
このガイドでは以下を学びます:
- AWS Step Functionsとは何か、ワークフロー自動化においてなぜ重要なのか。
- ウェブスクレイピングワークフローがこのAWSサービスに適している理由。
- – Bright Dataがウェブスクレイピング固有の課題を克服する方法を解説
- – Bright DataをAWS Step Functionsに統合する方法(直接API呼び出しまたは専用Lambda関数経由)。
さっそく見ていきましょう!
AWS Step Functionsの概要
AWS Step Functions を使用してウェブスクレイピングワークフローをオーケストレーションする方法を示す前に、このソリューションについてさらに詳しく見ていきましょう。
AWS Step Functionsとは?
AWS Step Functionsは、AWSサービス間で複雑なワークフローを調整・自動化できるフルマネージドサービスです。複数のAWSサービスをサーバーレスワークフローに接続し、分散アプリケーションの構築やプロセスの自動化を実現するビジュアルオーケストレーションサービスです。
Step Functions の中核はステートマシンであり、これは一連のステップ(ステートと呼ばれる)で構成されるワークフローです。各ステートは、AWS サービスの呼び出しやカスタムコードの実行などのタスクを実行します。
このアプローチにより、オーケストレーション、エラー処理、監視が簡素化され、インフラストラクチャではなくアプリケーションロジックに集中できます。具体的には、以下の主な利点があります:
- オーケストレーションの簡素化:複雑なコードを書かずに、複数ステップのプロセスと依存関係を管理できます。
- 組み込みのエラー処理:リトライとキャッチブロックにより、ワークフローが自動的に障害から回復します。
- 並列かつ動的な実行:タスクを同時に実行したり、データセットを反復処理して処理を高速化。
- ヒューマン・イン・ザ・ループのサポート:ワークフロー内に承認ステップやコールバックを含める。
- サービス統合:AWS Lambda、Glue、SQS、SNS、SageMakerなどとのシームレスな連携を実現。
詳細は公式ドキュメントでご確認ください。
AWS Step Functionsの仕組みを理解する
AWS Step Functionsを真に理解するには、あらゆるワークフローの基盤となる中核概念に焦点を当てることが有効です:
- ステートマシン:Step Functionsの基盤。ステートマシンはワークフローを表現し、タスクの進行に伴い状態を保存・更新します。JSONとAmazon States Languageを使用して定義します。長時間実行や人的介入が必要なプロセスには標準ワークフローを、短時間で大量処理が必要なタスクにはExpressワークフローを選択できます。
- 状態: ワークフローの各ステップ。状態では、作業の実行(Task)、決定(Choice)、実行の一時停止(Wait)、失敗/成功の処理(Fail/Succeed)、実行の分岐(Parallel)、入力に対する反復処理(Map)が可能です。状態の組み合わせがワークフローのロジックを定義します。
- タスク状態: ワークフロー内の作業単位。サービスタスクはLambdaやGlueなどのAWSサービスとの連携を自動化します。一方、アクティビティタスクは外部コードや人間と連携し、非同期ステップや承認処理に有用です。
- 実行と監視: Step Functionsは各ステップの入力、出力、再試行、エラーをログに記録し、問題の追跡やワークフロー動作の検証を可能にします。
サーバーレスウェブスクレイピングワークフローのオーケストレーション
AWS Step Functionsは、スケーラブルかつ信頼性の高い方法でサーバーレスウェブスクレイピングワークフローをオーケストレーションする効果的な手段を提供します。モノリシックなスクレイピングスクリプトを構築する代わりに、プロセスをイベント駆動型の小さなステップに分割し、ステートマシンを通じてそれらを調整できます。
たとえば、ワークフローはデータ収集タスクのトリガーから開始し、データのパースと検証を継続し、結果を Amazon S3 やデータベースなどのサービスに保存することができます。Step Functions は、AWS Lambda、AWS Glue、Amazon SQS などの他の AWS サービスと統合しながら、これらのステップを調整することができます。
このアプローチには、スケーラビリティの向上、組み込みのリトライとエラー処理、スクレイピングタスクの並列処理、各ワークフロー実行の明確な監視など、いくつかの利点があります。
しかし、大規模なウェブスクレイピングには課題も存在します。多くのウェブサイトが、自動化されたリクエストをブロックするボット対策やスクレイピング防止メカニズム(レートリミッター、フィンガープリント、CAPTCHA、JavaScriptチャレンジなど)を実装しているためです。
AWS Step Functionsによる完璧なWebデータ取得
AWS Step Functionsでウェブスクレイピングワークフローを構築するチーム向けに、Bright Dataは大規模なウェブデータ取得を成功させる包括的なソリューションを提供します。
Bright Dataには、Step Functionsとシームレスに連携する複数の専門スクレイピングサービスが用意されています:
- SERP API: SEO分析や市場調査向けに、大規模な検索エンジン結果を収集します。
- Web Unlocker:CAPTCHA、JavaScriptの障壁、IP制限などのボット対策回避により、あらゆるウェブページにアクセス。
- ウェブスクレイピングAPI: 最小限の設定で、eコマースプラットフォーム、ソーシャルネットワーク、その他のWebソースから構造化された情報を取得します。
- Crawl API:あらゆるドメインからウェブサイト全体のコンテンツをMarkdown、プレーンテキスト、HTML、JSON形式で自動抽出。
これらのソリューションは、195カ国以上で1億5000万を超えるIPアドレスを擁するプロキシネットワークを活用し、本番環境対応ユースケース向けに無制限の同時接続を実現します。さらに、すべてのサービスにはBright Dataのアンチボットツールキットが組み込まれており、CAPTCHAやその他のアクセス制限を回避します。
Step FunctionsのオーケストレーションとBright Dataのウェブデータツールを統合することで、抽出・変換・保存を管理する完全自動化されたパイプラインを実現します。これにより、複雑で大規模なエンタープライズ対応シナリオにおいても継続的な運用が可能となります。
Bright DataウェブスクレイピングソリューションをAWS Step Functionsに統合する方法
自動化されたウェブデータ取得のためにBright DataをAWS Step Functionsに統合するには、2つのアプローチが可能です:
- 「HTTPエンドポイント – HTTPS APIを呼び出す」ノードを使用:Bright DataのAPI(Web Unlocker API、ウェブスクレイピング API、SERP API、Crawl APIなど)に直接接続します。
- 「AWS Lambda – Invoke」ノードの活用:Lambda関数内でカスタムコード(Pythonまたはその他のサポート言語)を作成し、Bright Data製品との連携、データ取得、および必要に応じて特定のロジック(例:特定のフィールドのみへのアクセス、特定の構造でのデータ返却、カスタムパースロジックの適用)を適用します。
以下のセクションでは、両方のアプローチについてご説明します。まずは、2つの方法の長所と短所を見ていきましょう。
HTTPエンドポイント – HTTPS API呼び出しノード:長所と短所
👍長所:
- 設定が迅速。
- 管理・保守が容易。
- 単一ウェブページからのデータスクレイピングに適している。
👎デメリット:
- カスタムデータ処理の柔軟性が限られている。
- 複数の異なるBright DataスクレイピングAPI呼び出しを必要とする複雑なワークフローの処理が困難。
AWS Lambda – Invoke Node: 長所と短所
👍長所:
- ウェブデータ処理と変換を完全に制御できる。
- カスタムロジック(再試行、条件分岐など)の実装が可能。
- 単一関数内で複数のBright Dataサービスを統合可能。
👎デメリット:
- Python、Node.js、またはその他のサポート言語でのコーディングが必要。
- 監視・保守が必要な追加サービスが発生します。
前提条件
以下のガイドセクションを実践するには、次のものが必要です:
- 有効なAWSアカウント(無料トライアルでも可)。
- APIキーが設定済みのBright Dataアカウント。
- RESTful HTTP呼び出しの基本知識、またはLambda統合のための基本的なPythonプログラミングスキル。
Bright Dataアカウントの設定
Bright Dataアカウントをお持ちでない場合は、まず新規作成してください。既にアカウントをお持ちの場合はログインし、指示に従ってAPIキーを設定してください。このキーはHTTPリクエストの認証に必要です(HTTPリクエストから直接Bright Dataを呼び出す場合、またはLambda関数内で呼び出す場合のいずれにも適用されます)。
Bright Data Web Unlocker APIが設定済みであることを確認してください(Lambdaチュートリアルセクションを実行する場合はSERP APIも必要です):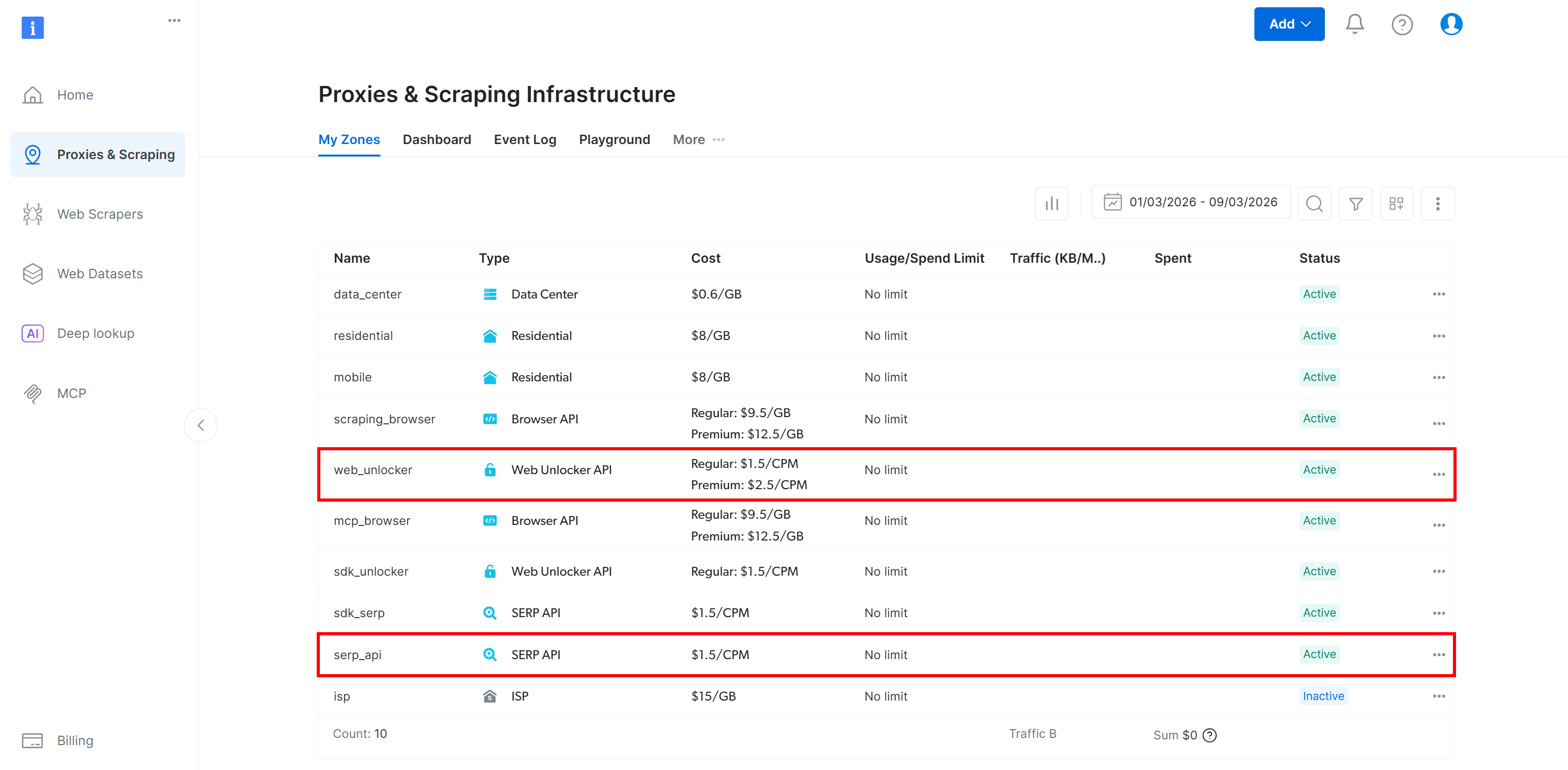
詳細は以下のドキュメントページを参照してください:
AWS Step Functionsワークフローの設定
まずAWSコンソールにログインし、「Step Functions」サービスを検索します。サービスページを開きます:
ここで「Get Started」ボタンをクリックし、「Create your own」を選択して、サーバーレスワークフローをゼロから構築します: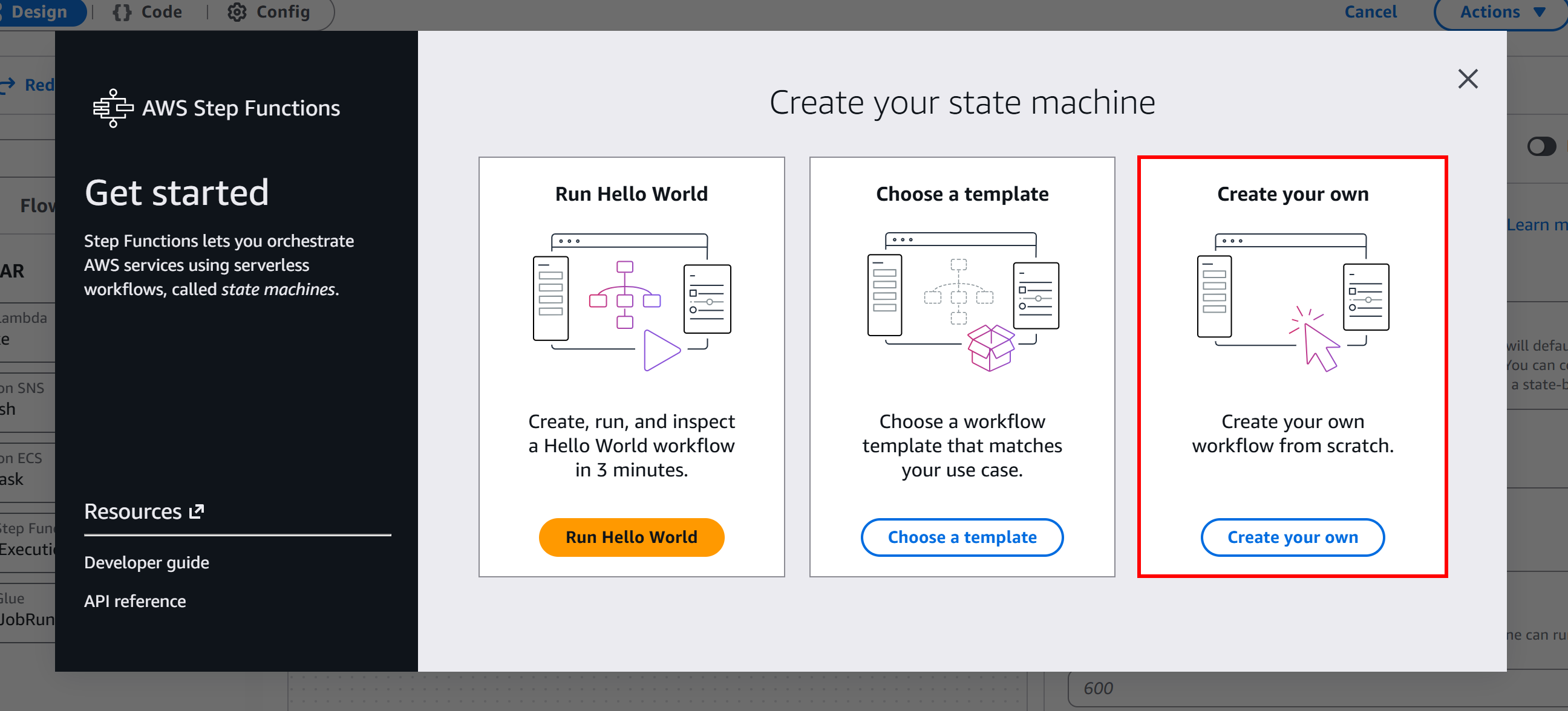
ステートマシンに名前を付け(例:"BrightDataWebScrapingMachine")、作成するステートマシンのタイプを選択します。このチュートリアルでは「標準」マシンを使用します: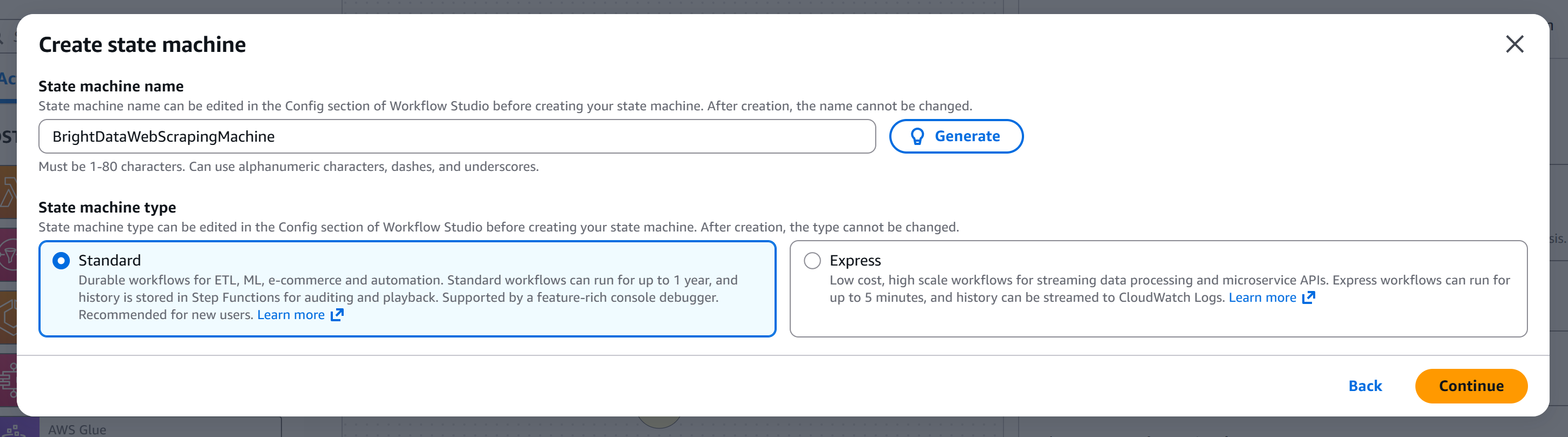
「続行」をクリックしてワークフローエディタページに移動します:
これで設定が完了し、AWS Step FunctionsワークフローにBright Dataウェブスクレイピングノードを追加する準備が整いました。
アプローチ #1: 「HTTPS API を呼び出す」ノードを使用する
ここでは、HTTP呼び出しを介してBright Data Web Unlocker APIに直接接続するノードの定義方法を学びます。このノードを使用すると、任意のウェブページからプログラムでデータをスクレイピングできます。特に、LLM取り込みに最適なMarkdown形式でデータを取得するよう設定します。
注:他のAPIベースのBright Data製品への接続にも、ほぼ同様の手順を適用できます。
ステップ #1: 「HTTPエンドポイント – HTTPS APIを呼び出す」ノードを追加
左パネルで「HTTPエンドポイント – HTTPS APIを呼び出す」ノードを選択し、「最初の状態をここにドラッグ」セクションへドラッグします: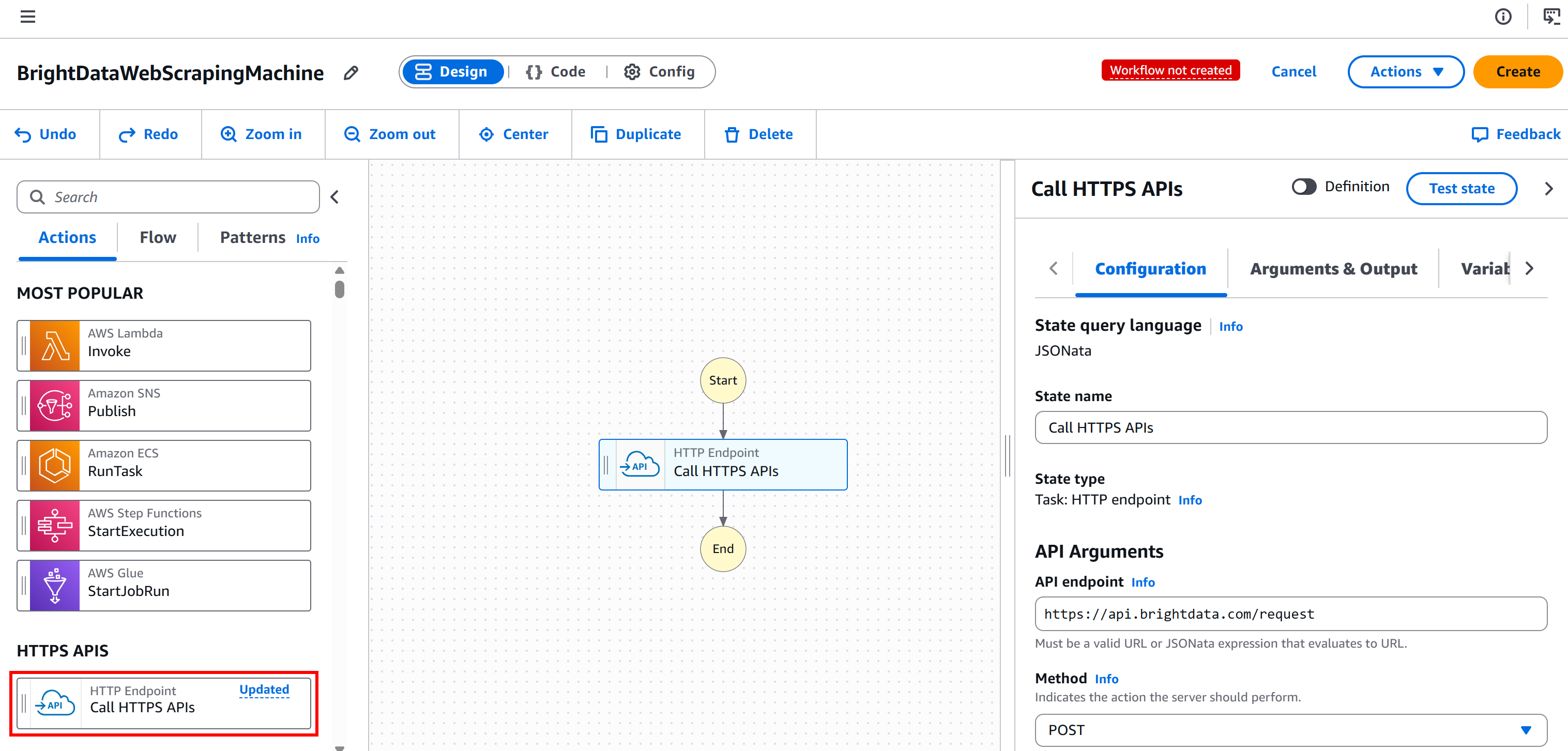
ノードを選択し、右側の「設定」タブで:
- ステートに名前を付けます。
- 「APIエンドポイント」を
https://api.brightdata.com/requestに設定します。 - 「メソッド」を
POSTに設定します。
これにより、Web UnlockerおよびSERP APIサービスの基盤となるBright Data APIであるPOST https://api.brightdata.com/requestエンドポイントへの接続が設定されます: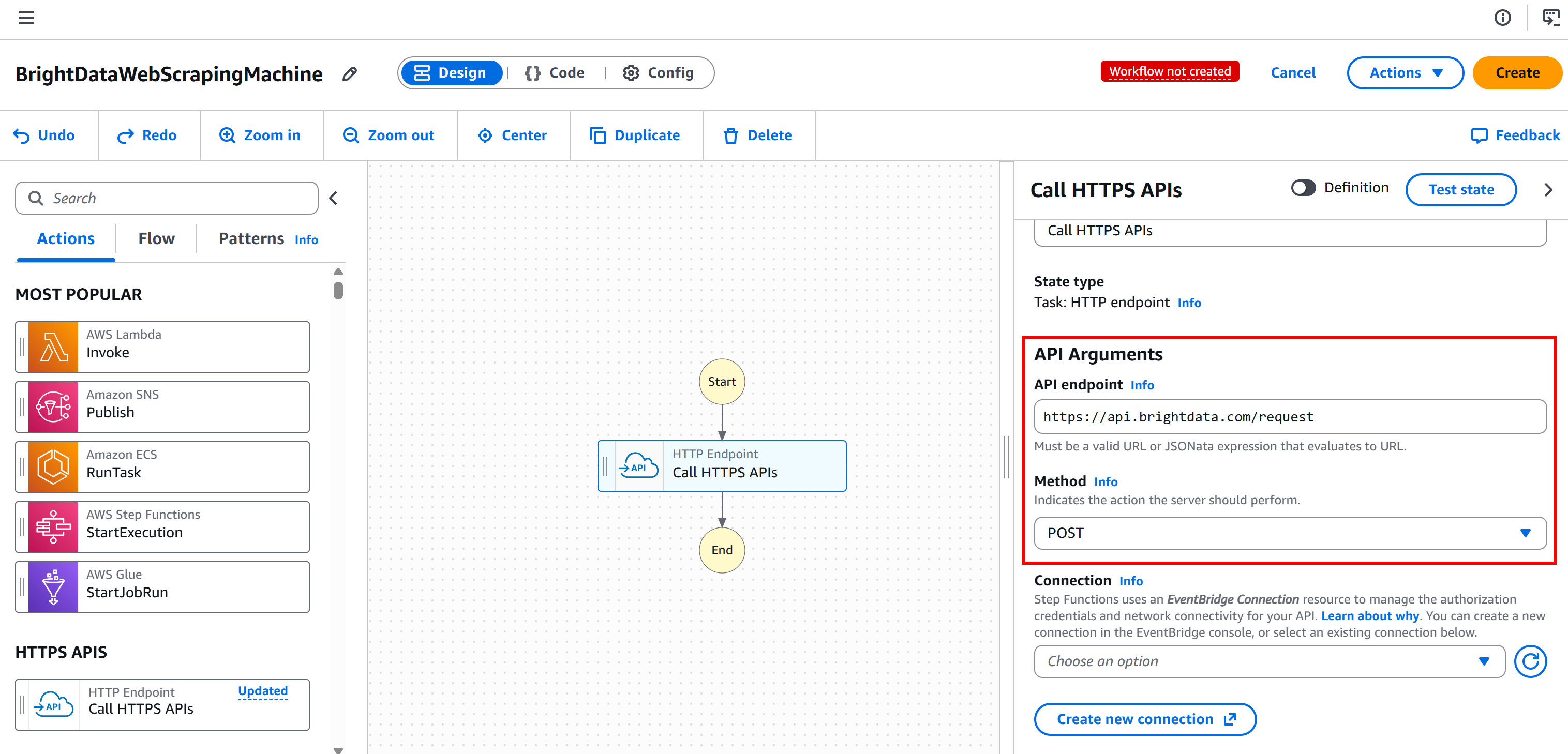
ステップ #2: API認証の設定
Bright Data API は、Bright Data API キーを使用して認証されます。具体的には、以下の形式でAuthorizationヘッダーに含める必要があります:
Bearer <BRIGHT_DATA_API_KEY>APIキーをノードにハードコードしないため、Amazon EventBridge経由で新規接続を作成する必要があります。これを行うには、「設定」タブ下の「接続」セクションにある「新規接続を作成」ボタンを押します:
接続に名前を付け(例:brightdata-api)、「公開」に設定します(Bright Data APIキーは公開されているため)。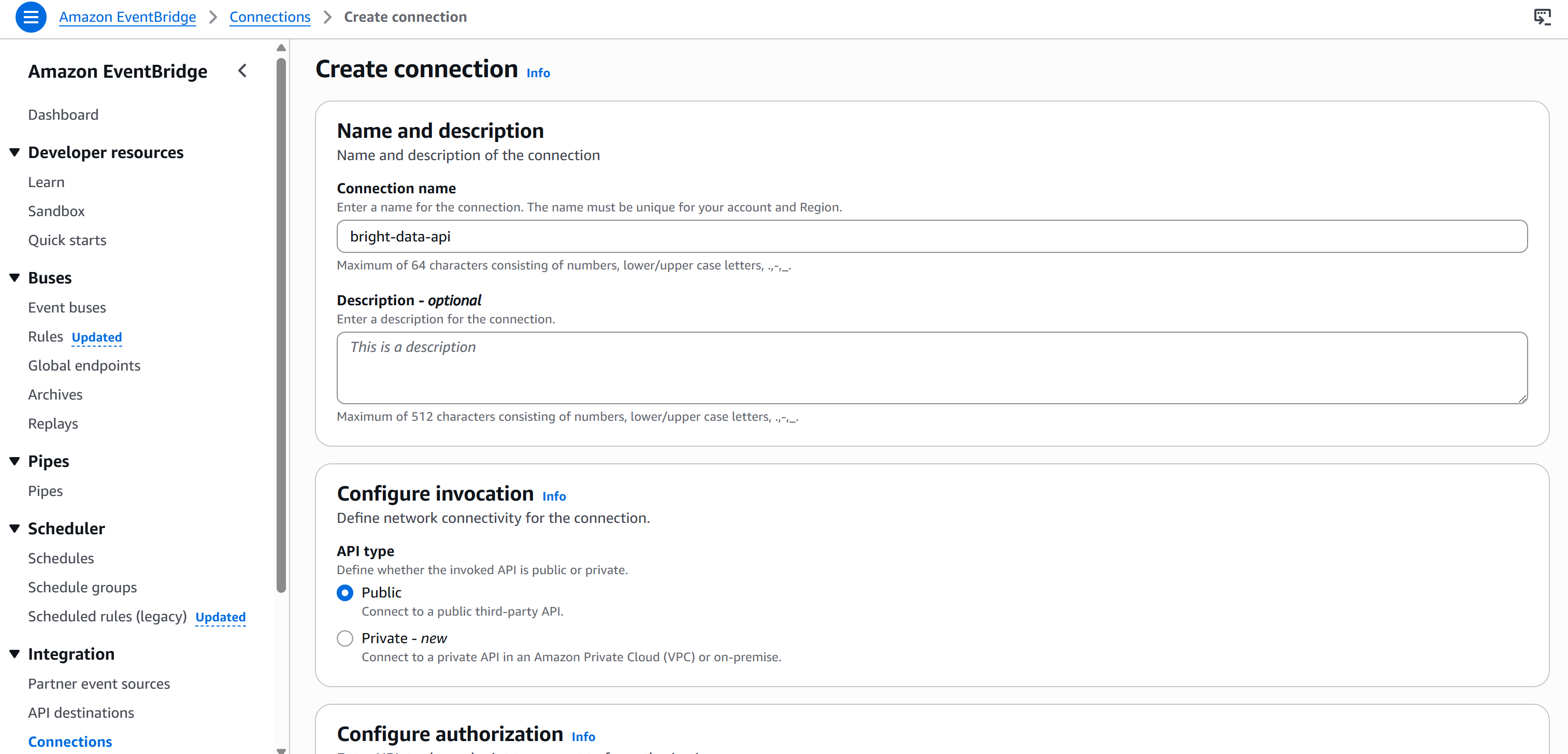
次に、「APIキー」認証タイプを選択し、以下のように設定します:
- APIキー名:
Authorization(認証に使用するHTTPヘッダー名と一致させる必要があります)。 - 値:
Bearer <BRIGHT_DATA_API_KEY>(<BRIGHT_DATA_API_KEY>プレースホルダーを実際のAPIキーで置き換えてください)。
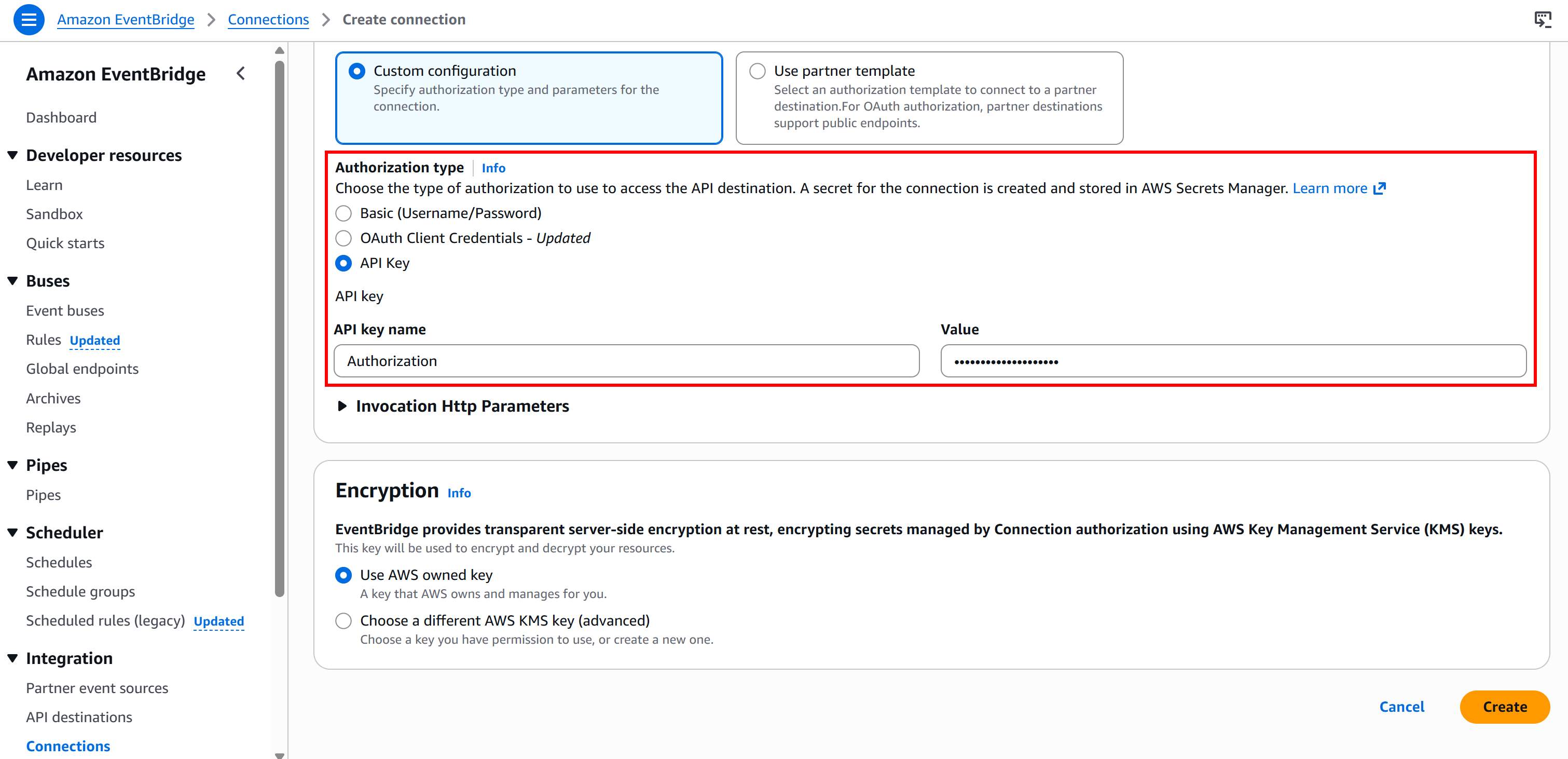
最後に「作成」を押してEventBridge接続を設定します。作成後、以下が表示されます: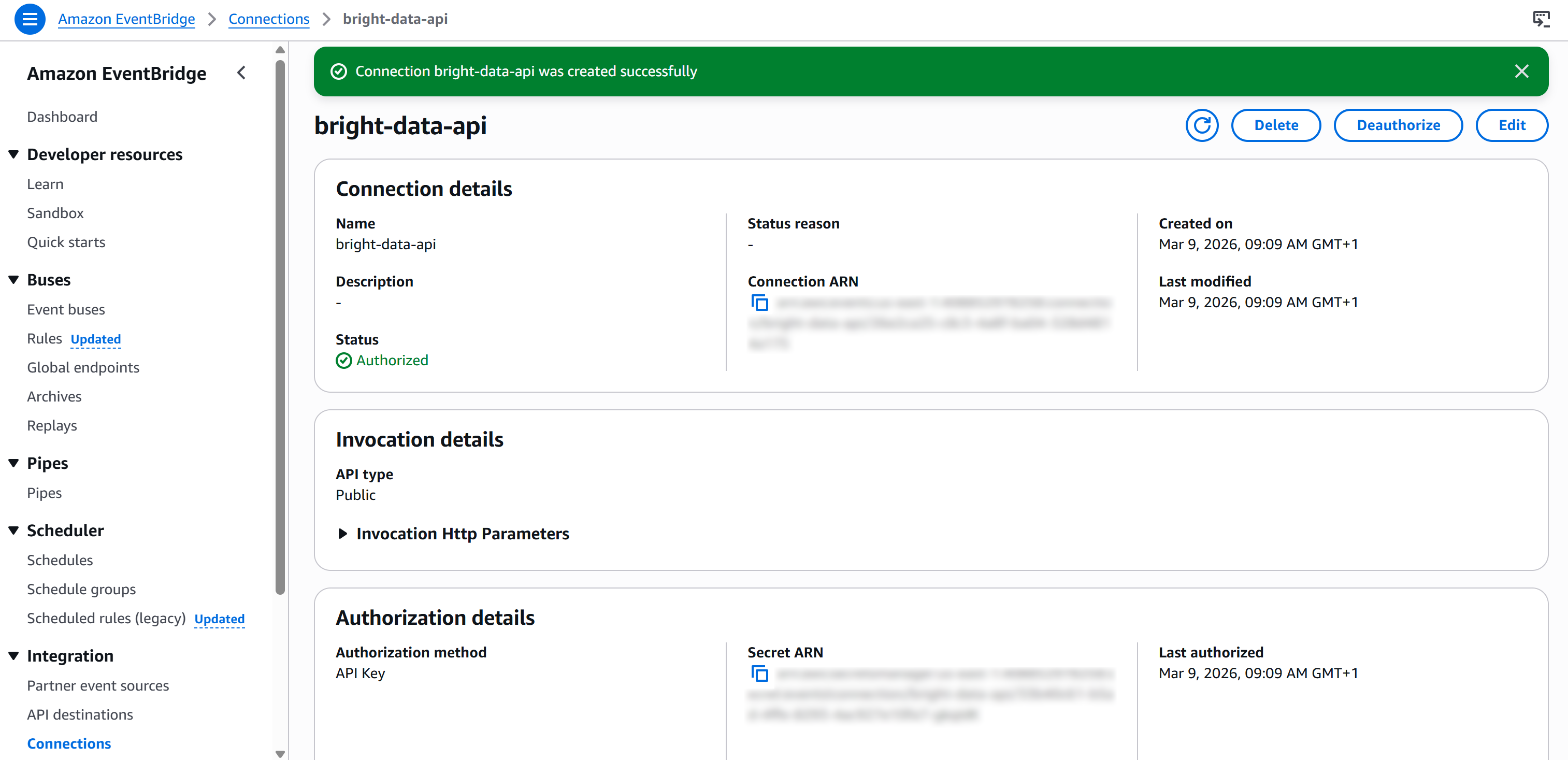
ステップ #3: API設定を完了する
ワークフローエディタページに戻り、「HTTPエンドポイント – HTTPS APIを呼び出す」ノードを選択し、「設定」タブに移動します。次に、先ほど作成した接続(bright-data-api)を選択します: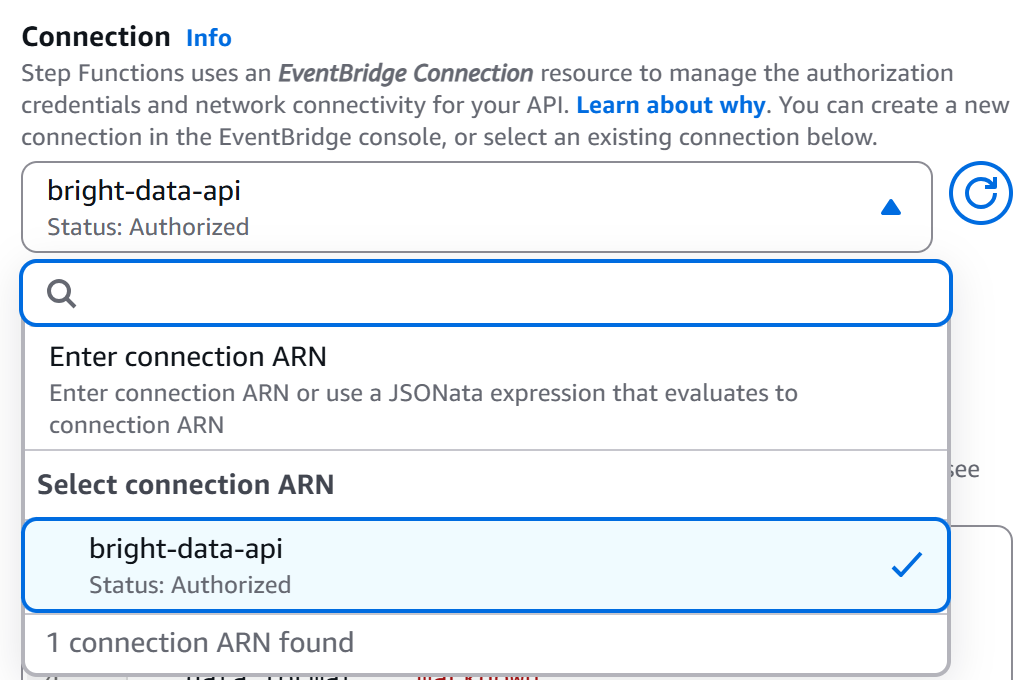
これにより、認証用のAuthorizationヘッダーにBright Data APIキーが(必要な形式で)追加されます。
次に、HTTPボディを以下のように定義します:
{
"ゾーン": "<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ゾーン_名>",
"url": "{% $states.input.url %}",
"format": "raw",
"data_format": "markdown"
}<YOUR_BRIGHT_DATA_WEB_UNLOCKER_ZONE_NAME>プレースホルダーを、Bright Data アカウントの Web Unlocker ゾーン名に置き換えてください。urlフィールドはワークフロー入力から動的に読み取られます({% $states.input.url %}構文による)。これによりURLをハードコーディングせずに異なるページをスクレイピング可能です。代わりにdata_format: "markdown"を指定することで、APIレスポンスがAI対応のMarkdown形式で返されることが保証されます。
この例では、Web Unlockerゾーンの名前は「``web_unlocker``」であるため、本文は次のようになります: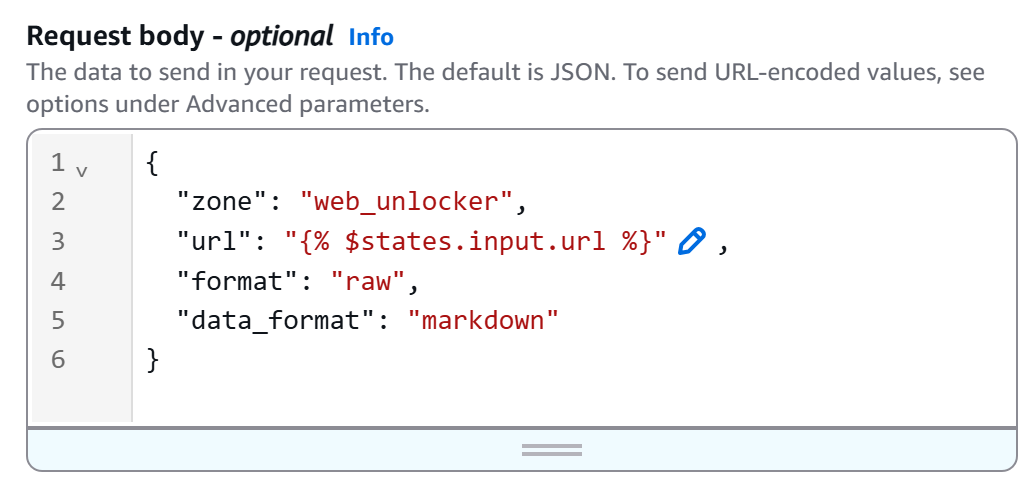
これでワークフローは次のようになります: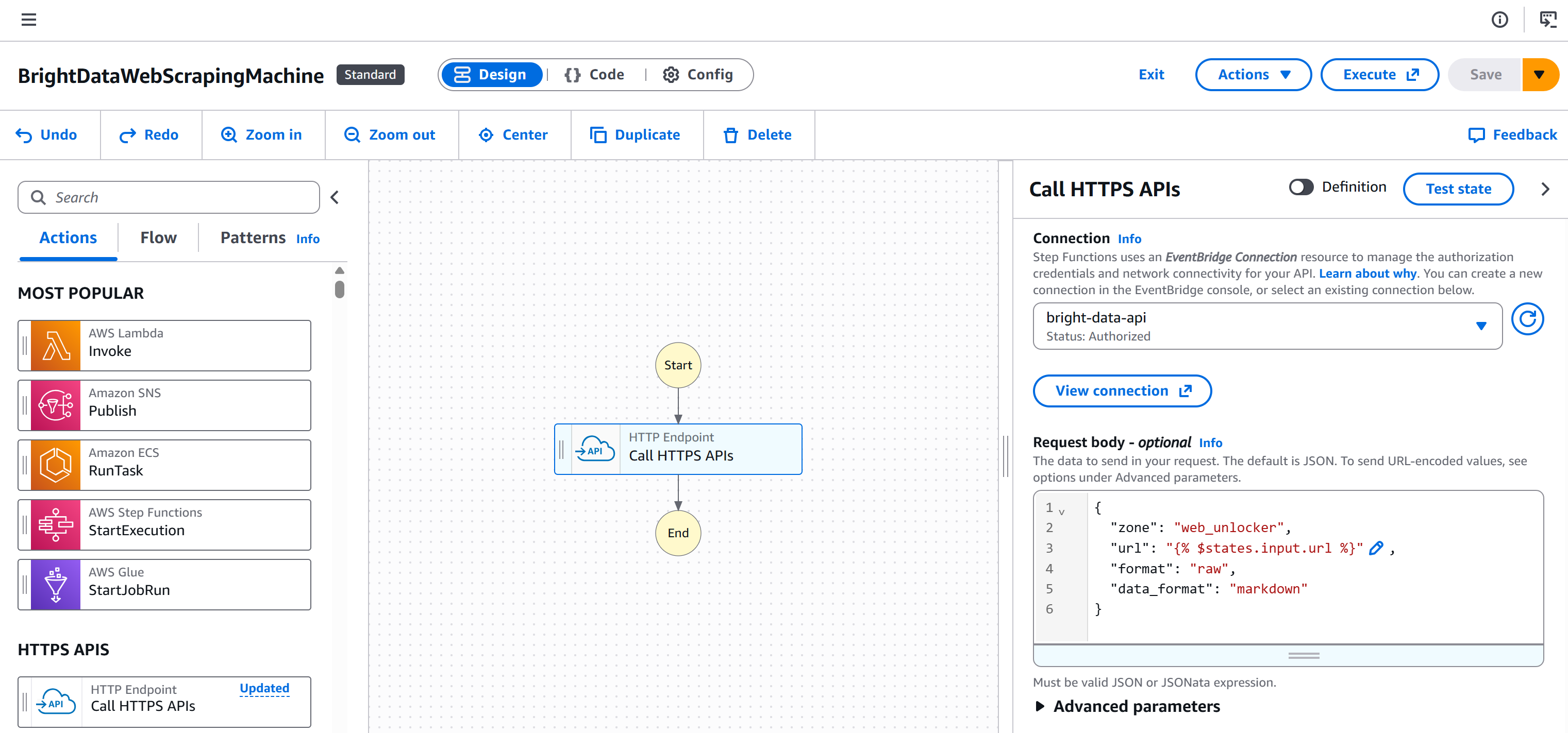
素晴らしい!設定は完了です。あとはAWS Step Functionsワークフロー内でBright Data統合をテストするだけです。
ステップ #4: Bright Data 搭載 ウェブスクレイピングノードのテスト
まず「作成」ボタンを押して、テストに必要なIAMロールとその他の要素をAWSコンソールで生成します:
次に、ノード上の「状態をテスト」ボタンを押します: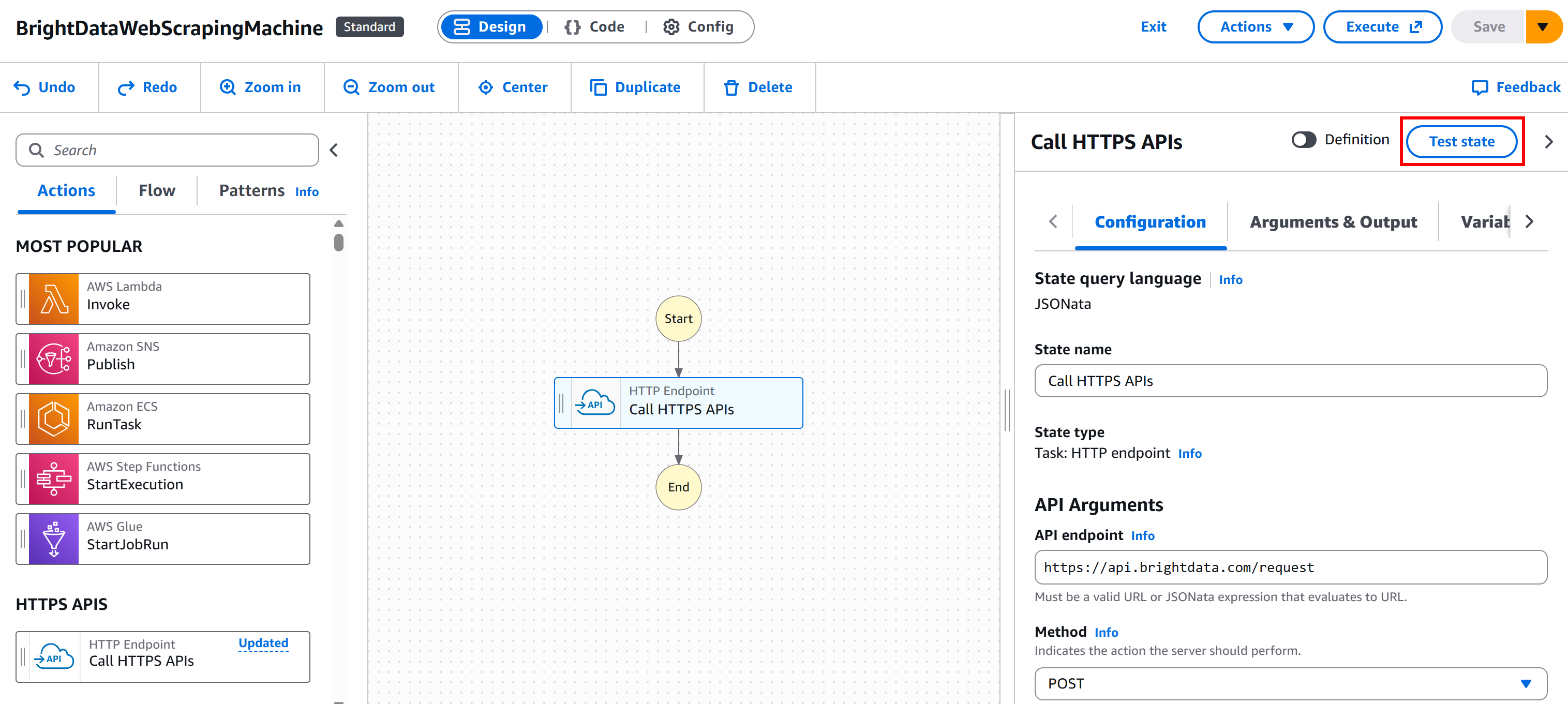
「状態テスト」モーダルが表示されます: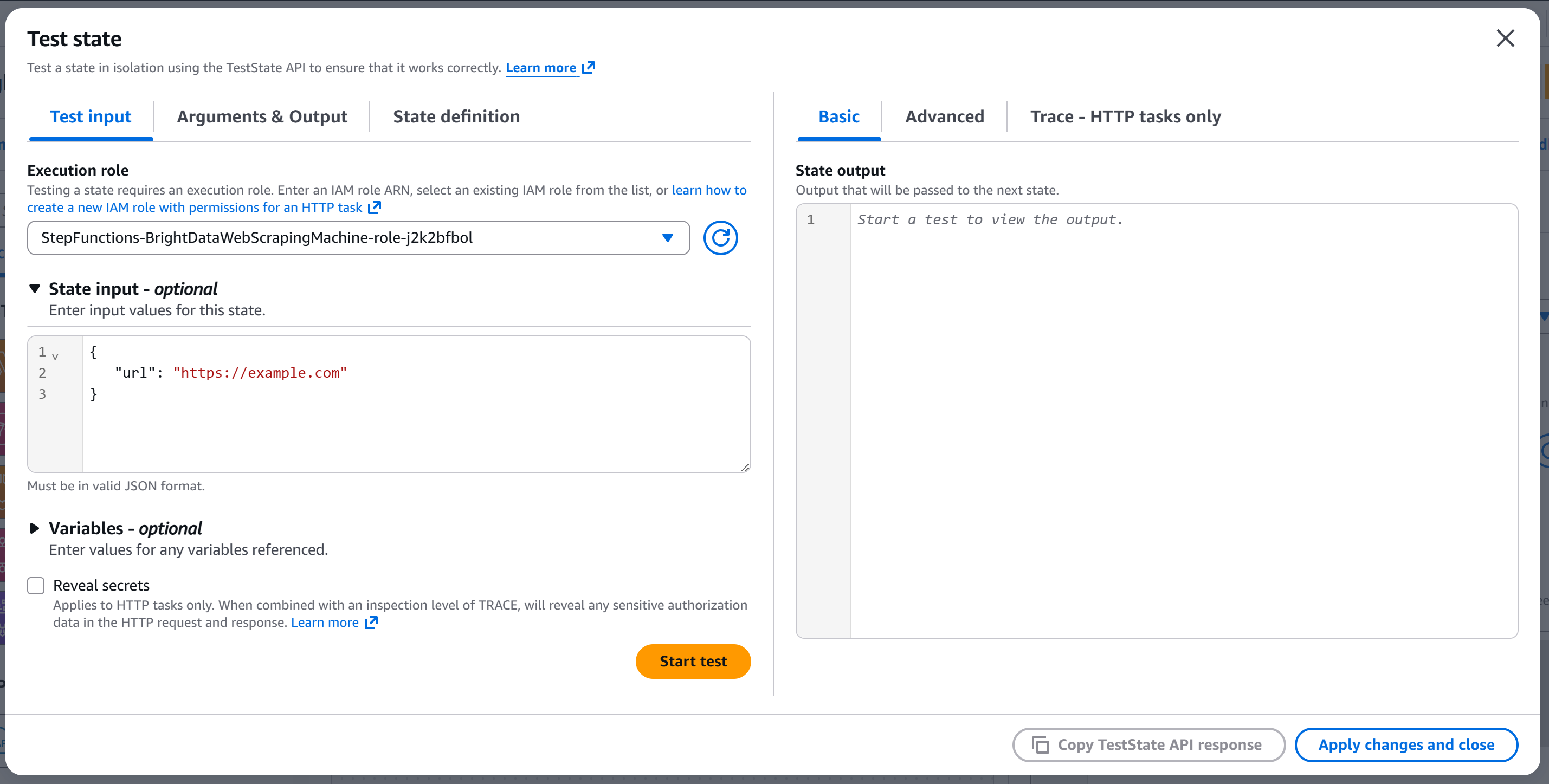
状態入力に以下のような設定を入力します:
{
"url": "https://example.com"
}urlフィールドはAPIボディに渡されます(ノードが入力からurlボディフィールドを読み取るよう設定されているため)。
「テスト開始」を押してノードを実行します。以下のような出力が表示されるはずです: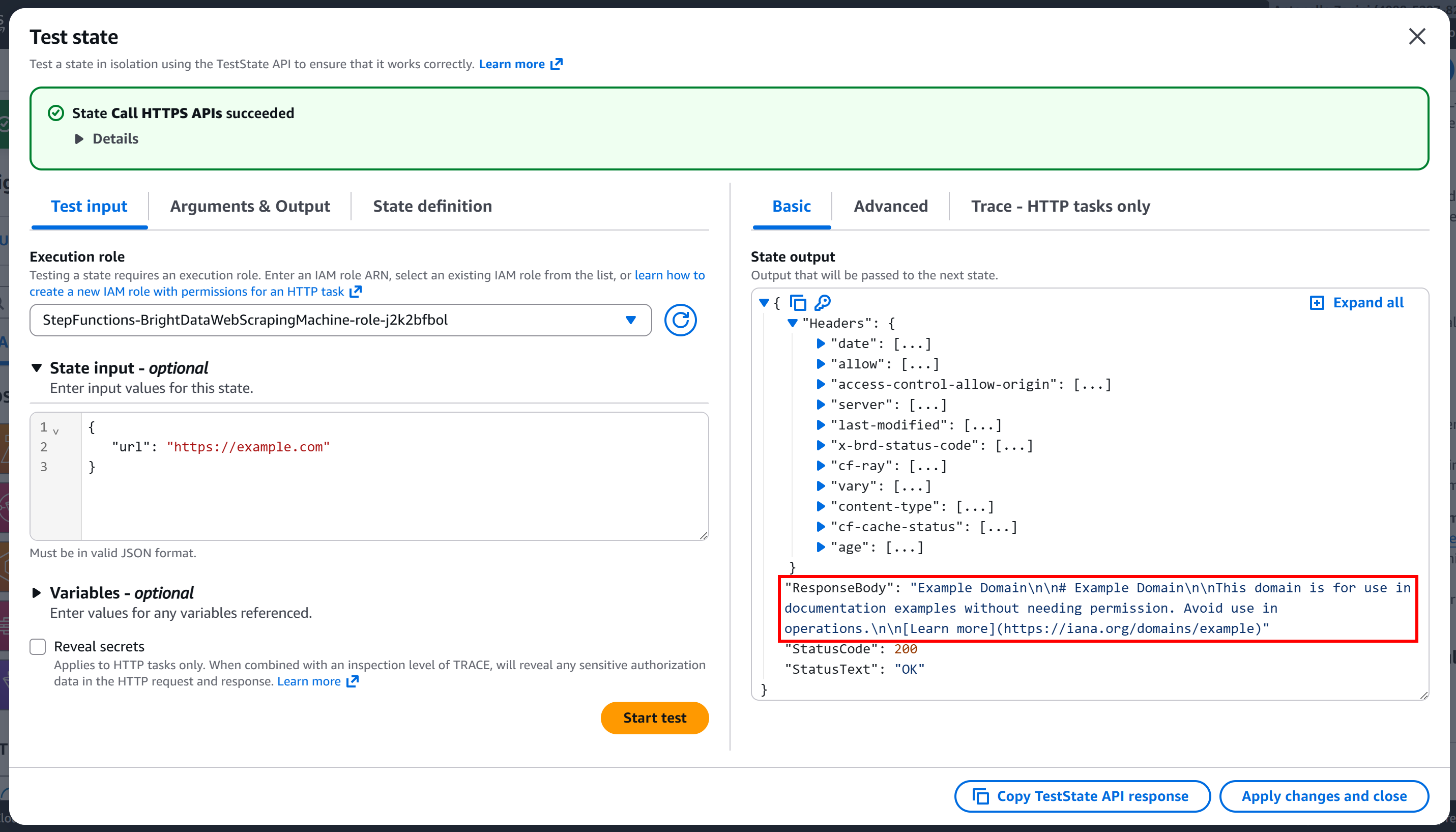
ご覧の通り、リクエストは成功し、レスポンスボディには対象ページのMarkdownバージョンが含まれています: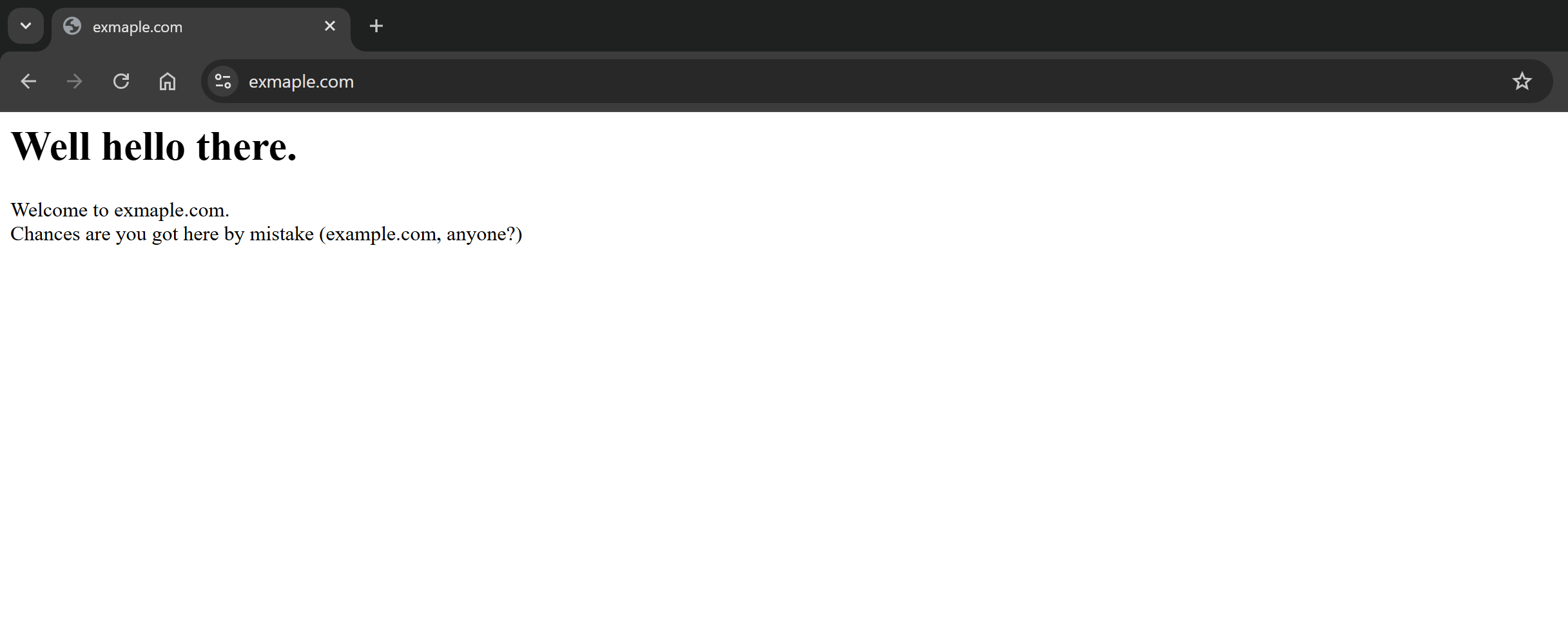
これで完了です! AWS Step Functions における Bright Data 統合が完全に機能し、本番環境での使用準備が整いました。
アプローチ #2: Lambda関数の使用
このセクションでは、カスタム AWS Lambda 関数経由で Bright Data サービスに接続する方法を理解します。
統合を簡素化しプロセスを迅速化するため、「AWS BedrockエージェントにBright Data SERP API経由のウェブ検索機能を提供する」記事のステップ#5、#6、#7に従うことができます。これらのステップでは、Bright Data SERP APIに接続するPythonのLambda関数を作成する手順を説明しています。
以下では、AWS Step Functionsを介してそのLambda関数をウェブスクレイピングワークフローに統合する方法を説明します!
ステップ #1: 「AWS Lambda – Invoke」ノードを追加
左パネルから「AWS Lambda – Invoke」ノードを選択します。次に、ワークフロー内の「最初の状態をここにドラッグ」セクションにドラッグします。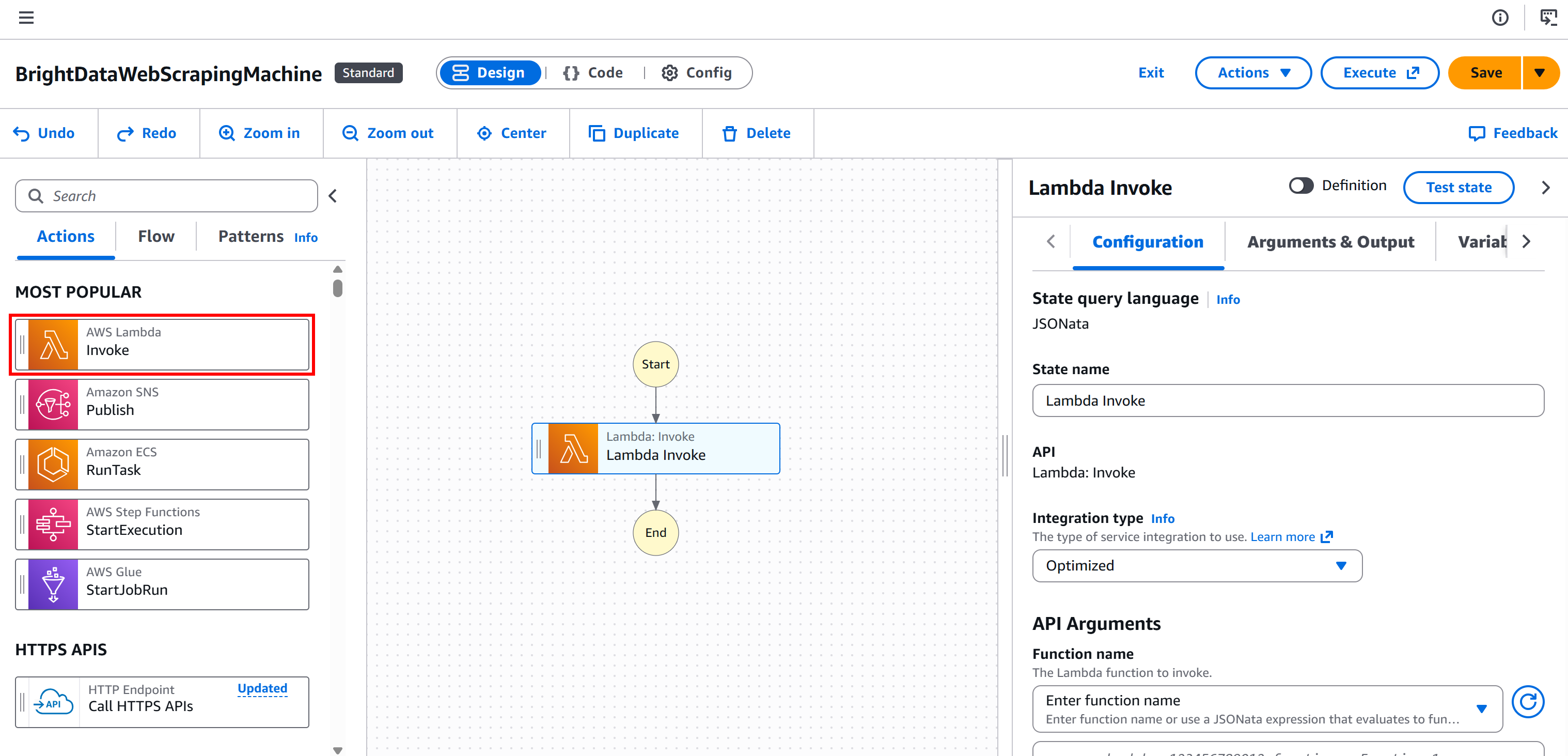
ステップ #2: Lambda関数の設定
「AWS Lambda – Invoke」ノードの「設定」セクションにある「API引数 – 関数名」ブロックで、呼び出すLambda関数を選択します: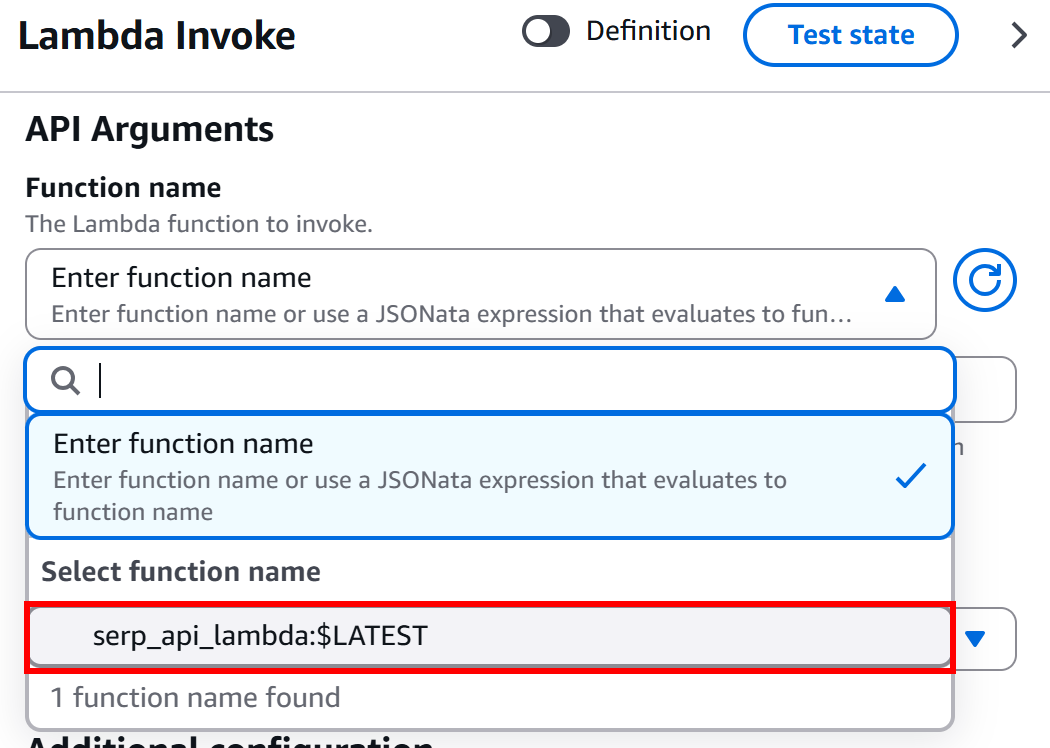
この例では、章の冒頭で説明した手順で作成した関数「serp_api_lambda」を使用します。この関数はBright DataのSERP APIと連携します。
素晴らしい!これで、Bright Dataを利用したSERPスクレイピング用Lambda関数がAWS Step Functionsワークフローに統合されました。
まとめ
このガイドでは、AWS Step Functions の概要と、自動化されたウェブスクレイピングワークフローのオーケストレーションに最適な理由について学びました。
Step Functionsがステートマシン、並列実行、再試行、人間による介入サポートを通じてワークフロー管理を簡素化する方法を確認しました。BrightDataがWeb Unlocker とSERP APIの統合を通じてこのプロセスを強化し、アンチボット対策を回避して、中断のないエンタープライズレベルのウェブデータ取得を保証する方法を探りました。
Bright DataをStep Functionsに統合することで、S3やその他のAWSサービスにおけるデータ収集、検証、保存を処理するエンドツーエンドのパイプラインを構築でき、スケーラビリティ、耐障害性、監視機能を維持できます。
今すぐBright Dataアカウントに登録し、当社のウェブデータソリューションを無料で試してみてください!




