

このガイドでは以下を学びます:
curl_cffiの概要と提供機能- TLSフィンガープリントに基づくボット検知を最小化する仕組み
- Pythonでのウェブスクレイピングへの活用方法
- 高度な使用法と手法
- 類似のHTTPクライアントとの比較
さあ、始めましょう!
curl_cffiとは?
curl_cffiは、CFFIを介してcurl-impersonateフォークのPythonバインディングを提供するライブラリです。つまり、ブラウザのTLS/JA3/HTTP2フィンガープリントを偽装できるHTTPクライアントです。これにより、TLSフィンガープリントに基づくボット対策ブロックを回避する優れたソリューションとなります。
⚙️ 機能
- JA3/TLS および HTTP2 フィンガープリントの偽装をサポート(最新ブラウザやカスタムフィンガープリントを含む)
requestsやhttpxよりもはるかに高速で、aiohttpと同等の性能requestsAPIを模倣- 非同期HTTPリ
クエストのためのasyncioをサポート - 各リクエストごとのプロキシローテーションをサポート
- HTTP/2.0をサポート
WebSocketsをサポート
仕組み
curl_cffi は、実際のブラウザと一致する TLS フィンガープリントを生成するライブラリであるcURL Impersonate を基盤としています。
HTTPSリクエストを送信すると、TLSハンドシェイクが発生し、一意のTLSフィンガープリントが生成されます。HTTPクライアントはブラウザとは異なるため、そのフィンガープリントは自動化を露呈し、ボット対策を引き起こす可能性があります。
cURL ImpersonateはcURLを修正し、実際のブラウザのTLSフィンガープリントに一致させます:
- TLSライブラリの調整: cURLのライブラリではなく、ブラウザが使用するTLS接続ライブラリに依存します。
- 設定変更:TLS拡張機能とSSLオプションを調整し、ブラウザを模倣します。
- HTTP/2のカスタマイズ:ブラウザのハンドシェイク設定に合わせる。
- 非デフォルトのcURLフラグ:
--ciphers、--curves、カスタムヘッダーを設定し精度を高めます。
これによりリクエストがブラウザ風に見え、ボット検知の回避に役立ちます。詳細はcURL Impersonateガイドを参照してください。
ウェブスクレイピングにおけるcurl_cffiの使用方法:ステップバイステップガイド
目標がウォルマートの「キーボード」ページをスクレイピングすることだと仮定します:
任意のHTTPクライアントでこのページにアクセスしようとすると、以下のエラーページが表示されます:
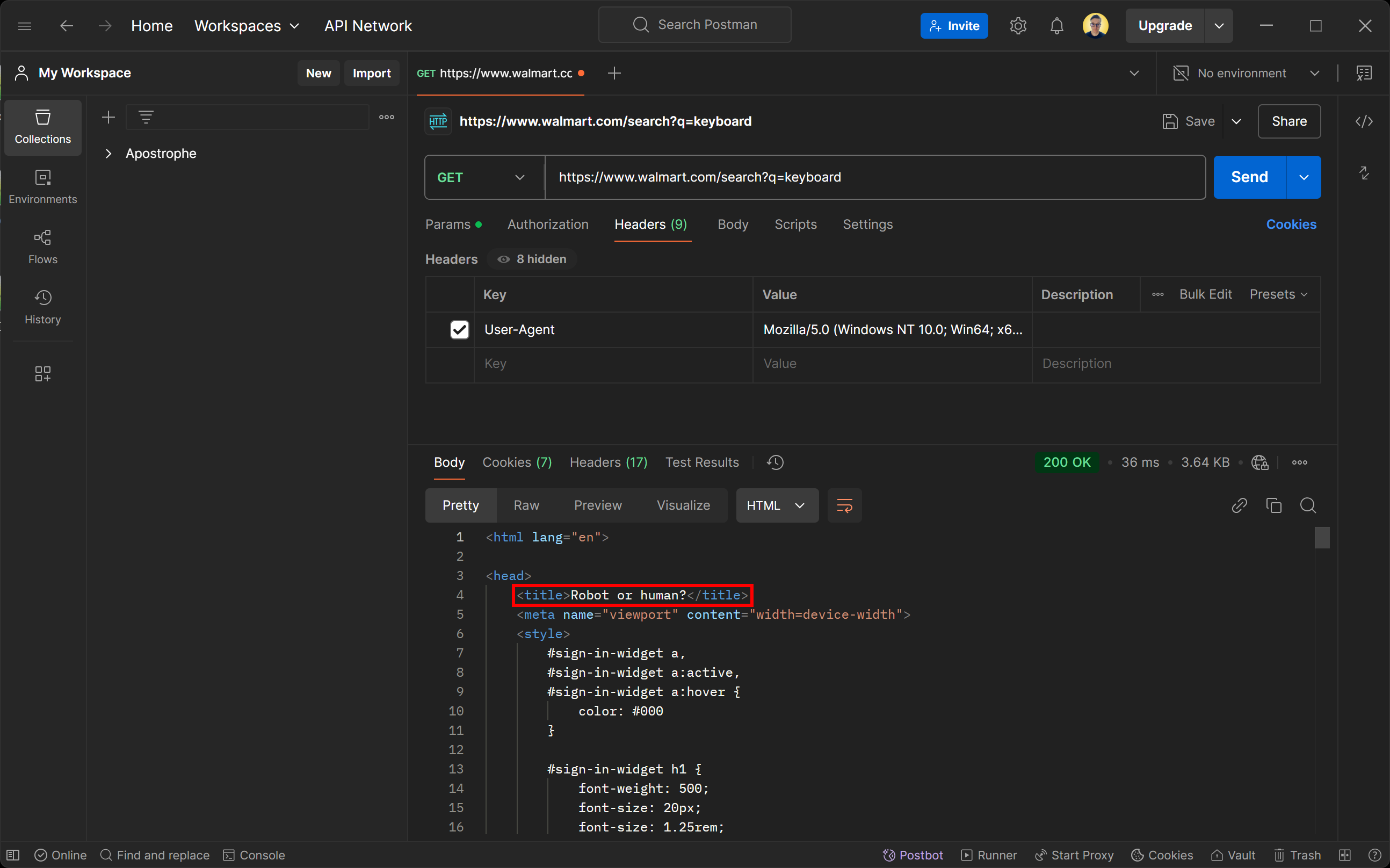
200 OKの応答ステータスに惑わされないでください。ウォルマートのサーバーが返すページは実際にはボット検知ページです。具体的にはCAPTCHAチャレンジで人間かどうかを確認するよう求められます。
「User-Agentを実際のブラウザに偽装してもなぜ検知されるのか?」と疑問に思うかもしれません。その答えはTLSフィンガープリンティングです!
それでは、curl_cffi を使用してボット対策回避とウェブスクレイピングを容易に行う方法を見ていきましょう。
ステップ #1: プロジェクト設定
まず、お使いのマシンにPython 3+がインストールされていることを確認してください。インストールされていない場合は、公式サイトからダウンロードし、インストール手順に従ってください。
次に、以下のコマンドでcurl_cffi スクラッピングプロジェクト用のディレクトリを作成します:
mkdir curl-cfii-スクレイパー
そのディレクトリに移動し、仮想環境を設定します:
cd curl-cfii-スクレイパー
python -m venv env
お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionなどが適しています。
次に、プロジェクトフォルダ内にscraper.py ファイルを作成します。最初は空ですが、すぐにスクレイピングロジックを追加します。
IDEのターミナルで仮想環境をアクティブ化します。LinuxまたはmacOSの場合、以下を実行:
./env/bin/activate
Windowsでは同等の操作として以下を実行:
env/Scripts/activate
素晴らしい!これで準備は完了です。
ステップ #2:curl_cffiのインストール
アクティブ化された仮想環境内で、curl-cffi pipパッケージ経由でHTTPクライアントをインストールします:
pip install curl-cffi
このライブラリはバックグラウンドで自動的にWindows、macOS、Linux用のcurl偽装バイナリをダウンロードします。
ステップ #3: ターゲットページへの接続
curl_cffi からrequests をインポートします:
from curl_cffi import requests
このオブジェクトは、Python Requestsライブラリと同様の高レベルAPIを公開します。
以下のように、ターゲットページへの GET HTTP リクエストを実行できます:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
impersonate="chrome" 引数は、curl_cffi に HTTP リクエストを最新バージョンの Chrome から送信されたように見せかけるよう指示します。その結果、Walmart は自動化されたリクエストを通常のブラウザリクエストとして扱い、ボット対策ページではなく標準のウェブページを返します。
対象ページのHTMLコンテンツには以下のようにアクセスできます:
html = response.text
htmlを出力すると、以下のように表示されます:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>Electronics - Walmart.com</title>
<!-- 簡略化のため省略 ... -->
素晴らしい!これが通常のウォルマート「キーボード」製品ページのHTMLです。
ステップ #4: データスクレイピングロジックの追加
curl_cffiは単にページのHTMLを取得するHTTPクライアントです。ウェブスクレイピングを行うには、BeautifulSoupのようなHTMLパースライブラリも必要です。詳細はBeautifulSoupウェブスクレイピングガイドを参照してください。
アクティブ化された仮想環境で、BeautifulSoupをインストールします:
pip install beautifulsoup4
scraper.pyでインポートします:
from bs4 import BeautifulSoup
次に、ページのHTMLをパースするために使用します:
soup = BeautifulSoup(response.text, "html.parser")
"html.parser"はPython標準ライブラリのデフォルトHTMLパーサーで、BeautifulSoupがHTML文字列をパースするために使用します。これでsoupには、ページ上のHTML要素を選択しデータを抽出するために必要な全メソッドが含まれます。
この例では、パースが主目的ではないため、ページタイトルのみをスクレイピングします。find()メソッドでCSSセレクタを用いて選択し、text属性でテキストにアクセスできます:
title_element = soup.find("title")
title = title_element.text
より高度なスクレイピングロジックについては、Walmartのスクレイピング方法に関するガイドを参照してください。
最後にページタイトルを出力します:
print(title)
素晴らしい!基本的なウェブスクレイピングロジックを実装できました。
ステップ #5: 全てを統合する
これが最終的なcurl_cffiウェブスクレイピングスクリプトです:
from curl_cffi import requests
from bs4 import BeautifulSoup
# Walmart検索ページに「keyboard」でGETリクエストを送信
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# ページからHTMLを抽出
html = response.text
# BeautifulSoupでレスポンス内容をパース
soup = BeautifulSoup(response.text, "html.parser")
# CSSセレクタでtitleタグを検索し出力
title_element = soup.find("title")
# そこからデータを抽出
title = title_element.text
# より複雑なスクレイピングロジック...
# スクレイピングしたデータを出力
print(title)
以下のコマンドで実行:
python3 スクレイパー.py
Windowsでは同等の方法で実行:
python スクレイパー.py
結果は次のようになります:
Electronics - Walmart.com
impersonate="chrome" 引数を削除すると、代わりに次の結果が得られます:
ロボットですか、それとも人間ですか?
これは、スクレイピング対策回避においてブラウザの偽装がどれほど重要かを示しています。
ミッション完了!
curl_cffi: 高度な使用法
ライブラリの仕組みを理解したところで、より高度なシナリオを探求する準備が整いました。
ブラウザの偽装選択
curl_cffi は複数のブラウザのなりすましをサポートしています。各ブラウザには固有のラベルが割り当てられており、以下のようにimpersonate 引数に渡すことができます:
response = requests.get("<YOUR_URL>", impersonate="<BROWSER_LABEL>")
サポートされているブラウザのラベルは以下の通りです:
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
注記:
- 常に最新のブラウザバージョンをエミュレートするには、単に
chrome、safari、safari_iosを使用できます。 - Firefoxは現在利用できません。WebKitベースのブラウザのみがサポートされています。
- ブラウザバージョンはフィンガープリントが変更された場合にのみ追加されます。
chrome122などのバージョンがスキップされた場合でも、前バージョンのヘッダーを使用することでエミュレート可能です。 - 非ブラウザ対象の場合は、
ja3、akamaiなどの引数を使用して独自のカスタム TLS フィンガープリントを指定してください。詳細は、なりすましに関するドキュメントを参照してください。
セッション管理
requestsライブラリと同様に、curl-cfiiはセッションをサポートしています。セッションオブジェクトを使用すると、クッキー、ヘッダー、その他のセッション固有のデータなど、特定のパラメータを複数のリクエストにわたって保持できます。
cURL ImpersonateライブラリのPythonバインディングでセッションを定義する方法は以下の通りです:
# 新しいセッションを作成
session = requests.Session()
# このエンドポイントはサーバーにクッキーを設定する
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# セッションのクッキーを出力し、保存されていることを確認
print(session.cookies)
上記スクリプトの出力例:
<Cookies[<Cookie userId=5 for httpbin.org />]>
この結果は、サーバーが定義したクッキーの保存など、セッションがリクエスト間で状態を維持していることを証明しています。
プロキシ統合
requestsライブラリと同様に、curl_cffiは proxiesオブジェクトを介したプロキシ統合をサポートします:
# プロキシURLを定義
proxy = "YOUR_PROXY_URL"
# HTTPとHTTPS用のプロキシ辞書を作成
proxies = {"http": proxy, "https": proxy}
# プロキシとブラウザ偽装を使用したリクエストの実行
response = requests.get("<YOUR_URL>", impersonate="chrome", proxies=proxies)
基盤となるAPIはrequestsと非常に類似しているため、Requestsでのプロキシ使用方法については当ガイドを参照してください。
非同期API
curl_cffiは AsyncSessionオブジェクトを介したasyncioによる非同期リクエストをサポートします:
from curl_cffi.requests import AsyncSession
import asyncio
# 非同期コードを実行する非同期関数を定義
async def fetch_data():
async with AsyncSession() as session:
# 非同期GETリクエストを実行
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# レスポンステキストを出力
print(response.text)
# 非同期関数を実行
asyncio.run(fetch_data())
AsyncSessionを使用すると、複数の非同期リクエストを効率的に処理しやすくなり、ウェブスクレイピングの高速化に不可欠です。
WebSockets接続
curl_cffiは WebSocketクラスを通じてWebSocketsもサポートします:
from curl_cffi.requests import WebSocket
# 受信メッセージを処理するコールバック関数を定義
def on_message(ws, message):
print(message)
# コールバック付きでWebSocket接続を初期化
ws = WebSocket(on_message=on_message)
# サンプルWebSocketサーバーに接続しメッセージを待機
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
これは、WebSocketを使用して動的にデータを更新するサイトやAPIからリアルタイムデータをスクレイピングするのに特に有用です。例としては、金融市場データ、スポーツのライブスコア、ライブチャットを提供するサイトなどが挙げられます。
レンダリングされたページをスクレイピングする代わりに、WebSocketチャネルを直接ターゲットにすることで効率的なデータ取得が可能です。
注:AsyncWebSocketクラスを利用すれば、WebSocketを非同期で扱えます。
ウェブスクレイピングにおけるcurl_cffi vs Requests vs AIOHTTP vs HTTPX
以下は、ウェブスクレイピング向けの curl_cffiと他の人気Python HTTPクライアントを比較した要約表です:
| 機能 | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| 同期 API | ✔️ | ✔️ | ❌ | ✔️ |
| 非同期 API | ✔️ | ❌ | ✔️ | ✔️ |
**WebSocket**のサポート |
✔️ | ❌ | ✔️ | ❌ |
| 接続プール | ✔️ | ✔️ | ✔️ | ✔️ |
| HTTP/2のサポート | ✔️ | ❌ | ❌ | ✔️ |
**User-Agent** カスタマイズ |
✔️ | ✔️ | ✔️ | ✔️ |
| TLSフィンガープリント偽装 | ✔️ | ❌ | ❌ | ❌ |
| 速度 | 高速 | 中 | 高 | 中 |
| 再試行メカニズム | ❌ | HTTPアダプター経由で利用可能 |
サードパーティ製ライブラリ経由でのみ利用可能 | 組み込みトランスポート経由で利用可能 |
| プロキシ統合 | ✔️ | ✔️ | ✔️ | ✔️ |
| クッキーの処理 | ✔️ | ✔️ | ✔️ | ✔️ |
curl_cffi 代替手段によるウェブスクレイピング
curl_cffi は手動でのウェブスクレイピングを必要とするため、コードの大半を自身で記述する必要があります。単純な静的ウェブサイトには適していますが、動的またはよりセキュリティの高いサイトをターゲットとする際には課題が生じやすいです。
Bright Dataは、ウェブスクレイピングのためのcurl_cffi代替手段を幅広く提供しています:
- スクレイピングブラウザAPI: Puppeteer、Selenium、Playwrightと統合された完全管理型のクラウドブラウザインスタンス。これらのブラウザは組み込みのCAPTCHAの解決機能と自動プロキシローテーションを提供し、ボット対策機能を回避しながら実際のユーザーのようにウェブサイトとやり取りします。
- WebスクレイパーAPI:100以上の人気ドメインから最新の構造化データを取得するための事前設定済みエンドポイント。これらのAPIは倫理的かつコンプライアンスに準拠しており、HTTPXやその他のHTTPクライアントを使用した簡単なデータ抽出を可能にします。
- ノーコードスクレイパー:コーディング不要の直感的なオンデマンドデータ収集サービス。インフラ、プロキシ、スクレイピング対策といった障壁を気にせず、制御性、拡張性、柔軟性を提供します。
- データセット:様々なウェブサイトから事前構築されたデータセットにアクセスするか、要件に合わせてデータ収集をカスタマイズできます。
これらのソリューションは、手作業を削減する堅牢でスケーラブル、かつコンプライアンスに準拠したデータ抽出ツールを提供することで、スクレイピングを簡素化します。
結論
本記事では、ウェブスクレイピングにcurl_cffiライブラリを活用する方法を解説しました。その目的、主要機能、利点を探求しました。このHTTPクライアントは、実ブラウザを模倣したリクエストを高速かつ確実に実行する優れた選択肢です。
ただし、自動化されたHTTPリクエストはパブリックIPアドレスを公開する可能性があり、身元や位置情報が漏洩するリスクがあります。セキュリティと匿名性を保護する最も効果的な解決策の一つは、プロキシサーバーを使用してIPアドレスを隠すことです。
Bright Dataは世界最高峰のプロキシサーバーを管理し、フォーチュン500企業を含む20,000以上の顧客にサービスを提供しています。その提供内容は多様なプロキシタイプを網羅しています:
- データセンター・プロキシ – 77万以上のデータセンターIPアドレス。
- レジデンシャルプロキシ – 195カ国以上で7,200万以上のレジデンシャルIP。
- ISPプロキシ – 70万以上のISP IPアドレス。
Bright Dataの無料アカウントを今すぐ作成し、プロキシとスクレイピングソリューションをお試しください!




