




- APIベースのスクレイパー
APIリクエスト構築用インターフェース - 大規模な自動化
頻度を制御する独自のスケジューラーを構築 - 配信
データを指定のストレージに配信、またはダウンロード
- APIやノーコードでオンデマンド対応
- 専任のアカウントマネージャー
- 大量リクエストの処理、最大5K URLsまで
- 結果を複数のフォーマットで取得
Trusted by 20,000+ customers worldwide
Wikipediaデータを簡単にスクレイピング

完全管理オプション
当社のマネージドサービスで、手間のかからないデータをお楽しみください
ウェブスクレイパー
利用可能なスクレイパー
インフラの開発や保守は不要。WebスクレイパーAPIやノーコードスクレイパーを使って、大量のWebデータを簡単に抽出し、スケーラビリティと信頼性を確保しましょう。
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 9.3K+
9.3K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - It collects the latest posts from the profile URL.
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook - Pages Posts by Profile URL - Collect profile information by user name
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Google News
URL, Title, Publisher, Date, Category, Keyword, Country, Image, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Yelp businesses overview
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Yelp businesses overview - Collect Yelp businesses by url
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Facebook - Comments
URL, Post id, Post url, Comment id, User name, User id, User url, Date created, and more.
Zoominfo companies information
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
Zoominfo companies information - discover records by search url
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
pitchbook companies information
URL, ID, Company name, Company socials, Year founded, Status, Employees, Latest deal type, and more.
Glassdoor job listings information
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Collect new jobs by keyword search like the job title
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Discover jobs by company URL
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Google Shopping
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Google Shopping - collects products from web using keywords
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Amazon sellers info
Seller id, URL, Seller name, Description, Detailed info, Stars, Feedbacks, Return policy, and more.
Amazon products global dataset
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collecting products by keyword search
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect Amazon products by seller URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect products from Brands URLs
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Gather data on products using specified keywords
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect products from shops on eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect records by category
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
Github repository
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - Discover github code by repository URL
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - discover new records by search url
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Home Depot US
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Gather data on products using specified keywords
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified UPC
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discovery products by specific category URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Facebook - Posts by group URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook Marketplace
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - Collect Facebook marketplace listings by keyword
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - discover by url
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook - Posts by post URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Australia real estate properties
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - discover records by search url
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - Discover records by Listing type
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Etsy
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collect data on products using specified keywords
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collects data from shop's URL
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Google Play Store
URL, Title, Developer, Monetization features, Images, About, Data safety, Rating, and more.
TikTok - Comments
URL, Post url, Post id, Post date created, Date created, Comment text, Num likes, Num replies, and more.
Trustpilot business reviews
Company name, Review id, Review date, Review rating, Review title, Review content, Is verified review, Review date of experience, and more.
G2 software - product reviews
Review id, Author id, Author, Position, Company size, Stars, Date, Title, and more.
Amazon products search
Asin, URL, Name, Sponsored, Initial price, Final price, Currency, Sold, and more.
Booking Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Yelp businesses reviews
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Yelp businesses reviews - Search for Yelp businesses by country, category and location
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Reddit - Comments
URL, Comment id, User posted, Comment, Date posted, Post url, Post id, Community name, and more.
Zillow price history
URL, Zpid, Date, Event, Posting is rental, Price, Price change rate, Price per squarefoot, and more.
Zara - Products
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Zara - Products - discovery by category url
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Facebook - Profiles
URL, Name, ID, Profile photo, Cover photo, Work, College, High school, and more.
Wikipedia articles
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Wikipedia articles - Discover new articles by searching keywords in Wikipedia
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Target
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Gather data on products using specified keywords
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by category url
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by specified UPC
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Indeed companies info
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - By company list
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Discover companies by Industries and location (State) in US
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Search company by company name
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Zoopla properties listing information
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Zoopla properties listing information - Discover by custom filters - location and property type
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Pinterest - Posts
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Collects posts by specific keywords
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Discover posts by using specific profile url
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Youtube - Comments
Comment id, Comment text, Likes, Replies, Username, Username md5, User channel, Date, and more.
Facebook - Pages and Profiles
ID, URL, Page name, Username, Entity type, Summary text, Primary category, Work, and more.
Best Buy products
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Best Buy products - Collect data on products using specified keywords
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Lazada - Products
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by keyword
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by category URL or brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by seller URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lowes.com
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Gather data on products using specified keywords
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Collect records by category
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Walmart sellers info
Seller id, URL, Catalog seller id, Seller name, Seller display name, Seller email, Seller phone, Seller about us, and more.
Facebook Events
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - discover Facebook events search URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - Discover events by venue URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Sephora products
URL, ID, Name, Sku, In stock, Regular price, Actual price, Unit price, and more.
OLX Brazil - marketplace ads
Body, Subject, Currency, PriceValue, ProfessionalAnnouncement, Category, ParentCategoryName, CategoryName, and more.
Ikea - Products
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
Ikea - Products - Discovery new products by category URL
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
BBC news
ID, URL, Author, Headline, Topics, Publication date, Content, Videos, and more.
BBC news - Discover BBC articles by keyword
ID, URL, Author, Headline, Topics, Publication date, Content, Videos, and more.
Xing social network
Account id, FamilyName, Gender, Membership, Country code, Experience, Education, Languages, and more.
Ozon.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Description, Image, and more.
Facebook - Reels by profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Wayfair products
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - Gather data on products using specified keywords
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - discover records by category url
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Google Play Store reviews
URL, Review id, Reviewer name, Review date, Review rating, Review, Found helpful, App url, and more.
Google Shopping products search US
URL, Product id, Title, Final price, Initial price, Currency, Rating, Reviews count, and more.
Digikey - Products
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Digikey - Products - Discover by category url
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Facebook Company Reviews
Company name, Company id, Company url, URL, Review time, Recommends, Review content, Review attachments, and more.
Myntra products
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by category URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by keyword
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by brand URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Owler companies information
CompanyID, Ownership, IndustrySectors, Revenue, Founded, CompanyName, Country, EmployeeCount, and more.
Naver products
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
Naver products - Discover products by category
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
US lawyers directory
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
US lawyers directory - Search on the website by attorney name, practice area, school, articles, or location
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
H&M - Products
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
H&M - Products - Discovery new products by category URL
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
Webmotors Brasil - Cars Listings
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
Webmotors Brasil - Cars Listings - Discover new records by category URL
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
Tokopedia Products
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Search products by keyword
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect URLs of products by category URLs
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect Tokopedia's products by seller URL
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
CNN news
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
CNN news - Discover CNN articles by search URL
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
CNN news - Discovery article by the publishing date and time
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
Mouser - Products
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
Mouser - Products - Discovery new products by category URL
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
Apple App Store reviews
URL, Review id, Review title, Review rating, Reviewer name, Review date, Review, Developer response, and more.
Agoda Properties Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by country
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by filter url
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Wildberries.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Image, Brand, and more.
Zonaprop Argentina - Properties Listing
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
Zonaprop Argentina - Properties Listing - Discover products by domain
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
Quora posts
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Quora posts - Search url of a question on Quora to discover answers given
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Pinterest - Profiles
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Pinterest - Profiles - Discover profiles by Keyword in profile name and profile posts
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
VentureRadar company information
URL, Location, Name, Country code, Ownership, Score, Auto analyst score, Website popularity, and more.
Inmuebles24 Mexico - Properties Listings
URL, Title, GeneratedTitle, Description, Seller, Precio, Publicado hace, CreatedDate, and more.
Chileautos Chile - Cars Listings
URL, Marca, Modelo, Ano, Variante, Kilometraje, Condicion, Combustible, and more.
Zalando products
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by domain
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover records by search keyword
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by category URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Collect products by brand URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Trustradius product reviews
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Trustradius product reviews - discover all reviews by product url
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Yapo Chile - marketplace ads
Title, Description, Seller name, Root category id, Root category name, Parent category id, Parent category name, Active, and more.
mercadolivre.com.br products
URL, Product id, Title, Breadcrumbs, Category, Tags, Final price, Original price, and more.
Asos - Products
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by category URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by keyword
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by brand URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
carsales.com.au - Cars Listings
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
carsales.com.au - Cars Listings - Collect car listings by keyword
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
Bluesky - Posts
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Bluesky - Posts - Collect posts from profile URL
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Vimeo - Videos posts
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - focus on licensed videos with "common creative" license
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - scrape videos by URL
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Lazada - Reviews
URL, Title, Rating, Reviews, Seller name, Sku, Mpn, Is super seller, and more.
Lego - Products
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Lego - Products - Discovery new products by category URL
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Hermes- Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Hermes- Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Metrocuadrado - Properties Listings
URL, ID, Precio, Habitaciones, Banos, Dimension propiedad, Dimension terreno, Comuna Ciudad, and more.
Home Depot CA
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - Gather data on products using specified keywords
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - discover records by category url
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Chanel Products
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Chanel Products - Discover new products in Chanel by category URL
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Lazada products search (GMV)
URL, Name, Price, Currency, Number sold, Sku, Image url, Rating, and more.
Kroger.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Kroger.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Dior - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Dior - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Toctoc - Properties Listings
Imagen, No de imagenes, Descripcion, Precio, Currency, Ubicacion, Habitaciones, Banos, and more.
Infocasas Uruguay - Properties Listings
URL, ID, Imagen, Descripcion, Precio, Ubicacion, Habitaciones, Banos, and more.
Ashleyfurniture - Products
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - sitemap
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - Discovery new products by category URL
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Properati Argentina and Colombia - Properties Listings
Type, Name, Estrato, Habitaciones, Banos, M2, Descripcion, Precio, and more.
Apple App Store
URL, Title, Sub title, Developer, Top charts, Monetization features, Image, Screenshots, and more.
AE.com - Complete Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
AE.com - Complete Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Mango Products
Product name, Price, Image, Size, Product article, Availability, Description, Colour code, and more.
Balenciaga.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Balenciaga.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Costco products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mediamarkt.de products
Brand, Description, Manufacturer, Ean, Sku, Initial price, Final price, In stock, and more.
Fanatics.com - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Fanatics.com - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Macys.com
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - By category url
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - Search by keyword
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Rona.ca products
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Rona.ca products - Discover records by category URL
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Rona.ca products - Discover records by search URL
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Toysrus - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Toysrus - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Crateandbarrel - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Crateandbarrel - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Autozone - products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Zara Home Products
Category id, Category key, Category name, Product id, Product name, Price, Price discount, Price with fillings, and more.
Carters.com - Products
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
Carters.com - Products - Discovery new products by category URL
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
Snapchat posts
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover posts by profile url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover new posts by search url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Loewe.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Loewe.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Prada.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Prada.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Twitch - streams dataset
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by a search term
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by category url
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Fendi Products
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
Fendi Products - Discover products by category URL
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
ChatGPT Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Recommendations, Country, and more.
Micro Center Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Bottegaveneta.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Bottegaveneta.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Massimo Dutti - Products
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Massimo Dutti - Products - Discovery new products by category URL
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Delvaux - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Delvaux - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Ysl.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Google SERP - 100 Results
URL, Keyword, General, Related, Pagination, Organic, People also ask, Navigation, and more.
Montblanc - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Montblanc - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Raymourflanigan.com - Products
Product name, Seller name, Brand, Description, Initial price, Final price, Currency, In stock, and more.
Harbor Freight Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Harbor Freight Products - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Mybobs.com - Products
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
Mybobs.com - Products - Discovery new products by category URL
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
B&H Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
 249+
249+Mattressfirm - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Mattressfirm - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
llbean.com - Products
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
llbean.com - Products - Discovery new products by category URL
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
Celine.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Celine.com - Products - Discover new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Sleepnumber.com - Products
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
Sleepnumber.com - Products - Discovery new products by category URL
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
Berluti.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Berluti.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Moynat.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
La-z-boy.com - Products
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
La-z-boy.com - Products - Discovery new products by category URL
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
Google AI Mode Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Index, Country, and more.
Walmart - products zipcodes
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by Keyword
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Poshmark.com
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by category
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by keyword
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Sweetwater
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Bass Pro Shops
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Suumo.jp
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
236+Suumo.jp - Discovery records by category
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
236+ACE products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ACE products - Sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Barnes & Noble Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mercari Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Ferguson Home Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Home Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vevor Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
233+Vevor Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
233+Threads - Posts
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Threads - Posts - Discover posts by profile URL
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Guitar Center Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zillow Full Properties Information
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Zillow Full Properties Information - Discover zillow records by zillow search url
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Overstock.com
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - Discovery by category
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - keyword
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Dick’s Sporting Goods
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
231+Summit Racing Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
231+Abercrombie & Fitch
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Dell Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Flipkart.com
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Flipkart.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Flipkart.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
apple shop products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Perplexity Search
URL, Prompt, Answer html, Answer text, Answer text markdown, Sources, Source html, Is shopping data, and more.
Newegg Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Staples
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Gemini Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Country, Index, and more.
Flipkart - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Flipkart - Reviews - Collect reviews by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
adidas products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
academy products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Falabella.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Falabella.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Bed Bath & Beyond
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Falabella.com
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by category
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by keyword
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Oscaro products - Global
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
LinkedIn people search
URL, Name, Subtitle, Location, Experience, Education, Avatar, and more.
Agoda Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
222+Snapchat profile
URL, Profile id, Profile name, Profile username, Profile alternate name, Profile description, Profile address, Profile image url, and more.
Threads - Profiles
URL, Profile name, Profile id, About formatted, Number of followers, Website, Instagram profile url, Threads, and more.
Office Depot Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Office Depot Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
GameStop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Grok Search
URL, Prompt, Answer text, Answer html, Index, Answer text markdown, Citations, Response raw, and more.
Trip Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Google Flights - Collect flights by input filters
URL, Itinerary id, Search, Pricing, Providers, Legs, and more.
Kroger.com - Search
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Kroger.com - Search - Discovery by category
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Kroger.com - Search - Discovery by keyword
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Flipkart.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Myfood4less.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Motointegrator.de
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by category
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by keyword
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Bing Copilot Search
URL, Prompt, Answer text, Answer html, Answer text markdown, Sources, Index, Answer section html, and more.
Macys.com - Reviews
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Macys.com - Reviews - In/out collector
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Zillow properties search page
URL, Zpid, Zipcode, Description, City, Country, State, Address, and more.
Walmart products search
ID, URL, Typename, Buy box suppression, Similar items, Us item id, Is bad split, Name, and more.
Trip Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Trip Hotel Listings - Collect hotels listings by location
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Falabella.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Vinted - Global
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by category URL
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by search
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Instacart products
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
Instacart products - Collect products by category URL
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
Kohls.com - Reviews
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Kohls.com - Reviews - Discovery by SKU
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Therealreal.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com - Discovery by category
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com - Discovery by keyword
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+TikTok - Posts by Profile Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Goodreads reviews
URL, Review url, Review id, Book details, Reviewer details, Rating, Review text, Review date, and more.
217+Goodreads reviews - Collect review by book URL
URL, Review url, Review id, Book details, Reviewer details, Rating, Review text, Review date, and more.
217+Kohls.com
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery PDPs by category URL
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery by keyword
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Idealo Global
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
217+Idealo Global - Discovery by category URL
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
217+Idealo Global - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
217+Idealo Global - Discovery by category URL and keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
217+TikTok - Posts by URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Agoda Properties Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings with Pricing - Collect properties listings by search inputs
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Google Hotel
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discovery records by search
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discover records by filter URL
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Reddit - Profiles
URL, Profile id, Name, Followers, Social links, Karma, Contributions, Reddit age, and more.
Overstock.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
216+Overstock.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
216+TikTok - Posts by Search URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Coupang products
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by category
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect product by brand URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by seller URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
TikTok Shop Category Products
URL, Product id, Category url, Category name, Sub categories, Title, Initial price, Final price, and more.
Booking Hotel Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings with Pricing - Collect listings by search input
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
スクレイピングの手間を省略
取得済みデータセット
より迅速な導入
1回の API 呼び出し。大量のデータ。
データディスカバリー
データの構造とパターンを検出し、効率的で的を絞ったデータ抽出を行います。
一括要求処理
サーバーの負荷を軽減し、大規模なスクレイピングタスクのデータ収集を最適化します。
データ解析
未加工のHTMLを構造化データに効率的に変換し、データの統合と分析を容易にします。
データ検証
データの信頼性を確保し、手作業での確認と前処理にかかる時間を節約できます。
仕組み
プロキシや CAPTCHA の心配はもうありません
- 自動 IP ローテーション
- CAPTCHA 解決ツール
- ユーザーエージェントローテーション
- カスタムヘッダー
- JavaScript レンダリング
- レジデンシャルプロキシ


最高峰の DX
簡単に開始可能。容易にスケーリング可能。
比類のない安定性
世界をリードするプロキシインフラストラクチャを利用することで、一貫したパフォーマンスを確保し、障害を最小限に抑えることができます。
Web スクレイピングをシンプルに
本番環境に対応した API でスクレイピングを自動化することで、リソースを節約し、メンテナンスの手間を減らせます。
無限のスケーラビリティ
最適なパフォーマンスを維持しつつ、データ需要に合わせてスクレイピングプロジェクトを簡単にスケーリングできます。
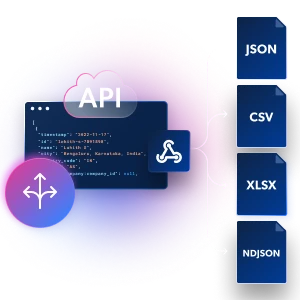
柔軟性
お客様のワークフローに合わせてカスタマイズ
Webhook や API 配信を使用して、JSON、NDJSON、または CSV ファイルで構造化 LinkedIn データを取得できます。

スケーラブル
ビルトインのインフラストラクチャとブロック解除
お客様がプロキシやブロック解除インフラストラクチャを管理する必要がないので、最大限の制御と柔軟性を実現できます。どの地理上の位置からでも、CAPTCHA やブロックを回避して簡単にデータをスクレイピングできます。

優れた安定性
実績のあるインフラストラクチャ
全世界 2 万社以上の企業に導入されている Bright Data プラットフォームは、アップタイム 99.99%、195 か国に広がる 7,200 万以上の実在のユーザー IP の使用で、安心してご利用いただけます。

コンプライアンス適合性
業界トップクラスのコンプライアンス
EU のデータ保護規制フレームワーク GDPR や CCPA をはじめ、各種のデータ保護法に準拠する当社のプライバシー慣行に基づき、お客様のプライバシー権の行使の要求などを尊重しています。
WikipediaスクレイパーAPIの使用事例
さまざまなトピックの解説を収集
Wikipedia の情報を他の情報源と比較
膨大なデータセットに基づいて調査を実施
Wikipedia Commons 画像のスクレイピング
なぜ 20,000+ のお客様がBright Dataを選ぶのか
100% 準拠
スクレイピングされたデータは倫理的に取得され、全てのプライバシー法に準拠しています。
24時間365日グローバルサポート
専任のデータ専門家チームがサポートいたします。
完全なデータカバレッジ
150 million+ グローバルIPにアクセスし、あらゆるウェブサイトからデータをスクレイピングできます。
不一致のデータ品質
高品質なデータのための先進技術と検証手法。
強力なインフラストラクチャ
ブロックされずに大量データをスクレイピングする。
カスタムソリューション
独自のニーズと目標に合わせたソリューションを提供します。
Bright Dataは世界のトップブランドに採用されています
当社は、安全で拡張性・柔軟性に優れたデータ管理により、企業の成長を支援します。
Wikipedia スクレイパーAPIに関するよくある質問
WikipediaスクレイパーAPIとは何か
WikipediaスクレイパーAPIは、Wikipedia Webサイトからのデータ抽出を自動化するように設計された強力なツールで、ユーザーはさまざまなユースケースで大量のデータを効率的に収集し、処理できます。
WikipediaスクレイパーAPIはどのように機能しますか?
WikipediaスクレイパーAPIは、Wikipedia Webサイトに自動リクエストを送信し、必要なデータポイントを抽出し、構造化された形式で提供します。このプロセスにより、正確で迅速なデータ収集が可能となります。
WikipediaスクレイパーAPIはデータ保護規制に準拠していますか?
はい、WikipediaスクレイパーAPIはGDPRやCCPAを含むデータ保護規制に準拠するように設計されています。これは、すべてのデータ収集活動の倫理的かつ合法的な実行が保証されることを意味します。
WikipediaスクレイパーAPIは競合分析に使用できますか?
もちろんです!WikipediaスクレイパーAPIは競合分析に最適で、競合他社の活動、動向、戦略に関する情報を収集できます。
WikipediaスクレイパーAPIを既存のシステムに統合するにはどうすれば良いですか?
WikipediaスクレイパーAPIは、さまざまなプラットフォームやツールと完璧に統合することができます。既存のデータパイプライン、CRMシステム、または分析ツールと組み合わせて使用すると、データ処理能力を向上させることができます。
WikipediaスクレイパーAPIの使用制限はどのくらいですか?
WikipediaスクレイパーAPIには特定の使用制限がないため、必要に応じて柔軟に拡張できます。
WikipediaスクレイパーAPIのサポートは提供していますか?
はい、WikipediaスクレイパーAPI専用のサポートを提供しています。当社のサポートチームは、APIの使用中に生じる可能性のある質問や問題について、24時間週7日年中無休体制で対応しています。
どのような配信方式が利用可能ですか?
Amazon S3、Google Cloud Storage、Google PubSub、Microsoft Azure Storage、Snowflake、SFTPをご利用いただけます。
どのファイル形式が利用可能ですか?
次のファイル形式が利用可能です:JSON、NDJSON、JSON Lines、CSV、.gzファイル(圧縮)