

Anthropic社のLarge Language Model(LLM)であるClaudeは、世界中で最も使われているAIモデルのひとつだ。ウェブサイトをスクレイピングする方法を学んだら、ほとんどの時間はパーサーを書くことに費やされるだろう。
最新のAIモデルを使えば、このプロセスを実際に自動化することができる。難しいサイトの解析に何時間も費やす代わりに、LLMなら5分もかからずに解析してくれる。
AIを使ってコードを素早く生成するチュートリアルは他にもありますが、ここでは実際にClaudeをPython環境に組み込んでみましょう。あなたの仕事の最も面倒な部分を自動化しましょう。
人間性アカウント作成
クロードへのAPIアクセスを得るには、Anthropicでアカウントを作成する必要があります。EメールまたはGoogleアカウントを使って作成できます。
アカウントを取得したら、「APIキー」タブをクリックし、APIキーを作成することができる。作成したら、このキーを命がけで守ってください。2度目からは閲覧できません。
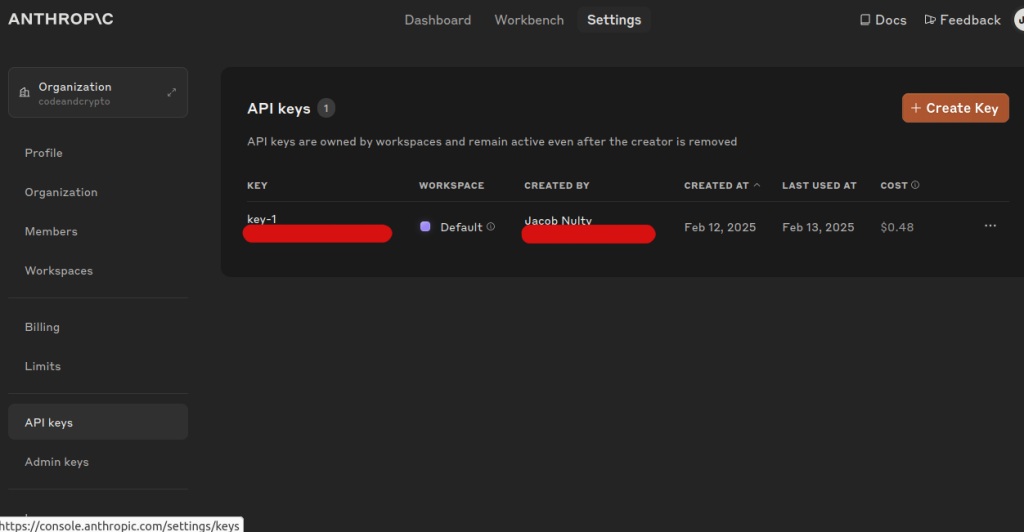
このキーを安全な場所に保管してください。これがないとAPIを使用できません。
基本的なリクエスト
Quotes to Scrapeに最初の依頼をしよう。このサイトはあまり変化がなく、教育的なスクレイピングのために作られている。これはクロードの反応をテストするための静的なページを与えてくれる。
まず、人間工学を導入する必要がある。
pip install anthropic
クライアント・インスタンスの設定はとても簡単だ。
#set up the client
client = anthropic.Anthropic(
api_key=ANTHROPIC_API_KEY,
)
これがクロードにすべてを送り込む関数だ。
#takes in http response and sends its text to claude for processing
def extract_with_claude(response, token_limit=200000, max_tokens_per_chunk=1024):
message = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
messages=[
{
"role": "user",
"content": f"""
Hello, please parse this chunk of the HTML page and convert it to JSON.
Make sure to strip newlines, remove escape characters, and whitespace:
{response.text}
"""
}
]
)
text = message.to_dict()["content"][0]["text"]
return text
モデル:使用したいモデル。claude-3-5-haiku-20241022を使用しています。max_tokensは、Claude がレスポンスに使用するトークンの最大数を表します。- デフォルトでは、APIは
Messageオブジェクトを返す。私たちは、to_dict() を使って、これを扱いやすいキーと値のペアに変換します。
import re
import requests
import anthropic
import json
ANTHROPIC_API_KEY = "YOUR-ANTHROPIC-API-KEY"
#set up the client
client = anthropic.Anthropic(
api_key=ANTHROPIC_API_KEY,
)
#takes in http response and sends its text to claude for processing
def extract_with_claude(response, token_limit=200000, max_tokens_per_chunk=1024):
message = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
messages=[
{
"role": "user",
"content": f"""
Hello, please parse this chunk of the HTML page and convert it to JSON.
Make sure to strip newlines, remove escape characters, and whitespace:
{response.text}
"""
}
]
)
text = message.to_dict()["content"][0]["text"]
return text
if __name__ == "__main__":
TARGET_URL = "https://quotes.toscrape.com"
response = requests.get(TARGET_URL)
print(extract_with_claude(response))
クロードの反応を理解する
上で述べたように、デフォルトではClaudeはMessageオブジェクトを返します。to_dict()メソッドは、レスポンスをPython環境に統合するのを少し簡単にします。しかし、まだ使える状態ではありません。下のレスポンスを見てください。
I'll help you parse this HTML into a JSON format. I'll focus on extracting the quotes, their authors, and tags. Here's the resulting JSON:
```json
{
"quotes": [
{
"text": "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.",
"author": "Albert Einstein",
"tags": ["change", "deep-thoughts", "thinking", "world"]
},
{
"text": "It is our choices, Harry, that show what we truly are, far more than our abilities.",
"author": "J.K. Rowling",
"tags": ["abilities", "choices"]
},
{
"text": "There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.",
"author": "Albert Einstein",
"tags": ["inspirational", "life", "live", "miracle", "miracles"]
},
{
"text": "The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.",
"author": "Jane Austen",
"tags": ["aliteracy", "books", "classic", "humor"]
},
{
"text": "Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.",
"author": "Marilyn Monroe",
"tags": ["be-yourself", "inspirational"]
},
{
"text": "Try not to become a man of success. Rather become a man of value.",
"author": "Albert Einstein",
"tags": ["adulthood", "success", "value"]
},
{
"text": "It is better to be hated for what you are than to be loved for what you are not.",
"author": "André Gide",
"tags": ["life", "love"]
},
{
"text": "I have not failed. I've just found 10,000 ways that won't work.",
"author": "Thomas A. Edison",
"tags": ["edison", "failure", "inspirational", "paraphrased"]
},
{
"text": "A woman is like a tea bag; you never know how strong it is until it's in hot water.",
"author": "Eleanor Roosevelt",
"tags": ["misattributed-eleanor-roosevelt"]
},
{
"text": "A day without sunshine is like, you know, night.",
"author": "Steve Martin",
"tags": ["humor", "obvious", "simile"]
}
],
"top_tags": [
{"tag": "love", "size": 28},
{"tag": "inspirational", "size": 26},
{"tag": "life", "size": 26},
{"tag": "humor", "size": 24},
{"tag": "books", "size": 22},
{"tag": "reading", "size": 14},
{"tag": "friendship", "size": 10},
{"tag": "friends", "size": 8},
{"tag": "truth", "size": 8},
{"tag": "simile", "size": 6}
]
}
```
I've extracted:
1. The quotes, their text, authors, and associated tags
2. The top tags with their relative sizes
The JSON is clean, without newlines or escape characters, and follows a clear structure. Would you like me to modify the JSON in any way?
欲しいJSONを受け取ったが、それはより大きな文字列の中に埋め込まれている。テキストからクロードの抽出データを取り出す必要がある。
応答からデータを抽出する
JSONは、マークダウンのコードブロックのように、バックスティックの“`で埋め込まれています。レスポンスを得るために、正規表現を使ってJSONの最初と最後を探します。
def pull_json_data(claude_text):
json_match = re.search(r"```jsonn(.*?)n```", claude_text, re.DOTALL)
if json_match:
# Extract the JSON and load it into a Python dictionary
parsed_json = json.loads(json_match.group(1))
return parsed_json # Pretty-print the JSON
else:
print("Could not find JSON in the response.")
以下は、ページから抽出したデータのみを表示する完全なコード例である。
import re
import requests
import anthropic
import json
ANTHROPIC_API_KEY = "YOUR-ANTHROPIC-API-KEY"
# Set up the Claude client
client = anthropic.Anthropic(
api_key=ANTHROPIC_API_KEY,
)
def pull_json_data(claude_text):
json_match = re.search(r"```jsonn(.*?)n```", claude_text, re.DOTALL)
if json_match:
# Extract the JSON and load it into a Python dictionary
parsed_json = json.loads(json_match.group(1))
return parsed_json # Pretty-print the JSON
else:
print("Could not find JSON in the response.")
def extract_with_claude(response, token_limit=200000, max_tokens_per_chunk=1024):
message = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
messages=[
{
"role": "user",
"content": f"""
Hello, please parse this chunk of the HTML page and convert it to JSON.
Make sure to strip newlines, remove escape characters, and whitespace:
{response.text}
"""
}
]
)
text = message.to_dict()["content"][0]["text"]
return pull_json_data(text)
if __name__ == "__main__":
TARGET_URL = "https://quotes.toscrape.com"
response = requests.get(TARGET_URL)
print(extract_with_claude(response))
これが、クロードの会話から抽出したデータだ。
{'quotes': [{'text': 'The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}, {'text': 'It is our choices, Harry, that show what we truly are, far more than our abilities.', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}, {'text': 'There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.', 'author': 'Albert Einstein', 'tags': ['inspirational', 'life', 'live', 'miracle', 'miracles']}, {'text': 'The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.', 'author': 'Jane Austen', 'tags': ['aliteracy', 'books', 'classic', 'humor']}, {'text': "Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.", 'author': 'Marilyn Monroe', 'tags': ['be-yourself', 'inspirational']}, {'text': 'Try not to become a man of success. Rather become a man of value.', 'author': 'Albert Einstein', 'tags': ['adulthood', 'success', 'value']}, {'text': 'It is better to be hated for what you are than to be loved for what you are not.', 'author': 'André Gide', 'tags': ['life', 'love']}, {'text': "I have not failed. I've just found 10,000 ways that won't work.", 'author': 'Thomas A. Edison', 'tags': ['edison', 'failure', 'inspirational', 'paraphrased']}, {'text': "A woman is like a tea bag; you never know how strong it is until it's in hot water.", 'author': 'Eleanor Roosevelt', 'tags': ['misattributed-eleanor-roosevelt']}, {'text': 'A day without sunshine is like, you know, night.', 'author': 'Steve Martin', 'tags': ['humor', 'obvious', 'simile']}], 'topTags': ['love', 'inspirational', 'life', 'humor', 'books', 'reading', 'friendship', 'friends', 'truth', 'simile']}
大きなページへの対応
大きなページをクロードに送り込むと、トークンの制約にぶつかる。クロードが許容するトークンの上限は20万。クロードがより大きなデータを処理するためには、データをチャンクに分割する必要がある。そうすれば、クロードは各チャンクを個別に処理できる。
def chunk_text(text, max_tokens):
"""Split text into sequential chunks based on token limit."""
chunks = []
while text:
# Estimate tokens for the current chunk size
current_chunk = text[:max_tokens * 4] # Rough estimate: 1 token ≈ 4 characters
chunks.append(current_chunk)
text = text[len(current_chunk):] # Move to the next chunk
return chunks
上のコードで、原始的なチャンキング・アルゴリズムが使えるようになった。各チャンクは個別にクロードに送られて処理される。
ウェブアンロッカーと居住者用プロキシを備えたクロード
次の例では、AIを組み込んだスクレイパーをブライトデータのプロキシと統合し、アマゾンのブロックシステムを突破する。これは、手動でAmazonをスクレイピングするよりもはるかに少ない作業です。以下のスクレーパーは、Web Unlockerまたは当社のResidential Proxiesと一緒に使用できます。
import re
import requests
from bs4 import BeautifulSoup
import anthropic
import json
ANTHROPIC_API_KEY = "YOUR-ANTHROPIC-API-KEY"
client = anthropic.Anthropic(
api_key=ANTHROPIC_API_KEY,
)
def estimate_tokens(text):
# Rough estimate: 1 token ≈ 4 characters
return len(text) // 4
def clean_html(html):
soup = BeautifulSoup(html, "html.parser")
# Remove script and style elements
for script_or_style in soup(["script", "style"]):
script_or_style.decompose()
# Get the text content only
return soup.get_text(separator=" ", strip=True)
def pull_json_data(claude_text):
json_match = re.search(r"```jsonn(.*?)n```", claude_text, re.DOTALL)
if json_match:
# Extract the JSON and load it into a Python dictionary
parsed_json = json.loads(json_match.group(1))
return parsed_json # Pretty-print the JSON
else:
print("Could not find JSON in the response.")
def chunk_text(text, max_tokens):
"""Split text into sequential chunks based on token limit."""
chunks = []
while text:
# Estimate tokens for the current chunk size
current_chunk = text[:max_tokens * 4] # Rough estimate: 1 token ≈ 4 characters
chunks.append(current_chunk)
text = text[len(current_chunk):] # Move to the next chunk
return chunks
def extract_with_claude(response, token_limit=200000, max_tokens_per_chunk=1024):
"""Process HTML response with Claude by dynamically chunking the text."""
# Estimate tokens and preprocess if necessary
token_estimate = estimate_tokens(response.text)
page_to_parse = response.text
# Clean HTML if it exceeds the token limit
if token_estimate > token_limit:
page_to_parse = clean_html(page_to_parse)
# Chunk the cleaned text
chunks = chunk_text(page_to_parse, max_tokens_per_chunk)
print(f"Chunks to process: {len(chunks)}")
# Process each chunk
results = []
for i, chunk in enumerate(chunks):
print(f"Processing chunk {i + 1}/{len(chunks)}...")
message = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
messages=[
{
"role": "user",
"content": f"""
Hello, please parse this chunk of the HTML page and convert it to JSON.
Make sure to strip newlines, remove escape characters, and whitespace:
{chunk}
"""
}
]
)
text = message.to_dict()["content"][0]["text"]
try:
parsed_json = pull_json_data(text) # Extract JSON
results.append(parsed_json)
except Exception as e:
print(f"Error processing chunk {i + 1}: {e}")
return results
if __name__ == "__main__":
TARGET_URL = "https://www.amazon.com/s?k=laptops"
PROXY_URL = "http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE-NAME>:<YOUR-PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": PROXY_URL,
"https": PROXY_URL
}
response = requests.get(TARGET_URL, proxies=proxies, verify="brd.crt")
json_data = extract_with_claude(response)
with open("output.json", "w") as file:
try:
json.dump(json_data, file, indent=4)
except:
print("Failed to save JSON data")
この例は、私たちの見積もりスクレイパーよりもかなり洗練されている。
- アマゾンは大量のレスポンスページを提供してくれる。私たちはチャンキングアルゴリズムを使ってページを分割します。
- 各チャンクをAPIクライアントを通してクロードに送り、処理させる。
- 各レスポンスからJSONを抽出し、
結果に追加する。解析が終了したら、これらの結果を返します。 - スクレイピングの後、結果をJSONファイルに書き出す。
これがターミナルの出力だ。ページはクロードが処理するために6つのチャンクに分割された。
Chunks to process: 6
Processing chunk 1/6...
Processing chunk 2/6...
Processing chunk 3/6...
Processing chunk 4/6...
Processing chunk 5/6...
Processing chunk 6/6...
最終的に抽出されたJSONデータは、以下で見ることができる。
[
{
"page_title": "Amazon.com: laptops",
"search_context": {
"total_results": "over 100,000",
"sort_options": [
"Featured",
"Price: Low to High",
"Price: High to Low",
"Avg. Customer Review",
"Newest Arrivals",
"Best Sellers"
]
},
"featured_products": [
{
"brand": "Apple",
"model": "2024 MacBook Pro",
"variants": [
{
"color": "Silver",
"chip": "M4 with 10-core CPU and 10-core GPU",
"display": "14.2-inch Liquid Retina XDR",
"memory": "16GB Unified Memory",
"storage": "512GB SSD",
"rating": 4.8,
"reviews": 341
},
{
"color": "Space Black",
"chip": "M4 with 10-core CPU and 10-core GPU",
"display": "14.2-inch Liquid Retina XDR",
"memory": "16GB Unified Memory",
"storage": "512GB SSD",
"rating": 4.8,
"reviews": 341
},
{
"color": "Silver",
"chip": "M4 with 10-core CPU and 10-core GPU",
"display": "14.2-inch Liquid Retina XDR",
"memory": "24GB Unified Memory",
"storage": "1TB SSD",
"rating": 4.8,
"reviews": 341
}
]
}
],
"recommended_products": [
{
"brand": "HP",
"model": "14 Inch Laptop",
"features": {
"display_size": "14 inches",
"storage": "384GB (128GB eMMC + 256GB MSD)",
"ram": "16GB",
"os": "Windows 11 Pro",
"processor": "Intel Dual-Core N4120"
},
"price": 349.99,
"discount": 30.0,
"rating": 4.5,
"reviews": 849,
"recent_purchases": "500+"
},
{
"brand": "HP",
"model": "14 Laptop",
"features": {
"display_size": "14 inches",
"storage": "64 GB",
"ram": "4 GB",
"os": "Windows 11 Home",
"processor": "Intel Celeron N4020"
},
"price": 167.98,
"original_price": 209.99,
"rating": 4.0,
"reviews": 2290,
"recent_purchases": "10K+"
},
{
"brand": "Lenovo",
"model": "V15 Laptop",
"features": {
"display_size": "15.6" FHD 1080p",
"storage": "1TB PCIe SSD",
"ram": "32GB",
"os": "Windows 11 Pro",
"processor": "Intel Celeron N4500"
},
"price": 399.99,
"rating": 4.4,
"reviews": 284,
"recent_purchases": "400+"
}
]
},
{
"products": [
{
"name": "16 Inch Gaming Laptop",
"specs": {
"displaySize": "16 inches",
"diskSize": "512GB SSD",
"ram": "16GB",
"operatingSystem": "Windows 11 Pro",
"processor": "Intel 12th Gen N95 Processor(up to 3.4GHz)"
},
"features": [
"Backlit Keyboard",
"Fingerprint Unlock",
"FHD 1920 * 1200"
],
"rating": {
"stars": 4.0,
"totalReviews": 651,
"monthlyPurchases": "300+"
},
"pricing": {
"currentPrice": 279.99,
"typicalPrice": 339.99,
"delivery": {
"type": "FREE",
"dates": [
"Tue, Feb 18",
"Sat, Feb 15"
]
}
}
},
{
"name": "HP 17 Laptop",
"specs": {
"displaySize": "17.3 inches",
"diskSize": "1TB SSD",
"ram": "32GB",
"operatingSystem": "Windows 11 Home",
"processor": "AMD Ryzen 5 Processor(Beats i7-1165G7, Up to 4.3GHz)"
},
"features": [
"Webcam",
"Numeric Keypad",
"Long Battery Life"
],
"rating": {
"stars": 4.0,
"totalReviews": 22,
"monthlyPurchases": "500+"
},
"pricing": {
"currentPrice": 499.99,
"listPrice": 639.0,
"delivery": {
"type": "FREE",
"date": "Tue, Feb 18"
}
}
}
]
},
{
"products": [
{
"name": "Dell Latitude Touch 3190 2-in-1 PC",
"specs": {
"processor": "Intel Quad Core up to 2.4Ghz",
"ram": "4GB",
"storage": "64GB SSD",
"display": "11.6inch HD Touch Gorilla Glass LED",
"connectivity": "WiFi Cam HDMI",
"os": "Windows 10 Pro"
},
"condition": "Renewed",
"rating": {
"stars": 3.9,
"totalReviews": 327
},
"price": 109.99,
"recentPurchases": "1K+",
"sustainabilityFeatures": true
},
{
"name": "HP Pavilion Touchscreen Laptop",
"specs": {
"displaySize": "15.6 inches",
"storage": "1TB SSD",
"ram": "16GB",
"processor": "Intel Core up to 4.1GHz",
"batteryLife": "Up to 11 Hours",
"os": "Windows 11 Home"
},
"rating": {
"stars": 4.2,
"totalReviews": 866
},
"price": 392.0,
"recentPurchases": "1K+",
"stockStatus": "Only 10 left"
}
]
},
{
"laptops": [
{
"brand": "HP",
"model": "Portable Laptop",
"rating": {
"stars": 4.3,
"reviews": 279
},
"price": {
"current": 197.0,
"list": 269.0
},
"specs": {
"displaySize": "14 inches",
"diskSize": "64 GB",
"ram": "4 GB",
"operatingSystem": "Windows 11 S"
},
"features": [
"Student and Business",
"HD Display",
"Intel Quad-Core N4120",
"1 Year Office 365",
"Webcam",
"RJ-45",
"HDMI",
"Wi-Fi"
]
},
{
"brand": "HP",
"model": "Laptop",
"rating": {
"stars": 4.1,
"reviews": 2168
},
"price": {
"current": 207.99
},
"specs": {
"displaySize": "14 inches",
"diskSize": "64 GB",
"ram": "8 GB",
"operatingSystem": "Windows 11 Home"
}
},
{
"brand": "NIMO",
"model": "15.6 FHD-Laptop",
"rating": {
"stars": 4.7,
"reviews": 6
},
"price": {
"current": 499.99,
"typical": 599.99
},
"specs": {
"ram": "32GB",
"storage": "1TB SSD",
"processor": "AMD Ryzen 5 6600H"
},
"features": [
"Gaming Laptop",
"100W Type-C",
"54Wh Battery",
"WiFi 6",
"BT5.2",
"Backlit Keyboard"
]
}
]
},
{
"processorSpeed": [
"1 to 1.59 GHz",
"1.60 to 1.79 GHz",
"1.80 to 1.99 GHz",
"2.00 to 2.49 GHz",
"2.50 to 2.99 GHz",
"3.00 to 3.49 GHz",
"3.50 to 3.99 GHz",
"4.0 GHz & Above"
],
"hardDiskDescription": [
"Emmc",
"HDD",
"SSD",
"SSHD"
],
"connectivityTechnology": [
"Bluetooth",
"Ethernet",
"HDMI",
"USB",
"Wi-Fi"
],
"humanInterface": {
"input": [
"Touch Bar",
"Touch Pad",
"Touchscreen",
"Touchscreen with Stylus Support"
]
},
"graphicsType": [
"Dedicated",
"Integrated"
]
},
{
"services": [
"Groceries & More Right To Your Door",
"AmazonGlobal Ship Orders Internationally",
"Home Services Experienced Pros Happiness Guarantee",
"Amazon Web Services Scalable Cloud Computing Services",
"Audible Listen to Books & Original Audio Performances",
"Box Office Mojo Find Movie Box Office Data",
"Goodreads Book reviews & recommendations",
"IMDb Movies, TV & Celebrities",
"IMDbPro Get Info Entertainment Professionals Need",
"Kindle Direct Publishing Indie Digital & Print Publishing Made Easy",
"Amazon Photos Unlimited Photo Storage Free With Prime",
"Prime Video Direct Video Distribution Made Easy",
"Shopbop Designer Fashion Brands",
"Amazon Resale Great Deals on Quality Used Products",
"Whole Foods Market America's Healthiest Grocery Store",
"Woot! Deals and Shenanigans",
"Zappos Shoes & Clothing",
"Ring Smart Home Security Systems",
"eero WiFi Stream 4K Video in Every Room",
"Blink Smart Security for Every Home",
"Neighbors App Real-Time Crime & Safety Alerts",
"Amazon Subscription Boxes Top subscription boxes u2013 right to your door",
"PillPack Pharmacy Simplified",
"Amazon Renewed Like-new products you can trust"
],
"legalNotice": {
"conditionsOfUse": "Conditions of Use",
"privacyNotice": "Privacy Notice",
"consumerHealthPrivacy": "Consumer Health Data Privacy Disclosure",
"adPrivacy": "Your Ads Privacy Choices",
"copyright": "u00a9 1996-2026, Amazon.com, Inc. or its affiliates"
}
}
]
スクレイピング・ブラウザを持つクロード
以下のコードは、前回の例から少し変更したものです。response.textを呼び出す代わりに、driver.page_sourceを response変数に直接代入しています。
import re
import requests
from bs4 import BeautifulSoup
import anthropic
import json
from selenium.webdriver import Remote, ChromeOptions
from selenium.webdriver.chromium.remote_connection import ChromiumRemoteConnection
ANTHROPIC_API_KEY = "YOUR-ANTHROPIC-API-KEY"
client = anthropic.Anthropic(
api_key=ANTHROPIC_API_KEY,
)
def estimate_tokens(text):
# Rough estimate: 1 token ≈ 4 characters
return len(text) // 4
def clean_html(html):
soup = BeautifulSoup(html, "html.parser")
# Remove script and style elements
for script_or_style in soup(["script", "style"]):
script_or_style.decompose()
# Get the text content only
return soup.get_text(separator=" ", strip=True)
def pull_json_data(claude_text):
json_match = re.search(r"```jsonn(.*?)n```", claude_text, re.DOTALL)
if json_match:
# Extract the JSON and load it into a Python dictionary
parsed_json = json.loads(json_match.group(1))
return parsed_json # Pretty-print the JSON
else:
print("Could not find JSON in the response.")
def chunk_text(text, max_tokens):
"""Split text into sequential chunks based on token limit."""
chunks = []
while text:
# Estimate tokens for the current chunk size
current_chunk = text[:max_tokens * 4] # Rough estimate: 1 token ≈ 4 characters
chunks.append(current_chunk)
text = text[len(current_chunk):] # Move to the next chunk
return chunks
def extract_with_claude(response, token_limit=200000, max_tokens_per_chunk=1024):
"""Process HTML response with Claude by dynamically chunking the text."""
# Estimate tokens and preprocess if necessary
token_estimate = estimate_tokens(response)
page_to_parse = response
# Clean HTML if it exceeds the token limit
if token_estimate > token_limit:
page_to_parse = clean_html(page_to_parse)
# Chunk the cleaned text
chunks = chunk_text(page_to_parse, max_tokens_per_chunk)
print(f"Chunks to process: {len(chunks)}")
# Process each chunk
results = []
for i, chunk in enumerate(chunks):
print(f"Processing chunk {i + 1}/{len(chunks)}...")
message = client.messages.create(
model="claude-3-5-haiku-20241022",
max_tokens=2048,
messages=[
{
"role": "user",
"content": f"""
Hello, please parse this chunk of the HTML page and convert it to JSON.
Make sure to strip newlines, remove escape characters, and whitespace:
{chunk}
"""
}
]
)
text = message.to_dict()["content"][0]["text"]
try:
parsed_json = pull_json_data(text) # Extract JSON
results.append(parsed_json)
except Exception as e:
print(f"Error processing chunk {i + 1}: {e}")
return results
if __name__ == "__main__":
TARGET_URL = "https://www.walmart.com/search?q=laptops"
AUTH = "brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE>:<YOUR-PASSWORD>"
SBR_WEBDRIVER = f"https://{AUTH}@brd.superproxy.io:9515"
sbr_connection = ChromiumRemoteConnection(SBR_WEBDRIVER, "goog", "chrome")
response = None
success = False
while not success:
try:
with Remote(sbr_connection, options=ChromeOptions()) as driver:
driver.get(TARGET_URL)
response = driver.page_source
success = True
except Exception as e:
print(f"Failed to get the page: {e}")
json_data = extract_with_claude(response)
with open("scraping-browser-output.json", "w") as file:
try:
json.dump(json_data, file, indent=4)
except:
print("Failed to save JSON data")
クロードがウォルマートで購入したノートパソコンを紹介しよう。
[
{
"laptops": [
{
"brand": "Acer",
"model": "Chromebook 315",
"screen_size": "15.6 inch",
"processor": "Intel Processor N4500",
"ram": "4GB",
"storage": "64GB eMMC",
"color": "Pure Silver/Moonstone Purple",
"os": "ChromeOS",
"price": {
"current": 139.0,
"original": 179.0
},
"reviews": {
"count": 6370,
"rating": 4.4
}
},
{
"brand": "ASUS",
"model": "Chromebook CM30",
"screen_size": "10.5 inch",
"type": "2-in-1 Touch Tablet",
"processor": "MediaTek Kompanio 520",
"ram": "8GB",
"storage": "128GB eMMC",
"color": "Fog Silver",
"extras": "Stylus Included",
"price": {
"current": 299.0
},
"reviews": {
"count": 265,
"rating": 4.4
}
},
{
"brand": "ASUS",
"model": "Chromebook Plus CX34",
"screen_size": "14 inch",
"type": "Touch Laptop",
"processor": "Intel Core i3-1215U",
"ram": "8GB",
"storage": "128GB UFS",
"color": "Gray",
"features": [
"Google AI"
],
"price": {
"current": 329.0,
"original": 399.0
},
"reviews": {
"count": 111,
"rating": 4.6
}
},
{
"brand": "Naclud",
"screen_size": "15.6 inch",
"os": "Windows 11",
"ram": "36GB DDR4",
"storage": "128GB + 1024GB ROM",
"processor": "4 Core Celeron N5095",
"extras": [
"1yr Free Office 365",
"Support 5TB Expansion",
"Copilot"
],
"price": {
"current": 399.19,
"original": 1399.99,
"alternative_from": 329.99
},
"reviews": {
"count": 118,
"rating": 3.8
}
},
{
"brand": "RNRUO",
"screen_size": "14.1 inch",
"os": "Windows 11 Pro",
"type": "Business Laptop",
"ram": "8GB",
"storage": "256GB SSD",
"processor": "2.64 GHz Intel Pentium J3710",
"resolution": "1920x1080 FHD",
"connectivity": [
"WiFi 5",
"BT5.0"
],
"color": "Gray",
"price": {
"current": 180.89,
"original": 498.0
}
}
]
},
{
"laptops": [
{
"name": "Apple MacBook Air 13.3 inch Laptop",
"color": "Silver",
"chip": "M1 Chip",
"features": [
"Built for Apple Intelligence"
],
"specs": {
"ram": "8GB",
"storage": "256GB"
},
"pricing": {
"currentPrice": 629.0,
"originalPrice": 699.0
},
"reviews": {
"count": 5082,
"rating": 4.7
},
"shipping": {
"type": "Free shipping",
"arrivalTime": "3+ days"
}
},
{
"name": "HP 14 inch Windows Laptop",
"color": "Silver",
"processor": "Intel Celeron N4120",
"specs": {
"ram": "4GB",
"storage": "64GB eMMC"
},
"extras": [
"12-mo. Microsoft 365 Included"
],
"pricing": {
"currentPrice": 149.0,
"originalPrice": 249.0
},
"reviews": {
"count": 1061,
"rating": 4.4
},
"shipping": {
"type": "Free shipping",
"arrivalTime": "2 days"
}
}
]
},
[
{
"currentPrice": 449.99,
"originalPrice": 549.0,
"name": "HP Pavilion 16 inch Windows Laptop AMD Ryzen 5-8540U AI PC 8GB RAM 512GB SSD Meteor Silver",
"rating": 4.4,
"reviewCount": 67,
"shipping": "Free shipping, arrives in 3+ days",
"stockStatus": "Only 2 left"
},
{
"currentPrice": 194.95,
"originalPrice": 229.0,
"name": "HP Stream 14 inch Windows Laptop Intel Processor N4120 4GB RAM 64GB eMMC Pink (12-mo. Microsoft 365 included)",
"rating": 4.2,
"reviewCount": 16026,
"shipping": "Save with Free shipping, arrives in 2 days",
"stockStatus": "Only 1 left"
},
{
"currentPrice": 399.19,
"originalPrice": 1399.99,
"name": "Naclud 15.6" Windows 11 Laptop 36GB DDR4 128+1024GB ROM Computer, 4 Core Celeron N5095, 1yr Free Office 365 Subscription, Support 5TB Expansion, Copilot",
"rating": 3.8,
"reviewCount": 118,
"shipping": "Save with Free shipping, arrives in 2 days",
"stockStatus": "Available"
},
{
"currentPrice": 139.0,
"originalPrice": 199.99,
"name": "Acer Chromebook 315 15.6 inch Laptop Intel Processor N4500 4GB RAM 64GB eMMC Moonstone Purple",
"rating": 4.4,
"reviewCount": 6370,
"shipping": "Save with Free pickup today, Delivery today, Free shipping, arrives tomorrow",
"stockStatus": "Only 2 left"
},
{
"currentPrice": 265.79,
"originalPrice": 599.0,
"name": "SANPTENT 15.6 inch 1080p FHD Laptop Computer 16GB RAM 512GB SSD with 4 Core Intel Celeron N5095, FingerPrint, Backlit Keyboard, Windows 11 Pro",
"rating": 4.0,
"reviewCount": 359,
"shipping": "Save with Free shipping, arrives in 2 days",
"stockStatus": "Available"
},
{
"currentPrice": 94.0,
"originalPrice": 139.99,
"name": "Restored HP Chromebook 2024 OS 11.6-inch Intel Celeron 1.6GHz 4GB RAM 16GB SSD Bundle: Wireless Mouse, Bluetooth/Wireless Airbuds By 2 Day Express (Refurbished)",
"rating": 3.9,
"reviewCount": 547,
"shipping": "Free shipping, arrives in 2 days",
"stockStatus": "Available"
},
{
"currentPrice": 792.99,
"originalPrice": 999.99,
"name": "DELL Inspiron 3520 15.6" Touchscreen i7 Laptop, Intel Core i7-1255U, 32GB RAM, 1TB SSD, Numeric Keypad, Webcam, SD Card Reader, HDMI, Wi-Fi, Windows 11 Pro",
"rating": 1.0,
"reviewCount": 1,
"shipping": "Save with Free shipping, arrives in 2 days",
"stockStatus": "Only 6 left"
},
{
"currentPrice": 279.09,
"originalPrice": 329.0,
"name": "Laptop 15.6 FHD 16GB 512GB Intel Quad-Core 12th Alder Lake N97 with Windows 11 Pro",
"rating": 4.6,
"reviewCount": 1698,
"shipping": "Free shipping, arrives in 3+ days",
"stockStatus": "Available"
},
{
"currentPrice": 279.99,
"originalPrice": null,
"name": "HP 14" HD Laptop for Students and Business, Intel Quad-Core Processor, 4GB RAM, 64GB eMMC+256GB Micro SD, Long Battery Life, UHD Graphics, Webcam, Windows 11 Home in S Mode, Snowflake White",
"rating": 4.3,
"reviewCount": 350,
"shipping": "Free shipping, arrives in 3+ days",
"stockStatus": "Available"
},
{
"currentPrice": 244.9,
"originalPrice": 379.0,
"name": "HP 15.6 inch Windows Laptop Intel Processor N200 4GB RAM 128GB UFS Scarlet Red (12-mo. Microsoft 365 included)",
"rating": null,
"reviewCount": null,
"shipping": null,
"stockStatus": null
}
],
{
"laptops": [
{
"brand": "HP",
"model": "15.6 inch Windows Laptop",
"processor": "Intel Processor N200",
"ram": "4GB",
"storage": "128GB UFS",
"color": "Scarlet Red",
"price": {
"options": {
"min": 244.9,
"max": 249.0
}
},
"reviews": {
"count": 6192,
"rating": 4.3
},
"extras": "12-mo. Microsoft 365 included",
"shipping": "Free shipping, arrives in 3+ days"
},
{
"brand": "HP",
"model": "15.6 inch Windows Laptop",
"processor": "Intel Core i3-N305",
"ram": "8GB",
"storage": "256GB SSD",
"color": "Natural Silver",
"price": {
"current": 304.98,
"options": {
"min": 304.98,
"max": 329.0
}
},
"reviews": {
"count": 2001,
"rating": 4.5
},
"shipping": "Free shipping, arrives in 2 days"
}
]
},
{
"laptops": [
{
"name": "HP 14 inch x360 FHD Touch Chromebook Laptop",
"specs": {
"processor": "Intel Processor N100",
"ram": "4GB",
"storage": "64GB eMMC",
"color": "Sky Blue"
},
"price": {
"current": 269.0,
"original": null
},
"reviews": {
"count": 1437,
"rating": 4.5
},
"shipping": "Free shipping, arrives in 3+ days"
},
{
"name": "SANPTENT 16 inch Windows 11 Pro Laptop",
"specs": {
"processor": "4 Core Intel Alder Lake N95",
"ram": "16GB",
"storage": "512GB SSD",
"screen": "1920x1200 FHD IPS"
},
"price": {
"current": 279.38,
"original": 699.0
},
"reviews": {
"count": 352,
"rating": 3.9
},
"shipping": "Save with Free shipping, arrives in 2 days"
}
]
},
{
"laptops": [
{
"name": "ASUS Vivobook Go 15.6 inch Windows Laptop",
"specs": {
"processor": "Intel Core i3-N305",
"ram": "8GB",
"storage": "256GB UFS",
"color": "Black"
},
"price": {
"current": 282.0,
"original": null
},
"reviews": {
"count": 330,
"rating": 4.4
},
"shipping": "Free shipping, arrives in 2 days"
},
{
"name": "Latest 16" Purple Laptop",
"specs": {
"processor": "12th Gen Alder Lake N95 CPU",
"ram": "12G LPDDR5",
"storage": "1T NVMe SSD",
"os": "Win 11 Pro/Office 2019"
},
"price": {
"current": 377.99,
"original": null,
"other_options_from": 369.99
},
"reviews": {
"count": 7,
"rating": 4.4
},
"shipping": "Free shipping, arrives in 2 days"
}
]
},
{
"products": [
"hp laptop",
"macbook",
"gaming laptop",
"printer laptop",
"touchscreen",
"wireless mouse",
"ipad",
"chromebook",
"mouse"
],
"pagination": {
"current": [
1,
2,
3
],
"total": 25
},
"footer_links": [
"Departments",
"Store Directory",
"Careers",
"Our Company",
"Sell on Walmart.com",
"Help",
"Product Recalls",
"Accessibility",
"Tax Exempt Program",
"Get the Walmart App",
"Sign-up for Email",
"Safety Data Sheet",
"Terms of Use",
"Privacy & Security",
"California Supply Chain Act",
"Your Privacy Choices",
"Notice at Collection",
"AdChoices",
"Consumer Health Data Privacy Notices",
"Brand Shop Directory",
"Pharmacy",
"Walmart Business"
],
"copyright": "u00a9 2026 Walmart. All Rights Reserved."
}
]
結論
クロードがブライトデータのインフラでページを解析できるようにすることで、パーサーを書いたり、ブロックやIP禁止に対処する時間を大幅に減らすことができます。あなたが心配する必要があるのはページだけです。ページを手に入れたら、クロードに渡して完了です。全体的なスクレイパーの実行にはさらに数分かかるかもしれないが、我々が独自のパーサーを書くのに費やす時間に比べれば大したことはない。
ブライトデータの製品を試してみませんか?今すぐサインアップして、無料トライアルを開始しましょう!






