

Webスクレイピングは、データ分析やAIモデルの微調整などの目的で、Webサイトからデータを自動的に収集するプロセスです。
Pythonは、XMLやHTMLドキュメントの解析に使用されるlxmlをはじめとする幅広いスクレイピングライブラリがあるため、Webスクレイピングによく使用されています。lxmlは、高速Cライブラリのlibxml2およびlibxslt用のPython APIを使用して、Pythonの機能を拡張します。また、lxmlはPythonのXML/HTMLツリー用の階層データ構造であるElementTreeとも統合できるため、効率的で信頼性の高いWebスクレイピングに適したツールとなっています。
この記事では、lxmlをWebスクレイピングに使用する方法を解説します。
完璧な代替手段となるBright Dataのソリューション
Webスクレイピングにおいて、Pythonでのlxmlの使用は強力なアプローチとなりますが、特に複雑なWebサイトや大量のデータを扱う場合、時間とコストがかかる可能性があります。Bright Dataは、すぐに使用できるデータセットとWebスクレイパーAPIという、効率的な代替手段を提供しています。これらのソリューションは、100以上のドメインから事前に収集されたデータと、統合が容易なスクレイピングAPIを提供することで、データ収集にかかる時間とコストを大幅に削減します。
Bright Dataを使用すると、手動でのスクレイピングに伴う技術的な課題を回避し、データの取得ではなく分析に集中できます。特定の要件に合わせたデータセットが必要な場合でも、プロキシ管理やCAPTCHA解決を行えるAPIをお求めの場合でも、Bright DataのツールはあらゆるWebスクレイピングのニーズに対応する効率的で費用対効果の高いソリューションを提供します。
PythonでのWebスクレイピングへのlxmlの使用
Webでは、構造化データと階層データをHTMLとXMLの2つの形式で表すことができます。
- XMLは基本構造であり、タグやスタイルがあらかじめ組み込まれていません。コーダーは独自のタグを定義して構造を作ります。タグの主な目的は、異なるシステム間で理解できる標準データ構造を作ることです。
- HTMLは事前に定義済みのタグを持つWebマークアップ言語です。これらのタグには、
font-sizeや、displayなど、いくつかのスタイルプロパティが含まれています。HTMLの主な機能は、Webページを効果的に構造化することです。
lxmlはHTMLとXMLの両方のドキュメントで機能します。
前提条件
lxmlでWebスクレイピングを開始する前に、マシンにいくつかのライブラリをインストールする必要があります:
pip install lxml requests cssselect
このコマンドは以下をインストールします:
静的HTMLコンテンツの解析
スクレイピングできるWebコンテンツには、主に静的と動的の2種類があります。静的コンテンツは、Webページが最初に読み込まれるときにHTMLドキュメントに埋め込まれていて、簡単にスクレイピングできます。対照的に、動的コンテンツは継続的に読み込まれるか、最初のページ読み込み後にJavaScriptによってトリガーされます。動的コンテンツをスクレイピングするには、コンテンツがブラウザで利用可能になってからスクレイピング機能を実行するように、タイミングを設定する必要があります。
この記事では、まずBooks to Scrape Webサイトをスクレイピングすることから始めます。このサイトには、テスト用に作られた静的HTMLコンテンツがあります。本の題名と価格を抽出し、その情報をJSONファイルとして保存します。
まず、ブラウザのデベロッパーツールを使用して、関連するHTML要素を特定します。Webページを右クリックして [検証] オプションを選択し、デベロッパーツールを開きます。Chromeをお使いの場合は、F12を押してこのメニューにアクセスできます:
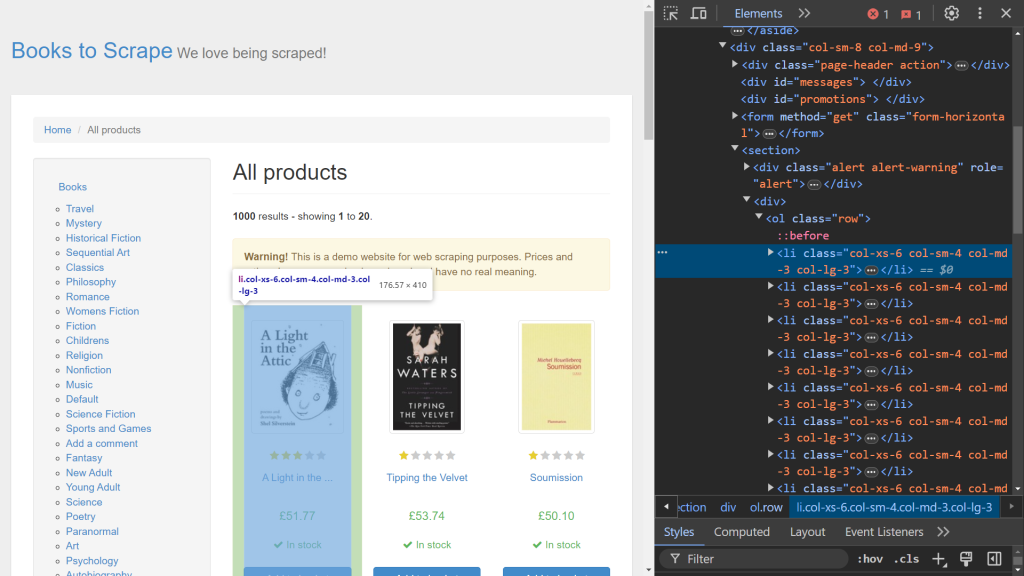
画面の右側には、ページのレンダリングを行うコードが表示されます。それぞれの本のデータを扱う特定のHTML要素を見つけるには、セレクトモード (画面左上にある矢印) を使用してコードの中を探します。
デベロッパーツールに次のコードスニペットが表示されます:
<article class="product_pod">
<!-- code omitted -->
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html" title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<!-- code omitted -->
</div>
</article>
このスニペットでは、それぞれの本がproduct_podクラスのラベルが付いた、<article>タグに含まれています。この要素をターゲットにしてデータを抽出します。static_scrape.pyという新しいファイルを作成し、次のコードを入力します:
import requests
from lxml import html
import json
URL = "https://books.toscrape.com/"
content = requests.get(URL).text
このコードは必要なライブラリをインポートし、URL変数を定義します。requests.get()を使用して、指定されたURLにGETリクエストを送信することにより、Webページの静的HTMLコンテンツを取得します。次に、応答のtext属性を使用して、HTMLコードが取得されます。
HTMLコンテンツを取得したら、次のステップはlxmlを使用してそれを解析し、必要なデータを抽出することです。lxmlでは、XPathとCSSセレクターの2つの抽出方法が使用できます。この例では、XPathを使用して本の題名を取得し、CSSセレクターを使用して本の価格を取得します。
スクリプトに次のコードを追加します:
parsed = html.fromstring(content)
all_books = parsed.xpath('//article[@class="product_pod"]')
books = []
このコードは、HTMLコンテンツを階層ツリー構造に解析するhtml.fromstring(content)を使用して、parsed変数を初期化します。all_books変数はXPathセレクターを使用して、product_podクラスを持つすべての<article>タグをWebページから取得します。この構文は、XPath式でのみ有効です。
次に、スクリプトに以下を追加して、all_booksのそれぞれの本を繰り返し処理し、データを抽出します:
for book in all_books:
book_title = book.xpath('.//h3/a/@title')
price = book.cssselect("p.price_color")[0].text_content()
books.append({"title": book_title, "price": price})
book_title変数は、<h3>タグ内の<a>タグからtitle属性を取得するXPathセレクターを使用して定義されます。XPath式の先頭にあるピリオド (.) は、デフォルトの開始点ではなく
タグから検索を開始することを指定します。次の行は、cssselectメソッドを使用して、price_colorクラスを持つ<p>タグから価格を抽出します。cssselectはリストを返すので、([0]) をインデックス化することで最初の要素にアクセスし、text_content()が要素内のテキストを取得します。その後、抽出されたそれぞれの題名と価格の組み合わせは辞書としてbooksリストに追加され、JSONファイルに簡単に保存できます。
Webスクレイピングプロセスが完了したので、このデータをローカルに保存します。スクリプトファイルを開き、次のコードを入力します:
with open("books.json", "w", encoding="utf-8") as file:
json.dump(books ,file)
このコードでは、books.jsonという名前の新しいファイルが作成されます。このファイルにはjson.dumpメソッドを使用して入力されます。このメソッドは、booksリストをソースとし、fileオブジェクトをデスティネーションとします。
このスクリプトをテストするには、ターミナルを開いて次のコマンドを実行します:
python static_scrape.py
このコマンドは、次の出力を含む新しいファイルをディレクトリに生成します:
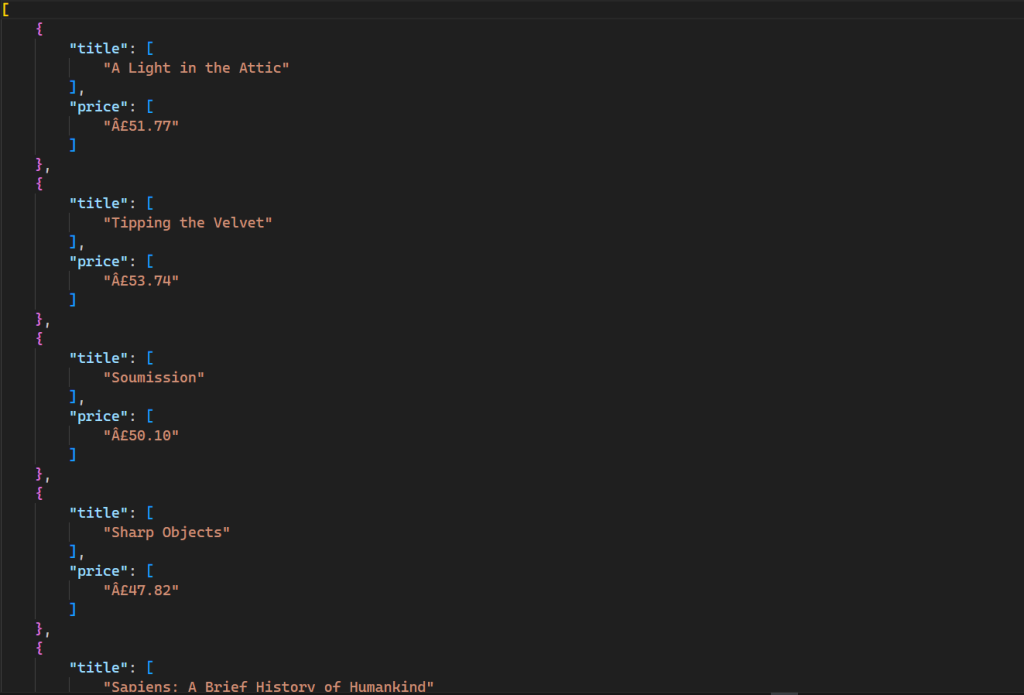
このスクリプトで使用されるすべてのコードは、GitHubで利用可能です。
動的HTMLコンテンツの解析
動的Webコンテンツのスクレイピングは、JavaScriptがデータを一度にすべてレンダリングするのではなく継続的にレンダリングするため、静的コンテンツのスクレイピングよりも工夫を要します。動的コンテンツをスクレイピングするには、Seleniumというブラウザ自動化ツールを使用します。これにより、ブラウザインスタンスを作成して実行し、プログラムで制御できます。
Seleniumをインストールするには、ターミナルを開いて次のコマンドを実行します:
pip install selenium
YouTubeは、JavaScriptを使用してレンダリングされるコンテンツの良い例です。チャンネルにアクセスすると、最初は限られた数の動画のみが読み込まれ、下にスクロールするとさらに多くの動画が表示されます。この例では、キーボード操作をエミュレートしてページをスクロールし、freecodeCamp.orgのYouTubeチャンネルの上位100本の動画のデータをスクレイピングします。
まず、WebページのHTMLコードを検証します。デベロッパーツールを開くと、次のように表示されます:
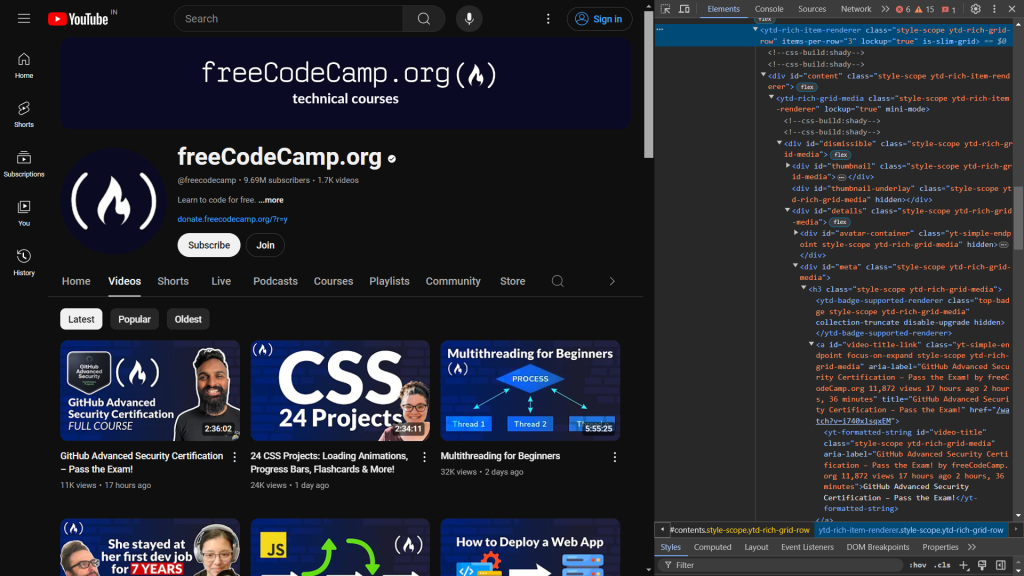
次のコードは、動画のタイトルとリンクを表示する要素を特定します:
<a id="video-title-link" class="yt-simple-endpoint focus-on-expand style-scope ytd-rich-grid-media" href="/watch?v=i740xlsqxEM">
<yt-formatted-string id="video-title" class="style-scope ytd-rich-grid-media">GitHub Advanced Security Certification – Pass the Exam!
</yt-formatted-string></a>
動画のタイトルは、video-titleというIDを持つyt-formatted-stringタグ内にあり、動画のリンクはvideo-title-linkというIDを持つaタグのhref属性にあります。
スクレイピングする対象を特定したら、dynamic_scrape.pyという名前の新しいファイルを作成し、スクリプトに必要なすべてのモジュールをインポートする次のコードを追加します:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from lxml import html
from time import sleep
import json
この例では、まずseleniumからwebdriverをインポートします。これにより、プログラムで制御できるブラウザインスタンスが作成されます。次の行では、ByとKeysをインポートします。これらはWeb上の要素を選択し、その要素上でいくつかのキー操作を実行します。sleep関数がインポートされ、プログラムの実行を一時停止し、JavaScriptがページのコンテンツをレンダリングするのを待ちます。
すべてのインポートが整理されたところで、任意のブラウザのドライバーインスタンスを定義できます。このチュートリアルではChromeを使用していますが、SeleniumはEdge、Firefox、Safariもサポートしています。
ブラウザのドライバーインスタンスを定義するには、スクリプトに次のコードを追加します:
URL = "https://www.youtube.com/@freecodecamp/videos"
videos = []
driver = webdriver.Chrome()
driver.get(URL)
sleep(3)
前のスクリプトと同様に、スクレイピングするWeb URLを含むURL変数と、すべてのデータをリストとして保存するvideos変数を宣言します。次に、ブラウザを操作するときに使用するdriver変数 (つまりChromeインスタンス) を宣言します。get()関数がブラウザインスタンスを開き、指定されたURLにリクエストを送信します。その後、sleep関数を呼び出して、すべてのHTMLコードがブラウザに読み込まれるように、3秒間待ってからWebページの要素にアクセスします。
前述のように、YouTubeではJavaScriptを使用して、ページの一番下までスクロールするにつれ、さらに多くの動画が読み込まれます。100本の動画からデータをスクレイピングするには、ブラウザを開いてから、プログラムでページの一番下までスクロールする必要があります。これは、スクリプトに次のコードを追加して行えます:
parent = driver.find_element(By.TAG_NAME, 'html')
for i in range(4):
parent.send_keys(Keys.END)
sleep(3)
このコードでは、find_element関数を使用して<html>タグが選択されます。 指定された条件に一致する最初の要素が返され、この場合はhtmlタグになります。send_keysメソッドは、ENDキーを押してページの一番下までスクロールすることをシミュレートし、他の動画の読み込みをトリガーします。十分な数の動画が読み込まれるように、この操作はforループ内で4回繰り返されます。sleep関数が、スクロールするたびに3秒間一時停止して、動画が読み込まれてから再びスクロールされるようにします。
スクレイピングプロセスを開始するのに必要なデータがすべて揃ったところで、lxmlとcssselectを使用して抽出する要素を選択します。
html_data = html.fromstring(driver.page_source)
videos_html = html_data.cssselect("a#video-title-link")
for video in videos_html:
title = video.text_content()
link = "https://www.youtube.com" + video.get("href")
videos.append( {"title": title, "link": link} )
このコードでは、ドライバーのpage_source属性のHTMLコンテンツをfromstringメソッドに渡します。これにより、HTMLの階層ツリーが構築されます。次に、CSSセレクターを使用して、video-title-linkというIDを持つすべての<a>タグを選択します。この際、#記号はタグのIDを使用して選択されたことを示します。この選択により、指定された条件を満たす要素のリストが返されます。次に、コードが各要素を繰り返し処理し、タイトルとリンクを抽出します。text_contentメソッドが内部テキスト (動画のタイトル) を取得し、getメソッドがhref属性値 (動画のリンク) を取得します。最後に、データがvideosというリストに保存されます。
この時点で、スクレイピングプロセスは完了です。次のステップでは、このスクレイピングされたデータをシステムにローカルに保存します。データを保存するには、スクリプトに次のコードを追加します:
with open('videos.json', 'w') as file:
json.dump(videos, file)
driver.close()
この例では、videos.jsonファイルを作成し、json.dumpメソッドを使用して動画リストをJSON形式にシリアル化して、ファイルオブジェクトに書き込みます。最後に、ドライバーオブジェクトのcloseメソッドを呼び出して、ブラウザインスタンスを安全に閉じて破棄します。
これで、ターミナルを開いて次のコマンドを実行して、スクリプトをテストできます:
python dynamic_scrape.py
スクリプトを実行すると、videos.jsonという名前の新しいファイルがディレクトリに作成されます:
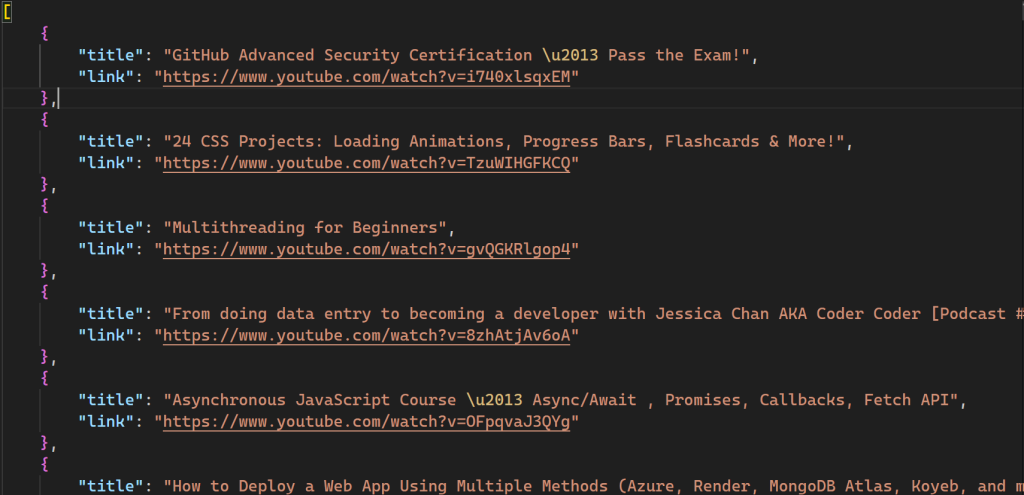
このスクリプトで使用されたコードもすべて、GitHubで利用可能です。
Bright Dataプロキシでのlxmlの使用
Webスクレイピングは、さまざまなソースからのデータ収集を自動化するための優れた手法ですが、このプロセスには課題がないわけではありません。Webサイトで実装されているスクレイピング対策ツール、レート制限、ジオブロック、匿名性の欠如に対処する必要があります。プロキシサーバーは、ユーザーのIPアドレスを隠す仲介者の役割を果たし、スクレイパーが制限を回避し、検出されることなく対象データにアクセスできるようにすることで、これらの問題を解決できます。Bright Dataは、信頼できるプロキシサービスとして多くのお客様に選ばれています。
次の例は、Bright Dataのプロキシがいかに簡単に使用できるかを示しています。この例では、Books to ScrapeのWebサイトをスクレイピングするために、script_scrape.pyファイルにいくつかの変更を加えます。
まず、5米ドル相当のプロキシリソースが提供される無料トライアルに登録して、Bright Dataからプロキシを取得する必要があります。Bright Dataアカウントを作成すると、次のダッシュボードが表示されます:
[マイゾーン] オプションに移動し、新しい住宅用プロキシゾーンを作成します。新しいゾーンを作成すると、次のステップで必要になるプロキシのユーザー名、パスワード、ホストが表示されます。
static_scrape.pyファイルを開き、URL変数の下に次のコードを追加します:
URL = "https://books.toscrape.com/"
# new
username = ""
password = ""
hostname = ""
proxies = {
"http": f"https://{username}:{password}@{hostname}",
"https": f"https://{username}:{password}@{hostname}",
}
content = requests.get(URL, proxies=proxies).text
username、password、hostnameプレースホルダーをプロキシの認証情報に置き換えます。このコードは、指定されたプロキシを使用するようにrequestsライブラリに指示します。スクリプトの残りの部分は変更されません。
次のコマンドを実行してスクリプトをテストします:
python static_scrape.py
このスクリプトを実行すると、前の例と同様の出力が表示されます。
このスクリプトの全体は、GitHubで確認できます。
まとめ
lxmlはHTMLドキュメントからデータを抽出するための、強力で使いやすいツールです。lxmlは高速化を実現するよう最適化されており、XPathおよびCSSセレクターをサポートしているため、大規模なXMLおよびHTMLドキュメントを効率的に解析できます。
このチュートリアルでは、lxmlを使用したWebスクレイピングと、動的・静的の両方のコンテンツのスクレイピングに関するさまざまなことを解説しました。また、Bright Dataのプロキシサーバーを使用し、Webサイトよるスクレイパーに対する制限を回避する方法についても解説しました。
Bright Dataは、あらゆるWebスクレイピングプロジェクトに対応できる、ワンストップソリューションです。プロキシ、スクレイピングブラウザ、reCAPTCHAなどの機能を提供し、ユーザーがWebスクレイピングの課題を効果的に解決できるようにします。また、Bright Dataは、Webスクレイピングに関するチュートリアルやベストプラクティスを含む、詳細なブログも提供しています。
ご利用を検討されている場合は、今すぐ登録して、当社の製品を無料でお試しください!






