

このガイド付きチュートリアルでは、以下のことを学びます:
- RAGの概要とそのメカニズム
- RAGを通してSERPデータをGPT-4oに統合する利点
- OpenAI GPTモデルとSERPデータを使ってPython RAGチャットボットを実装する方法
飛び込んでみよう
RAGとは?
RAGはRetrieval-Augmented Generationの略で、情報検索とテキスト生成を組み合わせたAIのアプローチです。RAGワークフローでは、アプリケーションはまず、ドキュメント、ウェブページ、データベースなどの外部ソースから関連データを取得します。その後、データをAIモデルに渡し、より文脈に関連した応答を生成できるようにする。
RAGは、GPTのような大規模言語モデル(LLM)が、元の学習データ以外の最新の情報にアクセスして参照できるようにすることで、LLMを強化します。このアプローチは、AIが生成する回答の品質と精度の両方を向上させるため、正確で文脈に特化した情報が必要とされるシナリオにおいて鍵となります。
AIモデルにSERPデータを与える理由
GPT-4oのナレッジカットオフは2023年10月であり、それ以降のイベントや情報にはアクセスできない。しかし、GPT-4oのモデルは、Bing検索との統合により、インターネットからリアルタイムでデータを取り込むことができる。そのため、より最新の情報を提供することができる。
しかし、AIモデルに特定のデータソースを採用させたい場合や、より信頼性の高い検索エンジンを選択させたい場合はどうすればいいのだろうか?そこでRAGが活躍する!
特に、RAGを介してSERP(検索エンジンの結果ページ)データをAIモデルに与えることは、より良い回答を得るための素晴らしい方法です。このアプローチは、最新の情報や専門的な洞察を必要とするタスクに特に有益です。
つまり、上位に表示された検索結果のデータをGPT-4oまたはGPT-4o miniに渡すことで、詳細かつ正確で、文脈に富んだ回答を得ることができる。
Pythonを使用したGPTモデルによるSERPデータのRAG:ステップバイステップのチュートリアル
このチュートリアルでは、OpenAIのGPTモデルを使ってRAGチャットボットを構築する方法を学びます。このアイデアは、特定の検索クエリでGoogleのトップパフォーマンスのページからテキストを収集し、GPTリクエストのコンテキストとして使用することです。
さて、最大の課題はSERPデータのスクレイピングである。というのも、ほとんどの検索エンジンは、ページへの自動アクセスを防ぐために、高度なアンチボット・ソリューションを備えているからだ。詳細なガイダンスについては、PythonでGoogleをスクレイピングする方法のガイドを参照してください。
スクレイピングプロセスを簡単にするために、Bright DataのSERP APIを使用する:
このプレミアムSERPスクレイパーは、シンプルなHTTPリクエストを使って、Google、DuckDuckGo、Bing、Yandex、Baidu、その他の検索エンジンのSERPを簡単に取得することができます。
そして、ヘッドレスブラウザを使って、返されたURLからテキストデータを抽出する。そして、その情報をRAGワークフローのGPTモデルのコンテキストとして使う。代わりにAIを使ってオンラインデータを直接取得したい場合は、ChatGPTを使ったウェブスクレイピングの記事をお読みください。
コードを調べたい場合、あるいは以下のステップを踏む際に手元に置いておきたい場合は、この記事をサポートしている GitHub リポジトリをクローンしてください:
git clone https://github.com/Tonel/rag_gpt_serp_scrapingREADME.mdファイルの指示に従って、プロジェクトの依存関係をインストールし、プロジェクトを起動する。
このブログ記事で紹介されているアプローチは、他の検索エンジンやLLMにも簡単に適用できることを覚えておいてください。
注:このガイドはUnixとmacOSを対象としています。Windowsユーザーであれば、Windows Subsystem for Linux(WSL)を使ってチュートリアルに従うことができます。
ステップ #1: Pythonプロジェクトの初期化
あなたのマシンにPython 3がインストールされていることを確認してください。そうでなければ、ダウンロードしてインストールしてください。
プロジェクト用のフォルダを作成し、ターミナルに入力します:
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scrapingrag_gpt_serp_scrapingフォルダは、あなたのPython RAGプロジェクトを含みます。
次に、お気に入りのPython IDEでプロジェクトディレクトリをロードします。PyCharm Community EditionまたはPython拡張機能付きのVisual Studio Codeでも構いません。
rag_gpt_serp_scrapingの中に、空のapp.pyファイルを追加します。ここにスクレイピングとRAGのロジックを記述します。
次に、プロジェクトディレクトリでPython仮想環境を初期化します:
python3 -m venv env以下のコマンドで仮想環境を有効にします:
source ./env/bin/activateすごい!これでセットアップは完了です。
ステップ2: 必要なライブラリのインストール
GPTモデルに基づくPython RAGプロジェクトで使用する依存ライブラリは以下の通りです:
python-dotenv: .env ファイルから環境変数をロードします。Bright Dataの認証情報やOpenAIのAPIキーなど、機密性の高い認証情報を安全に管理するために使用します。リクエスト:Bright Data の SERP API への HTTP リクエストを実行します。詳細については、Requests でプロキシを使用する方法のガイドを参照してください。langchain-community:これはLangChainフレームワークの一部で、相互運用可能なコンポーネントを連結して LLM を構築するツールのセットです。GoogleのSERPページからテキストを取得し、RAGに関連するコンテンツを生成するためにクリーニングするために使用されます。openai:OpenAI APIの公式Pythonクライアントライブラリです。与えられた入力とRAGのコンテキストに基づいて自然言語応答を生成するためにGPTモデルとのインタフェースに使用される。streamlit:PythonでインタラクティブなWebアプリケーションを構築するためのフレームワーク。ユーザーがGoogle検索クエリとAIプロンプトを入力し、結果を動的に表示できるUIを作成するのに便利です。
起動した仮想環境で、以下のコマンドを実行して、すべての依存関係をインストールする:
pip install python-dotenv requests langchain-community openai streamlit具体的には、langchain-communityのAsyncChromiumLoaderを使う:
pip install --upgrade --quiet playwright beautifulsoup4 html2textPlaywrightを正しく機能させるためには、ブラウザのインストールも必要です:
playwright installこれらのライブラリのインストールには時間がかかるので、気長に待とう。
素晴らしい!これでPythonロジックを書く準備ができました。
ステップ3: プロジェクトの準備
app.pyに以下のインポートを追加します:
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
stとしてstreamlitをインポートする次に、プロジェクトフォルダに.envファイルを作成して、すべての認証情報を保存します。これでプロジェクトの構造は以下のようになります:

.envから環境変数を読み込むようにpython-dotenvに指示するために、app.pyで以下の関数を使います:
load_dotenv()これで.envやシステムから環境変数をインポートできます:
os.environ.get("<ENV_NAME>")os.environ.get(“<ENV_NAME>”) ここで、osPython標準ライブラリをインポートした理由も説明します。
ステップ4: SERP APIの設定
冒頭で述べたように、検索エンジンの結果ページからコンテンツを取得し、Python RAGワークフローで使用するために、Bright DataのSERP APIを利用します。具体的には、SERP APIが返すウェブページのURLからテキストを抽出する。
SERP API をセットアップするには、公式ドキュメントを参照してください。または、以下の指示に従ってください。
アカウントを作成していない場合は、Bright Dataにサインアップしてください。ログイン後、アカウントダッシュボードに移動します:

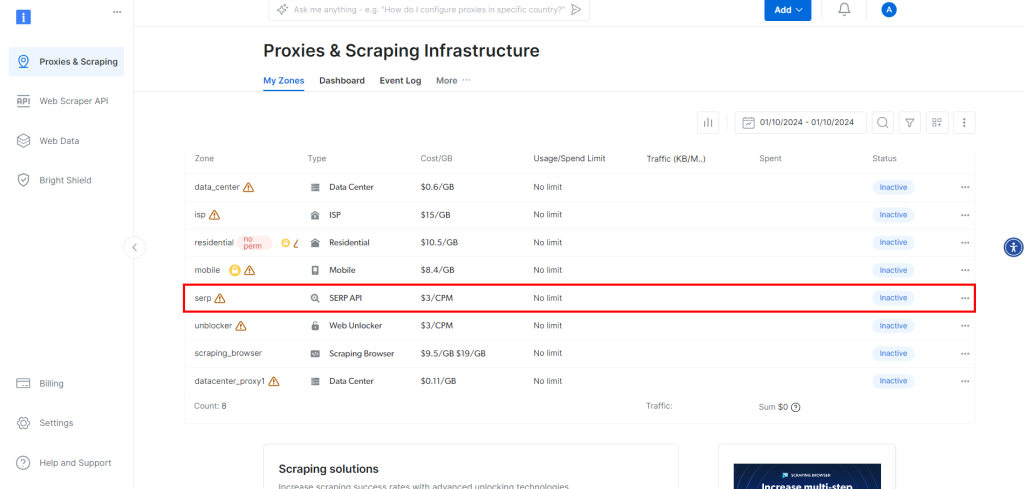
そこで、”プロキシ製品を取得 “ボタンをクリックします。
SERP API” の行をクリックします:
SERP API製品ページで、”Activate zone “を切り替えて製品を有効にする:
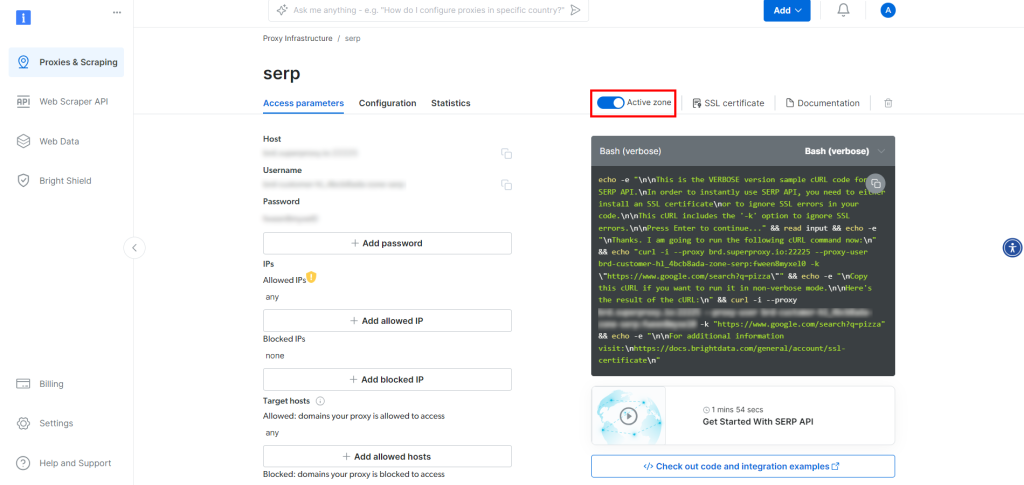
ここで、”Access parameters “セクションにあるSERP APIのホスト、ポート、ユーザー名、パスワードをコピーし、.envファイルに追加します:
bright_data_serp_api_host="<your_host>"
bright_data_serp_api_port=<your_port>
bright_data_serp_api_username="<your_username>"
bright_data_serp_api_password="<your_password>"<YOUR_XXXX>プレースホルダは、SERP APIページでBright Dataが提供する値に置き換えてください。
Access parameters “のホストは以下のような形式であることに注意してください:
brd.superproxy.io:33335以下のように分割する必要があります:
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335すごい!これでPythonでSERP APIを使えるようになりました。
ステップ #5: SERPスクレイピングロジックの実装
app.pyに以下の関数を追加して、Google SERPページから最初のnumber_of_urlsURLを取得します:
def get_google_serp_urls(query, number_of_urls=5):
# Bright DataのSERP APIリクエストを実行する
# JSONの自動解析機能付き
ホスト = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
パスワード = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
プロキシ = {"http": proxy_url, "https": proxy_url}.
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# パースされたJSONレスポンスを取得する
response_data = response.json()
# の "number_of_urls "数を抽出する。
# Google SERPのURLの数をレスポンスから抽出する
google_serp_urls = [] を返します。
if "organic" in response_data:
for item in response_data["organic"]:
itemに "link "があれば
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls].query引数に検索クエリを指定して、SERP APIにHTTP GETリクエストを行う。brd_json=1クエリパラメータを指定することで、SERP APIは検索結果を以下のフォーマットでJSONにパースします:
{
"general":{
"search_engine":"google"、
"results_cnt":1980000000,
「search_time":0.57,
"language":「en"、
「mobile": false、
「basic_view": false、
"search_type":「テキスト": false
"page_title":"ピザ - Google検索"、
"code_version":"1.90",
"タイムスタンプ":"2023-06-30T08:58:41.786Z"
},
"input":{
"original_url":"https://www.google.com/search?q=pizza&brd_json=1"、
"user_agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, like Gecko) Version/13.0.3 Safari/608.2.11"、
"request_id":"hl_1a1be908_i00lwqqxt1"
},
"オーガニック": [
{
"link":"https://www.pizzahut.com/"、
"display_link":"https://www.pizzahut.com"、
"title":"ピザハット|デリバリー&キャリーアウト - No One OutPizzas The Hut!"、
"image":"簡潔のため省略..."、
"image_alt":"www.pizzahut.com "のピザ、
"image_base64":"簡潔のため省略..."、
"rank":1,
「global_rank":1
},
{
"link":"https://www.dominos.com/en/"、
"display_link":"https://www.dominos.com ' ..."、
"タイトル":"ドミノ:ピザの宅配&キャリーアウト、パスタ、チキン&その他"、
"説明":"ドミノからピザ、パスタ、サンドウィッチ、その他をオンラインで注文。メニューの表示、店舗の検索、注文の追跡ができます。ドミノメールに登録 ..."、
"画像":画像": "簡潔のため省略..."、
"image_alt":"www.dominos.com "のピザ、
"image_base64":"簡潔のため省略..."、
"rank":2,
"global_rank":3
},
// 簡潔のため省略...
],
// 簡略化のため省略...
}関数の最後の数行は、結果のJSONデータから各SERP URLを取得し、最初のnumber_of_urlsURLのみを選択し、リストにして返します。
これらのURLからテキストを抽出する時間です!
ステップ #6: SERP URLからテキストを抽出する
それぞれのSERP URLからテキストを抽出する関数を定義します:
def extract_text_from_urls(urls, number_of_words=600):
# 与えられたURLにアクセスするよう、ヘッドレスChromeインスタンスに指示する
# 指定されたユーザーエージェントで
loader = AsyncChromiumLoader(
urls、
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0 Safari/537.36"、
)
html_documents = loader.load()
# 抽出されたHTMLドキュメントを処理してテキストを抽出する
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents、
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"]、
unwanted_tags=["a"]、
remove_comments=True、
)
# 各HTMLテキスト文書が数字だけを含むようにする
# 単語数
抽出されたテキストリスト
for doc_transformed in docs_transformed:
# テキストを単語に分割し、最初の number_of_words を連結する
words = doc_transformed.page_content.split()[:number_of_words].
抽出されたテキスト = "".join(words)
# 空のテキスト文書を無視する
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_listこの関数は
- ヘッドレスChromeブラウザのインスタンスを使用して、引数として渡されたURLからWebページを読み込みます。
- BeautifulSoupTransformerを使用して各ページのHTMLを処理し、特定のタグ(<p>、<h1>、<strong>など)からテキストを抽出します。
- 各ウェブページの抽出テキストを、引数
number_of_wordsで指定された語数に制限します。 - 各URLから抽出されたテキストのリストを返します。
ほとんどのウェブページからテキストを抽出するには、[“p”, “em”, “li”, “strong”, “h1”, “h2”]タグで十分であることを覚えておいてください。しかし、特定のシナリオでは、このHTMLタグのリストをカスタマイズする必要があるかもしれません。また、各テキスト項目の目標単語数を増減する必要があるかもしれません。
例えば、以下のウェブページを考えてみましょう:

そのページにこの関数を適用すると、次のようなテキスト配列になります:
[リサ・ジョンソン・マンデルの『トランスフォーマー・ワン』レビューは、これまで考えられなかったことを明らかにする:今年最高のアニメ映画のひとつだ!トランスフォーマー』映画についてこんなことを書くとは思ってもみなかったが、『トランスフォーマー・ワン』は実際、並外れた映画だ!..."]信じられない!完璧ではないとはいえ、AIモデルの水準としては高いクオリティである。
extract_text_from_urls()によって返されたテキスト項目のリストは、OpenAIモデルに与えるRAGコンテキストを表しています。
ステップ #7: RAGプロンプトの生成
AIプロンプトのリクエストとテキストコンテキストを、最終的なRAGプロンプトに変換する関数を定義します:
def get_openai_prompt(request, text_context=[]):
# デフォルトのプロンプト
prompt = request
# もしあれば、プロンプトにコンテキストを追加する
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "以下のコンテキストだけを使ってリクエストに答える。nnContext:n{context_string}nnRequest: {request}"
プロンプトを返すRAGコンテキストが指定されたときに前の関数によって返されるプロンプトは、このような形式を持っています:
以下のコンテキストのみを使用してリクエストに答えてください。
コンテキスト
Bla bla bla...
--------
Bla bla bla...
--------
Bla bla bla...
リクエスト: <YOUR_REQUESTステップ #8: GPTリクエストの実行
まず、app.pyファイルの先頭でOpenAIクライアントを初期化します:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))これはOPENAI_API_KEY環境変数に依存します。OPENAI_API_KEY環境変数は、システムの環境か.envファイルで直接定義することができます:
OPENAI_API_KEY="<YOUR_API_KEY>"
<YOUR_API_KEY>はOpenAI API キーの値に置き換えてください。取得方法がわからない場合は、公式ガイドに従ってください。
次に、OpenAIの公式クライアントを使って、GPT-4o miniAIモデルにリクエストを行う関数を書きます:
def interrogate_openai(prompt, max_tokens=800):
# 与えられたプロンプトでOpenAIモデルを質問する
response = openai_client.chat.completions.create(
model="gpt-4o-mini"、
messages=[{"role":"user", "content": prompt}]、
max_tokens=max_tokens、
)
return response.choices[0].message.contentOpenAI API でサポートされている GPT モデルであれば、どれでも設定できることに注意してください。
get_openai_prompt()が返すプロンプトに、指定したテキストコンテキストが含まれている場合にinterrogate_openai()をコールすると、意図したとおりに検索補強生成が行われます。
ステップ9: アプリケーションUIの作成
Streamlitを使用して、ユーザーが指定できるシンプルなフォームUIを定義します:
- SERP APIに渡すGoogle検索クエリ
- GPT-4o miniに送信するAIプロンプト
以下のコードで実現できます:
st.form("prompt_form"):
# 出力結果を初期化する
結果 = ""
final_prompt = ""
# ユーザーがGoogle検索クエリを入力するためのテキストエリア
google_search_query = st.text_area("Google Search:", None)
# AIプロンプトを入力するためのテキストエリア
request = st.text_area("AIプロンプト:", None)
# フォームを送信するためのボタン
submitted = st.form_submit_button("送信")
# もしフォームが送信されたら
if submitted:
# 与えられた検索クエリからGoogle SERPのURLを取得する
google_serp_urls = get_google_serp_urls(google_search_query)
# それぞれのHTMLページからテキストを抽出する
extracted_text_list = extract_text_from_urls(google_serp_urls)
# 抽出されたテキストをコンテキストとしてAIプロンプトを生成する
final_prompt = get_openai_prompt(request, extracted_text_list)
# 生成されたプロンプトでOpenAIモデルに質問する
result = interrogate_openai(final_prompt)
# 生成されたプロンプトを含むドロップダウン
final_prompt_expander = st.expander("AI最終プロンプト:")
final_prompt_expander.write(final_prompt)
# OpenAIモデルからの結果を書き込む
st.write(result)ほら、できた!Python RAGスクリプトの準備ができました。
ステップ #10: まとめる
app.pyファイルに以下のコードを記述します:
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
stとしてstreamlitをインポートする
# .env ファイルから環境変数を読み込む
load_dotenv()
# API キーで OpenAI API クライアントを初期化する
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5):
# Bright DataのSERP APIリクエストを実行します。
# JSON自動解析機能付き
ホスト = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
パスワード = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f "http://{username}:{password}@{host}:{port}"
プロキシ = {"http": proxy_url, "https": proxy_url}.
url = f "https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# パースされたJSONレスポンスを取得する
response_data = response.json()
# の "number_of_urls "数を抽出する。
# Google SERPのURLの数をレスポンスから抽出する
google_serp_urls = [] を返します。
if "organic" in response_data:
for item in response_data["organic"]:
itemに "link "があれば
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls].
def extract_text_from_urls(urls, number_of_words=600):
# 与えられたURLにアクセスするよう、ヘッドレスChromeインスタンスに指示する
# 指定されたユーザーエージェントで
loader = AsyncChromiumLoader(
urls、
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0 Safari/537.36"、
)
html_documents = loader.load()
# 抽出されたHTMLドキュメントを処理してテキストを抽出する
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents、
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"]、
unwanted_tags=["a"]、
remove_comments=True、
)
# 各HTMLテキスト文書が数字だけを含むようにする
# 単語数
抽出されたテキストリスト
for doc_transformed in docs_transformed:
# テキストを単語に分割し、最初の number_of_words を連結する
words = doc_transformed.page_content.split()[:number_of_words].
抽出されたテキスト = "".join(words)
# 空のテキスト文書を無視する
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_list
def get_openai_prompt(request, text_context=[]):
# デフォルトのプロンプト
prompt = request
# もしあれば、プロンプトにコンテキストを追加する
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f "以下のコンテキストだけを使ってリクエストに答える。nnContext:n{context_string}nnRequest: {request}"
プロンプトを返す
def interrogate_openai(prompt, max_tokens=800):
# 与えられたプロンプトでOpenAIモデルを質問する
レスポンス = openai_client.chat.completions.create()
model="gpt-4o-mini"、
messages=[{"role":"user", "content": prompt}]、
max_tokens=max_tokens、
)
return response.choices[0].message.content
# Streamlitアプリにユーザー入力用のフォームを作成する
with st.form("prompt_form"):
# 出力結果を初期化する
結果 = ""
final_prompt = ""
# ユーザーがGoogle検索クエリを入力するためのテキストエリア
google_search_query = st.text_area("Google Search:", None)
# AIプロンプトを入力するためのテキストエリア
request = st.text_area("AIプロンプト:", None)
# フォームを送信するためのボタン
submitted = st.form_submit_button("送信")
# もしフォームが送信されたら
if submitted:
# 与えられた検索クエリからGoogle SERPのURLを取得する
google_serp_urls = get_google_serp_urls(google_search_query)
# それぞれのHTMLページからテキストを抽出する
extracted_text_list = extract_text_from_urls(google_serp_urls)
# 抽出されたテキストをコンテキストとしてAIプロンプトを生成する
final_prompt = get_openai_prompt(request, extracted_text_list)
# 生成されたプロンプトでOpenAIモデルに質問する
result = interrogate_openai(final_prompt)
# 生成されたプロンプトを含むドロップダウン
final_prompt_expander = st.expander("AI最終プロンプト")
final_prompt_expander.write(final_prompt)
# OpenAIモデルからの結果を書き込む
st.write(result)信じられますか?150行以下のコードで、Pythonを使ってRAGを実現できるのです!
ステップ #11: アプリケーションのテスト
Python RAGアプリケーションを起動します:
streamlit run app.pyターミナルに次のような出力が表示されるはずです:
これで、Streamlitアプリをブラウザで見ることができます。
ローカルURL: http://localhost:8501
ネットワークURL: http://172.27.134.248:8501指示に従って、ブラウザでhttp://localhost:8501。以下が表示されるはずのものです:

お気づきのように、このフォームにはコードで定義した “Google Search: “と “AI Prompt: “のテキストエリア入力と、”Send “ボタンと “AI Final Prompt “ドロップダウンが含まれています。
以下のようにGoogle検索クエリを使用してアプリケーションをテストしてください:
トランスフォーマー・ワン レビューそして、次のようなAIプロンプトが表示されます:
映画「トランスフォーマー・ワン」のレビューを書いてください。送信」をクリックし、アプリケーションがリクエストを処理するまで待ちます。数秒後、このような結果が表示されるはずです:
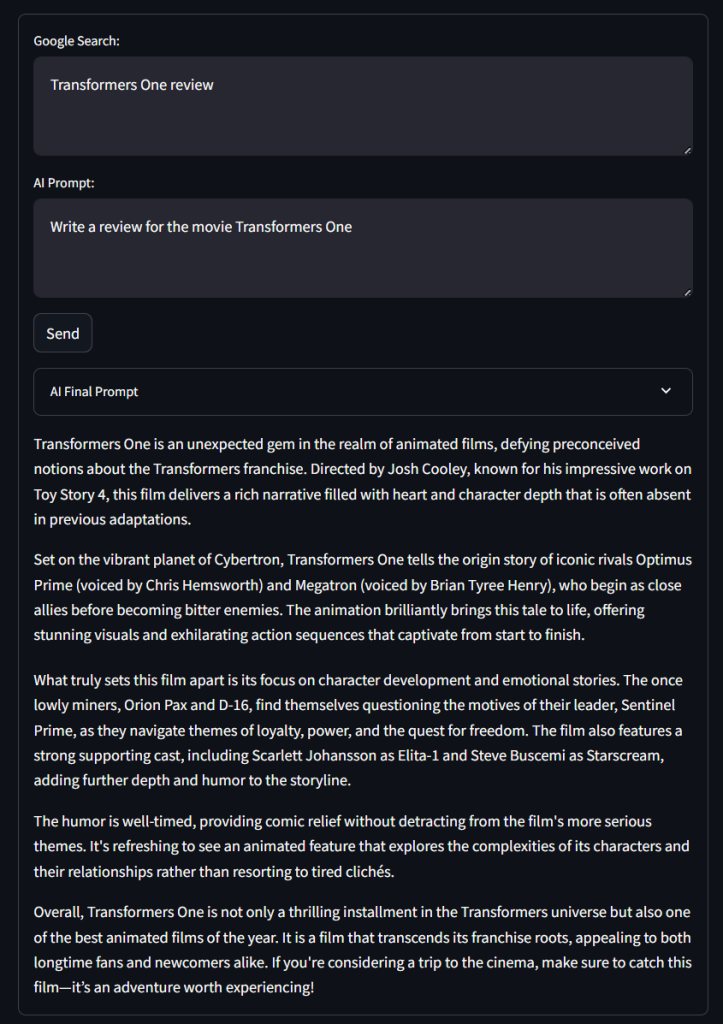
うわぁ!悪くないレビューだ…。
AI Final Prompt “ドロップダウンを展開すると、RAGのアプリケーションで使用される完全なプロンプトが表示されます。
これで完成です!GPT-4oミニでSERPデータを使ってPython RAGチャットボットを実装しました。
まとめ
このチュートリアルでは、RAGとは何か、AIモデルにSERPデータを与えることでどのように実現できるかを探りました。具体的には、SERPデータをスクレイピングし、結果の精度を向上させるためにGPTモデルでそれを使用するPython RAGチャットボットを構築することを学びました。
このアプローチの大きな課題は、Googleのような検索エンジンのスクレイピングである:
- 彼らは頻繁にSERPページの構造を変更する。
- 最も洗練されたボット対策によって保護されている。
- 大量のSERPデータを同時に取得するのは複雑で、多くのコストがかかる。
ここに示すように、Bright DataのSERP APIは、すべての主要検索エンジンからリアルタイムのSERPデータを手間なく取得するのに役立ちます。これはRAGや他の多くのアプリケーションをサポートします。今すぐ無料トライアルをご利用ください!
今すぐサインアップして、Bright Dataのプロキシサービスやスクレイピング製品の中から、お客様のニーズに最適なものを見つけてください。まずは無料トライアルから!






