

このガイドでは以下を学びます:
- – ZoomInfoスクレイパーの定義と動作原理
- ZoomInfoから自動抽出可能なデータの種類
- Pythonを使用したZoomInfoスクレイピングスクリプトの作成方法
- より高度なソリューションが必要な場合とその理由
さっそく見ていきましょう!
ZoomInfoスクレイパーとは?
ZoomInfoスクレイパーとは、詳細な企業情報と専門家情報を提供する主要プラットフォームであるZoomInfoからデータを抽出するツールです。このソリューションはスクレイピングプロセスを自動化し、大量のデータを収集することを可能にします。スクレイパーは、サイトをナビゲートしてコンテンツを取得するために、ブラウザ自動化などの技術に依存しています。
ZoomInfoから取得可能なデータ
ZoomInfoからスクレイピング可能な主なデータは以下の通りです:
- 企業情報:名称、業種、収益、本社所在地、従業員数
- 従業員詳細:氏名、役職、メールアドレス、電話番号。
- 業界インサイト:競合他社、市場動向、企業階層構造。
PythonでZoomInfoをスクレイピングする手順ガイド
このセクションでは、ZoomInfoスクレイパーの構築方法を学びます。
目標は、NVIDIA ZoomInfo 企業ページから自動的にデータを収集する Python スクリプトの作成手順を説明することです。
以下の手順に従ってください。
ステップ #1: プロジェクトの設定
開始前に、お使いのマシンにPython 3がインストールされていることを確認してください。インストールされていない場合は、ウィザードに従ってダウンロードおよびインストールを行ってください。
次に、プロジェクト用フォルダを作成する以下のコマンドを実行します:
mkdir zoominfo-スクレイパー
zoominfo-scraperディレクトリは、Python ZoomInfoスクレイパーのプロジェクトフォルダを表します。
その中に入り、仮想環境を初期化します:
cd zoominfo-スクレイパー
python -m venv env
お好みのPython IDEでプロジェクトフォルダを開きます。Python拡張機能付きのVisual Studio CodeやPyCharm Community Editionが適しています。
プロジェクトフォルダ内にscraper.py ファイルを作成します。以下のファイル構成を含む必要があります:

現時点では、scraper.py は空の Python スクリプトです。間もなく、目的のスクレイパーロジックが含まれるようになります。
IDEのターミナルで仮想環境を有効化します。LinuxまたはmacOSでは次のコマンドを実行:
./env/bin/activate
Windowsでは同等の以下のコマンドを実行します:
env/Scripts/activate
これでウェブスクレイピング用のPython環境が整いました!
ステップ #2: スクラッピングライブラリの選択
コーディングを始める前に、目標達成に最適なツールを理解する必要があります。そのためには、まず対象サイトを調査する予備テストを実施しましょう。手順は以下の通りです:
- 対象ページをブラウザのシークレットモードで開きます。これにより、事前に保存されたクッキーや設定が分析に影響するのを防げます。
- ページ上の任意の場所で右クリックし、「要素を検査」を選択してブラウザの開発者ツールを開きます。
- 「ネットワーク」タブに移動します。
- ページを再読み込みし、「フェッチ/XHR」タブの通信活動を観察します。
これにより、ウェブページがレンダリング時にどのように動作するかがわかります:
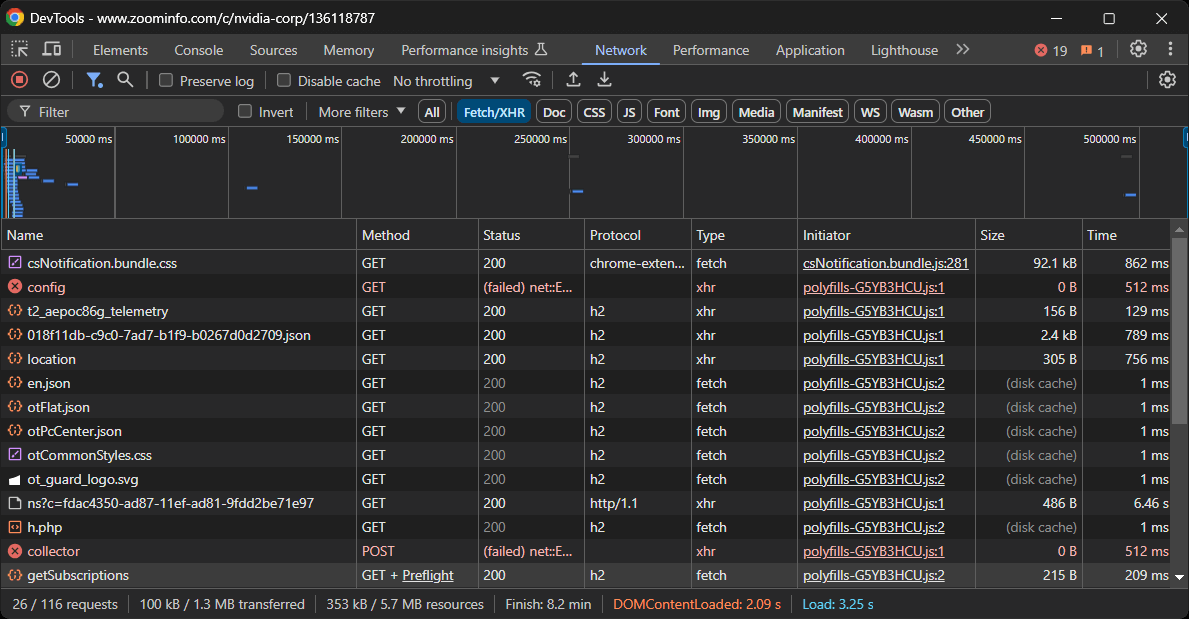
このセクションでは、ページが行う動的なAJAXリクエストをすべて確認できます。各リクエストを検査すると、関連データを含んでいないことがわかります。これは、ページ上の情報の大部分がサーバーから返されるHTML文書に既に埋め込まれていることを示しています。
この結果から、ZoomInfoのスクレイピングにはHTTPクライアントとHTMLパーサーの採用が自然となります。ただし、当サイトは厳格なボット対策技術を採用しており、ブラウザ発ではない自動リクエストの大半をブロックします。これを回避する最も簡単な方法は、Seleniumのようなブラウザ自動化ツールの使用です!
Seleniumを使用すると、プログラムでウェブブラウザを制御し、実際のユーザーが行うのと同じようにウェブページ上で特定の操作を実行させることができます。さあ、インストールして始めましょう!
ステップ #3: Selenium のインストールと設定
Pythonでは、Seleniumはselenium pipパッケージ経由で利用可能です。アクティブなPython仮想環境内で、以下のコマンドでインストールしてください:
pip install -U selenium
ツールの使用方法については、Seleniumを用いたウェブスクレイピングチュートリアルを参照してください。
scraper.py で Selenium をインポートし、Chrome インスタンスを制御するWebDriver オブジェクトを初期化します:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスを作成
driver = webdriver.Chrome(service=Service())
上記のコードはChrome上で動作するWebDriverインスタンスを作成します。ZoomInfoはヘッドレスブラウザをブロックする反スクレイピング技術を採用しているため、--headlessフラグを設定できません。代替手段としてPlaywright Stealthの利用を検討してください。
スクレイパーの最終行では、必ずWebDriverを閉じることを忘れないでください:
driver.quit()
素晴らしい!これでZoomInfoのスクラッピングを開始する準備が整いました。
ステップ #4: 対象ページへの接続
Selenium WebDriver オブジェクトのget()メソッドを使用して、ブラウザに目的のページへのアクセスを指示します:
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
これで、scraper.pyファイルには以下のコードが含まれるはずです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# Chrome WebDriverインスタンスの作成
driver = webdriver.Chrome(service=Service())
# ターゲットページへの接続
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# スクラッピング処理...
# ブラウザを閉じる
driver.quit()
最終行にデバッグブレークポイントを設定し、スクリプトを実行します。NVIDIAの会社ページが表示されるはずです。
「Chromeは自動テストソフトウェアによって制御されています」というメッセージは、Seleniumが想定通りChromeを制御していることを確認します。よくできました!
ステップ #5: 会社の基本情報をスクレイピング
必要なデータをスクレイピングする方法を理解するには、ページのDOM構造を分析する必要があります。目的は、目的のデータを含むHTML要素を特定することです。まず、会社情報セクションの上部にある要素を検査します:
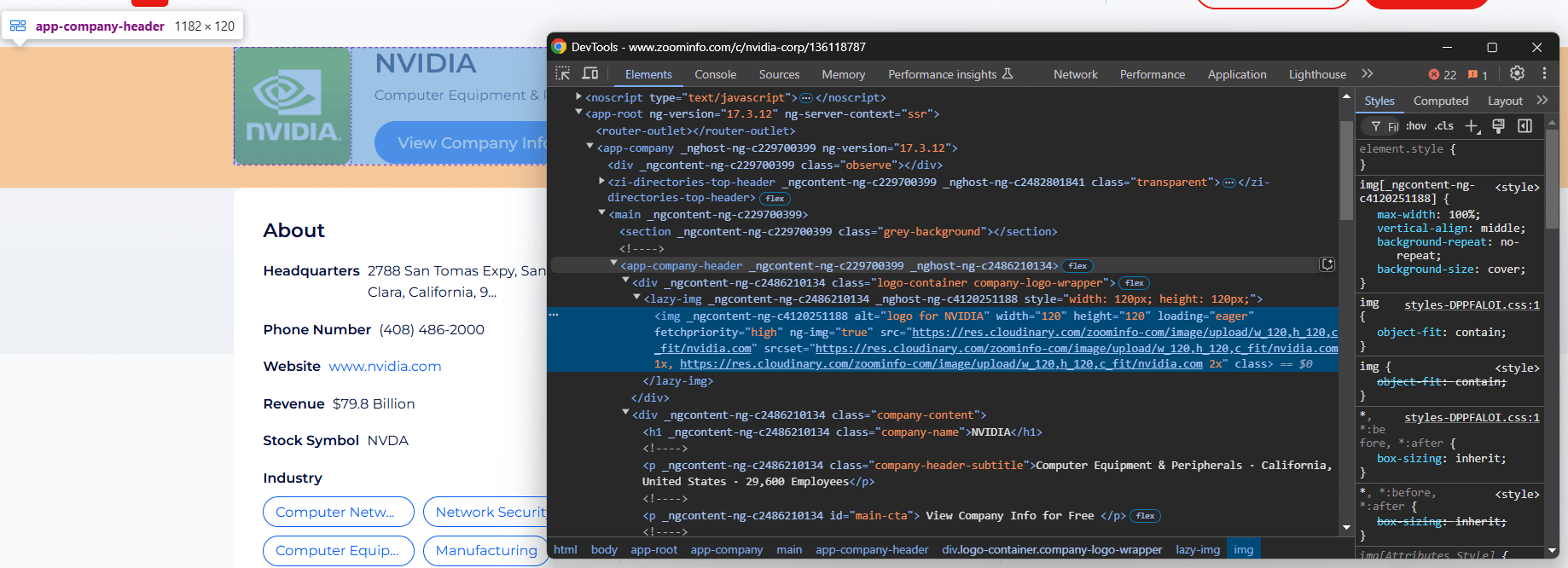
<app-company-header>要素には以下が含まれます:
- 会社ロゴ画像は、class=”
company-logo-wrapper” の<div>内に配置された<img>タグで囲まれています。 会社名はclass=company-nameのノード内にあります。- 会社サブタイトルはclass
=company-header-subtitleのノード内に格納されています。
Seleniumを使用してこれらの要素を特定し、データを収集します:
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
コードを動作させるには、Byのインポートを忘れないでください:
from selenium.webdriver.common.by import By
find_element()メソッドは、指定されたノード選択戦略を使用してノードを選択します。上記ではCSSセレクタを使用しました。XPathとCSSセレクタの違いについて詳しく学びましょう。
その後、text属性を使用してノードの内容にアクセスできます。属性にアクセスするには、get_attribute()メソッドを利用します。
スクレイピングしたデータを表示:
print(logo_url)
print(name)
print(subtitle)
出力結果:
https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com
NVIDIA
コンピューター機器・周辺機器 · カリフォルニア州, アメリカ合衆国 · 従業員数 29,600名
すごい!ZoomInfoスクレイパーは完璧に動作します。
ステップ #6: 会社概要情報のスクレイピング
会社ページの「About」セクションに注目:
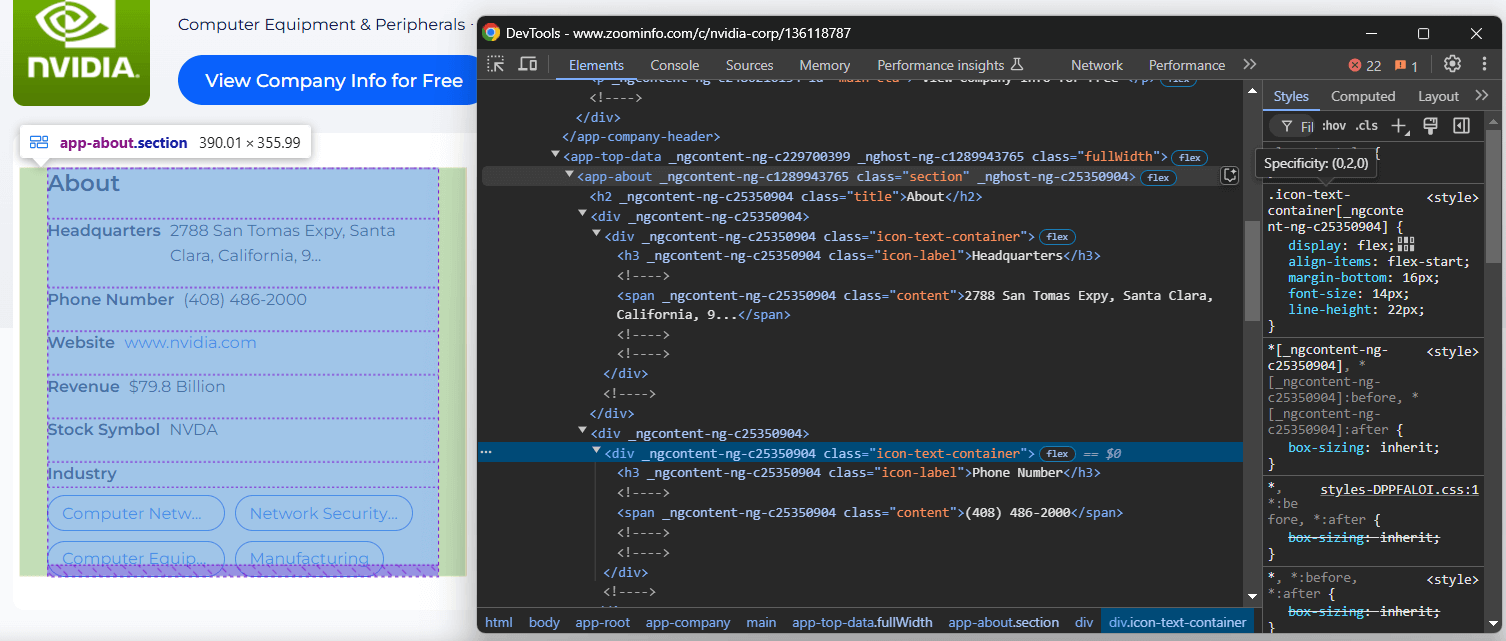
<app-about>ノードには、汎用クラスとランダムに生成されたと思われる属性が含まれています。これらの属性はビルドごとに変更される可能性があるため、スクレイピング対象の要素を特定する際に依存すべきではありません。
このセクションの情報をスクレイピングするには、まず<app-about>ノードを選択します:
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
次に、<app-about>内の全ての.icon-text-container要素に焦点を当てます。その後、それらのラベル(.icon-label)を検査し、対象となる特定の要素を特定します。ラベルが一致した場合、.content要素からデータを抽出します。このロジックを関数にカプセル化します:
def scrape_about_node(text_container_elements, text_label):
# 対象ノードからデータをスクレイピングするため、
# それらを反復処理する
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# コンテンツ要素を選択しデータを抽出
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
次に「About」情報をスクレイピングするには:
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
次に、業界タグと企業タグをターゲットにします。
h3 .incon-label で企業業界を、zi-directories-chips a でタグを選択します。それらからデータをスクレイピングします:
industry_element = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text for tag_element in tag_elements]
すごい!ZoomInfoのデータスクレイピングロジックが完成しました。
ステップ #7: スクレイピングしたデータの収集
現在、スクレイピングしたデータは複数の変数に分散しています。そのデータで新しい会社オブジェクトを作成します:
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
スクレイピングしたデータを印刷し、必要な情報が含まれていることを確認します
print(items)
以下の出力が得られます:
{'logo_url': 'https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com', 'name': 'NVIDIA', 'subtitle': 'Computer Equipment & Peripherals · カリフォルニア州、アメリカ合衆国 · 従業員数 29,600名', 'headquarters': '2788 San Tomas Expy, Santa Clara, California, 95051, United States', 'phone_number': '(408) 486-2000', 'revenue': '798億ドル', 'stock_symbol': 'NVDA', 'industry': '本社', 'tags': ['コンピュータネットワーク機器', 'ネットワークセキュリティハードウェア・ソフトウェア', 'コンピュータ機器・周辺機器', '製造業']}
素晴らしい!あとはこの情報をJSONのような人間が読める形式のファイルにエクスポートするだけです。
ステップ #8: JSON へのエクスポート
以下のコードで企業情報を company.json ファイルにエクスポートします:
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
まずopen() で出力ファイルcompany.json を作成します。次にjson.dump() がcompany を JSON 表現に変換し、出力ファイルに書き込みます。
Python標準ライブラリからjsonをインポートすることを忘れないでください:
import json
ステップ #9: 全てを統合する
以下が最終的なscraper.py ファイルです:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
def scrape_about_node(text_container_elements, text_label):
# 対象の特定ノードからデータをスクレイピングするため、それらを反復処理
for text_container_element in text_container_elements:
label = text_container_element.find_element(By.CSS_SELECTOR, ".icon-label").text.strip()
if label == text_label:
# コンテンツ要素を選択し、そこからデータを抽出
content_element = text_container_element.find_element(By.CSS_SELECTOR, ".content")
return content_element.text
return None
# Chrome Web Driverインスタンスを作成
driver = webdriver.Chrome(service=Service())
# 対象ページに接続
driver.get("https://www.zoominfo.com/c/nvidia-corp/136118787")
# 会社情報をスクレイピング
logo_element = driver.find_element(By.CSS_SELECTOR, ".company-logo-wrapper img")
logo_url = logo_element.get_attribute("src")
name_element = driver.find_element(By.CSS_SELECTOR, ".company-name")
name = name_element.text
subtitle_element = driver.find_element(By.CSS_SELECTOR, ".company-header-subtitle")
subtitle = subtitle_element.text
# 「About」セクションからデータをスクレイピング
about_element = driver.find_element(By.CSS_SELECTOR, "app-about")
text_container_elements = about_element.find_elements(By.CSS_SELECTOR, ".icon-text-container")
headquarters = scrape_about_node(text_container_elements, "Headquarters")
phone_number = scrape_about_node(text_container_elements, "Phone Number")
revenue = scrape_about_node(text_container_elements, "Revenue")
stock_symbol = scrape_about_node(text_container_elements, "Stock Symbol")
# 企業の業種とタグをスクレイピング
industry_element = about_element.find_element(By.CSS_SELECTOR, "h3.icon-label")
industry = industry_element.text
tag_elements = about_element.find_elements(By.CSS_SELECTOR, "zi-directories-chips a")
tags = [tag_element.text for tag_element in tag_elements]
# スクレイピングしたデータを収集
company = {
"logo_url": logo_url,
"name": name,
"subtitle": subtitle,
"headquarters": headquarters,
"phone_number": phone_number,
"revenue": revenue,
"stock_symbol": stock_symbol,
"industry": industry,
"tags": tags
}
# スクレイピングしたデータをJSONにエクスポート
with open("company.json", "w") as json_file:
json.dump(company, json_file, indent=4)
# ブラウザを閉じる
driver.quit()
わずか70行強のコードで、PythonによるZoomInfoデータスクレイピングスクリプトを作成しました!
以下のコマンドでスクレイパーを起動します:
python3 script.py
Windowsの場合:
python script.py
プロジェクトフォルダ内にcompany.jsonファイルが生成されます。開くと以下のような内容が表示されます:
{
"logo_url": "https://res.cloudinary.com/zoominfo-com/image/upload/w_120,h_120,c_fit/nvidia.com",
"name": "NVIDIA",
"subtitle": "Computer Equipment & Peripherals · カリフォルニア州、アメリカ合衆国 · 従業員数 29,600名",
"headquarters": "2788 San Tomas Expy, Santa Clara, California, 95051, United States",
"phone_number": "(408) 486-2000",
"revenue": "$798億",
"stock_symbol": "NVDA",
"industry": "本社",
"tags": [
"コンピュータネットワーク機器",
"ネットワークセキュリティハードウェア&ソフトウェア",
"コンピュータ機器・周辺機器",
"製造業"
]
}おめでとうございます、ミッション完了!
ZoomInfoデータの簡単取得
ZoomInfoは単なる企業概要以上の情報を提供します——豊富な有用なデータを提供します。問題は、ZoomInfoドメイン下のほとんどのページがボット対策で保護されているため、そのデータをスクレイピングするのが非常に困難なことです。
Seleniumやその他のブラウザ自動化ツールを使用してこれらのページにアクセスしようとすると、CAPTCHAページが表示され、試行がブロックされる可能性が高いです。
最初のステップとして、PythonでCAPTCHAを回避する方法に関するガイドを参照することを検討してください。ただし、サイトの厳格なレート制限により、429 Too Many Requestsエラーが発生する可能性があります。そのような場合、Seleniumにプロキシを統合して出口IPをローテーションさせることができます。
これらの問題は、適切なツールなしにZoomInfoをスクレイピングすることがいかに迅速に苛立たしいプロセスになり得るかを示しています。また、ヘッドレスブラウザが使用できないという事実が、スクレイピングスクリプトを遅くし、リソースを大量に消費させる原因となります。
解決策は?Bright Dataの専用ZoomInfoスクレイパーAPIを活用し、ブロックされることなくシンプルなAPI呼び出しで対象サイトからデータを取得することです!
結論
このステップバイステップチュートリアルでは、ZoomInfoスクレイパーの定義と取得可能なデータの種類を学びました。さらに、100行未満のコードでZoomInfoから企業概要データをスクレイピングするPythonスクリプトを構築しました。
課題は、ZoomInfoがCAPTCHA、ブラウザフィンガープリント、IP禁止など厳格なボット対策を採用し自動スクリプトをブロックすることです。当社のZoomInfoスクレイパーAPIなら、これらの課題をすべて解消できます。
ウェブスクレイピングは不要でも企業・従業員データにご興味がある方は、当社のZoomInfoデータセットをご検討ください!
スクレイパーAPIをお試しいただくか、データセットを閲覧するには、今すぐBright Dataの無料アカウントを作成してください。




