

このガイドでは以下の内容を学びます:
- AliExpressスクレイパーとは何か、その仕組み
- AliExpressから自動取得可能なデータの種類
- Pythonを使用したAliExpressスクレイピングスクリプトの構築方法
それでは始めましょう!
AliExpressスクレイパーとは?
AliExpressスクレイパーは、AliExpressページから特定のデータを自動的に取得します。ユーザーの閲覧習慣を模倣してAliExpressページをナビゲートし、ウェブページの内容をCSVやJSONなどの利用可能な形式に変換し、ページネーションなどの操作を制御します。最終的な目的は、商品画像、商品詳細、顧客フィードバック、価格などの構造化された情報を取得することです。
ウェブスクレイパーの構築についてさらに学びたい場合は、スクレイピングボットの構築方法に関するガイドをお読みください。
AliExpressからスクレイピング可能なデータ:ステップバイステップガイド
AliExpressには以下のような膨大な情報が含まれています:
- 製品詳細:名称、説明、画像、価格帯、販売者情報など
- 顧客フィードバック:評価、商品レビューなど。
- カテゴリとタグ:商品カテゴリ、関連タグ、ラベルなど。
これらをスクレイピングする方法を学びましょう!
PythonでAliExpressをスクレイピングする
このチュートリアルセクションでは、AliExpressスクレイパーを構築するためのステップバイステップガイドを提供します。
目標は、Pythonスクリプトを記述してAliExpressの「人間工学に基づいた椅子」ページから自動的に情報を取得する方法を解説することです:
ステップ #1: プロジェクト設定
ローカルコンピュータにPython 3がインストールされていることを確認してください。インストールされていない場合は、公式ドキュメントからダウンロードし、インストールウィザードに従って設定してください。
次に、以下のコマンドでプロジェクトディレクトリを作成します:
mkdir aliexpress-スクレイパー
このディレクトリにPythonコードを格納します。
ターミナルでディレクトリに移動し、その中に仮想環境を作成します:
cd aliexpress-スクレイパー
python -m venv env
お好みのPython IDE(例:Python拡張機能を搭載したVisual Studio Code)でプロジェクトフォルダを開きます。
IDEのターミナルで仮想環境を有効化します。macOSまたはLinuxを使用している場合は、次のコマンドを実行してください:
.env/bin/activate
Windowsの場合は同等のコマンドを使用します:
env/Scripts/activate
よし!
プロジェクトのルートディレクトリにscraper.py ファイルを作成してください。これでプロジェクトのフォルダ構造は次のようになります:
よし!AliExpressウェブスクレイピング用のPython環境が準備完了です。
ステップ #2: スクラッピングライブラリの選択
現在の目的は、AliExpressが動的ページか静的ページを使用しているかを判断することです。ブラウザのプライベートモードまたはシークレットモードで対象のAliExpressページに移動します。次に、ウェブページの背景の空いている部分を右クリックし、「要素を検査」オプションを選択して「ネットワーク」タブに移動し、「Fetch/XHR」フィルターを適用し、ページを更新します:
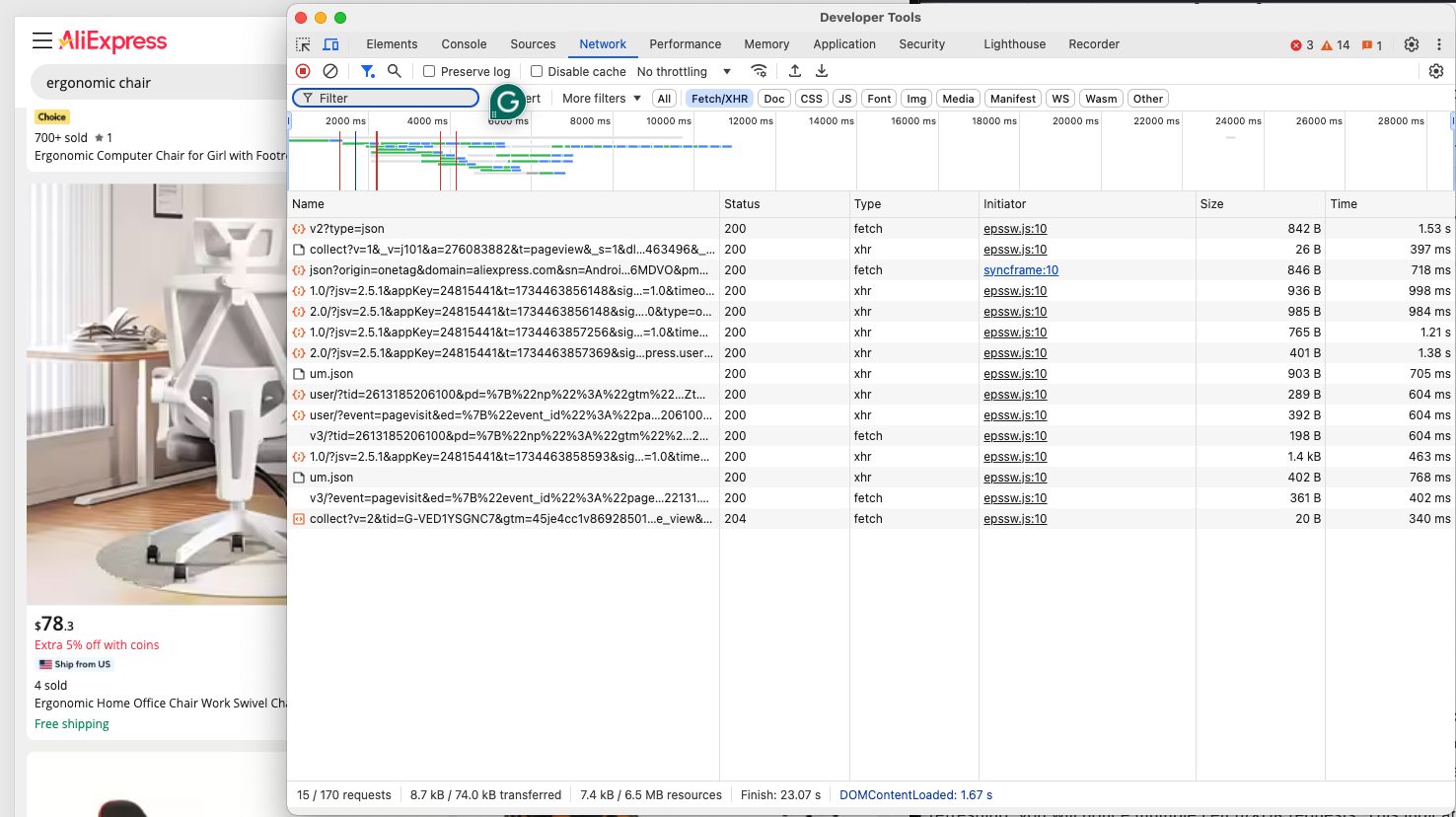
この開発者ツールセクションで、ページが動的クエリを実行しているか確認します。ページ更新後、複数のFetch/XHRリクエストが確認できるはずです。これはページが追加コンテンツを読み込むために動的リクエストを使用していることを示しています。サーバーから返されるHTMLドキュメントと比較してページのDOMを確認すると、AliExpressがJavaScriptレンダリングを使用していることもわかります。
AliExpressを効果的にスクレイピングするには、対象ページがレンダリングにJavaScriptに依存しているため、Seleniumのようなブラウザ自動化ツールが必要です。Seleniumウェブスクレイピングに関する当ブログは初心者向けの優れたリソースです。
Seleniumを使えば、ウェブブラウザを操作し、ユーザー操作を模倣し、JavaScriptでレンダリングされたコンテンツをスクレイピングできます。インストールして使い始めましょう!
ステップ #3: Selenium のインストールと設定
アクティブ化された仮想環境で、以下のコマンドでSeleniumをインストールします:
pip install -U selenium
scraper.pyファイルで、SeleniumからWebDriverをインポートし初期化します。
from selenium import webdriver
# Chromeドライバーを初期化
driver = webdriver.Chrome()
# スクラッピングロジック...
# ドライバーを閉じる
driver.quit()
上記のコードでは、Chromeインスタンスを操作するためにWebDriverが初期化されています。AliExpressにはヘッドレスブラウザのサイトアクセスを阻止する可能性のある反スクレイピング対策が施されている点に留意が必要です。
したがって、--headlessフラグの設定は推奨されません。代わりに、Playwright Stealthなどの代替オプションを検討してください。
AliExpressのスクレイピングを開始する準備が整いました。次に、対象ページへの接続方法を確認しましょう。
ステップ #4: ターゲットページへの接続
Selenium WebDriverオブジェクトが公開するget()メソッドを使用してターゲットページにアクセスします。scraper.pyファイルは次のようになります:
from selenium import webdriver
# Chromeドライバーの初期化
driver = webdriver.Chrome()
# ターゲットページのURL
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
# ターゲットページに接続
driver.get(url)
# スクラッピングロジック...
# ドライバーを閉じる
driver.quit()
最終行にデバッグブレークポイントを設定し、デバッガーでスクリプトを実行します。制御されたChromeブラウザが以下のように自動的に開くはずです:
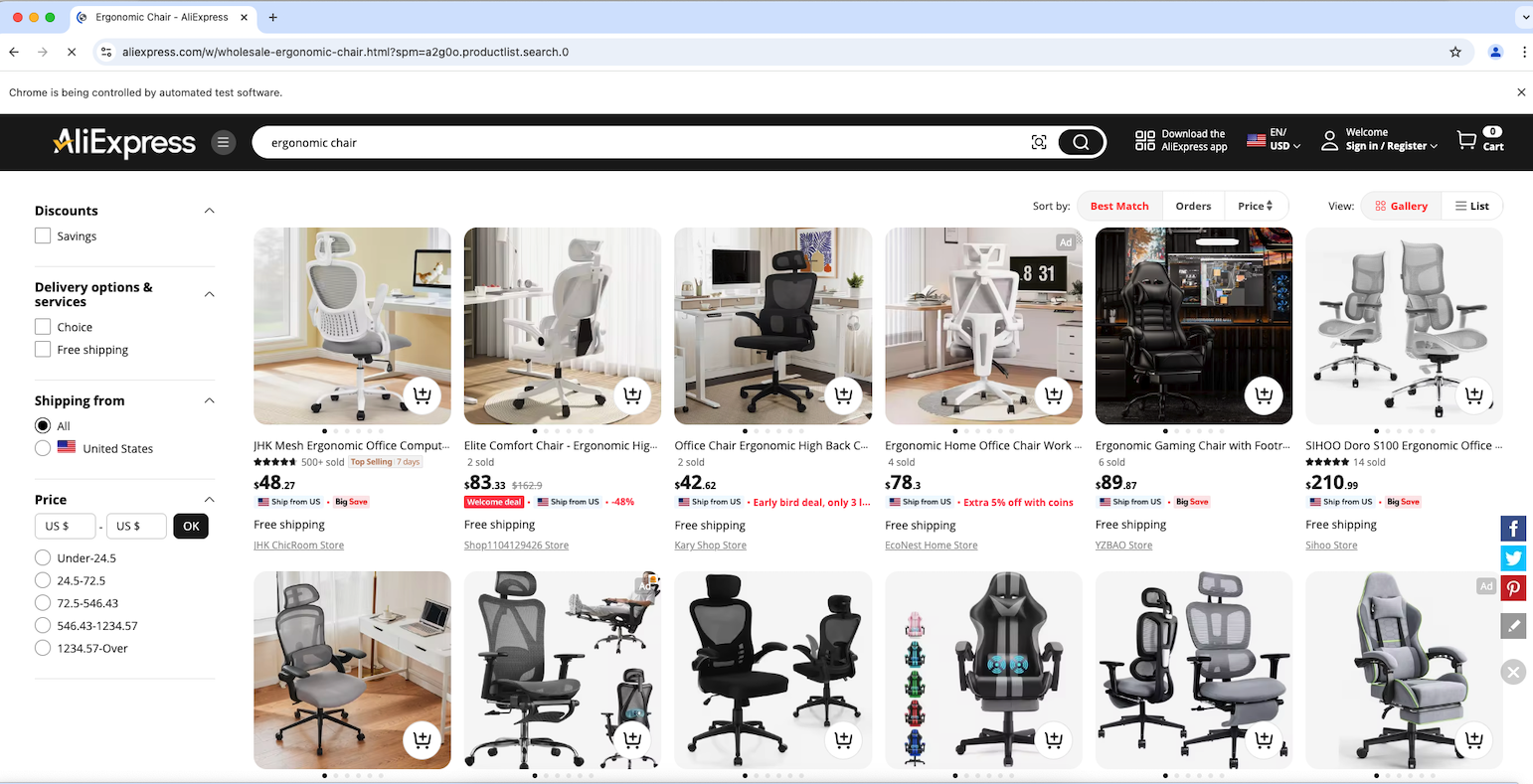
素晴らしい!「Chromeは自動テストソフトウェアによって制御されています」という通知は、設定通りSeleniumがChromeを正常に制御していることを示しています。
ステップ #5: 商品要素の選択
AliExpressの商品ページには複数の商品が含まれるため、スクレイピングしたデータを格納するデータ構造を最初に初期化する必要があります。この目的には配列が最適です:
products = []
サイトのレイアウト変更時でもスクレイパーが動作し続けるよう、セレクターの変更耐性を高めるヘルパー関数を作成します:
def find_element_smart(parent, by_list):
"""要素が見つかるまで複数のセレクタを試行"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
find_element_smart()関数は、指定された親要素内の要素を特定するため、by_listのセレクタ戦略リストを順に試行します。表示されている要素が見つかるまで各<by_type, selector>ペアを試行し、成功した場合はその要素を返します。一致する要素が見つからない場合はNoneを返します。
次に、ページ上の製品のHTML要素を調査し、それらの選択方法、含まれるデータの種類、およびそのデータの抽出方法を理解します。
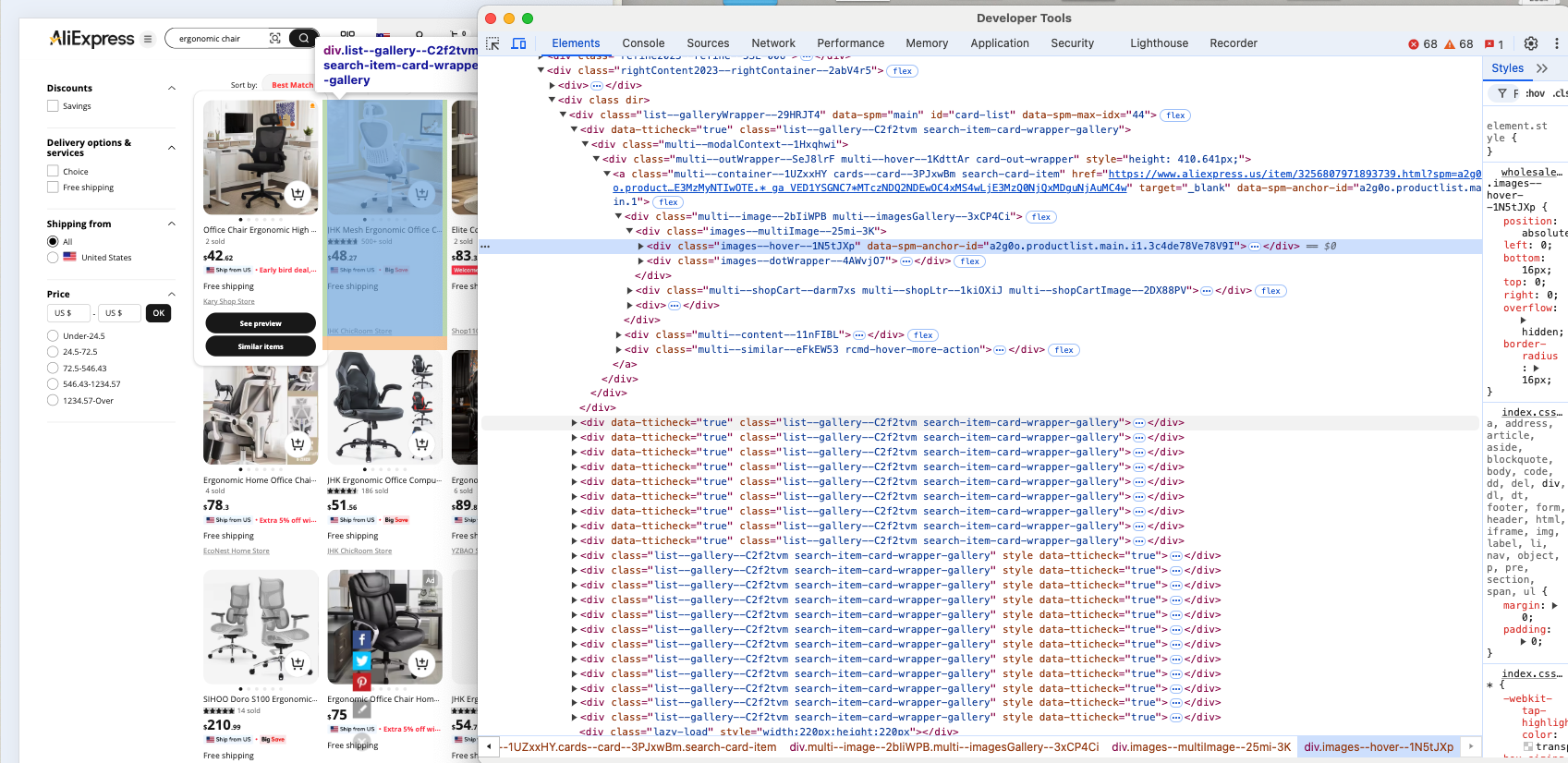
各商品要素が.list-–gallery—-C2f2tvm ノードであることは明らかです。
list--gallery--C2f2tvm はランダム生成された文字列を含むため、いつでも変更される可能性がある点に注意してください。したがって、要素選択にこのクラスを依存すべきではありません。代わりに、画像とリンクの両方を含むdiv 要素など、構造に基づいて製品を見つけることから始めるべきです。それが機能しない場合は、コンテンツに基づいて製品を探すか、より具体的な HTML 要素に焦点を当ててみてください。
商品選択ロジックを以下のように実装します:
# 構造パターンで製品を検索し、失敗時はクラスパターンにフォールバック
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# 商品の表示を待機して取得
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
上記のコードは、汎用的なCSSセレクタを使用してページ上の要素を取得するためのセレクタ戦略を適用します。
Pythonスクリプトに以下のインポートを含めてください:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
次に、WebDriverの初期化直後、ページ操作の前段階でWebDriverWaitインスタンスを導入します:
wait = WebDriverWait(driver, 20)
AliExpressのような動的ウェブサイトのウェブスクレイピングでは、ページ上の要素を即座に検索する代わりに、WebDriverWaitがスクレイパーに待機を指示し、要素が表示されるまで指定時間(この例では20秒)待機します。これは、ウェブページが要素を異なる速度で読み込むため重要です。適切な待機なしでは、スクレイパーが未読み込みの要素を処理してエラーを引き起こす可能性があります。
これでAliExpressの完全スクレイピングに一歩近づきました!
ステップ #6: AliExpress商品要素のスクレイピング
商品要素を検査してHTML構造を理解しましょう:
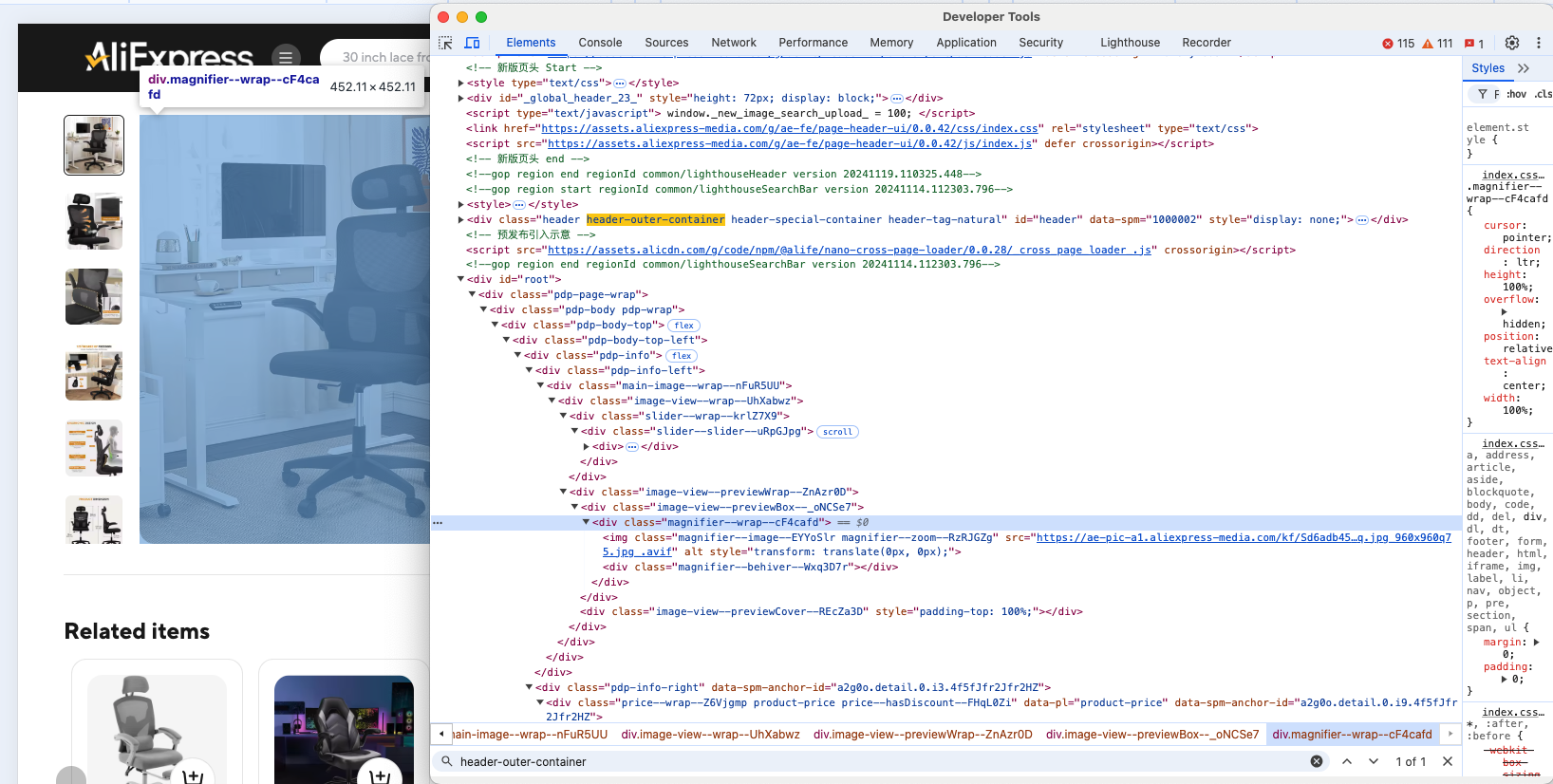
商品画像、URL、名称またはタイトル、価格、割引情報をスクレイピングできることが明らかです。
各商品をスクレイピングする前に、ビューポート内に表示されているか確認します:
wait.until(EC.visibility_of(product))
次に、各商品のデータをスクレイピングするためのセレクターを設定します。特定のクラス名を使用すると機能しなくなる可能性があるため、以下のようなパターンを使用します:
# 画像取得 - ソースパターンで商品画像を検索
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# URL取得 - 商品リンクを検索
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# タイトル取得 - 最長のテキスト要素を優先検索
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# 価格を取得 - 通貨記号/パターンを検索
price_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '$') or contains(text(), 'US') or contains(text(), 'GHS')]"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
# 割引情報がある場合取得を試みる
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
find_element()関数は、指定されたCSSセレクタに一致する最初の要素を返します。その後、text属性を使用してそのテキストコンテンツを抽出できます。
スクレイピングしたデータを products 配列に追加し、製品辞書を作成します:
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
これでデータ抽出ロジックが完成し、使用可能になりました。
ステップ #7: スクレイピングしたデータをCSVにエクスポート
現在の設定では、スクレイピングされたデータは products 配列に格納されています。他者と共有しアクセス可能にするには、CSVファイルなどの人間が読める形式にエクスポートする必要があります。スクレイピングしたデータでCSVファイルを作成・埋める方法は以下の通りです:
# CSVへのデータ書き込み
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
fieldnames = ["image_url", "product_url", "product_title", "product_price", "product_discount"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
writer.writeheader()
for product in products:
writer.writerow(product)
このコードはスプレッドシートのように機能するCSVファイルを作成します。各商品が独自の行を持ち、商品の詳細情報(画像、URL、タイトル、価格、割引情報)が別々の列に格納されます。最終的なaliexpress_products.csvファイルを開くと、スクレイピングしたAliExpressの商品情報が整然と列に配置されているのが確認できます。
最後に、Python標準ライブラリからcsvライブラリをスクリプトにインポートします:
import csv
ステップ #8: 全てを統合する
すべてのコードを統合した後の最終的なスクレイピングスクリプトは以下のようになります:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
def find_element_smart(parent, by_list):
"""複数のセレクターを試行し、要素が見つかるまで検索"""
for by_type, selector in by_list:
try:
element = parent.find_element(by_type, selector)
if element.is_displayed():
return element
except:
continue
return None
# ドライバーの初期化
driver = webdriver.Chrome()
wait = WebDriverWait(driver, 20)
# ターゲットURL
url = "https://www.aliexpress.com/w/wholesale-ergonomic-chair.html?spm=a2g0o.productlist.search.0"
driver.get(url)
# 初期商品の読み込み待機
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "div[class*='gallery']")))
# スクレイピングデータの保存先
products = []
# パターンで商品を検索、失敗時はクラスパターンにフォールバック
product_selectors = [
(By.XPATH, "//div[.//img and .//a[contains(@href, 'item')]]"),
(By.XPATH, "//div[.//img and .//*[contains(text(), '$')]]"),
(By.CSS_SELECTOR, "div[class*='gallery']")
]
# 商品の表示を待機して取得
wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div[class*='gallery']")))
products_found = []
for selector_type, selector in product_selectors:
try:
elements = wait.until(EC.presence_of_all_elements_located((selector_type, selector)))
if elements:
products_found = elements
break
except:
continue
# 見つかった商品を反復処理し、データをスクレイピング
for product in products_found:
# 商品が表示され操作可能になるまで待機
wait.until(EC.visibility_of(product))
# 画像取得 - ソースパターンで商品画像を検索
img_element = find_element_smart(product, [
(By.XPATH, ".//img[contains(@src, 'item') or contains(@src, 'product')]"),
(By.CSS_SELECTOR, "img[src*='item']"),
(By.CSS_SELECTOR, "img[class*='image']")
])
# URLを取得 - 商品リンクを検索
url_element = find_element_smart(product, [
(By.CSS_SELECTOR, "a[href*='item']"),
(By.XPATH, ".//a[contains(@href, 'product')]")
])
# タイトル取得 - 最初の長いテキスト要素を検索
title_element = find_element_smart(product, [
(By.XPATH, ".//div[string-length(text()) > 20]"),
(By.XPATH, ".//*[contains(@class, 'title')]"),
(By.CSS_SELECTOR, "[class*='name']")
])
# 価格を取得
price_element = find_element_smart(product, [
(By.CSS_SELECTOR, "*[class*='price-sale']"),
(By.CSS_SELECTOR, "*[class*='price']"),
(By.XPATH, ".//*[contains(@class, 'price')]")
])
if all([img_element, url_element, title_element, price_element]):
# 割引情報がある場合取得
discount_element = find_element_smart(product, [
(By.XPATH, ".//*[contains(text(), '%') or contains(text(), 'OFF')]"),
(By.CSS_SELECTOR, "[class*='discount']")
])
products.append({
"image_url": img_element.get_attribute("src"),
"product_url": url_element.get_attribute("href"),
"product_title": title_element.text.strip(),
"product_price": price_element.text.strip(),
"product_discount": discount_element.text.strip() if discount_element else "N/A"
})
# 結果を保存
csv_file_name = "aliexpress_products.csv"
with open(csv_file_name, mode="w", newline="", encoding="utf-8") as csv_file:
writer = csv.DictWriter(csv_file, fieldnames=["image_url", "product_url", "product_title", "product_price", "product_discount"])
writer.writeheader()
writer.writerows(products)
driver.quit()
次に、以下のコマンドでスクレイパーを起動します:
python スクレイパー.py
スクリプトは正常に実行され、aliExpress_products.csvファイルには以下のように抽出データが含まれるはずです:
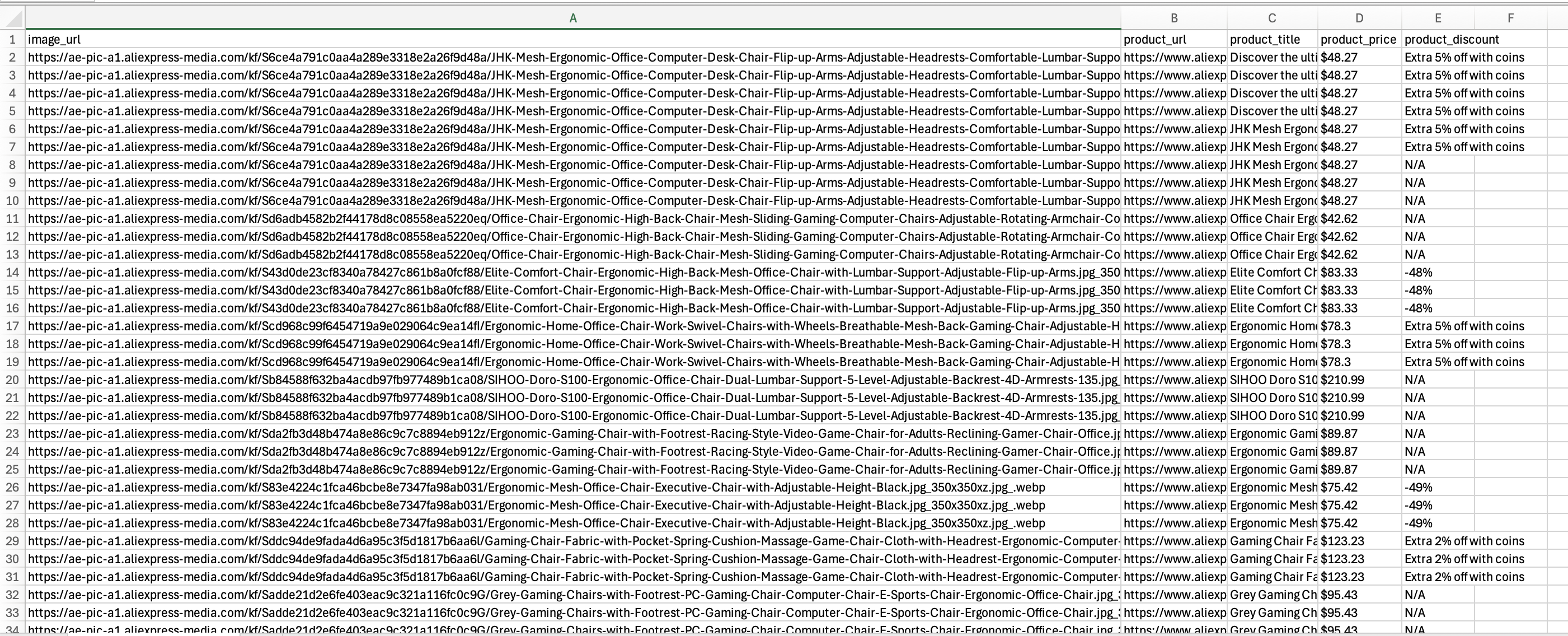
機能するスクレイピングスクリプトを構築した後、実行プロセスの自動化や最適化の実装など、いくつかの追加ステップを踏むことができます。これにより、スクレイパーが長期にわたり価値あるデータを提供し続けることが保証されます。
まとめ
本ガイドでは、AliExpressスクレイパーの定義と抽出可能なデータの種類について解説しました。また最小限のコードでAliExpress商品をスクレイピングするPythonスクリプトの作成方法を学びました。
しかし、AliExpressのスクレイピングにはいくつかの課題があります。プラットフォームは厳格なボット対策を実施しており、ページネーションなどの機能を使用しているため、スクレイピングプロセスに複雑さが加わります。強力なAlibabaスクレイピングソリューションを開発することは非常に困難です。
当社のAliExpressスクレイパーAPIは、こうした課題を解消する専門的なソリューションを提供します。シンプルなAPI呼び出しで、ブロックリスクを軽減しながら対象サイトからシームレスにデータを取得できます。データをすぐに必要ですか?
スクレイパーAPIの試用やデータセットの探索をご希望ですか?今すぐBright Dataアカウントを作成し、無料トライアルを開始しましょう!






