
ウェブスクレイピングは、特に迅速で情報に基づいた意思決定が不可欠な場合に、大規模なデータ収集において重要な役割を果たす。
このチュートリアルでは、次のことを学びます:
- Midscene.jsとは何か?
- Midscene.jsを使うことの限界、
- ブライト・データはこのような課題をどのように克服するか
- 効果的なウェブスクレイピングのためにMidscene.jsをBright Dataと統合する方法
さあ、飛び込もう!
Midscene.jsとは?
Midscene.jsはオープンソースのツールで、平易な英語を使ってブラウザのインタラクションを自動化することができる。複雑なスクリプトを書く代わりに、”ログインボタンをクリック “や “Eメールフィールドに入力 “のようなコマンドを入力するだけです。Midsceneはこれらの命令をAIエージェントを使って自動化のステップに変換します。
また、PuppeteerやPlaywrightといった最新のブラウザ自動化ツールもサポートしており、テストやUIの自動化、動的なウェブサイトのスクレイピングといった作業に特に役立つ。
主な特徴は以下の通り:
- 自然言語コントロール:コードではなく、明確な英語ベースのプロンプトを使用してタスクを自動化します。
- MCPサーバーとのAI統合:MCPサーバーを介してAIモデルに接続し、自動化スクリプトの生成を支援します。
- 組み込みのPuppeteerとPlaywrightのサポート:一般的なフレームワークの上位レイヤーとして機能し、ワークフローの管理と拡張を容易にします。
- クロスプラットフォーム自動化:Web(Puppeteer/Playwright経由)とAndroid(JavaScript SDK経由)の両方をサポートします。
- ノーコード体験: Midscene Chrome Extensionのようなツールを提供することで、コードを書くことなく自動化を構築できる。
- シンプルなAPI設計:ページ要素と相互作用し、コンテンツを効率的に抽出するために、クリーンで、十分に文書化されたAPIを提供します。
ウェブブラウザの自動化にMidsceneを使うことの限界
MidsceneはGPT-4oやQwenのようなAIモデルを使い、自然言語コマンドでブラウザを自動化する。PuppeteerやPlaywrightのようなツールと連動するが、重要な制限がある。
Midsceneの精度は指示の明確さと、その下にあるページ構造に依存します。似たようなボタンが複数ある場合、「ボタンをクリックしてください」のようなあいまいなプロンプトは失敗する可能性があります。AIはスクリーンショットとビジュアルレイアウトに依存しているため、小さな構造の変更やラベルの欠落がエラーやミスクリックの原因となることがあります。あるウェブページで機能するプロンプトが、同じような外観を持つ別のウェブページでは機能しないことがあります。
エラーを最小限に抑えるために、ページの構造に合った明確で具体的な指示を書きましょう。自動化スクリプトに組み込む前に、必ずMidscene Chrome Extensionでプロンプトをテストする。
もうひとつの重要な制限は、リソースの消費が大きいことだ。Midsceneの各自動化ステップはスクリーンショットとプロンプトをAIモデルに送信し、多くのトークンを使用する。これは、AI APIからのレート制限や、自動化ステップの増加に伴う使用コストの上昇につながります。
Midsceneはまた、CAPTCHAやクロスオリジンiframe、認証ウォールの背後にあるコンテンツなど、保護されたブラウザの要素と相互作用することはできません。そのため、セキュアなコンテンツやゲートされたコンテンツをスクレイピングすることはできません。ミッドシーンは、アクセス可能で構造化されたコンテンツを持つ静的または中程度の動的サイトで最も効果的です。
ブライト・データがより効果的なソリューションである理由
Bright Dataは、ウェブスクレイピング業務の構築、実行、拡張を支援する強力なデータ収集プラットフォームです。強力なプロキシインフラストラクチャ、自動化ツール、企業や開発者向けのデータセットを提供し、あらゆる公開ウェブサイトへのアクセス、抽出、対話を可能にします。
- 動的でJavaScriptを多用するウェブサイトにも対応Bright Dataは、SERP API、Crawl API、Browser API、Unlocker APIなど、コンテンツを動的に読み込む複雑なウェブサイトへのアクセス、データ抽出、対話を可能にするさまざまなツールを提供しています。これらのツールは、あらゆるプラットフォームからデータを取得できる様々なツールを提供し、eコマース、旅行、不動産のプラットフォームに最適です。
- 効率的なプロキシインフラBright Dataは、4つの主要ネットワークを通じて強力で柔軟なプロキシインフラを提供します:レジデンシャル、データセンター、ISP、モバイルです。これらのネットワークは、世界中の何百万ものIPアドレスへのアクセスを提供し、ユーザーはブロックを最小限に抑えながら、ウェブデータを確実に収集することができます。
- マルチメディアコンテンツに対応Bright Dataは、一般に公開されているソースから、ビデオ、画像、音声、テキストなど様々なタイプのコンテンツを抽出することができます。そのインフラストラクチャーは、大規模なメディアコレクションを扱い、コンピュータビジョンモデルのトレーニング、音声認識ツールの構築、自然言語処理システムのパワーアップなどの高度なユースケースをサポートするように設計されています。
- すぐに使えるデータセットを提供Bright Dataは、完全に構造化され、高品質で、すぐに使えるデータセットを提供しています。これらのデータセットは、eコマース、求人情報、不動産、ソーシャルメディアなど様々なドメインにまたがっており、様々な業界やユースケースに適しています。
Midscene.jsとBright Dataの統合方法
このチュートリアルでは、MidsceneとBright DataのBrowser APIを使用してウェブサイトからデータをスクレイピングする方法と、より良いウェブスクレイピング機能のために両方のツールを組み合わせる方法を学びます。
これを実証するために、従業員の連絡先カードのリストを表示する静的なウェブページをスクレイピングします。まずMidsceneとBright Dataを個別に使用し、次にPuppeteerを使用して両者を統合し、どのように連携できるかを示します。
前提条件
このチュートリアルに従うには、以下のものを用意してください:
- ブライトデータのアカウント。
- Visual Studio CodeやCursorなどのコードエディター。
- GPT-4o モデルをサポートするOpenAI API キー。
- JavaScriptプログラミング言語の基礎知識
ブライトデータのアカウントをまだお持ちでない方もご安心ください。以下のステップで作成方法を説明します。
ステップ1:プロジェクトのセットアップ
ターミナルを開き、以下のコマンドを実行して、オートメーション・スクリプト用の新しいフォルダを作成する:
mkdir automation-scripts
cd automation-scripts
以下のコード・スニペットを使って、新しく作成したフォルダにpackage.jsonファイルを追加する:
npm init -y
package.jsonのタイプ値をcommonjsから moduleに変更する。
{
"type": "module"
}
次に、TypeScriptの実行を有効にし、Midscene.jsの機能にアクセスするために必要なパッケージをインストールする:
npm install tsx @midscene/web --save
次に、PuppeteerとDotenvパッケージをインストールする。
npm install puppeteer dotenv
Puppeteerは、ChromeまたはChromiumブラウザを制御するための高レベルAPIを提供するNode.jsライブラリです。Dotenvを使用すると、APIキーを安全に保存できます。
これで、必要なパッケージがすべてインストールされた。自動化スクリプトを書き始めることができる。
ステップ2:Midscene.jsでウェブスクレイピングを自動化する
先に進む前に、automation-scriptsフォルダ内に.envファイルを作成し、OpenAI APIキーを環境変数としてファイルにコピーします。
OPENAI_API_KEY=<your_openai_key>
MidsceneはOpenAIのGPT-4oモデルを使用して、ユーザーのコマンドに基づいて自動化タスクを実行します。
次に、フォルダ内にファイルを作成する。
cd automation-scripts
touch midscene.ts
Puppeteer、Midscene Puppeteer Agent、およびdotenv設定をファイルにインポートします:
import puppeteer from "puppeteer";
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import "dotenv/config";
以下のコード・スニペットをmidscene.tsファイルに追加する:
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 initialize puppeteer
const browser = await puppeteer.launch({
headless: false,
});
//👇🏻 set the page config
const page = await browser.newPage();
await page.setViewport({
width: 1280,
height: 800,
deviceScaleFactor: 1,
});
/*
----------
👉🏻 Write automation scripts here 👈🏼
-----------
*/
})()
);
このコード・スニペットは、非同期の即時呼び出し関数式(IIFE)内でPuppeteerを初期化します。この構造により、複数の関数呼び出しでロジックをラップすることなく、トップレベルでawaitを使用することができます。
次に、IIFEの中に以下のコード・スニペットを追加する:
//👇🏻 Navigates to the web page
await page.goto(
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>"
);
// 👇🏻 init Midscene agent
const agent = new PuppeteerAgent(page as any);
//👇🏻 gives the AI model a query
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 Waits for 5secs
await sleep(5000);
// 👀 log the results
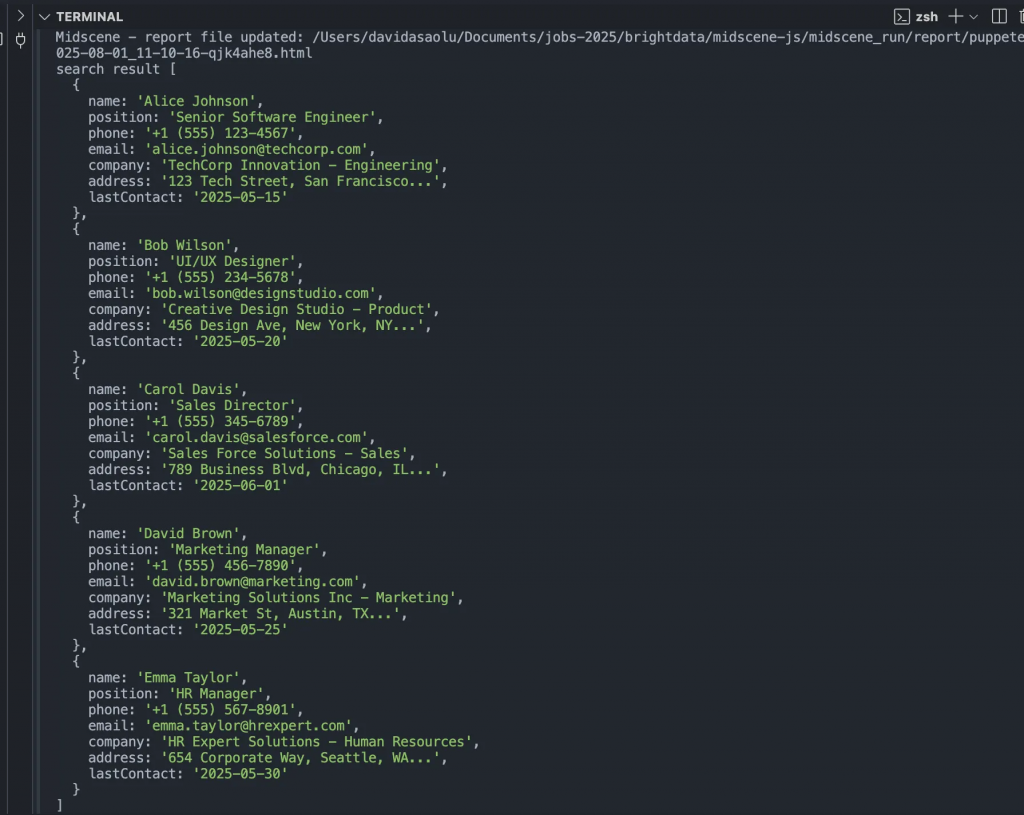
console.log("search result", items);
上記のコード・スニペットは、ウェブページのアドレスにアクセスし、Puppeteerエージェントを初期化し、ウェブページからすべての連絡先の詳細を取得し、その結果をログに記録します。
ステップ #3: Bright Data Browser APIでウェブスクレイピングを自動化する
automation-scriptsフォルダ内にbrightdata.tsファイルを作成する。
cd automation-scripts
touch brightdata.ts
Bright Dataのホームページにアクセスし、アカウントを作成してください。
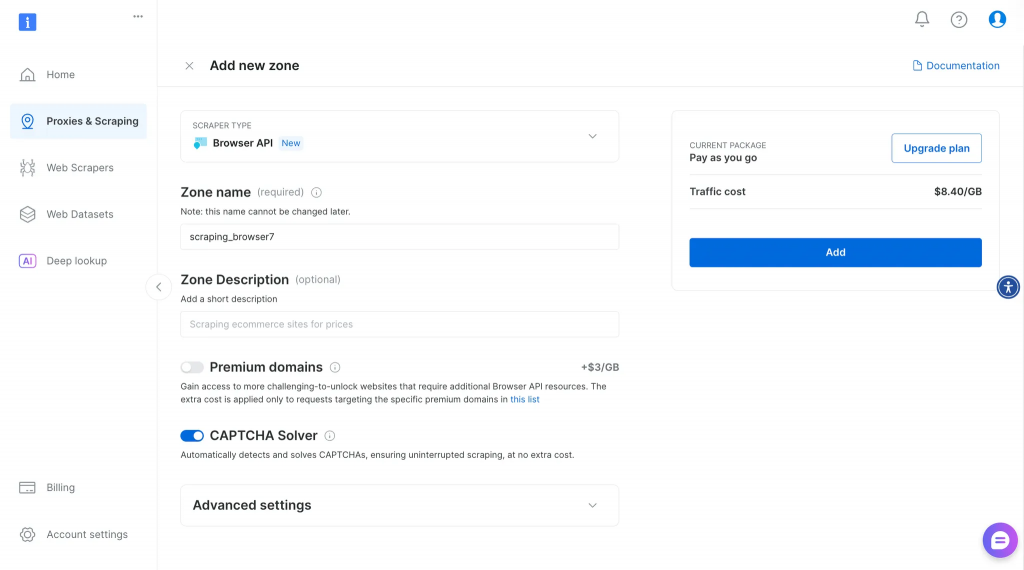
ダッシュボードでブラウザAPIを選択し、ゾーン名と説明を入力して新しいブラウザAPIを作成します。
次に、Puppeteerの認証情報をコピーし、以下のようにbrightdata.tsファイルに保存します:
const BROWSER_WS = "wss://brd-customer-******";
brightdata.tsを以下のように修正する:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
run(URL);
async function run(url: string) {
try {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
このコードでは、ウェブページのURLとBright DataのブラウザAPIクレデンシャルを変数として宣言し、そのURLをパラメータとして受け取る関数を宣言しています。
ウェブオートメーションワークフローのプレースホルダー内に以下のコードスニペットを追加します:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
以下のコードスニペットは、API WebSocketエンドポイントを使用してPuppeteerをBright Data Browserに接続します。接続が確立されると、新しいブラウザページを開き、run()関数に渡されたURLに移動します。
最後に、以下のコード・スニペットでCSSセレクタを使ってウェブページ上のデータを取得する:
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name:
(nameEl as HTMLElement)?.dataset.name ||
(nameEl as HTMLElement)?.innerText.trim() ||
null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
上記のコード・スニペットは、ウェブページ上の各連絡先カードをループし、名前、役職、電話番号、電子メールアドレス、会社名、住所、最終連絡日などの主要な詳細を抽出している。
オートメーション・スクリプトの完全版はこちら:
import puppeteer from "puppeteer";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS ="wss://brd-customer-*******";
run(URL);
async function run(url: string) {
try {
//👇🏻 connect to Bright data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to webpage
await page.goto(url, { waitUntil: "domcontentloaded", timeout: 60000 });
console.log("Navigated! Waiting for popup...");
//👇🏻 Get contact details using CSS attribute
const contacts = await page.evaluate(() => {
const cards = document.querySelectorAll("#contactsGrid .contact-card");
return Array.from(cards).map((card) => {
const nameEl = card.querySelector(".contact-name");
const detailsEl = card.querySelectorAll(
".contact-details .detail-item span:not(.detail-icon)"
);
const metaEl = card.querySelector(".contact-meta");
if (!nameEl || !detailsEl.length || !metaEl) {
return null; // Skip if any required element is missing
}
const contact = {
name: (nameEl as HTMLElement)?.dataset.name || (nameEl as HTMLElement)?.innerText.trim() || null,
jobTitle: (metaEl as HTMLElement)?.innerText.trim() || null,
phone: (detailsEl[0] as HTMLElement)?.innerText.trim() || null,
email: (detailsEl[1] as HTMLElement)?.innerText.trim() || null,
company: (detailsEl[2] as HTMLElement)?.innerText.trim() || null,
address: (detailsEl[3] as HTMLElement)?.innerText.trim() || null,
lastContact: (detailsEl[4] as HTMLElement)?.innerText.trim() || null,
};
return contact;
});
});
console.log("Contacts grid found! Extracting data...", contacts);
//👇🏻 close the browser
await browser.close();
} catch (err) {
console.error("Error fetching data");
}
}
ステップ4:ミッドシーンとブライトデータを使ったAI自動化スクリプト
Bright Dataは、Midsceneとの統合により、AIエージェントによるWebオートメーションをサポートしています。どちらのツールもPuppeteerをサポートしているため、これらを組み合わせることで、AIを利用したシンプルな自動化ワークフローを書くことができます。combine.tsファイルを作成し、以下のコードスニペットをコピーしてください:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-******";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
/*
---------------------------
👉🏻 Web automation workflow 👈🏼
---------------------------
*/
//👇🏻 close the browser
await browser.close();
})()
);
上記のコード・スニペットは、非同期のIIFE(Immediately Invoked Function Expression)を作成し、AIオートメーション・スクリプト内で遅延を追加できるsleep関数を含んでいます。
次に、以下のコード・スニペットをウェブ自動化ワークフローのプレースホルダーに追加する:
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
//👇🏻 declares page
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to website
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
// 👇🏻 get contact details using AI agent
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
//👇🏻 delays for 5secs
await sleep(5000);
//👇🏻 logs the result
console.log("search result", items);
このコードスニペットは、Puppeteerとそのエージェントを初期化し、ウェブページに移動し、すべての連絡先の詳細を取得し、結果をコンソールに記録します。これは、Puppeteer AIエージェントをBright Data Browser APIと統合し、Midsceneが提供する明確なコマンドに依存する方法を示しています。
ステップ5:すべてをまとめる
前のセクションでは、Midscene と Bright Data Browser API を統合する方法を学びました。完全なオートメーションスクリプトを以下に示します:
import { PuppeteerAgent } from "@midscene/web/puppeteer";
import puppeteer from "puppeteer";
import "dotenv/config";
const URL =
"<https://lf3-static.bytednsdoc.com/obj/eden-cn/nupipfups/Midscene/contacts3.html>";
const BROWSER_WS = "wss://brd-customer-*****";
const sleep = (ms: number) => new Promise((r) => setTimeout(r, ms));
Promise.resolve(
(async () => {
//👇🏻 connect to Bright Data Browser API
console.log("Connecting to browser...");
const browser = await puppeteer.connect({
browserWSEndpoint: BROWSER_WS,
});
console.log("Connected! Navigate to site...");
const page = await browser.newPage();
//👇🏻 Go to Booking.com
await page.goto(URL, { waitUntil: "domcontentloaded", timeout: 60000 });
// 👀 init Midscene agent
const agent = new PuppeteerAgent(page as any);
const items = await agent.aiQuery(
"get all the contacts details from the screen"
);
await sleep(5000);
console.log("search result", items);
await browser.close();
})()
);
ターミナルで以下のコード・スニペットを実行し、スクリプトを実行する:
npx tsx combine.ts
上記のコードスニペットは、オートメーションスクリプトを実行し、コンソールに連絡先の詳細をログに記録します。
[
{
name: 'Alice Johnson',
jobTitle: 'Senior Software Engineer',
phone: '+1 (555) 123-4567',
email: '[email protected]',
company: 'TechCorp Innovation - Engineering',
address: '123 Tech Street, San Francisco...',
lastContact: 'Last contact: 2026-05-15'
},
{
name: 'Bob Wilson',
jobTitle: 'UI/UX Designer',
phone: '+1 (555) 234-5678',
email: '[email protected]',
company: 'Creative Design Studio - Product',
address: '456 Design Ave, New York, NY...',
lastContact: 'Last contact: 2026-05-20'
},
{
name: 'Carol Davis',
jobTitle: 'Sales Director',
phone: '+1 (555) 345-6789',
email: '[email protected]',
company: 'Sales Force Solutions - Sales',
address: '789 Business Blvd, Chicago, IL...',
lastContact: 'Last contact: 2026-06-01'
},
{
name: 'David Brown',
jobTitle: 'Marketing Manager',
phone: '+1 (555) 456-7890',
email: '[email protected]',
company: 'Marketing Solutions Inc - Marketing',
address: '321 Market St, Austin, TX...',
lastContact: 'Last contact: 2026-05-25'
},
{
name: 'Emma Taylor',
jobTitle: 'HR Manager',
phone: '+1 (555) 567-8901',
email: '[email protected]',
company: 'HR Expert Solutions - Human Resources',
address: '654 Corporate Way, Seattle, WA...',
lastContact: 'Last contact: 2026-05-30'
}
]
ステップ6:次のステップ
このチュートリアルでは、MidsceneとBright Data Browser APIを統合することで可能になることを紹介します。この基礎の上に、より複雑なワークフローを自動化することができます。
この2つのツールを組み合わせることで、以下のような効率的でスケーラブルなブラウザ自動化タスクを実行できる:
- 動的またはJavaScriptを多用するウェブサイトから構造化データをスクレイピングする
- テストやデータ収集のためのフォーム送信の自動化
- ウェブサイトをナビゲートし、自然言語の指示を使って要素と対話する。
- プロキシ管理とCAPTCHA処理による大規模データ抽出ジョブの実行
結論
これまで、MidsceneとBright Data Browser APIを使用してWebスクレイピング処理を自動化する方法と、AIエージェントを介してWebサイトをスクレイピングするために両方のツールを使用する方法を学んできました。
Midsceneはブラウザの自動化のためにAIモデルに大きく依存しており、Bright Dataスクレイピングブラウザと一緒に使用することは、効果的なウェブスクレイピング機能でコード行数を減らすことを意味します。Browser APIは、Bright Dataのツールやサービスが、高度なAI主導の自動化にどのように力を与えることができるかの一例に過ぎません。
今すぐ登録して、すべての製品をご覧ください。





