

この記事では以下を学びます:
- – Camoufoxによるウェブスクレイピングとは何か、およびフィンガープリントベースのボット検出をどのように低減するか。
- 信頼性の高いデータ抽出のための、Bright DataレジデンシャルプロキシとCamoufoxの設定方法。
- Camoufoxが効果を発揮する場面、大規模運用で限界を迎えるケース、本番環境ではBright DataのスクレイピングブラウザやWeb Unlockerへの移行が適切なタイミング。
Camoufoxとは?その中核機能の解説

Camoufoxは、Firefoxベースを改良したオープンソースのアンチ検出ブラウザです。標準的なヘッドレスブラウザが容易に識別・ブロックされるブラウザ自動化やウェブスクレイピングのシナリオ向けに設計されています。
Camoufoxは、JavaScriptのみに依存する手法ではなく、エンジンレベルでのブラウザ動作変更により検知回避に重点を置いています。
主な機能:
- ブラウザフィンガープリント制御:ナビゲータープロパティ、グラフィックスインターフェース、メディア機能、ロケール信号などのフィンガープリント属性を変更。ブラウザレベルでの調整により、アンチボットシステムが検知する不整合を低減。
- エンジンレベルでのステルスパッチ:Camoufoxアンチ検出ブラウザは、デフォルトのブラウザビルドで露出する自動化指標を削除または変更します。これには、自動化フレームワークを露呈するプロパティの処理や、検出可能なスクリプトをページコンテキストに注入せずに一般的なヘッドレスブラウザのシグネチャを回避することが含まれます。
- セッションの分離と可変性:各Camoufoxブラウザセッションは分離されており、実行ごとに異なるフィンガープリントプロファイルを使用できます。これにより、複数ページのスクレイピング時やブラウザ再起動時のセッション間相関を防止します。
インストールと設定
Camoufoxのインストール:CamoufoxはPythonパッケージとして配布され、固定化されたFirefoxベースのブラウザを同梱しています。これにより、フィンガープリントの不安定性を増大させるブラウザバージョンの変動を回避します。
pip install -U camoufox[geoip]
ブラウザのダウンロード
camoufox fetch
PythonおよびOS要件:WindowsとmacOSの両方でPython3.9以降が必要です。各Camoufoxインスタンスは約200MBのメモリを消費するため、低RAMシステムでは同時実行数が制限されます。
仮想環境(推奨):仮想環境を使用することで、SSL処理、フォントレンダリング、グラフィックAPIに影響する依存関係衝突を防止できます。これはWindowsとmacOSの両方に適用されます。
python -m venv camoufox-envcamoufox-envScriptsactivate # Windowssource camoufox-env/bin/activate # macOS基本チュートリアル:CamoufoxによるWebスクレイピング
このセクションでは、Camoufox を使用したウェブスクレイピングに必要な最小限のワークフローを説明します。コードは Camoufox ブラウザを起動し、新しいページを開き、実際のユーザーと同様に URL をロードします。JavaScript レンダリング済みコンテンツが利用可能になるよう、すべてのネットワークアクティビティが完了するまで待機します。
ページ全体のスクリーンショットをキャプチャし、ページレンダリングの成功を視覚的に確認します。最後に、ページ本文から可視テキストを抽出し、スクレイピングが正しく機能していることを検証します。
from camoufox.sync_api import Camoufox
with Camoufox(headless=True) as browser:
page = browser.new_page()
page.goto("<replace_with_a_link>")
page.wait_for_load_state("networkidle")
page.screenshot(path="page.png", full_page=True)
content = page.text_content("body")
print(content[:500])このスクリプトは、完全にレンダリングされたウェブページを示すスクリーンショットをpage.pngという名前でプロジェクトディレクトリに保存します。ターミナルには表示されているページテキストの最初の部分が印刷され、コンテンツ抽出が成功したことを確認します。ページが正常に読み込まれる場合、エラーは発生しません。
Camoufoxはスクレイピングブラウザベースのワークフローのプロトタイピングに最適です。なぜなら、Firefoxの実際の動作を抽象化せずにそのまま再現するからです。
ブラウザネイティブ(C++レベル)のフィンガープリンティングは、初期セッションにおいて高品質なレジデンシャルプロキシと組み合わせることで約92%の成功率を達成します。
オープンソースツールとして、現代のアンチボットシステムがブラウザフィンガープリント、クッキー、セッション状態を評価する方法を学ぶ上で特に価値があります。
Camoufox での Bright Data プロキシの設定
このセクションでは、信頼性の高い実環境でのウェブスクレイピングのために、Camoufox で Bright Data のレジデンシャルプロキシを正しく設定する方法を説明します。
レジデンシャルプロキシが重要な理由
レジデンシャルプロキシは、データセンターインフラではなく実際の消費者IPアドレスを経由してリクエストをルーティングします。これにより、ウェブサイトがトラフィックパターン、IPレピュテーション、リクエスト発信元を積極的に監視するウェブスクレイピングタスクにおいて、その有効性が大幅に向上します。
多くの現代的なウェブサイトは、クラウドやデータセンターのIP範囲を迅速にブロックするボット対策システムを導入しています。レジデンシャルIPは通常のユーザートラフィックに似ており、実際のブラウジング行動と地理的に一致するため、このリスクを軽減します。これは、コンテンツが豊富なプラットフォーム、地域固有のページ、またはレート制限やアクセスポリシーを適用するサイトをスクレイピングする際に特に重要です。
Camoufoxと組み合わせることで、レジデンシャルプロキシは2つの主要な利点を提供します:現実的なブラウザフィンガープリントとIPレベルでの真正性です。この組み合わせにより、ページ読み込み成功率が向上し、CAPTCHA頻度が減少し、手動介入なしにスクレイパーを長時間稼働させることが可能になります。本番環境レベルのスクレイピングパイプラインにおいて、レジデンシャルプロキシは中核的なインフラコンポーネントです。
設定:Bright Data認証情報 + GeoIP自動設定
Bright Dataダッシュボードにログインし、「プロキシインフラストラクチャ」セクションに移動します。ここで全てのプロキシゾーンが作成・管理されます。
「プロキシを作成」ボタンをクリックして、新しいプロキシゾーンの設定を開始します。Bright Dataが簡単な設定フローを案内します。
プロキシタイプ → レジデンシャルプロキシを選択:プロキシタイプのリストから「レジデンシャルプロキシ」を選択します。レジデンシャルプロキシは実際のレジデンシャルIP経由でトラフィックをルーティングするため、データセンター・プロキシと比較して検出率が大幅に低減されます。
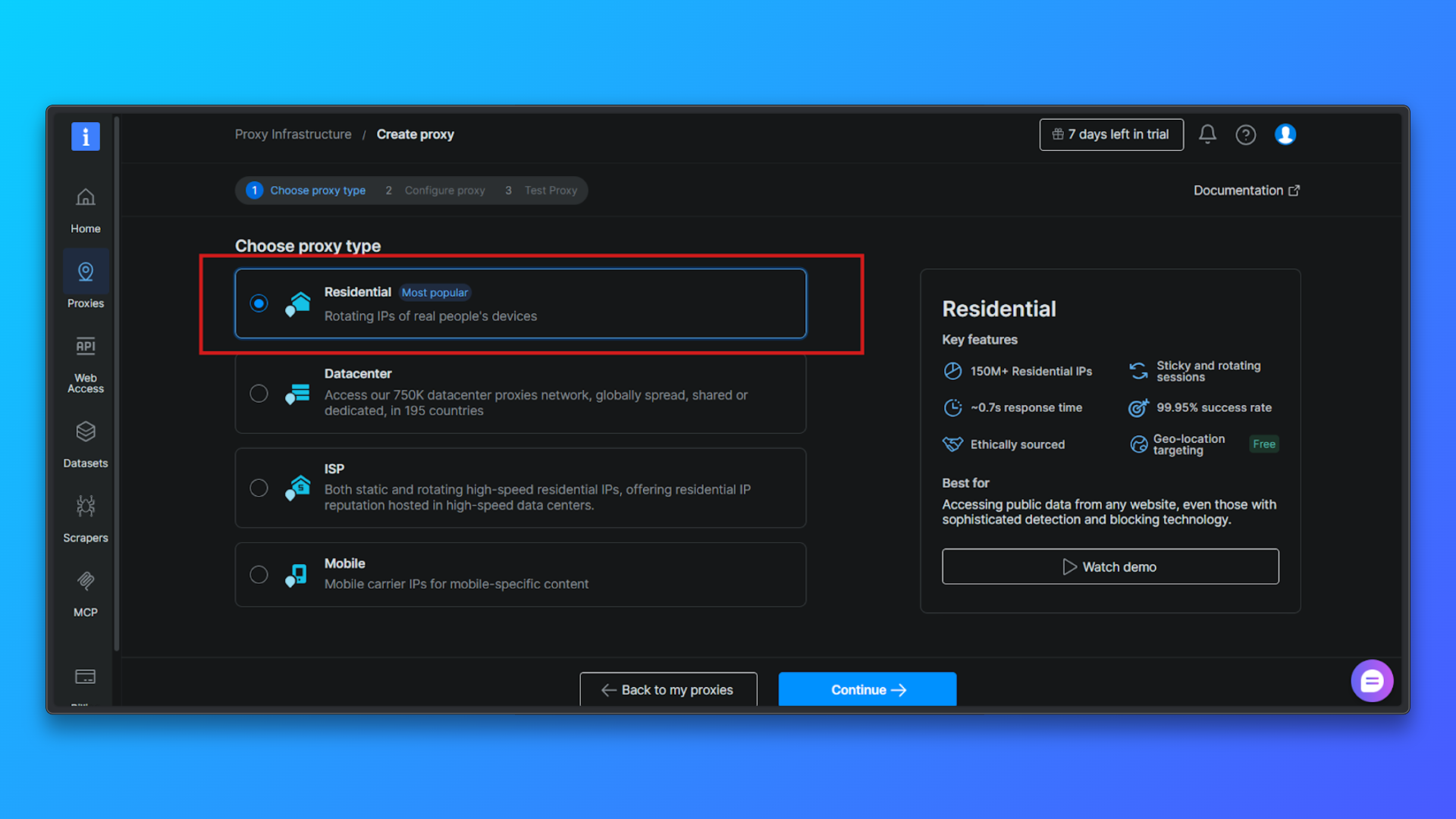
プロキシの設定(任意):以下の設定を任意で変更できます:国別ターゲティング、セッション動作、アクセスモード。
初心者の方はデフォルト設定で十分です。詳細オプションを変更せずに進めることができます。
「続行してゾーンを作成」をクリック:ゾーンの設定を確認し、セットアップを完了します。Bright Dataがレジデンシャルプロキシゾーンを作成し、概要ページにリダイレクトします。
概要タブでプロキシ認証情報を確認:概要タブには以下が表示されます:
- カスタマーID
- ゾーン名
- ユーザー名
- パスワード
- プロキシホストとポート
- アクセスモード
- すぐに使えるターミナルコマンド
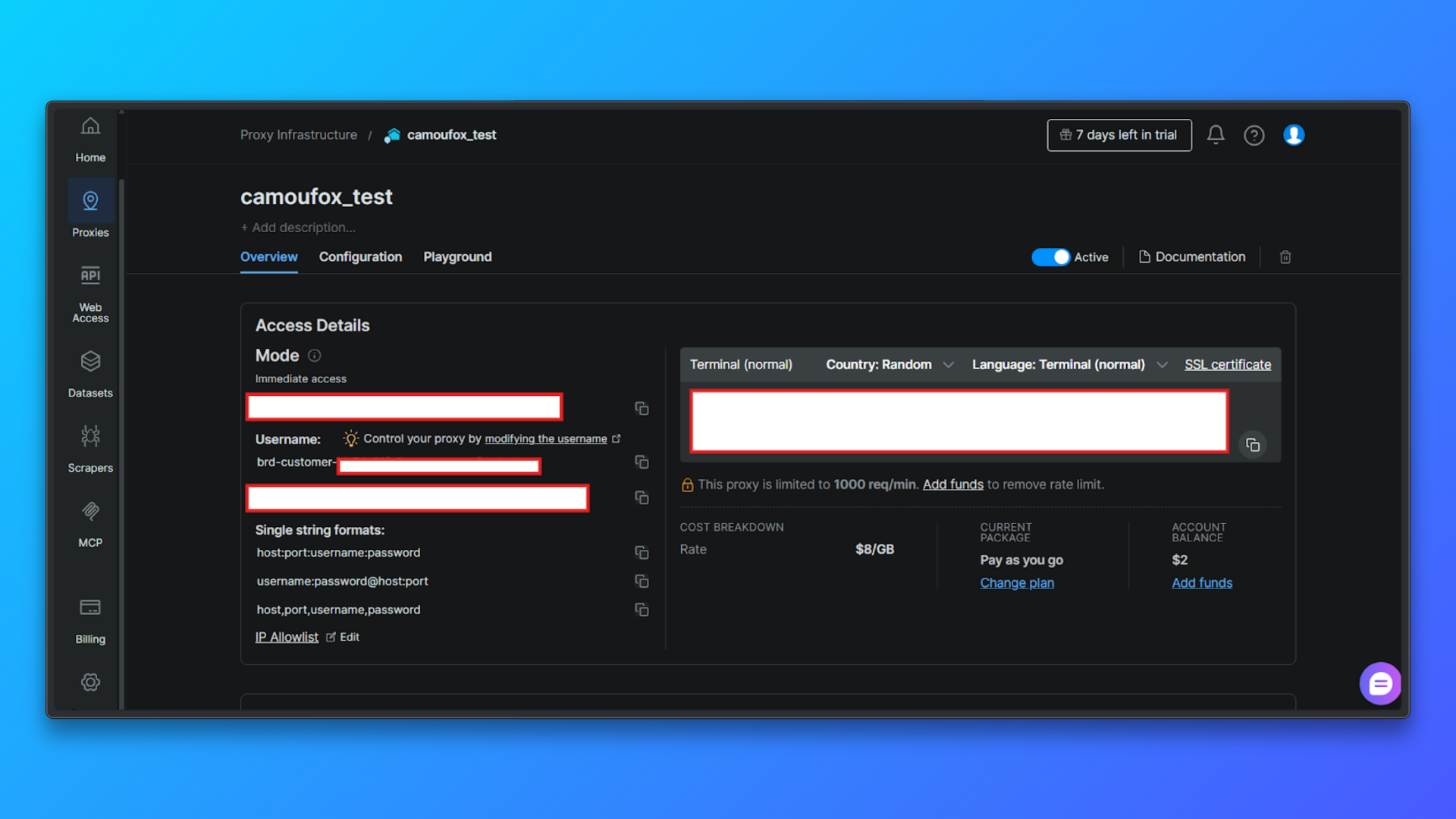
これらの値は、後でコード内でプロキシを設定する際に必要になります。
ターミナルコマンドによる認証情報の検証: ダッシュボードから提供されたターミナル(curl)コマンドをコピーし、ローカルで実行します。
このコマンドはプロキシ経由でBright Dataのテストエンドポイントにリクエストを送信し、以下を返します:
- HTTPステータス
- サーバー応答
- 割り当てられたIPの詳細
- 国、都市、およびASN情報
正常な応答は以下を確認します:
- プロキシ認証情報が有効
- 認証が機能している
- 住宅用IPルーティングが有効
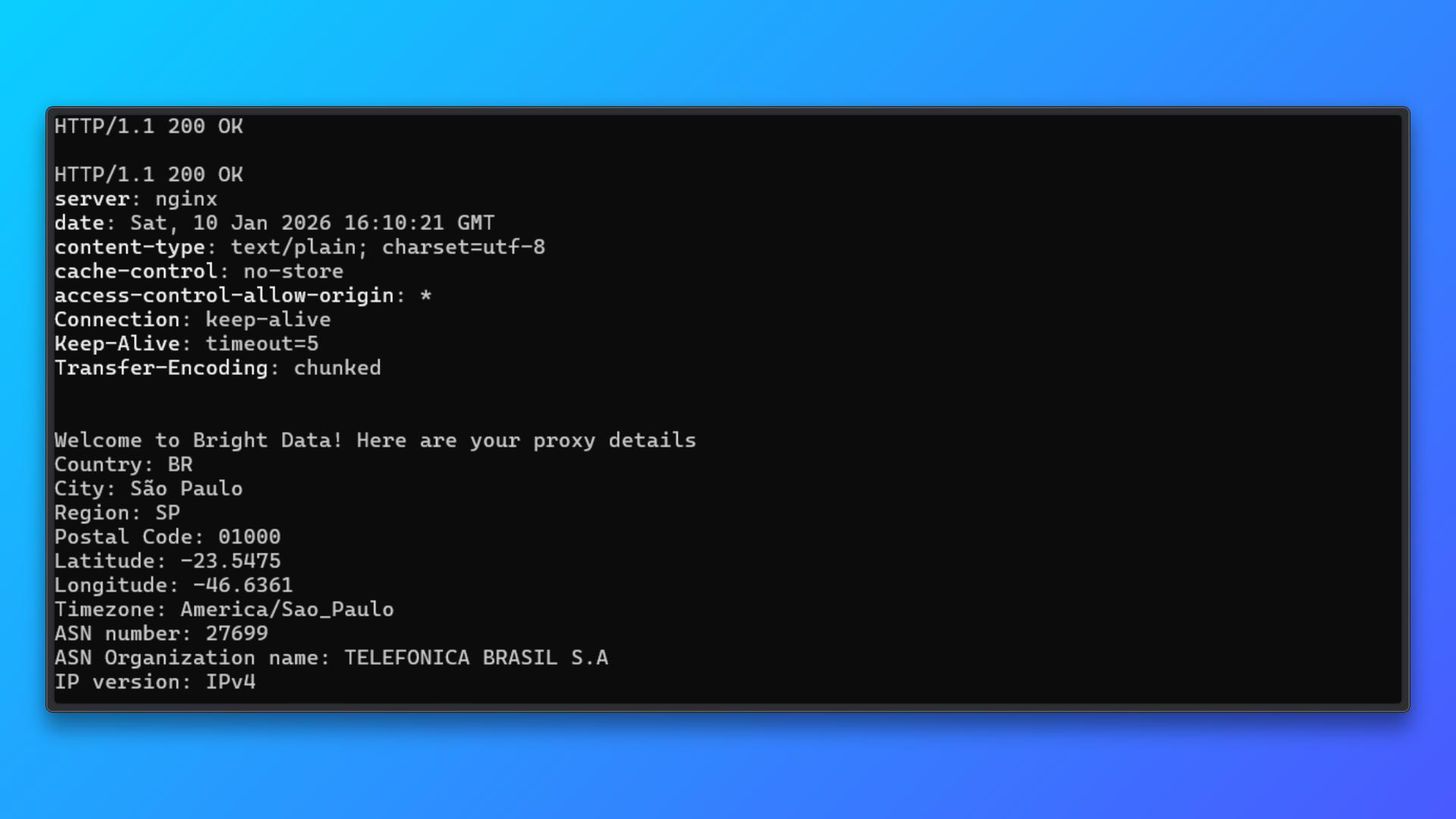
この検証ステップにより、プロキシをCamoufoxやスクレイピングコードに統合する前に、プロキシ設定の問題を特定できます。
Bright Dataではユーザー名経由で国レベルのルーティングを直接設定可能です。これによりIPアドレスの手動管理が不要となります。
Camoufoxでは、geoip=Trueを使用することで、ブラウザの動作をプロキシの地理的位置に合わせるオプションがあります。これにより、IP位置とブラウザシグナルの一貫性が向上します。
コード例: Camoufox + Bright Data
それでは、CamoufoxでBright Dataプロキシを設定しましょう。
ステップ1: Camoufoxのインポート
from camoufox.sync_api import Camoufoxステップ2: Bright Dataプロキシ設定の定義
プロキシ = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}server はBright Data では固定です。- 国指定はユーザー名で処理されます。
- 本番環境では、認証情報は環境変数に安全に保存してください。
ステップ3: プロキシを有効にしてCamoufoxを起動
with Camoufox(
プロキシ=プロキシ,
geoip=True,
headless=True,)
as browser:
page = browser.new_page(ignore_https_errors=True)
page.goto("https://example.com", wait_until="load")
print(page.title())スクリプトが正常に実行されると、CamoufoxはBright Dataのレジデンシャルプロキシを経由したヘッドレスFirefoxインスタンスを起動します。ブラウザはhttps://example.comを読み込み、ページタイトルをコンソールに出力します。
出力
プロキシローテーション戦略
Bright DataはネットワークレベルでIPローテーションを管理しますが、効果的なスクレイピングはブラウザレベルでのセッション構造と再利用に大きく依存します。プロキシローテーションとは、複数のリクエストにわたって現実的なブラウジング行動を維持することです。
Bright DataのレジデンシャルIPを使用する場合、スクレイピングワークフローでは通常約92%のページ読み込み成功率を達成します。これは、ほとんどのページがブロックや中断されることなく完全に読み込まれることを意味します。対照的に、データセンター・プロキシを使用した同様のスクレイピング設定では、特にフィンガープリンティング、IPレピュテーションチェック、または行動検知を使用するウェブサイトでは、成功率が約50%に留まることがよくあります。
以下は、CamoufoxとBright Dataを用いたウェブスクレイピングにおいて最も信頼性の高いローテーション戦略です。
- セッションベースのローテーション:リクエストごとにIPをローテーションする代わりに、単一のブラウザセッションを限定されたページ訪問数で再利用します。 複数のページ訪問や論理タスクの完了など、固定された閾値を超えた時点でセッションを終了し、新規セッションを生成します。この手法は実際のユーザーの閲覧行動を模倣し、クッキー・ヘッダー・ナビゲーションパターンの一貫性を維持します。セッションベースローテーションは匿名性と現実性のバランスに優れ、大半のクロール/スクレイピング作業に適しています。
- 障害ベースのローテーション:この戦略では、問題が発生した場合にのみセッションをローテーションします。ページの読み込み失敗、タイムアウト、予期しないコンテンツの返却が発生した場合、現在のブラウザセッションは破棄され、新しいセッションが作成されます。これにより、正常なリクエスト中の不要なローテーションを回避しつつ、ブロックや不安定なプロキシルートからの回復を可能にします。障害ベースのローテーションは、時折ネットワーク不安定性が予想される長時間稼働のクローラーに特に有用です。
- 国別ルーティング: Bright Dataではプロキシユーザー名経由で地理的ルーティングを直接設定可能。セッション認証情報に国コードを埋め込むことで、リクエストを特定地域のIP経由で一貫してルーティングします。地域制限コンテンツへのアクセスや、ローカライズされたページが正しい結果を返すことを保証するのに有用です。最適な結果を得るには、ブラウザのジオロケーション動作をプロキシの国と一致させ、信号の不一致を回避する必要があります。
- レート調整型クローリング:リクエストが過度に攻撃的に送信される場合、IPローテーションだけではブロックを防止できません。レート調整型クローリングでは、ページ訪問間に意図的な休止を導入し、連射的なナビゲーションパターンを回避します。レジデンシャルIPを使用する場合でも、スクレイピングが速すぎると異常と見なされる可能性があります。適度な遅延とセッション再利用を組み合わせることで、攻撃的で高頻度のローテーションよりも、実際のユーザー行動に極めて近いトラフィックパターンを生成できます。
- 過度なローテーションの回避: すべてのリクエストでIPをローテーションすることは、ほとんど有益ではありません。過剰なローテーションは不自然なトラフィックパターンを生み、接続オーバーヘッドを増大させ、疑いを回避するどころか引き起こすこともあります。ほとんどの場合、制御されたローテーションを伴う適度なセッション再利用が、より高い安定性と長期的な成功率につながります。
トラブルシューティング
- SSLまたはHTTPSエラー:証明書や発行者警告などのエラーは、HTTPSトラフィックがプロキシ経由でルーティングされる際に発生する可能性があります。ナビゲーションを確実に成功させるため、HTTPSエラーを無視する設定でページを作成してください。
- ページ読み込みタイムアウト:レジデンシャルプロキシは追加の遅延を引き起こす可能性があります。必要なコンテンツが部分的な場合、ナビゲーションのタイムアウト時間を延長し、ページ完全読み込みを待機しないようにしてください。
- プロキシ認証失敗:プロキシユーザー名がBright Dataの必須形式に準拠していること、正しいポートとパスワードが使用されていることを確認してください。ダッシュボードでプロキシゾーンが有効になっていることを確認してください。
- 誤った地域または言語コンテンツ: ページが予期しない地域のコンテンツを返す場合、プロキシ認証情報で国別ルーティングが正しく指定され、地理的位置情報の整合が有効になっていることを確認してください。
- 頻繁なCAPTCHAまたはアクセスブロック:これは通常、過度に積極的なスクレイピング動作を示します。リクエスト頻度を減らし、セッションをより効果的に再利用し、単一ブラウザインスタンス内での並列ページ読み込みを避けてください。
- ページコンテンツの不整合または不完全性:一部のページはデータを動的に読み込みます。適切な待機条件を使用し、必要な要素が存在することを確認してからコンテンツを抽出してください。
- 予期しないブラウザのクラッシュや切断:長時間のスクレイピング作業中のリソース枯渇を防ぐため、定期的にブラウザセッションを再起動し、長時間実行セッションを制限してください。
- Bright Data Web Unlocker: Cloudflareがブラウザ自動化を完全にブロックするサイト向けに、Bright DataのWeb Unlockerはコーディング不要で自動的なCloudflareバイパスを提供し、ブラウザレベルの回避策を不要にします。
実世界のEコマースプロジェクト:Camoufoxを用いたウェブスクレイピング(完全コード)
このプロジェクトでは、Cloudflareで保護されたECサイトのカテゴリページに対し、Camoufoxを用いたブラウザベースのウェブスクレイピングを実演します。目的は、ナビゲーション障害やページネーションを制御された再現可能な方法で処理しつつ、複数ページにわたる構造化された商品データを抽出することです。
この種のワークフローは、価格監視、カタログ分析、競合情報分析で一般的です。
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
import time
# Bright Data プロキシ設定 (マスク済み)
プロキシ = {
"server": "http://brd.superproxy.io:33335",
"username": "brd-customer-<CUSTOMER_ID>-zone-<ZONE_NAME>-country-us",
"password": "<YOUR_PROXY_PASSWORD>",
}
results = []
with Camoufox(
プロキシ=プロキシ,
ヘッドレス=True,
geoip=True,)
as browser:
# 新しいブラウザページを作成し、HTTPSインターセプトを許可
page = browser.new_page(ignore_https_errors=True)
page.set_default_timeout(60000)
base_url = "https://books.toscrape.com/"
max_pages = 5
for page_number in range(1, max_pages + 1):
try:
print(f"ページ {page_number} をスクレイピング中")
# ページに移動
page.goto(
base_url,
wait_until="domcontentloaded"
)
# すべての商品カードを検索
books = page.locator(".product_pod")
count = books.count()
if count == 0:
print("商品が見つかりません。クロールを停止します")
break
# 各商品からデータを抽出
for i in range(count):
book = books.nth(i)
title = book.locator("h3 a").get_attribute("title")
price = book.locator(".price_color").inner_text()
availability = book.locator(".availability").inner_text().strip()()
results.append({
"title": title,
"price": price,
"availability": availability,
"page": page_number,
})
# リクエストの集中を避けるため、少し遅延を追加
time.sleep(2)
except TimeoutError:
print(f"ページ {page_number} でタイムアウトが発生したためスキップします")
continue
except Exception as e:
print(f"ページ {page_number} で予期せぬエラーが発生しました: {e}")
break
print(f"n{len(results)}冊の書籍を収集しました")
# 結果の一部をプレビュー
for item in results[:5]:
print(item)Camoufoxは実際のFirefoxベースのブラウザインスタンスを起動し、Bright Dataは本物のユーザートラフィックに似たレジデンシャルIPを提供します。
スクリプトはBooks to Scrape ウェブサイトにアクセスし、ページ DOM の読み込みを待機した後、ページ上の各商品カードの位置を特定します。
各書籍リストから、タイトル、価格、在庫状況などの構造化フィールドを抽出し、さらなる処理のためにPythonリストに保存します。
コードには実環境でのスクレイピングに必要な基本的な耐障害性メカニズムも組み込まれています。ナビゲーションのタイムアウトは適切に処理され、予期せぬエラーは安全にクロールを停止させ、ページ読み込み間にわずかな遅延を追加して攻撃的なトラフィックパターンを回避します。
HTTPS 傍受エラーは明示的に無視されます。これは、TLS 接続を終了するプロキシを介してブラウザのトラフィックをルーティングする場合に必要です。
出力:
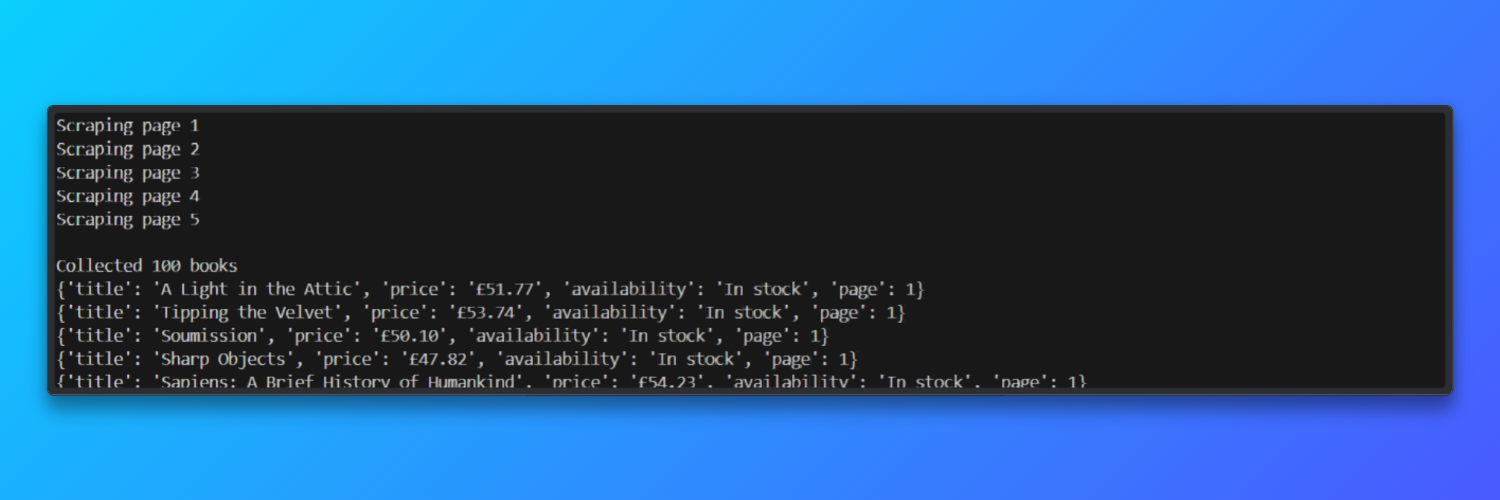
テスト実行では、Bright Dataのレジデンシャルプロキシを使用した場合、スクレイパーは5ページの分ページ処理を約45秒で処理し、ページ読み込み成功率約92%を達成しました。
パフォーマンスベンチマークと制限事項
本節では、Camoufoxをレジデンシャルプロキシと併用した際の測定済みパフォーマンス、実用上の制約、スケーリングへの影響をまとめ、それらの制約が次のアーキテクチャ設計に与える影響を考察します。
測定ベンチマーク(観測値)
- フィンガープリント耐性:CamoufoxはCreepJSテストで70%以上のスコアを獲得。オープンソースツールとしては一般的なブラウザフィンガープリント検査に対する高い耐性を示す。
- メモリフットプリント:ブラウザインスタンスあたり約200MBのRAMを消費し、一般的なサーバー環境では水平スケーリングに直接的な上限が生じます。
- セッション有効期間:クッキーは30~60分ごとに失効するため、アクセス維持には手動での更新またはセッション再起動が必要。
- 時間経過による成功率:セッションが古くなり検知システムが適応するにつれ、1時間目:約92% → 2時間目:約40% → 3時間目:約10%
- インフラ対比:Bright Dataは1億7500万以上のIP、99.95%の稼働率を提供し、ユーザー側のメンテナンス時間はゼロ。
大規模運用時の制約
Camoufoxによるウェブスクレイピングを長時間実行または大規模に展開する場合、以下の制約が顕在化します:
- セッションの有効期限: クッキーは通常30~60分で失効するため、アクセスを維持するには手動での更新またはブラウザの再起動が必要。
- メモリ使用量:各ブラウザインスタンスは約200MBのRAMを消費するため、標準サーバーでは同時実行数が制限されます。
- 同時実行数の上限:8GBサーバーでは、安定性が低下する前に実用的な上限は約30の同時ブラウザインスタンスです。
- 時間の経過に伴う信頼性の低下:セッションが古くなるにつれて成功率が顕著に低下します。介入なしの場合、1時間目で約92%、2時間目で約40%、3時間目までに約10%となります。
- 運用オーバーヘッド:一貫した結果を維持するには、通常、月20~30時間の積極的なメンテナンスと調整が必要です。
長期実行ジョブや予測可能な稼働時間を必要とするチームにとって、これらの制限により、スクレイピングロジックからインフラ管理へと焦点が移ります。
この段階では、マネージドソリューションが実用的な代替手段となります。Bright Dataのインフラは1億7500万以上のレジデンシャルIP、99.95%の稼働率を提供し、手動でのクッキーやセッション処理の必要性を排除します。
本番環境では、これにより通常99%以上の安定した成功率が得られ、自己管理型ブラウザ自動化で見られる漸進的な劣化は発生しません。
メンテナンス時間とインフラコストを考慮すると、管理型設定はDIYアプローチと比較して総月間コストを削減することが多い($1,200/月 vs $2,850 DIY(メンテナンス費含む))。
Camoufox vs Puppeteer vs Bright Data (比較表)
以下の表は、実際のスクレイピングプロジェクトで最も重要な要素について、CamoufoxとBright Dataのレジデンシャルプロキシ、Puppeteer、Bright Dataスクレイピングブラウザを比較したものです。
| 機能 | Camoufox + Bright Data プロキシ | Puppeteer | Bright Dataスクレイピングブラウザ |
|---|---|---|---|
| 成功率 | レジデンシャルプロキシ使用時:約92%の成功率 | 保護されたサイトでは約15~30% | 99%以上の安定した成功率 |
| 設定の難易度 | プロキシとフィンガープリント調整による中程度の設定 | パッチとプラグインが必要な高設定 | 低設定、すぐに使用可能 |
| クッキー管理 | 30~60分ごとの手動更新 | 完全手動処理 | 自動クッキー管理 |
| スケーリング制限 | サーバーあたり最大30の同時ブラウザ | 同時接続ブラウザ数:約50台 | 無制限のスケーリング |
| 月次メンテナンス | 20~30時間の継続的メンテナンス | 40~60時間のメンテナンス | 0時間必要 |
| 費用(100万リクエストあたり) | プロキシ使用料込みで約2,850ドル | 約2,500ドル+エンジニアリング時間 | 総費用:約1,200ドル |
Bright Dataへの移行時期
ボット対策回避Camoufoxブラウザは初期段階のスクラッピングワークフロー構築に有力な選択肢ですが、持続的な高負荷運用を想定した設計ではありません。
プロジェクトが拡大するにつれ、30~60分ごとのクッキー有効期限切れ、長期運用での成功率低下、頻繁なブラウザ再起動の必要性が運用上のオーバーヘッドをもたらします。
Camoufox によるウェブスクレイピングでは、99% 以上の安定した成功率、サーバーあたり 30 以上のブラウザという高い同時実行性、継続的な調整を必要としない予測可能なパフォーマンスが求められます。
Bright Dataのマネージドスクレイピングソリューションは、ブラウザフィンガープリンティング、セッション持続性、再試行、スケーリングを自動的に処理するため、手動メンテナンスが不要となり、長期実行パイプラインが安定します。
主なポイント
本ガイドでは、Camoufoxによるウェブスクレイピングの実践的な運用方法、その強みと限界を示しました。Camoufoxとレジデンシャルプロキシの組み合わせは、プロトタイピング、実験、現代的なボット検知システムの理解に適しています。
信頼性、拡張性、コスト効率が重要な本番環境では、BrightDataのようなマネージドスクレイピングインフラが明確な運用パスを提供します。
CamoufoxのPython環境が既に機能しているものの、頻繁な再起動、セッションリセット、プロキシ調整が必要な場合、制約要因はスクレイピングロジックではなくインフラストラクチャにあります。
Bright Dataのレジデンシャルプロキシとスクレイピングブラウザを活用し、メンテナンス負荷を軽減しながら、大規模で安定した本番環境レベルの成果を実現しましょう。
また、Bright Dataのスクレイピングブラウザは、フィンガープリンティング、セッション持続性、再試行を自動的に処理することで、本番環境規模のCamoufox代替手段として機能します。
全体として、これは市場で最大規模かつ最速、最も信頼性の高いスクレイピング特化プロキシネットワークの一つです。
今すぐ登録して無料プロキシトライアルを開始しましょう!






