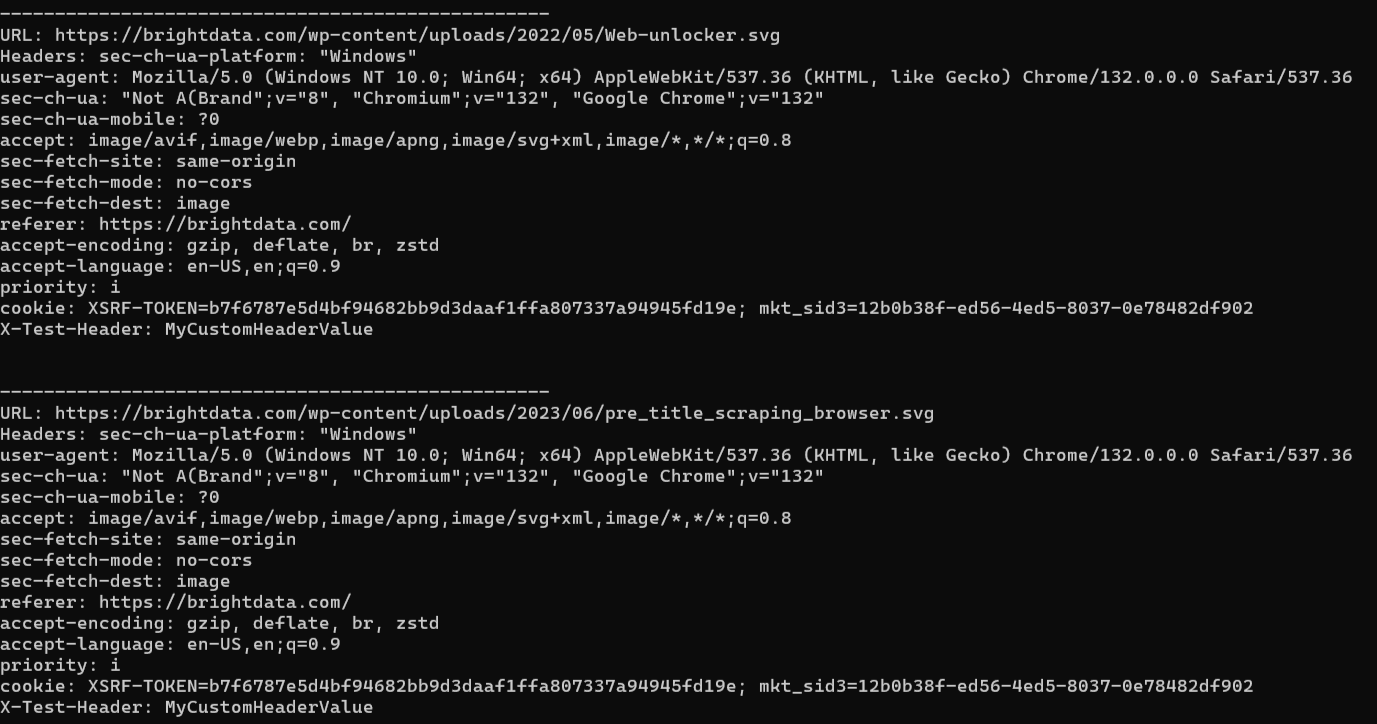
ブラウザが行ったリクエストがどのようにインターセプトされ、追加のヘッダー値が付け加えられたかを確認してください。
WebSocketの監視
多くの現代的なウェブページは、サーバーとのリアルタイム通信にWebSocketを使用しています。WebSocketはブラウザとサーバーの間に永続的な接続を確立します。これにより、従来のHTTPリクエストのオーバーヘッドなしにデータを継続的に交換できます。
多くの場合、重要なデータがこれらのチャネルを通じて流れ、直接アクセスすることはデータ取得において非常に価値があります。WebSocket通信をインターセプトすることで、ブラウザが変換したりページがレンダリングしたりするのを待たずに、サーバーから送信された生のデータを抽出できます。
リクエストオブジェクトにはWebSocketを管理するws_messages属性があることは既に学んでいます。Selenium WireWebSocketオブジェクトの属性は以下の通りです:
| 属性 | 説明 |
|---|---|
content |
メッセージの内容を報告します。文字列(str)またはバイト形式(bytes)で表されます。 |
date |
メッセージの日時を表示します。 |
ヘッダー |
レスポンスのヘッダーを辞書のようなオブジェクトで報告します(Selenium Wire ではヘッダーは大小文字を区別せず、重複も許可されることに注意してください)。 |
from_client |
メッセージがクライアントから送信された場合はTrue、サーバーから送信された場合はFalse を返すブール値です。 |
プロキシの管理
プロキシサーバーは、デバイスとターゲットサイト間の仲介役として機能し、その過程でIPアドレスを隠蔽します。ウェブスクレイピングにおいて不可欠な存在であり、以下の役割を果たします:
- IPベースの制限回避を支援
- レートリミッターによるブロックを回避
- 地域制限のあるサイトからのコンテンツスクレイピングを可能にする
Selenium Wireでプロキシを設定する方法は以下の通りです:
# Selenium Wireプロキシの設定
options = {
"proxy": {
"http": "<YOUR_HTTP_PROXY_URL>",
"https": "<YOUR_HTTPS_PROXY_URL>"
}
}
# Selenium WireでWebDriverを初期化
driver = webdriver.Chrome(seleniumwire_options=options)
この設定は、Chromeの--proxy-serverフラグに依存する標準Seleniumのプロキシ設定とは異なります。つまり、標準Seleniumではプロキシ設定は静的になります。
プロキシを設定すると、その設定はブラウザセッション全体に適用され、ブラウザを再起動せずに変更することはできません。この制限は、特にプロキシを動的にローテーションする必要があるシナリオでは制約となる可能性があります。
これに対し、Selenium Wireでは同じブラウザインスタンス内で動的にプロキシを変更する柔軟性が提供されます。これはproxy属性によって実現されます:
# プロキシを動的に変更
driver.proxy = {
"http": "<NEW_HTTP_PROXY_URL>",
"https": "<NEW_HTTPS_PROXY_URL>"
}
さらに、Chromeの–proxy-serverフラグはURL内に認証情報を含むプロキシをサポートしていません:
protocol://username:password@host:port
代わりに、Selenium Wireは認証プロキシを完全にサポートしているため、ウェブスクレイピングにはより適した選択肢となります。
プロキシ設定はSelenium Wireの最大の利点の一つであるため、このトピックについては次の章でさらに詳しく見ていきます。
ウェブスクレイピングのユースケース:Selenium Wireにおけるプロキシローテーション
前述の通り、ウェブスクレイピングにSelenium Wireを使用する主な理由は、その高度なプロキシ管理機能にあります。
このガイドセクションでは、プロキシローテーションのためのSelenium Wireプロジェクトの設定方法をご紹介します。これにより、リクエストごとに出口IPを変更できるようになります。
要件
このチュートリアルを再現するには、システムが以下の前提条件を満たしている必要があります:
- Python 3.7 以降: 3.7 より新しい Python バージョンであれば問題ありません。具体的には pip 経由で依存関係をインストールしますが、pip は Python 3.4 以降に標準でインストールされています。
- サポート対象のウェブブラウザ:Selenium WireはSeleniumを拡張するため、サポート対象のブラウザが必要です。
Selenium Wireのインストール前に、仮想環境ディレクトリを以下のように作成できます:
python -m venv venv
Windowsで有効化するには以下を実行:
venvScriptsactivate
macOS/Linuxでは同等の操作として以下を実行します:
source venv/bin/activate
これでSelenium Wireをインストールできます:
pip install selenium-wire
注: Selenium 本体のインストールは不要です。Selenium Wire の依存関係に含まれるため、Selenium Wire のインストール時に自動的に導入されます。
メインフォルダをselenium_wire/と仮定します。この手順終了時、フォルダ構造は以下のようになります:
selenium_wire/
├── selenium_wire.py
└── venv/
selenium_wire.py は、次のステップで実装するすべてのロジックを含む Python ファイルです。
ステップ1: プロキシのランダム化
まず、有効なプロキシURLのリストが必要です。入手先がわからない場合は、無料プロキシのリストを参照してください。それらをリストに追加し、random.choice()を使用してランダムに要素を選択します:
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ...
]
# リストをランダム化
return random.choice(プロキシ)
この関数を呼び出すと、リストからランダムなプロキシURLが返されます。
動作させるには、randomのインポートを忘れないでください:
import random
ステップ2: プロキシの設定
get_random_proxy()関数を呼び出してプロキシURLを取得します:
プロキシ = get_random_proxy()
次に、ブラウザインスタンスを初期化し、選択したプロキシを設定します:
# プロキシを使用したSelenium Wireの設定
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# ブラウザ設定
chrome_options = Options()
chrome_options.add_argument("--headless") # ヘッドレスモードでブラウザを実行
# 指定された設定でブラウザインスタンスを初期化
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
上記のスニペットには以下のインポートが必要です:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
ブラウザセッション中にプロキシを動的に変更するには、代わりに次のコードを使用します:
driver.proxy = {
"http": プロキシ,
"https": プロキシ
}
これで制御対象のChromeインスタンスが指定プロキシ経由でリクエストをルーティングするようになります。
ステップ3: 対象ページにアクセス
対象ウェブサイトにアクセスし、出力を抽出した後、ブラウザを閉じます:
try:
# ターゲットページにアクセス
driver.get("https://httpbin.io/ip")
# ページ出力を抽出
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# ブラウザまたはプロキシで発生したエラーを処理
print(f"プロキシ {proxy} でエラー: {e}")
finally:
# ブラウザを閉じる
driver.quit()
動作させるには、SeleniumからByをインポートします:
from selenium.webdriver.common.by import By
この例では、目的のページはHTTPBinプロジェクトの/ipエンドポイントです。これは意図的な選択であり、このページは呼び出し元のIPアドレスを返します。すべてが期待通りに進めば、スクリプトは実行ごとにプロキシリストとは異なるIPを出力するはずです。
それでは検証してみましょう!
ステップ4: 全体をまとめる
selenium_wire.pyファイルに記述すべき、Selenium Wireプロキシローテーションの全ロジックは以下の通りです:
import random
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
def get_random_proxy():
proxies = [
"http://PROXY_1:PORT_NUMBER_X",
"http://PROXY_2:PORT_NUMBER_Y",
"http://PROXY_3:PORT_NUMBER_Z",
# ここにプロキシを追加...
]
# プロキシをランダムに選択
return random.choice(proxies)
# ランダムなプロキシURLを選択
proxy = get_random_proxy()
# プロキシを使用したSelenium Wireの設定
seleniumwire_options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# ブラウザ設定
chrome_options = Options()
chrome_options.add_argument("--headless") # ヘッドレスモードでブラウザを実行
# 指定された設定でブラウザインスタンスを初期化
driver = webdriver.Chrome(service=Service(), options=chrome_options, seleniumwire_options=seleniumwire_options)
try:
# 対象ページにアクセス
driver.get("https://httpbin.io/ip")
# ページ出力を抽出
body = driver.find_element(By.TAG_NAME, "body").text
print(body)
except Exception as e:
# ブラウザまたはプロキシで発生したエラーを処理
print(f"プロキシ {proxy} でエラー: {e}")
finally:
# ブラウザを閉じる
driver.quit()
ファイルを実行するには、以下を起動:
python3 selenium_wire.py
各実行時の出力は次の通り:
{
"origin": "PROXY_1:XXXX"
}
または:
{
"origin": "PROXY_2:YYYY"
}
以下同様…
スクリプトを複数回実行すると、毎回異なるIPアドレスが表示されます。プロキシローテーションが機能しています!
プロキシローテーションのより優れたアプローチ:Bright Data Proxies
先ほど見たように、Selenium Wireでの手動プロキシローテーションには多くの定型コードが必要で、有効なプロキシURLのリストを管理しなければなりません。
幸いなことに、Bright Dataのローテーションプロキシはより効率的な解決策です!
当社のローテーションプロキシはIPアドレス変更を自動処理するため、手動でのプロキシ管理が不要です。195カ国をカバーするネットワークにより、卓越した稼働率と99.9%の成功率を保証します。当社のグローバルプロキシネットワークには以下が含まれます:
- データセンター・プロキシ– 77万以上のデータセンターIPアドレス
- レジデンシャルプロキシ– 195カ国以上で7,200万以上のレジデンシャルIP。
- ISPプロキシ– 70万以上のISP IPアドレス。
以下の手順に従い、Selenium WireでBright Dataのプロキシを使用する方法をご確認ください。
アカウントをお持ちの場合はBright Dataにログインしてください。お持ちでない場合は無料でアカウントを作成してください。以下のユーザーダッシュボードにアクセスできます:
「プロキシ製品を表示」ボタンをクリック:
以下の「プロキシ&スクレイピングインフラ」ページにリダイレクトされます:
下にスクロールし、「レジデンシャルプロキシ」カードを見つけて「開始」ボタンをクリックしてください:
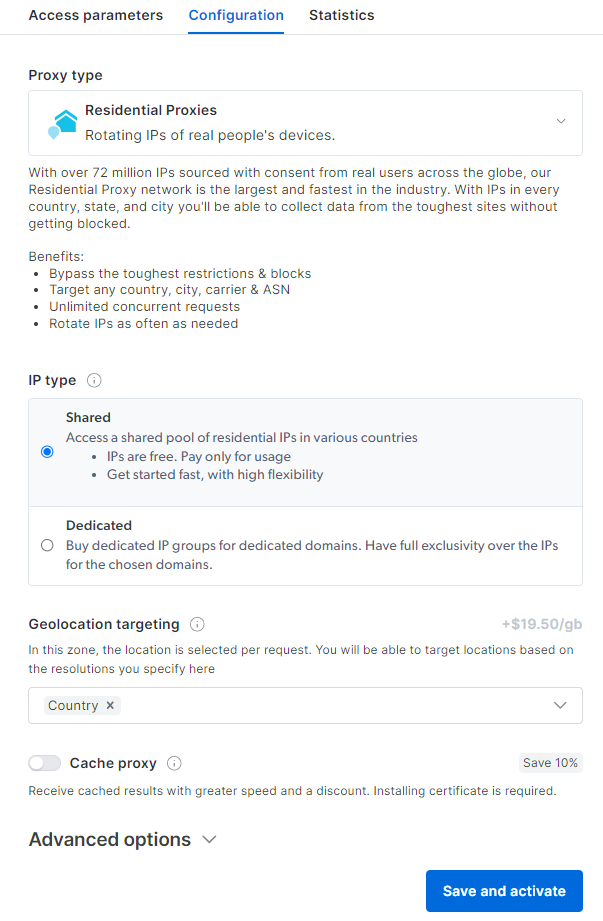
レジデンシャルプロキシ設定ダッシュボードが表示されます。ガイド付きウィザードに従い、必要に応じてプロキシサービスを設定してください。プロキシ設定方法に不明点がある場合は、24時間365日対応のサポートまでお気軽にお問い合わせください:
「アクセスパラメータ」タブに移動し、以下の手順でプロキシのホスト、ポート、ユーザー名、パスワードを取得してください:
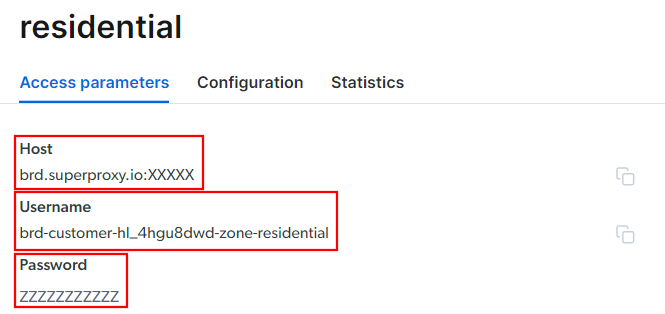
※「ホスト」欄にはポート番号が既に含まれています。
これでプロキシURLを構築し、Selenium Wireに設定する準備が整いました。以下の構文で全情報を組み合わせてURLを作成してください:
<username>:<password>@<host>
例:
brd-customer-hl_4hgu8dwd-ゾーン-residential:[email protected]:XXXXX
「Activeプロキシ」を切り替え、最後の指示に従えば準備完了です!

Bright Data 統合用の Selenium Wire プロキシスニペットは次のようになります:
# Bright DataプロキシURL
proxy = "brd-customer-hl_4hgu8dwd-zone-residential:[email protected]:XXXXX"
# Selenium Wireオプションの設定
options = {
"proxy": {
"http": proxy,
"https": proxy
}
}
# Selenium WireでWebDriverを初期化
driver = webdriver.Chrome(seleniumwire_options=options)
この方法ならプロキシローテーションがずっと簡単です!
ウェブスクレイピングにおけるSeleniumとSelenium Wireの比較
まとめとして、以下のSeleniumとSelenium Wireの比較表をご覧ください:
| Selenium | Selenium Wire | |
|---|---|---|
| 目的 | ウェブブラウザを自動化してUIテストやウェブ操作を実行するツール | Seleniumを拡張し、HTTP/HTTPSリクエストとレスポンスの検査・変更機能を追加 |
| HTTP/HTTPSリクエスト処理 | HTTP/HTTPSリクエストやレスポンスへの直接アクセスは提供しません | HTTP/HTTPSリクエストとレスポンスの検査、変更、キャプチャを可能にする |
| プロキシサポート | 限定的なプロキシサポート(手動設定が必要) | 高度なプロキシ管理、動的設定をサポート |
| パフォーマンス | 軽量かつ高速 | ネットワークトラフィックのキャプチャと処理に伴うオーバーヘッドにより、若干遅くなります |
| ユースケース | 主にWebアプリケーションの機能テストに使用されますが、基本的なウェブスクレイピングにも有用です | APIのテスト、ネットワークトラフィックのデバッグ、ウェブスクレイピングに有用 |
まとめ
本記事では、Selenium Wire の概要とウェブスクレイピングへの活用方法について解説しました。特にプロキシ統合とローテーションプロキシに焦点を当てています。Selenium Wire は有用ですが万能ソリューションではない点、また現在アクティブにメンテナンスされていない点に留意してください。
より良いアプローチは、Selenium Wireを拡張するのではなく、標準のSeleniumや他のブラウザ自動化ツールと専用のスクレイピングブラウザを組み合わせることです。
Bright Dataのスクレイピングブラウザは、Playwright、Puppeteer、Seleniumなどに対応したスケーラブルなクラウドブラウザです。リクエストごとに自動的に出口IPをローテーションし、ブラウザフィンガープリンティング、再試行、CAPTCHA解決などに対応しています。ブロックされる心配を忘れ、スクレイピング作業を効率化しましょう。
今すぐ登録して無料トライアルを開始しましょう!





