

本日のガイドでは、Scrapy Spiderを作成し AWS Lambdaにデプロイします。コード自体は非常にシンプルです。Lambdaのようなクラウドサービスでは多くの可変要素が存在します。これらの要素を管理する方法と、問題発生時の対処法を解説します。
前提条件
このタスクを実行するには、以下のものが必要です:
- here
- Scrapy を使ったスクレイピングの基本知識
サーバーレスとは?
サーバーレスアーキテクチャはコンピューティングの未来として称賛されています。サーバーレスアプリの実際の稼働時間は時間当たりでより高額になる可能性がありますが、既にサーバーの稼働費用を支払っていない場合、Lambdaは理にかなっています。
仮にスクレイパーの実行に1分かかり、1日1回実行するとします。従来のサーバーでは、24時間稼働の1か月分の料金を支払うことになりますが、実際の使用時間はわずか30分です。Lambdaのようなサービスでは、実際に使用した分だけ支払うことになります。
メリット
- 課金: 実際に使用した分だけ支払う。
- スケーラビリティ:Lambdaは自動でスケールするため、管理不要。
- サーバー管理:サーバー管理に時間を費やす必要はありません。すべてが自動化されています。
デメリット
- レイテンシー: 関数がアイドル状態の場合、起動と実行に時間がかかります。
- 実行時間: Lambda関数のデフォルトタイムアウトは3秒、最大実行時間は15分です。従来のサーバーの方がはるかに柔軟です。
- 移植性: OS互換性に依存するだけでなく、ベンダーの裁量に委ねられます。Lambda関数を単純にコピーしてAzureやGoogle Cloudで実行することはできません。
Bright Dataには、こうした制限のないソリューションがあります。次にそれを探ってみましょう。
サーバーレス関数:最良の代替手段
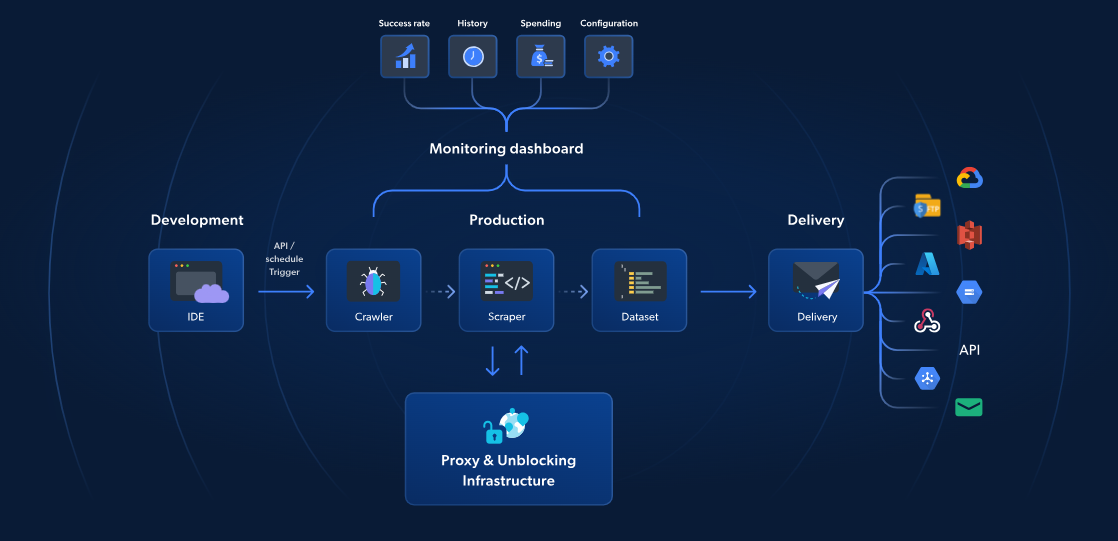
AWS LambdaやScrapyもサーバーレスウェブスクレイピングを提供しますが、Bright Dataのサーバーレス関数は、より高速で信頼性の高いウェブスクレイピングに特化したソリューションです。70以上の事前構築済みJavaScriptテンプレート、統合型クラウドベースIDE、AI搭載のブロック解除ソリューションにより、CAPTCHAの回避、容易なスケーリングが可能となり、インフラ管理の手間なくデータ抽出に集中できます。
AWSやScrapyのアプローチとは異なり、Bright Dataのソリューションにはプロキシ管理、自動スケーリング、S3やGoogle Cloudなどのストレージプラットフォームとの直接連携が含まれます。1,000ページロードあたりわずか2.7ドルから利用可能なServerless Functionsは、高度なウェブスクレイピングをよりシンプルに、より高速に、よりコスト効率良く実現します。
それでは、ScrapyとAWSのガイドを続行しましょう。
はじめに
サービスの設定
AWSアカウントを取得したら、S3バケットが必要です。「すべてのサービス」ページに移動し、下にスクロールします。
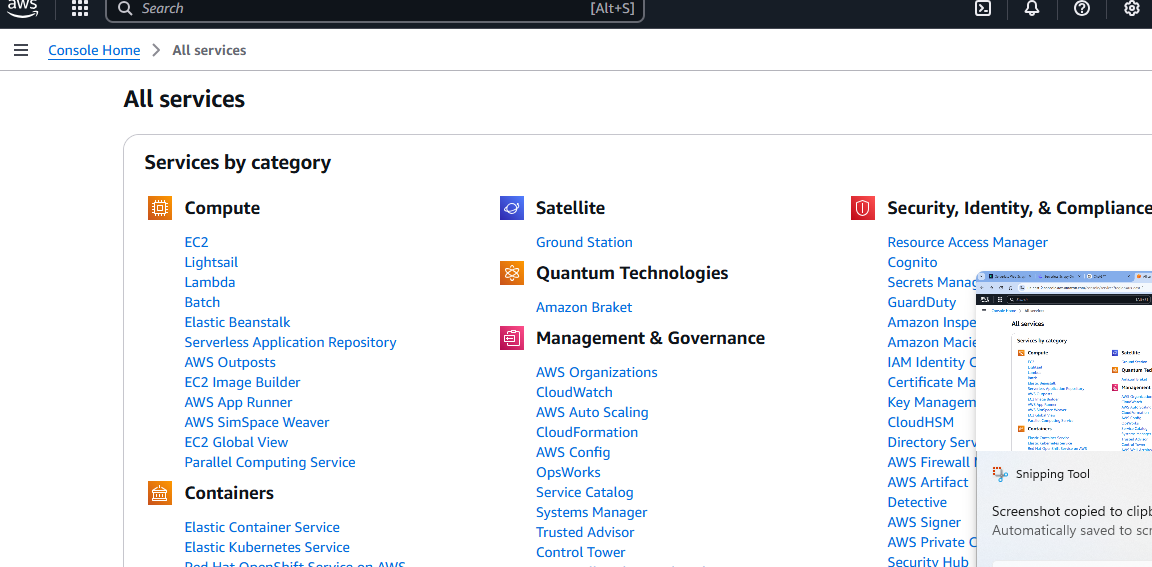
やがて「ストレージ」セクションが表示されます。このセクションの最初のオプションが「S3」です。クリックしてください。
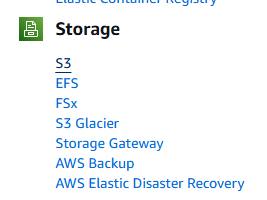
次に、「バケットの作成」ボタンをクリックします。
ここでバケット名と設定を選択します。ここではデフォルト設定のまま進めます。
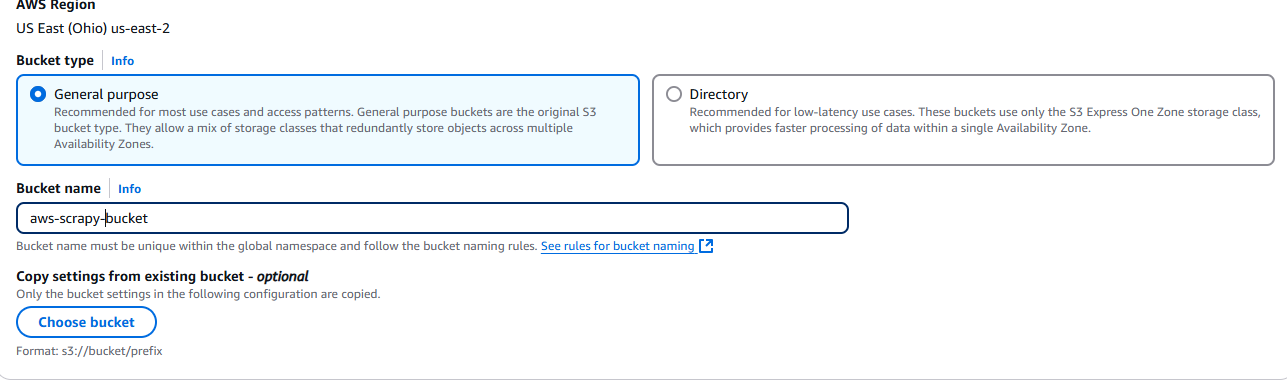
設定が完了したら、ページ右下の「バケットの作成」ボタンをクリックします。

作成が完了すると、バケットはAmazon S3の「バケット」タブに表示されます。
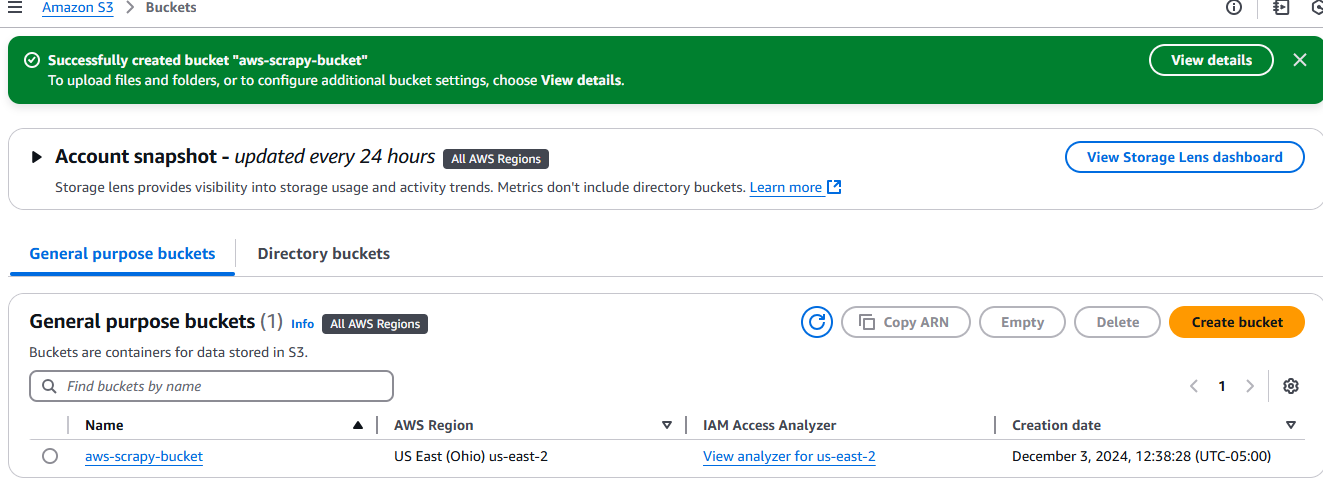
プロジェクトの設定
新しいプロジェクトフォルダを作成します。
mkdir scrapy_aws
新しいフォルダに移動し、仮想環境を作成します。
cd scrapy_aws
python3 -m venv venv
環境を有効化します。
source venv/bin/activate
Scrapyをインストールします。
pip install scrapy
スクレイピング対象
動的ウェブサイト、ボット対策、大規模スクレイピングには、Bright Dataのスクレイピングブラウザをご利用ください。タスクの自動化、CAPTCHAの回避、シームレスな拡張が可能です。
対象サイトとしてbooks.toscrapeを使用します。これはウェブスクレイピングに特化した教育サイトです。下の画像を見ると、各書籍はclass名product_podを持つ記事です。ページからこれらの要素をすべて抽出します。
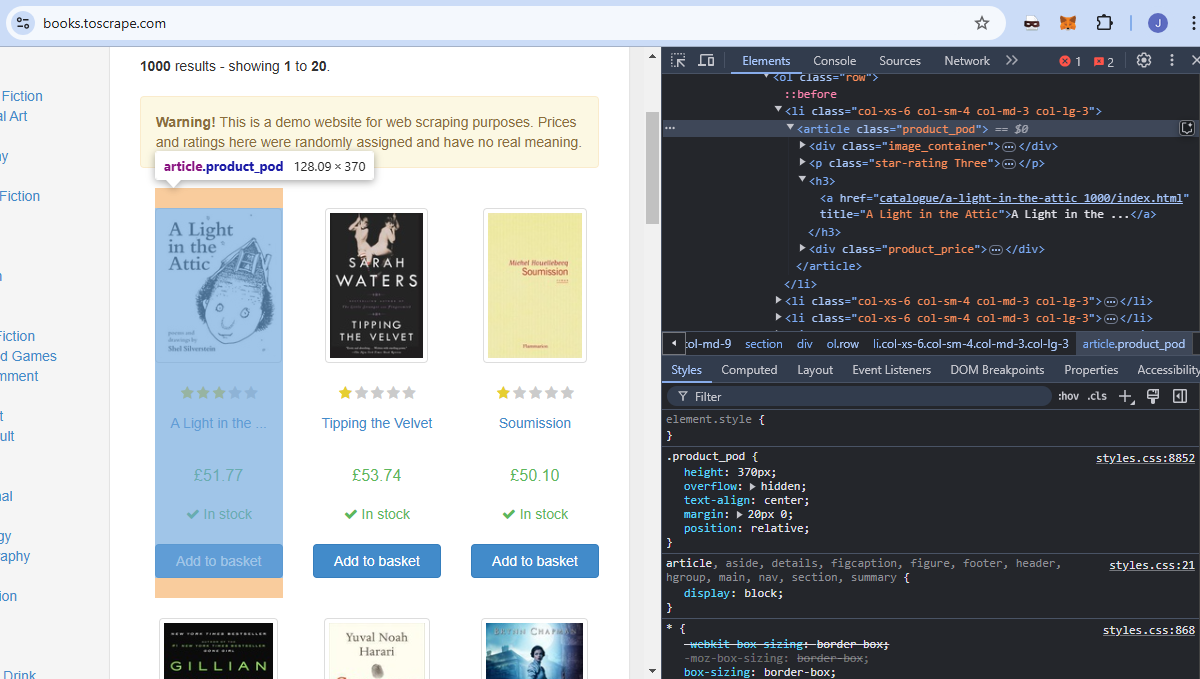
各書籍のタイトルは、h3要素内にネストされたa要素内に埋め込まれています。

各価格はdiv内にネストされたp内に埋め込まれています。クラス名はprice_colorです。
コードの記述
次に、スクレイパーを記述しローカルでテストします。新しいPythonファイルを開き、以下のコードを貼り付けます。当方のファイル名はaws_spider.pyとします。
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
以下のコマンドでスパイダーをテストできます。書籍と価格が記載されたJSONファイルが出力されるはずです。
python -m scrapy runspider aws_spider.py -o books.json
次に、ハンドラーが必要です。ハンドラーの役割は単純で、スパイダーを実行することです。ここでは基本的に同じ機能を持つ2つのハンドラーを作成します。主な違いは、1つをローカルで実行し、もう1つをLambda上で実行する点です。
ローカルハンドラーはlambda_function_local.py と名付けました。
import subprocess
def handler(event, context):
# ローカルテスト用出力ファイルパス
output_file = "books.json"
# Scrapyスパイダーを-oフラグ付きで実行し、出力をbooks.jsonに保存
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# 成功メッセージを返す
return {
'statusCode': '200',
'body': f"スクレイピング完了!出力は {output_file} に保存されました",
}
# ローカルテスト用にこのブロックを追加
if __name__ == "__main__":
# AWS Lambda呼び出しイベントとコンテキストをシミュレート
fake_event = {}
fake_context = {}
# ハンドラーを呼び出し結果を出力
result = handler(fake_event, fake_context)
print(result)
books.jsonを削除してください。以下のコマンドでローカルハンドラーをテストできます。正常に動作している場合、プロジェクトフォルダ内に新しいbooks.jsonが生成されます。bucket_nameを自身のバケット名に変更することを忘れないでください。
python lambda_function_local.py
次に、Lambdaで使用するハンドラーです。ほぼ同様ですが、データをS3バケットに保存するための微調整が加えられています。
import subprocess
import boto3
def handler(event, context):
# ローカル出力ファイルとS3出力ファイルのパスを定義
local_output_file = "/tmp/books.json" # Lambdaでは/tmp必須
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # S3バケット内のパス
# Scrapyスパイダーを実行し、出力をローカルに保存
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# ファイルをS3にアップロード
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"スクレイピング完了!出力は s3://{bucket_name}/{s3_key} にアップロードされました"
}
- まずデータを一時ファイルに保存します:
local_output_file = "/tmp/books.json"。これによりデータが失われるのを防ぎます。 s3.upload_file(local_output_file, bucket_name, s3_key)でバケットにアップロードします。
AWS Lambdaへのデプロイ
次に、AWS Lambdaにデプロイする必要があります。
パッケージフォルダを作成します。
mkdir package
依存関係をパッケージフォルダにコピーします。
cp -r venv/lib/python3.*/site-packages/* package/
ファイルをコピーします。以前にテストしたローカルハンドラーではなく、Lambda用に作成したハンドラーを必ずコピーしてください。
cp lambda_function.py aws_spider.py package/
packageフォルダをzipファイルに圧縮します。
zip -r lambda_function.zip package/
ZIPファイルを作成したら、AWS Lambdaに移動し「関数を作成」を選択します。プロンプトが表示されたら、ランタイム(Python)やアーキテクチャなどの基本情報を入力します。
S3バケットへのアクセス権限を付与することを必ず確認してください。
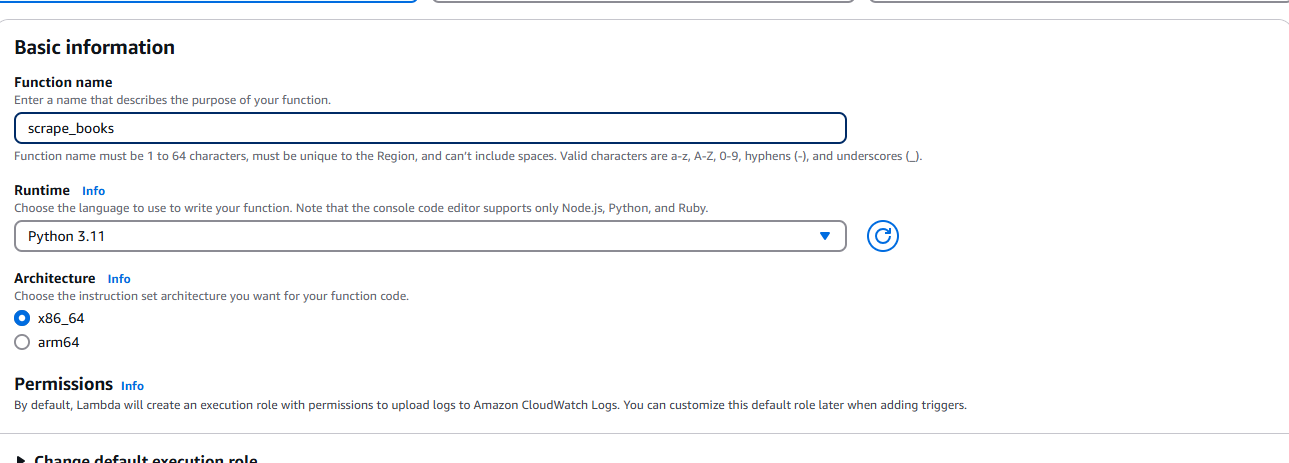
関数作成後、[ソース]タブ右上のドロップダウンから[アップロード]を選択します。

.zipファイルを選択し、作成したZIPファイルをアップロードします。
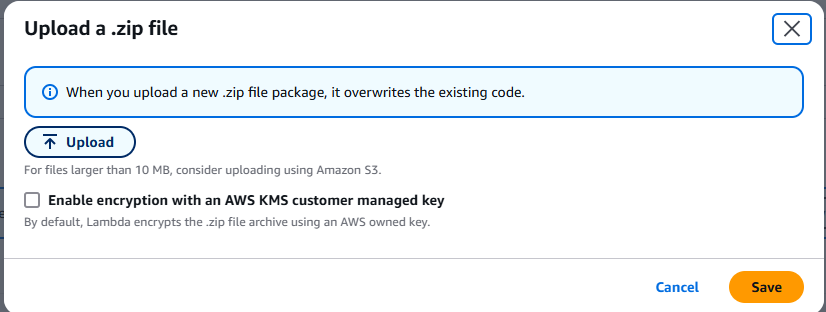
テストボタンをクリックし、関数の実行を待ちます。実行後、S3バケットを確認すると、新しいファイル「books.json」が作成されているはずです。
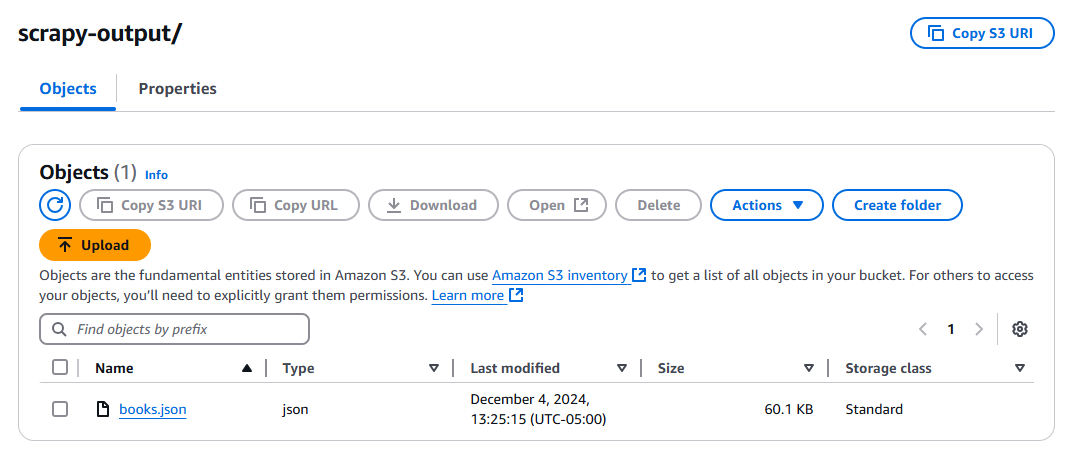
トラブルシューティングのヒント
Scrapyが見つからない
Scrapyが見つからないというエラーが発生する場合があります。その場合は、subprocess.run()内のコマンド配列に以下を追加する必要があります。

一般的な依存関係の問題
Pythonのバージョンが一致していることを確認してください。ローカルにインストールされているPythonを確認します。
python --version
このコマンドの出力が Lambda 関数と異なる場合は、Lambda 設定を変更して一致させてください。
ハンドラーの問題

ハンドラーはlambda_function.py で記述した関数と一致させる必要があります。上記のようにlambda_function.handler という形式です。lambda_function は Python ファイル名を、handler は関数名をそれぞれ表します。
S3への書き込み不可
出力の保存時に権限の問題が発生する可能性があります。その場合、Lambdaインスタンスに以下の権限を追加する必要があります。
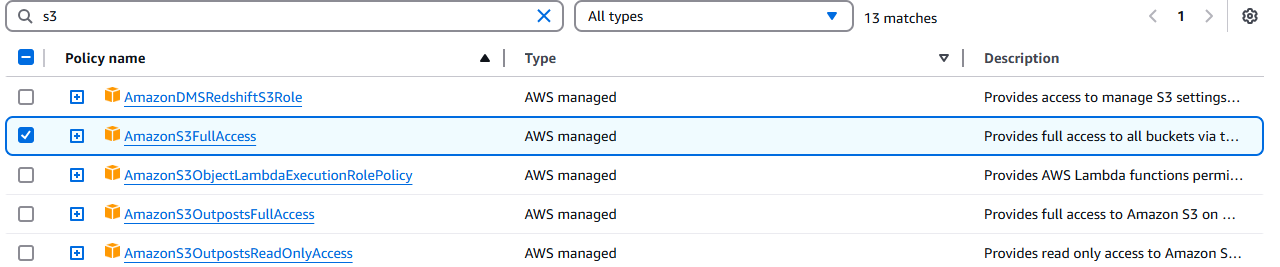
IAMコンソールに移動し、対象のLambda関数を検索します。該当関数をクリックし、「権限の追加」ドロップダウンを選択します。
[ポリシーの添付]をクリックします。
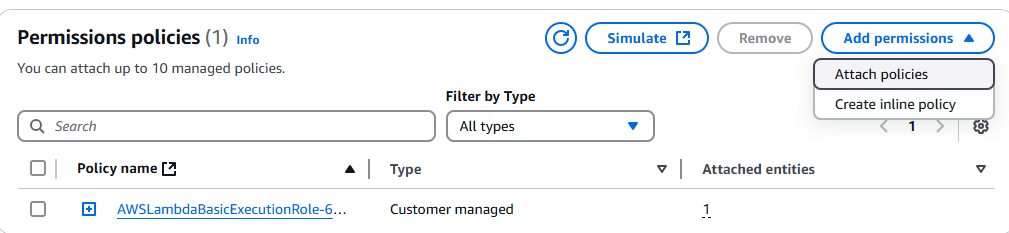
AmazonS3FullAccessを選択します。
まとめ
完了です!これで、AWSコンソールというUIの悪夢の中でも、自力で対処できるはずです。Scrapyを使ったクローラーの作成方法、Amazon Linuxとのバイナリ互換性を確保するためのLinuxまたはWSL環境のパッケージ化方法も理解できました。
ウェブスクレイピングに興味がない場合は、当社のウェブスクレイパー APIと既製のデータセットをご覧ください。今すぐ登録して無料トライアルを開始しましょう!





