
ウェブスクレイパーが失敗する原因は主に3つあります。JavaScriptによるページレンダリングでHTMLが空になる場合、フロントエンドの更新後にCSSセレクタが一致しなくなる場合、そしてCloudflareのようなアンチボット製品にリクエストがブロックされる場合です。Scraplingは、これら3つすべてに対応するオープンソースのPythonライブラリです。本ガイドでは、各部分を実際のウェブサイトで示し、本番規模でマネージドプロキシサービスが必要になる場面についても解説します。
TL;DR
Scrapling は、3つのフェッチャークラス(HTTP、Chromium、ステルスFirefox)、クラス名変更後も要素を再検索できるアダプティブパーサー、Scrapy スタイルのスパイダーを1つのPythonライブラリにまとめ、本番環境でのスクレイピングを実現します。
- 動作する最も低コストなフェッチャーを選び、ボット対策が施されたサイトではStealthyFetcherにエスカレートしてください。
- アダプティブセレクタは、最初に既知の正常なページのフィンガープリントを取得しておくことで、マークアップ変更後も復元できます。
- 本番環境では、チェックポイントと空結果アラームを備えたSpiderにパースロジックをラップしてください。
- ローカルのステルス機能が限界に達した場合(IPレピュテーション、エンタープライズ向けアンチボット製品)は、レジデンシャルプロキシまたはマネージドアンブロッキングエンドポイントに切り替えてください。
なぜ Scrapling なのか、requests + BS4 では不十分なのか?
requests と BeautifulSoup の組み合わせは、安定したマークアップを持つ静的ページには今でも有効です。問題は、スクレイパーをデプロイして継続的に動作させる必要が生じた瞬間に始まります。
フロントエンドチームが要素の名前や構造を変更すると、セレクタが一致しなくなります。今四半期はサーバーサイドレンダリングだったページが、来四半期にはクライアントサイドレンダリングに変わることもあります。1年間スクレイピングしてきたサイトが突然Cloudflare Bot Managementを導入し、すべてのリクエストがチャレンジページを返すようになることもあります。
これらは珍しい問題ではありませんが、それぞれに個別の対処が必要です。これらの修正をrequestsスクリプトにまとめようとすると、脆弱なtry/exceptブロックとセレクタのフォールバックの寄せ集めになりがちです(セレクタが頻繁に変わる低ボリュームのジョブでは、レンダリングされたHTML上でのLLM抽出パスが現実的な代替手段になっています。Scrapling は、ページあたりのコストが重要で大規模にレンダリングする場合にセットアップコストに見合います)。
Scrapling は一般的な修正を1つのライブラリに統合しています。
- 3つのフェッチャー、1つのAPI。TLSフィンガープリントなりすましを備えた高速HTTPクライアント(Fetcher)、Playwright駆動のブラウザ(DynamicFetcher)、そして一般的な自動化シグナルをマスクするパッチ済みFirefoxビルドであるCamoufoxベースのステルスブラウザ(StealthyFetcher)。これらはすべて同じパーサーオブジェクトを返すため、フェッチャーを変更してもセレクタコードを書き直す必要がありません。
- マークアップ変更に耐えるセレクタ。初回実行時に要素の構造的フィンガープリントを保存しておけば、その後の実行でクラス、ID、位置が変わっても同じ要素を見つけられます。
- 組み込みのSpiderフレームワーク。並列リクエスト、ドメインごとのスロットリング、一時停止と再開、robots.txt準拠、JSON/JSONLエクスポートがすべて組み込まれています。
- プロキシローテーション組み込み。ProxyRotatorヘルパーがすべてのセッションタイプと統合され、リクエストごとの上書きも可能です。
3つのフェッチャーは3つの難易度レベルに対応しているため、ターゲットを確認すれば通常どれを使うかは明らかです。
| ページの状態 | 使用するフェッチャー | リクエストあたりのコスト(時間・メモリ) |
|---|---|---|
| 静的HTML、アンチボットなし | Fetcher | ミリ秒、ブラウザ不要 |
| JavaScriptレンダリング、アンチボットなし | DynamicFetcher | 数秒、Chromiumメモリ |
| Cloudflareや同等のアンチボットの背後 | StealthyFetcher | 数秒、Camoufoxメモリ |
Scrapling のパーサーは Parsel や lxml とほぼ同等の速度で、大きなドキュメントではBeautifulSoupより高速です。5,000要素のドキュメントでは、公式ベンチマークによると約2msに対し、bs4 + lxmlは1.5秒以上かかります。小規模では大きな差はありませんが、月に数百万ページをパースするようになると積み重なります。
スクレイピングライブラリを選ぶ前に、まずターゲットが公式API、RSSまたはAtomフィード、サイトマップ、JSON-LDの埋め込み、公開データダンプを提供しているか確認してください。それらが存在する場合、APIコールは通常スクレイピングより速く安価です。スクレイピングが適切な答えとなるのは、APIがない場合、APIが有料またはユースケースで許容できないレート制限がある場合、または必要なデータがAPIで公開されていない場合です。
Scrapling がすべてに適しているわけではありません。
- 分散クラスター規模では、Scrapyクラスターやフレームワーク固有の分散ランナーの方がスケールします。
- curlと同等のスクレイピングでrequestsと5行のBeautifulSoupセレクタで十分な場合は、それらを使ってください。
- コードを書かずにマネージドスクレイパーが必要な場合は、ノーコードプラットフォームの方が適しています。
最も適しているのは、週をまたいで継続的に動作する本番スクレイパーです。メンテナンスが重要なほど複雑だが、クラスターが必要なほどではないケースです。
Scrapling は BSD-3 ライセンスです。本ガイドは v0.4.7(2026年4月)で検証済みです。ガイド内で使用しているAPI名は安定していますが、デフォルト値が異なる場合は新しいリリースの変更履歴を確認してください。型ヒントは公開APIをカバーしており、型付きパイプラインにレスポンスを渡す場合に役立ちます。
Scrapling のインストール
フェッチャーの依存関係は明示的なオプトインになっているため、パーサーのみが必要なマシンにPlaywrightやCamoufoxをインストールする必要はありません。フェッチャーエクストラとブラウザバイナリを含めてインストールします。
# pip
pip install "scrapling[fetchers]"
# または uv を使用(高速、ロックファイル対応)
uv pip install "scrapling[fetchers]"
scrapling install最初のコマンドはライブラリとHTTP・ブラウザフェッチャーをインストールします。2番目のコマンドはブラウザバイナリ(StealthyFetcher用のCamoufox、DynamicFetcher用のChromium)と必要なシステム依存関係をダウンロードします。Windowsでは、バイナリをシステム全体にインストールできるよう、初回は管理者としてターミナルを実行してください。
正常にインストールされたか確認するには:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://httpbin.org/headers')
print(page.status, page.json()['headers']['User-Agent'])正常にインストールされていれば、200とChromeスタイルのUser-Agent文字列が表示されます。User-Agentがpython-requests/x.xのように見える場合は、パーサーのみのビルドが実行されています。curl_cffi(FetcherのTLSなりすましを提供するライブラリ)もpipでインストールされるよう、[fetchers]エクストラを付けて再インストールしてください。
知っておくと便利なエクストラがさらに2つあります。
- scrapling[shell]はインタラクティブなIPythonシェル(scrapling shell)、curl-to-Scraplingコンバーター、そして1行でターミナルからコンテンツを取得するscrapling extract CLIを追加します。例えば、scrapling extract get https://example.com out.mdは、ページ(またはCSSセレクタで絞り込んだ部分)をMarkdownとして書き出します。
- scrapling[all]はAIエージェント統合用のMCP(Model Context Protocol)サーバーを含むすべてをインストールします。詳細はプロジェクトのドキュメントを参照してください。
scrapling[fetchers]で以下のすべての例をカバーできます。
最初のスクレイピング:静的ページから引用文を取得する
標準的なサンドボックスはquotes.toscrape.comで、プレーンなサーバーレンダリングHTMLで1ページあたり10件の引用文を表示します。JavaScriptもアンチボットもレート制限もないため、Fetcherパスの最初のテストとして最適です。
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/', stealthy_headers=True)
for quote in page.css('.quote'):
text = quote.css('.text::text').get()
author = quote.css('.author::text').get()
tags = quote.css('.tag::text').getall()
print(f"{author}: {text[:60]}... [{', '.join(tags)}]")Fetcher.get()はパーサーハンドルとしても機能するResponseオブジェクトを返します。stealthy_headers=Trueを設定すると、デフォルトのpython-requestsヘッダーセットではなく、User-Agent、Accept、Accept-Language、sec-ch-uaを含むリアルなブラウザヘッダーを送信します。サンドボックスでは不要ですが、本番サイトはヘッダーの一貫性でフィルタリングすることが多いです。
page.css(‘.quote’)は一致するすべての要素のSelectorsコンテナを返します。::text疑似要素はScrapy/Parselの慣習で、周囲のタグではなくテキストノードを直接抽出します。
出力は次のようになります。
Albert Einstein: "The world as we have created it is a process of our t... [change, deep-thoughts, thinking, world]
J.K. Rowling: "It is our choices, Harry, that show what we truly are,... [abilities, choices]
Albert Einstein: "There are only two ways to live your life. One is as t... [inspirational, life, live, miracle, miracles]
...Scrapyを使ったことがあれば、APIは意図的に馴染みやすく設計されています。BeautifulSoupを使ったことがあれば、Scrapling にはfind_allとfind_by_textもあります。
quotes = page.find_all('div', class_='quote')
einstein = page.find_by_text('Einstein', partial=True)実際のターゲットをスクレイピング:Hacker News のフロントページ
サンドボックスサイトは練習用に過ぎません。同じコード構造は実際のターゲットでも機能しますが、2つの変更が必要です。セレクタは実際のマークアップを調べて作成し、データはより多くのクリーニングが必要です。Hacker Newsは最初の実際のターゲットとして適しています(安定したHTML、アンチボットなし)。そのレイアウトには知っておく価値のある特殊な構造があります。各ストーリーは行で、メタデータ(ポイント、ユーザー、投稿時刻)は直後の兄弟行にあります。スクレイパーの実装:
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://news.ycombinator.com/', stealthy_headers=True)
stories = []
for athing in page.css('tr.athing'):
title = athing.css('.titleline a::text').get()
href = athing.css('.titleline a::attr(href)').get()
rank = athing.css('.rank::text').get()
# メタデータは次の兄弟行にある
subline = athing.next.css('.subline')
points_text = subline.css('.score::text').get() or '0 points'
user = subline.css('.hnuser::text').get()
age = subline.css('.age a::text').get()
stories.append({
'rank': int(rank.rstrip('.')) if rank else None,
'title': title,
'url': href,
'points': int(points_text.split()[0]),
'user': user,
'age': age,
'id': athing.attrib.get('id'),
})
print(f"scraped {len(stories)} stories")
for s in stories[:3]:
print(f" {s['rank']}. [{s['points']:>4}] {s['title'][:55]} by {s['user']}")このスニペットはサンドボックスの例では示されていない3つのパターンを使用しています。
- athing.nextは次の兄弟要素に移動します。構造的に関連する行がデータを共有する場合(古いテーブルベースのマークアップでよく見られるパターン)に便利です。
- .attrib.get(‘id’)は便利な::attr()ショートカットがない場合に生のHTML属性を読み取ります。
- or ‘0 points’のデフォルト値は、スコアなしでHacker Newsのフロントページに表示される求人投稿をカバーします。
実際のターゲットにはほぼ必ずこのような小さな不規則性があります(欠損フィールド、混在するアイテムタイプ、偶発的な不正な行)。セレクタを調整し、小さなデフォルト値を追加してください。コードの構造は同じままです。
find_similar を使ってセレクタなしでスクレイパーを書く
行セレクタを書く必要すらない場合もあります。表示されているテキストから始め、適切なコンテナまで上に移動し、Scrapling に構造的に類似したすべての要素を見つけさせます。
sample = page.find_by_text("1.") # ストーリー#1のランクラベル
row = sample.find_ancestor(lambda e: e.tag == "tr") # ストーリー行まで上に移動
peers = row.find_similar() # 構造的に類似したすべての行を検索
print(f"Found {len(peers) + 1} story rows without writing a CSS selector for the row")ライブのフロントページでは、これは30と表示されます(開始した行との構造的類似性で見つけた、すべてのストーリー行)。find_similarはオプションのsimilarity_threshold(デフォルト0.2;値が低いほど構造的一致が厳密)とignore_attributesリスト(デフォルトはhrefとsrc)を受け取り、URLの違いが一致を妨げないようにします。マークアップがセレクタのメンテナンスより速く変化するサイトでは、find_by_textとfind_similarの組み合わせがクラス名を追いかけるより安定しています。
テーブルの抽出:Wikipediaの国別データ
テーブルは実際のデータのもう一つの一般的な形式です(財務数値、スポーツ統計、参照リストなど)。Wikipediaは単一のtable.wikitableクラスの下にデータテーブルを提供しており、百科事典全体で一貫しているため、同じセレクタパターンがほぼどこでも機能します。国別人口のスクレイピング:
from scrapling.fetchers import Fetcher
URL = 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)'
page = Fetcher.get(URL, stealthy_headers=True)
table = page.css('table.wikitable')[0]
countries = []
for row in table.css('tbody tr'):
cells = row.css('td')
if len(cells) < 3: # ヘッダー行とグループ行をスキップ
continue
name = cells[0].css('a::attr(title)').get()
pop_text = cells[1].text.strip()
if not name or not pop_text:
continue
countries.append({
'country': name,
'population': int(pop_text.replace(',', '')),
})
print(f"scraped {len(countries)} country rows")
top = sorted(countries, key=lambda c: c['population'], reverse=True)[:3]
for c in top:
print(f" {c['country']:<20} {c['population']:>15,}")ここで重要なパターンが2つあります。cells[0].css(‘a::attr(title)’).get()はリンクのtitle属性から国名を抽出します。同じセル内の国旗アイコンノイズをスキップできるため、.textよりもクリーンです。if len(cells) < 3ガードは、ほぼすべてのサードパーティHTMLテーブルに現れる不規則なヘッダー行とグループ行をスキップします。
サイト変更に耐えるセレクタ
サイトがクラス名を.product-cardから.product-tileに変更したとします。スクレイパーは空の結果を返し始めます。パイプラインの後続ステップでデータ欠損が報告されるまで気づかないかもしれません。
Scrapling の解決策は、1つの設定オプションと2つのフラグです。それぞれが1つのことを行います。
| 記述内容 | 記述タイミング | 動作 |
|---|---|---|
| フェッチャー呼び出しにselector_config={‘adaptive’: True} | 常に(初回AND後続の実行) | 機能をオンにします。これがないと、Scrapling は他の2つのフラグを無視します。 |
| .css()にauto_save=True | 初回実行 | 一致した要素の構造的フィンガープリント(タグ、属性、位置、周囲のテキスト)を小さなローカルSQLiteファイルに記録します。 |
| .css()にadaptive=True | 後続の実行 | セレクタが何も返さない場合、保存されたフィンガープリントを使用して要素を再検索します。 |
エンドツーエンドのライフサイクル:
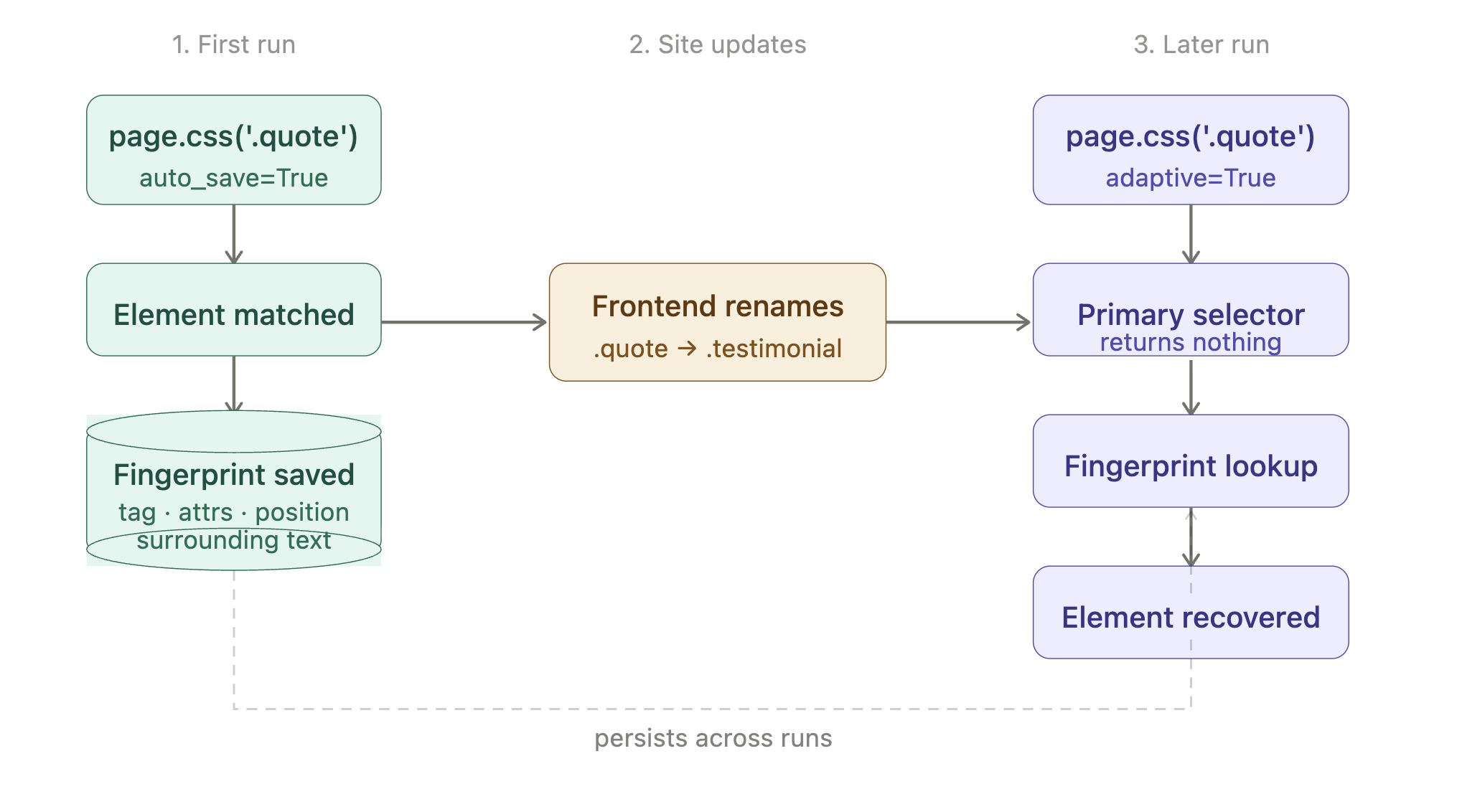
コードでは次のようになります。
from scrapling.fetchers import Fetcher
# 初回実行:フェッチャーでアダプティブを有効化し、auto_saveでフィンガープリントを保存
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', auto_save=True)
print(f"Found {len(quotes)} quotes on first run")
# 後続の実行:同じセレクタに加え、フォールバックパス用のadaptive=True。
# サイトが `.quote` を変更した場合、フィンガープリントで要素を復元します。
page = Fetcher.get(
'https://quotes.toscrape.com/',
selector_config={'adaptive': True},
)
quotes = page.css('.quote', adaptive=True)
print(f"Found {len(quotes)} quotes (recovered via fingerprint if needed)")フィンガープリントデータベースはスクリプトの隣に保存されるため、同じスクリプトが実行をまたいで保存されたフィンガープリントを再利用します。このパターンはすべてのフェッチャーで同じように機能します。フェッチ呼び出しでselector_configを一度渡し、.css()呼び出しでauto_saveとadaptiveを使用します。
フィンガープリントファイルはマイグレーションアーティファクトとして扱ってください。再現可能なCIの実行のためにコミットし、Dockerではボリュームとしてマウントし、検証していないページに対してauto_save=Trueを絶対に実行しないでください。auto_save付きでスクレイピングしたCAPTCHAウォールはフィンガープリントを汚染し、後続の実行で間違った要素を復元してしまいます。リセットするにはファイルを削除してください。
制限事項:アダプティブマッチングは、要素のコンテンツがほぼ安定していて、マークアップのみが変化した場合にのみ機能します。サイトがセクション全体を別の機能に置き換えた場合、どのアルゴリズムでも復元できません。フィンガープリントで対処できない方法でサイトが変更された場合に気づけるよう、空の結果セットにアラートを設定してください。
JavaScriptレンダリングページのスクレイピング
多くのサイトはほぼ空のHTMLスケルトンを送信し、実際のコンテンツをクライアントサイドでレンダリングします。これをテストする標準的なページはquotes.toscrape.com/jsで、静的バージョンと同じ引用文をJavaScriptで挿入します。Fetcherをこのページに向けると、結果は予測可能です。
from scrapling.fetchers import Fetcher
page = Fetcher.get('https://quotes.toscrape.com/js/')
print(page.css('.quote::text').getall())
# []空です。テキストはページロード時にブラウザが実行するvar data = […]というJavaScript変数内に格納されており、基本的なHTTPクライアントはそのスクリプトを実行しません。修正方法は、内部で実際のChromiumインスタンスを制御するDynamicFetcherを使用することです。
from scrapling.fetchers import DynamicFetcher
page = DynamicFetcher.fetch(
'https://quotes.toscrape.com/js/',
headless=True,
network_idle=True,
)
for quote in page.css('.quote'):
print(quote.css('.text::text').get())このスニペットの2つのフラグが重要です。headless=Trueはサーバーで使用する設定です。network_idle=Trueはネットワーク活動が停止するまで待ってからパーサーがページを読み取り、ほとんどのJavaScriptレンダリングページに対応します。ハイドレーション重視のSPA(Next.js、Remix、SvelteKit)では、Reactがまだハイドレーション中にネットワークがアイドル状態になることがあります。その場合は、既知の安定した要素でwait_selector=”…”を代わりに、または追加で渡してください。
ブラウザがページを取得したら、残りのAPIは静的なFetcherの例と同じです。
各ブラウザセッションは約1GBのメモリを使用します(本番スケーリングのセクションに詳細があります)。1日数百ページなら2GBのワーカーで十分ですが、1日数万ページを超えたらDynamicSessionでリクエスト間でブラウザを再利用するか、自社サーバー外で実行されるマネージドスクレイピングブラウザに移行してください。
StealthyFetcher でアンチボット防御を回避する
Cloudflare Turnstile、DataDome、HUMAN Bot Defender(旧PerimeterX)などの現代的なアンチボット製品は、リクエストが本物のブラウザから来ているかを判断するために数十のシグナルを確認します。そのリストには、TLSハンドシェイクフィンガープリント(JA3とJA4が一般的な形式)、HTTP/2フレーム順序、navigatorプロパティ(navigator.webdriver、プラグインリスト、言語ヘッダー)、canvasとWebGLハッシュ、タイミングパターンが含まれます。これらの静的チェックを通過すると、行動レイヤー(マウス移動のエントロピー、スクロールのリズム、滞在時間)が引き継ぐことが多いです。バニラのPlaywrightやSeleniumセッションはデフォルトでこれらのいくつかを露出させてしまうため、「Playwrightを追加したのにまだブロックされる」というのはスクレイピングフォーラムでよく見られる質問です。
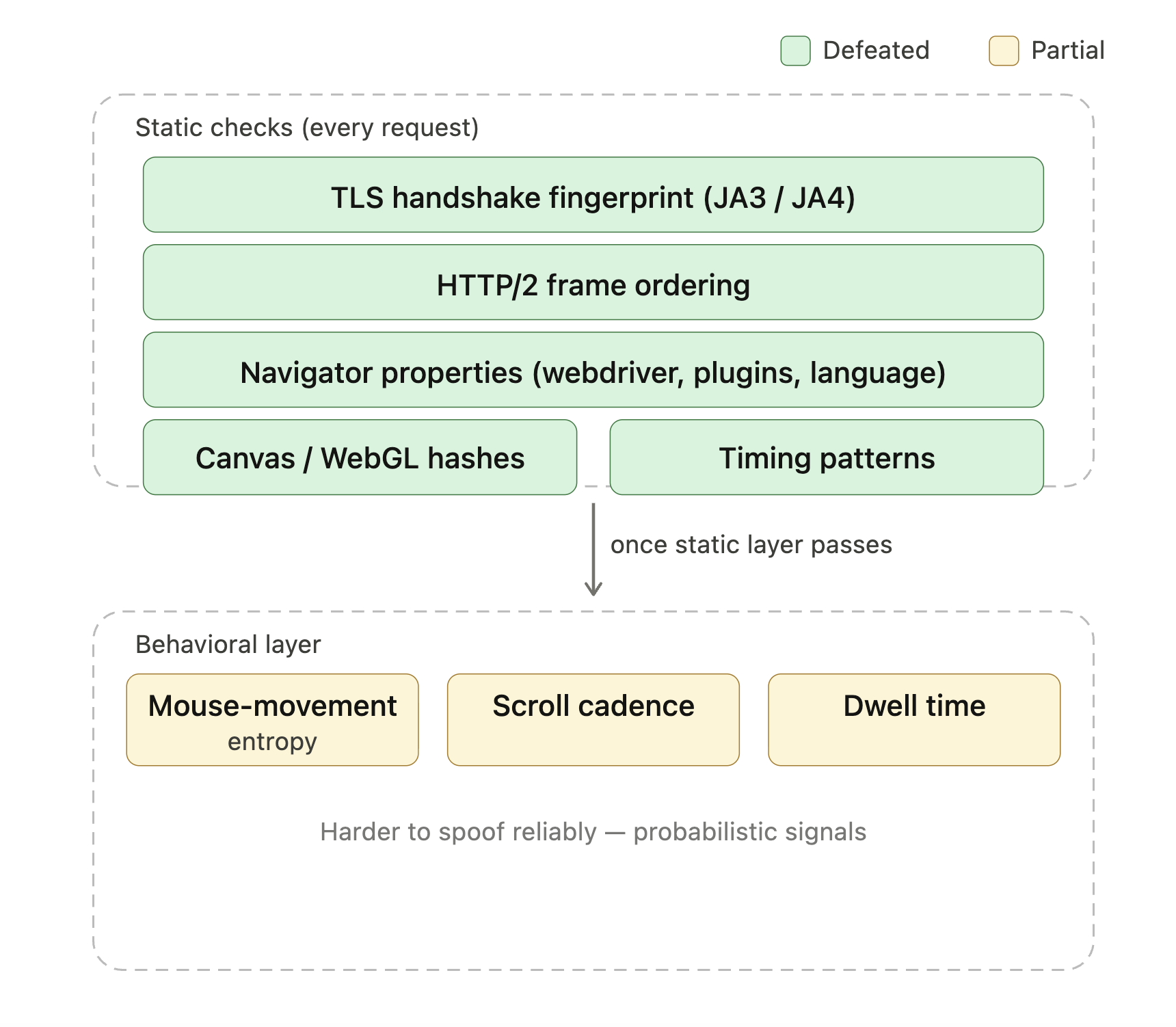
緑のレイヤーはStealthyFetcherのCamoufoxベースが単独で処理するもの、黄色は行動スコアリングが介入し、マネージドアンブロッキングがそのコストに見合う場所です。
StealthyFetcherは、これらのシステムが確認するヘッドレスブラウザとPlaywrightのフィンガープリントを打破するために、一般的な自動化シグナルをマスクするパッチ済みFirefoxビルドであるCamoufoxを使用します。Cloudflareの軽量なBot Managementティアでは、それだけで十分なことが多いです。Turnstileと行動スコアリングを組み合わせたエンタープライズティアのデプロイは、ローカルのステルスセットアップでもブロックされます。そこでマネージドアンブロッキングが実用的な答えになります(本番スケーリングのセクションで説明)。Turnstileチャレンジを明示的に実行するサイトでは、Scrapling には自動的にチャレンジを通過するsolve_cloudflareフラグがあります。
from scrapling.fetchers import StealthyFetcher
page = StealthyFetcher.fetch(
'https://nopecha.com/demo/cloudflare',
headless=True,
solve_cloudflare=True,
network_idle=True,
)
links = page.css('#padded_content a::attr(href)').getall()
print(f"Found {len(links)} links past the challenge")この例のページは、実際のTurnstileチャレンジを実行しているCloudflareの公開デモです。
いくつかの実際の制限を覚えておく価値があります。
- solve_cloudflareパスはマネージドTurnstileチャレンジに機能します。すべてのCAPTCHAカテゴリを処理することは保証していません。画像グリッドチャレンジ(古いreCAPTCHA、hCaptcha画像パズル)には、サードパーティのソルバーサービス(2Captcha、CapSolver)をページアクションに組み込むか、チャレンジレイヤーをエンドツーエンドで処理するマネージドアンブロッキングエンドポイントが必要です。
- ステルスバイパス技術は頻繁に変化します。一度きりのセットアップではなく、実際のターゲットで定期的な検証を計画してください。
- 結果はIPレピュテーションにも依存します。ターゲットでフラグが立っているデータセンターIPは、ブラウザフィンガープリントがどれだけ優れていても成功しません。
Cloudflareを使用していないサイトでは、チャレンジソルバーなしでステルスの恩恵を受けられます。
page = StealthyFetcher.fetch('https://example.com', headless=True)デフォルトのフィンガープリント保護が適用され、解決すべきチャレンジがなければsolve_cloudflareは何もしません。
知っておくべきパターン:隠れたブロック
アンチボットシステムは、明示的な403や503の代わりに、偽装されたブロックページ(CAPTCHAウォール、空の結果ページ、「人間であることを確認中」インタースティシャル)を含む200 OKを返すことがあります。空結果チェック(本番対応スクリプトで示す)は明らかなケースを検出します。構造が無傷でデータのみが間違っている隠れたブロックには、コンテンツレベルのチェックが必要です。レスポンスの長さをベースラインと比較する、特定の文字列(本文内の「captcha」、「are you human」、「access denied」)を探す、または既知の安定したアイテムの期待フィールドをサンプリングするなどです。完璧な方法はありませんが、組み合わせることで悪いデータが下流に流れる前にほとんどのサイレントブロックを検出できます。
Spiderフレームワークはこのためのis_blockedフックを公開しています。オーバーライドすると(これもasync def)、Scrapling はブロックされたレスポンスをmax_blocked_retries(デフォルト3)まで自動リトライします。
class MySpider(Spider):
max_blocked_retries = 5
async def is_blocked(self, response: Response) -> bool:
body = (response.body or b'').lower()
return b'are you human' in body or b'captcha' in bodyブロックリトライ数はクロール後にresult.stats.blocked_requests_countに表示されます。このカウンターを本番アラートメトリクスとして使用してください。
FetcherSession でログイン後のページをスクレイピングする
実際のターゲットはログインを必要とすることが多いです。FetcherSessionのパターンは、requests + Sessionで書くような標準的なCSRF + Cookieフローですが、Scrapling のパーサーがレスポンスを処理します。Quotes-to-Scrapeサンドボックスには/loginに動作するログインが含まれており、簡単なテストケースとして機能します。
from scrapling.fetchers import FetcherSession
with FetcherSession(impersonate='chrome') as session:
# 1. ログインページをGETしてCSRFトークンを取得
login_page = session.get('https://quotes.toscrape.com/login')
csrf = login_page.css('input[name="csrf_token"]::attr(value)').get()
# 2. 認証情報をPOST。Cookieはセッションに自動的に保持される。
session.post(
'https://quotes.toscrape.com/login',
data={'csrf_token': csrf, 'username': 'demo', 'password': 'demo'},
)
# 3. ログイン後にのみアクセスできるページを取得。
page = session.get('https://quotes.toscrape.com/')
if page.css('a[href="/logout"]').get():
print("Logged in OK")
# このサンドボックスのログイン後ページでは引用ごとにGoodreadsリンクが追加表示される
print("first goodreads link:", page.css('a[href*="goodreads"]::attr(href)').get())ここで重要な3つのことがあります。
- 個別のFetcher.get()呼び出しではなく、セッションを使用してください。FetcherSessionはリクエスト間でCookie(およびサーバーが返すSet-Cookie)を保持しますが、個別のFetcher.get()呼び出しは状態を共有しません。
- ログインフォームからCSRFトークンを読み取ってください。最新のフレームワークのほとんどはCSRFトークンを含み、それなしのPOSTリクエストを拒否します。フィールド名はフレームワークによって異なります。Djangoはcsrfmiddlewaretoken、Railsはauthenticity_tokenを使用し、多くのSPAはヘッダーでトークンを送信します。名前を仮定する前にフォームを確認してください。
- 処理を進める前にログインが成功したことを確認してください。ログアウトリンク、ナビバーのユーザー名、またはログインフォームの不在を確認してください。ログインがエラーなく失敗してパブリックページをスクレイピングすると、正しいように見えるが実際には間違ったデータが得られます。
2FA、OAuth、または長期トークンを発行するログインフローを持つサイトには、最もシンプルなアプローチは一度手動で(またはサイトのAPIを通じて)ログインし、結果のCookieまたはトークンを取得して再利用することです。FetcherSessionは構築時にcookies={…}辞書を受け取るため、保存されたCookieからセッションを初期化できます。
AsyncFetcher による並列フェッチ
URLのリストがあってすべてが必要な場合、同期のFetcherはそれらを直列化します。AsyncFetcherは同じAPIをコルーチンとして公開しているため、asyncio.gatherですべてのリクエストを同時に発行し、複数のネットワークラウンドトリップを並列実行できます(パーサーが添付されたAIOHTTPによる非同期スクレイピングと同じパターン)。
import asyncio
from scrapling.fetchers import AsyncFetcher
URLS = [f'https://quotes.toscrape.com/page/{i}/' for i in range(1, 11)]
async def fetch_all():
tasks = [AsyncFetcher.get(u, stealthy_headers=True) for u in URLS]
pages = await asyncio.gather(*tasks)
return [q.css('.text::text').get()
for p in pages for q in p.css('.quote')]
quotes = asyncio.run(fetch_all())
print(f"scraped {len(quotes)} quotes")同じ10ページの引用文で、これにより一般的な家庭用回線で直列の9秒のフェッチが約1秒に短縮されます。FetcherSession自体もasync withで動作するため、同期コードと同様にAsync呼び出し間でCookieとヘッダーを再利用できます。スロットリング、重複排除、再開を伴う完全なクロールには、Spiderフレームワークの方が通常適しています。AsyncFetcherは、既知のURLリストがあって並列に取得したい場合に重要です。
一つの落とし穴:素のasyncio.gather(*tasks)は最初の例外を即座に再送出しますが、他のタスクはバックグラウンドで実行を続け、作業を止めずにその結果にアクセスできなくなります。部分的な成功を望む本番リストには、return_exceptions=Trueを渡して結果をフィルタリングするか、asyncio.TaskGroup(3.11+)を使用してください。後者は最初の失敗時に兄弟をキャンセルし、タスクごとの明示的なエラー処理を提供します。
Spider フレームワークでマルチページクローラーを構築する
実際のスクレイピングジョブが1ページで完結することはほとんどありません。ページネーションを辿り、商品リンクを辿り、URLを重複排除し、リクエストレートを制限し、すべてをディスクに書き込み、何か失敗した場合に適切に再開します。Scrapling はこのためのSpiderフレームワークを提供しており、Spider/parse/yieldの形状はScrapyユーザーには馴染み深いものです。Scrapyのミドルウェア、パイプライン、シグナルに依存しないスパイダーはほぼそのまま移植できます。それ以外はScrapling のフックと非同期parseシグネチャに対して書き直しが必要です。
約1,000冊の書籍の50ページのページネーションカタログを持つbooks.toscrape.com上のシンプルなクローラー:
from scrapling.spiders import Spider, Response
class BooksSpider(Spider):
name = "books"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5 # ドメインごとのリクエスト間隔(秒)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
result = BooksSpider().start()
print(f"Scraped {len(result.items)} books")
result.items.to_jsonl("books.jsonl")このスニペットが手動で構築する必要がある処理をいくつか行っています。concurrent_requestsは8つのリクエストを同時実行し、books.toscrape.comでの完全なクロールを数分から数秒に短縮します。download_delayはドメインごとのギャップを強制し、単一ホストに過負荷をかけないようにします。response.follow()は現在のページに対して相対URLを解決し、最も一般的なページネーションバグ(相対的なnextリンクの結合を忘れること)を排除します。非同期のparseシグネチャにより、クロールループをブロックせずにページごとのI/O(詳細ページのフェッチ、外部API呼び出し)が可能です。
知っておく価値のある2つのパーサーメソッドがあります。.css()結果の.re_first(pattern)は最初の正規表現マッチを返し、フォーマットされたテキストから数値を抽出するのに便利です。
# '£51.77' を1つの式で51.77に変換
price = float(book.css('.price_color::text').re_first(r'[d.]+')).css()が返すSelectorsコンテナには述語を取る.filter()メソッドがあるため、2番目のループを書かずにScrapling がすでに持っているデータを絞り込めます。
expensive = response.css('article.product_pod').filter(
lambda b: float(b.css('.price_color::text').re_first(r'[d.]+')) >= 50
)
yield {'count_over_50': len(expensive)}サイトがフィルタリングしたいフィールドのURLフィルターパラメーターを公開していない場合に便利です。
最後のエクスポートは1行に1つのJSONオブジェクトを書き出し、ほとんどの下流パイプラインが期待する形式です。単一のJSON配列には.to_json()も使用できますし、process_itemフックをオーバーライドして独自のパイプラインを書くこともできます。
クロール全体の完了を待たずにスクレイピングされたアイテムをパイプラインに渡す必要がある場合、SpiderはAsync ジェネレーターとして.stream()を公開しています。
import asyncio
async def main():
async for item in BooksSpider().stream():
await write_to_kafka(item) # または任意の下流シンク
asyncio.run(main())長いクロールには、最初から一時停止・再開メカニズムを設定する価値があります。
result = BooksSpider(crawldir="./crawl_data").start()crawldirを渡すと、Scrapling は訪問済みURLと保留中のリクエストをディスクにチェックポイントします。Ctrl+Cを押すとクロールが適切にシャットダウンします。同じcrawldirで再度実行すると、停止した場所から再開します。50ページのクロールでは不要ですが、長期実行の本番クロール(カタログ更新、市場調査、価格監視)では、1日分の進捗を失うか失わないかの差になります。
ターゲットがよりリソース集約型のフェッチャーを必要とする場合、スパイダーはURLごとに異なるセッションにリクエストをルーティングできます。
from scrapling.spiders import Spider, Request, Response
from scrapling.fetchers import FetcherSession, AsyncStealthySession
class HybridSpider(Spider):
name = "hybrid"
start_urls = ["https://example.com/catalog"]
def configure_sessions(self, manager):
manager.add("fast", FetcherSession(impersonate="chrome"))
manager.add("stealth", AsyncStealthySession(headless=True), lazy=True)
async def parse(self, response: Response):
for link in response.css('a::attr(href)').getall():
if "/protected/" in link:
yield Request(link, sid="stealth", callback=self.parse_protected)
else:
yield Request(link, sid="fast", callback=self.parse)
async def parse_protected(self, response: Response):
yield {"url": response.url, "title": response.css('h1::text').get()}ルーティング図として可視化すると:
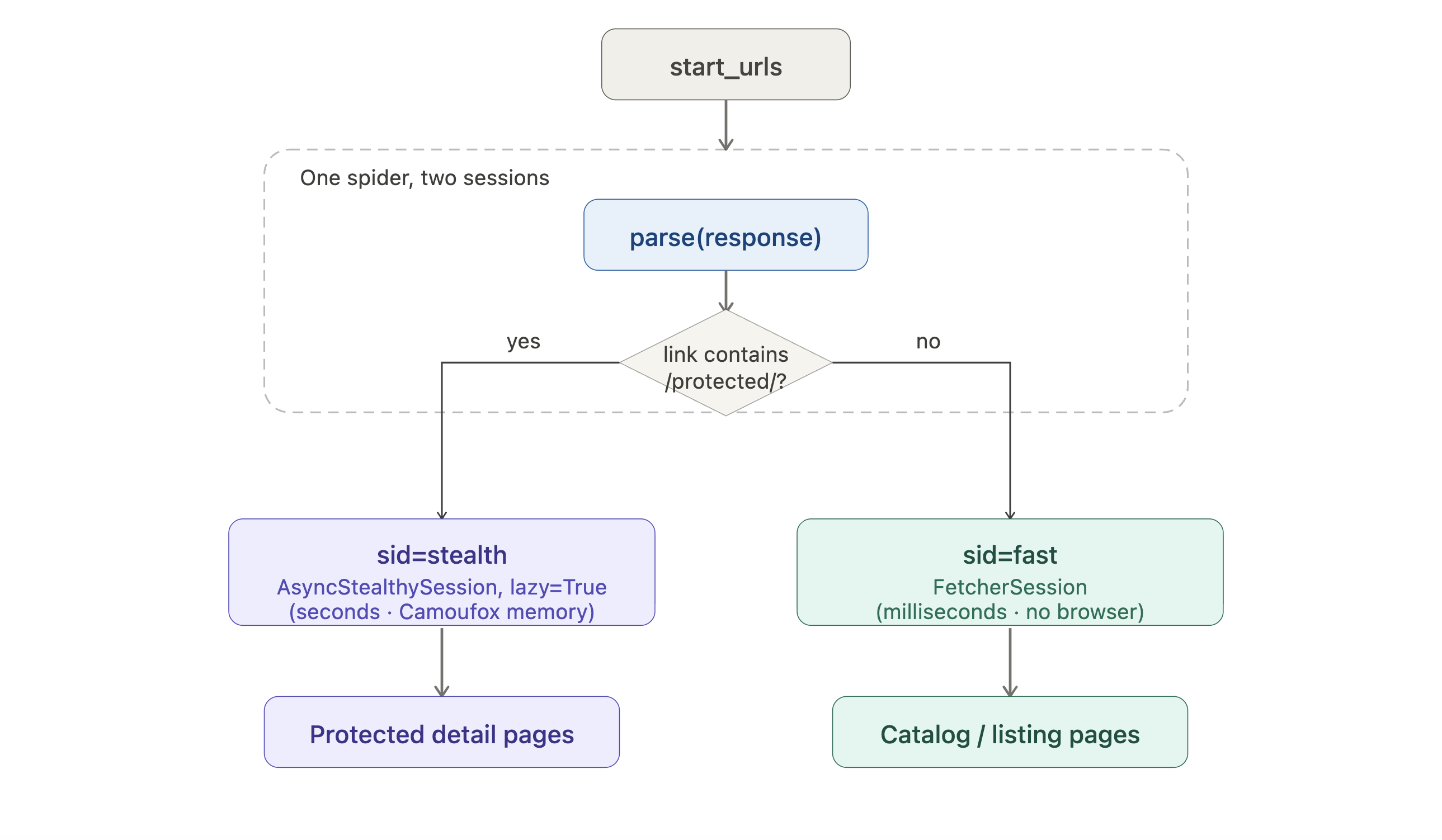
一覧ページは安価なHTTPパスを使用し、保護された詳細ページのみがブラウザのコストを支払います。lazy=Trueはブラウザの起動を最初のステルスリクエストが実際に発生するまで遅延させるため、一覧のみにアクセスするクロールはCamoufoxを開くことがありません。
この例のいくつかの詳細はコードからは明らかではありません。AsyncStealthySessionとAsyncDynamicSessionは長期間のブラウザセッションです。毎回新しいブラウザを起動するStealthyFetcher.fetch()やDynamicFetcher.fetch()の代わりに、多くのリクエストをまたいで再利用してください。
configure_sessionsはmanager(SpiderのセッションレジストリとなるSpiderのセッションレジストリ)を受け取ります。manager.add(name, session)は後でRequest(url, sid=name)でルーティングできる名前でセッションを登録します。ステルスセッションのlazy=Trueフラグは、最初のステルスリクエストを行うまでブラウザを開くことを遅らせ、パブリックページのみをリクエストするクロールはブラウザ起動のオーバーヘッドを発生させません。
fastセッションは一覧ページに安価なHTTPフェッチャーを使用し、保護された詳細ページのみが本物のブラウザを必要とします。そのようなルーティングを汎用クローラーに後から追加するのは困難です。
実際のサイトでのページネーション
実際のターゲットがbooks.toscrape.comのようにシンプルな.nextリンクを持つことはほとんどありません。よく見られるケースの大半は3つのパターンで処理できます。
- 番号付きページネーション(例:?page=1, 2, 3…)が最も簡単です。start_urlsでURLを直接生成するか、ループでparseからRequestオブジェクトをyieldします。
- 無限スクロールは通常JSON XHRエンドポイントに依存しています。DevTools → Networkを開き、ページをスクロールして、次のアイテムのバッチを返すリクエストを探してください。その後、そのエンドポイントをFetcherで呼び出します(ブラウザで各スクロールをレンダリングするよりはるかに安価)。
- 「もっと読み込む」ボタンはブラウザ内での実際のクリックが必要です。DynamicFetcherとStealthyFetcherは基礎となるPlaywrightページを受け取るpage_actionコーラブルを受け付けます。そこでボタンをクリックし、新しいコンテンツを待ち、関数が返るときにパーサーがページを読み取ります。
from scrapling.fetchers import DynamicFetcher
def click_load_more(page):
# `page` は基礎となるPlaywright同期Pageです。
for _ in range(5):
page.click("button.load-more")
page.wait_for_load_state("networkidle")
return page
result = DynamicFetcher.fetch(
"https://example.com/products",
page_action=click_load_more,
headless=True,
)
items = result.css(".product")ターゲットに合わせてセレクタとクリック回数を調整してください。非同期セッションクラス(AsyncDynamicSession、AsyncStealthySession)は同じコーラブルの非同期版を受け取ります。
本番環境向けにScraplingをスケールする:プロキシとアンブロッキング
本番環境のターゲットを大規模にスクレイピングすると、アーキテクチャが変わります。通常、3つの制約が同時に現れます。
- IPレピュテーション。同じサイトに1時間あたり1,000件のリクエストを送信する単一のレジデンシャルまたはデータセンターIPは、実際のユーザーのように見えません。ほとんどの本番ターゲットはレート制限し、スロットリングし、ブロックします。解決策はIPのプールで、リクエストまたはセッションごとにローテーションする、理想的にはレジデンシャル(実際の消費者接続)またはISP(アンチボットスコアリングではレジデンシャルに見えるキャリア割り当てのデータセンターIP)です。
- 地理的ターゲティング。一部のサイトは国、州、または都市によって異なるコンテンツ(または異なる価格)を提供します。これらのビューを再現するには、それらの場所のプロキシが必要です。
- CDNグレードのアンチボット。Cloudflareの基本的なTurnstileを超えて、Akamai Bot Manager(および厳格モードのDataDomeやHUMAN)はローカルのステルスセットアップをブロックすることが多いです。その時点では、独自のブラウザプールとチャレンジソルバーを維持するマネージドアンブロッキングエンドポイントが通常カスタムソリューションより優れています。
リトライ、タイムアウト、一時的なエラー
大規模ではネットワークエラーは避けられません。接続リセット、負荷下での偶発的な503、レート制限時の429などです。FetcherSessionは構築時にretries=、retry_delay=、timeout=を受け付けます(v0.4.7のデフォルト:3、1秒、30秒;インストール済みバージョンでhelp(FetcherSession)で確認)。ブラウザフェッチャー(StealthyFetcher、DynamicFetcher)は各.fetch()呼び出しでフェッチごとに同じパラメーターを受け付けます。
サーバーが429でRetry-Afterヘッダーを送信するターゲット固有のレート制限には、parseメソッドでそのヘッダーを読み取り、遅延付きでRequestを再yieldしてください。デフォルトのリトライはRetry-Afterを尊重しないため、それに依存すると同じ429が再び返されます。
ブラウザメモリ:具体的なサイジング数値
実際のブラウザを実行することはDynamicFetcherとStealthyFetcherを使用するコストです。一般的なコンテンツページ(約200KB HTML、メディア重視のSPAなし)では、単一のCamoufoxまたはChromiumセッションはLinux x86_64のヘッドレスモードで約700〜900MBのRAMを使用します。サイズは同じセッション内のフェッチ間でほとんど変化しないため、コンテナのサイジング時に並列ブラウザセッションあたり約1GBを計画してください。4GBのワーカーは3〜4の並列セッションを快適に実行でき、8GBのワーカーは6〜8を処理します。重いターゲット(画像が多いページ、密なSPA、数十の分析スクリプトを読み込むサイト)はセッションあたりのコストを1.2〜1.5GBまで押し上げます。リクエストごとにブラウザ起動の遅延が発生しないよう、一発の.fetch()呼び出しの代わりにセッションを再利用してください。
本番ボリュームで重要な2つのブラウザフェッチャーフラグがあります。block_ads=TrueはScrapling の組み込みブロックリスト(約3,500の広告とトラッカードメイン)を有効にし、無関係なネットワークリクエストをスキップすることで広告が多いサイトのフェッチ時間を削減します。dns_over_https=TrueはDNSクエリをCloudflareのDoH(DNS over HTTPS)エンドポイントを通じてルーティングし、レジデンシャルプロキシを通じてトラフィックをルーティングする際のDNSリークを防ぐのに役立ちます。どちらもDynamicFetcherとStealthyFetcherに適用されます(HTTPフェッチャーのリクエストはページリソースを読み込まないため、どちらのフラグも必要ありません)。
自己管理型プロキシローテーション
Scrapling には基本的なローテーションケースを直接処理するProxyRotatorヘルパーがあります。
from scrapling.fetchers import FetcherSession
from scrapling.engines.toolbelt.proxy_rotation import ProxyRotator
rotator = ProxyRotator([
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
"http://user:[email protected]:8000",
])
with FetcherSession(proxy_rotator=rotator) as session:
for url in target_urls:
page = session.get(url)
process(page)少数の静的プロキシを持つ小規模プロジェクトでは、それだけで十分です。それより大きなものには、通常リクエストごとに新鮮なIP(またはユーザーごとのスティッキーセッション)を提供する単一エンドポイントが必要で、そこで商用プロバイダーの利用が理にかなっています。
Bright Dataのレジデンシャルプロキシネットワークは同じプロキシURLパターンを使用してScraplingと統合します。ユーザー名とパスワード認証を持つ単一のHTTPプロキシエンドポイントで、ユーザー名には国やスティッキーセッションIDを含むネットワークが必要とするルーティングパラメーターが含まれています。値はBright Dataダッシュボードのゾーンのアクセスパラメーターページから取得します。
以下の例を実行するには:brightdata.comでサインアップし(無料トライアル、開始時にカード不要)、ダッシュボードでレジデンシャルプロキシゾーンを作成し、id、zone、passwordをプロキシURLにコピーします。レジデンシャルプロキシはゾーンのアクティベーション前に一度限りのKYC確認が必要です。リクエストごとにローテーションする典型的なセットアップは次のとおりです。
from scrapling.fetchers import FetcherSession
# <id>、<zone>、<password> をダッシュボードの値に置き換えてください。
PROXY = "http://brd-customer-<id>-zone-<zone>:<password>@brd.superproxy.io:33335"
with FetcherSession(impersonate="chrome", verify=False) as session:
page = session.get(
"https://quotes.toscrape.com/",
proxy=PROXY,
stealthy_headers=True,
)このセットアップに関する2つの注意事項:
- FetcherSessionコンストラクタではなく、リクエストごとにproxy=を渡してください。リクエストごとのproxy=はフェッチャータイプ全体で一貫して動作し、呼び出しごとのオーバーライドが最も簡単です。これはBright Dataだけでなく、任意のプロバイダーに適用されます。
- セッションにverify=Falseを設定してください。Bright Dataのレジデンシャルネットワークは自己署名証明書チェーンでプロキシホップを終端します(レジデンシャルプロキシサービスの標準)。検証はプロキシへのローカルホップのみで無効化されています。ターゲット接続はプロキシのCONNECTメソッドを通じて依然としてエンドツーエンドのTLSです。本番向けのよりクリーンなパターンは、Bright DataのCA証明書をトラストストアにインストールしてverify=Falseを完全に削除することです。レジデンシャルプロキシを経由しないコードパスにコピーペーストしないようにしてください。
スティッキーセッション(カートやログイン状態を保持するために複数のリクエストで同じIPを使用)では、ユーザー名にセッションIDが含まれます。例えばbrd-customer–zone–session-rand123のようになります。ローテーションロジックはプロバイダー側で実行され、ライブラリはURLを通常のHTTPプロキシとして扱います。
同じScrapling統合は、URLのゾーン名が変わるだけでBright Dataの他のプロキシタイプ(高ボリュームのレジデンシャル品質IPにはISPプロキシ、モバイル専用ビューにはモバイルプロキシ)でも機能します。
最も困難なターゲットには、Web Unlockerパターンを知っておく価値があります。ベンダーが新しい検出チェックを出荷するたびに独自のステルスブラウザを実行してフィンガープリントを更新する代わりに、フェッチャーを単一エンドポイントに向けます。レンダリング、フィンガープリント、IPローテーション、チャレンジ解決がリモートで行われます。Bright DataのWeb Unlockerはこのパターンを中心に構築されており、国レベルのターゲティングとベンダーが維持するドメインごとのアンブロッキングロジックを備えています。パースコードは同じままで、フェッチ行だけが変わります。
同じトレードオフはJavaScript重視のターゲットにも適用されます。CamoufoxやChromiumをローカルで実行することは中程度のボリュームには機能します。多くのブラウザコンテナを管理するようになったら、マネージドのBright Data スクレイピングブラウザがアンブロッキングとフィンガープリントのメンテナンスをチームから引き受けます。スクレイピングブラウザはPlaywrightが内部で使用するのと同じプロトコルであるWebSocketを通じて接続するリモートブラウザで、ローカルのChromiumブラウザと同じコードパスに組み込めます。
これらを選択する際に2つの実用的な注意事項があります。
- 問題が「レート制限を避けるためにリクエストごとに異なるIPが必要」なら、ローカルのFetcherまたはStealthyFetcherとレジデンシャルプロキシの組み合わせで通常十分です。ブロックを回避する作業ではなく、IPに対して料金を払っています。
- 問題が「解決できないCAPTCHAチャレンジが来ており、サイトが数週間ごとに保護を変更する」なら、マネージドアンブロッキングエンドポイントは通常、より高いリクエストあたりのコストを正当化するほどのエンジニアリング時間を節約します。
完全な本番対応 Scrapling スクリプト
基本的なBooksSpiderはサンドボックス上でクリーンに動作します。以下の番号付きコメントでマークされた5つの追加で本番対応になります。
import logging
from datetime import datetime, timezone
from scrapling.spiders import Spider, Response
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s %(levelname)s %(message)s",
)
log = logging.getLogger("books")
class BooksSpider(Spider):
name = "books_production"
start_urls = ["https://books.toscrape.com/"]
concurrent_requests = 8
download_delay = 0.5
robots_txt_obey = True # 1. robots.txtとCrawl-delayを尊重
async def parse(self, response: Response):
if response.status != 200: # 2. 非200レスポンスを明示的に処理
log.warning("Non-200 status %s on %s", response.status, response.url)
return
books_on_page = response.css('article.product_pod')
if not books_on_page: # 3. 古いセレクタを早期に検出
log.error("No books found on %s; selector may be outdated", response.url)
return
for book in books_on_page:
yield {
"scraped_at": datetime.now(timezone.utc).isoformat(), # 4. すべての行にタイムスタンプ
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
"rating": book.css('p.star-rating::attr(class)').get(),
"url": response.urljoin(book.css('h3 a::attr(href)').get()),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page:
yield response.follow(next_page, callback=self.parse)
if __name__ == "__main__":
spider = BooksSpider(crawldir="./crawl_data") # 5. 一時停止/再開のためのチェックポイント
result = spider.start()
log.info("Scraped %d items", len(result.items))
result.items.to_jsonl("books.jsonl")各追加が提供するもの:
- robots_txt_obeyはrobots.txtとCrawl-delayディレクティブを自動的に尊重します。
- ステータスチェックにより、スパイダーはサーバー側の失敗を「アイテムが見つからない」として処理する代わりに明示的に記録します。
- 空結果チェックにより、古いセレクタを3週間後にダウンストリームのレポートでデータがないと気づく代わりに、翌朝に検出できます。
- タイムスタンプは各行がスクレイピングされた時刻を記録し、日をまたいだ再実行が混在しないようにします。
- crawldirにより、Ctrl+C、カーネルパニック、ネットワーク切断がクロールの進捗を破壊しません。
同じスクリプトをレジデンシャルプロキシに切り替えるには、フェッチャーセッションを変更するだけです。Web Unlockerエンドポイントに切り替えるには、プロキシURLをアンブロッキングサービスに変更します。パースロジックとスパイダーの動作は同一のままです。
スケジュールで実行する
スクリプトをcron、systemdタイマー、またはAirflowやPrefectのようなオーケストレーターでラップしてください。前の実行の再開状態が新しい実行に持ち込まれないよう、実行ごとのcrawldir(例:./crawl_data/$(date +%Y%m%d))を使用し、出力をワーカーマシンのディスクに残すのではなく耐久性のあるストレージに送信してください。一般的なシンク:アドホック分析のためのpolarsやDuckDBで読み取るS3またはGCS上のParquet、またはリレーショナルルックアップが必要な場合はPostgresテーブル。
JSONLファイル以外の宛先には、Spiderのon_start、on_scraped_item、on_closeフックをオーバーライドします(3つすべてasync def)。on_startでデータベース接続またはメッセージキュープロデューサーを一度開きます。on_scraped_itemでyieldされる各アイテムを書き込みます(アイテムを返して転送するか、Noneを返してドロップ)。on_closeでクリーンアップします。
import asyncpg
from scrapling.spiders import Spider, Response
class BooksToPostgres(Spider):
name = "books_to_pg"
start_urls = ["https://books.toscrape.com/"]
async def on_start(self, resuming: bool = False) -> None:
self.db = await asyncpg.connect(DSN)
async def parse(self, response: Response):
for book in response.css('article.product_pod'):
yield {
"title": book.css('h3 a::attr(title)').get(),
"price": book.css('.price_color::text').get(),
}
async def on_scraped_item(self, item):
await self.db.execute(
"INSERT INTO books (title, price) VALUES ($1, $2)",
item["title"], item["price"],
)
return item # 下流にも転送
async def on_close(self) -> None:
await self.db.close()スクレイピングが壊れたとき:デバッグチェックリスト
本番スクレイパーはユニットテストが検出しない方法で失敗します。いくつかの簡単なチェックでほとんどに対処できます。
ブラウザを表示モードで開く。StealthyFetcher.fetch()またはDynamicFetcher.fetch()にheadless=Falseを渡し、ページがレンダリングされるのを見てください。CAPTCHAチャレンジ、リダイレクトチェーン、ジオIPリダイレクト、アンチボット検出ページは、何が起きているかを見ることができる場合にのみ明らかになることが多いです。ローカルで実行してください。ヘッドレスサーバーでは、代わりにpage_actionでスクリーンショットを保存してください。
レスポンスHTMLをディスクに保存する。セレクタが何も返さない場合、生のレスポンスを保存してブラウザで開いてください。
page = Fetcher.get('https://example.com')
with open('debug.html', 'wb') as f:
f.write(page.body)次に、パーサーが受け取ったものと期待したものを比較してください。ほとんどの場合、スクレイピングしたものがCAPTCHAウォール、別の言語へのリダイレクト、または一見成功ケースと同じに見える空結果ページであることが判明します。HTMLはステータスコードが誤解を招く場合でも真実を示します。
インタラクティブシェルを使用する。scrapling[shell]をインストールしてscrapling shellを実行してください。Scrapling がプリインポートされたIPythonセッションと2つの便利なヘルパーが読み込まれます。uncurl(…)はcurlコマンド(DevToolsのCopy as cURLから)をScrapling のRequestオブジェクトに解析し、送信されているものを正確に調べられます。curl2fetcher(…)は解析して実行し、パース済みのResponseを返します。DevToolsで任意のXHR呼び出しを右クリックしてcURLとしてコピーし、シェル内に貼り付けると、動作するScraplingフェッチができあがります。
すでに持っている要素からセレクタをリバースエンジニアリングする。find_by_text、ナビゲーション、または他の方法で要素を見つけた場合、.generate_css_selectorと.generate_xpath_selectorプロパティ(注:メソッドではなくプロパティ)がその要素の再利用可能なセレクタを提供します。
einstein = page.find_by_text("Albert Einstein")
print(einstein.generate_css_selector)
# body > div > div:nth-of-type(2) > div > div > span:nth-of-type(2) > small出力は人間が読みやすいものではありませんが、再利用可能で要素を移動しないコンテンツ変更に耐えます。
最初に確認すべきことについての注意。昨日動いていたスクレイパーが今日壊れた場合、最も速いチェックから最も遅いチェックの順で作業してください。空結果チェック(「セレクタが何も返さない」)、保存されたHTML(「ページは正常にレンダリングされたか?」)、次にheadless=False(「サイトはブラウザにチャレンジしているか?」)。
ターゲットへの追加リクエストを送信せずにparse()を繰り返し改善する。Spiderクラスにdevelopment_mode = Trueとdevelopment_cache_dir = “./_dev”を設定してください。
class MySpider(Spider):
name = "iter"
start_urls = ["https://target.example.com/"]
development_mode = True
development_cache_dir = "./_dev"
async def parse(self, response):
...最初の実行はネットワークにアクセスしてすべてのレスポンスをディスクにキャッシュします。後続の実行はキャッシュから再生します(サンドボックスサイトで約50msに対して1.2秒、約24倍の高速化)。セレクタを調整してデータをクリーニングしている間、テスト実行ごとにネットワークを待つ必要がなくなります。デプロイ前にdevelopment_modeをFalseに戻してください。
次のステップ
スクレイピングしたかった実際のターゲットを選び、それに機能する最も軽量なフェッチャーから始めてください。Fetcherは静的HTMLを処理します。コンテンツがJavaScriptでレンダリングされている場合はDynamicFetcherを、サイトがCloudflareや同等のアンチボットベンダーの背後にある場合はStealthyFetcherを使用してください。
継続的に実行する予定のものには、最初からこれらのデフォルトを設定してください。
- crawldir、robots_txt_obey=True、およびすべてのページでの空結果チェックを備えたSpiderにパースロジックをラップしてください。
- サイトがマークアップを変更する前に構造的フィンガープリントがディスクにあるよう、最初の実行でselector_config={‘adaptive’: True}とauto_save=Trueをオンにしてください。
- 共有インフラストラクチャではdownload_delayを少なくとも0.5〜1秒に設定し、429レスポンスにはparseメソッドでRetry-Afterヘッダーを読み取ってください。
ローカルのステルスが不十分になった場合(IPレピュテーション、並列数のスケーリング、CDNグレードのアンチボット)、各フェッチ呼び出しに単一のproxy=引数を追加することでレジデンシャルプロキシまたはマネージドアンブロッキングエンドポイントに切り替えてください。基本認証を持つHTTPプロキシを公開する任意のプロバイダーが同じように機能します。
完全なリファレンスについては、公式ドキュメントを参照してください。
FAQ
Scrapling を商用製品で使用できますか?
はい。ScraplingはBSD-3-Clauseライセンスのため、ロイヤリティや有料ティアなしに商用製品、SaaSバックエンド、または内部ツールの中に組み込めます。選択した任意のサードパーティサービス(レジデンシャルプロキシやCAPTCHAソルバーなど)のみ料金がかかります。Scrapling 自体のいかなる機能もライセンスによって制限されていません。
Scrapling はPlaywrightやSeleniumと比べてどうですか?
Scrapling はスクレイピング専用に構築されており、PlaywrightとSeleniumは汎用のブラウザ自動化ツールです。Scrapling はステルスパッチ済みのCamoufoxビルド(Playwright経由で駆動)、リトライ、セッション再利用、アダプティブセレクタをラップしているため、グルーコードが少なくなり、バニラのPlaywrightが露出するChromium-CDPフィンガープリントを回避できます。
Scrapling はCAPTCHAを解決しますか?
部分的に。StealthyFetcherはsolve_cloudflare=Trueの場合にマネージドのCloudflare Turnstileチャレンジを通過します。他のカテゴリ(画像グリッドhCaptcha、音声CAPTCHA、カスタムエンタープライズ)にはサードパーティのソルバー(2Captcha、CapSolver)またはチャレンジレイヤーをエンドツーエンドで処理するマネージドアンブロッキングエンドポイントが必要です。
Scrapling は Scrapy と連携できますか?
はい。ScraplingのパーサーはParselと同じ疑似要素構文(::text、::attr(href))を使用するため、Scrapling Selector はほとんどのセレクタを変更せずにScrapyコールバック内で機能します。Spider/parse/yieldの形状も引き継がれます。重いミドルウェアやパイプラインを使用しないスパイダーはほぼそのまま移植できます。
Scrapling を使うにはプロキシサービスが必要ですか?
いいえ、Scrapling は小規模なジョブではプロキシなしで動作します。本番ボリュームでは、完全な制御が必要な場合はScraplingの組み込みProxyRotatorと静的リストを使用し、リクエストごとの新鮮なIPや国レベルのターゲティングが必要な場合はマネージドのレジデンシャル、ISP、またはモバイルエンドポイントを使用してください。
Scrapling はDockerで動作しますか?
はい。プロジェクトはすべてのブラウザ依存関係がプリインストールされた公式Dockerイメージを提供しています。StealthyFetcherとDynamicFetcherでは、公式イメージにより、カスタムコンテナでCamoufoxとChromiumを動作させるのに約1時間かかる作業が省けます。基本的なFetcherには、標準的なPythonイメージが機能します。





