

Pythonはウェブスクレイピングにおいて最も人気のある言語の一つです。インターネット上で最大の情報源は何でしょうか?Googleです!だからこそPythonによるGoogleスクレイピングが広く普及しているのです。その目的はSERPデータを自動的に取得し、マーケティングや競合監視などに活用することにあります。
このガイド付きチュートリアルに従い、Seleniumを使用したPythonでのGoogleスクレイピング方法を学びましょう。さっそく始めましょう!
Googleからスクレイピングすべきデータとは?
Googleはインターネット上で最大の公開データソースの一つです。Googleマップのレビューから「People also ask(よくある質問)」の回答まで、そこから取得できる興味深い情報は膨大です:
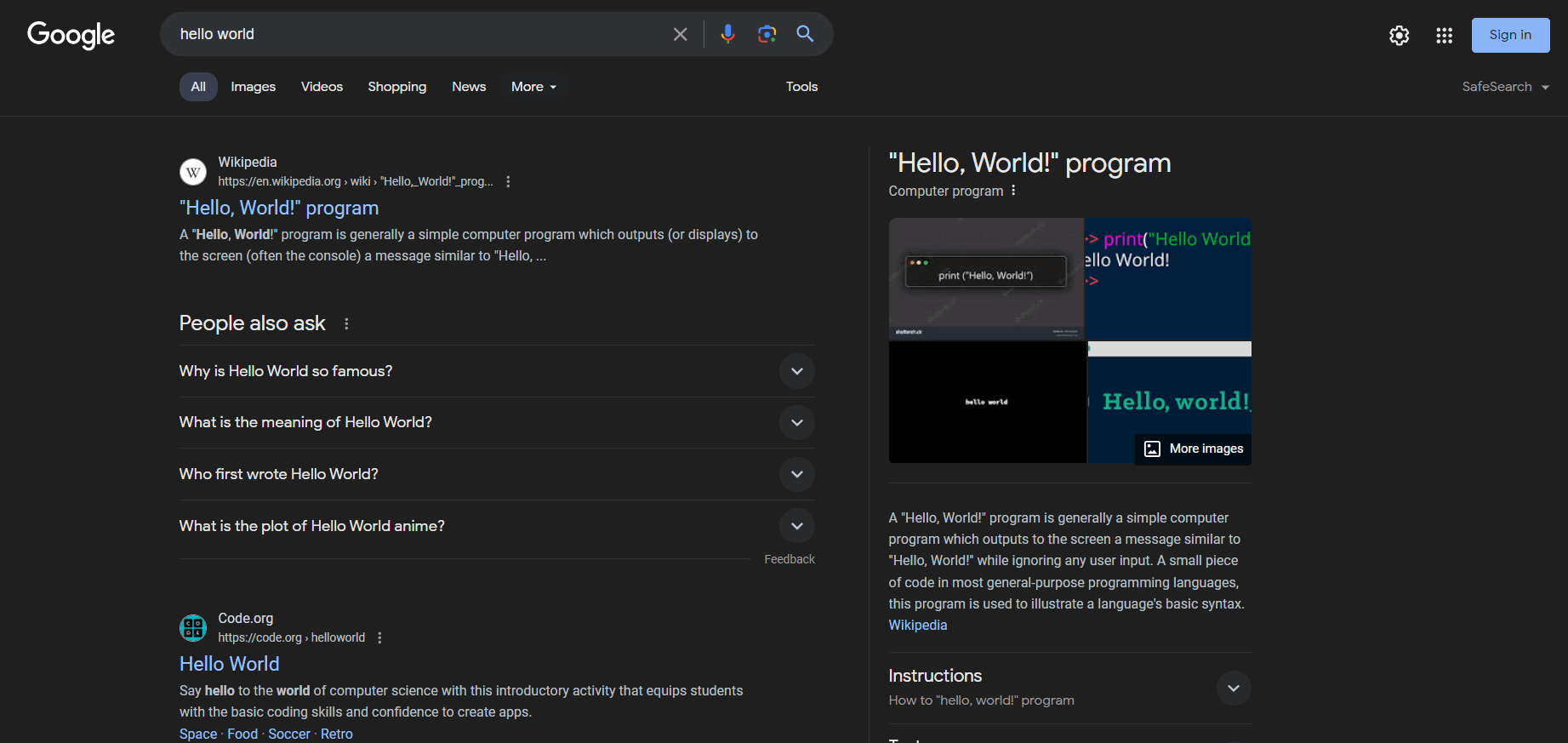
しかし、ユーザーや企業が通常関心を持つのはSERPデータです。SERP(Search Engine Results Page)とは、Googleなどの検索エンジンがユーザーのクエリに応答して返すページを指します。通常、検索エンジンが提案するウェブページへのリンクとテキスト説明を含むカードの一覧が表示されます。
SERPページの外観は以下の通りです:
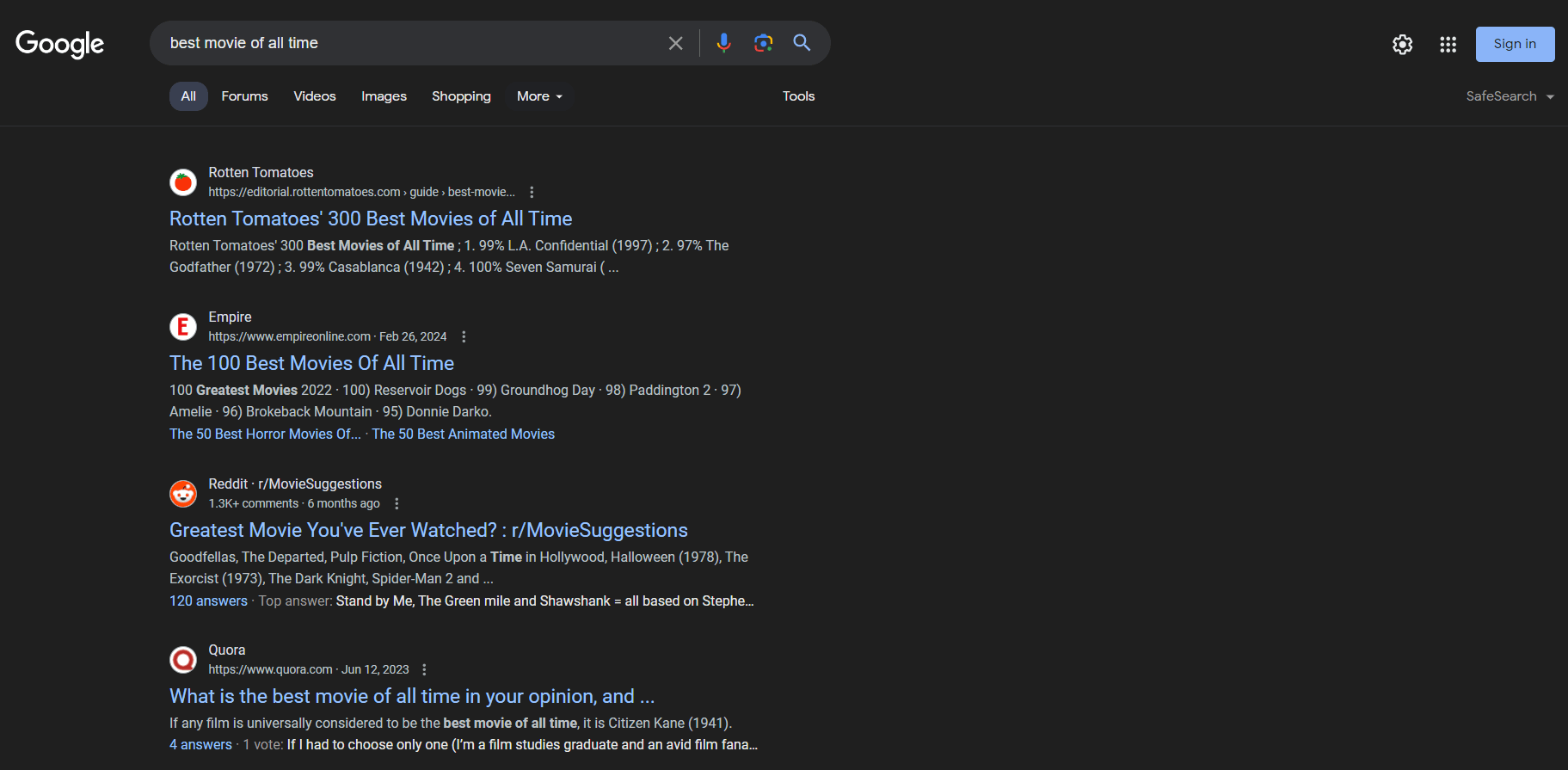
SERPデータは、企業が自社のオンライン可視性を理解し、競合を分析する上で極めて重要です。ユーザーの嗜好、キーワードのパフォーマンス、競合他社の戦略に関する洞察を提供します。SERPデータを分析することで、企業はコンテンツを最適化し、SEOランキングを向上させ、ユーザーのニーズをより良く満たすためのマーケティング戦略を調整できます。
以上から、SERPデータが非常に価値あるものであることは明らかです。あとは、そのデータを取得するための適切なツールの選び方を知るだけです。Pythonはウェブスクレイピングに最適なプログラミング言語の一つであり、この目的に完璧に適しています。しかし、手動でのスクレイピングに着手する前に、Google検索結果をスクレイピングするための最良かつ最速の選択肢、Bright DataのSERP APIについて見ていきましょう。
Bright DataのSERP APIのご紹介
手動スクレイピングガイドに進む前に、効率的かつシームレスなデータ収集のためにBright DataのSERP APIの活用をご検討ください。 SERP APIは、Google、Bing、DuckDuckGo、Yandex、Baidu、Yahoo、Naverを含む主要検索エンジンの検索結果へリアルタイムでアクセスします。この強力なツールは、Bright Dataの業界をリードするプロキシサービスと高度なボット対策ソリューションを基盤として構築されており、ウェブスクレイピングに通常伴う課題を排除し、信頼性と正確性を兼ね備えたデータ取得を保証します。
手動スクレイピングではなくBright DataのSERP APIを選ぶ理由
- リアルタイム結果と高精度:SERP APIはリアルタイムの検索エンジン結果を提供し、正確かつ最新のデータを保証します。都市レベルまでの位置精度により、世界中のどこにいても実際のユーザーが目にしているものと全く同じ結果を確認できます。
- 高度なボット対策ソリューション:ブロックやCAPTCHAの煩わしさは不要です。SERP APIには自動CAPTCHAの解決、ブラウザフィンガープリンティング、完全なプロキシ管理機能が組み込まれており、スムーズで中断のないデータ収集を保証します。
- カスタマイズ性と拡張性:APIは多様な検索パラメータに対応し、特定のニーズに合わせたクエリのカスタマイズを可能にします。大量処理を前提に設計されており、増加するトラフィックやピーク時にも容易に対応します。
- 使いやすさ:シンプルなAPI呼び出しで、構造化されたSERPデータをJSONまたはHTML形式で取得可能。既存システムやワークフローへの統合が容易です。応答時間は非常に速く、通常5秒未満です。
- コスト効率性:SERP APIの利用により運用コストを削減。成功したリクエストに対してのみ課金され、スクレイピングインフラの維持やサーバー問題への対応に投資する必要はありません。
今すぐ無料トライアルを開始し、Bright DataのSERP APIの効率性と信頼性を体感してください!
PythonでGoogle SERPスクレイパーを構築する
このステップバイステップチュートリアルに従い、PythonでGoogle SERPスクレイピングスクリプトを構築する方法をご覧ください。
ステップ1: プロジェクト設定
このガイドを実行するには、お使いのマシンにPython 3がインストールされている必要があります。インストールが必要な場合は、インストーラーをダウンロードし、起動してウィザードに従ってください。
これでPythonでGoogleをスクレイピングする準備が整いました!
以下のコマンドで仮想環境付きのPythonプロジェクトを作成します:
mkdir google-scraper
cd google-scraper
python -m venv envgoogle-スクレイパーがプロジェクトのルートディレクトリになります。
お気に入りのPython IDEでプロジェクトフォルダを開きます。PyCharm Community Editionや Python拡張機能付きのVisual Studio Codeが優れた選択肢です。
LinuxまたはmacOSでは、以下のコマンドで仮想環境をアクティブ化します:
./env/bin/activateWindowsの場合は代わりに以下を実行:
env/Scripts/activate一部のIDEは仮想環境を自動的に認識するため、手動でアクティベートする必要はありません。
プロジェクトフォルダ内に scraper.py ファイルを追加し、以下のように初期化します:
print("Hello, World!")これは「Hello, World!」メッセージを出力する単純なスクリプトですが、すぐにGoogleスクレイピングロジックが含まれるようになります。
IDEの「実行」ボタン、または以下のコマンドでスクリプトが意図した通りに動作することを確認してください:
python スクレイパー.pyスクリプトは以下を出力します:
Hello, World!よくできました!これでSERPスクレイピング用のPython環境が整いました。
PythonでGoogleをスクレイピングする前に、Pythonによるウェブスクレイピングのガイドを参照することをお勧めします。
ステップ2: スクラッピングライブラリのインストール
Googleからデータをスクレイピングするための適切なPythonライブラリをインストールします。いくつかの選択肢があり、最適な手法を選ぶには対象サイトの分析が必要です。ただし、対象はGoogleです。Googleの仕組みは周知の通りです。
Googleのボット対策技術を回避する検索URLを構築するのは複雑です。Googleがユーザー操作を要求することは周知の事実です。そのため、検索エンジンと対話する最も簡単かつ効果的な方法は、ブラウザを通じて実際のユーザーの動作をシミュレートすることです。
つまり、制御可能なブラウザ環境でウェブページをレンダリングするにはヘッドレスブラウザツールが必要です。Seleniumが最適です!
アクティブなPython仮想環境で、以下のコマンドを実行してseleniumパッケージをインストールします:
pip install seleniumセットアップには時間がかかる場合がありますので、お待ちください。
素晴らしい!これでプロジェクトの依存関係にSeleniumが追加されました。
ステップ3: Seleniumの設定
scraper.py に以下の行を追加して Selenium をインポートします:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import OptionsヘッドレスモードでChromeウィンドウを制御するChrome WebDriverインスタンスを以下のように初期化します:
# Chromeをヘッドレスモードで起動するためのオプション
options = Options()
options.add_argument('--headless') # ローカル開発時はコメントアウト
# 指定したオプションでWebDriverインスタンスを初期化
driver = webdriver.Chrome(
service=Service(),
options=options
)注:--headlessフラグは Chrome を GUI なしで起動します。スクリプトが Google ページ上で行う操作を確認したい場合は、このオプションをコメントアウトしてください。一般的に、ローカル開発時は--headlessフラグを無効にし、本番環境では有効にします。これは、GUI 付きで Chrome を実行すると多くのリソースを消費するためです。
スクリプトの最終行として、WebDriverインスタンスを閉じることを忘れないでください:
driver.quit()これでscraper.pyファイルの内容は以下のようになります:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Chromeをヘッドレスモードで起動するためのオプション
options = Options()
options.add_argument('--headless') # ローカル開発時はコメントアウト
# 指定したオプションでWebドライバーインスタンスを初期化
driver = webdriver.Chrome(
service=Service(),
options=options)
# スクラッピングロジック...
# ブラウザを閉じ、リソースを解放
driver.quit()素晴らしい!動的ウェブサイトのスクレイピングに必要なすべてが揃いました。
ステップ4: Googleにアクセス
PythonでGoogleをスクレイピングする最初のステップは、対象サイトへの接続です。ドライバーオブジェクトのget()関数を使用して、ChromeにGoogleホームページへのアクセスを指示します:
driver.get("https://google.com/")ここまでで、PythonによるSERPスクレイピングスクリプトは次のようになります:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# Chromeをヘッドレスモードで起動するためのオプション
options = Options()
options.add_argument('--headless') # ローカル開発時はコメントアウト
# 指定したオプションでWebDriverインスタンスを初期化
driver = webdriver.Chrome(
service=Service(),
options=options)
# 対象サイトに接続
driver.get("https://google.com/")
# スクラッピングロジック...
# ブラウザを閉じ、リソースを解放
driver.quit()スクリプトをヘッドレスモードで起動すると、quit()命令が終了処理を行う直前に、一瞬以下のブラウザウィンドウが表示されます:
EU(欧州連合)在住ユーザーの場合、Googleホームページには以下のGDPRポップアップも表示されます:
いずれの場合も、「Chromeは自動テストソフトウェアによって制御されています」というメッセージが表示され、Seleniumが意図した通りにChromeを制御していることを示しています。
素晴らしい!Seleniumが意図した通りにGoogleページを開きました。
注:GDPR関連でGoogleがクッキーポリシーダイアログを表示した場合、次の手順を実行してください。表示されない場合は手順6へスキップ可能です。
ステップ5: GDPRクッキーダイアログへの対応
以下のGoogle GDPRクッキーダイアログは、IPの所在地によって表示されるか否かが異なります。プロキシサーバーをSeleniumに統合し、希望する国の出口IPを選択することでこの問題を回避できます。
開発者ツールでクッキーダイアログのHTML要素を検査します:
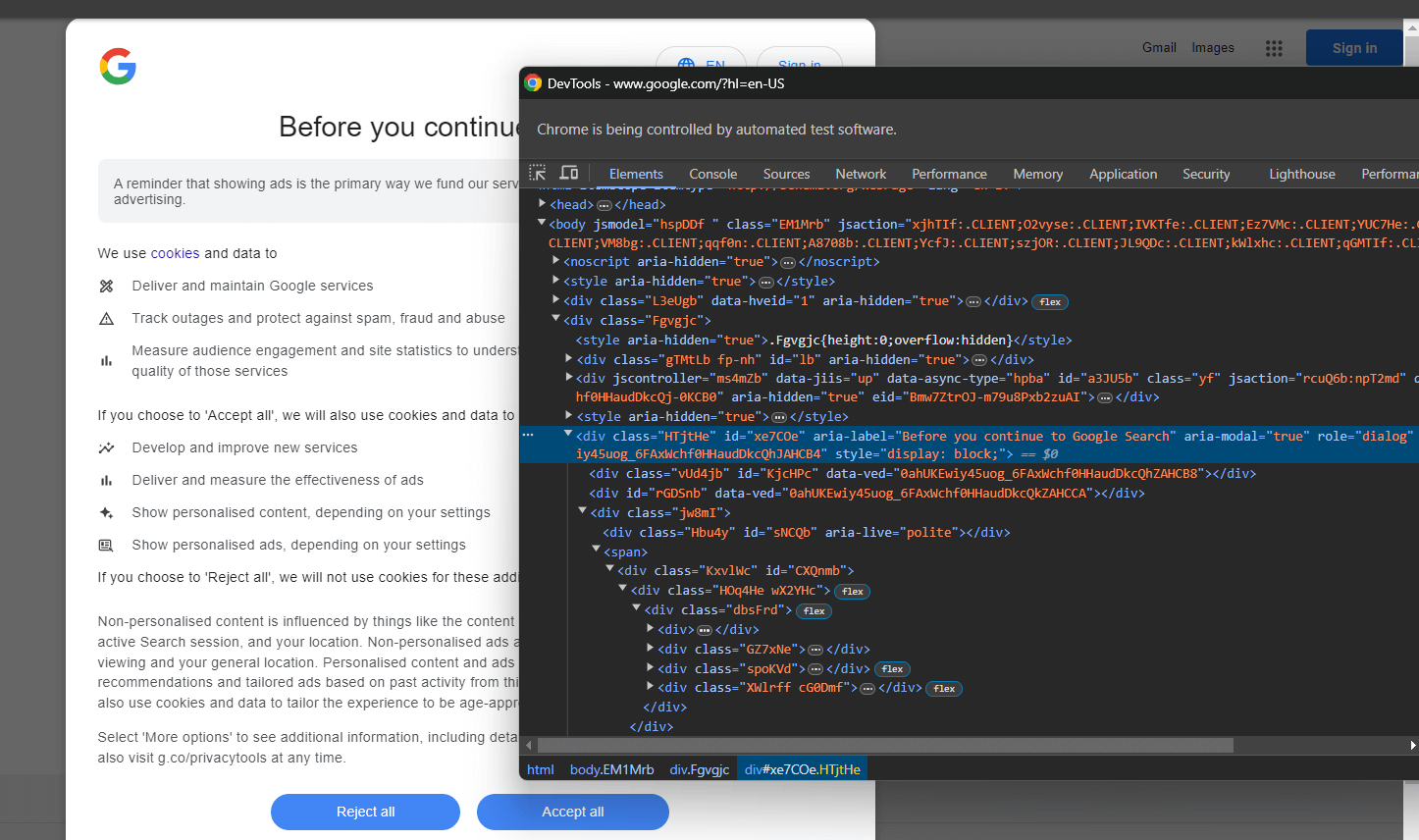
コードを展開すると、以下のCSSセレクタでこのHTML要素を選択できることがわかります:
[role='dialog']「すべて受け入れる」ボタンを検査すると、単純なCSS選択戦略では選択できないことがわかります:
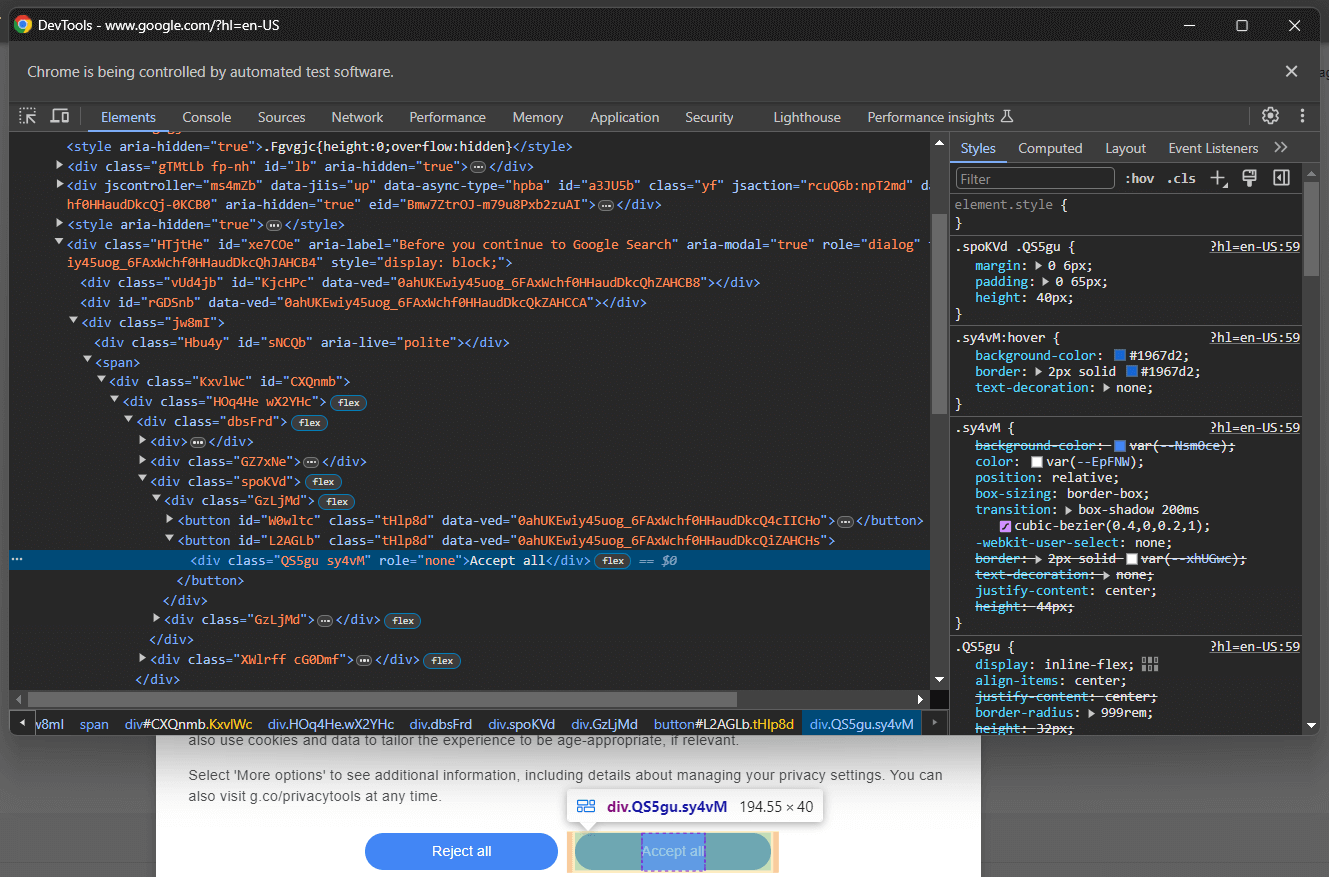
具体的には、HTMLコード内のCSSクラスはランダムに生成されているようです。ボタンを選択するには、クッキーダイアログ要素内の全ボタンを取得し、「Accept all」テキストを持つものを探します。クッキーダイアログ内の全ボタンを取得するCSSセレクタは次の通りです:
[role='dialog'] buttonfind_elements() SeleniumメソッドにCSSセレクタを渡してDOMに適用します。これにより、指定された戦略(この場合はCSSセレクタ)に基づいてページ上のHTML要素が選択されます:
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")上記が正しく動作するには、以下のインポートが必要です:
from selenium.webdriver.common.by import Bynext()を使用して「Accept all」ボタンを検索します。次に、それをクリックします:
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# 「Accept all」ボタンが存在する場合にクリック
if accept_all_button is not None:
accept_all_button.click()この指示は、ダイアログ内のテキストに「Accept all」という文字列を含む<button>要素を特定します。存在する場合、Seleniumのclick()メソッドを呼び出してクリックします。
素晴らしい!これでPythonでGoogle検索をシミュレートし、SERPデータを収集する準備が整いました。
ステップ6: Google検索のシミュレーション
ブラウザでGoogleを開き、開発者ツールで検索フォームを検査します:
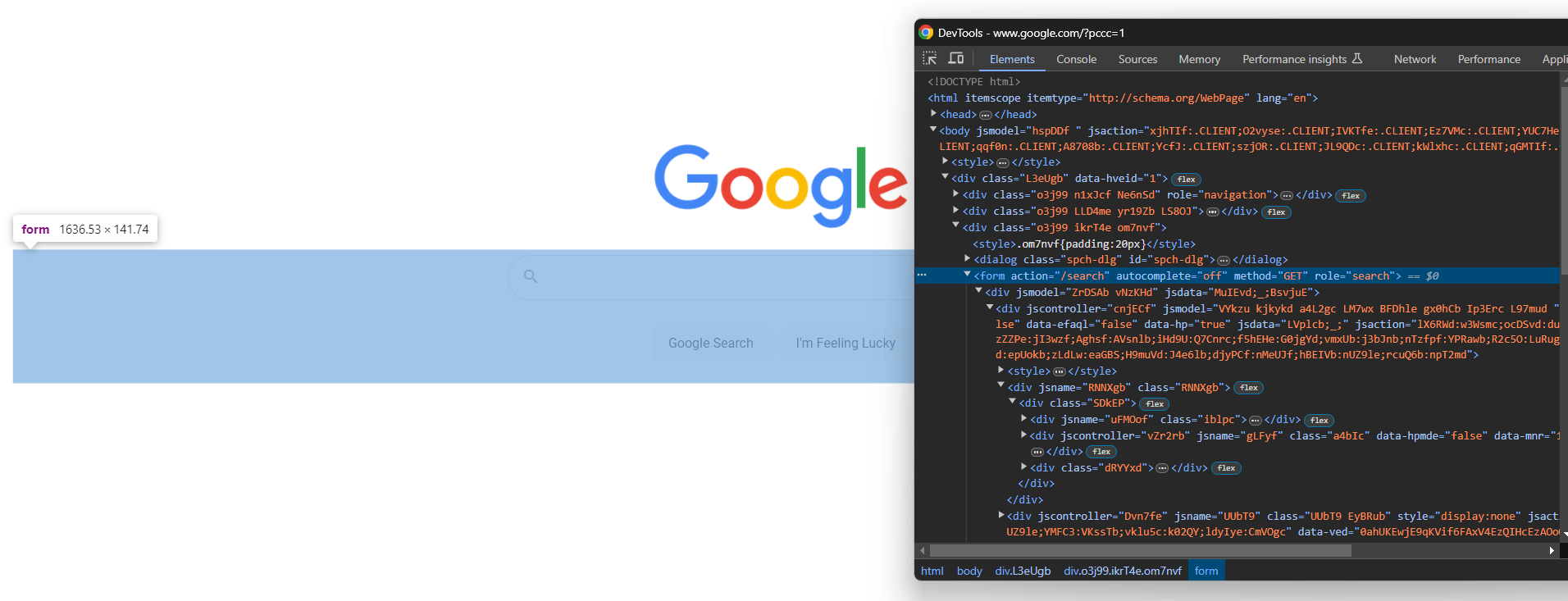
CSSクラスはランダムに生成されているように見えますが、このCSSセレクターでaction属性をターゲットにすることでフォームを選択できます:
form[action='/search']Seleniumでfind_element()メソッドを介してフォーム要素を取得するために適用します:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")ステップ5をスキップした場合、以下のインポートを追加する必要があります:
from selenium.webdriver.common.by import ByフォームのHTMLコードを展開し、検索テキストエリアに焦点を当てます:
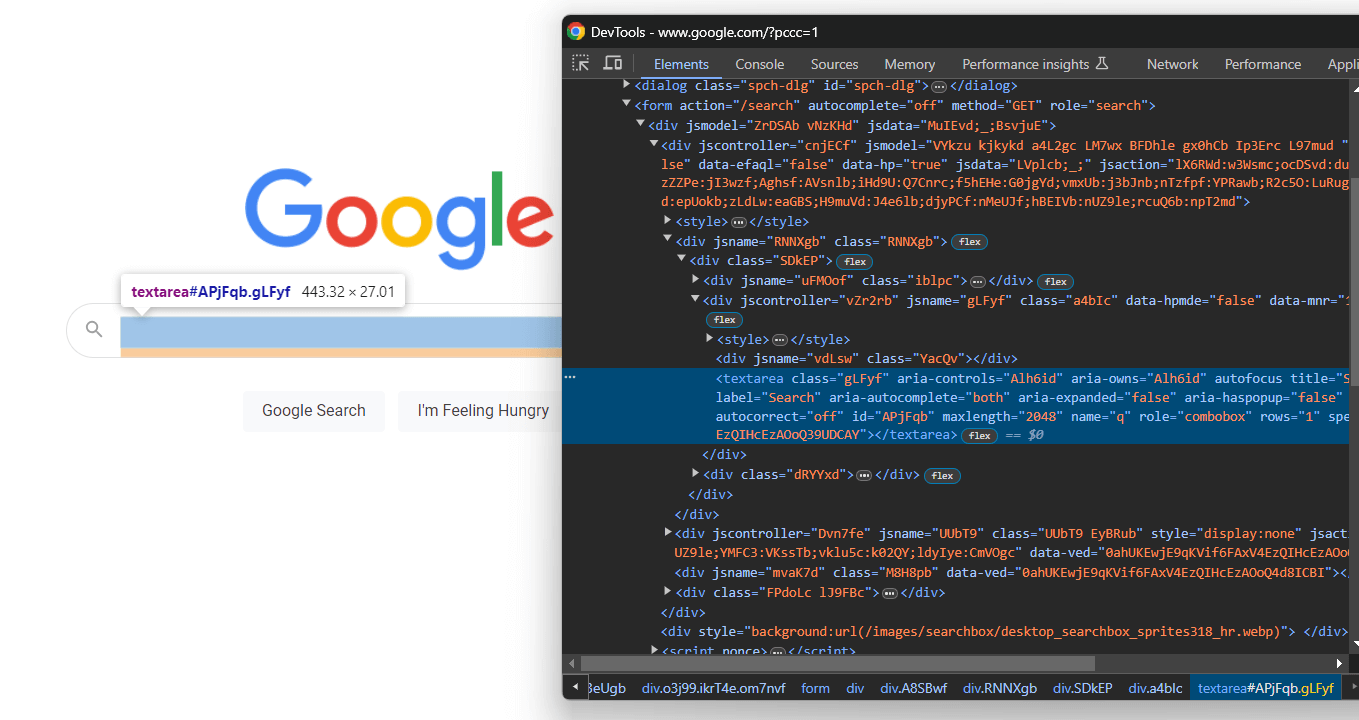
CSSクラスはランダム生成されますが、aria-label値をターゲットにすることで選択可能です:
textarea[aria-label='Search']したがって、フォーム内のテキストエリアを特定し、send_keys()ボタンを使用してGoogle検索クエリを入力します:
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)この場合、Googleのクエリは「bright data」になります。他のクエリでも問題ないことに留意してください。
次に、フォーム要素のsubmit()を呼び出してフォームを送信し、Google検索をシミュレートします:
search_form.submit()Googleは指定されたクエリに基づいて検索を実行し、目的の検索結果ページ(SERP)にリダイレクトします:
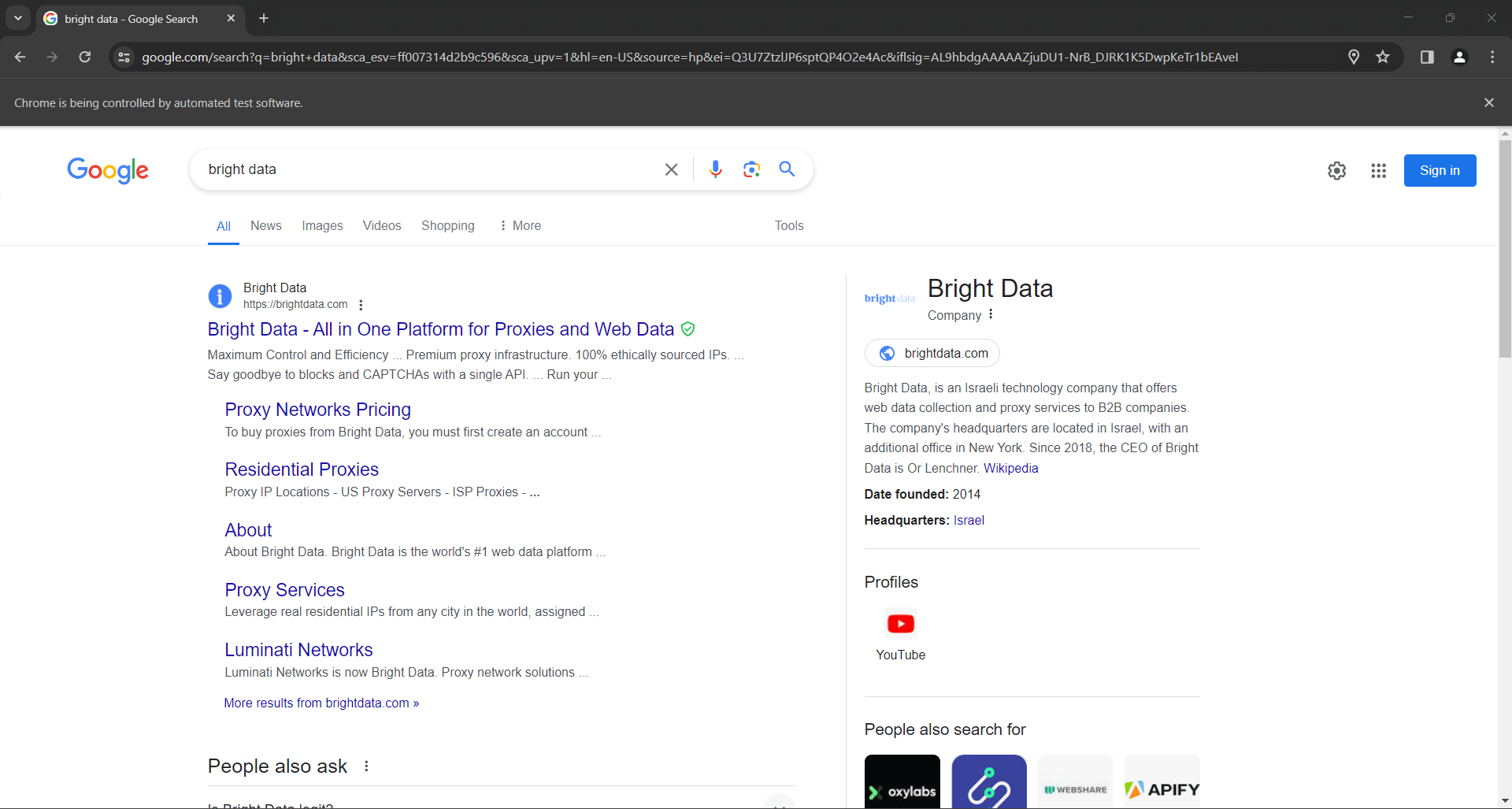
Seleniumを使用したPythonでのGoogle検索シミュレーションのコードは以下の通りです:
# Google検索フォームを選択
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# フォーム内のテキストエリアを選択
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# テキストエリアに指定のクエリを入力
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# フォームを送信しGoogle検索を実行
search_form.submit()さあ始めましょう!PythonでGoogleをスクレイピングしてSERPデータを取得する準備を整えましょう。
ステップ7: 検索結果要素の選択
結果セクションの右側カラムを調査します:
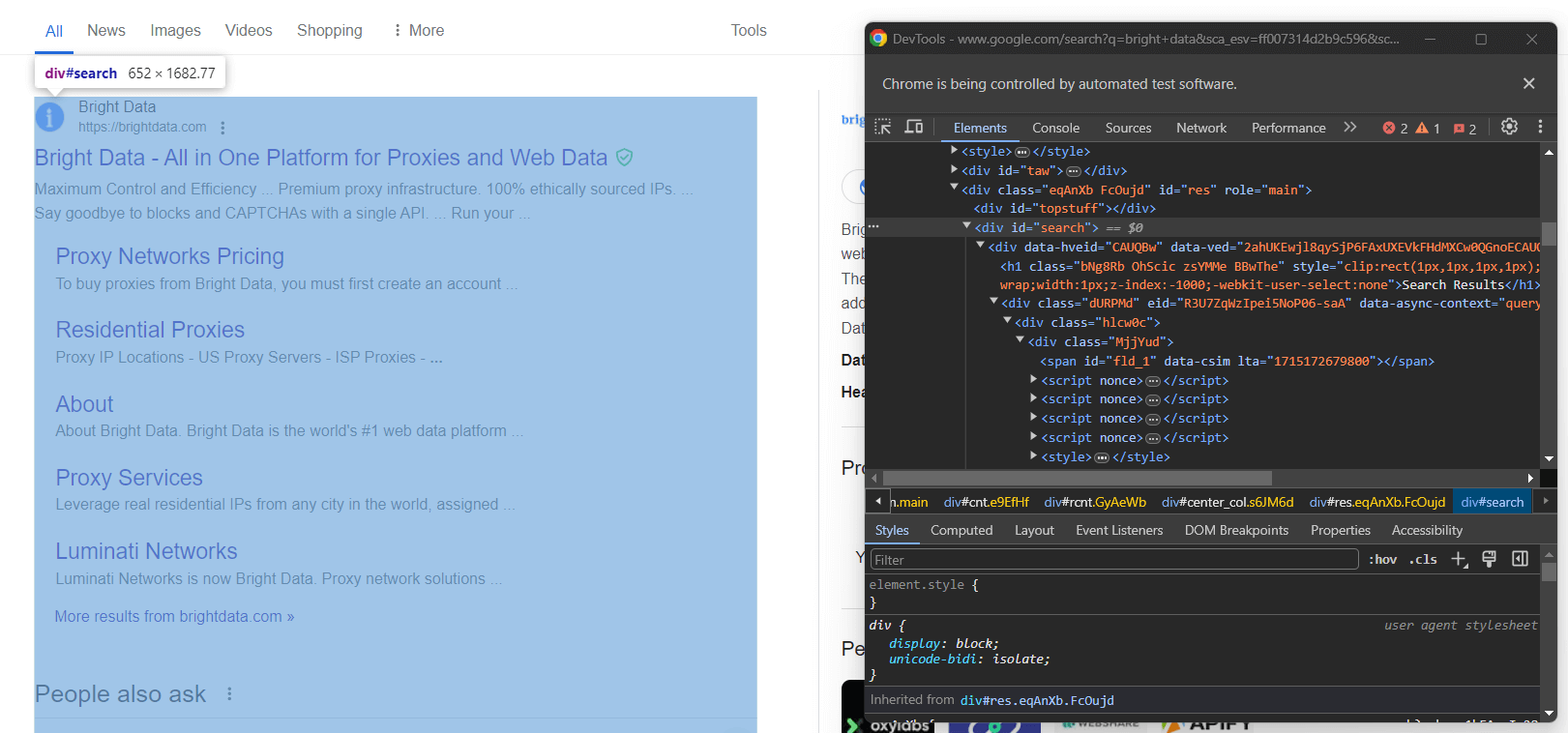
ご覧の通り、これは以下のCSSセレクタで選択可能な<div>要素です:
#searchGoogleのページは動的に生成されることを忘れないでください。そのため、この要素がページ上に存在するのを確認してから操作する必要があります。以下の行で実現します:
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))WebDriverWaitは、明示的な待機を実装するためにSeleniumが提供する特別なクラスです。特に、ページ上で特定のイベントが発生するまで待機することを可能にします。
この場合、スクリプトは#searchHTMLノードがページ上に存在するまで最大10秒待機します。これにより、Google検索結果ページが意図した通りに読み込まれることを保証できます。
WebDriverWaitを使用するには追加のインポートが必要です。スクレイパー.py に以下を追加してください:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC次に、Google検索要素を検査します:
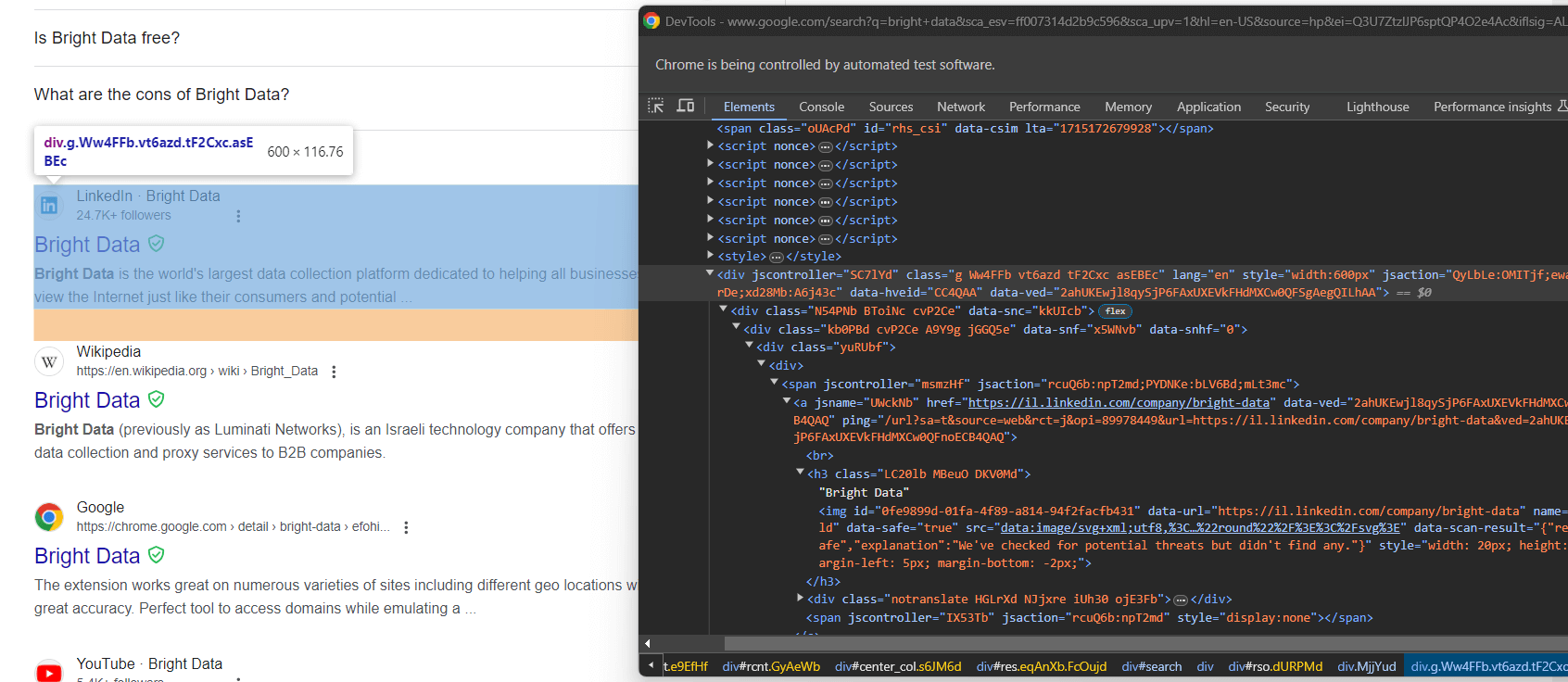
繰り返しになりますが、CSSクラスによる選択は適切な手法ではありません。代わりに、特徴的なHTML属性に注目してください。Google検索要素を取得するための適切なCSSセレクタは次の通りです:
div[jscontroller][lang][jsaction][data-hveid][data-ved]これはjscontroller、lang、jsaction、data-hveid、data-ved属性を全て持つ<div>を特定します。
Selenium経由でPythonから全てのGoogle検索要素を選択するには、find_elements()にこのセレクタを渡します:
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")全体のロジックは以下の通りです:
# ページ上に検索用div要素が表示されるまで最大10秒待機
# 表示されたら選択
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# SERP内のGoogle検索要素を選択
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")素晴らしい!PythonでSERPデータをスクレイピングするまであと一歩です。
ステップ8: SERPデータの抽出
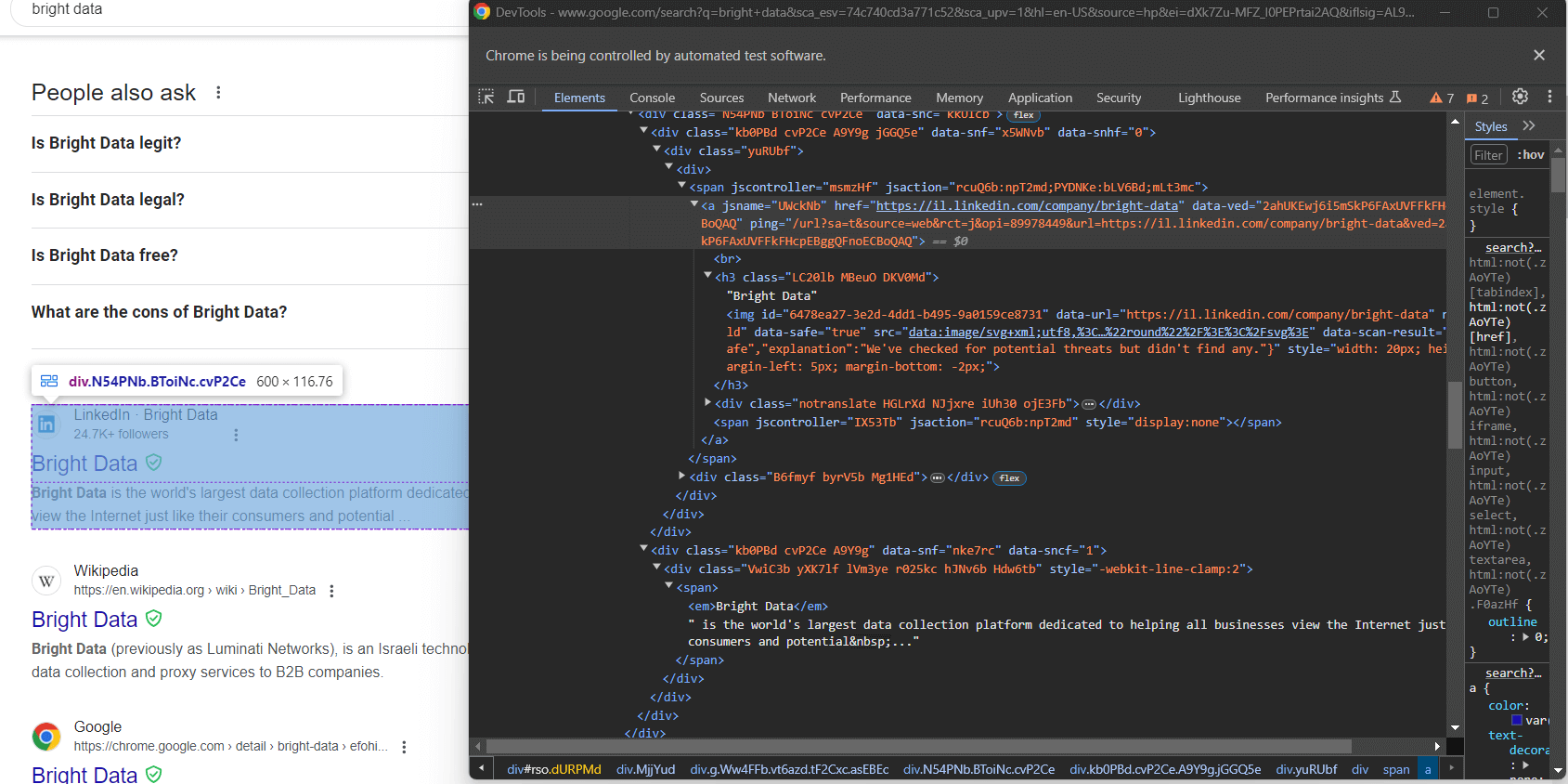
GoogleのSERPは全て同じ構造ではありません。場合によっては、ページ上の最初の検索結果が他の検索結果要素とは異なるHTMLコードを持っていることがあります:
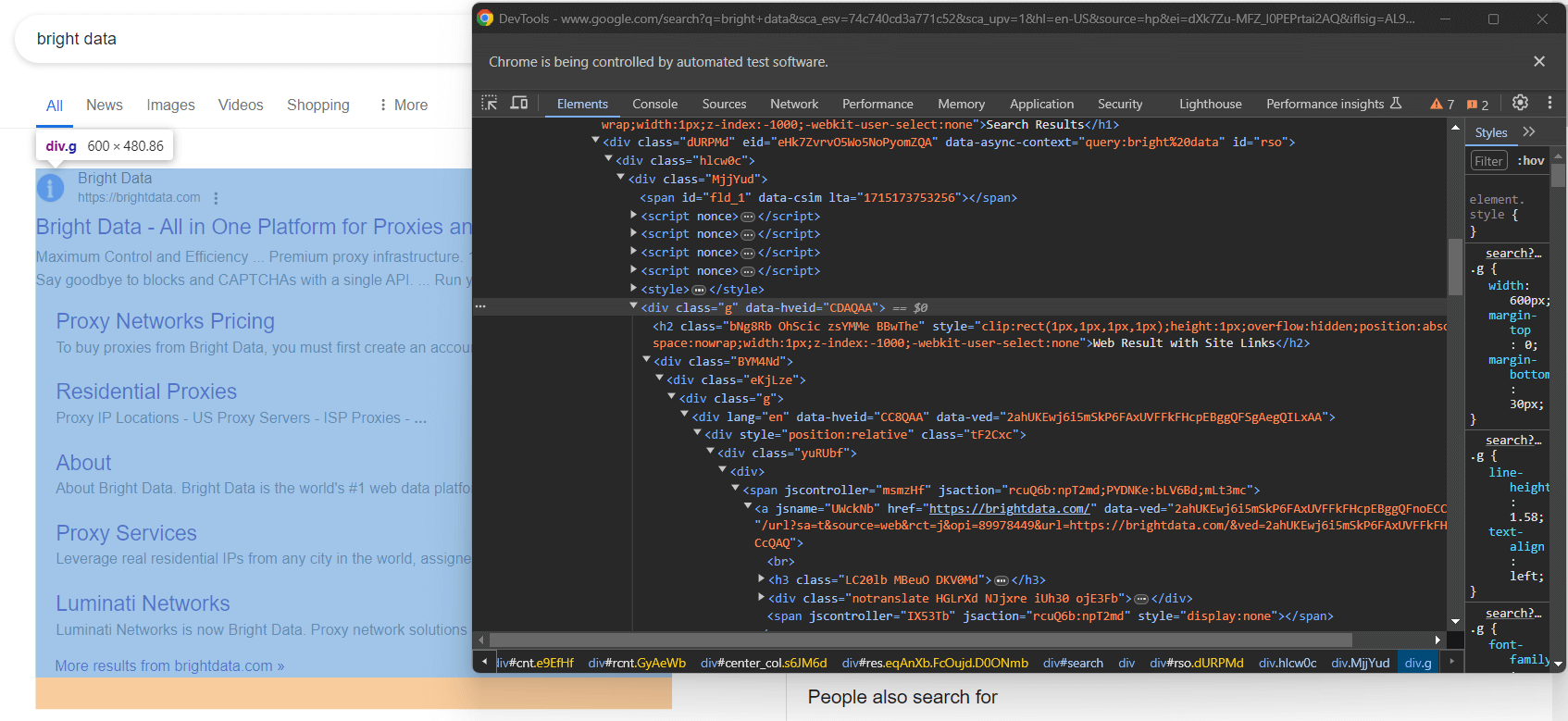
例えば、このケースでは、最初の検索結果要素は次のCSSセレクタで取得できます:
div.g[data-hveid]それ以外では、Googleの検索結果要素に含まれる内容はほぼ同じです。これには以下が含まれます:
<h3>ノード内のページタイトル- 上記の
<h3>要素の親となる<a>要素内の特定ページへのURL。 [data-sncf='1'] <div>内の説明文。
単一のSERPには複数の検索結果が含まれるため、スクレイピングしたデータを格納する配列を初期化します:
serp_elements = []また、ページ上での順位を追跡するための整数ランクも必要です:
rank = 1PythonでGoogle検索結果要素をスクレイピングする関数を以下のように定義します:
def scrape_search_element(search_element, rank):
# 検索要素内の対象要素を選択し、
# 存在しない要素は無視して
# データ抽出ロジックを適用
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# "h3"の子要素を持つ"a"要素を取得
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# 新しいSERPデータ要素を返す
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}GoogleはSERPページを頻繁に変更する傾向があります。検索要素内のノードが消失する可能性があるため、try ... catch文で保護する必要があります。具体的には、要素がDOM上に存在しない場合、find_element() はNoSuchElementException例外を発生させます。
例外をインポート:
from selenium.common import NoSuchElementException特定の子要素を持つノードを選択するためにhas()CSS演算子を使用している点に注意してください。詳細は公式ドキュメントを参照してください。
次に、最初の検索要素と残りの要素をscrape_search_element()関数に渡します。その後、返されたオブジェクトをserp_elements配列に追加します:
# SERP上の最初の要素からデータをスクレイピング
# (存在する場合)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# SERP上の全検索要素からデータをスクレイピング
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1これらの処理の終了時、serp_elementsには対象のSERPデータが全て格納されます。ターミナルで出力して確認してください:
print(serp_elements)すると以下のような出力が得られます:
[
{'rank': 1, 'url': 'https://brightdata.com/', 'title': 'Bright Data - All in One Platform for プロキシとWebデータ', 'description': None},
{'rank': 2, 'url': 'https://il.linkedin.com/company/bright-data', 'title': 'Bright Data', 'description': "Bright Data is the world's largest data collection platform dedicated to helping all businesses view the Internet just like their consumers and potential..."},
# 省略...
{'rank': 6, 'url': 'https://aws.amazon.com/marketplace/seller-profile?id=bf9b4324-6ee3-4eb3-9ca4-083e558d04c4', 'title': 'Bright Data - AWS Marketplace', 'description': 'Bright Dataは主要なデータ収集プラットフォームであり、顧客が数百万のウェブサイトから構造化および非構造化データセットを収集することを可能にします...'},
{'rank': 7, 'url': 'https://techcrunch.com/2024/02/26/meta-drops-lawsuit-against-ウェブスクレイピング企業 Bright Data ...', 'title': 'Meta drops lawsuit againstウェブスクレイピング企業 Bright Data ...', 'description': '2024年2月26日 — メタは、数週間前に訴訟の主要な主張で敗訴した後、イスラエルのウェブスクレイピング企業ブライトデータに対する訴訟を取り下げた。'}
]素晴らしい!あとはスクレイピングしたデータをCSVにエクスポートするだけです。
ステップ9: スクレイピングしたデータをCSVにエクスポート
PythonでGoogleをスクレイピングする方法がわかったところで、取得したデータをCSVファイルにエクスポートする方法を見てみましょう。
まず、Python標準ライブラリのcsvパッケージをインポートします:
import csv次に、csvパッケージを使用してSERPデータを出力ファイルserp_data.csvに格納します:
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)これで完成です!Google Pythonスクレイピングスクリプトの準備が整いました。
ステップ10: 全てを統合する
これが最終的なscraper.pyスクリプトのコードです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import NoSuchElementException
import csv
def scrape_search_element(search_element, rank):
# 検索要素内の対象要素を選択し、
# 欠落している要素は無視して、
# データ抽出ロジックを適用
try:
title_h3 = search_element.find_element(By.CSS_SELECTOR, "h3")
title = title_h3.get_attribute("innerText")
except NoSuchElementException:
title = None
try:
# "h3"の子要素を持つ"a"要素を取得
url_a = search_element.find_element(By.CSS_SELECTOR, "a:has(> h3)")
url = url_a.get_attribute("href")
except NoSuchElementException:
url = None
try:
description_div = search_element.find_element(By.CSS_SELECTOR, "[data-sncf='1']")
description = description_div.get_attribute("innerText")
except NoSuchElementException:
description = None
# 新しいSERPデータ要素を返す
return {
'rank': rank,
'url': url,
'title': title,
'description': description
}
# Chromeをヘッドレスモードで起動するためのオプション
options = Options()
options.add_argument('--headless') # ローカル開発時はコメントアウト
# 指定されたオプションでWebDriverインスタンスを初期化
driver = webdriver.Chrome(
service=Service(),
options=options)
# ターゲットサイトに接続
driver.get("https://google.com/?hl=en-US")
# クッキーダイアログ内のボタンを選択
buttons = driver.find_elements(By.CSS_SELECTOR, "[role='dialog'] button")
accept_all_button = next((b for b in buttons if "Accept all" in b.get_attribute("innerText")), None)
# 「Accept all」ボタンが存在する場合、クリック
if accept_all_button is not None:
accept_all_button.click()
# Google検索フォームを選択
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# フォーム内のテキストエリアを選択
search_form_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
# テキストエリアに指定のクエリを入力
google_search_query = "bright data"
search_form_textarea.send_keys(google_search_query)
# フォームを送信しGoogle検索を実行
search_form.submit()
# 検索結果divがページに表示されるまで最大10秒待機
# 表示後に選択
search_div = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, '#search')))
# SERP内のGoogle検索要素を選択
google_search_elements = search_div.find_elements(By.CSS_SELECTOR, "div[jscontroller][lang][jsaction][data-hveid][data-ved]")
# スクレイピングしたデータの保存先
serp_elements = []
# 現在のランキングを追跡するため
rank = 1
# SERP上の最初の要素からデータをスクレイピング
# (存在する場合)
try:
first_search_element = driver.find_element(By.CSS_SELECTOR, "div.g[data-hveid]")
serp_elements.append(scrape_search_element(first_search_element, rank))
rank += 1
except NoSuchElementException:
pass
# SERP上の全検索要素からデータをスクレイピング
for google_search_element in google_search_elements:
serp_elements.append(scrape_search_element(google_search_element, rank))
rank += 1
# スクレイピングしたデータをCSVにエクスポート
header = ["rank", "url", "title", "description"]
with open("serp_data.csv", 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(serp_elements)
# ブラウザを終了しリソースを解放
driver.quit()すごい!わずか100行強のコードで、PythonによるGoogle SERPスクレイパーを構築できます。
IDEで実行するか、以下のコマンドで期待通りの結果が得られることを確認してください:
python スクレイパー.pyスクレイパーの実行が終了すると、プロジェクトのルートフォルダにserp_results.csvファイルが生成されます。開くと以下が表示されます:

おめでとうございます!PythonでGoogleスクレイピングを実行できました。
まとめ
このチュートリアルでは、Googleから収集可能なデータの種類と、SERPデータが最も有用な理由を確認しました。特に、Seleniumを用いたPythonでのSERPスクレイパー構築にブラウザ自動化を活用する方法を学びました。
単純な例では機能しますが、PythonでGoogleをスクレイピングする際には主に3つの課題があります:
- GoogleはSERPのページ構造を頻繁に変更します。
- Googleは市場で最も高度なボット対策ソリューションをいくつか備えています。
- 大量のSERPデータを並列で取得できる効果的なスクレイピングプロセスを構築するのは複雑で、多額の費用がかかります。
Bright DataのSERP APIを使えば、これらの課題を忘れてください。この次世代APIは、主要な検索エンジンすべてからリアルタイムのSERPデータを公開する一連のエンドポイントを提供します。SERP APIは、Bright Dataの最高水準のプロキシサービスとボット対策バイパスソリューションを基盤としており、手間をかけずに複数の検索エンジンを対象としています。
SERP APIを利用すれば、シンプルなAPI呼び出しでJSONまたはHTML形式のSERPデータを取得可能。今すぐ無料トライアルを開始しましょう!





