
この記事では、以下のことを学びます:
- Apache AirflowとApache Sparkとは何か、そしてそれらが提供する機能について。
- Bright DataのWeb Unlocker APIをAirflowおよびSparkでオーケストレーションすることが、リードジェネレーションにおいて強力な戦略となる理由。
- 構造化されたビジネスデータを大規模に収集、処理、保存するエンドツーエンドのパイプラインを構築する方法。
具体的なツールや実装について掘り下げる前に、基礎となる概念を整理し、それらがリードジェネレーションのワークフロー内でどのように連携するかを確認しましょう。
Apache Airflowとは?
Apache Airflowは、データパイプラインをプログラムで作成、スケジュール設定、監視するためのオープンソースのワークフローオーケストレーションプラットフォームです。もともとAirbnbで開発されたもので、データエンジニアがプレーンなPythonを使用してワークフローを有向非循環グラフ(DAG)として定義できるようにし、タスクの依存関係、再試行、スケジューリング、アラート設定を完全に制御できます。
その主な目的は、複雑で多段階にわたるデータパイプラインを確実に実行できるようにすることです。これは、豊富なオペレーターエコシステム(Bash、Python、HTTP、Spark、SQLなどに対応)、実行状況を監視するための視覚的なWeb UI、組み込みのリトライおよびアラートロジック、そしてAWS、GCP、Azureなどのクラウドプラットフォームとのネイティブ統合を提供することで実現されています。
ワークフローのオーケストレーションについて理解したところで、パイプラインのデータ処理側を見ていきましょう。
Apache Sparkは、大規模データ処理のための統合型分析エンジンです。これは、マシンクラスタ全体で膨大なデータセットをメモリ上で処理できる分散コンピューティングフレームワークを提供し、従来のディスクベースの処理システムよりも劇的に高速です。
Sparkは、Python(PySpark)、Scala、Java、Rで利用可能な統一APIを通じて、バッチ処理、ストリーミング、SQLクエリ、機械学習、グラフ計算をサポートしています。大量のスクレイピングされたビジネスデータのクリーニング、重複排除、エンリッチメント、変換といったデータ集約型のワークロードにおいて、Sparkは業界標準のツールです。
Apache Airflow 対 Apache Spark:その違いとは?
このスタックに不慣れな方にとっては、両者が頻繁に組み合わせて使われるため、混同しがちです。しかし、その目的は大きく異なります:
- Apache Airflowはオーケストレーターです。タスクの実行タイミング、順序、障害の処理方法、およびパイプライン全体の監視方法を決定します。それ自体はデータを処理しません。
- Apache Sparkはデータ処理ツールです。生データや半構造化データを受け取り、多数のコアやマシンに分散した計算を用いて、大規模なデータ変換を行います。
両者は互いに補完し合っています。AirflowはSparkジョブを適切なタイミングと順序でスケジューリングおよびトリガーし、Sparkはデータ変換という重労働を処理します。このチュートリアルでは、Airflowがパイプライン全体をエンドツーエンドでどのようにオーケストレーションするかを確認します。具体的には、Bright Dataをトリガーしてビジネスリストを収集し、生の結果をSparkに渡してクリーニングとエンリッチメントを行い、最終的なリードをデータベースに書き込むプロセスです。
なぜBright DataをAirflow + Sparkパイプラインに統合するのか?
Airflowは、パイプラインタスクとして任意のREST APIを呼び出せるSimpleHttpOperatorと PythonOperatorを提供しています。これにより、データ変換やロードジョブと同様に、Webデータ収集をDAG内の第一級のステップとしてトリガーできます。
しかし、信頼性の高い構造化されたビジネスデータを大規模にパイプラインに取り込むには、カスタムスクレイパーのメンテナンスを必要とせず、ボット対策、地域ターゲティング、構造化された出力を処理できるソースが必要です。そこで、Bright DataのWeb Unlocker APIが役立ちます。
Web Unlocker API を使用すれば、ボット対策、JavaScript レンダリング要件、地理的制限に関係なく、あらゆる公開 Web ページにアクセスできます。ターゲット URL を指定した POST リクエストを送信するだけで、Bright Data がページコンテンツを返します。ブラウザの自動化コードも、プロキシ管理も、CAPTCHA 処理も不要です。
このアプローチは、特に次のような場合に役立ちます:
- ディレクトリから定期的に最新の企業情報を収集し、CRMやアウトリーチツールに連携させるリードジェネレーションパイプライン。
- 競合分析のために、地域や業界を横断してビジネスデータを集約する市場調査ワークフロー。
- 既存のリードデータベースに連絡先情報、企業規模、または業種分類を追加するデータエンリッチメントシステム。
- 企業情報の変更を監視し、ターゲット企業がプロフィールを更新した際にアラートを発信するセールスインテリジェンスプラットフォーム。
Airflowのスケジューリングおよびオーケストレーション機能と、Sparkの分散データ処理、そしてBright DataのWebデータインフラストラクチャを組み合わせることで、自動運転で稼働する本番環境レベルのリードジェネレーションエンジンを構築できます。
Airflow、Spark、Bright Data を使用したリードジェネレーションパイプラインの構築方法
このガイドセクションでは、以下の3つの主要な段階で構成されるエンドツーエンドのパイプラインを構築します:
- 企業リストの取得:AirflowタスクがBright DataのWeb Unlocker APIを呼び出し、3つの都市にわたるイエローページの検索結果を取得します。
- 収集データの検証:2つ目のタスクが保存された結果を読み込み、データが正常に収集されたことを確認します。
- Sparkによる処理:PySparkジョブが、生のレコードをクリーニング、重複排除、スコアリングします。
注:これは数あるアーキテクチャの1つに過ぎません。Sparkの出力をBigQueryやSnowflakeなどのデータウェアハウスに書き込んだり、API経由でCRMに直接プッシュしたり、自動リードスコアリングのためのLLMベースのエンリッチメントステップに投入したりすることも可能です。
以下の手順に従って、Apache AirflowとSpark内でBright DataのWeb Unlocker APIを活用した自動リード生成パイプラインを構築しましょう!
前提条件
この手順を実行するには、以下が必要です:
- 有効なWeb Unlockerゾーンを持つBright Dataアカウント。Bright Dataダッシュボードにログインし、「アカウント設定」に移動して、APIトークンをコピーしてください。これはUUID形式になっています。また、ゾーン名も確認しておいてください。
- Docker Desktop(macOSまたはWindows)またはネイティブのPython環境(Ubuntu/Linux)。両方のオプションについてはステップ1を参照してください。
ステップ1:プロジェクトの設定
Docker Desktopをインストールし、続行する前に正常に動作していることを確認してください。Docker Desktopの設定で「リソース」に移動し、メモリを少なくとも5 GB割り当ててください。Airflowのマルチコンテナスタックにはこれが必要です。
ステップ2: プロジェクト構造の作成
作業ディレクトリと、Airflowに必要なフォルダを作成します:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins configプロジェクト構造は次のようになります:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yamlステップ 3: Docker Compose の設定
Airflowの公式Docker Composeファイルをダウンロードします:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'同じディレクトリにDockerfileを作成します。これは、ベースとなる Airflow イメージを拡張してrequestsライブラリを追加するものです:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkdocker-compose.yaml を開きます。上部付近にあるx-airflow-commonブロックを見つけ、image:行の直下にbuild: . を追加します:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .また、_PIP_ADDITIONAL_REQUIREMENTS行が空であることを確認してください。依存関係は、この環境変数ではなく Dockerfile に記述するのが正しい方法です:
_PIP_ADDITIONAL_REQUIREMENTS: ""最後に、同じブロックの `volumes:`リストに`spark_jobs/`のボリュームマウントを追加してください。デフォルトのファイルでは`dags/`、`logs/`、`plugins/`、および`config/` のみがマウントされるため、この追加を行わないとワーカーコンテナは Spark ジョブファイルを見つけられません:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobsファイルの残りの部分は、ダウンロードしたままの状態で保持してください。デフォルトでは、メッセージブローカーとして Redis、メタデータデータベースとして PostgreSQL を使用した CeleryExecutor が提供され、プロジェクトフォルダからdags/、logs/、config/、およびplugins/フォルダがボリュームとしてマウントされます。また、デフォルトの認証情報(ユーザー名:airflow、パスワード:airflow)と、初回起動時に一度実行され、データベースの移行と管理者ユーザーの作成を行うairflow-initサービスも含まれています。
カスタムイメージをビルドし、すべてのサービスを起動します:
docker compose build
docker compose up -d約60秒待ってから、6つのコンテナすべてが正常に動作していることを確認します:
docker compose ps期待される出力:

ブラウザでhttp://localhost:8080を開き、ユーザー名「airflow」、パスワード「airflow」でログインします。
ステップ4: Airflow DAGの作成
dags/lead_generation_dag.py ファイルを作成します:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "your-brightdata-api-token-here"
ZONE = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"取得中: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"ゾーン": ZONE,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"{url} から {len(response.text)} 文字を取得しました")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"{len(results)} ページを {RAW_DATA_PATH} に保存しました")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"検証に合格しました: {count} ページを収集")
for item in data:
print(f" URL: {item['url']} | ステータス: {item['status']} | サイズ: {len(item['content'])} 文字")
with DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Bright Data Web Unlocker を使用してビジネスリードを収集",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_datayour-brightdata-api-token-here を実際の API トークンに置き換え、ZONE をWeb Unlocker のゾーン名に合わせて更新してください。
各部分の役割を詳しく見ていきましょう:
API_KEYとZONE: Bright Data の認証情報です。API トークンは、アカウント設定にある UUID 形式のトークンであり、ゾーンのパスワードではありません。TARGETS: サンフランシスコのソフトウェア企業、ニューヨークのマーケティング代理店、オースティンのフィンテックスタートアップを対象とした、3つのイエローページ検索URLです。fetch_business_listings: 各ターゲットURLを順に処理し、Web Unlocker APIへPOSTリクエストを送信します。Bright Dataがボット対策、プロキシローテーション、JavaScriptのレンダリングを処理し、ページコンテンツをMarkdown形式で返します。結果はディスクに保存され、レコード数は次のタスクが読み取れるようAirflowのXComストアにプッシュされます。validate_output: 保存されたファイルを読み込み、各URL、HTTPステータス、コンテンツサイズをログに記録します。これは、下流の処理に先立って行われる軽量なデータ品質チェックとして機能します。fetch_listings >> validate_data:>>演算子はタスクの依存関係を定義します。検証はフェッチが成功した後にのみ実行されます。
重要:定期スケジュールを持つDAGを初めてデプロイする際は、必ず
start_date を今日の日付に設定し、catchup=False に設定してください。start_date を過去の日付に設定し、catchup=True に設定すると、Airflowはその日付以降にスキップされたすべての期間についてバックフィル実行をキューに入れます。10週間前に開始した週次スケジュールの場合、DAGの停止を解除した瞬間に、ワーカースロットを奪い合う10の同時実行が発生することになります。
ステップ 5: PySpark 変換ジョブの作成
spark_jobs/process_leads.py ファイルを作成します:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
)
.filter(col("company_name").isNotNull())
.filter(col("phone").isNotNull())
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"{enriched_df.count()}件のリードを処理しました。出力は{output_path}に書き込まれました")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])このジョブは4つの処理を行います。まず、fetch_listingsによって生成された生のJSONデータをディスクから読み込みます。次に、空白の正規化、数値フィールドの型変換、および名前や電話番号が欠落しているレコードの削除を行い、データをクレンジングします。さらに、会社名と電話番号に基づいてレコードの重複排除を行い、都市間で重複するリストを削除します。 最後に、各レコードにlead_scoreラベルを付与します。評価が 4.0 以上でレビューが 50 件以上の企業は「hot」、評価が 3.0 以上でレビューが 10 件以上の企業は「warm」、それ以外は「cold」とマークされます。
ステップ6:パイプラインの起動と監視
dags/フォルダにDAGファイルを配置すると、Airflowは30秒以内に自動的にそれを検出します。
Docker ユーザーは、DAG の停止を解除してトリガーします:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation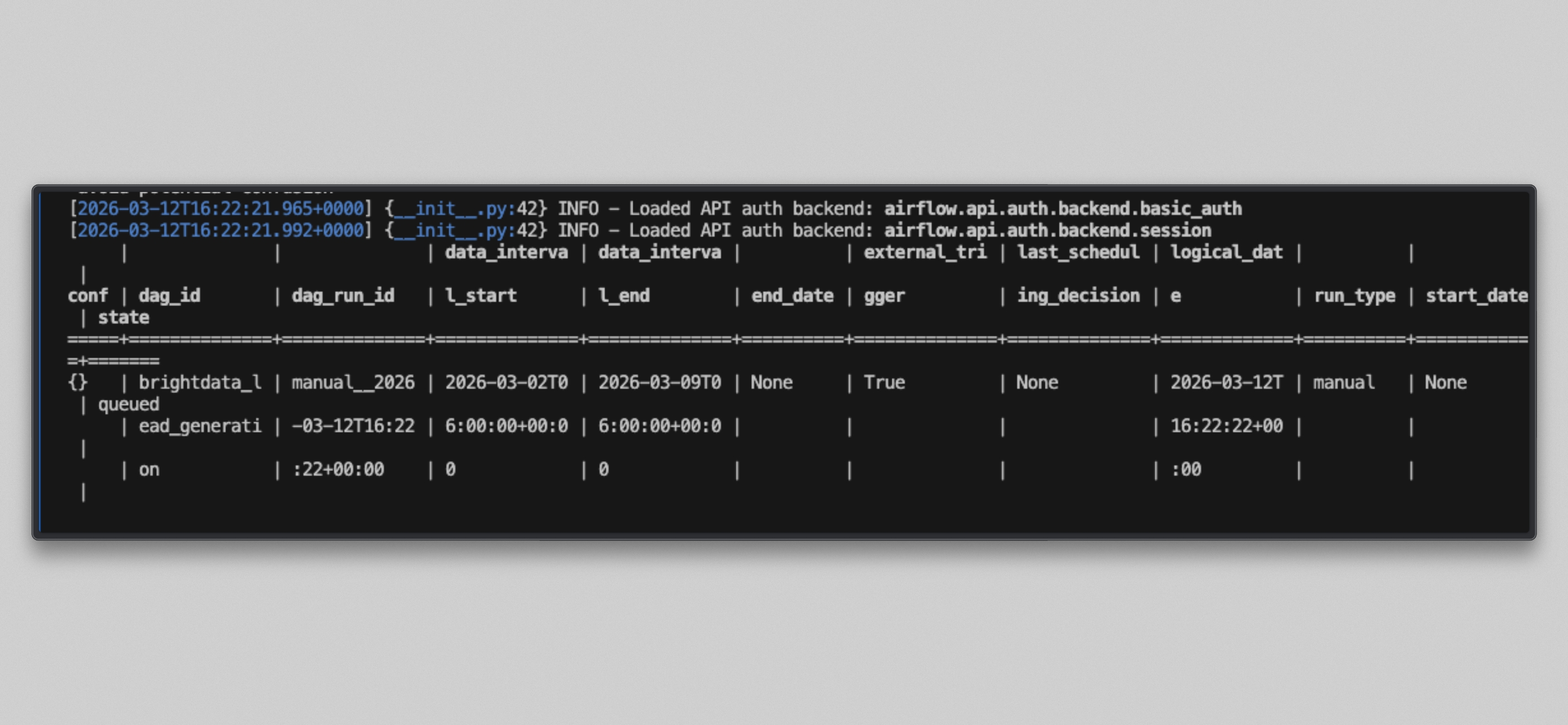
ワーカーのログを確認します:
docker compose logs airflow-worker -f --tail=20タスクが実行されると、次のような出力が表示されます:
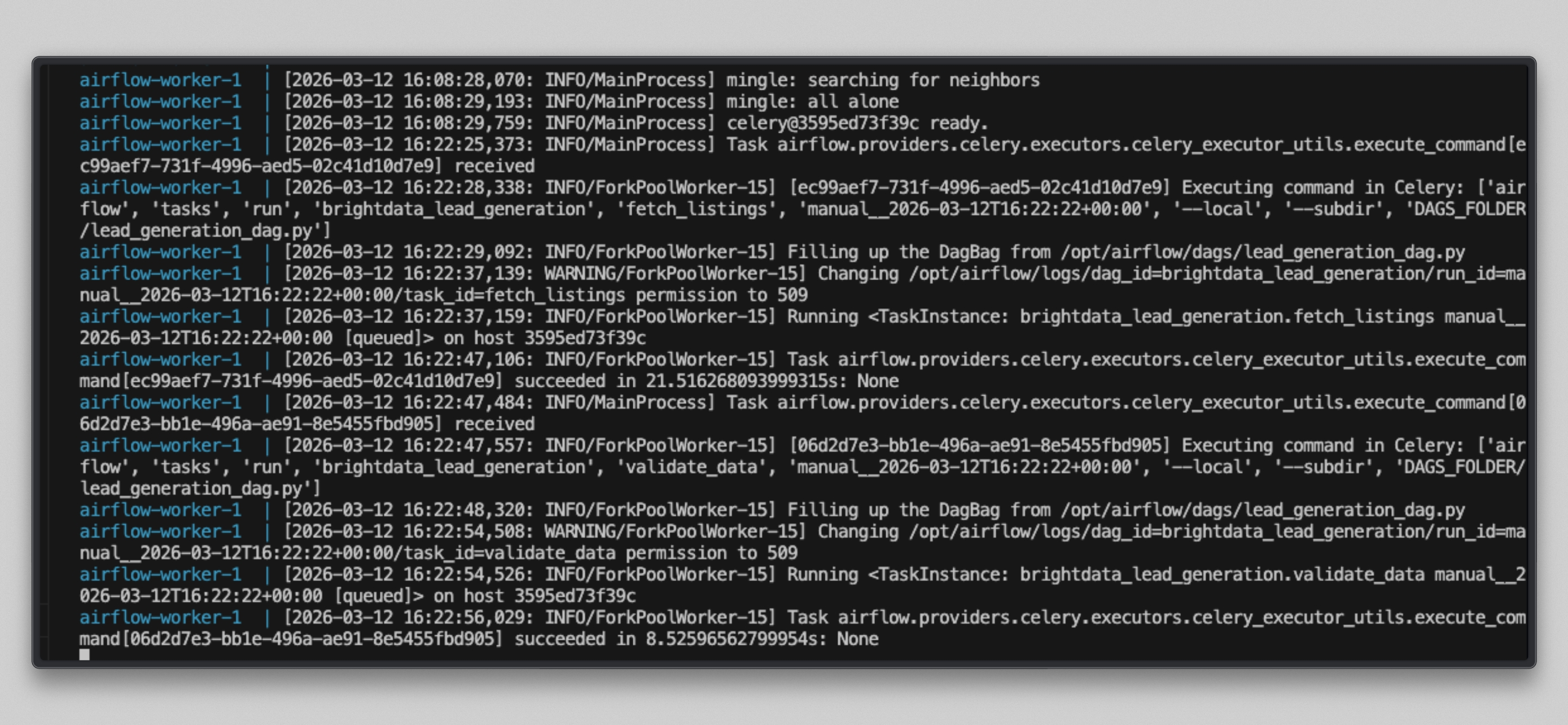
http://localhost:8080 を開き、brightdata_lead_generationDAG をクリックして、グリッドビューに切り替えます。各タスクのタイルは、完了するにつれて緑色に変わります。任意のタスクタイルをクリックし、「ログ」を選択すると、取得された各 URL や Bright Data から返された文字数など、リアルタイムの出力を確認できます。
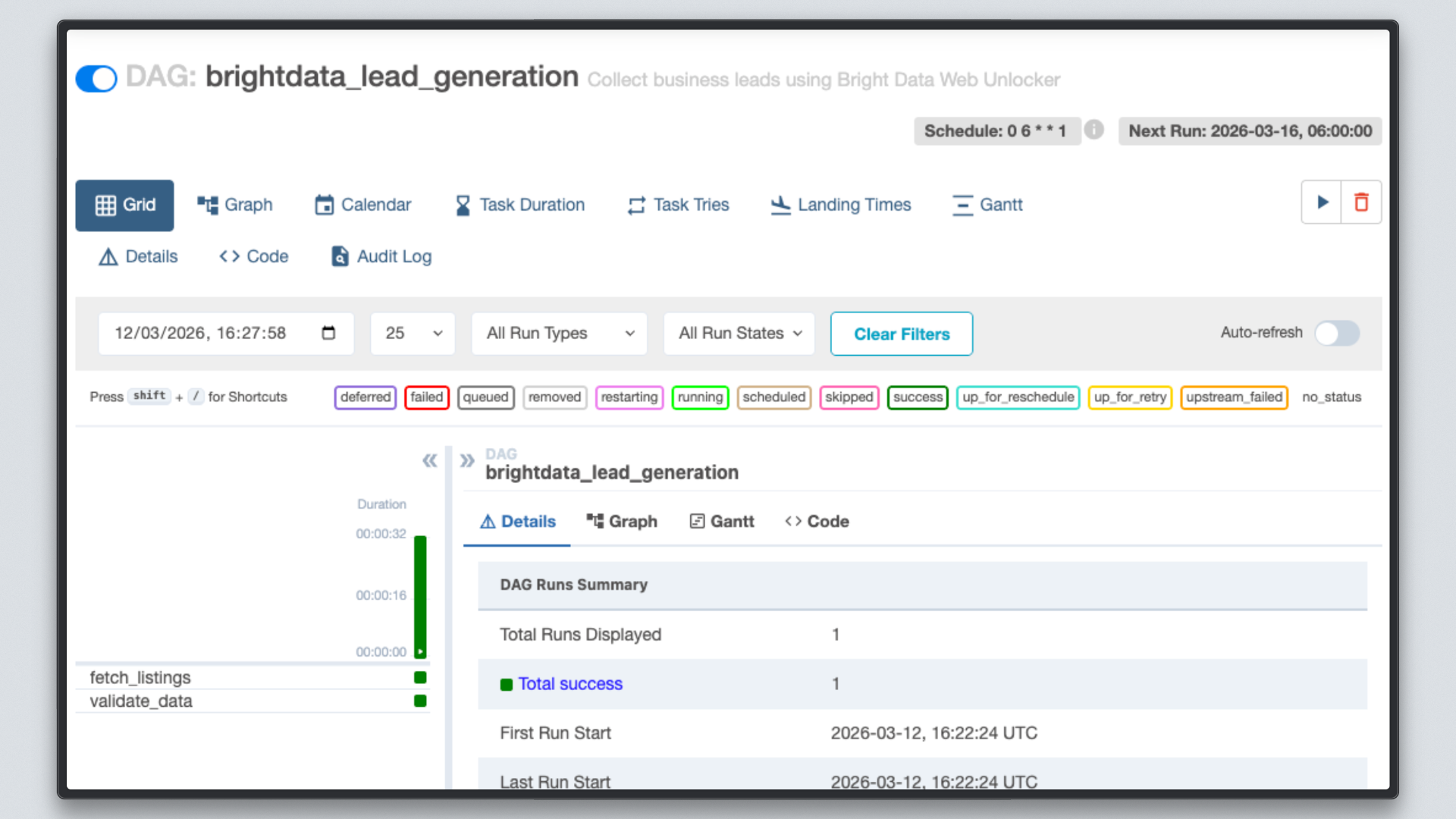
ステップ 7: 結果の確認
両方のタスクが緑色になったら、出力ファイルを確認してください。
Docker ユーザーの場合:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUbuntuネイティブユーザー:
cat /tmp/brightdata_raw/leads.jsonターゲットURLごとに1つずつ、合計3つのエントリを含むJSON配列が表示されます:
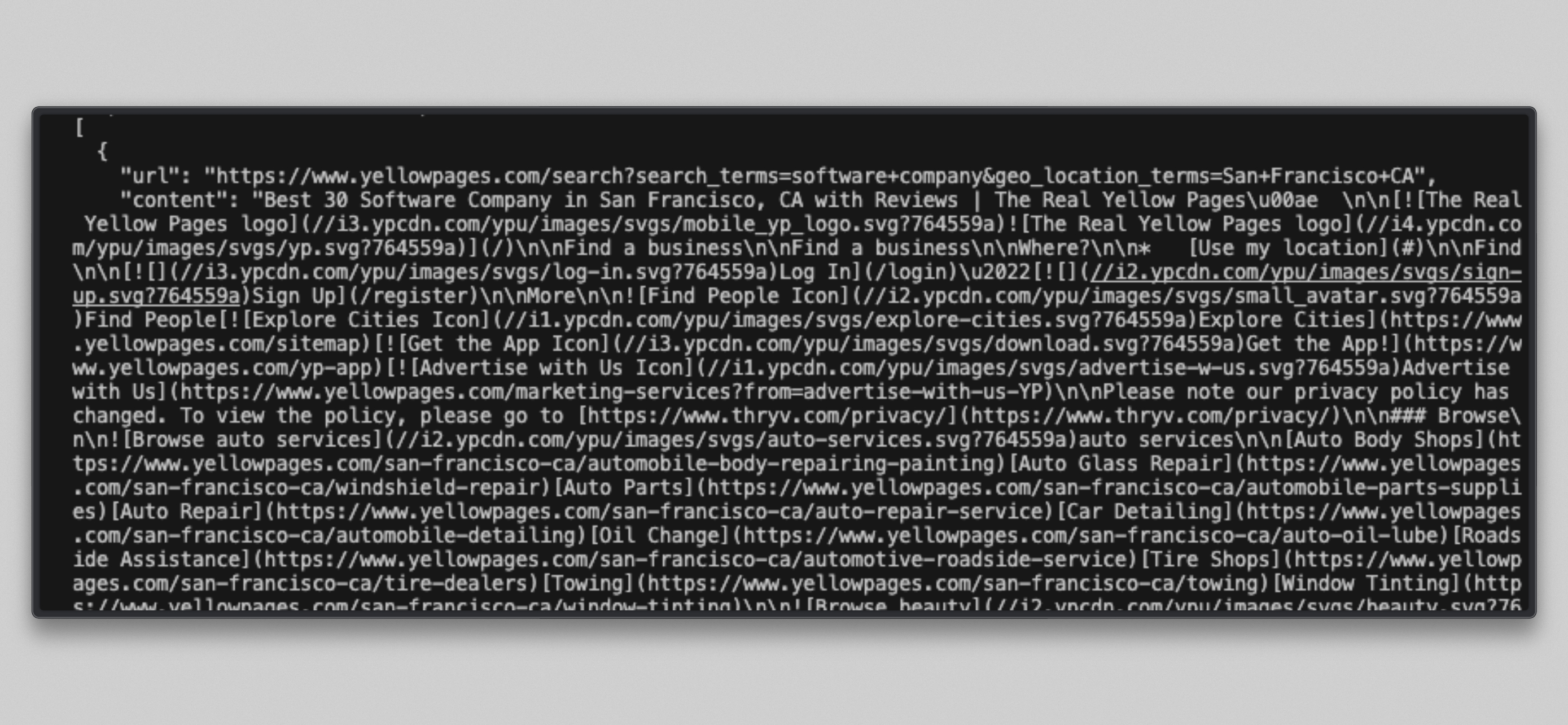
注:Bright Dataの即時アクセスモード下でサイトが制限されている場合、一部のイエローページURLでは
「bad_endpoint」メッセージが返されることがあります。これは正常な動作です。Bright Dataはエラーを黙って失敗させるのではなく、レスポンス内にエラー情報を明示します。制限されたサイトへの完全なアクセスが必要な場合は、Bright Dataのアカウントマネージャーにお問い合わせください。
最後に、出力に対してSparkジョブを実行します:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leadsこれにより、クリーニングおよびスコアリング済みの Parquet ファイルが/tmp/brightdata_processed/leads に書き込まれ、PostgreSQL やその他の下流システムへのロード準備が整います。
Web Unlocker APIはYellow Pagesから最新のリアルタイムコンテンツを配信し、パイプラインはウェブスクレイピングやプロキシ管理のコードを1行も記述することなく、自動的にデータをクリーニング、スコアリング、保存しました。ボット検出システムやレート制限のため、ビジネスリストを手動で収集することは非常に困難です。Bright DataのWeb Unlockerを使用すれば、インフラの維持管理を必要とせず、あらゆる地域の公開サイトから確実にページコンテンツを取得できます。
さらなる活用
このパイプラインは実用的な基盤であり、さまざまな方向に拡張することができます:
- 中間データ層としてローカルファイルシステムをAmazon S3やGoogle Cloud Storageに置き換え、パイプラインを分散ワーカー間で動作させる。
- Spark処理とデータベースへのロードの間にLLMによるエンリッチメントステップを追加し、OpenAIやAnthropicのAPIを使用して、有望なリードごとにパーソナライズされたアウトリーチ要約を生成します。
- Airflowの既存プロバイダーオペレーターを使用して、ローカル出力先をSalesforce、HubSpot、またはPipedriveへの直接CRMプッシュに変更します。
- Great ExpectationsやAirflowのSQLCheckOperatorを使用したデータ品質チェックタスクを追加し、データをコミットする前にレコード数やフィールドの完全性を検証します。
AWS EMR、 - DAGやPySparkのコードは変更せずに、Airflow内のSpark接続URLを更新するだけで、AWS EMR、Google Dataproc、またはDatabricks上のマネージドクラスターへスケールアウトできます。
- Bright DataのSERP APIを並列収集タスクとして使用し、各リードに最新のニュースや検索可視性データを付加します。
可能性は事実上無限大です!
まとめ
この記事では、Bright DataのWeb Unlocker API、Apache Airflow、およびApache Sparkを組み合わせて、実用的なリード生成パイプラインを構築しました。
Airflow は、スケジューリング、リトライロジック、依存関係管理、および可観測性を処理します。Spark は、生のビジネスデータの分散クリーニング、重複排除、およびスコアリングを処理します。Bright Data は、プロキシの管理、スクレイパーコードの記述、またはアンチボットシステムとの戦いを必要とせずに、Web から最新のページコンテンツを収集するという最も困難な部分を解消します。
ノーコードの自動化ツールとは異なり、このスタックでは、収集パラメータ、変換ロジック、出力スキーマ、スケジューリングの頻度など、パイプラインのあらゆるレイヤーを完全に制御できます。また、あらゆる最新のデータプラットフォームに自然に統合され、データ量に応じてスケーリングが可能です。
より充実したパイプラインを構築するには、検索データ用のSERP API、JavaScriptが多用されたページ用のWeb Unlocker、一般的なユースケース向けの既成データセットなど、Bright Dataのデータ収集ツール一式をご活用ください。
今すぐBright Dataの無料アカウントに登録し、パイプラインに必要なビジネスデータの収集を開始しましょう。






