

このGoutteウェブ・スクレイピング・ガイドでは、以下のことを学びます:
- PHPライブラリGoutteとは
- ステップバイステップのチュートリアルでウェブスクレイピングに使用する方法
- ウェブスクレイピングのためのGoutteに代わるもの
- このアプローチの限界と可能な解決策
さあ、飛び込もう!
グーテとは何か?
Goutteは画面スクレイピングとウェブクローリングのためのPHPライブラリで、直感的なAPIを提供してウェブサイトをナビゲートし、HTML/XMLレスポンスからデータを抽出します。HTTPクライアントとHTML解析機能が統合されており、HTTPリクエストでWebページを取得し、データスクレイピングのために処理することができます。
注:2023年4月1日現在、Goutteはメンテナンスされておらず、現在は非推奨とされている。しかし、この記事を書いている時点では、まだ確実に機能している。
Goutteでウェブスクレイピングを行う方法:ステップ・バイ・ステップ・ガイド
このステップバイステップのチュートリアルセクションに従って、”Hockey Teams“サイトからデータを抽出するためのGoutteの使い方をご覧ください:
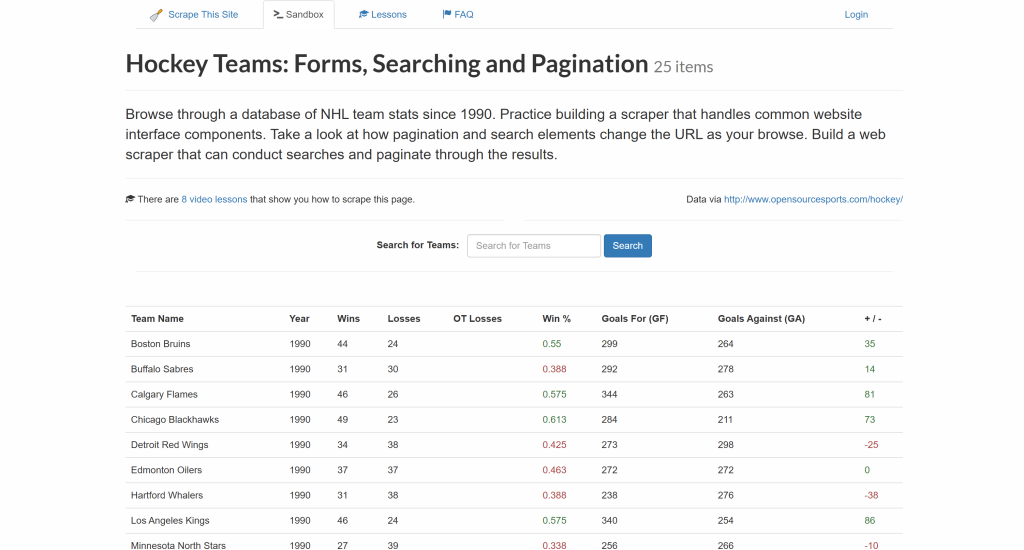
目標は、上の表からデータを抽出し、CSVファイルにエクスポートすることである。
Goutteでウェブスクレイピングを行う方法を学ぶ時間だ!
ステップ1:プロジェクトのセットアップ
始める前に、お使いのシステムがGoutteの要件-PHP7.1以上-を満たしていることを確認してください。現在のPHPバージョンを確認するには、以下のコマンドを実行してください:
php -v出力は次のようになるはずだ:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend TechnologiesPHPのバージョンが7.1より低い場合は、先に進む前にPHPをアップグレードする必要があります。
次に、GoutteはPHPの依存性マネージャであるComposerを介してインストールされることに留意してください。Composerがインストールされていない場合は、公式サイトからダウンロードし、インストール手順に従ってください。
次に、Goutteプロジェクト用の新しいディレクトリを作成し、ターミナルでそこに移動する:
mkdir goutte-parser
cd goutte-parser次に、composer initコマンドを使って、フォルダ内のComposerプロジェクトを初期化する:
composer initComposerは、パッケージ名や説明など、プロジェクトの詳細を入力するよう促します。デフォルトの答えで大丈夫ですが、あなたの目的に応じて自由にカスタマイズしてください。
次に、プロジェクトフォルダをお好みの PHP IDE で開きます。Visual Studio Code (PHP 拡張モジュール付き)あるいはIntelliJ WebStormがよいでしょう。
プロジェクトフォルダーに空のindex.phpファイルを作成する:
php-html-parser/
├── vendor/
├── composer.json
└── index.phpindex.phpを開き、Composerライブラリをインポートするために以下のコードを追加する:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...このファイルには間もなくグーテのスクレイピング・ロジックが含まれることになる。
これで、このコマンドを使ってスクリプトを実行できる:
php index.php素晴らしい!これでPHPでGoutteを使ったデータスクレイピングの準備は完了です。
ステップ2:Goutteのインストールと設定
以下のComposeコマンドでGoutteをインストールする:
composer require fabpot/goutteこれで、composer.jsonファイルにfabpot/goutteの依存関係が追加され、以下を含むようになります:
"require": {
"fabpot/goutte": "^4.0"
}index.phpに以下のコードを追加してGoutteをインポートする:
use GoutteClient;これは、ターゲット・ページに接続し、そのHTMLを解析し、そこからデータを抽出するために使用できるGoutte HTTPクライアントを公開している。その方法は次のステップで説明する!
ステップ #3: ターゲットページのHTMLを取得する
まず、新しいGoutte HTTPクライアントを作成する:
$client = new Client();GoutteのClientクラスは、SymfonyのBrowserKitHttpBrowserコンポーネントのラッパーです。Laravelを使ったWebスクレイピングのガイドで動作しているところをご覧ください。
次に、対象となるウェブページのURLを変数に格納し、request()メソッドを使用してその内容を取得します:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);これはWebページにGETリクエストを送り、HTMLドキュメントを取得し、あなたのためにそれを解析します。具体的には、$crawlerオブジェクトはsymfonyのDomCrawlerコンポーネントのすべてのメソッドへのアクセスを提供します。crawlerはページからデータを抽出するために使うオブジェクトです。
驚いた!これでGoutteウェブスクレイピングに必要なものはすべて揃った。
ステップ#4: 目的のデータをスクレイピングする準備
データを抽出する前に、対象ページのHTML構造に慣れておく必要がある。
まず、対象データはテーブル内の行に表示されることを覚えておこう。テーブルには複数の行が含まれるため、スクレイピングしたデータを格納するデータ構造としては配列が適している:
$teams = [];次に、テーブルのHTML構造に注目する。ブラウザで目的のページにアクセスし、目的のデータを含むテーブルを右クリックし、”Inspect “オプションを選択する:
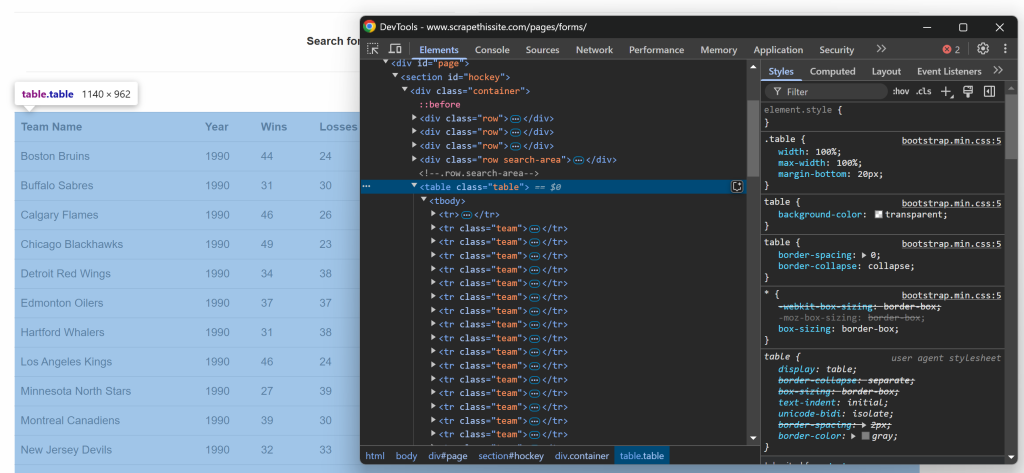
DevToolsでは、テーブルがtableクラスを持っていて、id=`”“hockey“という要素を持つ
。これは、以下のCSSセレクタを使用してテーブルをターゲットにできることを意味します:
#hockey .tableCSS セレクタを適用し、$crawler->filter()メソッドを使用してテーブルノードを選択します:
$table = $crawler->filter("#hockey .table");次に、各行がチームというクラスを持つ
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});素晴らしい!これでGoutteデータスクレイピングの骨格ができた。
ステップ#5:データ抽出ロジックの実装
前回同様、今回はテーブルの中の行を検査する:
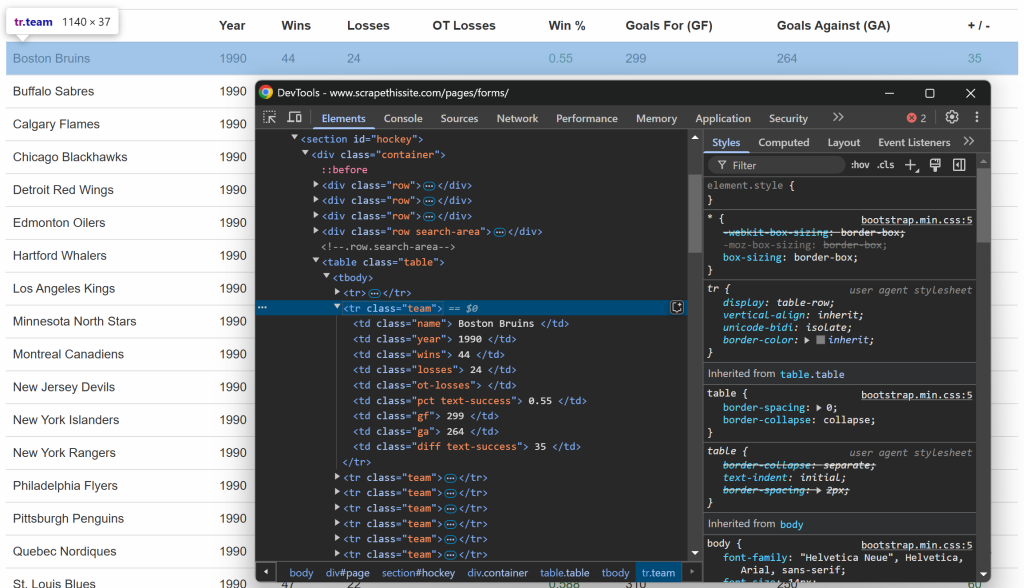
各行には、専用のカラムに以下の情報が含まれていることにお気づきだろう:
- チーム名 →
.name要素内 - シーズン年 →
.year要素内 - 勝利数 →
.wins要素内 .loss要素内の損失数→損失数- 時間外損失 →
.ot-losses要素内 - 勝率 →
.pct要素内 - 得点(Goals For – GF) →
.gf要素内 - 失点数(Goals Against – GA) →
.ga要素内 - ゴール差 →
.diff要素内
ひとつの情報を取り出すには、次の2つのステップを踏む必要がある:
filter() を使用して HTML 要素を選択するtext()メソッドでテキストを取り出し、trim()で余分なスペースを削除します。
例えば、チーム名をスクレイピングすることができる:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());同様に、このロジックを他のすべての列に拡張する:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());行から目的のデータを取り出したら、それを$teams配列に格納します:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];すべての行をループした後、$teamsの配列は以下のようになる:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)素晴らしい!グーテ・データ・スクレイピング成功。
ステップ#6:クローリングロジックの実装
さて、ターゲット・サイトは複数のページにわたってデータを提示し、一度に一部だけを表示することを忘れてはならない。テーブルの下には、すべてのページへのリンクを提供するページネーション要素があります:

このように、以下の簡単なステップで、スクレイピング・スクリプトのページネーションを管理することができる:
- ページネーション・リンク要素を選択する
- ページ分割されたページのURLを抽出する。
- 各ページにアクセスし、先ほど考案したスクレイピング・ロジックを適用する。
ページネーションのリンク要素を調べることから始めよう:
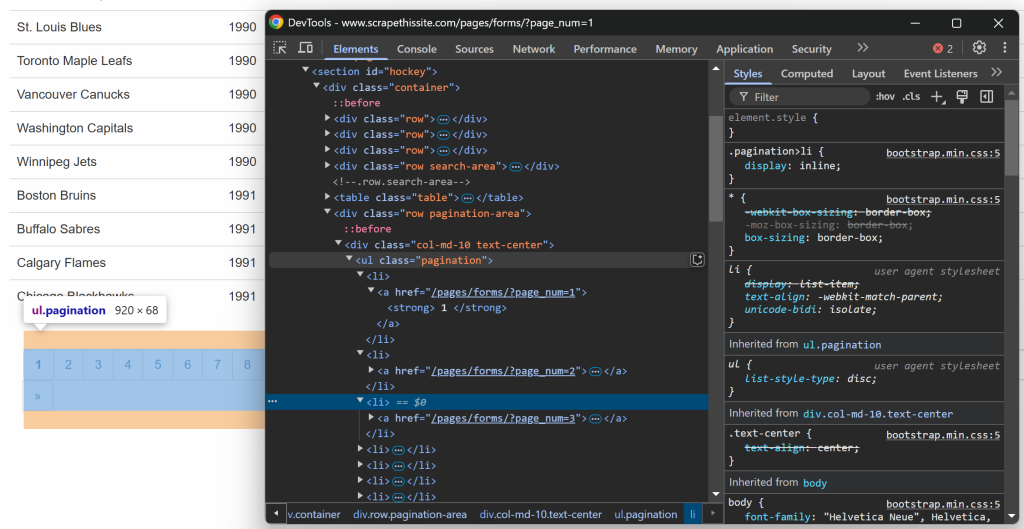
以下のCSSセレクタを使えば、すべてのページネーション・リンクを選択できることに注意してください:
.pagination li aステップ2を実装し、すべてのページネーションURLを収集するには、次のロジックを使用します:
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});これは、ページ分割リンクを保存する URL のリストを初期化します。そして、すべてのページ分割要素を選択し、 新しい URL がまだ存在しない場合にのみ$urls配列に追加します。ページの URL は相対 URL なので、リストに追加する前に絶対 URL に変換しなければなりません。
ページネーション処理は一度だけ実行されるべきで、データ抽出とは直接関係しないので、関数でラップするのが最善です:
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}このようにgetPaginationUrls()関数を呼び出すことができます:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");実行後、$urlsはすべてのページ分割されたURLを含む:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)完璧だ!Goutteにウェブクローリングを実装したところだ。
ステップ#7:すべてのページからデータをかき集める
これですべてのページのURLが配列に格納されたので、1つずつスクレイピングすることができる:
- リストの反復処理
- 各URLのHTMLコンテンツの取得と解析
- 必要なデータの抽出
- スクレイピングした情報を
$teams配列に格納する。
上記のロジックを以下のように実装する:
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}スクレイパーが操作している現在のページを記録するecho命令に注意してください。この情報はスクリプトが実行中に何をしているかを理解するのに便利です。
美しい!あとはスクレイピングしたデータをCSVのような人間が読める形式にエクスポートするだけだ。
ステップ#8:スクレイピングしたデータをCSVにエクスポートする
現在、スクレイピングされたデータは$teams配列に格納されています。他のチームがアクセスできるようにし、分析しやすくするには、CSVファイルにエクスポートします。
PHP はfputcsv()関数によって CSV エクスポートをビルトインでサポートしています。この関数を使用して、スクレイピングしたデータをteams.csvという名前のファイルに書き出します:
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);ミッション完了!グーテ・スクレーパーは完全に機能する。
ステップ9:すべてをまとめる
あなたのGoutteウェブスクレイピングスクリプトは、これで以下の内容を含んでいるはずです:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);このコマンドで起動する:
php index.phpスクレーパーは次のような出力を記録する:
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...実行の最後には、このデータを含むteams.csvファイルがプロジェクトフォルダーに表示されます:
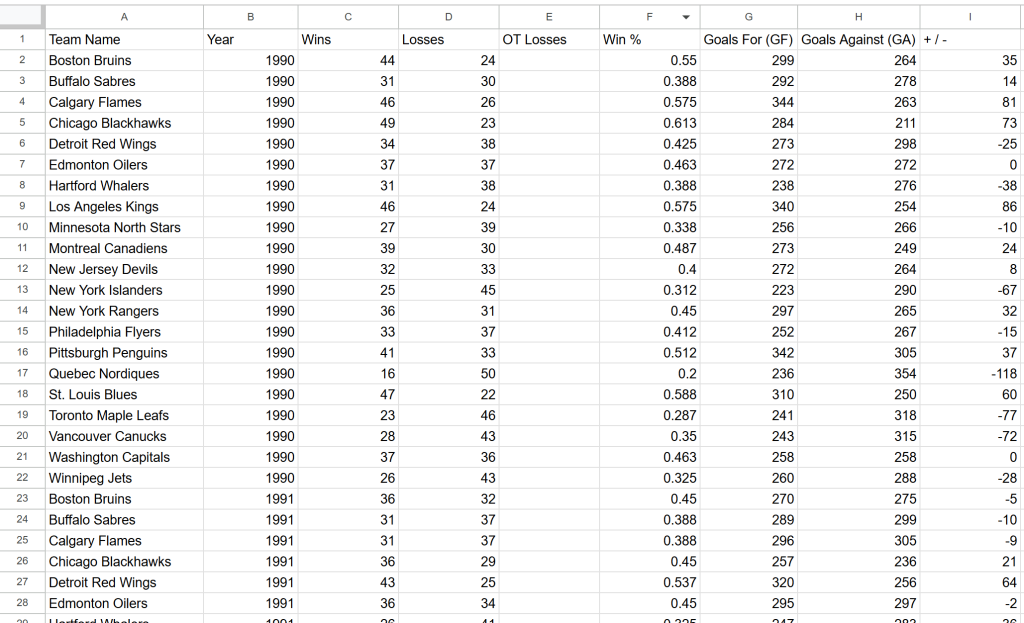
出来上がり!ターゲット・サイトの正確なデータが、構造化されたフォーマットで利用可能になった。
ウェブスクレイピング用PHP Goutteライブラリの代替品
この記事の冒頭で述べたように、Goutteは非推奨であり、もはやメンテナンスされていない。つまり、別の解決策を検討する必要がある。
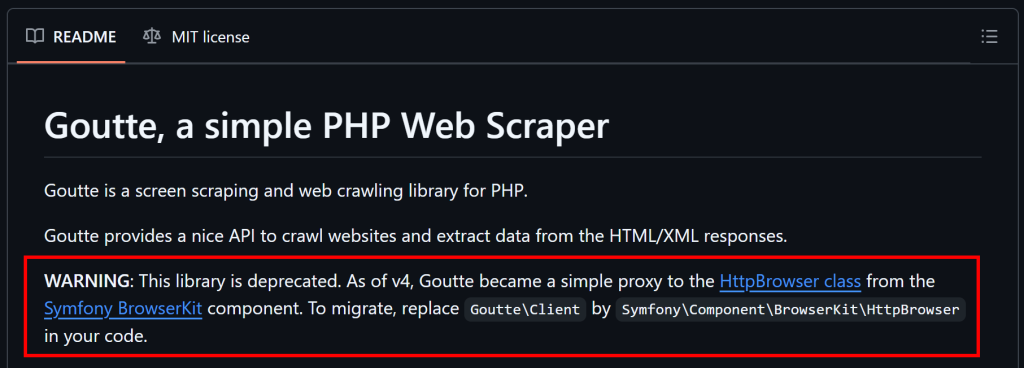
GitHubで説明されているように、Goutte v4は本質的にSymfonyのHttpBrowserクラスのプロキシになったので、移行すべきです。そのためには、これらのライブラリをインストールするだけです:
composer require symfony/browser-kit symfony/http-clientそして、交換する:
use GoutteClient;と
use SymfonyComponentBrowserKitHttpBrowser;最後に、プロジェクトの依存関係からGoutteを削除する。基本的なAPIは変わらないので、スクリプトを大きく変更する必要はないはずだ。
Goutteの代わりに、HTTPクライアントとHTMLパーサーを組み合わせることもできる。お勧めの選択肢をいくつか紹介しよう:
- HTTPリクエストを行うためのGuzzleまたはcURL。
DomHTMLDocument, Simple HTML DOM Parser あるいはDomCrawlerを使ってPHP で HTML をパースします。
これらの選択肢はすべて、より柔軟性を与え、あなたのウェブスクレイピングスクリプトが長期的に保守可能であることを保証します。
ウェブスクレイピングのこのアプローチの限界
Goutteは強力なツールだが、ウェブスクレイピングに使うにはいくつかの制限がある:
- ライブラリは非推奨
- そのAPIはもはや保守されていない
- レートリミッターとアンチスクレイピング・ブロックが適用される。
- JavaScriptに依存する動的なページは扱えない
- IPバンを避けるために不可欠なプロキシのサポートは限られている。
これらの制限のいくつかは、PHPを使ったWebスクレイピングのガイドで取り上げているように、別のライブラリや別のアプローチを使うことで軽減することができます。それでも、Web Unlocker APIを使うことでしか回避できないスクレイピング対策には常に直面することになります。
Web Unlocker API は、アンチボット保護を回避し、あらゆるウェブページの生の HTML を取得するために設計された、特殊なスクレイピング・エンドポイントです。APIコールを行い、返されたコンテンツを解析するのと同じくらいシンプルです。このアプローチでは、この記事で示されたように、Goutte (もしくは symfony の更新されたコンポーネント) とシームレスに統合できます。
結論
このガイドでは、ステップバイステップのチュートリアルを通して、Goutteとは何か、Webスクレイピングのために何を提供してくれるのかを探りました。このライブラリは現在では非推奨となっているため、代替となるライブラリもいくつか紹介しました。
どのPHPスクレイピング・ライブラリを選ぶかにかかわらず、最大の課題は、ほとんどのウェブサイトがアンチボットとアンチスクレイピング技術を用いてデータを保護していることです。これらのメカニズムは、自動化されたリクエストを検知してブロックすることができるため、従来のスクレイピング手法は効果がありません。
幸いなことに、Bright Dataはこのような問題を回避するための一連のソリューションを提供しています:
- ウェブアンロッカー:アンチスクレイピング保護をバイパスし、最小限の労力であらゆるウェブページからクリーンなHTMLを提供するAPI。
- スクレイピング・ブラウザ:JavaScriptレンダリングを備えたクラウドベースの制御可能なブラウザ。CAPTCHA、ブラウザフィンガープリント、再試行などを自動的に処理します。PantherやSelenium PHPとシームレスに統合できます。
- ウェブスクレイピングAPI:数十の一般的なドメインから構造化されたウェブデータにプログラムでアクセスするためのエンドポイント。
ウェブスクレイピングはしたくないけれど、「オンラインウェブデータ」に興味がある?すぐに使えるデータセットをご覧ください!
今すぐBright Dataに登録し、無料トライアルを開始してスクレイピングソリューションをお試しください。




