

このガイドでは以下の内容を学びます:
- – サイトが複雑なナビゲーション構造を持つ場合の識別方法
- – こうした状況に対応する最適なスクレイピングツール
- 一般的な複雑なナビゲーションパターンのスクレイピング方法
さっそく見ていきましょう!
サイトが複雑なナビゲーションを持つのはいつ?
複雑なナビゲーションを持つサイトは、開発者が直面する一般的なウェブスクレイピングの課題です。しかし「複雑なナビゲーション」とは具体的に何を指すのでしょうか?ウェブスクレイピングにおいて、複雑なナビゲーションとは、コンテンツやページへのアクセスが容易でないウェブサイト構造を指します。
複雑なナビゲーションのシナリオには、動的要素、非同期データ読み込み、ユーザー主導のインタラクションが頻繁に含まれます。これらの要素はユーザー体験を向上させる一方で、データ抽出プロセスを著しく複雑化させます。
複雑なナビゲーションを理解する最良の方法は、具体例を考察することです:
- JavaScriptでレンダリングされるナビゲーション:React、Vue.js、AngularなどのJavaScriptフレームワークに依存し、ブラウザ内で直接コンテンツを生成するウェブサイト。
- ページネーションされたコンテンツ:データが複数ページに分散しているサイト。AJAXを介してページネーションが数値的に読み込まれる場合、後続ページへのアクセスが困難になり、複雑さが増します。
- 無限スクロール:ユーザーがスクロールすると動的に追加コンテンツが読み込まれるページ。ソーシャルメディアのフィードやニュースサイトでよく見られる。
- 多階層メニュー:ネストされたメニュー構造を持ち、深い階層のナビゲーションを表示するために複数回のクリックやホバー操作を必要とするサイト(例:大規模ECプラットフォームの商品カテゴリツリー)。
- インタラクティブマップインターフェース:地図やグラフ上に情報を表示するウェブサイト。ユーザーがパンやズーム操作を行うとデータポイントが動的に読み込まれる。
- タブまたはアコーディオン:コンテンツが動的にレンダリングされるタブや折りたたみ可能なアコーディオンの下に隠されており、そのコンテンツがサーバーから返されるHTMLページに直接埋め込まれていないページ。
- 動的フィルタリングとソート機能:複雑なフィルタリングシステムを備えたサイト。複数のフィルタを適用すると、URL構造を変更せずにアイテムリストが動的に再読み込みされる。
複雑なナビゲーションサイトに対応する最適なスクレイピングツール
複雑なナビゲーションを持つサイトを効果的にスクレイピングするには、必要なツールを理解する必要があります。この作業自体は本質的に困難であり、適切なスクレイピングライブラリを使用しないとさらに困難になります。
上記の複雑なインタラクションの多くに共通する特徴は以下の通りです:
- 何らかのユーザー操作を必要とする、または
- ブラウザ内のクライアントサイドで実行される
つまり、これらのタスクにはJavaScriptの実行が必要であり、これはブラウザのみが実行可能です。したがって、このようなページに対しては単純なHTMLパーサーに依存できません。代わりに、Selenium、Playwright、Puppeteerなどのブラウザ自動化ツールを使用する必要があります。
これらのソリューションでは、ブラウザにプログラムで指示を出し、ウェブページ上で特定のアクションを実行させ、ユーザー操作を模倣できます。これらはグラフィカルインターフェースなしでブラウザをレンダリングできるため、システムリソースを節約する「ヘッドレスブラウザ」と呼ばれることが多いです。
ウェブスクレイピングに最適なヘッドレスブラウザツールを発見しましょう。
一般的な複雑なナビゲーションパターンのスクレイピング方法
このチュートリアルセクションでは、PythonでSeleniumを使用します。ただし、このロジックはPlaywright、Puppeteer、その他のブラウザ自動化ツールにも容易に適用できます。また、Seleniumを使用したウェブスクレイピングの基本を既にご存知であることを前提とします。
具体的には、以下の一般的な複雑なナビゲーションパターンのスクレイピング方法を解説します:
- 動的ページネーション:AJAX経由で動的に読み込まれるページネーション付きデータを持つサイト
- 「さらに読み込む」ボタン: JavaScriptベースの一般的なナビゲーション例。
- 無限スクロール:ユーザーがスクロールダウンするにつれて継続的にデータをロードするページ。
さあ、コーディングを始めましょう!
動的ページネーション
この例のターゲットページは「アカデミー賞受賞作品:AJAXとJavaScript」スクレイピングサンドボックスです:
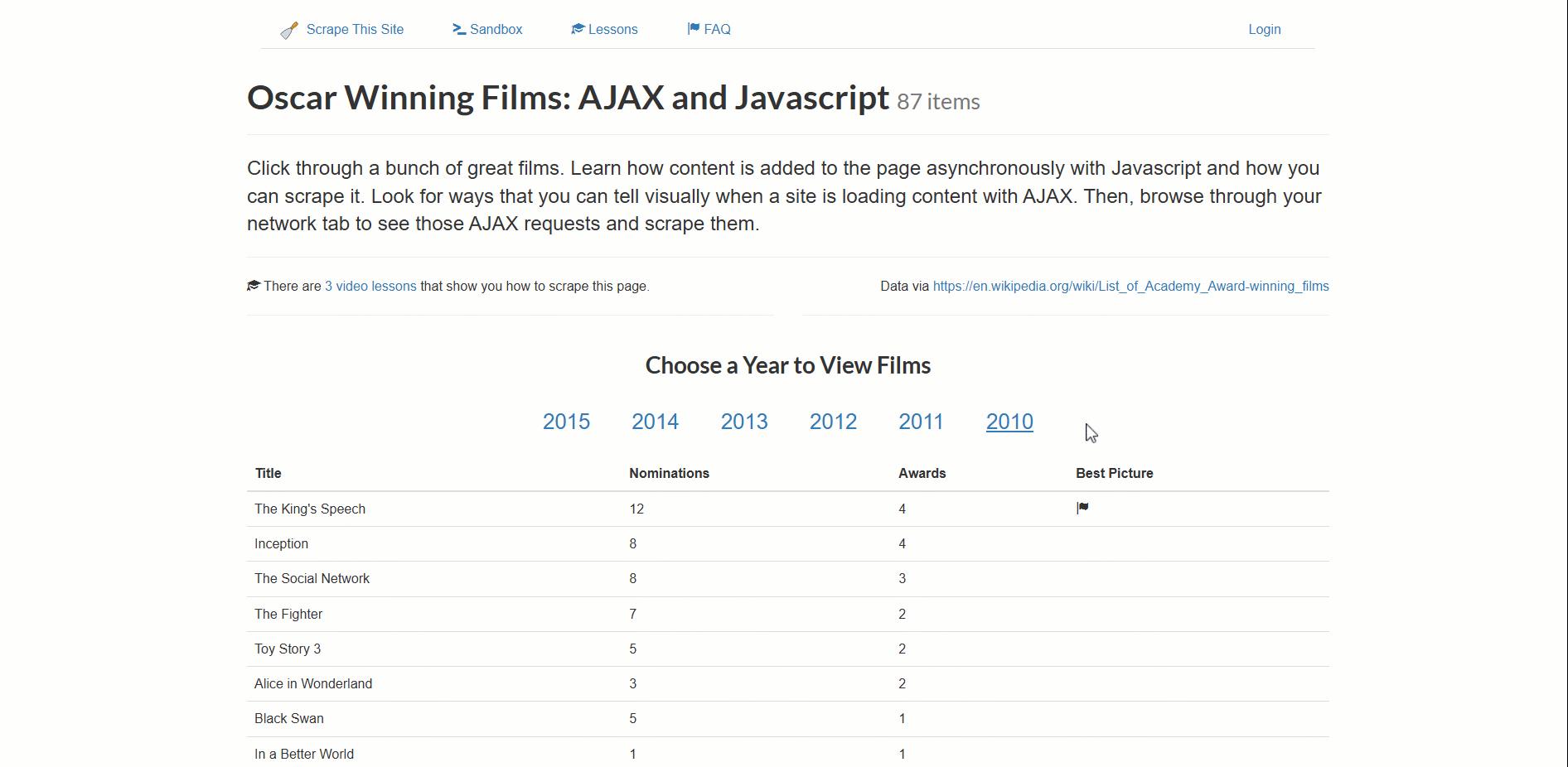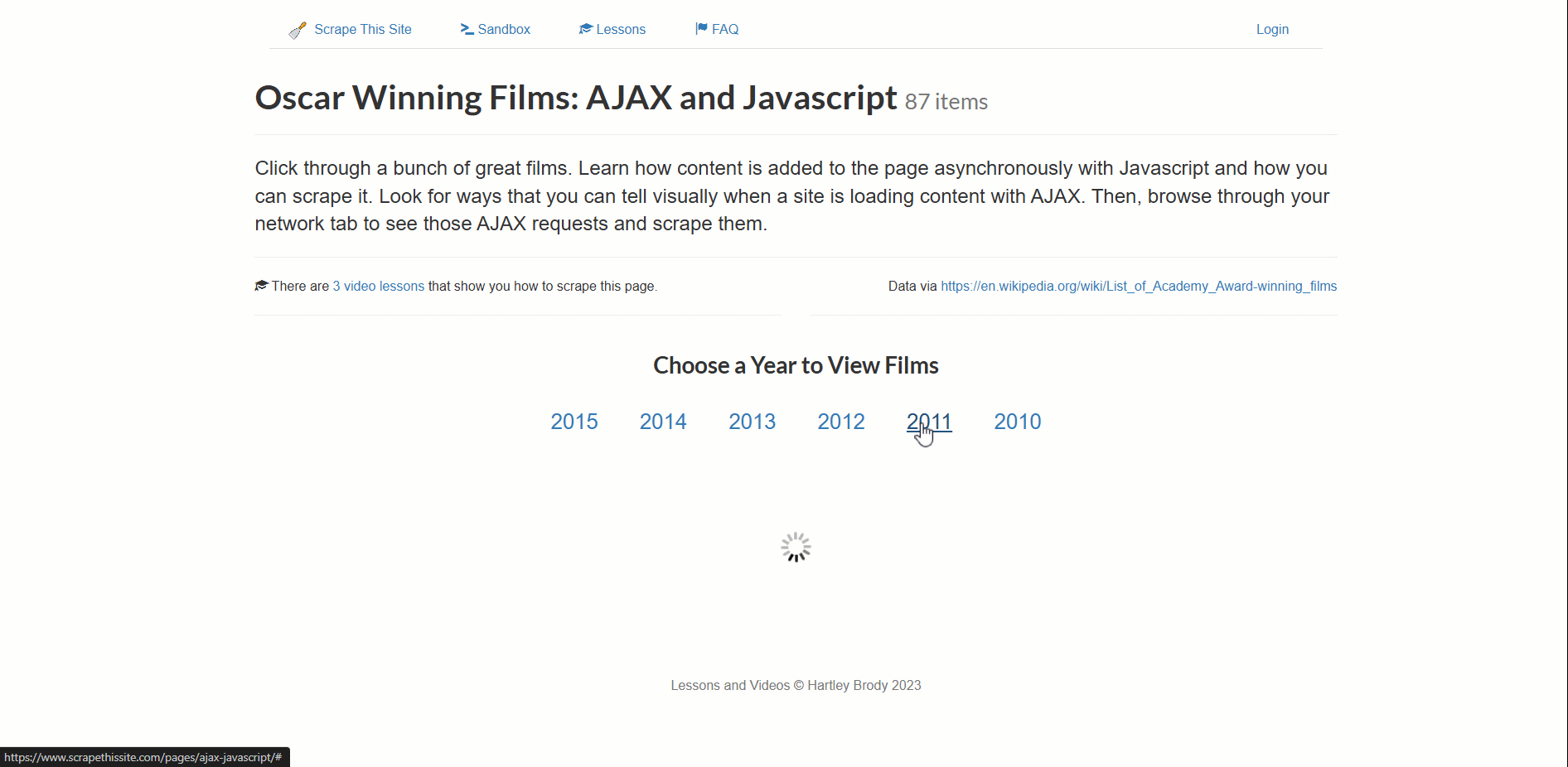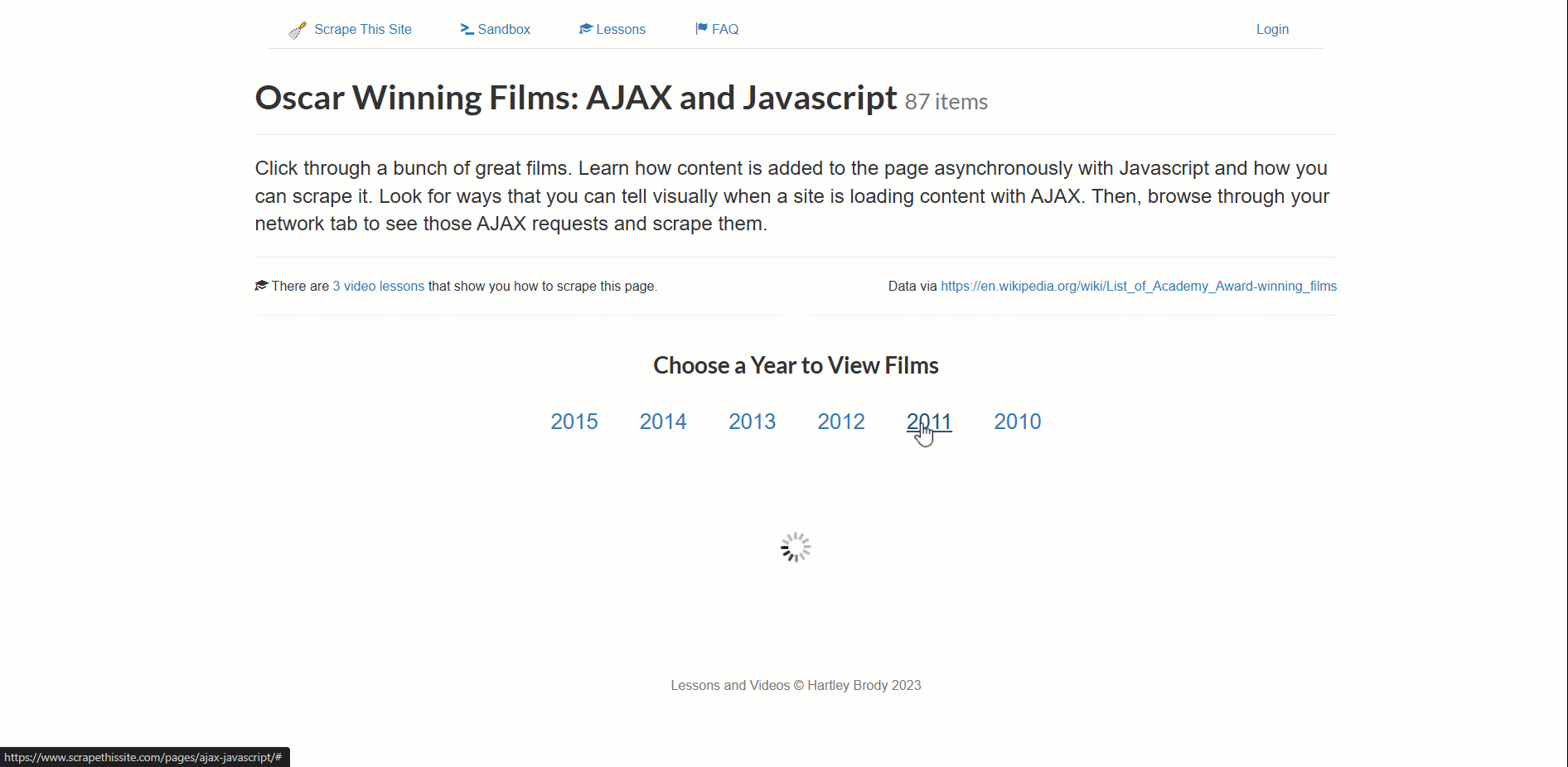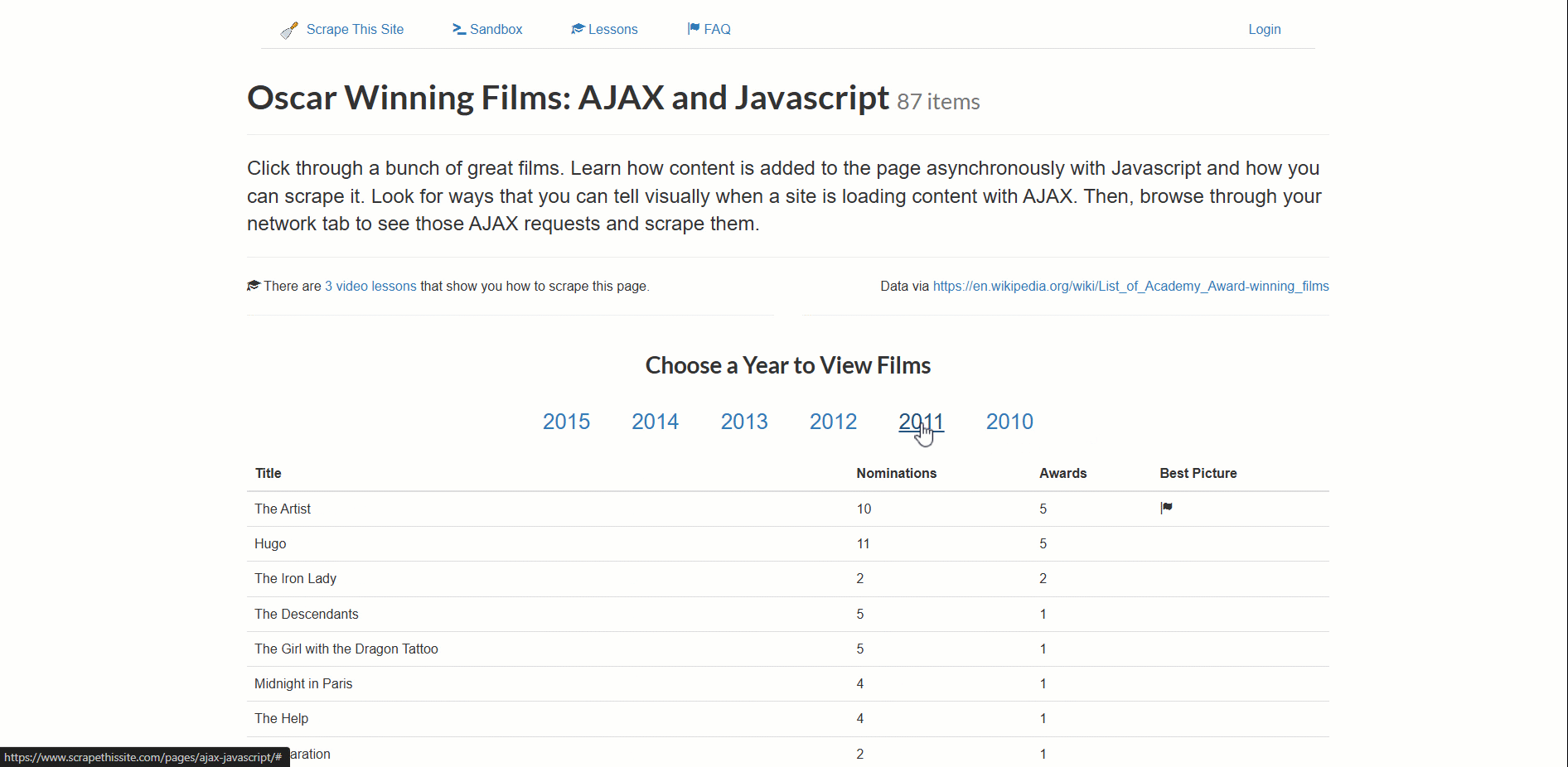
このサイトはアカデミー賞受賞作品データを動的に読み込み、年別にページネーションしています。
このような複雑なナビゲーションを処理するため、以下のアプローチを採用します:
- 新しい年をクリックしてデータ読み込みをトリガー(ローダー要素が表示されます)。
- ローダー要素が消えるのを待つ(データが完全に読み込まれた状態)。
- データを含むテーブルがページ上で正しくレンダリングされていることを確認する。
- データが利用可能になったらスクレイピングする。
詳細な実装方法(PythonのSelenium使用)は以下の通りです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# ヘッドレスモード用のChromeオプション設定
options = Options()
options.add_argument("--headless")
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service(), options=options)
# 対象ページへの接続
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# 「2012」ページネーションボタンをクリック
element = driver.find_element(By.ID, "2012")
element.click()
# ローダーが表示されなくなるまで待機
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;")
# データが読み込まれた状態...
# ページ上にテーブルが表示されるまで待機
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table")))
# スクレイピングしたデータの保存先
films = []
# テーブルからデータをスクレイピング
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# スクレイピングしたデータを保存
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# データエクスポートロジック...
# ブラウザドライバーを閉じる
driver.quit()
上記コードの解説:
- コードはヘッドレスChromeインスタンスを設定します。
- スクリプトは対象ページを開き、「2012」のページネーションボタンをクリックしてデータ読み込みをトリガーします。
- Selenium
はWebDriverWait()を使用してローダーが消えるのを待機します。 - ローダーが消えた後、スクリプトはテーブルが表示されるのを待機します。
- データが完全に読み込まれた後、スクリプトは映画タイトル、ノミネート作品、受賞作品、およびその映画が最優秀作品賞を受賞したかどうかをスクレイピングします。このデータを辞書のリストに保存します。
結果は次のようになります:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]
このナビゲーションパターンを処理する最適な方法は必ずしも一つとは限りません。ページの動作に応じて他の選択肢が必要になる場合があります。例としては:
- 特定のHTML要素の出現または消失を待機するために、
WebDriverWait()と期待される条件を組み合わせて使用します。 - AJAXリクエストのトラフィックを監視し、新規コンテンツが取得されたタイミングを検出する。これにはブラウザのログ記録の使用が含まれる可能性がある。
- ページネーションによってトリガーされるAPIリクエストを特定し、プログラムでデータを取得するための直接リクエストを実行する(例:
requestsライブラリを使用)。
「さらに読み込む」ボタン
ユーザー操作を伴うJavaScriptベースの複雑なナビゲーションシナリオを表現するため、「Load More」ボタン例を選択しました。概念は単純です:アイテムリストが表示され、ボタンクリック時に追加アイテムが読み込まれます。
今回は、スクレイピングコースの「Load More」サンプルページを対象とします:
この複雑なナビゲーションスクレイピングパターンを処理するには、以下の手順に従ってください:
- 「Load More」ボタンを特定し、クリックします。
- ページに新しい要素が読み込まれるまで待機します。
Seleniumでの実装方法は以下の通りです:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# ヘッドレスモード用のChromeオプションを設定
options = Options()
options.add_argument("--headless")
# Chrome WebDriverインスタンスを作成
driver = webdriver.Chrome(options=options)
# 対象ページに接続
driver.get("https://www.scrapingcourse.com/button-click")
# 初期の商品数を取得
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# 「Load More」ボタンを特定してクリック
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# ページ上の商品アイテム数が増加するまで待機
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# スクレイピングしたデータの保存先
products = []
# 商品詳細をスクレイピング
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# 商品詳細を抽出
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# スクレイピングしたデータを保存
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# データエクスポートロジック...
# ブラウザドライバーを閉じる
driver.quit()
このナビゲーションロジックに対処するため、スクリプトは以下を実行します:
- ページ上の初期商品数を記録
- 「Load More」ボタンをクリック
- 商品数が増加するまで待機し、新規アイテムが追加されたことを確認
このアプローチは、読み込む要素の正確な数を把握する必要がないため、スマートかつ汎用的です。ただし、同様の結果を得るための他の方法も存在することを念頭に置いてください。
無限スクロール
無限スクロールは、特にソーシャルメディアやECプラットフォームでユーザーエンゲージメント向上に広く採用されているインタラクションです。この場合、対象ページは前述と同じですが、「さらに読み込む」ボタンではなく無限スクロールが実装されています:
ほとんどのブラウザ自動化ツール(Seleniumを含む)は、ページを直接スクロールダウン/アップする機能を提供していません。代わりに、スクロール操作を実行するためにページ上でJavaScriptスクリプトを実行する必要があります。
基本的な考え方は、以下の条件でスクロールダウンするカスタムJavaScriptスクリプトを作成することです:
- 指定回数スクロールするか、
- 読み込み可能なデータがなくなるまで
注:各スクロールで新しいデータが読み込まれ、ページ上の要素数が増加します。
その後、新たに読み込まれたコンテンツをスクレイピングできます。
これがSeleniumで無限スクロールを処理する方法です:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# ヘッドレスモード用のChromeオプション設定
options = Options()
# options.add_argument("--headless")
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(options=options)
# 無限スクロール対象ページへの接続
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# 現在のページの高さ
scroll_height = driver.execute_script("return document.body.scrollHeight")
# ページ上の商品数
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# スクロールの最大回数
max_scrolls = 10
scroll_count = 1
# スクロール回数を10回に制限
while scroll_count < max_scrolls:
# 下にスクロール
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# ページ上の商品アイテム数が増加するまで待機
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# 商品数を更新
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# 新しいページの高さを取得
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# 新しいコンテンツが読み込まれていない場合
if new_scroll_height == scroll_height:
break
# スクロール高を更新し、スクロール回数をインクリメント
scroll_height = new_scroll_height
scroll_count += 1
# 無限スクロール後の商品詳細をスクレイピング
products = []
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# 商品詳細を抽出
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# スクレイピングしたデータを保存
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# CSV/JSONへのエクスポート...
# ブラウザドライバーを閉じる
driver.quit()
このスクリプトは、まず現在のページの高さと商品数を特定することで無限スクロールを管理します。その後、スクロール操作を最大10回の反復に制限します。各反復では以下の処理を行います:
- ページ最下部までスクロール
- 商品数が増加するまで待機(新規コンテンツの読み込みを示す)
- ページ高さを比較し、追加コンテンツの有無を検出
スクロール後もページ高さが変化しない場合、ループを終了し、読み込むデータがなくなったことを示します。これが複雑な無限スクロールパターンに対処する方法です。
素晴らしい!これで複雑なナビゲーションを持つウェブサイトのスクレイピングの達人です。
結論
この記事では、複雑なナビゲーションパターンに依存するサイトと、PythonとSeleniumを使ってそれらに対処する方法について学びました。これは、ウェブスクレイピングが困難な場合があることを示していますが、スクレイピング対策によってさらに困難になることもあります。
企業は自社データの価値を理解し、あらゆる手段で保護します。そのため多くのサイトでは自動スクリプトをブロックする対策が実装されています。これらの対策には、過剰なリクエスト後のIPブロック、CAPTCHAの提示、さらに厄介な手法も含まれます。
Seleniumのような従来のブラウザ自動化ツールでは、こうした制限を回避できません…
解決策は、スクレイピングブラウザのようなクラウドベースのスクレイピング専用ブラウザを利用することです。これはPlaywright、Puppeteer、Seleniumなどのツールと連携し、リクエストごとに自動的にIPをローテーションするブラウザです。ブラウザフィンガープリンティング、再試行、CAPTCHAの解決などにも対応可能です。複雑なサイト処理中にブロックされる心配はもう不要です!




