このブログ記事では、以下の内容をご紹介します:
- Convexとは何か、そのメンタルモデルがどのように機能するか、そして他のデータベースとの比較について。
- その詳細な仕組みと、基盤となる主要コンポーネントについて。
- リアルタイムのWebデータを保存する際に、Convexがなぜ優れているのか。
- ウェブからライブデータを取得する際の主な障害と課題。
- Bright Dataが、Convexでの保存に即対応可能な構造化されたリアルタイムWebデータを提供することで、これらの課題の解決をどのように支援するか。
- ウェブデータ取得にBright Dataを、データ保存とシームレスなUI更新にConvexを組み合わせた完全なデモの始め方。
さっそく見ていきましょう!
Convexの概要
まず、Convexとは何か、どのようなメリットがあり、その背後にある基本的な概念を理解するために、Convexについて探ってみましょう。
Convex とは?
Convexは、Webアプリとモバイルアプリを常に同期させるために設計された、オープンソースのリアクティブバックエンドプラットフォームです。
内部的には、データベース、サーバーレス関数、認証、クライアントライブラリを単一のシステムに統合しています。Reactコンポーネントが状態の変化に応答するように、Convexのクエリはデータベースの更新に自動的に反応するため、ライブで動的なアプリケーションに最適です。
クエリはTypeScriptで記述され、データベース内で直接実行されるため、開発が簡素化されると同時に、インフラのオーバーヘッドを最小限に抑えながら高速でリアクティブなアプリケーションを実現します。また、このソリューションはモジュール式コンポーネント、リアルタイムデータ同期、スケジューリング、AI支援によるコード生成もサポートしています。React、Next.js、Vue、Svelte、Nuxtなどのフレームワークと統合できるほか、Python、Swift(iOS向け)、Kotlin(Android向け)、Rustアプリケーションとも相互運用が可能です。
その柔軟性により開発者の間で人気を博しており、GitHubでは1万900件以上のスターを獲得し、npmでの週間ダウンロード数は40万件を超えています。
Convexの核心的な考え方:そのメンタルモデルを理解する
従来のデータベースとは異なり、Convexはデータベースを単なる受動的なデータストレージではなく、ライブでリアクティブなシステムとして扱います。データが追加、更新、または削除されるたびに、その変更は不変のトランザクションログに記録されます。これは、すべての操作の永続的なタイムスタンプ付き履歴です。同時に、クエリは単にデータを取得するだけではありません。クエリは、読み込んだデータの一部を自動的に追跡し、これを「リードセット」と呼びます。
これにより、Convexはクエリが依存するデータのいずれかが変更されたことを即座に検知でき、システムは結果をリアルタイムで更新することが可能になります。このアーキテクチャはリアルタイムサブスクリプションをサポートし、決定論的トランザクションと楽観的並行制御メカニズムを通じて強力な一貫性を維持します。これらの特性のおかげで、複数のユーザーが競合することなく、同時にデータベースとやり取りすることができます。
Convexと他のデータベースの比較
Convexが他の人気データベースとどのように位置づけられているかをより深く理解するには、以下の比較表を参照してください:
| 機能 | Convex | Firebase | Supabase | 従来のSQLデータベース |
|---|---|---|---|---|
| データベースの種類 | トランザクション対応ドキュメントストア | NoSQL / Firestore | PostgreSQL | リレーショナルSQL |
| リアルタイム | ✔️ (組み込み、自動サブスクリプション) | ✔️ (標準搭載) | ➖ (オプション、別途サーバー経由) | ❌ (ネイティブではない) |
| トランザクション | 常にトランザクション処理 | 制限あり | サポートされている | サポートされている |
| スキーマ | オプション、段階的、TypeScriptから自動生成 | 柔軟 / スキーマレス | 強制(Postgres) | 厳格、手動 |
| SQLのサポート | ❌ | ❌ | ✔️ | ✔️ |
| TypeScript 統合 | 完全 | 限定 | 一部対応(サーバーサイド) | ORMに依存 |
| 認証/OAuth | 標準 + ネイティブ | 標準 + Firebase Auth | 標準 + ネイティブ | カスタム設定 |
| データベースの責任範囲 | Convexが全面的に管理 | 共有 | 共有 | 開発者が完全に管理 |
Convexの仕組み:アーキテクチャ、コンポーネント、データフロー
Convexのアーキテクチャは、3つの主要コンポーネントからなるフルスタックバックエンドプラットフォームに基づいています:
- データベース:JSON のようなオブジェクトがテーブルに整理された、リアクティブなドキュメントリレーショナルストアです。Convex データベースは各プロジェクトごとにクラウド上で自動的にプロビジョニングされるため、手動での接続設定やクラスタ管理は不要です。
- サーバー関数:クエリとミューテーションは TypeScript 関数として記述されるため、SQL や ORM は不要です。クエリは純粋な読み取り専用であり、ミューテーションはACID 保証、シリアライズ可能な分離レベル、および楽観的並行制御を備えた完全管理型のトランザクション内で実行されます。
- クライアントライブラリ:サーバー関数をサブスクライブし、結果を自動的に同期し、ミューテーションキューを管理するフレームワーク固有のライブラリ(Next.js、React、Vue、Svelteなど)。これらは、手動でのサブスクライブや状態管理を必要とせずに、一貫性のあるリアルタイムのUI更新を保証します。
これら3つのコンポーネントにより、データはサーバー関数を介してデータベースからクライアントへとリアクティブに流れます。クエリは依存関係を自動的に追跡し、データが変更されると再実行され、更新をリアルタイムでプッシュします。ミューテーションは完全に管理されたトランザクションとして実行され、データベースと依存するクエリを更新することで、手動での同期なしにクライアントが常に最新の状態を確認できるようにします。
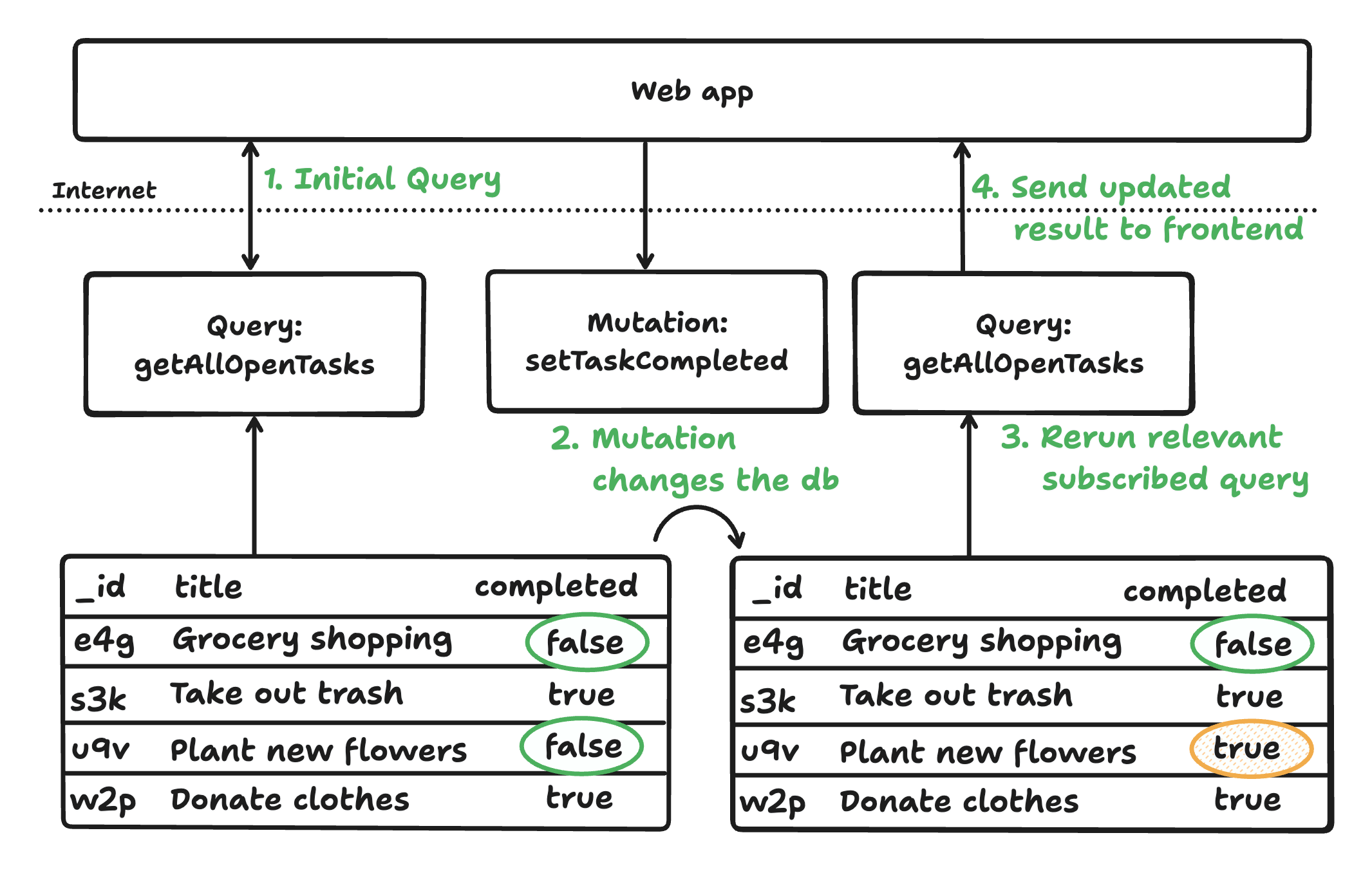
Convexの統合されたアーキテクチャは、最小限の定型コードで、リアクティブかつ一貫性があり、型安全なアプリケーションを保証します。データベースのチューニングや同期処理を抽象化することで、人間によるコードとAI生成コードの両方における迅速な開発をサポートします。Convexは、認証やスケジューリングなどの機能も提供しています。
ConvexとリアルタイムWebデータの組み合わせが最適な理由
Convexのようなリアルタイムデータベースは、データソース自体がリアルタイムである場合にのみ、その真価を発揮します。つまり、そのリアクティブアーキテクチャは、リアルタイムの状況(株価、ソーシャルメディアのフィード、ニュースの更新、ECサイトの在庫など)を反映する必要があるアプリケーションに最適です。
さて、地球上で最も大規模かつ絶えず変化し続ける動的データの源とは何でしょうか?それはウェブです!ウェブデータは数百万ものソースからリアルタイムで流れ込んでおり、Convexベースのリアクティブアプリケーションにとって理想的な入力源となります。
ConvexをリアルタイムのWebデータストリームに接続することで、アプリは複雑なポーリングや手動の同期、状態管理を行うことなく、更新に即座に対応できます。これにより、情報とユーザーインターフェース間の遅延が解消され、シームレスで常に最新のユーザー体験が実現します。
WebデータをConvexアプリケーションに接続する際の課題
ここまでで、リアルタイムのWebデータがConvexのようなソリューションに最適である理由がお分かりいただけたでしょう。次の疑問は、実際にどのようにデータを取得するかということです。その答えは「ウェブスクレイピング」です。これは、プログラムを用いてWebページから情報を抽出するプロセスです。
ウェブスクレイピングは強力な手法ですが、いくつかの課題も伴います。これらは技術的なハードルから運用上の複雑さまで多岐にわたり、具体的には以下の通りです:
- 動的コンテンツ:現代のウェブサイトはJavaScript、AJAX、そして複雑なナビゲーションやインタラクションパターンに依存しており、構造化されたデータの抽出をより困難にしています。
- ボット対策:多くのウェブサイトでは、CAPTCHA、レート制限、フィンガープリント、その他の防御手段を用いて、自動化されたアクセスを検知・ブロックしています。
- 頻繁な変更:レイアウト、HTML構造、URLは頻繁に変更されるため、スクレイパーが機能しなくなり、継続的な監視とメンテナンスが必要となります。
- スケーラビリティ:大規模なデータ収集には、堅牢なインフラストラクチャ、IPローテーションのための信頼できるプロキシプロバイダーとの連携、そして堅牢なエラー処理が求められます。
- データの一貫性:特に頻繁に更新されるデータの場合、正確性、完全性、および最新性を確保することは困難です。
その結果、Webデータ上に完全にリアクティブなConvexアプリケーションを構築することは、非常に困難な作業となります。これらの課題を自力で解決しようとするのではなく、Bright Dataのようなエンタープライズ対応のリアルタイムWebデータプロバイダーに依存することが最適なアプローチです。
リアルタイムWebデータに基づくリアクティブアプリのためのBright Data + Convex
ライブWebデータを活用したリアクティブアプリケーションの開発において、Bright DataとConvexの組み合わせは際立っています。両者を組み合わせることで、役割分担が明確になります。Bright Dataは大規模なデータ収集に注力し、Convexはライブ状態の同期とUIの更新を処理します。
Bright Data を使用すれば、プログラムによってリアルタイムでウェブ上の情報を検索・抽出できます。スクレイピングされたデータは構造化された JSON 形式で返され、Convex に容易に取り込むことができます。その後、Convex がリアクティブクエリを通じて、接続されたすべてのクライアントにデータを即座に伝播させます。
Bright Dataの特に魅力的な点は、エンタープライズグレードのインフラストラクチャにあります。同社は世界最大級のプロキシネットワークの一つを運用しており、195カ国にまたがる1億5,000万以上のIPアドレスを保有し、無制限の同時接続を実現しています。この基盤により、99.99%の稼働率、99.95%の成功率、24時間365日のサポートといった高い信頼性が支えられています。
Bright Dataのすべてのリアルタイムデータ取得ソリューションは、このインフラストラクチャを基盤として構築されています。主なサービス内容は以下の通りです:
- WebスクレイパーAPI:人気ウェブサイトから構造化されたライブデータを抽出するための、すぐに使えるAPIエンドポイント。
- Unlocker API:CAPTCHA、ブロック機能、ボット対策システムを自動的に処理し、ブロックされていないページコンテンツへのアクセスを可能にします。
- SERP API:複数の検索エンジンからのリアルタイム検索結果を提供し、応答時間は1秒未満のレイテンシーを実現します。
- Crawl API:ウェブサイト全体を構造化されたデータセットに変換します。
ConvexとBright Dataの組み合わせにより、ウェブスクレイピングに伴う一般的な運用上の負担なしに、ウェブからユーザーへ新鮮なデータを継続的に提供することが可能になります。その結果、リアルタイムのウェブデータに基づいた、スケーラブルで保守性が高く、完全にリアクティブなシステムが実現します。
アーキテクチャの例
以下は、Convexで構築され、Bright Dataが提供するリアルタイムWebデータを利用するリアクティブWebまたはモバイルアプリケーションのアーキテクチャ例です:
- データ取得のトリガー(Bright Data):ユーザーが特定のアクション(例:ボタンのクリック)を実行すると、フロントエンドからバックエンドへリクエストが送信されます。サーバーはその後、Bright Data APIを呼び出してウェブから最新のデータを取得します。スクレイピングされるデータには、商品価格、ニュース記事、求人情報などが含まれます。
- バックエンド処理(Convex):構造化されたJSONデータを受信すると、ミューテーションを通じてConvexに渡されます。この段階で、データは取り込まれ、正規化、検証され、Convexデータベースに保存されます。また、アプリケーションのロジックに基づいて、ここでデータをエンリッチ(拡張)したり変換したりすることも可能です。
- UIのライブ更新(Convexのリアクティブ機能):フロントエンドはConvex内のクエリをサブスクライブします。データベースが更新されるとすぐに、関連するクエリが自動的に再実行されます。更新された結果は即座にクライアントにプッシュされ、手動操作なしにUIがリアルタイムで更新されます。
ConvexとBright Dataを活用したリアルタイムAI市場調査ターミナルの構築方法
ConvexとBright Dataの統合によって可能になる活用例として、実際のデモである「BrightDataのAI市場調査ターミナル」を見てみましょう。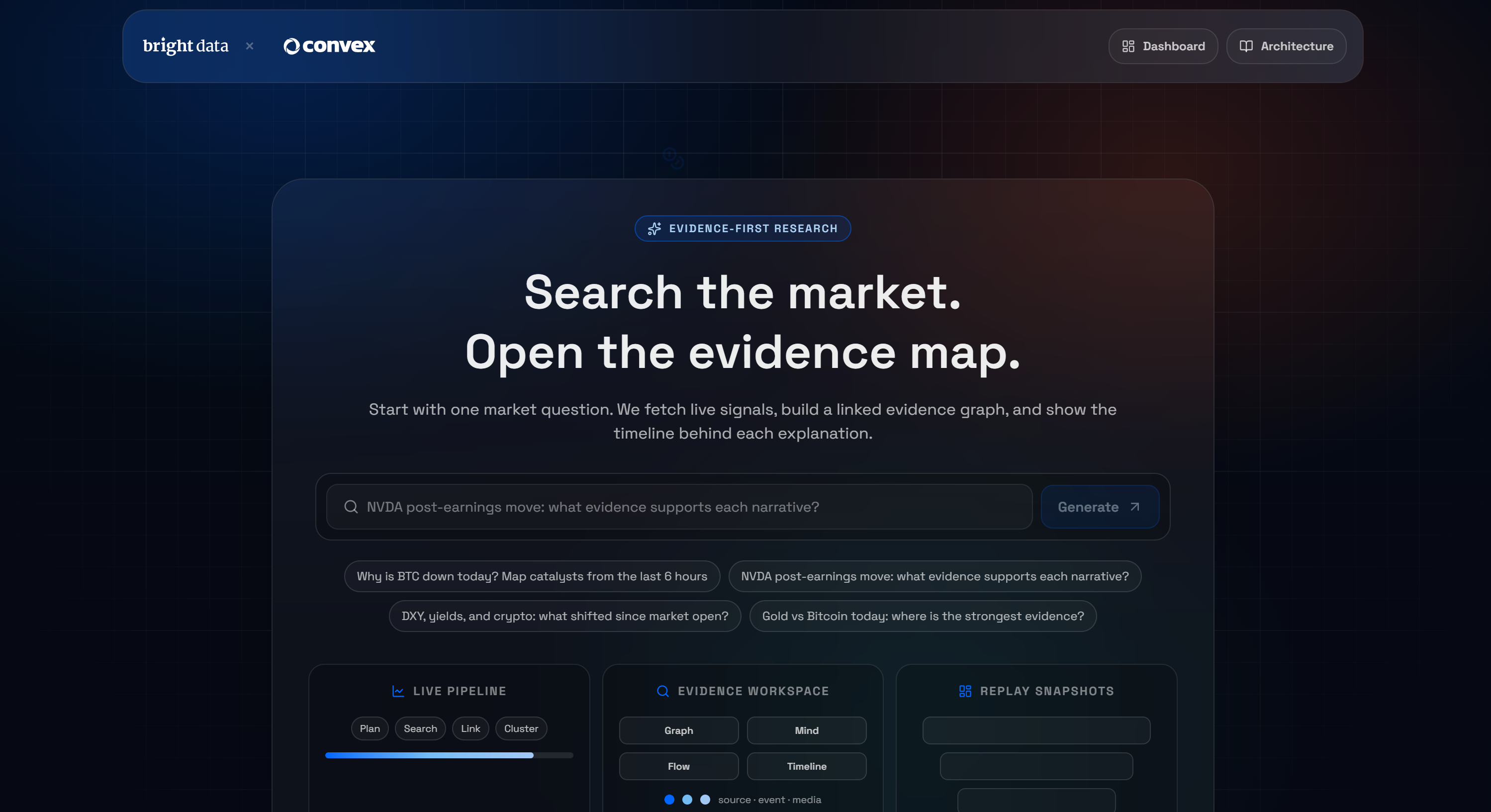
これはConvex上に構築されたNext.jsアプリケーションであり、質問を入力すると、ウェブスクレイピングによって生成されたライブのエビデンスグラフを受け取ることができます。この概念に馴染みのない方のために説明すると、エビデンスグラフとは、データ、主張、および裏付けとなる証拠の間の関係を示す構造化された表現のことです。
内部的には、このアプリケーションは8つの段階で構成されるパイプラインに従っています:
- Plan:LLMがトピックに基づいて4~6個の焦点を絞った検索クエリを生成します。
- Search:4~6件のBright Data SERP APIリクエストを同時に送信します。
- スクレイピング:Bright Data Web Unlocker APIを使用して、上位のURLをMarkdown形式で抽出します。
- 抽出(Extract):SERPスニペットとMarkdownを組み合わせて、構造化された証拠項目を作成します。
- 要約: LLMが各項目について、主要な要点、エンティティ、要因、および感情を抽出します。
- 成果物:信頼度スコア付きのナレッジグラフのノードとエッジを構築します。
- リンク: 接続性の修正、ドメインタグ付け、テープイベントなどを含むヒューリスティックなエンリッチメントを適用します。
- レンダリング → 完了:最終的なアーティファクトをクライアントにストリーミングしつつ、Convex内でセッションを永続化します。
さあ、このデモを実際に試して、ローカル環境でテストしてみましょう!実世界のConvex + Bright Dataアプリケーションが、リアクティブなワークフローでライブWebデータを収集、処理、配信する様子をご覧ください。
前提条件
このチュートリアルセクションを順を追って進めるには、以下の環境が整っていることを確認してください:
- Node.js 20以上がローカルにインストールされていること。
- OpenRouter API キー。
- SERPおよびWeb Unlockerゾーンが設定されたBright Dataアカウント。
- Convexプロジェクトがセットアップされていること(無料プランで十分です)。
- ローカル環境にGitがインストールされていること。
Bright Data と Convex の設定については、現時点では心配する必要はありません。これらについては、2つの専用のサブチャプターで順を追って説明します。
ステップ #1: Bright Data アカウントの準備
冒頭で述べたように、このデモアプリケーションは2つのBright Data製品を利用しています:
- SERP API
- Web Unlocker API
以下では、アカウントでの設定手順をご案内します。より詳細な手順については、Bright Dataの公式ドキュメントもご参照ください:
まだアカウントをお持ちでない場合は、作成してください。すでにアカウントをお持ちの場合は、ログインしてください。ログイン後、コントロールパネルの「Proxies & Scraping」ページに移動します。「My Zones」セクションで、「SERP API」と「Web Unlocker API」というラベルの付いた行を探してください: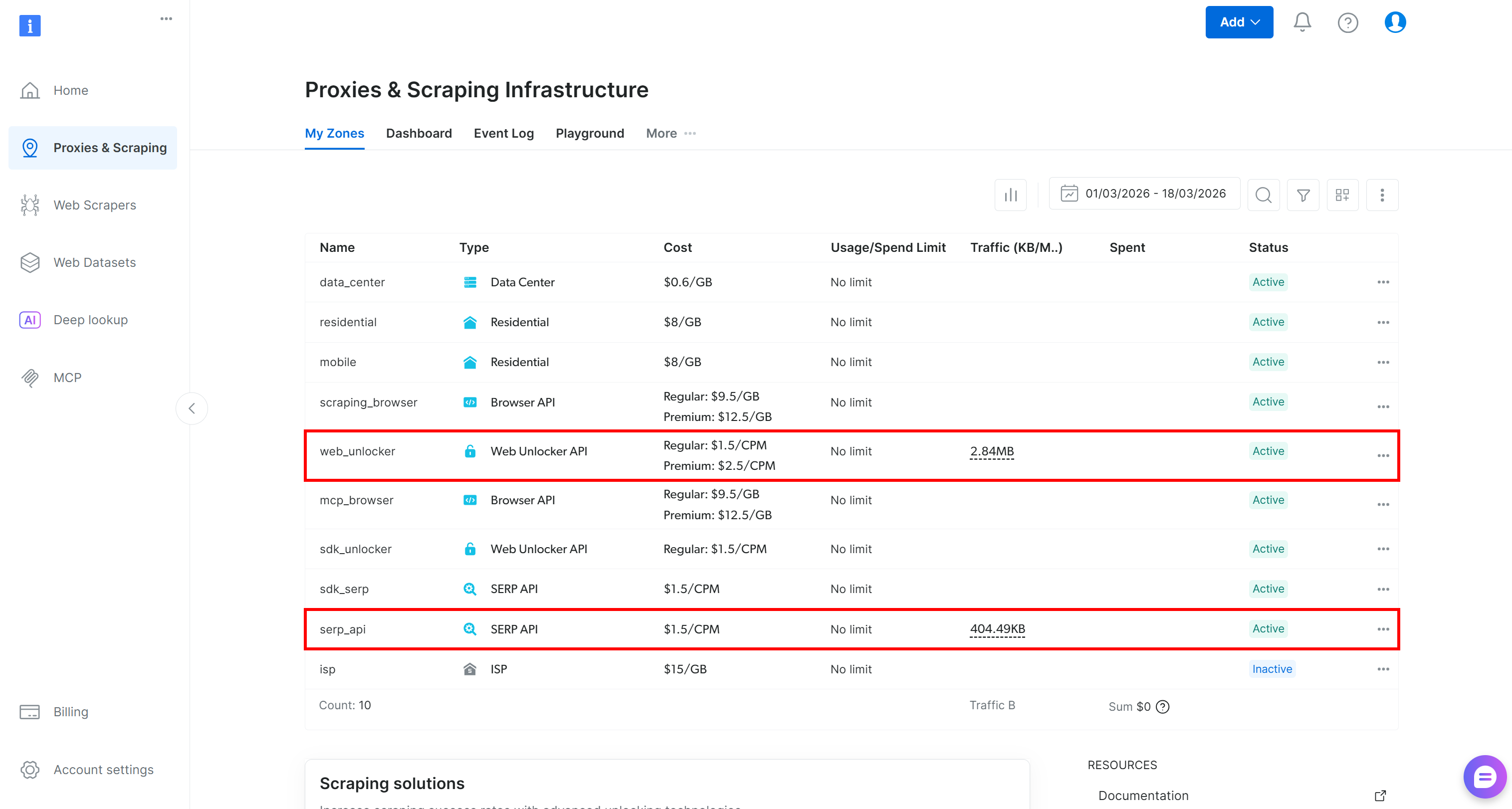
いずれかの行が表示されていない場合は、対応するゾーンがまだ設定されていないことを意味します。例えば、SERP APIゾーンを作成するには、「SERP API」セクションまでスクロールし、「Create Zone」をクリックしてください: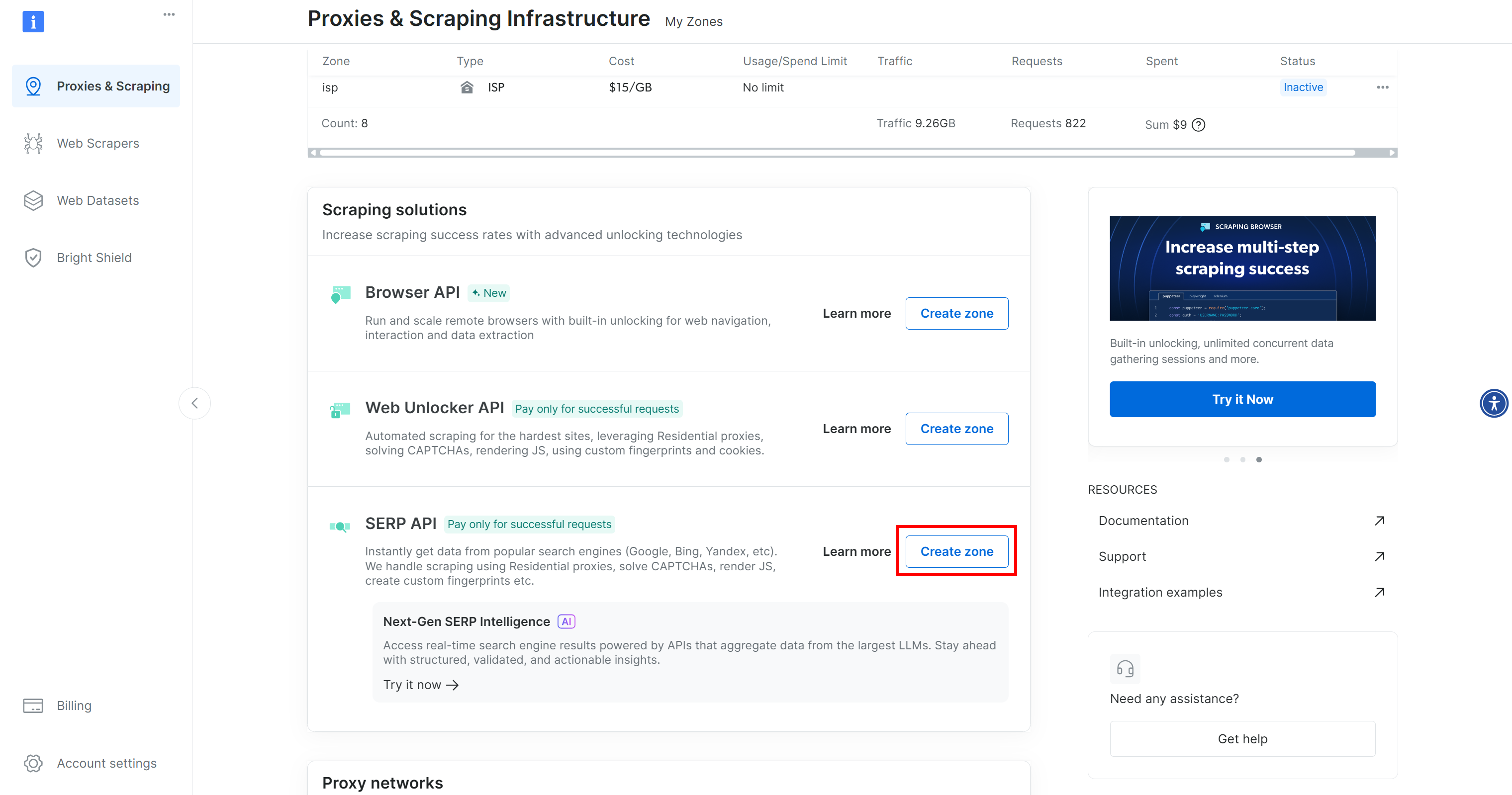
SERP APIゾーンを作成し、serp_api(または任意の名前)などの名前を付けます。ゾーン名は後で必要になるため、メモしておいてください。
Web Unlocker APIについても同様の手順を繰り返します。このチュートリアルでは、Web Unlockerゾーンの名前をweb_unlocker とすることを前提とします。
最後に、公式チュートリアルに従ってBright Data API キーを生成してください。Convex 搭載の Next.js アプリから SERP API および Web Unlocker への API リクエストを認証するために必要となるため、安全に保管してください。
素晴らしい!これでBright Dataアカウントの設定は完了し、AI市場調査端末のデモへの統合準備が整いました。
ステップ #2: Convex アカウントの設定
まず、Convexにログインするか、まだアカウントをお持ちでない場合は新規アカウントを作成してください。Convexのダッシュボードが表示されます:
ここで、「Create Project」ボタンを押してください。プロジェクト名を「AI 市場調査端末」(またはお好みの名前)とし、「Create」をクリックします: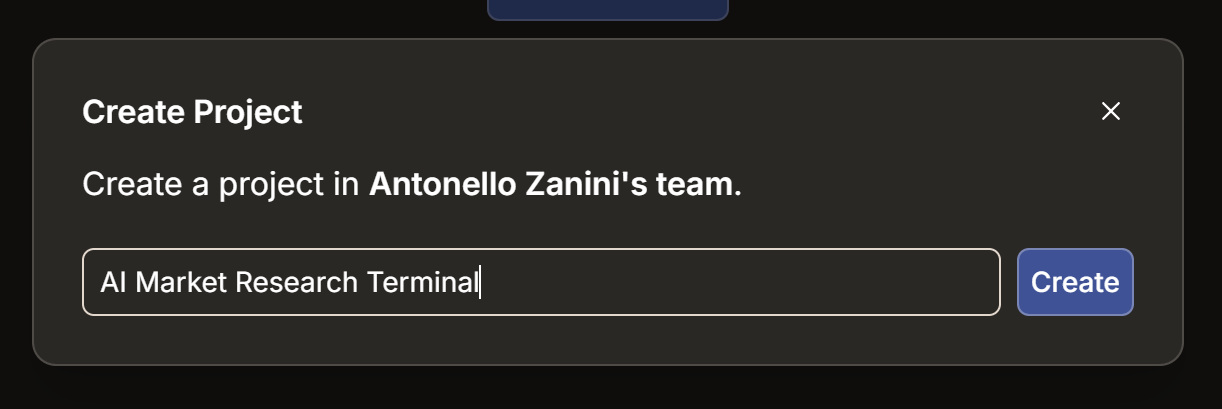
プロジェクトの初期化が完了するまで待ち、デプロイメント地域を選択してください: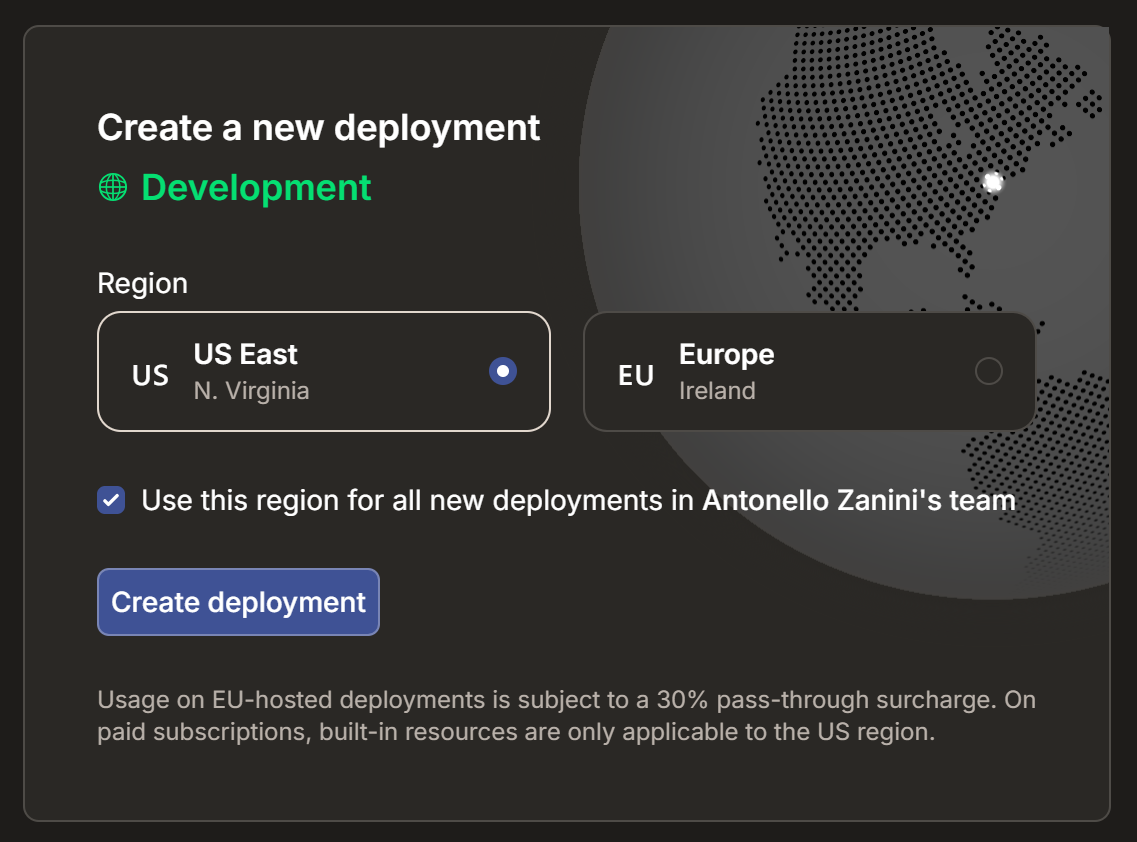
「デプロイメントの設定」を押して確定します。数秒後、プロジェクトの準備が整います:
素晴らしい!これで、プロジェクトをクローンしてローカルで実行するために必要なすべての準備が整いました。
ステップ #3: プロジェクトの設定
まず、デモリポジトリを ai-market-research-terminal/ というローカルフォルダにクローンします:
git clone https://github.com/brightdata/market-terminal AI-市場調査-terminalこれで、AI市場調査端末/プロジェクトフォルダには、公式リポジトリにリストされているすべてのファイルが含まれるはずです。
プロジェクトディレクトリに移動します:
cd ai-市場調査端末次に、プロジェクトの依存関係をインストールします:
npm install素晴らしい!これで、Visual Studio Code などのお気に入りの JavaScript IDE でプロジェクトを開くことができます。実際に操作して、その仕組みに慣れてみてください。詳細情報や開発の舞台裏については、DEV の専用ディープダイブ記事をご覧ください。
ステップ #4: アプリケーションの設定
アプリケーションは、すべての設定を.env.localファイルから読み込みます。リポジトリには.env.local.example というサンプルファイルが含まれています。これをコピーして、独自の.env.localファイルを作成してください:
cp .env.local.example .env.local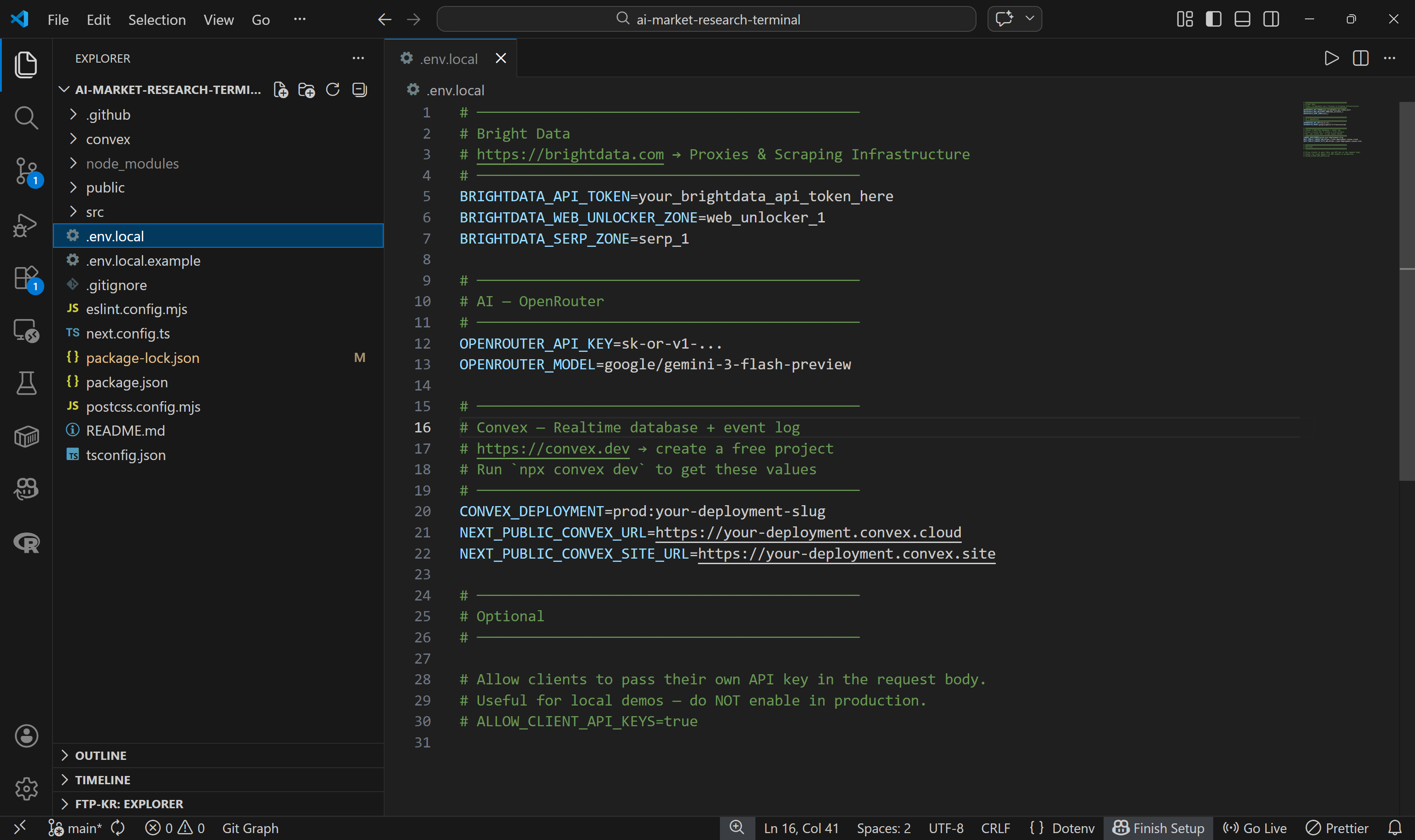
次に、プロジェクトのルートフォルダで次のコマンドを実行して、Convexコネクタを設定します:
npx convex dev指示に従い、ブラウザでデバイスをConvexアカウントに接続してください。その後、ステップ #2 で作成した既存の「AI市場調査端末」プロジェクトを選択します。Convexは、必要な環境変数を.env.localファイルに自動的に更新します。この場合、以下が追加されます:
CONVEX_DEPLOYMENT=dev:deafening-bloodhound-209
NEXT_PUBLIC_CONVEX_URL=https://deafening-bloodhound-209.convex.cloud
NEXT_PUBLIC_CONVEX_SITE_URL=https://deafening-bloodhound-209.convex.siteこれらの値により、アプリケーションはConvexプロジェクトに接続できるようになります。
デフォルトでは、Convexプロジェクトに2つの新しいテーブル(sessionEnvtsとsession)が追加されます: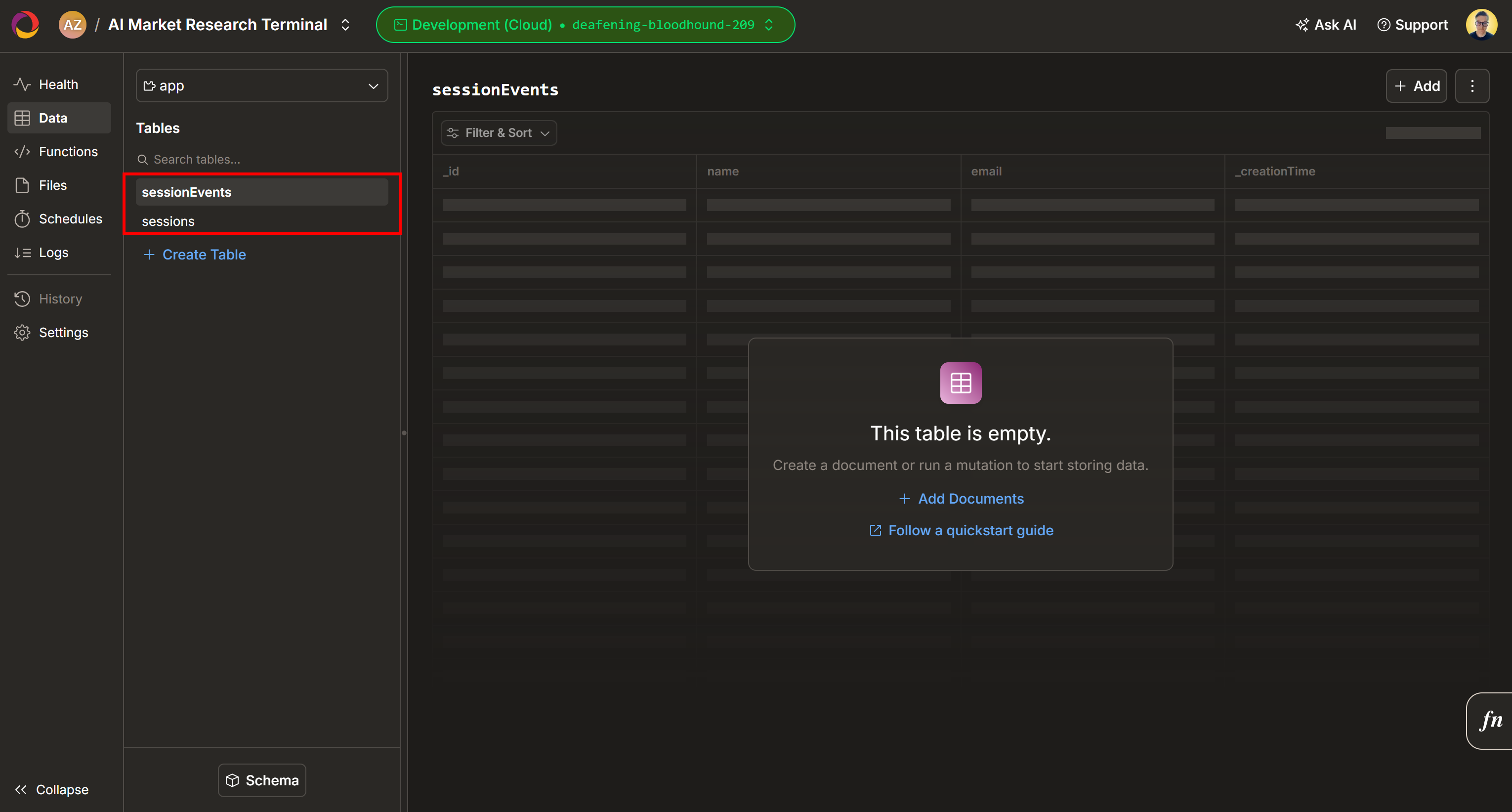
次に、.env.local ファイルの残りの環境変数を設定します:
BRIGHTDATA_API_TOKEN=<YOUR_BRIGHTDATA_API_KEY>
BRIGHTDATA_WEB_UNLOCKER_ZONE=<YOUR_BRIGHTDATA_WEB_UNLOCKER_API_NAME> # 例: "web_unlocker"
BRIGHTDATA_SERP_ZONE=<YOUR_BRIGHTDATA_SERP_API_NAME> # 例: "serp_api"
OPENROUTER_API_KEY=<YOUR_OPENROUTER_API_KEY>
OPENROUTER_MODEL=google/gemini-3-flash-previewプレースホルダーを、Bright Data API トークン、Web Unlocker ゾーン名、SERP API ゾーン名、および OpenRouter API キーに置き換えてください。デフォルトの LLM はGemini 3 Flash ですが、必要に応じて他のサポートされているモデルを使用することも可能です。
素晴らしい!これでデモの設定は完了し、ローカルで実行できる状態になりました。
ステップ #5: アプリケーションをローカルで実行する
以下のコマンドでローカルでデモを起動します:
npm run devブラウザでhttp://localhost/market-terminalを開き、ローカルのAI 市場調査 Terminalアプリにアクセスしてください。次のような画面が表示されます: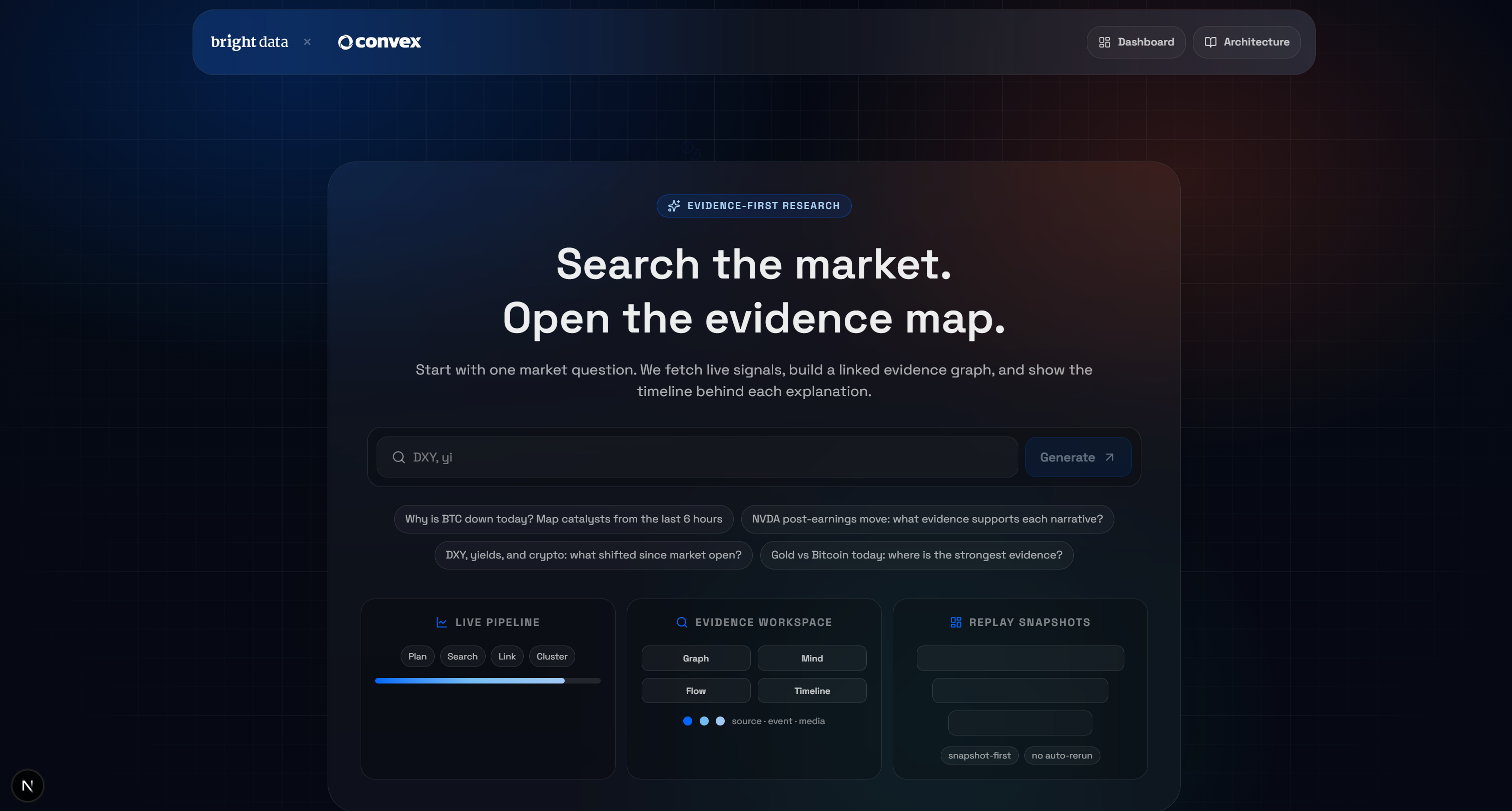
クエリを入力してアプリケーションをテストしてください。例:
「なぜ今日のBTCは下落しているのですか?」「Generate」ボタンを押すと、次のような結果が表示されます: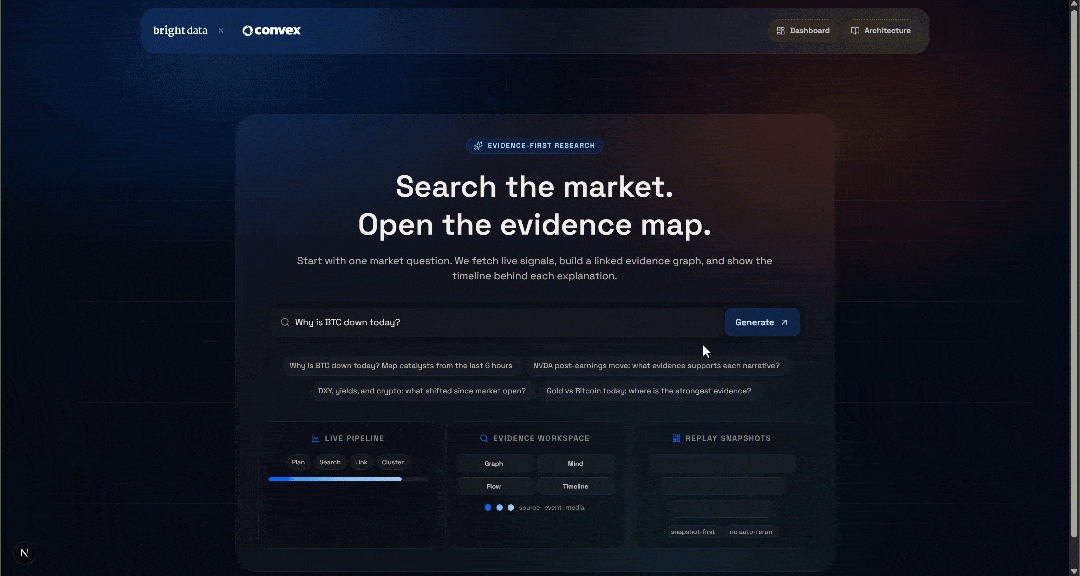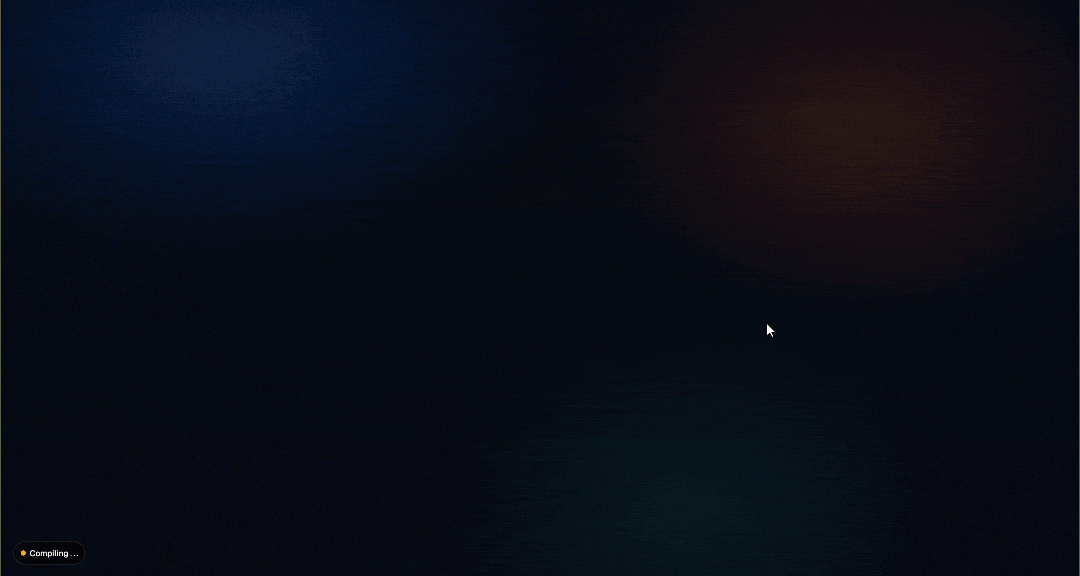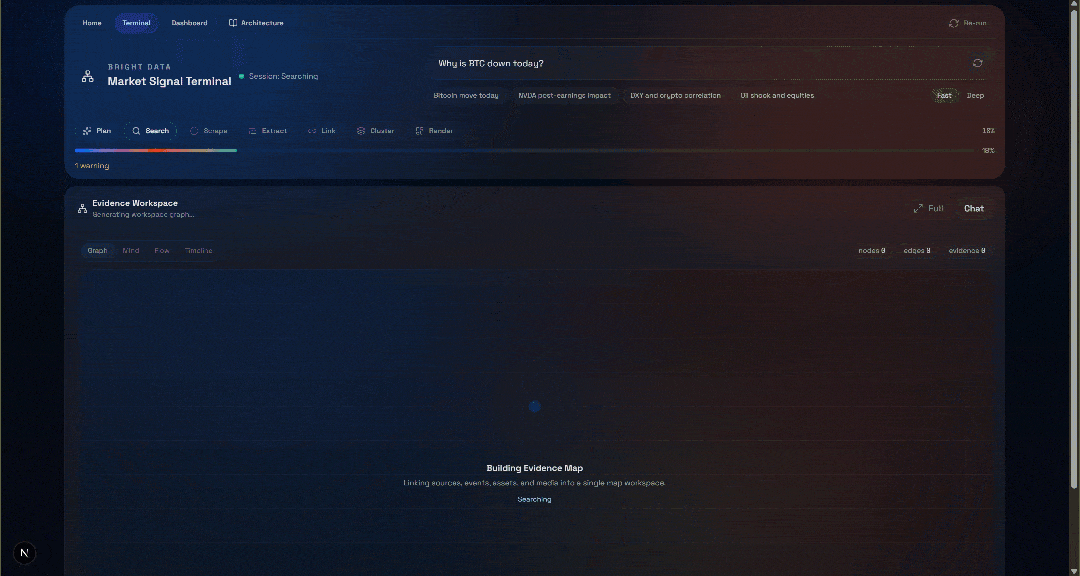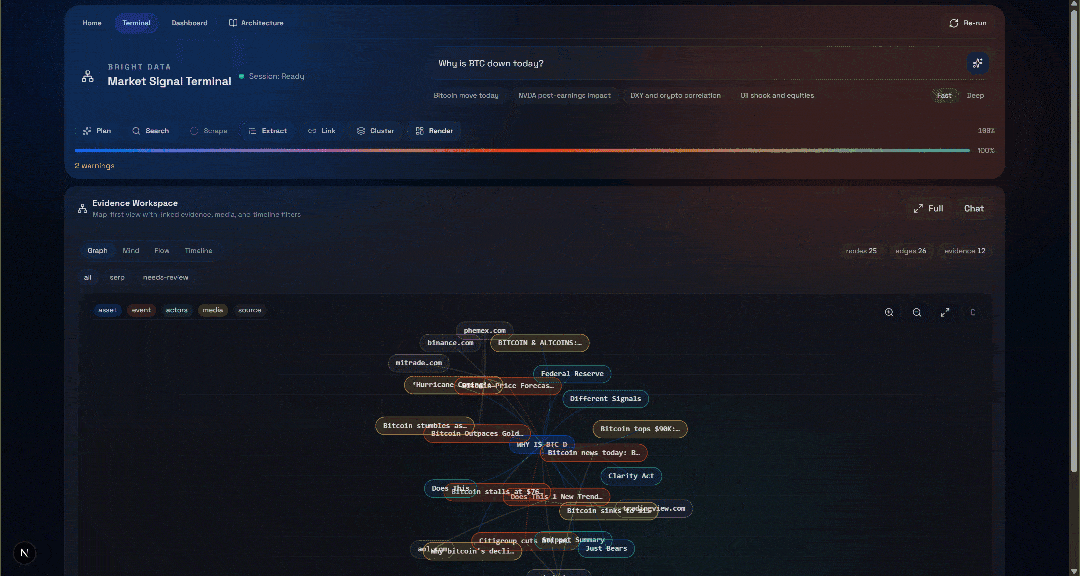
次に、「Evidence Workspace」セクションを確認してください。このビューには、ウェブスクレイピングを通じてリアルタイムで取得され、集計・処理され、Convexに保存されたすべてのデータが含まれています。Convexデータベースには、今回の実行に関するデータが格納されます: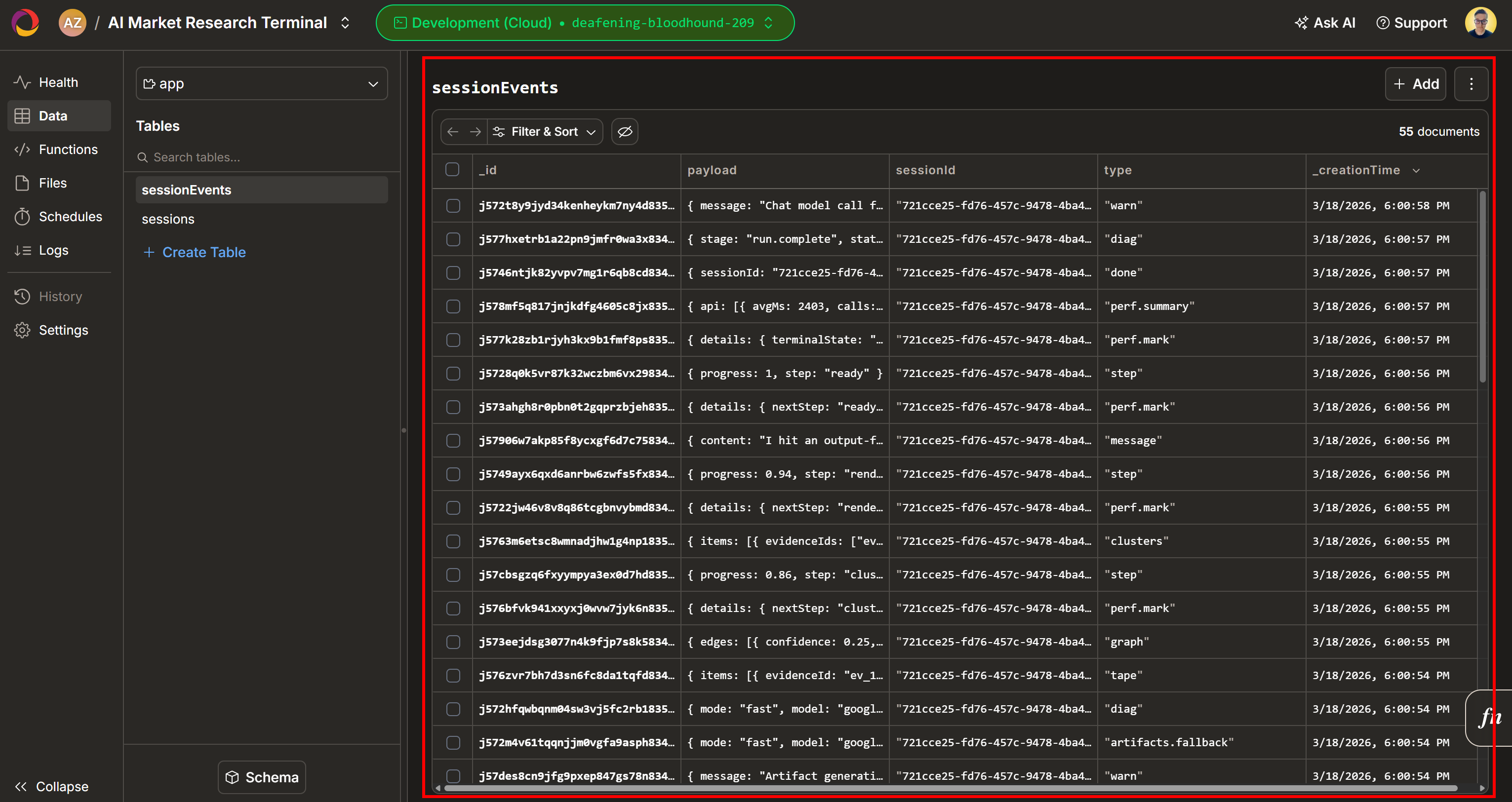
次に、「Graph」、「Mind」、「Flow」、「Timeline」の各ビューを確認してください: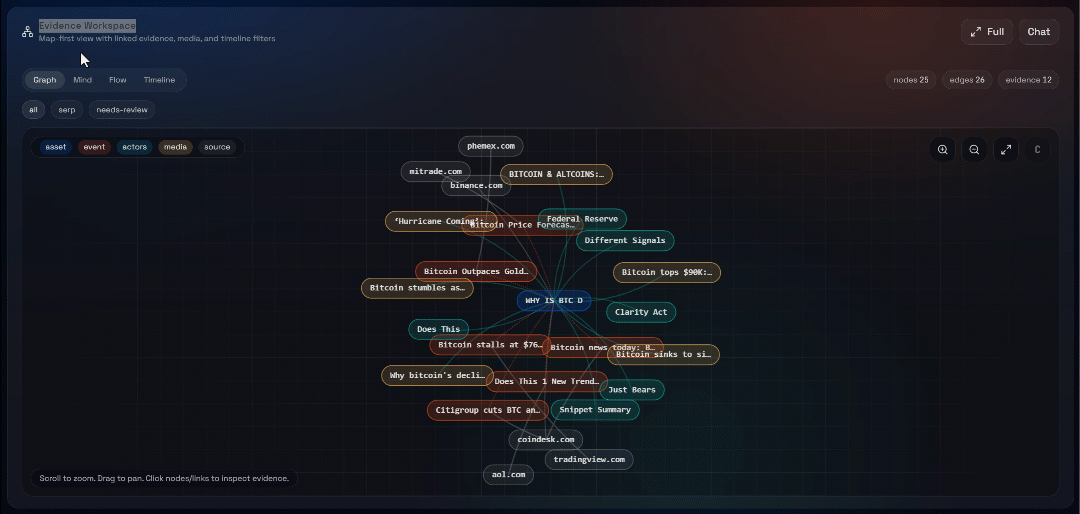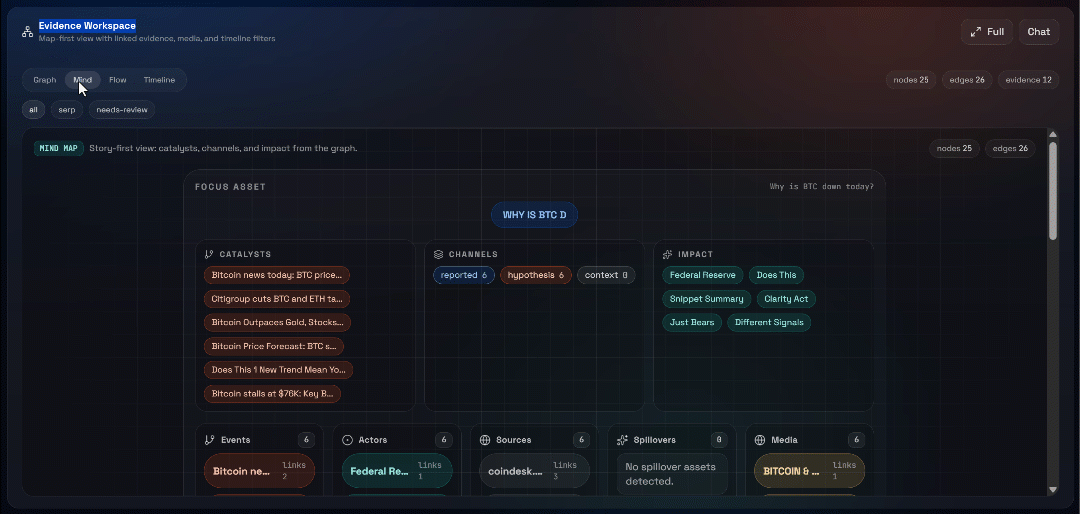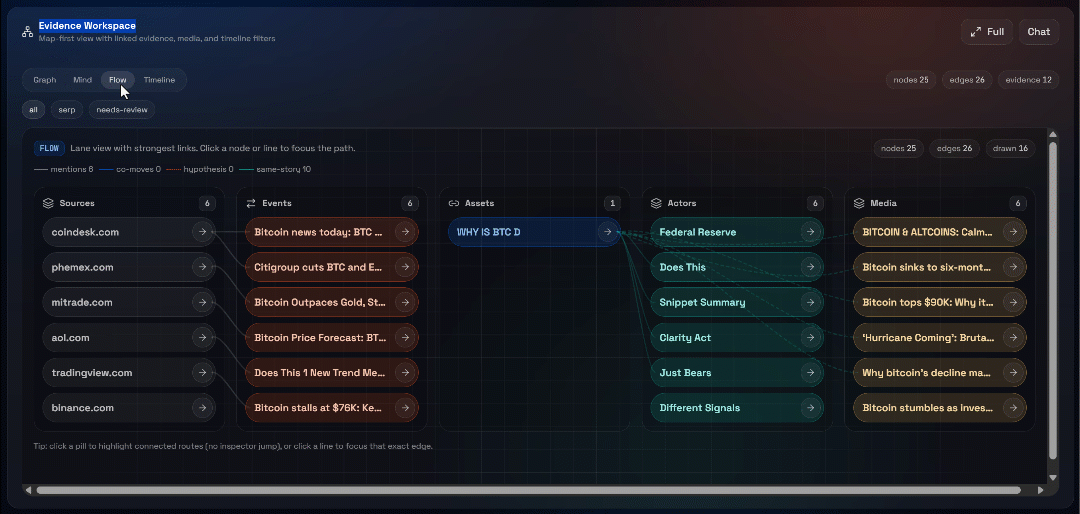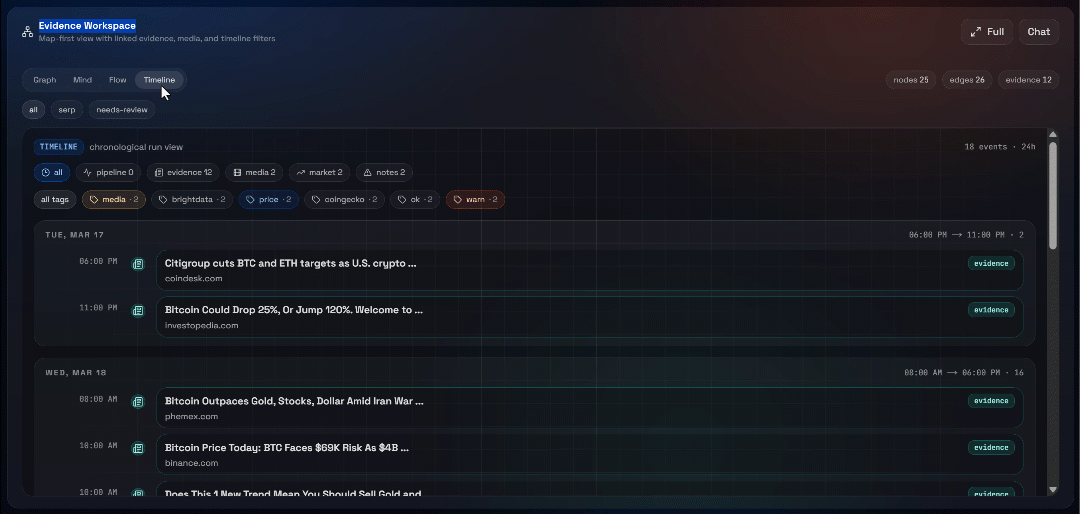
ここでは、取得されたソースを確認し、フィルタリングを行い、さらにデータを掘り下げて深い洞察を得ることができます。
これで完成です!Bright Dataを基盤とし、Convexをバックエンドデータベースとして活用した、完全に機能するAI市場調査ターミナルアプリが完成しました。これは、リアルタイムのWebデータをワークスペースに直接取り込む、ライブで反応性の高いアプリケーションです。
まとめ
この記事では、Convexとは何か、その仕組み、そしてリアクティブアプリケーションの実現にどのように役立つかについて学びました。このソリューションは、Webからライブでスクレイピングされた最新のデータを保存するために使用すると、さらに強力な機能を発揮します。
Bright Dataは、エンタープライズグレードのインフラを通じてリアルタイムのウェブスクレイピングを実現します。これは幅広いウェブスクレイピングサービスの基盤となり、ブロックされることなく、迅速かつ確実にウェブからデータを収集することを可能にします。
今すぐBright Dataに無料で登録し、当社のリアルタイムWebデータ収集ソリューションをご体験ください!