
この記事では、以下の内容を学びます:
- Alteryx Oneとは何か、またその機能について。
- Bright Dataのウェブデータと連携することで、ワークフローがより洞察に富んだものになる理由。
- Bright Dataのウェブスクレイピングから取得した構造化された最新のウェブデータを使用して、Alteryx Oneで自動化されたワークフローを定義する方法。
さっそく始めましょう!
Alteryx Oneとは?
Alteryx Oneは、統合されたAI搭載の分析プラットフォームです。データ準備、分析、自動化、AIを単一の環境に統合しています。具体的には、組織が複数のデータソースに接続し、再利用可能なワークフローを構築し、大規模にインサイトを運用化するのを支援します。
Alteryx Oneが提供する主な機能は以下のとおりです:
- AIネイティブ分析:別のツールを使わずに、分析ワークフローにAIを統合してパターンを検出し、インサイトを生成し、予測モデリングをサポートします。
- AI対応データ準備:組み込みのガバナンスにより、複数のソースからデータを接続・クリーニング・変換し、信頼性の高い分析対応データセットを作成します。
- ワークフロー自動化:繰り返しの分析タスクやエンドツーエンドのプロセスを自動化し、手作業を削減して一貫性を向上させます。
- 統合分析ワークスペース:チームが協力して分析ワークフローを構築・実行・管理できる単一の環境を提供します。
- エンタープライズガバナンスとセキュリティ:コンプライアンス、系統追跡、アクセス制御を確保し、大規模な組織全体で安全に分析をスケールできます。
- 拡張可能なインテグレーション:エンタープライズシステムやLLMと接続し、既存のデータエコシステムに分析を直接組み込みます。
Bright DataがAlteryx Oneをサポートする方法
Alteryx Oneのワークフローの力は、消費するデータの質に依存します。確かに、このプラットフォームはデータ準備、分析、自動化のための強力な機能を提供しています。しかし、入力データの品質、鮮度、信頼性が最終的に出力の精度を決定します。ここでBright Dataがエンタープライズグレードのウェブデータプロバイダーとして重要な役割を果たします!
Bright Dataは、195カ国にわたる4億以上のIPのグローバルプロキシインフラを通じて、大規模な構造化ウェブデータを提供します。99.99%の稼働率と99.95%の成功率により、本番グレードの分析パイプラインに必要な信頼性を提供します。
Alteryx Oneとの直接統合には、Bright DataのWeb Scraping APIを使用して最新のウェブデータを取得するか、Bright Dataデータセット経由で静的なウェブデータにアクセスすることから始められます。このデータは構造化された形式でAmazon S3(またはその他の一般的な配信先)に自動的に配信できます。
Alteryx OneはそのデータセットをS3から直接インポートし、ノーコードのワークフローで処理します。最後に、処理された結果はダウンストリームでの使用のためにS3(または任意の配信先)に書き戻されます。
結果として、自動化されたエンドツーエンドの分析パイプラインが実現します。ここでBright Dataは信頼性の高いエンタープライズグレードのデータ取り込みを保証し、Alteryx Oneはそのデータを実用的なインサイトに変換します。
Bright DataのウェブデータでAlteryx Oneの自動データ分析ワークフローを構築する
このステップバイステップの章では、Alteryx Oneで自動化されたワークフローのセットアップを順を追って説明します。
このタイプのウェブ自動化ワークフローを実演するために、以下のコンポーネントを使用します:
- Bright DataのYahoo Finance Scraperを使用して最新の株式データを収集し、Amazon S3への配信を設定します。
- データをインポートし、出来高でソートして、プラス株とマイナス株の2つのデータセットに分割するAlteryx Oneワークフロー。その後、処理された出力をAmazon S3に書き戻します。
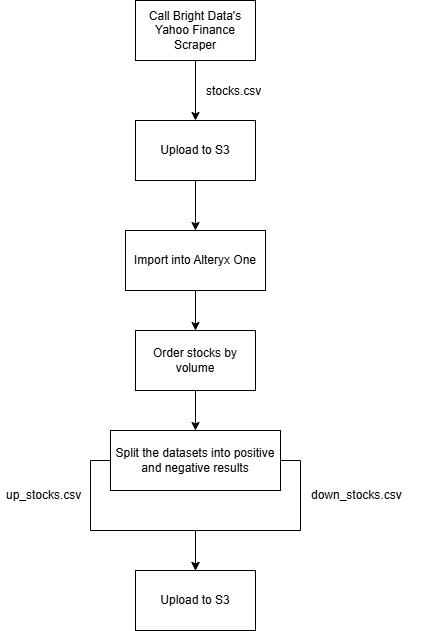
以下の手順に従ってこのワークフローを構築してください!
前提条件
このセクションを進めるには、以下が必要です:
- Alteryx Oneアカウント(無料トライアルでも構いません)。
- AWSアカウントで定義されたS3バケット。
- APIキーが設定されたBright Dataアカウント。公式の手順に従ってAPIキーを生成してください。
このチュートリアルでは、S3バケット名がbright-data-datasetsであると仮定します。ただし、他のバケット名でも問題ありません。
ステップ#1:Bright DataスクレイピングAPIのセットアップ
ウェブデータ自動化パイプラインの最初のステップは、ウェブからソースデータを取得することです。そのために、Bright DataのYahoo Finance Scraperを使用してリアルタイムの財務データを収集します。さっそく始めましょう!
まだアカウントをお持ちでない場合は、Bright Dataアカウントを作成してください。既にアカウントをお持ちの場合は、ログインしてください。コントロールパネルで「Scrapers > Scrapers Library」ページに移動します:
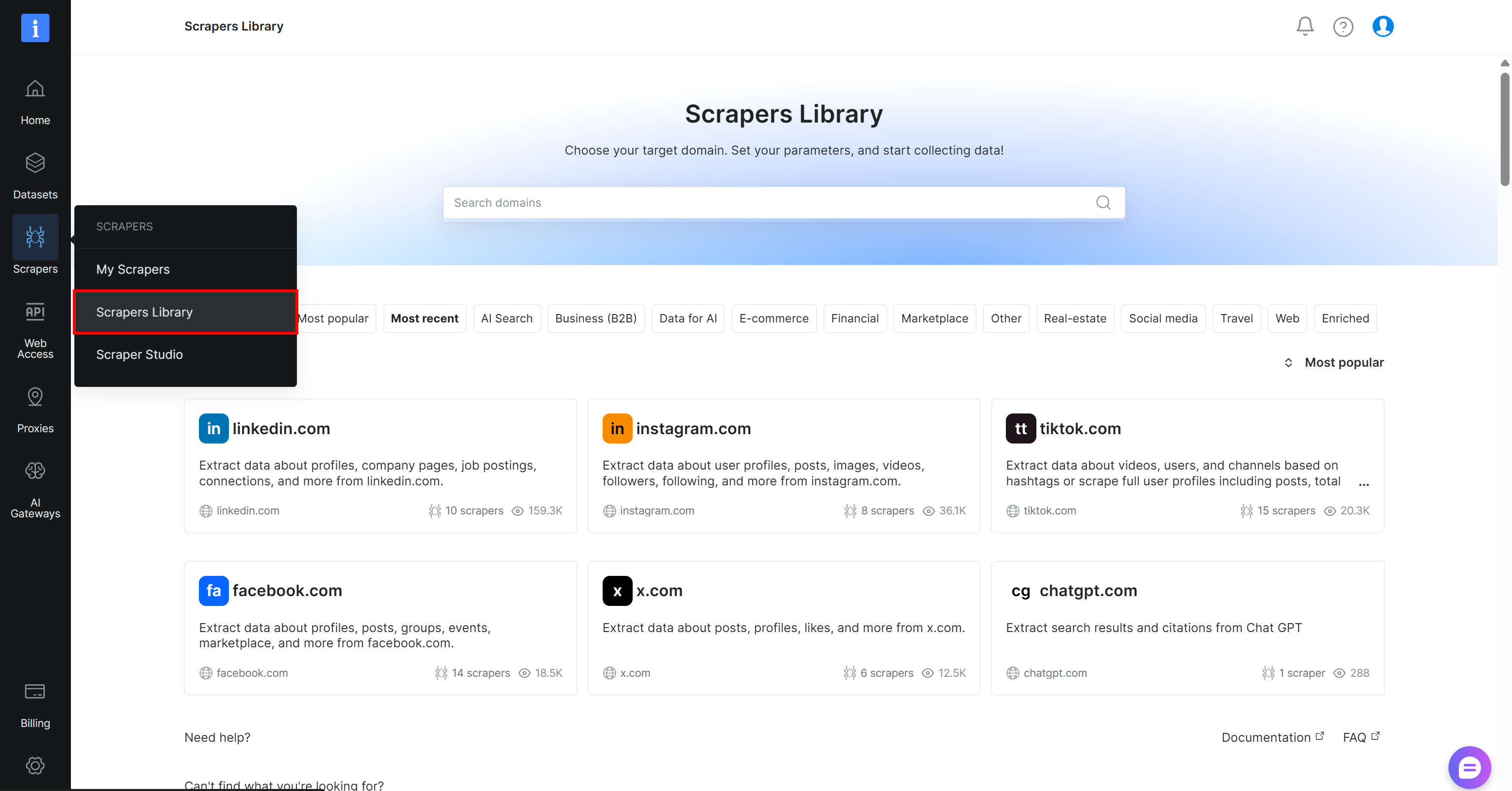
「yahoo finance」を検索し、「finance.yahoo.com」スクレイパーを選択します:
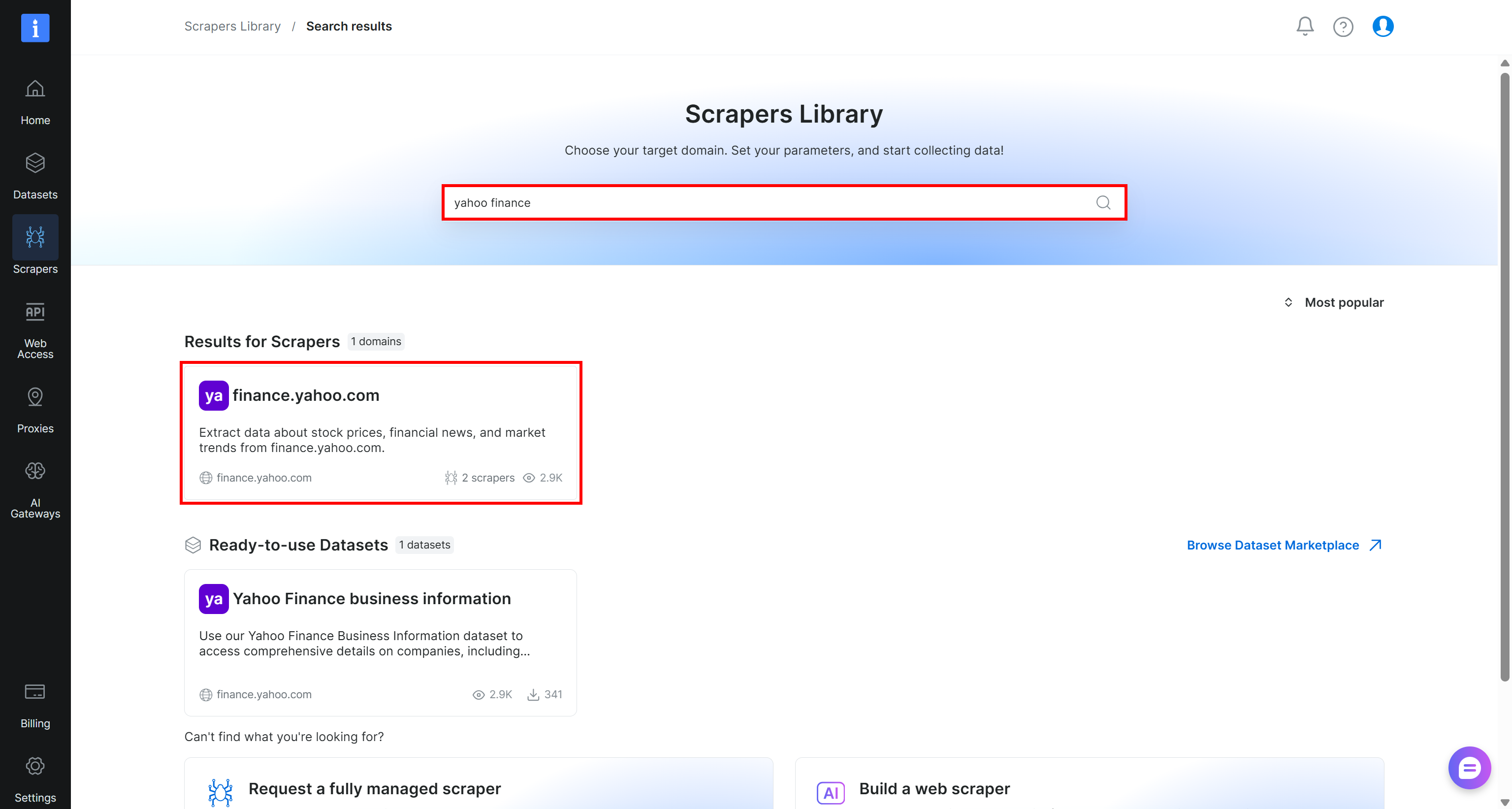
Yahoo Finance Scraperページで、スクレイパーの入力要件と出力スキーマを確認します:
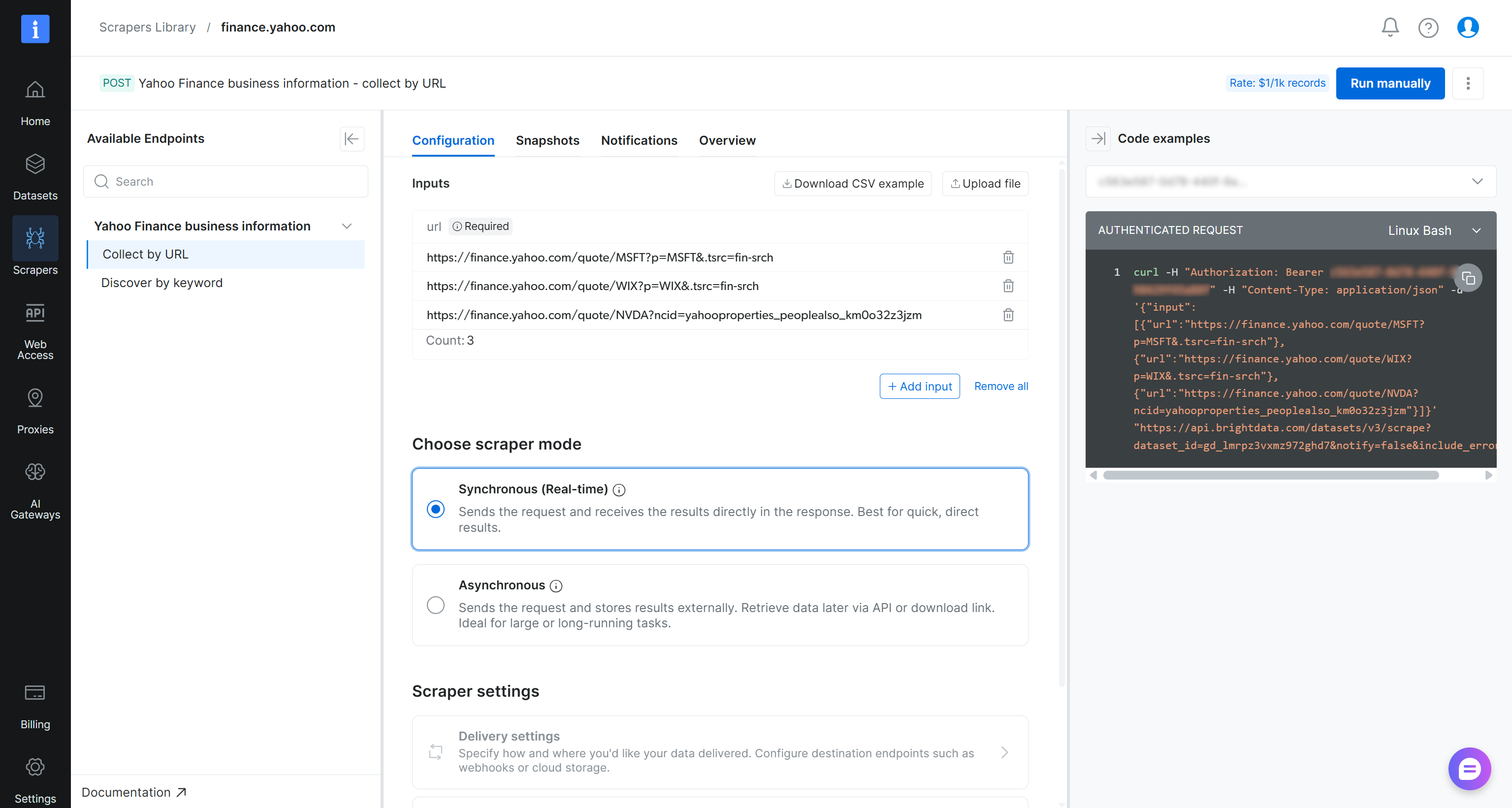
大まかに言うと、このスクレイパーは1つ以上のYahoo Finance株式ページのURLを入力として受け取り、構造化されたリアルタイムの財務データを返します。まさに必要なものです!
ステップ#2:S3配信の設定
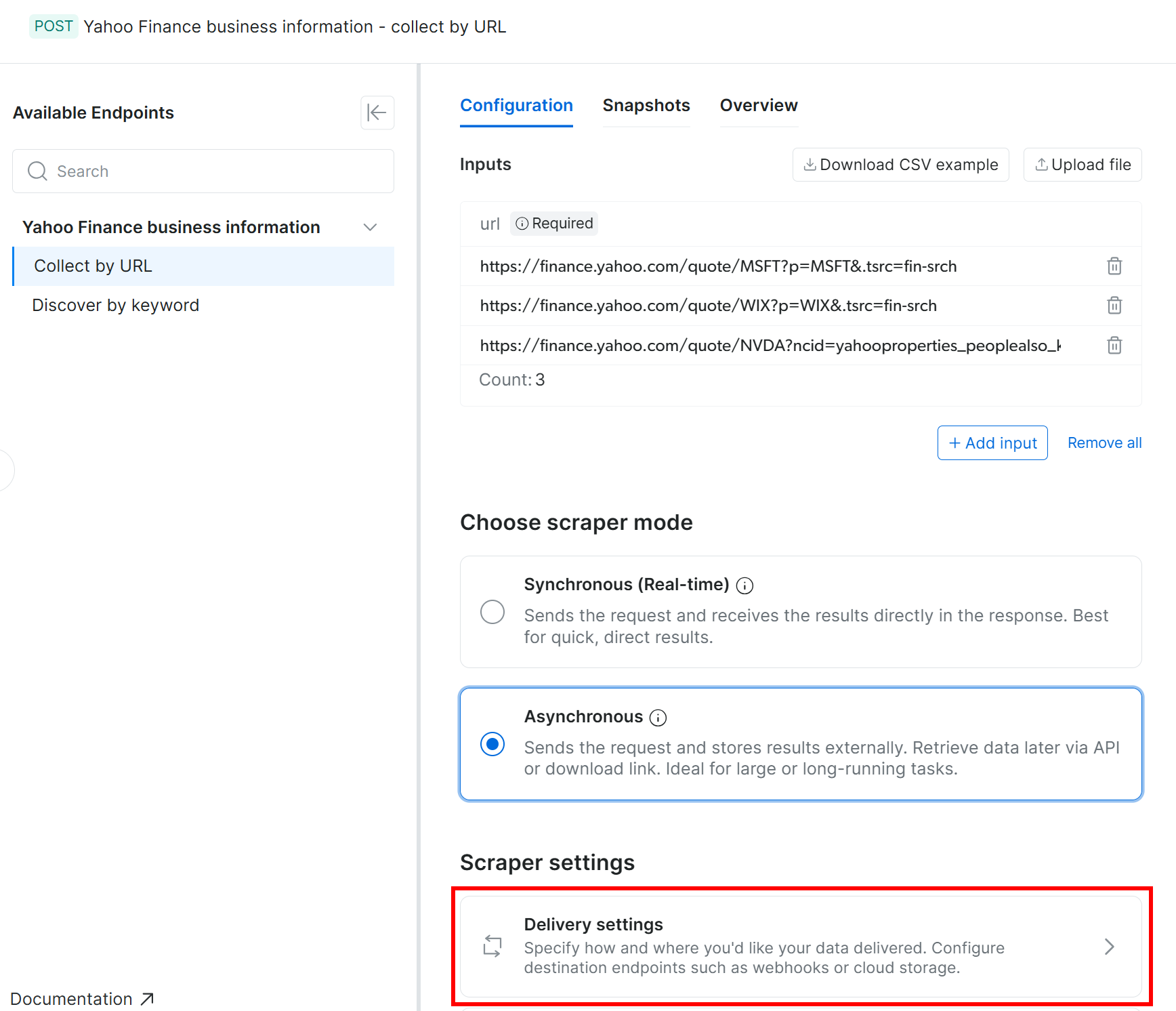
Bright DataのWeb Scraping APIは、スクレイピングされたデータのAmazon S3への自動配信(および他のいくつかのクラウドストレージプロバイダーと配信方法)をサポートしています。Amazon S3への配信を有効にするには、まずスクレイパーを非同期モードに切り替える必要があります。
「Configuration」タブで「Asynchronous」オプションを選択し、「Delivery settings」を押します:
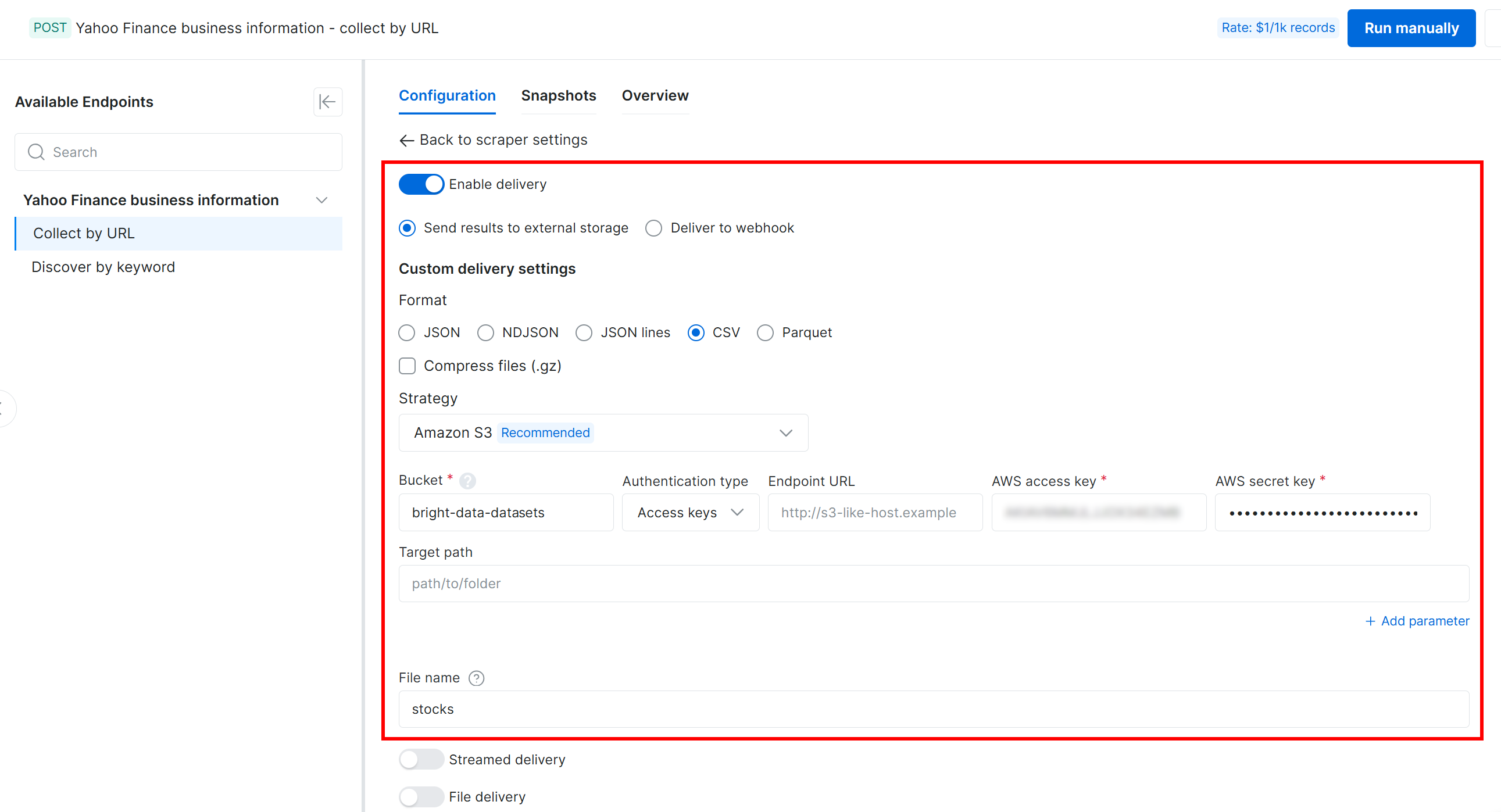
次に、以下の設定を使用してAmazon S3バケットへの配信を設定します:
- 「Enable delivery」トグルを有効にします。
- 出力データ形式をCSVに設定します。
- ストレージ先として「Amazon S3」を選択します。
- S3バケット名を入力します(この例では
bright-data-datasets)。(「Endpoint URL」フィールドは空のままにできます。) - 「Target path」を空のままにして、バケットのルートフォルダにファイルをアップロードします。
- 「Authentication type」オプションを「Access keys」に設定します。
- AWS Access Key IDとAWS Secret Access Keyを貼り付けます。
- ファイル名を
stocksに設定します。
この設定により、Web Scraping APIは非同期モードで実行されます。データをすぐに返す代わりに、Bright Dataはそのインフラ上で実行されるスクレイピングジョブを作成します。ジョブが完了すると、スクレイピングされたデータが自動的にAmazon S3バケットにアップロードされます。手間いらずで便利です!
ステップ#3:ウェブデータ取得タスクの実行
ウェブデータ抽出ワークフローが正しく機能することを確認するために、いくつかのYahoo Finance株式URLを入力として追加します。この例では、Nasdaqトップ10銘柄(NVDA、AAPL、GOOGL、MSFT、AMZN、TSLA、META、AVGO、WMT、AMD)を追跡したいと仮定します。
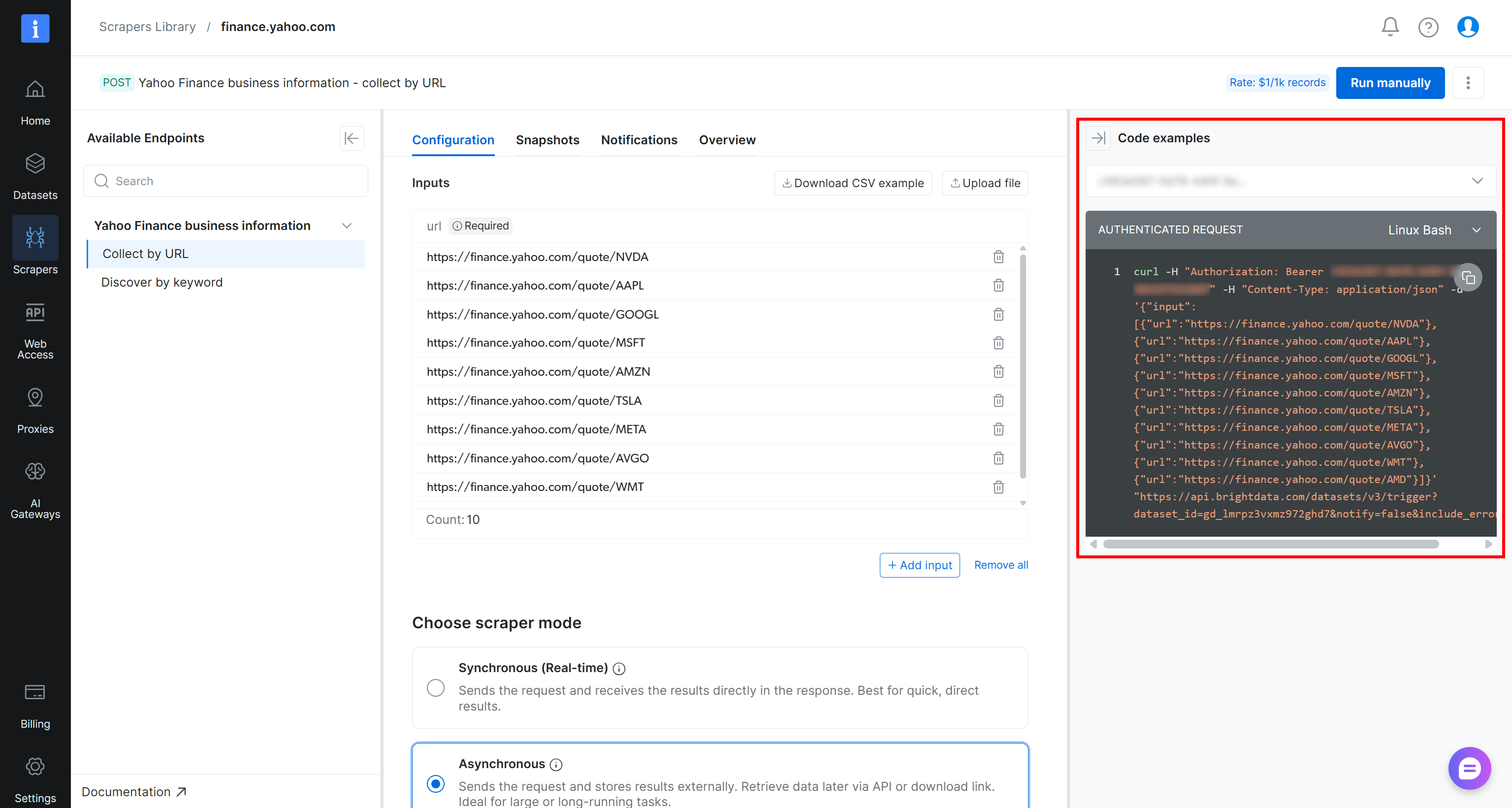
スクレイピングタスクをプログラムで起動するには、スクレイパーページに表示されているcURLスニペットを使用できます:
curl -H "Authorization: Bearer <YOUR_BRIGHT_DATA_API_KEY>" -H "Content-Type: application/json" -d '{"input":[{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}]}' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true"または、以下のPythonスクリプトを実行することもできます:
# pip install requests
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://finance.yahoo.com/quote/NVDA"},{"url":"https://finance.yahoo.com/quote/AAPL"},{"url":"https://finance.yahoo.com/quote/GOOGL"},{"url":"https://finance.yahoo.com/quote/MSFT"},{"url":"https://finance.yahoo.com/quote/AMZN"},{"url":"https://finance.yahoo.com/quote/TSLA"},{"url":"https://finance.yahoo.com/quote/META"},{"url":"https://finance.yahoo.com/quote/AVGO"},{"url":"https://finance.yahoo.com/quote/WMT"},{"url":"https://finance.yahoo.com/quote/AMD"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lmrpz3vxmz972ghd7¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())いずれの場合も、<YOUR_BRIGHT_DATA_API_KEY>をBright DataのAPIキーに置き換えてください。
注意:さらに簡単な方法として、コントロールパネルから直接「Run manually」ボタンをクリックしてタスクを実行することもできます。
起動されると、スクレイピングリクエストがBright Dataのクラウドインフラに送信され、抽出タスクが開始されます。Bright Dataコントロールパネルからリアルタイムでステータスを監視できます:
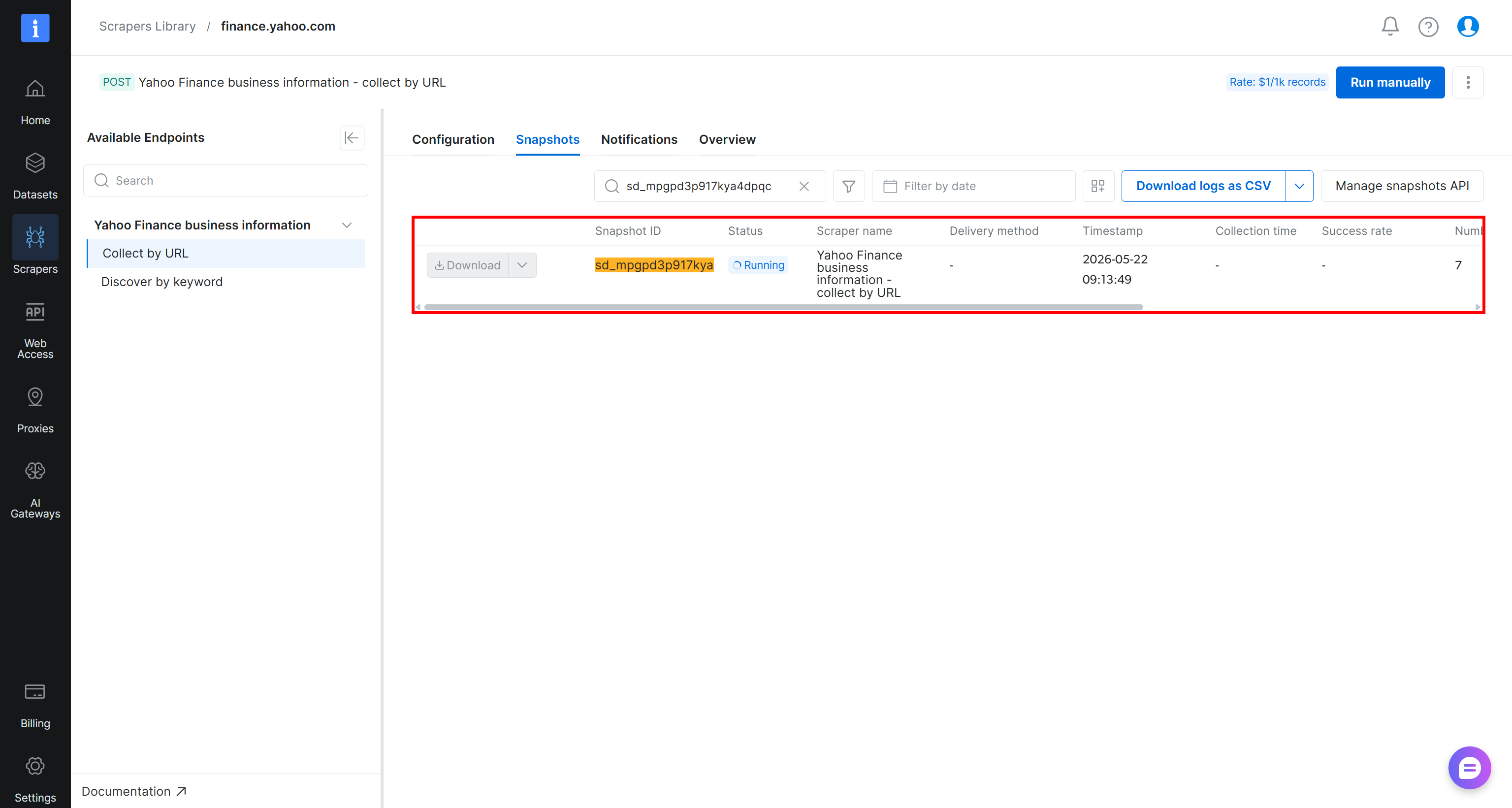
タスクのステータスが「Ready」に変わったら、Amazon S3バケットを開きます。stocks.csvという名前の新しいファイルが表示されているはずです:

stocks.csvファイルをダウンロードして開くと、次のような内容が表示されます:
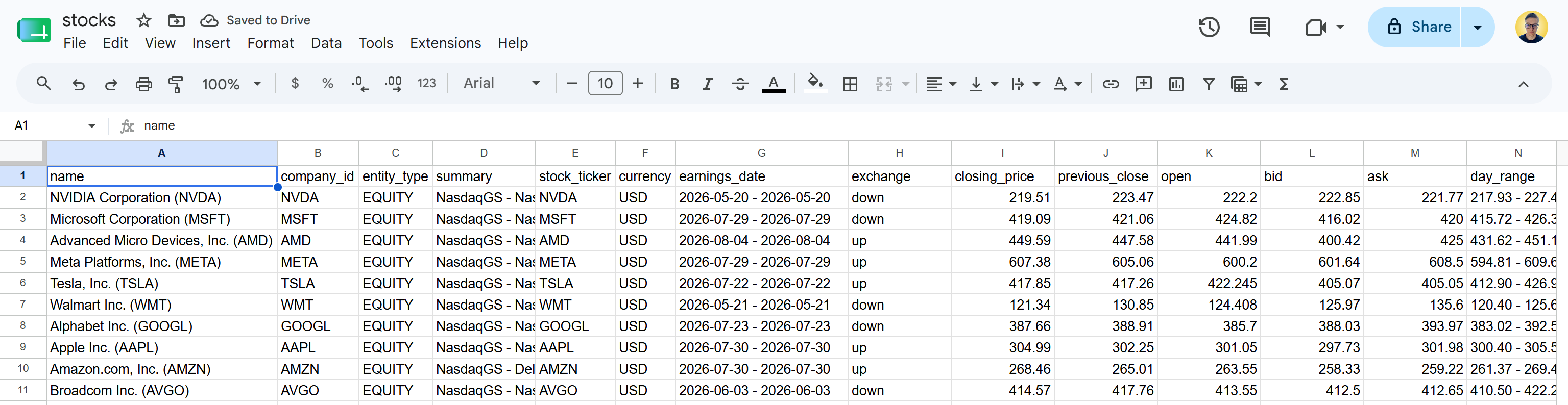
これは指定されたYahoo Financeページで利用可能な株式データと同じです。Bright DataのYahoo Finance Scraper APIが株式データを取得し、構造化されたCSV形式に変換しました。
スクレイピングされたデータの構造と利用可能な列をより深く理解するには、Yahoo Financeスクレイパーページの「Overview」タブにある「Dictionary」セクションを参照してください:
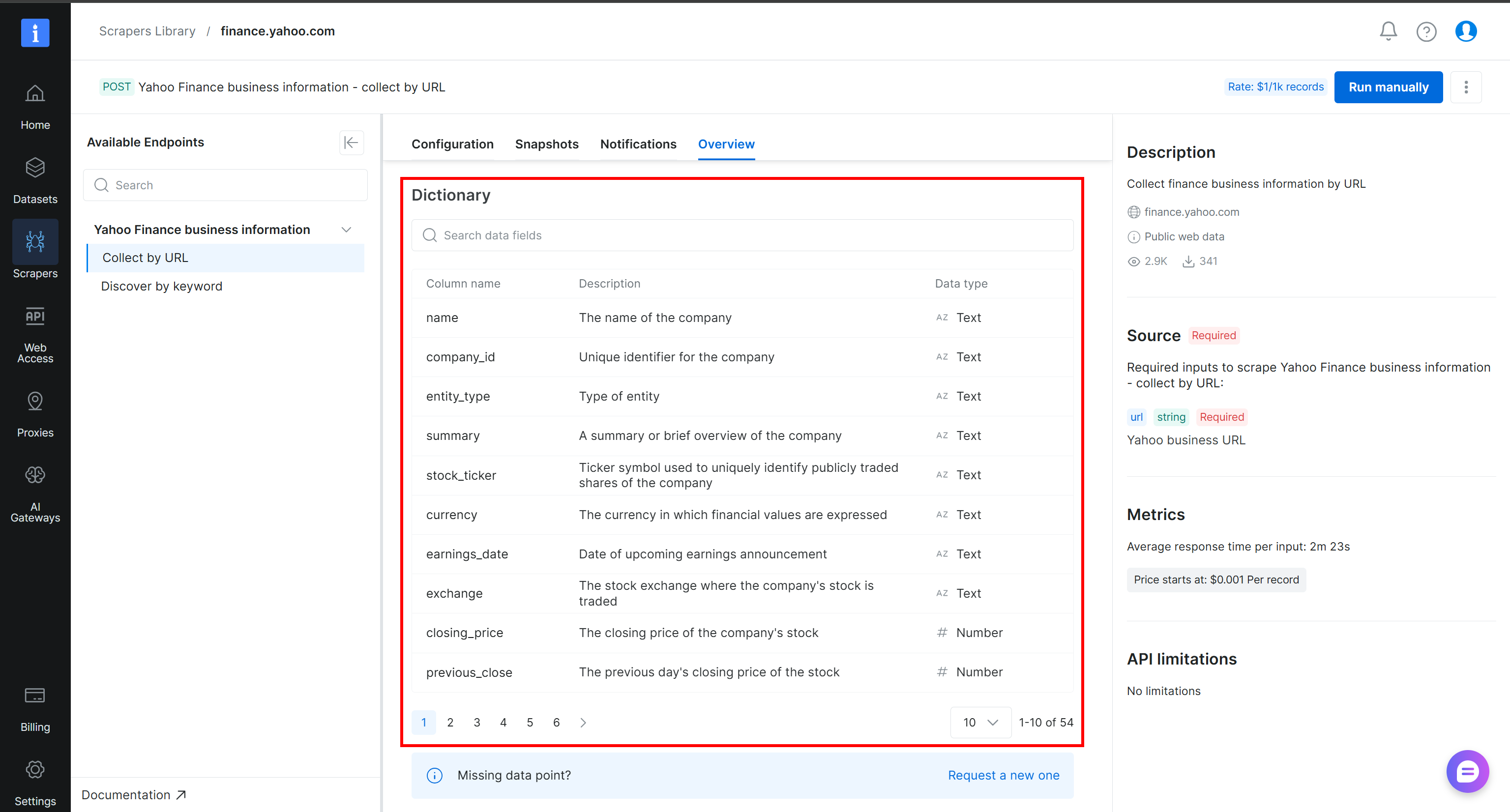
素晴らしい!これでAlteryx Oneのウェブデータパイプラインを構築するために必要なデータが揃いました。
ステップ#4:Alteryx OneをS3データソースに接続する
現在、スクレイピングされたソースデータはAmazon S3に配信されています。次のステップは、ワークフローが必要に応じてデータにアクセスして分析できるように、Alteryx OneアカウントをそのS3バケットに接続することです。
Amazon S3バケットへの接続を作成するには、Alteryx Oneにログインします。「Data」ページに移動し、「Connections」タブを開きます。次に「New Connection」をクリックします:
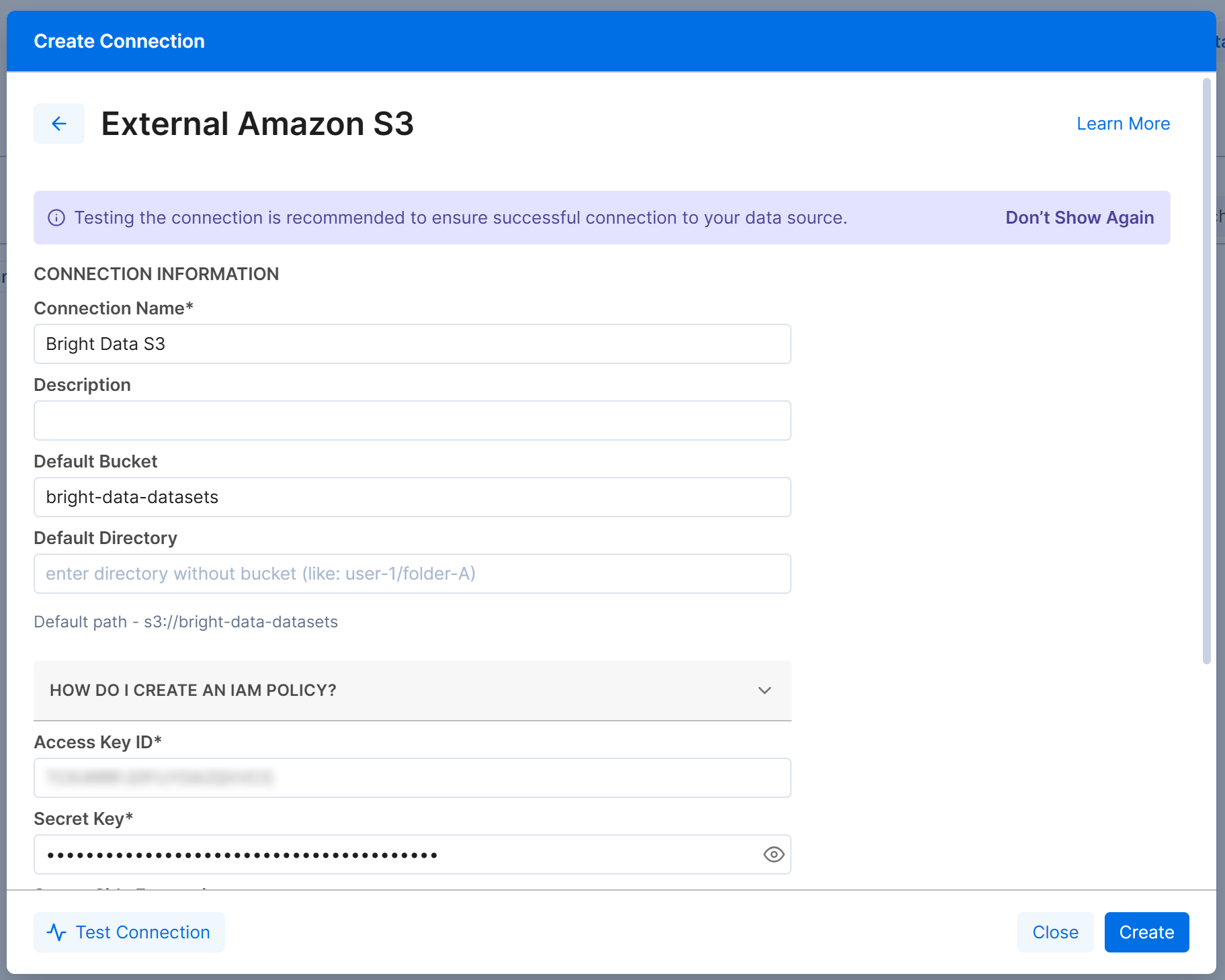
次に、「External Amazon S3」接続フォームを以下のように設定します:
- Connection Name:Bright Data S3(または任意の名前)。
- Default Bucket:
bright-data-datasets(または実際のバケット名)。 - Access Key IDとSecret Access Key:AWS Access Key IDとAWS Secret Access Key。
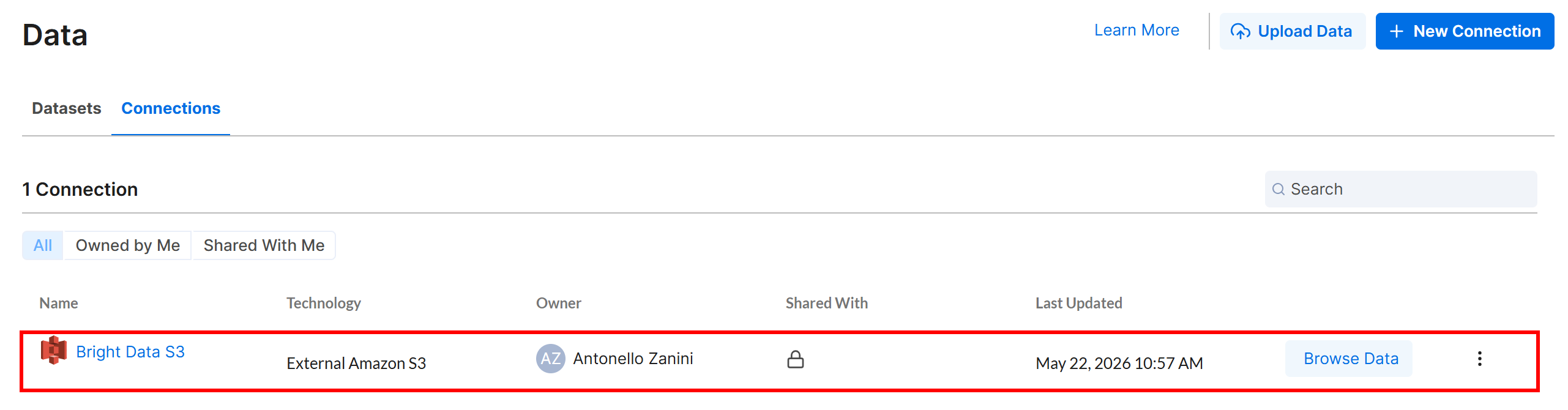
「Create」をクリックすると、Amazon S3接続が「Connections」タブに表示されます:
素晴らしい!次は、Yahoo Finance Scraper APIが出力を保存するAmazon S3バケットから入力データを読み取るAlteryx Oneワークフローを定義します。
ステップ#5:Alteryx Oneワークフローの初期化
「Overview」ページに移動し、「New Workflow with Designer Cloud」ボタンをクリックします:
または、Alteryx Oneデスクトップアプリからワークフローを作成することもできます。
ワークフローに「Automated Stock Analyzer」などの名前を付けます:
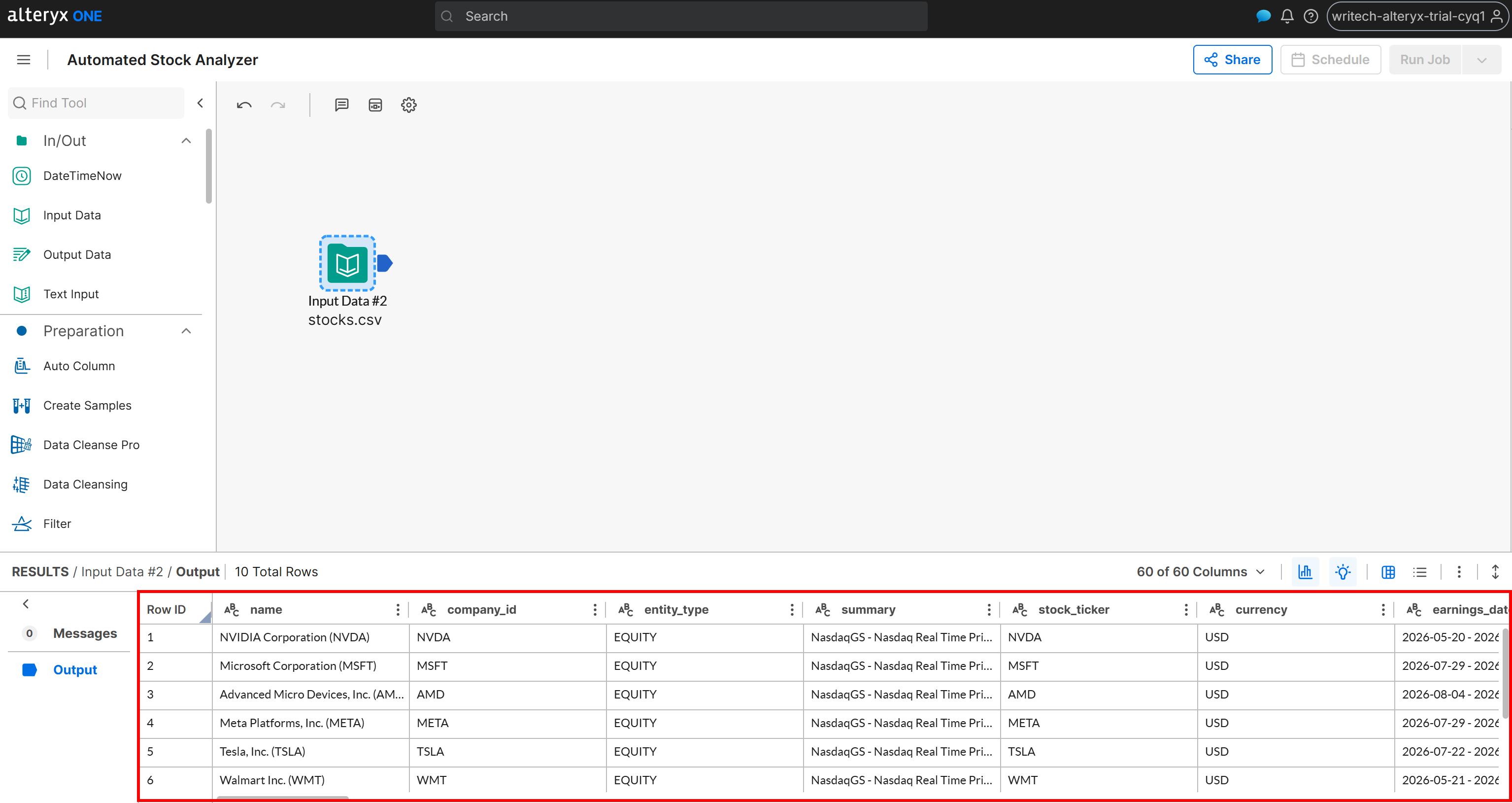
ワークフロー構築の最初のステップは、ソースデータを読み込むことです。これを行うには、「Input Data」ノードをワークフローキャンバスにドラッグします:

次に、ノードをダブルクリックして設定し、Amazon S3バケットに接続してstocks.csvファイルを選択します。セットアップウィザードに従ってデータセットをインポートします。完了すると、データが正常に読み込まれたことが確認できます:
この時点で、ワークフローはスクレイピングされたウェブデータにアクセスできます。素晴らしい!次は、データ分析ロジックの追加を始めましょう。
ステップ#6:データ分析ロジックの定義
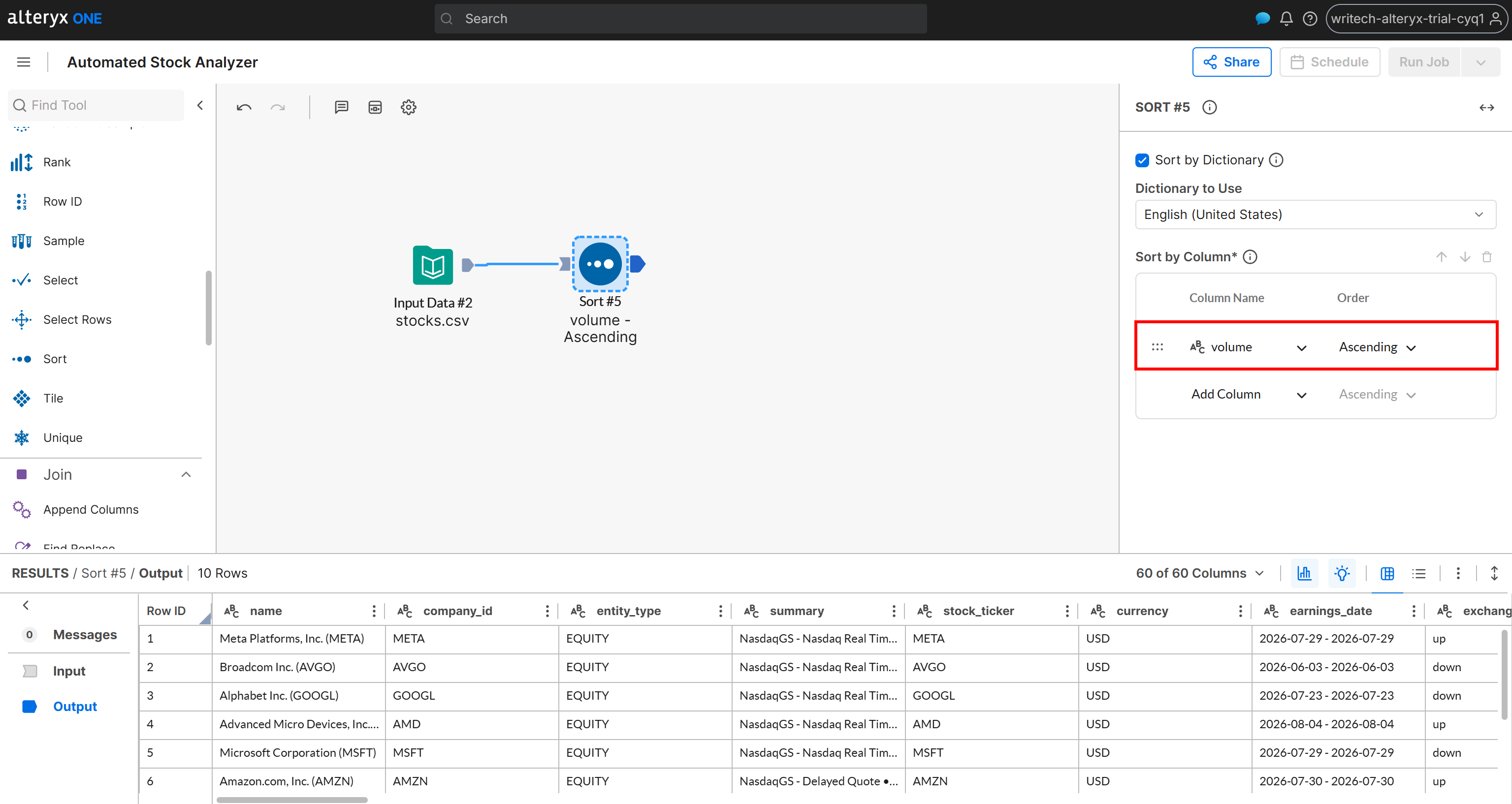
日次取引量などの特定の基準で結果を並べ替えたいとします。「Sort」ノードを追加し、ソート設定でvolume列を選択して順序をAscending(昇順)に設定します:
次に、データセットを2つのグループに分割したいとします:
- その日をプラスで終えた銘柄。
- その日をマイナスで終えた銘柄。
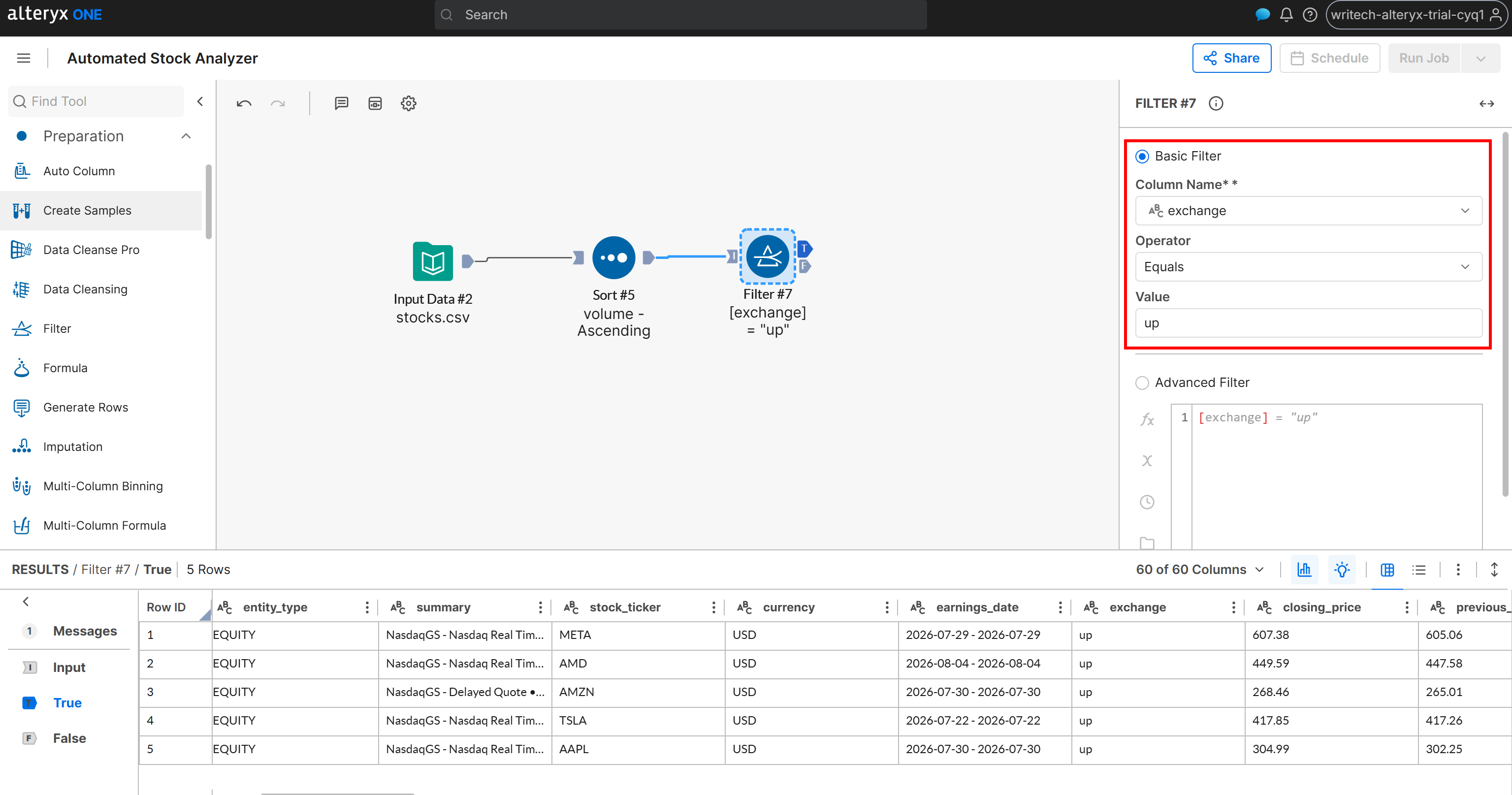
そのために、exchangeフィールドに「up」または「down」が含まれているかどうかに基づいて銘柄を分類します。「Filter」ノードを追加し、「Sort」ノードの出力に接続します。次に、以下のようなフィルター条件を定義します:
- Column Name:
exchange - Operator:Equals
- Value:
up
Filterノードは2つの出力を生成します:
T(True):exchangeフィールドが「up」の銘柄を含みます。F(False):exchangeフィールドが「up」でない銘柄(つまり「down」)を含みます。
このシンプルなウェブ自動化ワークフローの最後のステップは、出力先を定義することです。それを行いましょう!
ステップ#7:出力ファイルの指定
「Output Data」ノードをキャンバスに追加し、「Filter」ノードのT出力に接続します。「Output Data」ノードを設定して、Amazon S3バケット(または他の接続されたデータソース)にデータを書き込みます。例えば、up_stocks.csvという名前のファイルを作成します:
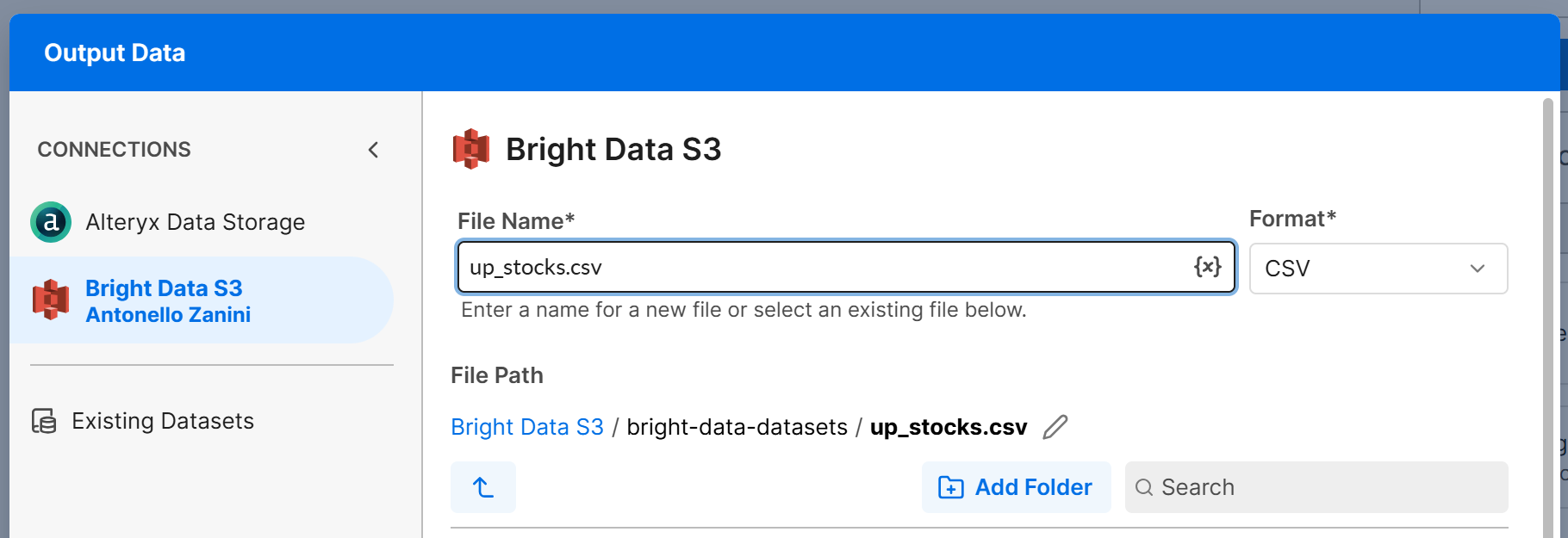
「Next」をクリックし、「Confirm」をクリックしてTブランチの出力設定を保存します。Fブランチでも同じプロセスを繰り返し、down_stocks.csvファイルに書き込むように設定します。
最終的なワークフローは次のようになります:
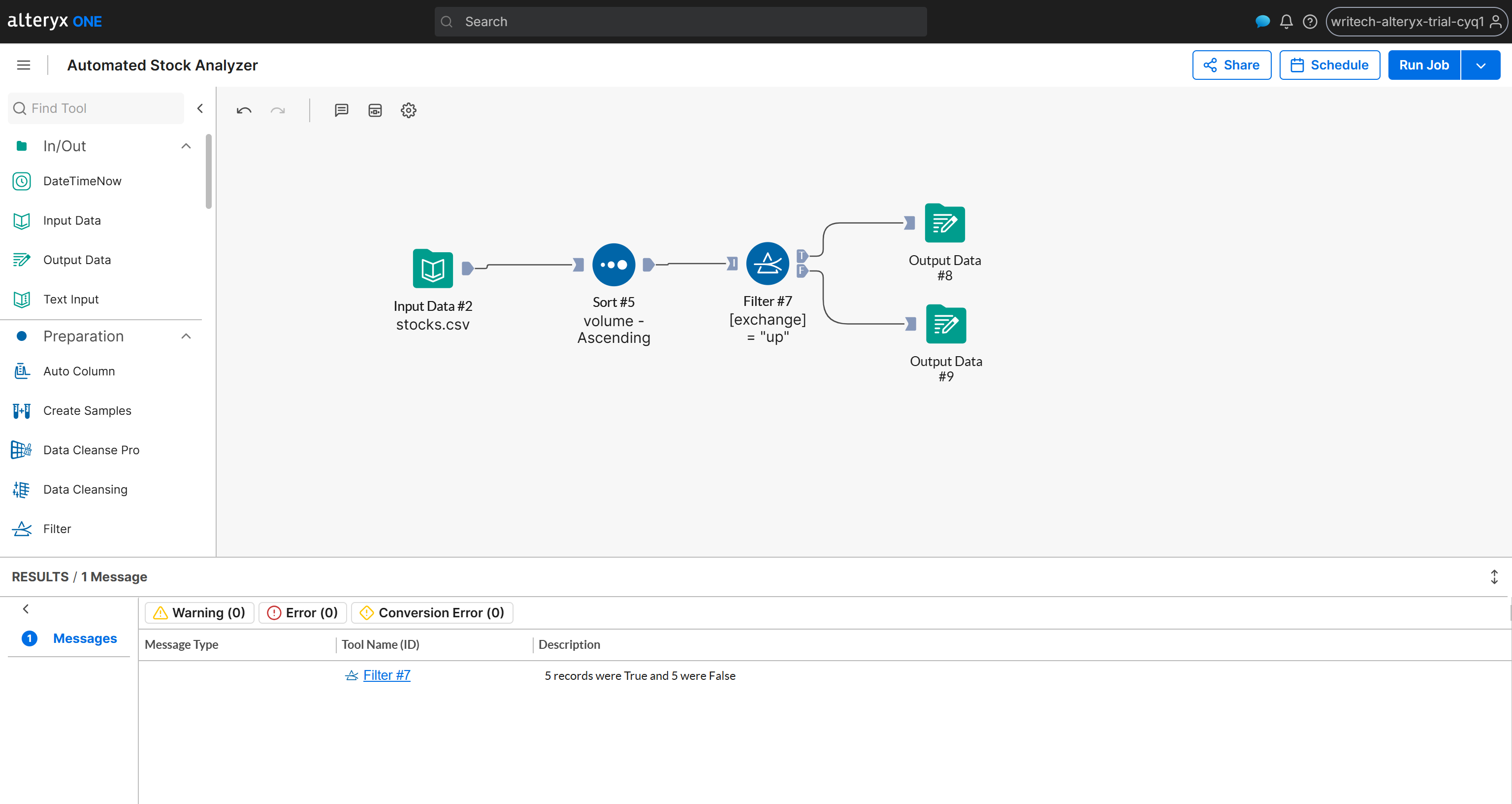
完成です!後はワークフローを実行して、すべてが期待通りに動作することを確認するだけです。
ステップ#8:ワークフローの起動
「Run Job」ボタンをクリックし、Bright Dataを活用した自動ウェブデータ分析ワークフローが完了するまで待ちます:

実行が完了すると、Alteryx Oneで成功通知が届き、確認メールも送信されます。
次に、Tシナリオの生成された出力を確認します:
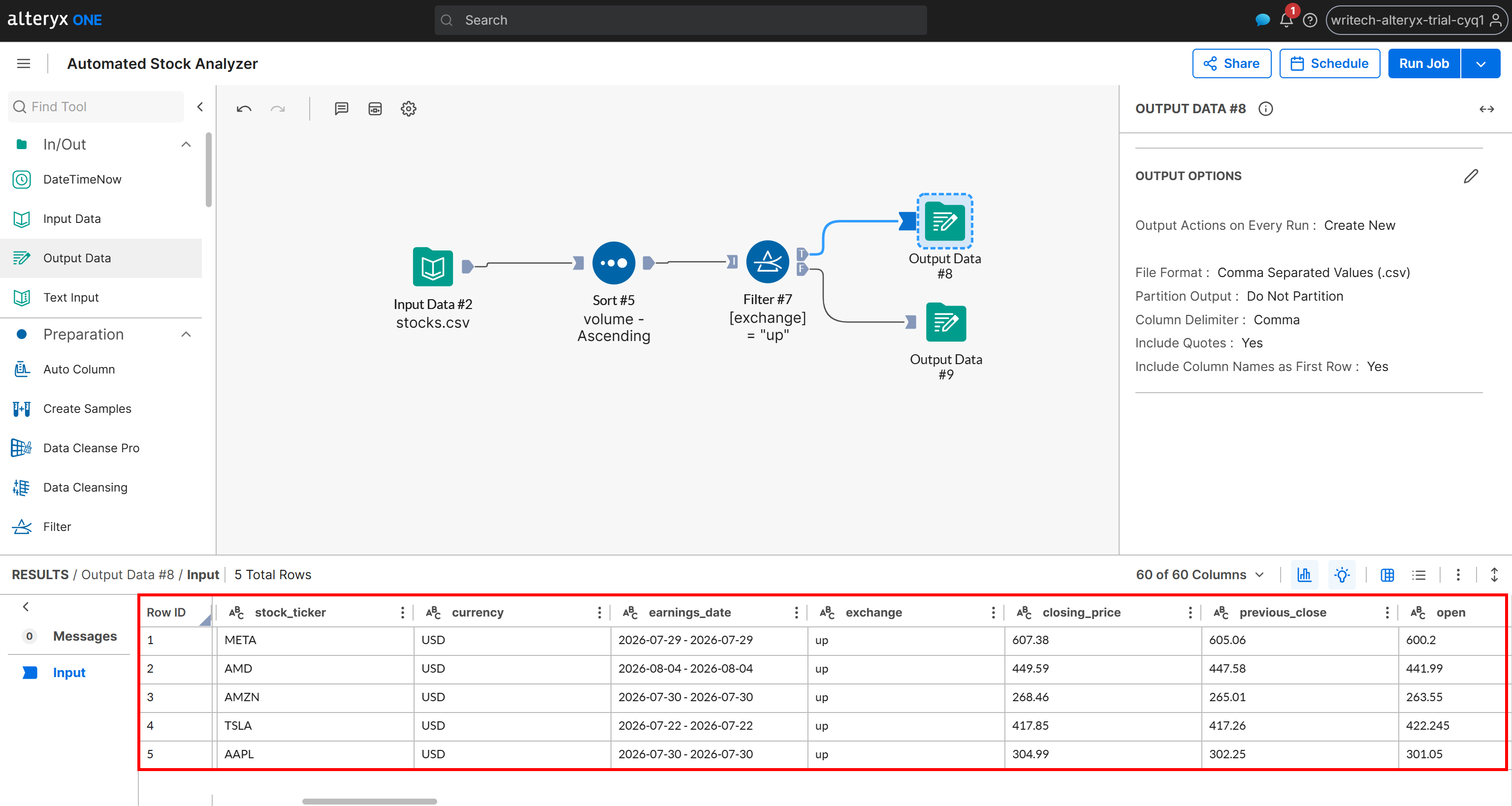
この出力には、変化ステータスが「up」の銘柄のみが含まれており、出来高の昇順でソートされています。同じデータは、パイプラインによって生成されAmazon S3バケットに保存されたup_stocks.csvファイルでも確認できます。
次に、Fシナリオの生成された出力を確認します:
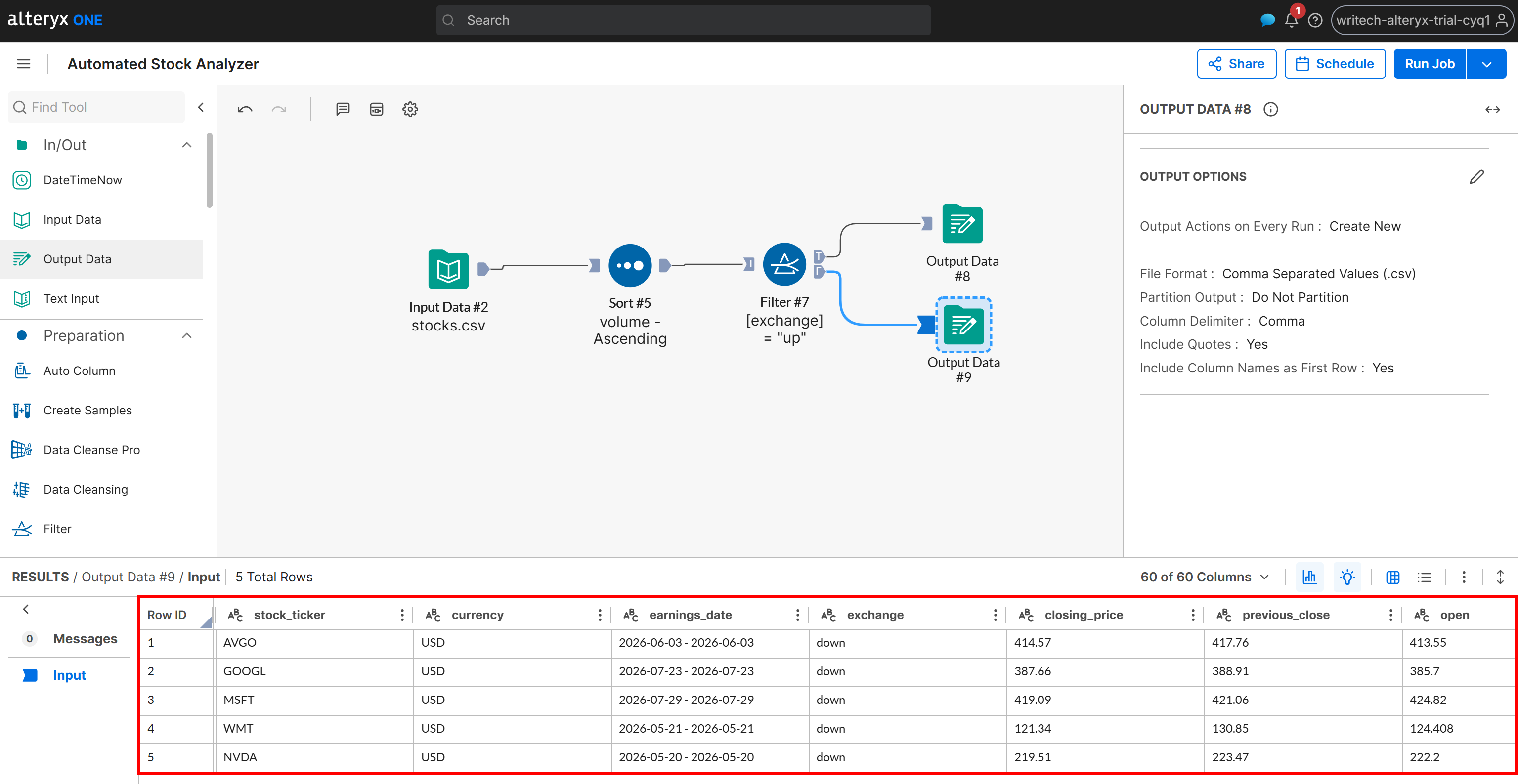
この出力には、変化ステータスが「down」の銘柄のみが含まれており、こちらも出来高の昇順でソートされています。同じ結果がAmazon S3バケットのdown_stocks.csvファイルに書き込まれます。
完成です!Bright Dataを活用したAlteryx Oneのウェブデータ分析パイプラインを構築しました。これはあくまで一例であり、他にも多くのウェブデータ自動化シナリオが可能です。
次のステップ
これはいくつかのサンプルステップを含むシンプルなデータ分析パイプラインに過ぎないことを念頭に置いてください。実際には、追加の処理ノード(AIノードを含む)を追加したり、複数のデータソースを導入したりすることで、はるかに複雑なものにすることができます。
例えば、他のBright DataのWeb Scraping APIを設定して同じAmazon S3バケットに書き込むことができます。結果のデータセットは、結合操作を使用してエンリッチメントやより高度な分析のために組み合わせることができます。
また、完全に自動化された常に最新のデータパイプラインを構築するには:
- Bright DataのWeb Scraping APIをトリガーして、Amazon S3のソースデータを更新します。
- Bright Dataで、Webhookを設定してAlteryx Oneワークフロー実行APIを呼び出します。
まとめ
このチュートリアルでは、Alteryx Oneが自動データ分析にもたらすものを学びました。具体的には、Bright DataのWeb Scraping APIで取得したデータをAmazon S3を通じてAlteryx Oneに統合する方法を確認しました。高品質なウェブデータはインサイトの精度と価値を大幅に向上させ、より優れた分析結果をもたらします。
今すぐBright Dataの無料アカウントを作成して、エンタープライズ対応のウェブデータソリューションを探索してみましょう!




